对Langchain4j的补充以及与springAi的对比
| 框架 | 核心定位 | Agent 能力 | 对你的开发影响 |
|---|---|---|---|
| LangChain4j | Java 生态专门做LLM 应用 / Agent 开发的一站式框架,Agent 是它的原生核心能力 | 完整的 Agent 闭环开箱即用,自带 Think-Act-Observe 循环、工具解析、上下文管理、异常重试、终止判断,全给你封装好了 | 你只需要定义工具,一行循环代码都不用写,几行代码就能实现多轮工具调用的 Agent |
| Spring AI | Spring 生态的大模型统一适配层,核心目标是屏蔽不同大模型的 API 差异,让你在 Spring 里方便对接各种 LLM | 只提供了「单次工具调用」的底层积木,完全没有内置完整的 Agent 闭环流程 | 所有的循环逻辑、状态管理、上下文维护、异常处理、死循环防护,全要你自己手写,开发成本极高 |
用代码对比,直观感受天差地别
就用你的 AI 零代码平台最核心的场景:用户说一句话,AI 自动完成「生成页面代码→截图生成封面→部署上线→返回结果」的多步操作。
1. LangChain4j 写法:开箱即用,几行代码搞定
你只需要做两件事:定义工具、发起对话,剩下的 Agent 多轮循环全给你自动处理。
/**
* 第一步:定义你的业务工具,加个@Tool注解就行
*/
@Component
public class AppDevTools {
@Tool("根据用户需求生成前端页面代码")
public String generatePageCode(String userDemand) {
// 你的代码生成逻辑
return "生成的完整前端页面代码";
}
@Tool("根据页面代码生成封面截图,返回截图保存路径")
public String generateAppCover(String pageCode) {
// 你之前写的WebDriver截图逻辑
return "/app-cover/xxx/cover.jpg";
}
@Tool("部署前端页面,返回线上访问地址")
public String deployApp(String pageCode) {
// 你的部署逻辑
return "https://xxx.xxx.com/app/123";
}
}
/**
* 第二步:调用Agent,一行代码搞定多轮执行
*/
@Service
public class AppDevService {
@Autowired
private ChatLanguageModel chatLanguageModel;
@Autowired
private AppDevTools appDevTools;
public String handleUserDemand(String userDemand) {
// 构建AI服务,注册工具,直接调用
return AiServices.builder(chatLanguageModel)
.tools(appDevTools) // 注册你的工具
.build()
.chat(userDemand); // 自动完成多轮工具调用,直接返回最终结果
}
}这就实现了Agent的功能。
就这么点代码,LangChain4j 会自动完成:
- 先思考调用「生成页面代码」工具,拿到代码;
- 再思考调用「生成封面截图」工具,拿到截图路径;
- 再思考调用「部署应用」工具,拿到部署地址;
- 最后判断需求完成,整理结果返回给用户。
全程你不用写任何循环、判断、上下文维护的代码,框架全给你封装好了,连异常重试、格式校验、上下文管理都帮你处理了。
2. Spring AI 写法:所有 Agent 逻辑全要自己手写
Spring AI 只给你提供了最基础的「调用大模型」「执行单次工具」的接口,整个 Agent 的闭环逻辑,全要你自己从零搭建。要实现上面完全一样的功能,你要写这么多:
@Service
public class SpringAiAppDevService {
@Autowired
private ChatClient chatClient;
// 你自己定义的工具,还要自己实现Spring AI的FunctionCallback接口
private final List<FunctionCallback> devTools = List.of(
new GeneratePageCodeTool(),
new GenerateCoverTool(),
new DeployAppTool()
);
public String handleUserDemand(String userDemand) {
// 1. 自己手动维护对话上下文,全程自己管
List<Message> messageContext = new ArrayList<>();
messageContext.add(new UserMessage(userDemand));
// 2. 自己手写死循环,实现Think-Act的闭环
int maxLoopCount = 10; // 自己加防死循环的限制,不然大模型瞎调用会卡死
int currentLoop = 0;
while (currentLoop < maxLoopCount) {
currentLoop++;
// 3. 自己调用大模型
ChatResponse response = chatClient.prompt()
.messages(messageContext)
.functions(devTools)
.call()
.chatResponse();
AssistantMessage assistantMsg = response.getResult().getOutput();
// 4. 自己解析大模型的输出,判断要不要调用工具
if (assistantMsg.getToolCalls().isEmpty()) {
// 没有工具调用,自己判断结束循环,返回结果
return assistantMsg.getText();
}
// 5. 自己遍历工具调用,自己执行,自己处理异常
for (ToolCall toolCall : assistantMsg.getToolCalls()) {
try {
// 自己找对应的工具,自己传参,自己处理参数解析异常
FunctionCallback tool = findTool(toolCall.getName());
String toolResult = tool.call(toolCall.getArguments());
// 6. 自己把工具执行结果,手动加入上下文
messageContext.add(new ToolMessage(toolResult, toolCall.getId()));
} catch (Exception e) {
// 自己处理工具调用异常,自己给大模型返回错误信息
messageContext.add(new ToolMessage("工具执行失败:" + e.getMessage(), toolCall.getId()));
}
}
// 7. 自己把大模型的回复加入上下文,继续下一轮循环
messageContext.add(assistantMsg);
}
// 自己处理循环超时的兜底逻辑
return "抱歉,操作步骤过多,未能完成您的需求,请简化需求后重试";
}
// 自己写工具查找逻辑
private FunctionCallback findTool(String toolName) {
return devTools.stream()
.filter(tool -> tool.getName().equals(toolName))
.findFirst()
.orElseThrow(() -> new RuntimeException("工具不存在:" + toolName));
}
}智能体(Agent)构建智能体开发_智能体开发示例-CSDN博客 w
我这里也有写SpringAi的Agent的搭建。
这还只是最基础的骨架,你还要额外处理:
- 大模型输出格式错误的兼容;
- 工具调用超时控制;
- 上下文长度溢出的管理;
- 更复杂的异常重试、回退逻辑;
- 多用户对话的记忆隔离。
这些东西,LangChain4j 全给你内置好了,Spring AI 全要你自己手写造轮子,开发成本和出 bug 的概率,完全不是一个量级的。
LangChain4j 自带了完整的 Agent 能力,开箱即用;Spring AI 只给了底层积木,Agent 要你自己从零搭建。
并且LangChain4j还可以自定义Agent:
1. 最基础的自定义:改提示词、改循环上限、改重试策略
开箱即用的 AiServices,本身就支持大量自定义,一行配置就能改,不用重写逻辑
AiServices.builder(chatLanguageModel)
.tools(appDevTools)
// 自定义系统提示词,给Agent定专属的行为规范(比如你的代码生成规范)
.systemMessageProvider(ctx -> "你是一个专业的低代码平台开发助手,必须严格遵守以下规范:1. 生成的代码必须是Vue3+TS;2. 生成代码前必须先确认需求边界;3. 代码生成后必须先做语法校验,再执行后续操作...")
// 自定义最大循环次数,防止死循环
.maxRetries(5)
// 自定义超时时间
.timeout(Duration.ofSeconds(120))
// 自定义记忆存储(比如把对话记录存到数据库,而不是内存)
.chatMemory(persistentChatMemory)
// 自定义工具执行异常的回调
.onToolCallError((toolCall, error) -> {
log.error("工具调用失败", error);
return "工具执行失败,错误信息:" + error.getMessage() + ",请换一种方式重试,或告知用户问题";
})
.build();这些最常用的个性化配置,LangChain4j 直接给你封装好了,一行配置就搞定,不用你自己写逻辑。
2. 深度自定义:完全重写 Agent 的思考与执行逻辑
如果你觉得默认的 Agent 逻辑满足不了你的需求,比如你要做一个「代码生成→语法校验→安全扫描→截图→部署」的固定流程 Agent,或者要自定义大模型的思考逻辑,LangChain4j 提供了 Agent 接口,你可以完全自定义核心逻辑,同时还能复用框架里的工具解析、上下文管理、异常处理等成熟能力,不用从零写。
举个自定义 Agent 的极简例子:
/**
* 自定义专属的代码开发Agent,完全自定义执行逻辑
*/
public class CustomCodeDevAgent implements Agent {
private final ChatLanguageModel chatLanguageModel;
private final List<ToolSpecification> tools;
private final int maxSteps;
// 构造方法,传入你的大模型、工具、配置
public CustomCodeDevAgent(ChatLanguageModel chatLanguageModel, List<Object> toolObjects, int maxSteps) {
this.chatLanguageModel = chatLanguageModel;
this.tools = ToolSpecifications.toolSpecificationsFrom(toolObjects);
this.maxSteps = maxSteps;
}
// 重写核心的执行逻辑,完全自定义
@Override
public AgentResult run(ChatMemory chatMemory) {
int currentStep = 0;
while (currentStep < maxSteps) {
currentStep++;
// 1. 自定义思考逻辑:给大模型加专属的步骤提示
chatMemory.add(SystemMessage.from("当前是第" + currentStep + "步执行,请严格按照「需求分析→代码生成→校验→部署」的流程执行,不要跳步"));
// 2. 调用大模型,框架帮你处理工具提示词注入
ChatResponse response = chatLanguageModel.generate(chatMemory.messages(), tools);
AssistantMessage assistantMessage = response.result().output();
chatMemory.add(assistantMessage);
// 3. 自定义判断逻辑:没有工具调用,就结束
if (assistantMessage.toolCalls().isEmpty()) {
return AgentResult.finished(assistantMessage.text());
}
// 4. 自定义工具执行逻辑:比如先校验工具权限,再执行,失败了自定义重试
for (ToolCall toolCall : assistantMessage.toolCalls()) {
// 自定义:比如检查用户有没有权限调用这个部署工具
if (!hasPermission(toolCall.name())) {
chatMemory.add(ToolMessage.from("你没有权限调用这个工具,请更换方案", toolCall.id()));
continue;
}
// 执行工具,框架帮你处理参数解析、方法调用
ToolExecutionResult result = ToolExecutor.execute(tools, toolCall);
if (result.isError()) {
// 自定义异常处理
chatMemory.add(ToolMessage.from("工具执行失败:" + result.error(), toolCall.id()));
} else {
chatMemory.add(ToolMessage.from(result.output(), toolCall.id()));
}
}
}
// 自定义超出步数的兜底逻辑
return AgentResult.finished("执行步骤超出上限,未能完成全部需求,请简化需求后重试");
}
// 自定义权限校验方法
private boolean hasPermission(String toolName) {
// 你的权限逻辑
return true;
}
}你看,哪怕你完全重写 Agent 的核心逻辑,LangChain4j 还是帮你做了大量的脏活累活:
- 工具的定义、解析、参数绑定,不用你自己写;
- 工具的执行、异常捕获,不用你自己处理;
- 对话上下文、记忆的管理,框架帮你维护;
- 你只需要聚焦在「自定义业务逻辑」上,不用从零造轮子。
更极致的自定义:全链路组件替换
LangChain4j 里的所有核心组件,都是可插拔、可替换的:
- 你想自定义记忆的存储方式(比如存 Redis、存数据库):实现
ChatMemory接口就行; - 你想自定义工具的解析和执行逻辑:实现
ToolExecutor接口就行; - 你想自定义大模型的输出解析器:实现
OutputParser接口就行; - 甚至你想自定义流式输出的 Agent 逻辑,也有对应的接口支持。
Spring AI 所谓的 “自定义 Agent”,本质是框架完全不提供任何 Agent 相关的封装,所有逻辑全要你自己手写。就像我上一轮给你看的代码例子,哪怕是最基础的多轮工具调用循环,你都要自己写:
- 自己维护对话上下文;
- 自己写 while 死循环,自己加防死循环的限制;
- 自己解析大模型的工具调用输出,自己找对应的工具;
- 自己处理工具的参数绑定、方法调用、异常处理;
- 自己把工具执行结果拼回上下文,自己控制循环的终止;
- 所有的权限校验、重试逻辑、超时控制,全要你自己一行一行写。
这根本不叫 “自定义 Agent”,这叫「从零实现一个 Agent 框架」。
- 不管是开箱即用的 Agent,还是深度自定义的 Agent,LangChain4j 都是最优选择。它的自定义能力极强,从简单的配置修改,到全链路的逻辑重写,都能支持,而且有成熟的框架兜底,帮你省掉 90% 的脏活累活,开发效率高、坑少、稳定性强。
- Spring AI 完全不适合做 Agent 开发,哪怕是自定义的。它没有任何 Agent 框架的封装,所谓的自定义,就是让你从零实现整个 Agent 的所有逻辑,开发成本极高,只适合极其特殊、连 LangChain4j 都满足不了的场景(这种场景 99.9% 的业务都遇不到)。
AI工作流(超级超级超级重要):
、先彻底搞懂:工作流到底是个啥?为啥要用它?
1. 最直白的类比
你可以把「工作流」理解成一份写死的「奶茶制作流程单」:
- 你开奶茶店,做一杯奶茶,必须按固定步骤来:接单→选茶底→煮茶→加小料→加糖→装杯→封口→给顾客。
- 中间还有分支:顾客要无糖,就跳过加糖;要加双份珍珠,就多一步加珍珠;做错了,就要回到上一步重做。
而我们代码里的「工作流」,就是把「AI 代码生成」这个复杂的事,像做奶茶一样,拆成一步一步的小任务,再规定好「先做啥、后做啥、啥情况走啥分支、做错了要不要重来」。
2. 不用工作流会咋样?(痛点对比)
就像你做奶茶,没有流程单,想到啥做啥:煮茶煮到一半去加糖,加完糖发现茶还没煮好,顾客要无糖你忘了,全乱了。
对应到代码里,如果不用工作流,AI 代码生成的逻辑会写成一个超大的方法,里面塞满了:
- 一堆
if/else判断(要不要加图片、要不要质检) - 一堆循环重试(代码质检不通过,要重新生成)
- 一堆手动写的多线程(同时收集不同类型的图片)
- 一堆给前端推进度的代码(每做一步都要告诉前端做到哪了)
最后代码会变成「一锅粥」,改一个小步骤,可能整个方法都要改,还特别容易出 bug。
3. 用了工作流的好处
- 步骤拆分,互不影响:把「收集图片、生成代码、代码质检」拆成一个个独立的小步骤,每个步骤只干一件事,改哪个就改哪个,不会影响别的。
- 流程清晰,一眼看懂:先做啥后做啥,啥情况走啥分支,明明白白写在流程定义里,不用在一堆
if/else里找逻辑。 - 自带高级能力:不用自己写多线程、重试、循环、实时进度推送,工作流的工具包(langgraph4j)已经帮你做好了,直接用就行。
- 好调试、好排查:哪个步骤出错了,一眼就能定位到,不会在大方法里找不到问题在哪
5 个必懂的核心概念(全是大白话,记牢)
我还是用「做奶茶」的例子,给你对应清楚,保证你不会忘
| 专业名词 | 大白话类比 | 干啥用的? |
|---|---|---|
| 工作流(Workflow) | 完整的「奶茶制作流程单」 | 规定了整个事情的所有步骤、顺序、分支规则,是整个流程的总纲 |
| 节点(Node) | 流程里的「单个步骤」(比如煮茶、加珍珠) | 每个节点只干一件具体的事,是工作流里最小的执行单元 |
| 边(Edge) | 步骤之间的「先后顺序」(比如煮茶完了才能加珍珠) | 规定了上一个节点做完了,下一步要走到哪个节点 |
| 条件边(Conditional Edge) | 「看情况走不同的路」(比如无糖就跳过加糖) | 根据上一步的结果,动态决定下一步走哪个分支,甚至回到之前的步骤重试 |
| 上下文(Context/State) | 整个流程共用的「小本本」 | 所有步骤的输入、输出、中间结果,全存在这个小本本里。上一步写的内容,后面所有步骤都能看到、能修改,是步骤之间传数据的唯一方式 |
咱们先写一个「做奶茶」的极简工作流,10 分钟就能懂、能跑起来,彻底搞懂它的使用套路。
第一步:先引入依赖(就像买做奶茶的工具)
要使用 langgraph4j,首先要在你的 Spring Boot 项目的pom.xml里,引入它的依赖(鱼皮的项目里已经加好了,你自己写的话要加):
<!-- langgraph4j 核心依赖 -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langgraph4j</artifactId>
<version>0.34.0</version>
</dependency>第二步:定义「共用的小本本」(上下文 / State)
先定义一个类,用来存整个流程里的所有数据,就像奶茶店的订单小票,顾客要啥、做到哪一步了、结果咋样,全写在上面。
import dev.langchain4j.state.State;
import lombok.Data;
/**
* 奶茶制作流程的「共用小本本」
* 整个工作流的所有节点,都能读写这个类里的内容
*/
@Data // 自动生成get/set方法,不用自己写
public class MilkTeaState implements State {
// 顾客的需求
private String teaType; // 茶底:比如珍珠奶茶、果茶
private String sugarLevel; // 甜度:全糖、半糖、无糖
private String topping; // 小料:珍珠、椰果、不加
// 流程中间结果
private String stepResult; // 当前步骤的结果
private String finalProduct; // 最终做好的奶茶
}第三步:写「每个步骤要干的事」(节点 Node)
把做奶茶的每一步,都写成一个独立的方法,每个方法只干一件事,输入是「小本本」,输出也是「更新后的小本本」
/**
* 奶茶制作的所有步骤(节点)
* 每个方法就是一个节点,只干一件事
*/
public class MilkTeaNodes {
/**
* 节点1:煮茶底
*/
public MilkTeaState boilTea(MilkTeaState state) {
// 从小本本里拿到顾客要的茶底
String teaType = state.getTeaType();
// 干自己的活:煮茶
String result = "已经煮好【" + teaType + "】的茶底";
System.out.println(result);
// 把结果写回小本本
state.setStepResult(result);
// 返回更新后的小本本,给下一个步骤用
return state;
}
/**
* 节点2:加小料
*/
public MilkTeaState addTopping(MilkTeaState state) {
String topping = state.getTopping();
String result = "已经添加小料:【" + topping + "】";
System.out.println(result);
state.setStepResult(result);
return state;
}
/**
* 节点3:加糖
*/
public MilkTeaState addSugar(MilkTeaState state) {
String sugarLevel = state.getSugarLevel();
String result = "已经添加甜度:【" + sugarLevel + "】";
System.out.println(result);
state.setStepResult(result);
return state;
}
/**
* 节点4:装杯封口,完成制作
*/
public MilkTeaState finish(MilkTeaState state) {
String finalProduct = "一杯【" + state.getTeaType() + "】,甜度:" + state.getSugarLevel() + ",小料:" + state.getTopping() + ",制作完成!";
System.out.println(finalProduct);
state.setFinalProduct(finalProduct);
return state;
}
}第四步:定义「流程顺序和分支规则」(把节点用边连起来)
现在我们有了小本本、有了每个步骤,接下来就要定「先做啥、后做啥、啥情况跳步」,也就是把工作流拼起来。
import dev.langchain4j.graph.MessagesStateGraph;
import dev.langchain4j.graph.Graph;
public class MilkTeaWorkflow {
public static void main(String[] args) {
// 1. 先把我们写的步骤工具类实例化
MilkTeaNodes nodes = new MilkTeaNodes();
// 2. 创建工作流的构建器,告诉它我们用的小本本是 MilkTeaState
MessagesStateGraph<MilkTeaState> workflowBuilder = MessagesStateGraph.builder(MilkTeaState.class);
// 3. 把所有的节点,加到工作流里(给每个节点起个名字,后面连边要用)
workflowBuilder.addNode("煮茶底", nodes::boilTea);
workflowBuilder.addNode("加小料", nodes::addTopping);
workflowBuilder.addNode("加糖", nodes::addSugar);
workflowBuilder.addNode("完成制作", nodes::finish);
// 4. 定义流程的起点:流程启动后,第一个要执行的节点是啥
workflowBuilder.addEdge("START", "煮茶底");
// 5. 定义普通的边:上一个节点做完,下一步去哪
workflowBuilder.addEdge("煮茶底", "加小料"); // 煮茶完了,就去加小料
workflowBuilder.addEdge("加小料", "加糖"); // 加完小料,就去加糖
// 6. 重点:定义条件边(看情况走分支)
// 需求:如果顾客要无糖,就跳过加糖的步骤,直接去完成制作
workflowBuilder.addConditionalEdge(
"加小料", // 从哪个节点出来后,要做判断
state -> {
// 从小本本里拿到顾客要的甜度
String sugarLevel = state.getSugarLevel();
// 根据甜度,决定下一步走哪个节点
if ("无糖".equals(sugarLevel)) {
return "完成制作"; // 无糖,跳过加糖,直接完成
} else {
return "加糖"; // 有糖,就去加糖的步骤
}
}
);
// 7. 定义流程的终点:哪个节点做完,整个流程就结束了
workflowBuilder.addEdge("加糖", "完成制作"); // 加糖完了,去完成
workflowBuilder.addEdge("完成制作", "END"); // 完成制作,流程结束
// 8. 编译工作流:把你定义的流程,变成能实际跑的程序
Graph<MilkTeaState> workflow = workflowBuilder.compile();
// ---------------------- 以上,我们就把整个工作流定义完了,接下来就是跑它 ----------------------
// 9. 准备初始的小本本:模拟顾客的订单需求
MilkTeaState initState = new MilkTeaState();
initState.setTeaType("珍珠奶茶");
initState.setSugarLevel("半糖"); // 你可以改成"无糖",看看会不会跳过加糖步骤
initState.setTopping("双份珍珠");
// 10. 执行工作流,传入初始的小本本,等它跑完
MilkTeaState finalState = workflow.invoke(initState);
// 11. 拿到最终结果
System.out.println("流程最终结果:" + finalState.getFinalProduct());
}
}第五步:跑一下,看看效果
已经煮好【珍珠奶茶】的茶底
已经添加小料:【双份珍珠】
已经添加甜度:【半糖】
一杯【珍珠奶茶】,甜度:半糖,小料:双份珍珠,制作完成!
流程最终结果:一杯【珍珠奶茶】,甜度:半糖,小料:双份珍珠,制作完成!
如果是无糖的话那个条件边缘判断就不会走进去,直接无糖。
下面咱们来看实战项目中的应用(No code生成平台):
这个工作流其实就是代替了原项目中
@GetMapping(value = "/chat/gen/code", produces = MediaType.TEXT_EVENT_STREAM_VALUE)
@RateLimit(limitType = RateLimitType.USER, rate = 5, rateInterval = 60, message = "AI 对话请求过于频繁,请稍后再试")
public Flux<ServerSentEvent<String>> chatToGenCode(@RequestParam Long appId,
@RequestParam String message,
HttpServletRequest request)这个接口的作用,这个接口的作用是流式回复用户并且把代码写入文件中。
然后部署和静态接口还是不变的那些没有在工作流中。
引入依赖就不说了。
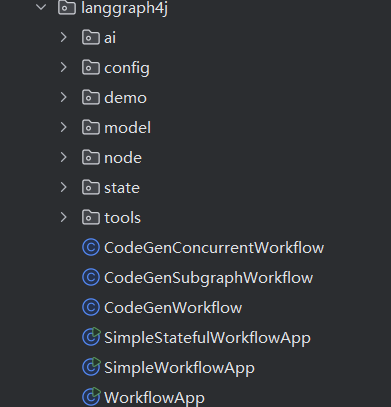
先来看项目结构:
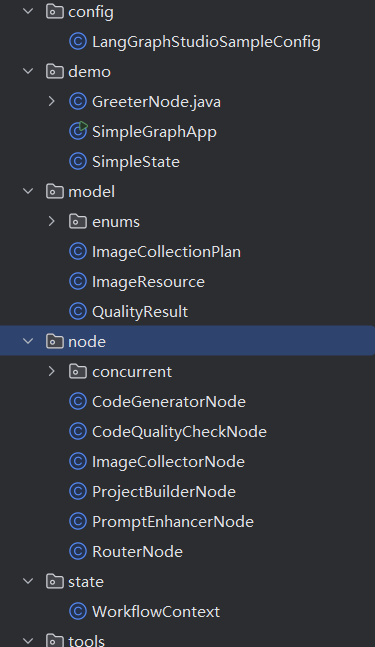
再来看每个包下的:
下面先来看一下流程:
- 触发入口:用户在前端输入需求,点击生成,后端接口收到请求,先创建好整个流程要用的「共享小本本」
WorkflowContext,把用户的需求、appId、代码要存的目录,全写进去。 - 第一步:图片收集:调用
ImageCollectorNode,分析用户的需求,调用 AI 和搜图工具,收集需要的图片、插画、Logo、架构图,把结果写进小本本。 - 第二步:提示词增强:调用
PromptEnhancerNode,把用户的一句话需求,加上前面收集的图片、代码规范、技术栈要求、输出格式,包装成能让 AI 生成高质量代码的专业提示词,写进小本本。 - 第三步:智能路由:调用
RouterNode,让 AI 分析用户的需求,判断要生成什么类型的项目(比如是单页面、还是完整的 Vue 项目、还是官网、还是后台管理系统),确定生成策略,给后续的代码生成做引导,结果写进小本本。 - 第四步:代码生成:调用
CodeGeneratorNode,用前面增强好的提示词和路由结果,调用大模型生成代码,把代码写入本地项目文件,记录生成的文件路径,写进小本本。 - 第五步:代码质检:调用
CodeQualityCheckNode,读取生成的代码,调用 AI 检查代码有没有语法错误、依赖有没有漏、格式规不规范,把质检结果写进小本本。 - 条件分支判断:
- 如果质检通过:继续往下走,执行项目构建节点;
- 如果质检不通过,且重试次数没到 3 次:回到代码生成节点,让 AI 根据错误信息重新生成代码;
- 如果重试次数用完了:直接终止流程,标记生成失败。
- 第六步:项目构建:调用
ProjectBuilderNode,给生成的前端项目执行npm install安装依赖,验证项目能不能正常编译,把最终的成功 / 失败结果写进小本本。 - 流程结束:不管成功还是失败,都会把最终结果实时推送给前端,用户能在页面上看到生成的结果
1. 根目录下的核心工作流定义类(6 个类)
这些类是工作流的「总设计师」,负责把所有节点串成完整的流程,对外提供执行能力
| 类名 | 核心作用 | 在项目里的角色 |
|---|---|---|
CodeGenWorkflow |
最核心的主工作流类,项目里前端调用的就是这个工作流。它做的事:注入所有节点、定义节点的执行顺序、定义条件分支和重试规则、编译工作流、对外提供流式 / 同步执行方法。 | 整个代码生成业务的核心流程定义,用户点击生成按钮,最终跑的就是这个类里定义的工作流。 |
CodeGenConcurrentWorkflow |
并发版工作流,是基础版的优化扩展。核心优化:把原本串行的图片收集步骤,拆成多个并行的子任务(比如搜图片、生成 Logo、生成架构图、找插画可以同时执行),用多线程并行执行,大幅提升图片收集的速度。 | 给需要快速生成多图片的场景用,其他核心的代码生成、质检、构建流程和主工作流完全一致。 |
CodeGenSubgraphWorkflow |
子图版工作流,是代码复用的优化。核心作用:把可复用的流程(比如图片收集流程)封装成一个独立的「子图」,主流程里直接调用这个子图就行,不用重复写节点逻辑。 | 好处是代码复用性高,多个工作流都需要图片收集时,只需要写一次子图,修改的时候也只改一处。 |
WorkflowApp |
工作流本地测试入口类。 | 不用启动整个 Spring Boot 项目,就能在本地写 main 方法测试工作流的执行逻辑,适合开发调试用。 |
SimpleWorkflowApp |
langgraph4j 框架的官方入门 demo,和项目业务无关。 | 用来演示框架最基础的用法,教你怎么定义最简单的节点和流程,不用关注。 |
SimpleStatefulWorkflowApp |
langgraph4j 框架的带状态 demo,和项目业务无关。 | 用来演示框架里的状态传递、更新的基础用法,不用关注。 |
下面来看一步步地解释:
🎯 一、控制层:WorkflowSseController
@RestController
@RequestMapping("/workflow")
public class WorkflowSseController {
// 同步执行 - 等全部完成才返回结果
@PostMapping("/execute")
public WorkflowContext executeWorkflow(@RequestParam String prompt) {
return new CodeGenWorkflow().executeWorkflow(prompt);
}
// Flux 流式 - 逐步推送执行进度
@GetMapping(value = "/execute-flux", produces = MediaType.TEXT_EVENT_STREAM_VALUE)
public Flux<String> executeWorkflowWithFlux(@RequestParam String prompt) {
return new CodeGenWorkflow().executeWorkflowWithFlux(prompt);
}
// SSE 流式 - 手动控制推送事件
@GetMapping(value = "/execute-sse", produces = MediaType.TEXT_EVENT_STREAM_VALUE)
public SseEmitter executeWorkflowWithSse(@RequestParam String prompt) {
return new CodeGenWorkflow().executeWorkflowWithSse(prompt);
}
}| 接口 | 作用 | 适用场景 |
|---|---|---|
/execute |
同步执行,等待工作流全部完成 | 测试、调试 |
/execute-flux |
响应式流式输出进度 | 生产环境 |
/execute-sse |
SSE 服务器推送事件 | 需要精细控制 |
很显然就是三种向前端的推送方式。
🔄 二、工作流定义:CodeGenWorkflow
package com.yupi.yuaicodemother.langgraph4j;
import cn.hutool.json.JSONUtil;
import com.yupi.yuaicodemother.exception.BusinessException;
import com.yupi.yuaicodemother.exception.ErrorCode;
import com.yupi.yuaicodemother.langgraph4j.model.QualityResult;
import com.yupi.yuaicodemother.langgraph4j.node.*;
import com.yupi.yuaicodemother.langgraph4j.state.WorkflowContext;
import com.yupi.yuaicodemother.model.enums.CodeGenTypeEnum;
import lombok.extern.slf4j.Slf4j;
import org.bsc.langgraph4j.CompiledGraph;
import org.bsc.langgraph4j.GraphRepresentation;
import org.bsc.langgraph4j.GraphStateException;
import org.bsc.langgraph4j.NodeOutput;
import org.bsc.langgraph4j.prebuilt.MessagesState;
import org.bsc.langgraph4j.prebuilt.MessagesStateGraph;
import org.springframework.web.servlet.mvc.method.annotation.SseEmitter;
import reactor.core.publisher.Flux;
import java.io.IOException;
import java.util.Map;
import static org.bsc.langgraph4j.StateGraph.END;
import static org.bsc.langgraph4j.StateGraph.START;
import static org.bsc.langgraph4j.action.AsyncEdgeAction.edge_async;
/**
* 代码生成工作流(实际可用)
*/
@Slf4j
public class CodeGenWorkflow {
/**
* 创建完整的工作流
*/
public CompiledGraph<MessagesState<String>> createWorkflow() {
try {
return new MessagesStateGraph<String>()
// 添加节点 - 使用完整实现的节点
.addNode("image_collector", ImageCollectorNode.create())
.addNode("prompt_enhancer", PromptEnhancerNode.create())
.addNode("router", RouterNode.create())
.addNode("code_generator", CodeGeneratorNode.create())
.addNode("code_quality_check", CodeQualityCheckNode.create())
.addNode("project_builder", ProjectBuilderNode.create())
// 添加边
.addEdge(START, "image_collector")
.addEdge("image_caollector", "prompt_enhancer")
.addEdge("prompt_enhancer", "router")
.addEdge("router", "code_generator")
.addEdge("code_generator", "code_quality_check")
// 新增质检条件边:根据质检结果决定下一步
.addConditionalEdges("code_quality_check",
edge_async(this::routeAfterQualityCheck),
Map.of(
"build", "project_builder", // 质检通过且需要构建
"skip_build", END, // 质检通过但跳过构建
"fail", "code_generator" // 质检失败,重新生成
))
.addEdge("project_builder", END)
// 编译工作流
.compile();
} catch (GraphStateException e) {
throw new BusinessException(ErrorCode.OPERATION_ERROR, "工作流创建失败");
}
}
/**
* 执行工作流
*/
public WorkflowContext executeWorkflow(String originalPrompt) {
CompiledGraph<MessagesState<String>> workflow = createWorkflow();
// 初始化 WorkflowContext
WorkflowContext initialContext = WorkflowContext.builder()
.originalPrompt(originalPrompt)
.currentStep("初始化")
.build();
GraphRepresentation graph = workflow.getGraph(GraphRepresentation.Type.MERMAID);
log.info("工作流图:\n{}", graph.content());
log.info("开始执行代码生成工作流");
WorkflowContext finalContext = null;
int stepCounter = 1;
for (NodeOutput<MessagesState<String>> step : workflow.stream(
Map.of(WorkflowContext.WORKFLOW_CONTEXT_KEY, initialContext))) {
log.info("--- 第 {} 步完成 ---", stepCounter);
// 显示当前状态
WorkflowContext currentContext = WorkflowContext.getContext(step.state());
if (currentContext != null) {
finalContext = currentContext;
log.info("当前步骤上下文: {}", currentContext);
}
stepCounter++;
}
log.info("代码生成工作流执行完成!");
return finalContext;
}
/**
* 执行工作流(Flux 流式输出版本)
*/
public Flux<String> executeWorkflowWithFlux(String originalPrompt) {
return Flux.create(sink -> {
Thread.startVirtualThread(() -> {
try {
CompiledGraph<MessagesState<String>> workflow = createWorkflow();
WorkflowContext initialContext = WorkflowContext.builder()
.originalPrompt(originalPrompt)
.currentStep("初始化")
.build();
sink.next(formatSseEvent("workflow_start", Map.of(
"message", "开始执行代码生成工作流",
"originalPrompt", originalPrompt
)));
GraphRepresentation graph = workflow.getGraph(GraphRepresentation.Type.MERMAID);
log.info("工作流图:\n{}", graph.content());
int stepCounter = 1;
for (NodeOutput<MessagesState<String>> step : workflow.stream(
Map.of(WorkflowContext.WORKFLOW_CONTEXT_KEY, initialContext))) {
log.info("--- 第 {} 步完成 ---", stepCounter);
WorkflowContext currentContext = WorkflowContext.getContext(step.state());
if (currentContext != null) {
sink.next(formatSseEvent("step_completed", Map.of(
"stepNumber", stepCounter,
"currentStep", currentContext.getCurrentStep()
)));
log.info("当前步骤上下文: {}", currentContext);
}
stepCounter++;
}
sink.next(formatSseEvent("workflow_completed", Map.of(
"message", "代码生成工作流执行完成!"
)));
log.info("代码生成工作流执行完成!");
sink.complete();
} catch (Exception e) {
log.error("工作流执行失败: {}", e.getMessage(), e);
sink.next(formatSseEvent("workflow_error", Map.of(
"error", e.getMessage(),
"message", "工作流执行失败"
)));
sink.error(e);
}
});
});
}
/**
* 格式化 SSE 事件的辅助方法
*/
private String formatSseEvent(String eventType, Object data) {
try {
String jsonData = JSONUtil.toJsonStr(data);
return "event: " + eventType + "\ndata: " + jsonData + "\n\n";
} catch (Exception e) {
log.error("格式化 SSE 事件失败: {}", e.getMessage(), e);
return "event: error\ndata: {\"error\":\"格式化失败\"}\n\n";
}
}
/**
* 执行工作流(SSE 流式输出版本)
*/
public SseEmitter executeWorkflowWithSse(String originalPrompt) {
SseEmitter emitter = new SseEmitter(30 * 60 * 1000L);
Thread.startVirtualThread(() -> {
try {
CompiledGraph<MessagesState<String>> workflow = createWorkflow();
WorkflowContext initialContext = WorkflowContext.builder()
.originalPrompt(originalPrompt)
.currentStep("初始化")
.build();
sendSseEvent(emitter, "workflow_start", Map.of(
"message", "开始执行代码生成工作流",
"originalPrompt", originalPrompt
));
GraphRepresentation graph = workflow.getGraph(GraphRepresentation.Type.MERMAID);
log.info("工作流图:\n{}", graph.content());
int stepCounter = 1;
for (NodeOutput<MessagesState<String>> step : workflow.stream(
Map.of(WorkflowContext.WORKFLOW_CONTEXT_KEY, initialContext))) {
log.info("--- 第 {} 步完成 ---", stepCounter);
WorkflowContext currentContext = WorkflowContext.getContext(step.state());
if (currentContext != null) {
sendSseEvent(emitter, "step_completed", Map.of(
"stepNumber", stepCounter,
"currentStep", currentContext.getCurrentStep()
));
log.info("当前步骤上下文: {}", currentContext);
}
stepCounter++;
}
sendSseEvent(emitter, "workflow_completed", Map.of(
"message", "代码生成工作流执行完成!"
));
log.info("代码生成工作流执行完成!");
emitter.complete();
} catch (Exception e) {
log.error("工作流执行失败: {}", e.getMessage(), e);
sendSseEvent(emitter, "workflow_error", Map.of(
"error", e.getMessage(),
"message", "工作流执行失败"
));
emitter.completeWithError(e);
}
});
return emitter;
}
/**
* 发送 SSE 事件的辅助方法
*/
private void sendSseEvent(SseEmitter emitter, String eventType, Object data) {
try {
emitter.send(SseEmitter.event()
.name(eventType)
.data(data));
} catch (IOException e) {
log.error("发送 SSE 事件失败: {}", e.getMessage(), e);
}
}
/**
* 根据质检结果决定下一步
*
* @param state
* @return
*/
private String routeAfterQualityCheck(MessagesState<String> state) {
WorkflowContext context = WorkflowContext.getContext(state);
QualityResult qualityResult = context.getQualityResult();
// 如果质检失败,重新生成代码
if (qualityResult == null || !qualityResult.getIsValid()) {
log.error("代码质检失败,需要重新生成代码");
return "fail";
}
// 质检通过,使用原有的构建路由逻辑
log.info("代码质检通过,继续后续流程");
return routeBuildOrSkip(state);
}
/**
* 根据代码生成类型决定是否需要构建
*
* @param state
* @return
*/
private String routeBuildOrSkip(MessagesState<String> state) {
WorkflowContext context = WorkflowContext.getContext(state);
CodeGenTypeEnum generationType = context.getGenerationType();
// HTML 和 MULTI_FILE 类型不需要构建,直接结束
if (generationType == CodeGenTypeEnum.HTML || generationType == CodeGenTypeEnum.MULTI_FILE) {
return "skip_build";
}
// VUE_PROJECT 需要构建
return "build";
}
}🏗️ 一、createWorkflow() - 创建工作流:
public CompiledGraph<MessagesState<String>> createWorkflow() {
try {
return new MessagesStateGraph<String>()
// 1. 添加 6 个节点
.addNode("image_collector", ImageCollectorNode.create())
.addNode("prompt_enhancer", PromptEnhancerNode.create())
.addNode("router", RouterNode.create())
.addNode("code_generator", CodeGeneratorNode.create())
.addNode("code_quality_check", CodeQualityCheckNode.create())
.addNode("project_builder", ProjectBuilderNode.create())
// 2. 添加边(定义执行顺序)
.addEdge(START, "image_collector")
.addEdge("image_collector", "prompt_enhancer")
.addEdge("prompt_enhancer", "router")
.addEdge("router", "code_generator")
.addEdge("code_generator", "code_quality_check")
// 3. 条件边(质检结果决定下一步)
.addConditionalEdges("code_quality_check",
edge_async(this::routeAfterQualityCheck),
Map.of(
"build", "project_builder", // 通过 + 需要构建
"skip_build", END, // 通过 + 跳过构建
"fail", "code_generator" // 失败 → 重新生成
))
.addEdge("project_builder", END)
// 4. 编译工作流
.compile();
} catch (GraphStateException e) {
throw new BusinessException(ErrorCode.OPERATION_ERROR, "工作流创建失败");
}
}该类利用 MessagesStateGraph 构建了一个有向图,核心思想是将复杂的代码生成任务拆解为独立的原子节点,并通过边(Edge)定义执行顺序和流转逻辑。
- 状态管理 (
MessagesState<String>):- 工作流使用 LangGraph4j 预定义的
MessagesState作为全局状态容器。 - 为了传递业务上下文,代码巧妙地将自定义的
WorkflowContext对象序列化或嵌入到 State 中(通过WorkflowContext.WORKFLOW_CONTEXT_KEY)。这使得每个节点都能读取上一步的产出(如生成的代码、质检结果、构建类型等),实现数据的链式传递。
- 工作流使用 LangGraph4j 预定义的
- 节点定义 (Nodes):
工作流包含六个关键节点,形成了一个完整的闭环:image_collector:收集或处理输入的图片/素材信息。prompt_enhancer:优化用户输入的 Prompt,使其更适合 LLM 理解。router:根据上下文进行初步路由或分类。code_generator:核心节点,调用 LLM 生成代码。code_quality_check:关键质量控制点,对生成的代码进行静态分析或规则校验。project_builder:将生成的代码片段组装成完整的项目结构(如 Maven/Gradle 工程)。
高级流程控制:条件分支与循环
这段代码最精彩的部分在于 code_quality_check 节点之后的条件边(Conditional Edges)设计,它实现了智能的自我修正和动态路径选择。
- 动态路由逻辑 (
routeAfterQualityCheck):- 失败重试机制:如果质检节点 (
CodeQualityCheckNode) 返回的结果显示代码无效 (!isValid),工作流不会直接报错结束,而是返回"fail"信号,将流程指回code_generator节点。这形成了一个自动重试循环,直到生成合格的代码。 - 成功分流:如果质检通过,则进入次级路由逻辑 (
routeBuildOrSkip)。
- 失败重试机制:如果质检节点 (
- 基于类型的构建决策 (
routeBuildOrSkip):- 根据
WorkflowContext中的CodeGenTypeEnum判断后续动作。 - 如果是
HTML或MULTI_FILE类型,直接跳过构建步骤,流向END(因为可能只是静态文件或无需编译的结构)。 - 如果是
VUE_PROJECT等需要编译的类型,则流向project_builder进行工程化构建。
- 根据
这种设计体现了 Agentic Workflow(代理工作流) 的典型特征:具备反思(Reflection)和自我修正能力,而非简单的线性执行。
| 代码 | 作用 |
|---|---|
MessagesStateGraph<String>() |
创建状态图构建器 |
.addNode() |
添加节点(名字 + 执行逻辑) |
.addEdge() |
添加无条件边(固定顺序) |
.addConditionalEdges() |
添加条件边(根据返回值决定去向) |
.compile() |
编译成可执行的工作流 |
GraphStateException |
图结构错误时抛出(如节点名写错) |
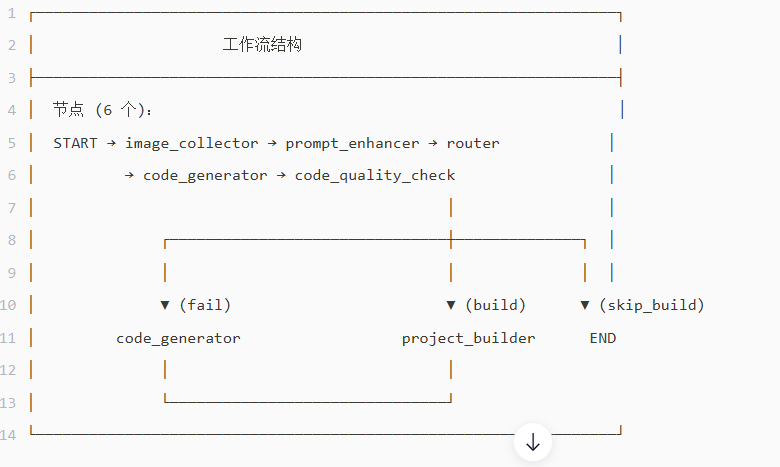
这里最关键的是这个,就是当
addConditionalEdges("code_quality_check"这一步通过后就是这个节点通过后,就会
edge_async(this::routeAfterQualityCheck),
Map.of(
"build", "project_builder", // 质检通过且需要构建
"skip_build", END, // 质检通过但跳过构建
"fail", "code_generator" // 质检失败,重新生成
))
.addEdge("project_builder", END)
进行这些,这些就是异步根据routeAfterQualityCheck的返回值选择要不要进行构建因为vue这些需要进行npm install。
routeAfterQualityCheck 条件边判断。
看这个方法的代码:
private String routeAfterQualityCheck(MessagesState<String> state) {
WorkflowContext context = WorkflowContext.getContext(state);
QualityResult qualityResult = context.getQualityResult();
// 如果质检失败,重新生成代码
if (qualityResult == null || !qualityResult.getIsValid()) {
log.error("代码质检失败,需要重新生成代码");
return "fail";
}
// 质检通过,使用原有的构建路由逻辑
log.info("代码质检通过,继续后续流程");
return routeBuildOrSkip(state);
}看这个方法校验成功后是不是就该进
private String routeBuildOrSkip(MessagesState<String> state) {
WorkflowContext context = WorkflowContext.getContext(state);
CodeGenTypeEnum generationType = context.getGenerationType();
// HTML 和 MULTI_FILE 类型不需要构建,直接结束
if (generationType == CodeGenTypeEnum.HTML || generationType == CodeGenTypeEnum.MULTI_FILE) {
return "skip_build";
}
// VUE_PROJECT 需要构建
return "build";
}这就是根据上下文存的state拿到状态然后返回“build”还是“skip_build”
"build", "project_builder", // 通过 + 需要构建
"skip_build", END, // 通过 + 跳过构建
如果是返回build就执行projeBuilder这个结点。
这个state
WorkflowContext context = WorkflowContext.getContext(state);
就是获取此用户的对象,然后
CodeGenTypeEnum generationType = context.getGenerationType();
拿到type,这个type是node中存入的。
然后回到CodeGenWorkflow这个类。
下面看:
/**
* 执行工作流
*/
public WorkflowContext executeWorkflow(String originalPrompt) {
CompiledGraph<MessagesState<String>> workflow = createWorkflow();
// 初始化 WorkflowContext
WorkflowContext initialContext = WorkflowContext.builder()
.originalPrompt(originalPrompt)
.currentStep("初始化")
.build();
GraphRepresentation graph = workflow.getGraph(GraphRepresentation.Type.MERMAID);
log.info("工作流图:\n{}", graph.content());
log.info("开始执行代码生成工作流");
WorkflowContext finalContext = null;
int stepCounter = 1;
for (NodeOutput<MessagesState<String>> step : workflow.stream(
Map.of(WorkflowContext.WORKFLOW_CONTEXT_KEY, initialContext))) {
log.info("--- 第 {} 步完成 ---", stepCounter);
// 显示当前状态
WorkflowContext currentContext = WorkflowContext.getContext(step.state());
if (currentContext != null) {
finalContext = currentContext;
log.info("当前步骤上下文: {}", currentContext);
}
stepCounter++;
}
log.info("代码生成工作流执行完成!");
return finalContext;
}第1步:创建工作流图:
CompiledGraph<MessagesState<String>> workflow = createWorkflow();
第2步:初始化上下文
WorkflowContext initialContext = WorkflowContext.builder()
.originalPrompt(originalPrompt)
.currentStep("初始化")
.build();
第3步:生成并打印工作流图(调试用)
GraphRepresentation graph = workflow.getGraph(GraphRepresentation.Type.MERMAID);
log.info("工作流图:\n{}", graph.content());
log.info("开始执行代码生成工作流");| 代码 | 作用 |
|---|---|
getGraph(Type.MERMAID) |
生成 Mermaid 格式的流程图代码 |
log.info(...) |
打印到日志,方便调试和可视化 |
ExecutorService pool = ExecutorBuilder.create()
.setCorePoolSize(10) // 核心线程数:10
.setMaxPoolSize(20) // 最大线程数:20
.setWorkQueue(new LinkedBlockingQueue<>(100)) // 任务队列容量:100
.setThreadFactory(ThreadFactoryBuilder.create()
.setNamePrefix("Parallel-Image-Collect").build()) // 线程名前缀
.build();配置线程池防止高并发。
② 配置并行执行策略
RunnableConfig runnableConfig = RunnableConfig.builder()
.addParallelNodeExecutor("image_plan", pool) // ← 关键配置
.build();| 参数 | 说明 |
|---|---|
"image_plan" |
节点名称,表示这个节点可以并行执行 |
pool |
使用上面创建的线程池来执行 |

③ 使用配置执行工作流
for (NodeOutput<MessagesState<String>> step : workflow.stream(
Map.of(WorkflowContext.WORKFLOW_CONTEXT_KEY, initialContext),
runnableConfig)) { // ← 传入并发配置
// ... 处理每个节点的输出
}| 对比 | 串行执行 | 并发执行 |
|---|---|---|
| 代码 | workflow.stream(initialState) |
workflow.stream(initialState, runnableConfig) |
| 执行方式 | 一个节点完成后再执行下一个 | 某些节点可以同时执行 |
| 耗时 | 较长 | 较短(对于可并行的任务) |
下面看Flux这种方法:
public Flux<String> executeWorkflowWithFlux(String originalPrompt) {
return Flux.create(sink -> {
Thread.startVirtualThread(() -> {
try {
CompiledGraph<MessagesState<String>> workflow = createWorkflow();
WorkflowContext initialContext = WorkflowContext.builder()
.originalPrompt(originalPrompt)
.currentStep("初始化")
.build();
sink.next(formatSseEvent("workflow_start", Map.of(
"message", "开始执行代码生成工作流",
"originalPrompt", originalPrompt
)));
GraphRepresentation graph = workflow.getGraph(GraphRepresentation.Type.MERMAID);
log.info("工作流图:\n{}", graph.content());
int stepCounter = 1;
for (NodeOutput<MessagesState<String>> step : workflow.stream(
Map.of(WorkflowContext.WORKFLOW_CONTEXT_KEY, initialContext))) {
log.info("--- 第 {} 步完成 ---", stepCounter);
WorkflowContext currentContext = WorkflowContext.getContext(step.state());
if (currentContext != null) {
sink.next(formatSseEvent("step_completed", Map.of(
"stepNumber", stepCounter,
"currentStep", currentContext.getCurrentStep()
)));
log.info("当前步骤上下文: {}", currentContext);
}
stepCounter++;
}
sink.next(formatSseEvent("workflow_completed", Map.of(
"message", "代码生成工作流执行完成!"
)));
log.info("代码生成工作流执行完成!");
sink.complete();
} catch (Exception e) {
log.error("工作流执行失败: {}", e.getMessage(), e);
sink.next(formatSseEvent("workflow_error", Map.of(
"error", e.getMessage(),
"message", "工作流执行失败"
)));
sink.error(e);
}
});
});
}下面看SSE这种方法:
/**
* 执行工作流(SSE 流式输出版本)
*/
public SseEmitter executeWorkflowWithSse(String originalPrompt) {
SseEmitter emitter = new SseEmitter(30 * 60 * 1000L);
Thread.startVirtualThread(() -> {
try {
CompiledGraph<MessagesState<String>> workflow = createWorkflow();
WorkflowContext initialContext = WorkflowContext.builder()
.originalPrompt(originalPrompt)
.currentStep("初始化")
.build();
sendSseEvent(emitter, "workflow_start", Map.of(
"message", "开始执行代码生成工作流",
"originalPrompt", originalPrompt
));
GraphRepresentation graph = workflow.getGraph(GraphRepresentation.Type.MERMAID);
log.info("工作流图:\n{}", graph.content());
int stepCounter = 1;
for (NodeOutput<MessagesState<String>> step : workflow.stream(
Map.of(WorkflowContext.WORKFLOW_CONTEXT_KEY, initialContext))) {
log.info("--- 第 {} 步完成 ---", stepCounter);
WorkflowContext currentContext = WorkflowContext.getContext(step.state());
if (currentContext != null) {
sendSseEvent(emitter, "step_completed", Map.of(
"stepNumber", stepCounter,
"currentStep", currentContext.getCurrentStep()
));
log.info("当前步骤上下文: {}", currentContext);
}
stepCounter++;
}
sendSseEvent(emitter, "workflow_completed", Map.of(
"message", "代码生成工作流执行完成!"
));
log.info("代码生成工作流执行完成!");
emitter.complete();
} catch (Exception e) {
log.error("工作流执行失败: {}", e.getMessage(), e);
sendSseEvent(emitter, "workflow_error", Map.of(
"error", e.getMessage(),
"message", "工作流执行失败"
));
emitter.completeWithError(e);
}
});
return emitter;
}
现在开始最最重要的看各个节点的方法:
1️⃣ ImageCollectorNode - 图片收集节点
package com.yupi.yuaicodemother.langgraph4j.node;
import com.yupi.yuaicodemother.langgraph4j.ai.ImageCollectionPlanService;
import com.yupi.yuaicodemother.langgraph4j.model.ImageCollectionPlan;
import com.yupi.yuaicodemother.langgraph4j.model.ImageResource;
import com.yupi.yuaicodemother.langgraph4j.state.WorkflowContext;
import com.yupi.yuaicodemother.langgraph4j.tools.ImageSearchTool;
import com.yupi.yuaicodemother.langgraph4j.tools.LogoGeneratorTool;
import com.yupi.yuaicodemother.langgraph4j.tools.MermaidDiagramTool;
import com.yupi.yuaicodemother.langgraph4j.tools.UndrawIllustrationTool;
import com.yupi.yuaicodemother.utils.SpringContextUtil;
import lombok.extern.slf4j.Slf4j;
import org.bsc.langgraph4j.action.AsyncNodeAction;
import org.bsc.langgraph4j.prebuilt.MessagesState;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.CompletableFuture;
import static org.bsc.langgraph4j.action.AsyncNodeAction.node_async;
/**
* 图片收集节点(并发)
*/
@Slf4j
public class ImageCollectorNode {
public static AsyncNodeAction<MessagesState<String>> create() {
return node_async(state -> {
WorkflowContext context = WorkflowContext.getContext(state);
String originalPrompt = context.getOriginalPrompt();
List<ImageResource> collectedImages = new ArrayList<>();
try {
// 第一步:获取图片收集计划
ImageCollectionPlanService planService = SpringContextUtil.getBean(ImageCollectionPlanService.class);
ImageCollectionPlan plan = planService.planImageCollection(originalPrompt);
log.info("获取到图片收集计划,开始并发执行");
// 第二步:并发执行各种图片收集任务
List<CompletableFuture<List<ImageResource>>> futures = new ArrayList<>();
// 并发执行内容图片搜索
if (plan.getContentImageTasks() != null) {
ImageSearchTool imageSearchTool = SpringContextUtil.getBean(ImageSearchTool.class);
for (ImageCollectionPlan.ImageSearchTask task : plan.getContentImageTasks()) {
futures.add(CompletableFuture.supplyAsync(() ->
imageSearchTool.searchContentImages(task.query())));
}
}
// 并发执行插画图片搜索
if (plan.getIllustrationTasks() != null) {
UndrawIllustrationTool illustrationTool = SpringContextUtil.getBean(UndrawIllustrationTool.class);
for (ImageCollectionPlan.IllustrationTask task : plan.getIllustrationTasks()) {
futures.add(CompletableFuture.supplyAsync(() ->
illustrationTool.searchIllustrations(task.query())));
}
}
// 并发执行架构图生成
if (plan.getDiagramTasks() != null) {
MermaidDiagramTool diagramTool = SpringContextUtil.getBean(MermaidDiagramTool.class);
for (ImageCollectionPlan.DiagramTask task : plan.getDiagramTasks()) {
futures.add(CompletableFuture.supplyAsync(() ->
diagramTool.generateMermaidDiagram(task.mermaidCode(), task.description())));
}
}
// 并发执行Logo生成
if (plan.getLogoTasks() != null) {
LogoGeneratorTool logoTool = SpringContextUtil.getBean(LogoGeneratorTool.class);
for (ImageCollectionPlan.LogoTask task : plan.getLogoTasks()) {
futures.add(CompletableFuture.supplyAsync(() ->
logoTool.generateLogos(task.description())));
}
}
// 等待所有任务完成并收集结果
CompletableFuture<Void> allTasks = CompletableFuture.allOf(
futures.toArray(new CompletableFuture[0]));
allTasks.join();
// 收集所有结果
for (CompletableFuture<List<ImageResource>> future : futures) {
List<ImageResource> images = future.get();
if (images != null) {
collectedImages.addAll(images);
}
}
log.info("并发图片收集完成,共收集到 {} 张图片", collectedImages.size());
} catch (Exception e) {
log.error("图片收集失败: {}", e.getMessage(), e);
}
// 更新状态
context.setCurrentStep("图片收集");
context.setImageList(collectedImages);
return WorkflowContext.saveContext(context);
});
}
}

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)