AnomalyDiffusion: Few-Shot Anomaly Image Generation with Diffusion Model
AnomalyDiffusion: Few-Shot Anomaly Image Generation with Diffusion Model
摘要
异常检测在工业生产中占有重要地位。由于异常数据不足,现有的异常检测方法在性能上受到限制。虽然已经提出了增强异常数据的异常生成方法,但它们要么存在生成真实性差的问题,要么存在生成的异常与掩码之间的对准不准确的问题。针对上述问题,我们提出了一种新的基于扩散的少样本异常生成模型AnomalyDiffulation,该模型利用从大规模数据集中学习的潜空间扩散模型的强先验信息来提高在少样本训练数据下的生成真实性。首先,我们提出了空间异常嵌入,它由一个可学习的异常嵌入和一个由异常掩码编码的空间嵌入组成,将异常信息分解为异常外观和位置信息。此外,为了提高生成的异常与异常掩码之间的对准,引入了一种新的自适应注意力加权机制。基于生成的异常图像和正常样本之间的差异,它动态地引导模型更多地关注生成异常较不明显的区域,从而能够生成精确匹配的异常图像-掩模对。大量实验表明,该模型在生成真实性和多样性方面明显优于现有方法,有效地提高了下游异常检测任务的性能。代码和数据在https://github.com/sjtuplayer/anomalydiffusion.中可用
1 引言
由于异常数据不足,现有的异常检测方法在性能上受到限制。现有的异常生成补充异常数据的办法主要分成两类:
- 无模型方法,从已有的异常或异常纹理数据集中随机裁剪和粘贴斑块到正常样本上,表现出较差的真实性(图1-底部-a/b);
- GAN方法,大多需要大量数据,唯一的少样本GAN方法是DFMGAN(图1-底部-c),但该方法生成的异常区域与异常掩码存在错位问题。现有异常生成方法无法通过少样本异常数据学习,同时实现高保真异常生成与图像-掩码的精确对齐。

针对上述问题,提出AnomalyDiffusion——一种基于扩散模型的新型异常生成方法,该方法通过异常掩码将异常特征注入到输入的正常样本中。通过利用预训练LDM中学习到的强先验信息,仅需少量异常图像即可提取更优质的异常表征,同时提升生成结果的真实性与多样性。
为实现指定类型和位置的异常生成,提出空间异常嵌入技术,将异常信息解耦为:
- 异常嵌入(学习得到的文本嵌入,用于表征异常外观类型)
- 空间嵌入(从异常掩码编码而来,用于指示异常位置)
通过解耦异常位置与外观特征,可在任意指定位置生成异常,从而为下游任务批量生成异常图像-掩码对。此外,还提出自适应注意力重加权机制,在扩散推理阶段根据生成图像与输入正常样本的差异动态调整交叉注意力图,使模型更关注生成异常不明显的区域。该机制能确保生成的异常图像与掩码精确对齐,显著提升下游异常定位任务的性能。
本文的主要贡献可以概括为以下几点:
- 提出了AnomalyDiffusion,一种基于少量扩散的异常生成方法,它将异常分解为异常嵌入(用于异常外观)和空间嵌入(用于异常定位),并生成真实且多样化的异常图像。
- 设计了自适应注意力重新加权机制,自适应地将更多注意力分配到生成异常不太明显的区域,从而改善生成异常和掩模之间的对齐。
- 大量实验证明,我们的模型相比现有最优方法具有显著优势;生成的非典型数据有效提升了下游异常检测任务的性能。相关数据将公开发布,以推动该领域的后续研究。
2 方法理论
1 )空间异常嵌入
我们的Anomaly Diffusion旨在通过从几个异常样本中学习来生成大量与异常掩码对齐的异常数据。该模型的输入包括一个无异常样本y和一个异常模板m,输出是一幅在模板区域产生异常的图像,其余区域与输入的无异常样本是一致的。如图所示,我们的无序扩散基于latent diffusion。为了将异常位置信息从异常现象中分离出来,我们提出了空间异常嵌入e,它由一个异常嵌入 e a e_a ea (异常出现)和一个空间嵌入 e s e_s es (异常定位)组成。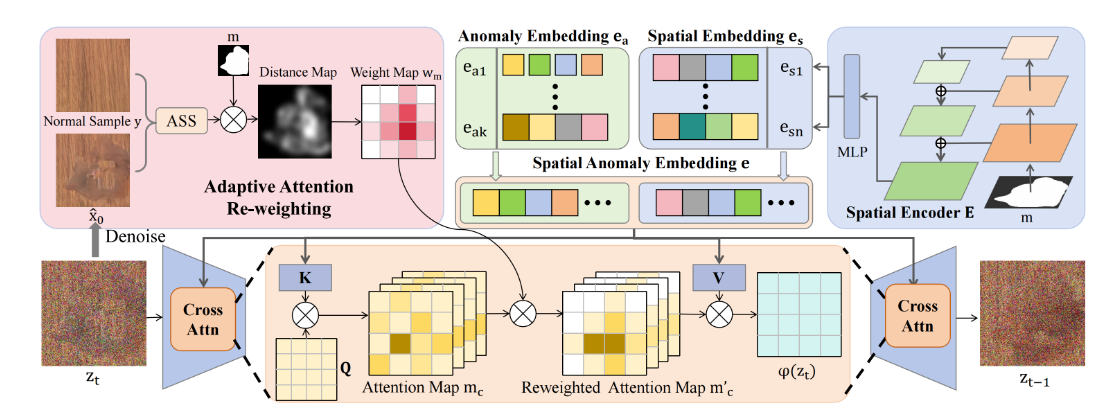
此外,为了增强生成的异常与给定掩码之间的对齐,引入了一种自适应注意力重新加权机制,该机制帮助模型将更多的注意力分配到生成异常不太明显的区域(图©)。
具体来说,异常嵌入 e a e_a ea 提供异常外观类型信息,一个 e a e_a ea 对应某一特定类型的异常(例如,榛子-裂纹,胶囊-挤压),这是通过掩蔽文本反转(Masked textual inversion )学习得到的。空间嵌入 e s e_s es 提供异常位置信息,它由空间编码器 E E E(在所有异常之间共享)从输入异常掩码 m m m 编码得到。通过将异常嵌入 e a e_a ea 与空间嵌入 e s e_s es 结合,空间异常嵌入 e e e 同时包含异常外观和空间信息,作为扩散模型中的文本条件以指导生成过程。以空间异常嵌入为条件,给定一个正常样本,我们通过混合扩散过程生成异常图像:
x t − 1 = p θ ( x t − 1 ∣ x t , e ) ⊙ m + q ( y t − 1 ∣ y 0 ) ⊙ ( 1 − m ) , (1) x_{t-1} = p_\theta(x_{t-1}|x_t, e) \odot m + q(y_{t-1}|y_0) \odot (1 - m), \tag{1} xt−1=pθ(xt−1∣xt,e)⊙m+q(yt−1∣y0)⊙(1−m),(1)
其中 x t x_t xt 是时间步 t t t 生成的异常图像, y 0 y_0 y0 是输入的正常样本, m m m 是异常掩码, q ( ⋅ ) q(\cdot) q(⋅) 和 p θ ( ⋅ ) p_\theta(\cdot) pθ(⋅) 分别是第3.1节所述的扩散过程中的前向和后向过程。
将空间信息与异常现象区分开来 。我们的目标是实现具有特定异常类型和位置的可控异常生成。一个直接的解决方案是通过文本反演学习的文本嵌入来控制异常类型,并通过输入掩码控制异常位置。然而,文本反演倾向于同时捕捉异常位置和异常类型信息,导致生成的异常仅分布在特定位置。为解决这个问题,我们提议将文本嵌入拆分为两部分,其中一部分(空间嵌入 e s e_s es)直接从异常掩码编码以指示异常位置,其余部分(异常嵌入 e a e_a ea)仅学习异常类型信息。我们将分解后的文本嵌入称为空间异常嵌入。
异常嵌入 。一种学习文本嵌入,用于表示异常出现类型的信息。与学习整幅图像特征的文本反演方法不同,异常生成中,我们的模型只需关注异常区域,无需提供整幅图像的信息。因此,我们引入了遮蔽文本反转,即遮蔽异常图像中无关的背景和正常区域,模型只可见异常区域。我们用 k k k 个 token 初始化异常嵌入 e a e_a ea,并利用掩蔽扩散模型进行优化:
L d i f f = ∥ m ⊙ ( ϵ − ϵ θ ( z t , t , { e a , e s } ) ) ∥ 2 2 , (5) \mathcal{L}_{diff}= \|m \odot (\epsilon - \epsilon_\theta (z_t, t, \{e_a, e_s\}))\|_2^2, \tag{5} Ldiff=∥m⊙(ϵ−ϵθ(zt,t,{ea,es}))∥22,(5)
其中 ϵ ∼ N ( 0 , 1 ) \epsilon \sim N(0,1) ϵ∼N(0,1), z t z_t zt 是输入图像 x x x 在时间步 t t t 时的噪声潜码。
空间嵌入。 为了提供异常位置的准确空间信息,我们引入了空间编码器 E E E,将输入异常掩码 m m m 编码为空间嵌入 e s e_s es, e s e_s es 以文本嵌入形式呈现,包含掩模的精确位置信息。具体来说,我们将异常掩膜输入 ResNet-50,提取不同层的图像特征,并通过特征金字塔网络将它们融合在一起。最后,采用多个全连通网络将融合特征映射到文本嵌入空间,每个网络预测一个文本符号,从而输出包含 n n n 个符号的最终空间嵌入 e s e_s es。
整体培训框架。对于每个异常类型i,我们使用异常嵌入ea,i提取其外观信息,所有异常类别共享一个通用的空间编码器E。对于训练数据中的一组图像-掩码对 ( x , m i ) (x,m_i) (x,mi),我们首先将异常掩蔽函数输入空间编码器E以获得空间嵌入 e s = E ( m i ) e_s = E(m_i) es=E(mi)。然后,我们将异常嵌入 e a , i e_{a,i} ea,i和空间嵌入 e s e_s es连接起来,得到空间异常嵌入 e = e a , e s e = {e_a, e_s} e=ea,es。最后,连接文本嵌入 e 作为扩散模型的文本条件,训练过程可表述为:
e a ∗ , E ∗ = arg min e a , E E z ∼ E ( x i ) , m i , ϵ , t L d i f f . (6) e_a^*, E^* = \arg \min_{e_a, E} \mathbb{E}_{z \sim \mathcal{E}(x_i), m_i, \epsilon, t} \mathcal{L}_{diff}. \tag{6} ea∗,E∗=argea,EminEz∼E(xi),mi,ϵ,tLdiff.(6)
其中 E ( ⋅ ) E(\cdot) E(⋅) 是潜扩散模型的图像编码器,且 ϵ ∼ N ( 0 , 1 ) \epsilon \sim N(0,1) ϵ∼N(0,1)。
2 )自适应注意力重权
利用空间异常嵌入 e e e,我们可以将其作为文本条件,指导方程(1)生成异常图像。然而,生成的异常图像有时无法填满整个掩体,尤其是在掩罩中存在多个异常区域或遮罩形状不规则时(图3-a/c)。在这种情况下,生成的异常通常与掩膜不匹配,限制了下游异常定位任务的改进。为解决这一问题,我们提出了一种自适应注意力加权机制,该机制在去噪过程中对产生异常较不明显的区域分配更多注意力,从而促进生成异常与异常掩体之间的更好对齐。
自适应注意力权重图。具体来说,在第 t t t 个去噪步,我们计算对应的 x ^ 0 = D ( p θ ( z 0 ∣ z t , e ) ) \hat{x}_0 = D(p_\theta(z_0|z_t, e)) x^0=D(pθ(z0∣zt,e))(其中 D D D 是LDM的解码器)。然后,我们计算 x ^ 0 \hat{x}_0 x^0 与掩码 m m m 内正常采样 y y y 之间的像素级差。基于差异,我们通过自适应缩放 S o f t m a x Softmax Softmax(ASS)操作计算权重映射 w m w_m wm:
w m = ∥ m ∥ 1 ⋅ Softmax ( f ( ∥ m ⊙ y − m ⊙ x ^ 0 ∥ 2 ) ) , (7) w_m = \|m\|_1 \cdot \operatorname{Softmax}\left(f(\|m \odot y - m \odot \hat{x}_0\|^2)\right), \tag{7} wm=∥m∥1⋅Softmax(f(∥m⊙y−m⊙x^0∥2)),(7)
其中 f ( x ) = 1 / x f(x) = 1/x f(x)=1/x ,当 x ≠ 0 x \neq 0 x=0;否则 f ( x ) = − ∞ f(x) = -\infty f(x)=−∞。对于掩码内与正常样本相似的区域,这些区域产生的异常较不明显。为了增强异常生成效应,这些区域根据方程(7)被赋予更高权重,并通过注意力重新加权分配更多注意力。
注意力重新加权。我们使用权重图 w m w_m wm 来自适应地控制交叉注意力,以引导模型更多关注那些生成异常较少的区域。在我们的交叉注意力计算中,查询由潜在代码 z t z_t zt 计算,键和值由空间异常嵌入计算:
Q = W Q ( i ) ⋅ φ i ( z t ) , K = W K ( i ) ⋅ e , V = W V ( i ) ⋅ e , (8) Q = W_Q^{(i)} \cdot \varphi_i(z_t),\quad K = W_K^{(i)} \cdot e,\quad V = W_V^{(i)} \cdot e, \tag{8} Q=WQ(i)⋅φi(zt),K=WK(i)⋅e,V=WV(i)⋅e,(8)
其中 φ i \varphi_i φi 是U-Net( ϵ θ \epsilon_\theta ϵθ)的中间表示, W ( i ) W^{(i)} W(i) 是可学习的投影矩阵。交叉注意力的计算过程随后表述为 Attn ( Q , K , V ) = m c ⋅ V \operatorname{Attn}(Q, K, V) = m_c \cdot V Attn(Q,K,V)=mc⋅V,其中 m c = Softmax ( Q K T d ) m_c = \operatorname{Softmax}\left(\frac{QK^T}{\sqrt{d}}\right) mc=Softmax(dQKT) 是交叉注意力映射。
考虑到交叉注意力映射 m c m_c mc 控制生成的布局和效果,其中更高的注意力会导致更强的生成效应,我们根据权重映射重新加权交叉注意力映射: m c ′ = m c ⊙ w m m'_c = m_c \odot w_m mc′=mc⊙wm。新的交叉注意力映射 m c ′ m'_c mc′ 更侧重于生成异常较不明显的区域,从而提升生成异常与输入异常掩码之间的比对精度。重新加权的交叉注意力表述为 RW-Attn ( Q , K , V ) = m c ′ ⋅ V \operatorname{RW-Attn}(Q, K, V) = m'_c \cdot V RW-Attn(Q,K,V)=mc′⋅V。
3 )掩膜生成
回忆我们的模型需要异常掩模作为输入。然而,训练数据集中真实异常掩膜数量极少,且掩膜数据即使在增强后也缺乏多样性,这促使我们通过学习真实掩膜分布来生成更多异常掩模。我们利用文本反演来学习嵌入它们的遮罩,该掩码可用作文本条件以生成广泛的异常掩码。具体来说,我们将嵌入 k ′ k' k′ 的随机符号初始化掩码,并通过以下方式进行优化:
e m ∗ = arg min e m E z ∼ E ( m ) , ϵ , t [ ∥ ϵ − ϵ θ ( z t , t , e m ) ∥ 2 2 ] . (9) e_m^* = \arg\min_{e_m} \mathbb{E}_{z\sim\mathcal{E}(m), \epsilon,t} \left[ \| \epsilon - \epsilon_\theta (z_t, t, e_m) \|_2^2 \right]. \tag{9} em∗=argemminEz∼E(m),ϵ,t[∥ϵ−ϵθ(zt,t,em)∥22].(9)
通过学习到的掩膜嵌入,我们可以为每种类型的异常生成广泛的异常掩模。
3 实验部分
1) 实验设置
数据集 :MVTec(Bergmann等人,2019)数据集,数据集包含15类工业产品或材料类别,总计约5354张高分辨率图像。每个类别的数据由正常样本和异常样本组成,其中正常样本只包含无缺陷产品,而异常样本则包含多种真实工业缺陷。
实验基于MVTec数据集进行。对于每个异常类别,采用原始数据中ID号最低的三分之一异常样本作为训练集,剩余三分之二用于测试。由于原始训练样本极少(通常少于10张),直接训练面临严重过拟合风险。
为缓解训练数据匮乏导致的过拟合问题,在训练过程中对图像-掩码对采用了随机裁剪、平移和旋转等数据增强策略。对于每种异常类型,最终生成1000个异常图像-掩码对用于下游异常检测任务。
评估指标
-
在生成质量评估中,由于异常样本有限导致FID和KID不可靠,故采用Inception
Score(IS)衡量图像质量,采用簇内成对LPIPS距离(IC-LPIPS)衡量多样性; -
在异常检测与定位任务中,使用生成的异常图像结合正常样本训练U-Net,并计算图像级与像素级的AUROC、平均精度(AP)和最大F1分数(F1-max)。
-
在异常分类任务中,参照DFMGAN的设置,使用生成的异常图像训练ResNet-34分类器,并在剩余测试集上计算分类准确率,以验证生成数据的类别区分能力。
参数设置
| 类别 | 参数项 | 设置值 |
|---|---|---|
| 嵌入配置 | 异常嵌入 e a e_a ea token数 | 8 |
| 嵌入配置 | 空间嵌入 e s e_s estoken数 | 4 |
| 嵌入配置 | 掩码嵌入 e m e_m emtoken数 | 4 |
| 超参数 | 批大小 | 4 |
| 超参数 | 学习率 | 0.005 |
| 超参数 | 空间异常嵌入+空间编码器训练迭代 | 300K 次 |
| 超参数 | 掩码嵌入训练迭代 | 30K 次 |
| 超参数 | 硬件设备 | NVIDIA GeForce RTX 3090 (24GB) |
| 超参数 | 训练耗时 | 约 3 天 |
2)异常生成基线的比较
为全面验证模型的有效性,实验设置了多组对比方法和评估场景:
- 生成方法分类:将现有异常生成方法分为两类进行对比。
① 第一类可生成图像-掩码对,包括Crop&Paste、DRAEM、PRN、DFMGAN,用于异常检测与定位任务的比较;
② 第二类可生成特定异常类型,包括DiffAug、CDC、Crop&Paste、SDGAN、DefectGAN、DFMGAN,用于生成质量与多样性的直接比较。 - 下游任务验证:为进一步验证生成数据对异常检测任务的提升作用,将本模型生成的异常数据训练得到的U-Net,与当前先进的异常检测方法(包括CFLOW、DRAEM、CFA、RD4AD、PatchCore、DevNet、DRA、PRN)在同一测试集上进行对比。这些方法均使用官方代码或预训练模型进行复现,确保比较的公平性。
4 实验结果
① 异常生成质量
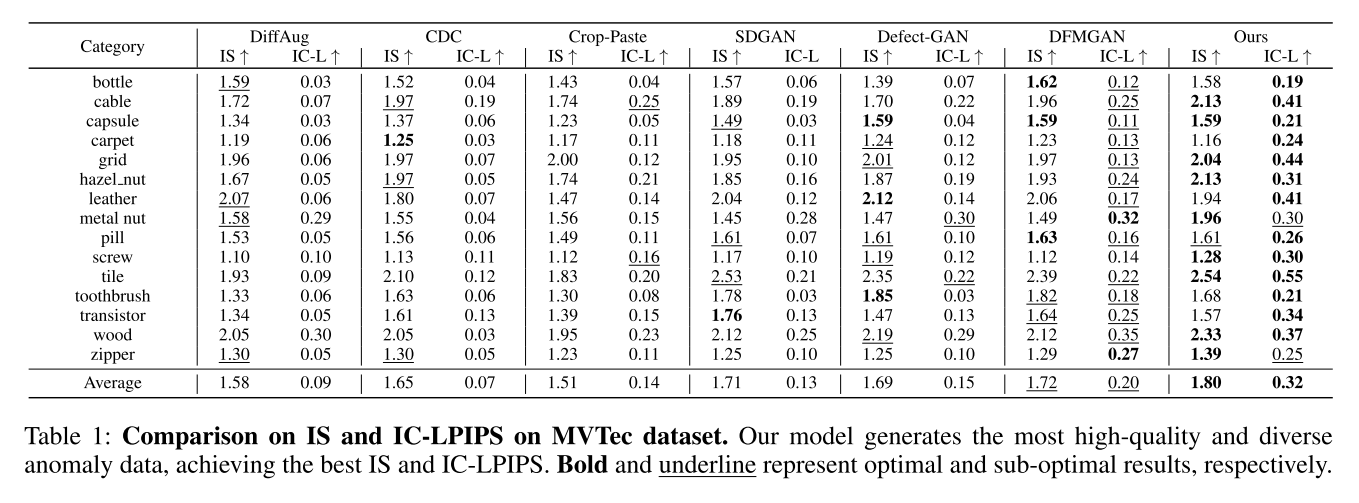
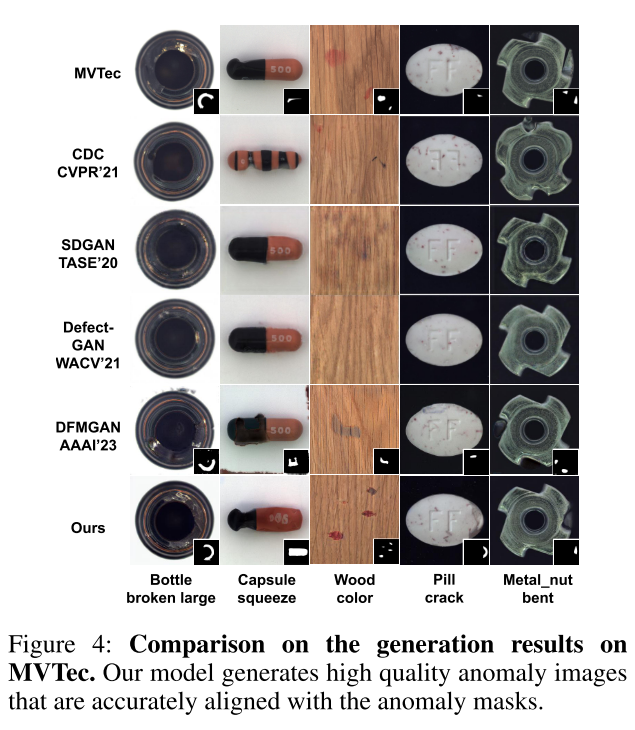
我们的模型在IS和IC-LPIPS指标上均优于DiffAug、CDC、Crop&Paste、SDGAN、DefectGAN和DFMGAN,生成的异常图像具有最高的真实感和多样性。定性结果(图4)显示,我们的模型能够生成与掩码精确对齐的高质量异常,而CDC在结构异常类别(如胶囊挤压)上产生视觉混乱的结果,SDGAN和DefectGAN在生成特定异常(如药丸裂缝)时质量较差,DFMGAN则有时出现异常与掩码错位(如金属螺母弯曲)。
② 异常检测与定位
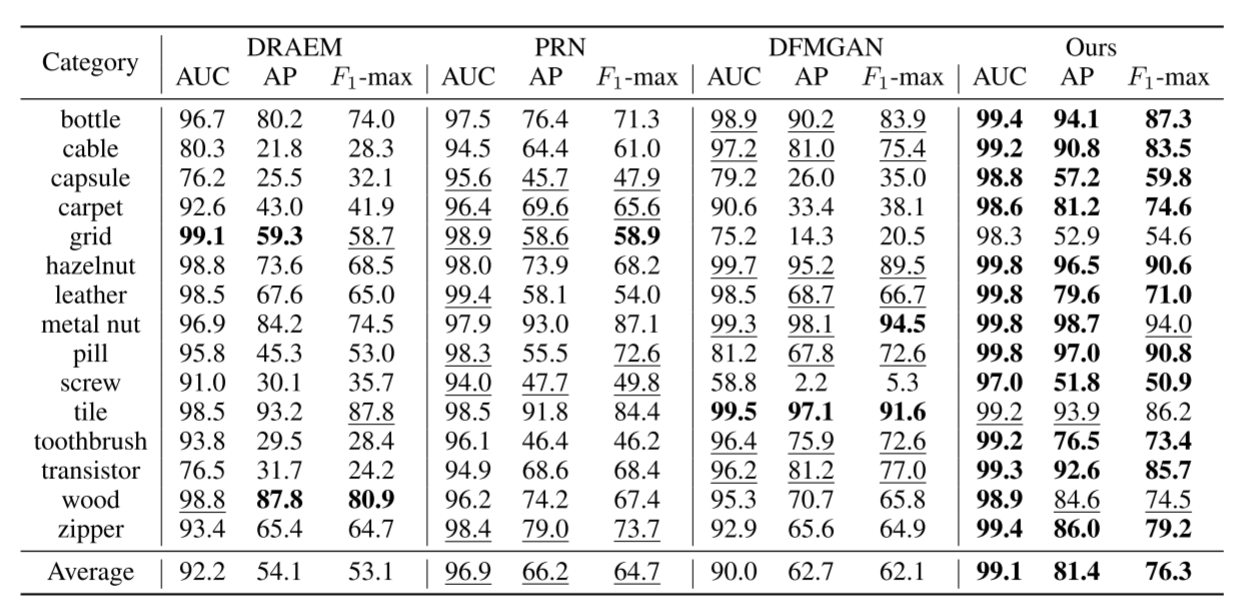
与裁剪粘贴、DRAEM、PRN、DFMGAN等方法相比,我们的模型在大多数类别上取得了更高的像素级和图像级AUROC、AP和F1-max(见表2、表3),定性结果(图5)进一步验证了其优越的定位精度。
Tab.2 像素级异常定位`
Tab.3 图像级异常定位`
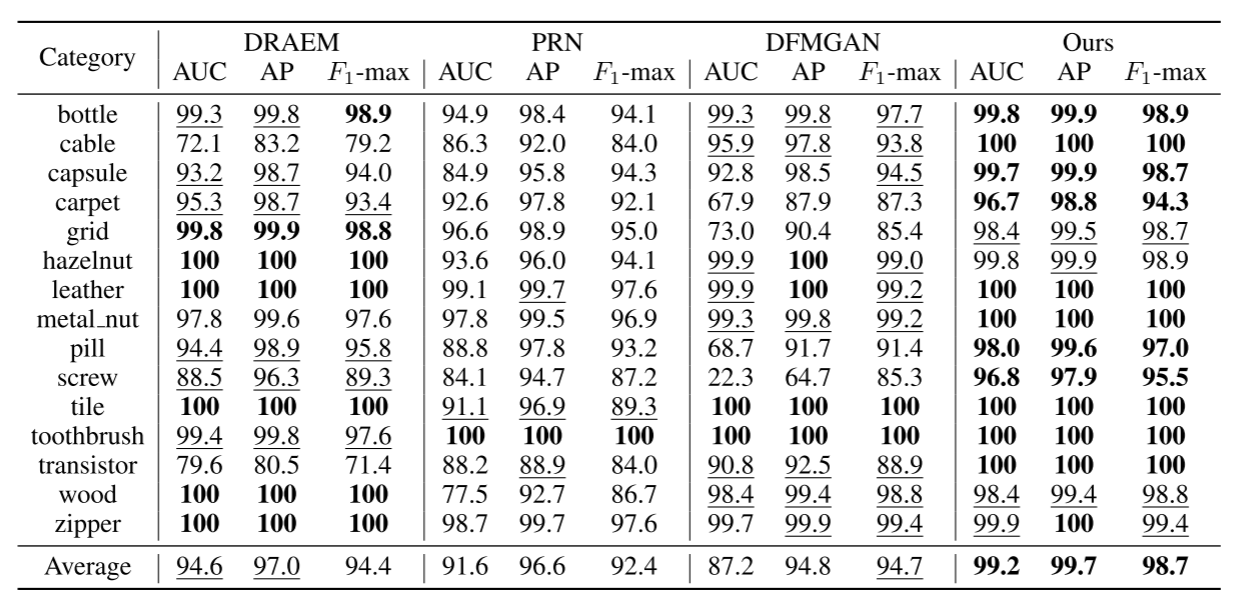

③ 异常分类任务
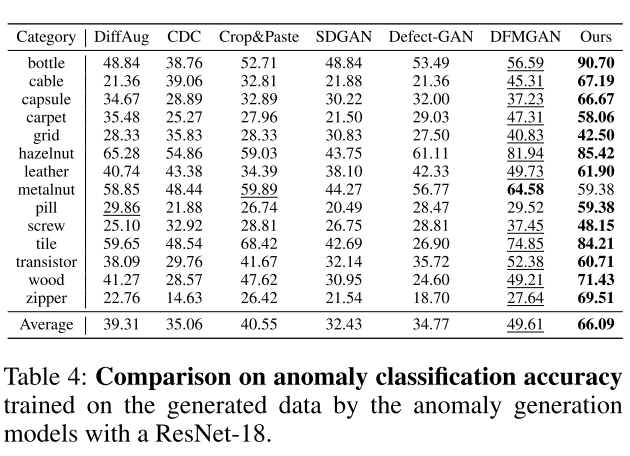
使用本模型生成数据训练的ResNet-34平均准确率达到66.09%,较第二名的DFMGAN(49.61%)提升16.48%(见表4)。与先进异常检测模型的比较表明,尽管本模型仅采用简单的U-Net结构,但在生成数据的辅助下,其像素级AP达到81.4%、AUROC达到99.1%(见表5),显著超越CFLOW、DRAEM、PatchCore等专用检测模型,充分证明了所生成异常数据对下游任务的有效性。
5 消融研究
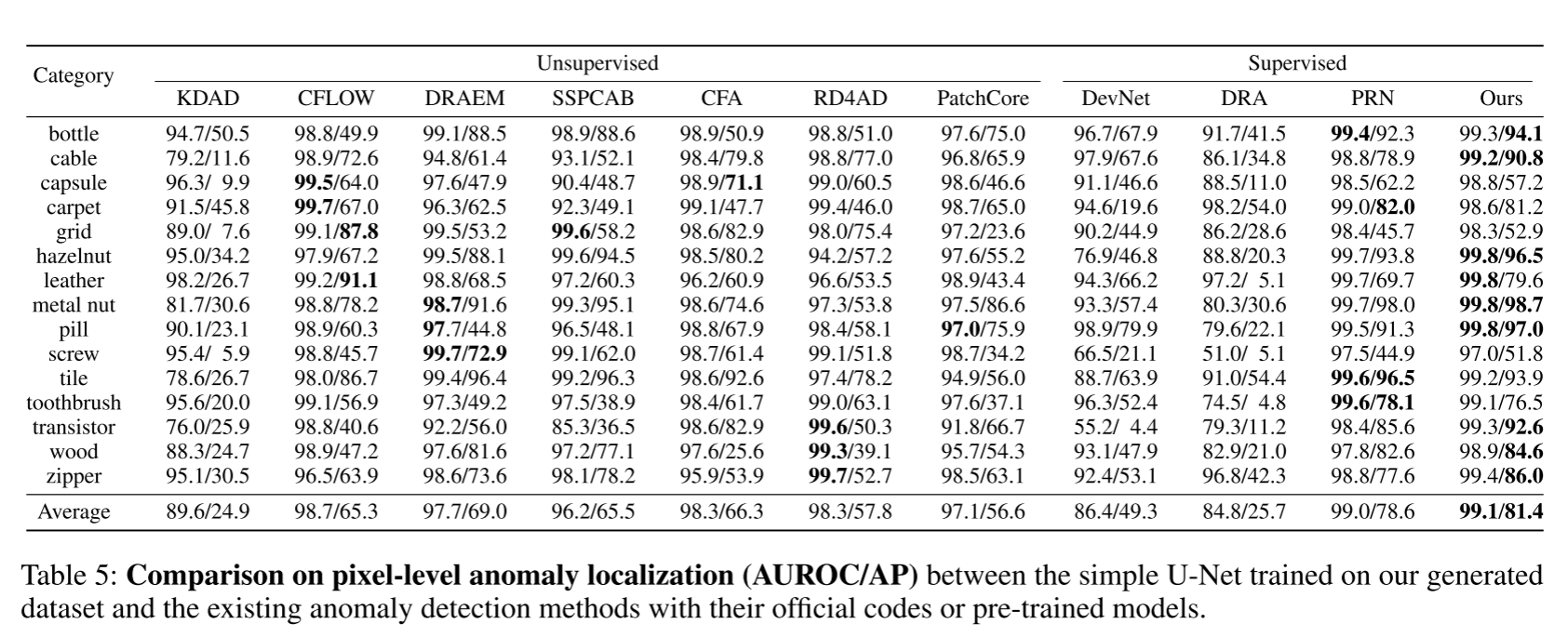
我们评估了各个模块的有效性:空间异常嵌入(SAE)、掩蔽扩散损失(Masked L)和自适应注意力重新加权机制(AAR)。请注意,未使用SAE的模型仅采用通过文本反转训练的异常嵌入。我们训练了5个模型:①不含任何上述模块;②仅含SAE;③SAE + 掩蔽损失;④掩蔽损失 + AAR;⑤完整模型(我们的方法)。使用这些模型生成1000个异常图像-掩码对,并训练一个U-Net进行异常定位。像素级定位结果的对比见表6。结果表明,缺少任何一个所提出的模块都会导致模型在异常定位任务上的性能显著下降,这验证了所提模块的有效性。更多实验请参阅原文补充材料。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 9
9 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)