NineData 社区版的慢 SQL 分析,比查看日志 + 看 EXPLAIN 适合中小团队
本文讨论的是 NineData 社区版 在 MySQL 慢 SQL 场景下的使用边界。社区版支持本地离线、Docker 单机部署,数据库 DevOps 配额为 10 个数据源。如果你的诉求是分布式集群、跨机房容灾、无限扩展和 SLA,那是企业版能力,本文不展开。

很多团队排查慢 SQL,通常会重复如下流程。
-
登录数据库服务器,把慢日志导出 / 查看。
-
在客户端把 SQL 拿出来跑 EXPLAIN。
-
判断是不是索引问题、扫描量问题或者锁等待。
-
把结论丢到群里,让研发去改 SQL。
-
等改完上线,再观察一轮。
这套流程没有任何问题,但问题在于,如果慢 SQL 变多,情况就不太一样了。DBA 就需要开始考虑一堆问题:
-
哪些慢 SQL 频繁出现?
-
哪些 SQL 开始变慢?
-
原因是什么?
这些信息在 slow log 里都存在,但是一旦慢 SQL 很多,人工整理会比较耗时。你一定经历过在慢日志里翻了半天,后来才发现几十条 SQL 其实只是同一个模板。
慢 SQL 通常是“模板问题”
在真实系统里,大部分慢 SQL 其实不是随机出现的。它们往往来自某一类固定写法,比如:
SELECT * FROM orders WHERE user_id = ?
只要某个条件触发,比如数据量增长、索引缺失、参数范围扩大,这一类 SQL 就会开始大量出现在 slow log 里。如果只靠翻日志,其实不够直观。
NineData 社区版做的一件事:把慢 SQL 按模板整理出来
NineData 在慢 SQL 场景里的能力,是把 slow log 里的 SQL 按 模板进行聚合。
先看大盘慢查询分析支持按时间范围查看趋势,并支持按 数据源、环境、标签、数据源类型 等维度筛选和分组。这一步很关键,因为你先看到的是“哪一类问题正在变多”,而不是单条日志。
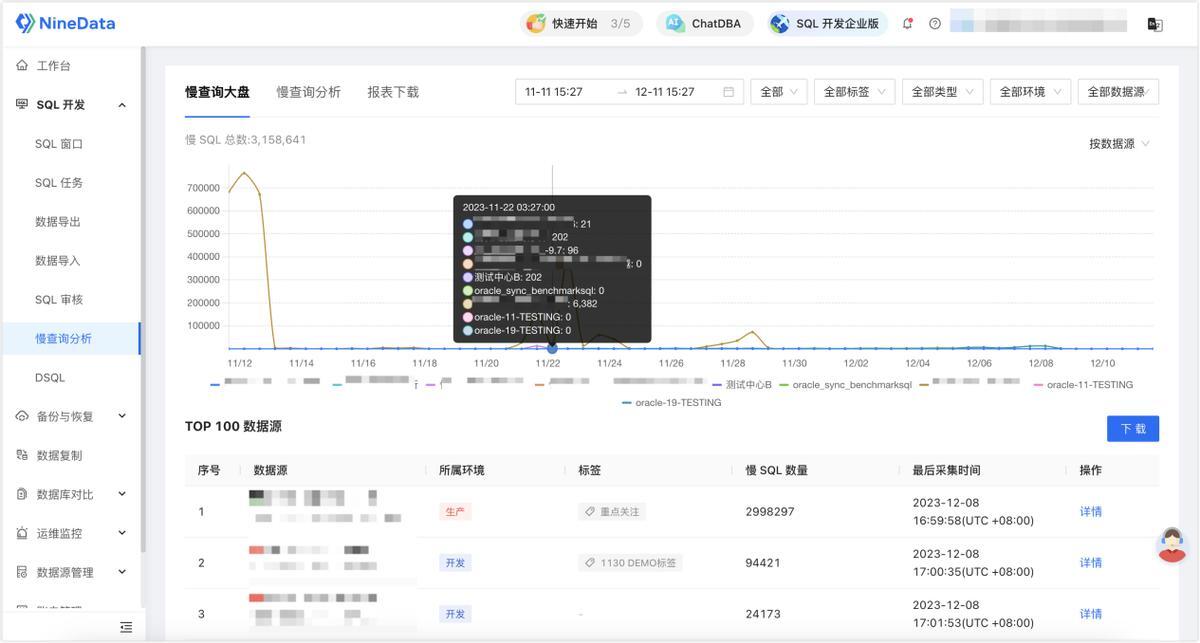
再看模板 NineData 会把慢 SQL 分成两层:外层是 SQL 模板,内层是具体语句样本。这样你看到的不是零散的几十条、几百条 SQL,而是“同一类问题到底出现了多少次”。这比人工翻日志更接近真实治理场景,因为团队实际需要处理的通常不是某一条语句,而是一类重复出现的写法。
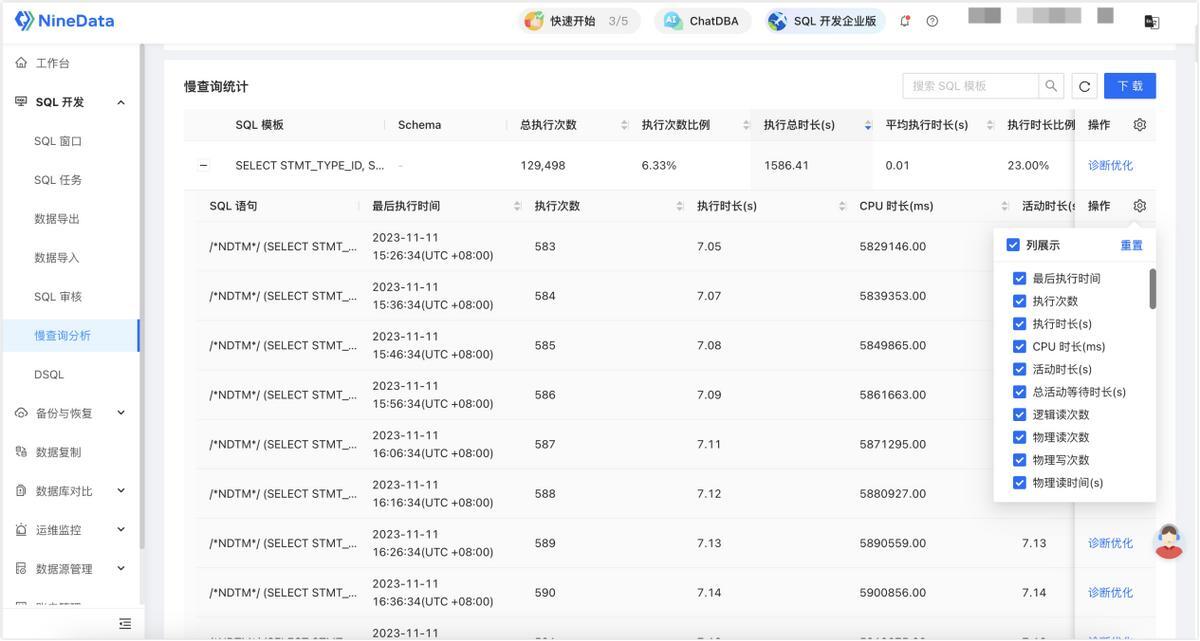
然后看诊断在具体 SQL 上,NineData 会给出 性能诊断、规范审核、索引建议 等信息。也就是说,它不是只告诉你“这条 SQL 慢”,而是继续往下回答:可能慢在哪里、该往哪个方向改。这一步较为重要,因为很多团队并不是完全不会优化,而是缺少一个稳定、统一的判断入口。
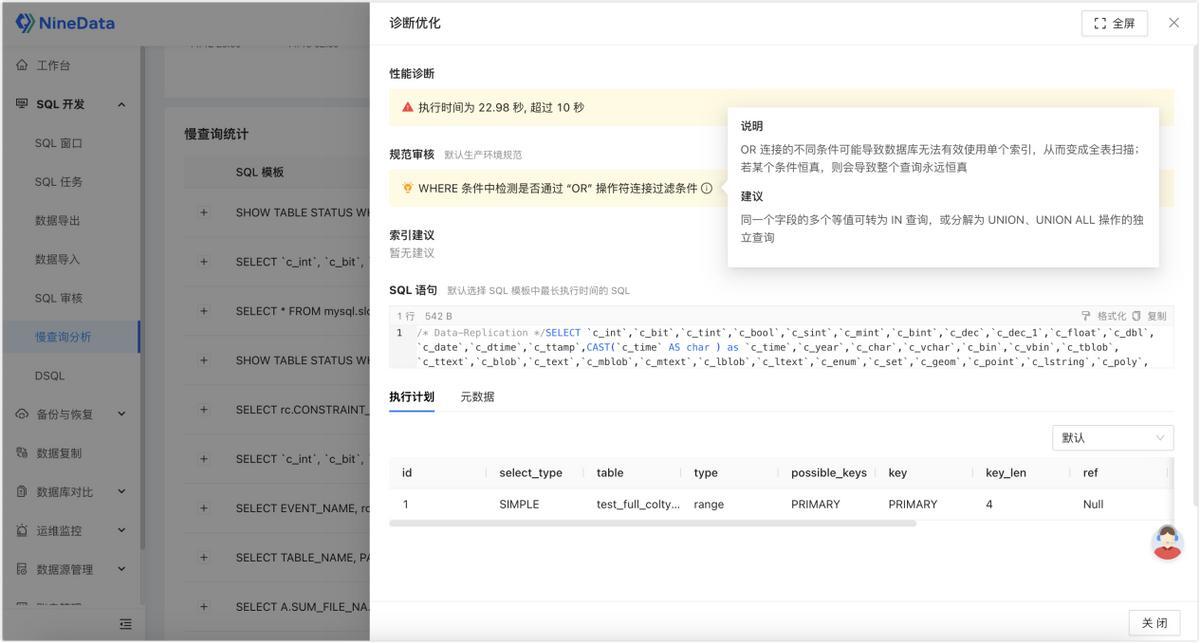
再治理慢 SQL 分析不是终点。定位到问题后,就可以继续回到 NineData 的 SQL 窗口 做 EXPLAIN 或改写验证;如果修复已经涉及 DDL、上线或审批,还可以继续纳入 SQL 任务、审核和发布流程。
对中小团队来说,一个 NineData 可覆盖大部分常用场景
很多数据库性能分析平台其实也能做类似事情,但中小团队往往有几个现实限制:
-
数据库日志不方便上传到外部平台。
-
没有精力维护复杂的监控系统。
-
需要工具能在内网快速部署。
NineData 社区版比较适合这种场景:
-
支持 Docker 单机部署。
-
可以在本地内网运行。
-
部署完成后就可以接入数据库做慢查询分析。
社区版提供 10 个数据源的可用额度,对于不少中小团队来说已经足够覆盖开发、测试和核心生产环境。
总结
对 DBA 来说,慢 SQL 的难点往往不在技术本身,而在每天重复的排查工作。
如果工具能把日志整理、问题定位和后续操作连在一起,那么慢 SQL 的处理过程就会慢慢变成一件更可持续的日常工作。
这大概也是 NineData 在慢日志分析这个场景里很实用的价值所在。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 7
7 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)