本地部署量化大模型的“上下文杀手”问题与解法:基于 oMLX 的 KV Cache 优化实践
关键词:本地 LLM、量化模型、OpenClaw、KV Cache、长上下文优化、oMLX、Apple Silicon
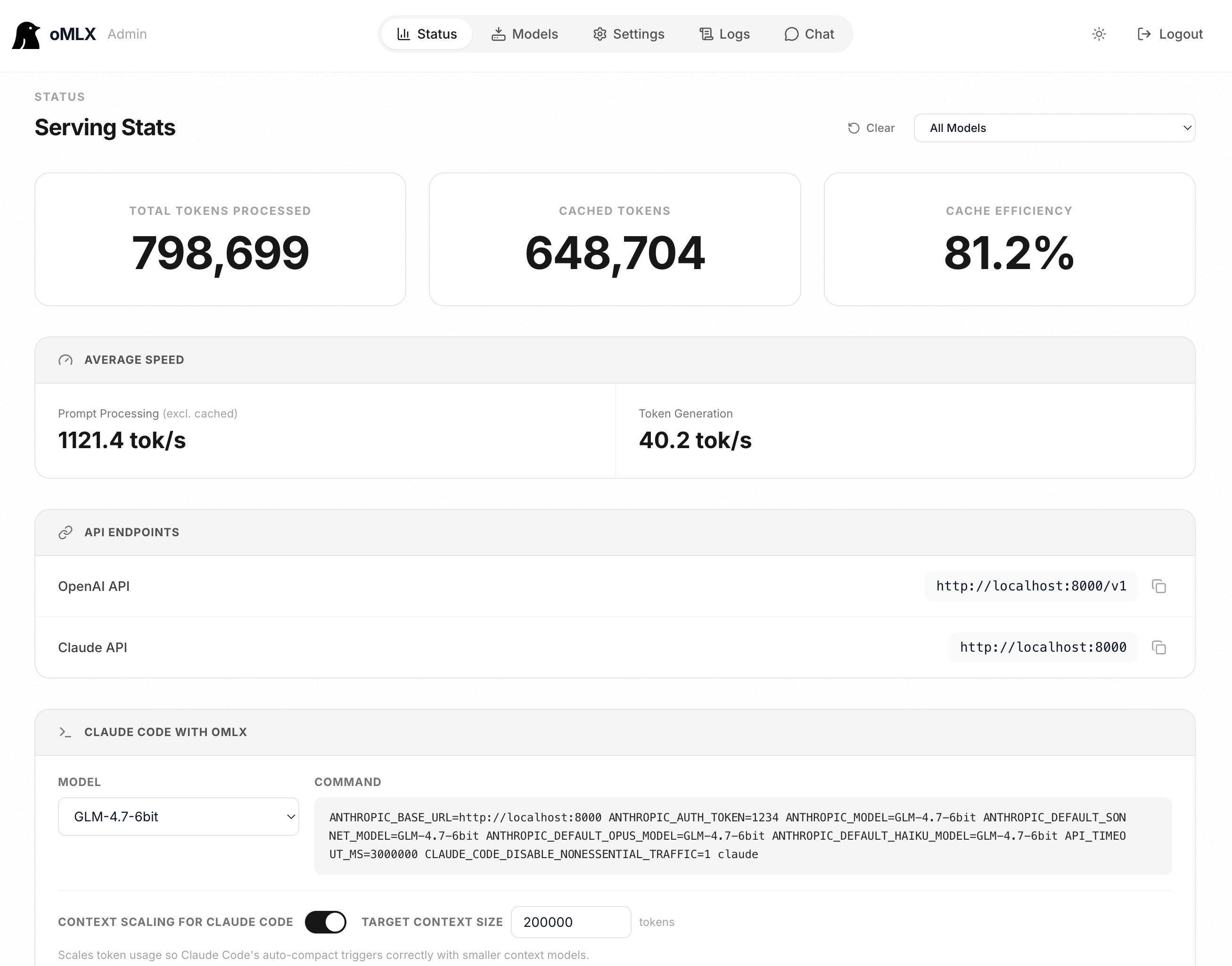
一句话总结
oMLX 本质上把 KV Cache 从“临时内存”升级为“可复用资产”
一、问题背景:本地大模型 + Agent 框架的“致命组合”
随着本地大模型(如 LLaMA、Qwen、DeepSeek 系列)逐渐普及,结合 Agent 框架(如 OpenClaw、LangChain、AutoGPT)构建本地 AI 工作流,成为越来越多工程师的选择。
但在实际使用中,你很快会遇到一个典型问题:
上下文过大 → 推理极慢 → 模型直接被“打死”
尤其是在以下场景:
- OpenClaw 持续发送超长 system prompt(工具描述 + memory + workspace)
- 多轮对话不断叠加上下文(10K ~ 100K tokens)
- 本地量化模型(如 3B / 7B)运行在 Mac / 轻量 GPU 上
典型表现:
- 每次请求都重新 prefill(30s ~ 90s)
- 内存飙升(KV Cache 占用超过模型本体)
- Ollama / LM Studio / llama.cpp 直接卡死或 OOM
二、本质原因:KV Cache 成为最大瓶颈
在 Transformer 推理中,KV Cache 是性能核心。
1. KV Cache 是什么?
在自回归推理中,每个 token 的 attention 计算依赖历史 token:
- Key(K)
- Value(V)
这些中间结果会缓存下来,避免重复计算。
👉 KV Cache = 用空间换时间
2. KV Cache 的问题有多严重?
现实数据:
- 8K 上下文:KV Cache ≈ 模型权重大小
- 32K 上下文:KV Cache > 模型权重
- 多并发:指数级增长
研究表明:
- KV Cache 占用可达总内存的 60%~80%
- 利用率却只有 20%~38%
3. OpenClaw 场景的致命点
Agent 类框架有一个特点:
每次请求的 prefix 在变化
例如:
System Prompt + Tools + Memory + 当前问题
问题:
- prefix 每次略微变化
- KV Cache 直接失效
- 重新 prefill 整个上下文
“每次 30~90 秒,完全不可用”
三、传统优化方案(但不够)
在 oMLX 之前,业界已经有一些 KV 优化方案:
1. PagedAttention(vLLM)
核心思想:
- KV Cache 分页管理(类似操作系统内存)
- 支持共享、复用
效果:
- 利用率提升到 96%
- 吞吐提升 2~4 倍 :contentReference[oaicite:3]{index=3}
👉 问题:
- 依赖 prefix 完全一致
- OpenClaw 场景依然频繁失效
2. KV Cache 量化(FP8 / INT4)
例如:
- FP8 KV Cache → 内存减半 :contentReference[oaicite:4]{index=4}
- KIVI / KVLinC → 极限压缩
👉 问题:
- 只是“缩小”,不是“复用”
- 仍然需要重新计算
3. GQA / MQA(模型结构优化)
通过减少 KV head 数量:
- KV Cache 降低 4~8 倍
👉 问题:
- 需要模型层面支持
- 对已有模型不可用
4. Sliding Window / StreamingLLM
只保留最近窗口:
- 控制 KV 增长
👉 问题:
- 长程记忆丢失
- 不适合 Agent
四、关键突破:oMLX 的 KV Cache 分层设计
oMLX 的核心思想可以总结为一句话:
让 KV Cache“持久化 + 可复用”,而不是每次重算
1. 项目概览
oMLX 是一个专为 Apple Silicon 优化的本地推理服务:
- 基于 MLX / mlx-lm
- 支持 OpenAI API
- 支持多模型并发
核心亮点:
两级 KV Cache(RAM + SSD)
2. 两级 KV Cache 架构
┌──────────────┐
│ 请求输入 │
└──────┬───────┘
│
┌────────▼────────┐
│ 热缓存(RAM) │ ← 当前活跃 KV
└────────┬────────┘
│
┌────────▼────────┐
│ 冷缓存(SSD) │ ← 历史 KV
└─────────────────┘
特性:
- RAM:高速访问
- SSD:持久化存储(safetensors)
3. 核心机制
(1)Block-based KV Cache
- 类似 vLLM 分页
- 按 block 管理 KV
(2)Prefix 匹配复用
- 新请求 → 查找已有 KV block
- 命中 → 直接复用
(3)Copy-on-Write
- 修改部分 context 时
- 不影响已有缓存
4. 真正解决的问题
传统方案:
prefix 变化 → cache 失效 → 全量重算
oMLX:
prefix 变化 → 部分复用 → 增量计算
5. 实际效果
“第二轮开始,5秒返回”
相比:
| 场景 | 传统方案 | oMLX |
|---|---|---|
| 首次请求 | 30~90s | 30~90s |
| 后续请求 | 30~90s | ~5s |
| 重启后 | 重新计算 | 直接复用 |
五、结合 OpenClaw 的实战架构
1. 原始架构
OpenClaw → Ollama / llama.cpp → 模型
问题:
- 每次请求 full context
- KV Cache 不复用
2. 优化架构(推荐)
OpenClaw
↓
oMLX(KV Cache 层)
↓
MLX 模型(量化)
3. 请求流变化
before
每次请求:
→ 重新 prefill 30K tokens
→ KV Cache 重建
after
首次:
→ 计算 + 写入 SSD
后续:
→ 命中 KV block
→ 只计算 diff
六、进一步优化建议
仅使用 oMLX 还不够,建议叠加以下策略:
1. 模型量化
推荐:
- Q4 / Q5(平衡)
- Q8(质量优先)
目标:
- 降低权重占用
- 给 KV Cache 留空间
2. 控制 system prompt
OpenClaw 默认:
- 工具描述极长
建议:
- 精简 tool schema
- 使用 embedding 检索
3. 分层 memory
将 context 拆分:
- 固定 prefix(缓存命中)
- 动态 memory(小窗口)
4. KV Cache 量化(未来)
结合:
- FP8 KV Cache
- INT4 KV Cache
可以进一步:
- 内存降低 2~4 倍
5. 结合先进研究方向
未来可关注:
- xKV(SVD 压缩)→ 6.8x 压缩
- KVLinC(低比特量化)→ 更高精度
- OjaKV(在线低秩)→ 动态适配
七、总结:本地 LLM 的“第二增长曲线”
本地大模型优化正在经历一个关键转变:
从“模型量化” → “KV Cache 工程”
核心结论
- 真正的瓶颈不是模型,而是 KV Cache
- Agent 场景会放大 KV 问题
- oMLX 通过 SSD 持久化 KV Cache 实现质变
- 本地推理从“不可用” → “工程可用”
八、适用场景
- Mac 本地开发(M1/M2/M3)
- OpenClaw / Claude Code 类 Agent
- 长上下文 coding / RAG
- 多轮复杂对话

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 9
9 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)