六、优化技术
前言
训练大模型面临的主要挑战是显存限制和计算效率。为了在有限硬件资源上训练千亿甚至万亿参数模型,一系列优化技术应运而生。本章将深入探讨混合精度训练、梯度累积、激活检查点、模型并行策略、ZeRO优化器以及序列并行等关键技术。
1、混合精度训练
混合精度训练通过同时使用低精度(FP16/BF16)和高精度(FP32)来加速计算、减少显存占用,同时保持模型收敛质量。
精度类型 显存占用 动态范围 计算速度 适用场景
FP32 4 字节 极广 慢 权重更新、关键计算
FP16 2 字节 窄 快 前向 / 反向传播计算
BF16 2 字节 与 FP32 相同 快 大模型训练(无需损失缩放)
1.1 原理
FP16(16位浮点):占用显存减半,计算速度提升(尤其在有Tensor Cores的GPU上)。但FP16的数值范围窄,容易发生溢出(上溢或下溢)。
BF16(bfloat16):Google提出,与FP32具有相同指数位(8位),因此动态范围与FP32相同,但尾数位较少。BF16无需损失缩放,稳定性更好,成为许多大模型(如GPT-3、LLaMA)的首选。
FP32主权重:为防止梯度下溢导致参数更新失效,始终保留一份FP32的权重副本。前向和反向传播使用FP16/BF16计算,得到梯度后更新FP32权重,再转换为低精度用于下一轮。
1.2 损失缩放(Loss Scaling)
由于FP16的梯度可能下溢(变为0),需要将损失乘以一个缩放因子(如 2^16),使梯度落入FP16可表示范围,更新参数后再还原。动态损失缩放根据梯度溢出情况自动调整因子。
eg
初始缩放因子 = 65536(2^16);
若梯度出现上溢(NaN/Inf),将缩放因子减半(32768),跳过本轮参数更新;
若连续 N 轮无溢出,将缩放因子恢复,保证梯度有效。
1.3 实现
PyTorch 提供 torch.cuda.amp 自动混合精度,DeepSpeed 和 Megatron-LM 也内置支持。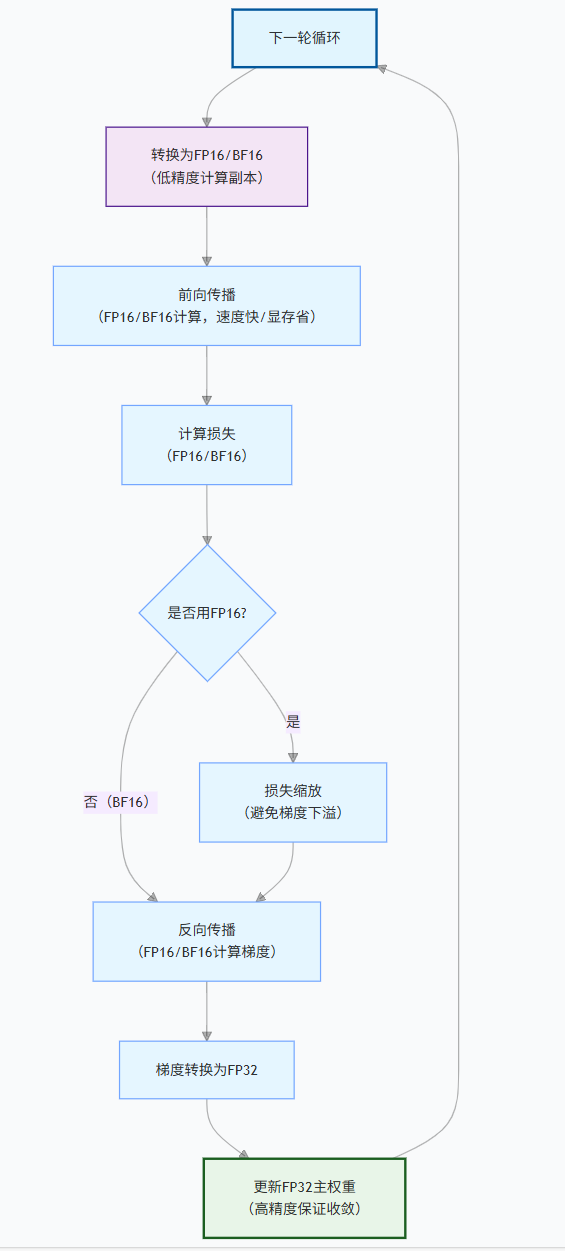
2、梯度累计(Gradient Accumulation)
梯度累积通过累加多个微批次(micro-batch)的梯度后再更新参数,模拟大批量训练。
作用:突破单卡显存限制,实现更大的有效批次大小,提高训练稳定性和吞吐量。
实现:每个微批次正常前向和反向,但不立即更新参数,而是将梯度累加(通过 loss.backward() 累积,不执行 optimizer.step())。达到累积步数后,执行一步参数更新,然后清零梯度。
维度 普通批量训练(batch=32) 梯度累积(micro-batch=8,N=4)
显存占用 高(需容纳 32 个样本) 低(仅容纳 8 个样本)
梯度计算 一次性计算 32 个样本梯度 分 4 次计算,累加梯度
参数更新频率 每 32 个样本更新 1 次 每 32 个样本更新 1 次(等效)
训练速度 快(单次计算) 稍慢(多次计算,但显存允许更大 N)
注意事项:需适当调整学习率(线性缩放法则),并注意 batch norm 层的行为(但大模型通常用 LayerNorm,无影响)。
3、激活检查点(重计算)
激活检查点(Activation Checkpointing,又称重计算)
激活检查点通过牺牲少量计算来节省显存。
原理:在前向传播时,只保存部分层的激活值(检查点),其余层的激活值丢弃。反向传播时,需要这些激活值时重新执行前向计算得到它们。
传统前向-反向传播(高显存)
前向传播:
Layer 1 → Layer 2 → Layer 3 → Layer 4 → Output
↓ ↓ ↓ ↓
Act1 Act2 Act3 Act4 ← 全部保存!
反向传播:
使用 Act4 → 使用 Act3 → 使用 Act2 → 使用 Act1
计算grad4 计算grad3 计算grad2 计算grad1
显存占用:O(L) (L=层数,需要保存所有激活值)
激活检查点(低显存)
前向传播(只保存检查点):
Layer 1 → Layer 2 → Layer 3 → Layer 4 → Output
↓ ↓
Act1 Act3(CP) ← 只保存检查点(CP)
✗ ✗
Act2被丢弃 Act4被丢弃
反向传播(需要时重计算):
步骤1: 使用 Act3(CP) → 重计算 Layer4 → 得到 Act4 → 计算grad4
步骤2: 使用 Act3(CP) → 计算grad3
步骤3: 使用 Act1 → 重计算 Layer2 → 得到 Act2 → 计算grad2
步骤4: 使用 Act1 → 计算grad1
显存占用:O(√L) 或 O(1) (只需保存少量检查点)
效果:可以将显存占用从 O(L) 降至 O(√L) 或更低(L为层数),但增加约20-30%的计算量。
层数(L) | 普通方法显存 | Checkpoint显存 | 显存节省 | 额外计算
--------|-------------|---------------|---------|----------
10 | 100% | 32% | 68% | ~20%
50 | 100% | 14% | 86% | ~25%
100 | 100% | 10% | 90% | ~30%
200 | 100% | 7% | 93% | ~30%
理论分析:
- 普通方法:显存 O(L),计算 O(L)
- Checkpoint:显存 O(√L) 或 O(log L),计算 O(L√L) 或 O(L log L)
实现:PyTorch 提供 torch.utils.checkpoint.checkpoint 函数包装需要重计算的模块
4、模型并行(Model Parallelism)
当模型参数超过单卡显存时,必须将模型切分到多张 GPU 上。模型并行主要分为三种类型:
┌─────────────────────────────────────────────────────────────────┐
│ 三种并行策略对比 │
├─────────────────────────────────────────────────────────────────┤
│ │
│ 数据并行 (DP) 张量并行 (TP) 流水线并行 (PP) │
│ ┌─────┐ ┌─────┐ ┌─────┐ ┌─────┐ ┌───── ┌─────┐ │
│ │Model│ │Model│ │Layer│ │Layer│ │Layer│ │Layer│ │
│ │全量 │ │全量 │ │ 切分│ │ 切分│ │ 1-6 │ │ 7-12│ │
│ └──┬──┘ └──┬──┘ └──┬──┘ └──┬──┘ └──┬──┘ └──┬──┘ │
│ │ │ │ │ │ │ │
│ ┌──┴──┐ ┌──┴──┐ ┌──┴───────┴──┐ ┌──┴──┐ ┌──┴──┐ │
│ │Data1│ │Data2│ │ 完整计算 │ │Data │ │Data │ │
│ └─────┘ └───── └───────────── └─────┘ └─────┘ │
│ │
│ 每卡存完整模型 每卡存部分权重 每卡存部分层 │
│ 处理不同数据 协同计算一层 流水执行 │
└─────────────────────────────────────────────────────────────────┘
4.1 数据并行(Data Parallelism)
方式:每张 GPU 持有完整模型副本,处理不同数据分片。前向后向独立计算梯度,然后通过 All-Reduce 通信同步梯度,更新所有副本。
前向传播:
GPU 0: Model(W) + Data[0:32] → Output0 → Loss0
GPU 1: Model(W) + Data[32:64] → Output1 → Loss1
GPU 2: Model(W) + Data[64:96] → Output2 → Loss2
GPU 3: Model(W) + Data[96:128]→ Output3 → Loss3
反向传播:
GPU 0: 计算 Grad0
GPU 1: 计算 Grad1
GPU 2: 计算 Grad2
GPU 3: 计算 Grad3
梯度同步(All-Reduce):
GPU 0: ──┐
GPU 1: ──┼──> All-Reduce ──> Grad_avg ──> 更新所有GPU的W
GPU 2: ──┤
GPU 3: ──┘
显存占用(每卡):
┌─────────────────────────┐
│ 模型参数 W (100%) │
│ 梯度 Grad (100%) │
│ 优化器状态 (200%) │ ← Adam有momentum和variance
│ 激活值 (batch相关) │
└─────────────────────────┘
代表:PyTorch DDP(DistributedDataParallel)。
优点:实现简单,适合模型能装入单卡但需要加速的场景。
缺点:每卡仍需存储完整模型参数、梯度和优化器状态,显存开销大。
4.2 张量并行(Tensor Parallelism,也称层内并行)
方式:将一层内的权重矩阵按行或列切分到多卡,每卡计算部分结果,通过通信合并。例如,Megatron-LM 将自注意力中的 QKV 投影矩阵按列切分,将 MLP 的两个线性层分别按行和列切分。
Transformer层的张量并行切分:
自注意力模块(按列切分QKV,按行切分Output):
═══════════════════════════════════════════════════
GPU 0 GPU 1
┌──────────────┐ ┌──────────────┐
│ Q₀ K₀ V₀ │ │ Q₁ K₁ V₁ │ ← 列切分
│ [d_model/2] │ │ [d_model/2] │
└──────┬───────┘ └─────────────┘
│ │
└────────┬──────────────────┘
│
┌──────▼──────┐
│ All-Gather │ ← 拼接Q, K, V
└────────────┘
│
┌──────▼──────┐
│Attention计算│
└──────┬──────
│
┌──────▼──────┐
│ All-Reduce │ ← 合并输出
└──────┬──────┘
│
Output
MLP模块(按列切分第一层,按行切分第二层):
═══════════════════════════════════════════════
GPU 0 GPU 1
┌──────────────┐ ┌──────────────┐
│ FC1₀ (4d/2) │ │ FC1₁ (4d/2) │ ← 列切分
└─────────────┘ ──────┬───────┘
│ │
┌────▼────┐ ┌────▼────┐
│ GELU │ │ GELU │
└────┬────┘ └────┬────┘
│ │
└────────┬──────────────────┘
│
┌──────▼──────┐
│ FC2₀ FC2₁ │ ← 行切分
└──────┬──────┘
│
┌──────▼──────┐
│ All-Reduce │
└──────┬──────┘
│
Output
通信:需要 All-Reduce 或 All-Gather 来合并结果,通信量较大。
优点:能处理超大规模层,减少单卡显存压力。
代表:NVIDIA Megatron-LM、Colossal-AI。
4.3 流水线并行(Pipeline Parallelism)
方式:将模型的不同层分配到不同设备,每个设备负责一部分层。输入数据被切成微批次(micro-batch),在设备间流水执行,使所有设备尽可能同时工作。
GPipe流水线并行(微批次):
═══════════════════════════════════════════════════════
设备0 (Layer 1-3) 设备1 (Layer 4-6) 设备2 (Layer 7-9)
│ │ │
微批次0:
F0─┐
│──>F0───────────────>│──>F0───────────────>│
B0<┼────────────────────<┼────────────────────<┼
│ │ │
微批次1:
F1─┐
│──>F1───────────────>│──>F1───────────────>│
B1<┼────────────────────<┼────────────────────<┼
│ │ │
微批次2:
F2─┐
│──>F2───────────────>│──>F2───────────────>│
B2<┼────────────────────<┼────────────────────<┼
│ │ │
微批次3:
F3─┐
│──>F3───────────────>│──>F3───────────────>│
B3<┼────────────────────<┼────────────────────<┼
│ │ │
时间轴:
T0: F0
T1: F0 F1
T2: F0 F1 F2
T3: F0 F1 F2 F3 ← 所有设备忙碌
T4: B0 F2 F3
T5: B0 B1 F3
T6: B0 B1 B2
T7: B0 B1 B2 B3
气泡(Bubble):设备空闲时间
GPipe气泡率 = (num_stages - 1) / num_microbatches
1F1B调度(PipeDream优化):
═══════════════════════════════════════════════════════
设备0 设备1 设备2
│ │ │
F0─┐
│──>F0───────────>│──>F0─────────────>│
F1─┐│ │ │
││──>F1─────────>│──>F1─────────────>│
F2─┐││ │ │
│││──>F2───────>│──>F2─────────────>│
B0<┼│││ │ │
││││ │ │
F3─┐│││ B0<─────────────────│
││││──>F3─────>││ │
B1<┼││││ ││ │
│││││ ││ │
B2<┼││││ B1<─────────────────│
│││││ ││ │
B3<┼││││ B2<─────────────────│
│││││ ││ │
│││││ B3<─────────────────│
1F1B:一次前向,一次后向交替执行
优点:减少显存(不需要保存所有激活值)
降低气泡率
经典方案:GPipe 引入微批次和梯度累积,减少设备空闲气泡;PipeDream 使用 1F1B 调度进一步优化。
优点:减少跨设备通信量(仅需传输中间激活和梯度)。
缺点:存在设备空闲(气泡),且需处理微批次间的依赖。
4.4 混合并行
实际大规模训练通常结合上述三种策略:如 3D 并行(数据并行 + 张量并行 + 流水线并行)。例如,训练 1750 亿参数的 GPT-3 使用 8 路张量并行 + 64 路流水线并行 + 数据并行。
3D并行架构(以GPT-3为例):
═══════════════════════════════════════════════════════
总配置:
- 模型参数: 175B
- GPU总数: 512卡
- 并行策略: TP=8 × PP=64 × DP=1
GPU组织(512卡):
┌─────────────────────────────────────────────────────┐
│ DP Group 0 (64卡) │
│ ┌─────────────────────────────────────┐ │
│ │ PP Stage 0 (8卡TP) │ │
│ │ GPU 0-7: Layer 1-2 (TP切分) │ │
│ └─────────────────────────────────────┘ │
│ ┌─────────────────────────────────────┐ │
│ │ PP Stage 1 (8卡TP) │ │
│ │ GPU 8-15: Layer 3-4 (TP切分) │ │
│ └─────────────────────────────────────┘ │
│ ... │
│ ┌─────────────────────────────────────┐ │
│ │ PP Stage 63 (8卡TP) │ │
│ │ GPU 496-503: Layer 125-126 (TP) │ │
│ └─────────────────────────────────────┘ │
└─────────────────────────────────────────────────────┘
┌─────────────────────────────────────────────────────┐
│ DP Group 1 (64卡) - 处理不同数据 │
│ ... │
└─────────────────────────────────────────────────────┘
...
┌─────────────────────────────────────────────────────┐
│ DP Group 7 (64卡) │
└─────────────────────────────────────────────────────┘
数据流:
1. 数据并行:不同DP组处理不同batch
2. 流水线并行:batch切分为micro-batch在PP stages间流水
3. 张量并行:每个layer内的矩阵运算在TP组内切分
显存分配(每卡):
┌─────────────────────────────────┐
│ 模型参数: 175B / (8×64) = 341M │ ← TP+PP切分
│ 优化器状态: 341M × 2 (FP16) │
│ 梯度: 341M │
│ 激活值: 取决于micro-batch大小 │
│ │
│ 总计: ~3-5 GB/卡(可行!) │
└─────────────────────────────────┘
4.5 序列并行(Sequence Parallelism)
当输入序列极长(如 100k tokens)时,自注意力的显存和计算成为瓶颈。序列并行将序列维度切分到多卡。
自注意力机制的显存与计算复杂度
═══════════════════════════════════════════════════════
注意力矩阵计算:
Q: [batch, seq_len, d_model]
K: [batch, seq_len, d_model]
V: [batch, seq_len, d_model]
Attention(Q, K, V) = softmax(QK^T / √d) V
QK^T 形状:[batch, seq_len, seq_len]
↓
注意力分数矩阵
显存需求:
─────────────────────────────────────────
序列长度 │ 注意力矩阵大小(FP16) │ 显存占用
─────────────────────────────────────────
2K │ 2K × 2K = 4M │ 8 MB
4K │ 4K × 4K = 16M │ 32 MB
8K │ 8K × 8K = 64M │ 128 MB
16K │ 16K × 16K = 256M │ 512 MB
32K │ 32K × 32K = 1024M │ 2 GB
64K │ 64K × 64K = 4096M │ 8 GB
128K │ 128K × 128K = 16384M│ 32 GB
─────────────────────────────────────────
计算复杂度:O(seq_len² × d_model)
↓
序列长度翻倍 → 计算量×4!
问题:单卡无法处理超长序列!
4.5.1 方式一:
Ring Attention:将序列分成块,每卡处理一块,通过块间通信实现全局注意力计算。
序列并行原理图解
Ring Attention 核心思想:
═══════════════════════════════════════════════════════
将序列分块,每卡处理一块,通过环状通信计算全局注意力
示例:4卡处理长度为L的序列
每卡处理 L/4 个token
GPU 0 GPU 1 GPU 2 GPU 3
┌─────┐ ┌─────┐ ┌─────┐ ┌─────
│ Q₀ │ │ Q₁ │ │ Q₂ │ │ Q₃ │
│ K₀ │ │ K₁ │ │ K₂ │ │ K₃ │
│ V₀ │ │ V₁ │ │ V₂ │ │ V₃ │
└─────┘ └───── └─────┘ └─────┘
│ │ │ │
└───────────┴───────────┴───────────┘
环状通信(Ring All-Reduce风格)
通信轮次(4卡需要3轮):
═══════════════════════════════════════════════════════
轮次0(初始状态):
GPU 0: 持有 (Q₀, K₀, V₀)
GPU 1: 持有 (Q₁, K₁, V₁)
GPU 2: 持有 (Q₂, K₂, V₂)
GPU 3: 持有 (Q₃, K₃, V₃)
轮次1(发送K,V到右边,接收左边):
GPU 0: 发送(K₀,V₀)→GPU1, 接收(K₃,V₃)←GPU3
计算 Attn(Q₀, [K₃,K₀], [V₃,V₀])
GPU 1: 发送(K₁,V₁)→GPU2, 接收(K₀,V₀)←GPU0
计算 Attn(Q₁, [K₀,K₁], [V₀,V₁])
GPU 2: 发送(K₂,V₂)→GPU3, 接收(K₁,V₁)←GPU1
计算 Attn(Q₂, [K₁,K₂], [V₁,V₂])
GPU 3: 发送(K₃,V₃)→GPU0, 接收(K₂,V₂)←GPU2
计算 Attn(Q₃, [K₂,K₃], [V₂,V₃])
轮次2(继续传递):
GPU 0: 转发(K₃,V₃)→GPU1, 接收(K₂,V₂)←GPU3
计算 Attn(Q₀, [K₃,K₀,K₂], [V₃,V₀,V₂])
...
轮次3(最后一轮):
所有卡都收到了所有(K, V)块
计算完整的注意力并累加
最终结果:
GPU 0: 输出 [Attn(Q₀, K_all, V_all)]
GPU 1: 输出 [Attn(Q₁, K_all, V_all)]
GPU 2: 输出 [Attn(Q₂, K_all, V_all)]
GPU 3: 输出 [Attn(Q₃, K_all, V_all)]
优势:
- 每卡只需存储 L/4 的 Q, K, V
- 注意力矩阵从 L×L 降为 (L/4)×(L/4)
- 显存从 O(L²) 降为 O(L²/P)(P为卡数)
Ring Attention 通信图
环状通信拓扑:
═══════════════════════════════════════════════════════
GPU 0
↗ ↖
发送 接收
↙ ↘
GPU 3 ←──→ GPU 1
↖ ↙
接收 发送
↖ ↗
GPU 2
每轮通信:
- 向右邻居发送 (K, V)
- 从左邻居接收 (K, V)
- 本地计算部分注意力
- 累加结果
总轮次:P - 1(P为GPU数量)
Megatron-LM 序列并行:与张量并行结合,沿序列维度切分 LayerNorm 和 Dropout,减少中间激活显存。
4.5.2 Megatron-LM 序列并行策略
═══════════════════════════════════════════════════════
与张量并行(TP)结合,沿序列维度切分
标准Transformer层:
─────────────────────────────────────────
Input (seq_len, batch, hidden)
↓
LayerNorm
↓
Self-Attention
↓
Dropout + Residual
↓
LayerNorm
↓
MLP
↓
Dropout + Residual
↓
Output
序列并行切分点:
─────────────────────────────────────────
Input: [seq_len/P, batch, hidden] ← 序列维度切分
↓
LayerNorm (序列并行)
↓
Self-Attention (每卡处理部分序列)
↓
Dropout (序列并行)
↓
All-Reduce (同步结果)
↓
Residual
↓
...
关键优化:
1. LayerNorm沿序列切分
- 每卡只计算部分序列的统计量
- 需要All-Reduce同步mean/variance
2. Dropout沿序列切分
- 每卡独立生成mask
- 无需额外通信
3. 注意力计算
- 每卡处理 seq_len/P 的Q
- 但需要全局的K, V(通过通信)
显存节省:
- 激活值从 O(seq_len) 降为 O(seq_len/P)
- 注意力矩阵从 O(seq_len²) 降为 O((seq_len/P)²)
4.5.3 DeepSpeed-Ulysses
DeepSpeed-Ulysses 多头注意力切分:
═══════════════════════════════════════════════════════
传统多头注意力:
─────────────────────────────────────────
num_heads = 32
每头维度:d_head = d_model / num_heads
Q, K, V: [batch, seq_len, num_heads, d_head]
Attention: 对每个head独立计算
Ulysses策略:切分heads到多卡
─────────────────────────────────────────
GPU数:P = 4
每卡处理:num_heads / P = 8个head
GPU 0: 处理 head 0-7
GPU 1: 处理 head 8-15
GPU 2: 处理 head 16-23
GPU 3: 处理 head 24-31
前向传播:
1. 每卡计算自己的8个head的注意力
Q_local: [batch, seq_len, 8, d_head]
K_local: [batch, seq_len, 8, d_head]
V_local: [batch, seq_len, 8, d_head]
2. All-to-All通信:交换head维度
每卡收集所有32个head的结果
3. 拼接所有head
Output: [batch, seq_len, 32, d_head]
4. 投影回d_model
优势:
- 每卡只计算 1/P 的head
- 计算量减少P倍
- 注意力矩阵大小不变,但数量减少
通信模式:All-to-All
- 比Ring Attention通信量小
- 适合中等长度序列
优点:支持超长上下文训练,如 GPT-4 的 32k、128k 上下文。
代表:Ring Attention、DeepSpeed-Ulysses、Colossal-AI。
5、ZeRO优化器(DeepSpeed)
ZeRO(Zero Redundancy Optimizer)由 Microsoft DeepSpeed 提出,核心思想:将模型状态(参数、梯度、优化器状态)切分到不同 GPU 上,消除冗余。,极大提升可训练模型规模。
5.1 阶段一(ZeRO-1):优化器状态切分
切分对象:优化器状态(如 Adam 的动量、方差)。
方式:每卡只保存一部分优化器状态,只更新对应的参数分片。通信只在参数更新时进行。
显存节省:减少 4 倍(若使用 Adam,优化器状态占参数量的 2 倍,切分到 N 卡后每卡占 2/N 倍参数量的显存)。
5.2 阶段二(ZeRO-2):梯度切分
在 ZeRO-1 基础上,进一步将梯度也切分到各卡。每卡只保存自己负责的参数的梯度(即模型梯度的分片),反向传播后通过 Reduce-Scatter 收集并切分梯度。
显存节省:额外减少梯度占用的显存(原本每卡需存全部梯度)。
5.3 阶段三(ZeRO-3):参数切分
切分对象:模型参数本身。每卡只保存一部分参数,前向/反向需要其他卡的参数时,通过广播通信动态获取。
显存节省:模型参数也被分片,可以训练参数量远超单卡显存的模型。
通信开销:ZeRO-3 引入额外通信,但可通过预取、重叠通信等优化。
5.4 ZeRO-Offload:CPU 卸载增强
ZeRO-3 结合 CPU Offload 可以进一步节省 GPU 显存,将优化器状态和参数卸载到 CPU 内存。
ZeRO-Offload 架构:
═══════════════════════════════════════════════════════
GPU (高速计算) CPU (大容量存储)
┌─────────────────┐ ┌─────────────────┐
│ 激活值 │ │ 模型参数 │
│ 部分梯度 │ <─────── │ 优化器状态 │
│ 计算单元 │ PCIe │ (ZeRO-Offload) │
└─────────────────┘ └─────────────────┘
流程:
1. Forward: GPU 从 CPU 拉取需要的参数分片
2. Compute: GPU 计算
3. Backward: GPU 计算梯度,推送到 CPU
4. Update: CPU 更新优化器状态和参数
优势:
- GPU 显存占用极低(仅保留激活值和少量梯度)
- 可利用 CPU 大内存训练超大模型
劣势:
- PCIe 带宽成为瓶颈(训练速度下降 30%-50%)
- 适合显存极度受限但 CPU 内存充足的场景
5.5 对比
在标准数据并行(DDP)中,每张 GPU 都保存完整的模型副本。这导致了巨大的显存浪费。
标准数据并行(DDP)的显存分布:
═══════════════════════════════════════════════════════
GPU 0 GPU 1
┌─────────────────────────┐ ┌─────────────────────────┐
│ 模型参数 (100%) │ │ 模型参数 (100%) │ ← 冗余!
│ 梯度 (100%) │ │ 梯度 (100%) │ ← 冗余!
│ 优化器状态 (100%) │ │ 优化器状态 (100%) │ ← 冗余!
│ 激活值 (Batch 相关) │ │ 激活值 (Batch 相关) │
└─────────────────────────┘ └─────────────────────────┘
问题:
如果模型有 100 亿参数,单卡显存需要 ~160GB(含优化器状态)。
即使有 8 张卡,每张卡仍需 160GB,无法利用多卡显存总和。
ZeRO 三阶段原理图解:显存组成分析(以 Adam 优化器 + 混合精度为例)
每参数显存占用(Bytes):
─────────────────────────────────────
1. 模型权重 (FP16) : 2 Bytes
2. 主权重 (FP32, 用于更新) : 4 Bytes
3. 梯度 (FP32/FP16) : 2-4 Bytes
4. 优化器状态 (Adam) : 8 Bytes (动量 + 方差,FP32)
─────────────────────────────────────
总计:~16 Bytes / 参数
ZeRO-1 / 2 / 3 切分策略对比
┌───────────────────────────────────────────────────────────────────┐
│ ZeRO 显存切分策略 │
├──────────────┬─────────────┬─────────────┬─────────────┬─────────┤
│ 组件 │ 标准 DDP │ ZeRO-1 │ ZeRO-2 │ ZeRO-3 │
├──────────────┼─────────────┼─────────────┼─────────────┼─────────┤
│ 模型参数 │ 每卡完整 │ 每卡完整 │ 每卡完整 │ 每卡分片 │
│ (Parameters) │ (冗余) │ (冗余) │ (冗余) │ (无冗余) │
├──────────────┼─────────────┼─────────────┼─────────────┼─────────┤
│ 梯度 │ 每卡完整 │ 每卡完整 │ 每卡分片 │ 每卡分片 │
│ (Gradients) │ (冗余) │ (冗余) │ (无冗余) │ (无冗余) │
├──────────────┼─────────────┼─────────────┼─────────────┼─────────┤
│ 优化器状态 │ 每卡完整 │ 每卡分片 │ 每卡分片 │ 每卡分片 │
│ (Optimizer) │ (冗余) │ (无冗余) │ (无冗余) │ (无冗余) │
├──────────────┼─────────────┼─────────────┼─────────────┼─────────┤
│ 显存节省 │ 1x │ ~4-8x │ ~8-12x │ ~16x+ │
├──────────────┼─────────────┼─────────────┼─────────────┼─────────┤
│ 通信开销 │ 低 │ 低 │ 中 │ 高 │
└──────────────┴─────────────┴─────────────┴─────────────┴─────────┘
可视化切分流程
ZeRO-1:优化器状态切分
═══════════════════════════════════════════════════════
GPU 0: [Params, Grads, Optim_State_Part_0]
GPU 1: [Params, Grads, Optim_State_Part_1]
更新时:All-Reduce 梯度 → 每卡更新自己的 Optim_State_Part
ZeRO-2:优化器状态 + 梯度切分
═══════════════════════════════════════════════════════
GPU 0: [Params, Grad_Part_0, Optim_State_Part_0]
GPU 1: [Params, Grad_Part_1, Optim_State_Part_1]
反向时:Reduce-Scatter 梯度 → 每卡只保留自己的 Grad_Part
ZeRO-3:优化器状态 + 梯度 + 参数切分
═══════════════════════════════════════════════════════
GPU 0: [Param_Part_0, Grad_Part_0, Optim_State_Part_0]
GPU 1: [Param_Part_1, Grad_Part_1, Optim_State_Part_1]
前向时:All-Gather 缺失的参数 → 计算 → 释放
反向时:All-Gather 缺失的参数 → 计算梯度 → 释放
5.6 举例
显存节省计算(以 10B 参数模型为例)
模型规模:10 Billion Parameters
精度:FP16 混合精度训练
GPU 数量:8 卡
标准 DDP 每卡显存需求:
─────────────────────────────────────
参数 (FP16) : 10B × 2B = 20 GB
主权重 (FP32) : 10B × 4B = 40 GB
梯度 (FP32) : 10B × 4B = 40 GB
优化器 (Adam FP32) : 10B × 8B = 80 GB
激活值 (估算) : ~20 GB
─────────────────────────────────────
总计/卡 : ~200 GB ❌ (单卡无法加载)
ZeRO-1 (8 卡) 每卡显存:
─────────────────────────────────────
参数 + 主权重 + 梯度 : 100 GB (未切分)
优化器 (切分 8 份) : 80 GB / 8 = 10 GB
激活值 : ~20 GB
─────────────────────────────────────
总计/卡 : ~130 GB ❌ (仍较大)
ZeRO-2 (8 卡) 每卡显存:
─────────────────────────────────────
参数 + 主权重 : 60 GB (未切分)
梯度 (切分 8 份) : 40 GB / 8 = 5 GB
优化器 (切分 8 份) : 80 GB / 8 = 10 GB
激活值 : ~20 GB
─────────────────────────────────────
总计/卡 : ~95 GB ⚠️ (A100 80GB 仍不够)
ZeRO-3 (8 卡) 每卡显存:
─────────────────────────────────────
参数 (切分 8 份) : 20 GB / 8 = 2.5 GB
主权重 (切分 8 份) : 40 GB / 8 = 5 GB
梯度 (切分 8 份) : 40 GB / 8 = 5 GB
优化器 (切分 8 份) : 80 GB / 8 = 10 GB
激活值 : ~20 GB
─────────────────────────────────────
总计/卡 : ~42.5 GB ✅ (单卡 40-80GB 可训练!)
ZeRO-3 + Offload (8 卡) 每卡显存:
─────────────────────────────────────
参数 + 优化器 (CPU) : 0 GB (GPU 上)
梯度 (切分) : 5 GB
激活值 : ~20 GB
─────────────────────────────────────
总计/卡 (GPU) : ~25 GB ✅✅ (消费级显卡也可尝试)
通信开销对比
通信模式与开销:
═══════════════════════════════════════════════════════
DDP:
通信:All-Reduce (梯度)
频率:每 Step 1 次
数据量:2 × 参数量 (FP16)
ZeRO-1:
通信:All-Reduce (梯度)
频率:每 Step 1 次
数据量:2 × 参数量
额外:无(优化器状态本地更新)
ZeRO-2:
通信:Reduce-Scatter (梯度)
频率:每 Step 1 次
数据量:2 × 参数量
优势:梯度无需全量保存,通信量略减
ZeRO-3:
通信:All-Gather (参数) + Reduce-Scatter (梯度)
频率:每层 Forward/Backward 前后
数据量:3 × 参数量 (参数 gather + 梯度 scatter)
劣势:通信量显著增加,依赖高带宽网络
优化技术:
1. 通信与计算重叠 (Overlap Comm)
2. 参数预取 (Prefetch)
3. 梯度累积 (减少通信频率)
5.7 小结
场景选择
┌──────────────────┬─────────────┬─────────────┬─────────────┐
│ 场景 │ 推荐方案 │ 显存需求 │ 速度 │
├──────────────────┼─────────────┼─────────────┼─────────────┤
│ 模型 < 单卡显存 │ DDP │ 高 │ 最快 │
│ 模型稍大 │ ZeRO-1 │ 中 │ 快 │
│ 模型较大 │ ZeRO-2 │ 低 │ 中 │
│ 模型 > 单卡显存 │ ZeRO-3 │ 极低 │ 较慢 │
│ 显存极度受限 │ZeRO-3+Offload│ 超低 │ 慢 │
└──────────────────┴─────────────┴─────────────┴─────────────┘
网络要求
ZeRO-1/2:千兆/万兆以太网即可,对带宽不敏感。
ZeRO-3:必须使用高速互联(NVLink, InfiniBand, RoCE)。如果是多机训练,网络带宽是核心瓶颈。
ZeRO-Offload:依赖 PCIe 带宽(Gen3/Gen4),CPU 内存速度。
常见问题排查
1、OOM (Out Of Memory):
降低 reduce_bucket_size。
启用 cpu_offload。
减小 micro_batch_size。
2、训练速度慢:
检查网络带宽(ZeRO-3 对网络敏感)。
开启 overlap_comm: true。
增加 gradient_accumulation_steps 减少通信频率。
3、** hangs (死锁)**:
确保所有 GPU 的 world_size 配置一致。
检查 NCCL 环境变量 (NCCL_DEBUG=INFO)。
┌─────────────────────────────────────────────────────────────────┐
│ ZeRO 优化器核心总结 │
├─────────────────────────────────────────────────────────────────┤
│ 1. 核心目标:消除数据并行中的显存冗余(参数、梯度、优化器状态)。 │
│ 2. 三个阶段: │
│ - ZeRO-1: 切分优化器状态 (节省 ~4x) │
│ - ZeRO-2: 切分优化器 + 梯度 (节省 ~8x) │
│ - ZeRO-3: 切分优化器 + 梯度 + 参数 (节省 ~16x+) │
│ 3. 代价:显存节省是以增加通信开销为代价的。 │
│ 4. 扩展:ZeRO-Offload 可将状态卸载到 CPU,进一步节省 GPU 显存。 │
│ 5. 生态:DeepSpeed 原生支持,PyTorch FSDP 提供原生替代方案。 │
│ 6. 适用:训练参数量超过单卡显存限制的大模型必备技术。 │
└─────────────────────────────────────────────────────────────────┘

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 5
5 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)