【AI企业】【信息科学与工程学】计算机科学与自动化 第八十篇 人工智能数学方程式/算法表02 Token
|
编号 |
类别 |
领域 |
模型配方 |
数学公式/定理/算法/模型/方法名称 |
数学公式/定理/算法/模型/方法的逐步思考推理过程及每一个步骤的数学方程式和参数选择/优化/迭代 |
精度/密度/误差/强度 |
底层规律/理论 |
典型应用场景和特征 |
变量/常量/参数列表及说明 |
数学特征 |
语言特征 |
时序和交互流程的所有细节/分步骤时序情况及数学方程式 |
流动模型和流向方法的数学描述 |
多GPU芯片执行情况和方程式列表 |
关联知识和算法 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
AI-A0-0186 |
优化算法 |
注意力计算 |
一种IO感知的精确注意力算法,通过分块和重计算减少内存访问,提高计算效率。 |
Flash Attention |
1. 目标: 计算注意力输出 O=softmax(QKT)V,同时减少高带宽内存(HBM)与片上内存(SRAM)之间的数据传输。 |
优点: 大幅减少内存访问, 加速注意力计算, 支持长序列。 |
算法优化, 内存层次。 利用GPU内存层次,通过分块和重计算优化注意力计算的内存效率。 |
场景: 训练和推理大模型, 尤其是长序列场景。 |
Q,K,V: 查询、键、值矩阵,形状 (L,d)。 |
分块矩阵乘法: QKT分块计算。 |
描述为“将注意力计算分块进行,在片上内存中逐块计算注意力分数和输出,并使用在线softmax避免存储整个注意力矩阵,从而减少内存访问”。 |
**1. 初始化输出 O=0,softmax分母 l=0,最大值 m=−∞。 |
“分块流”: 查询流 Q被分成小块流 Qi,键值流 K,V被分成小块流 Kj,Vj。注意力计算流在SRAM中进行:对于每个 Qi,依次与所有 Kj,Vj块流交互,通过在线softmax流逐步更新输出流 Oi。这种流避免了将整个 QKT矩阵流经HBM,减少了数据移动。 |
Flash Attention 利用GPU的共享内存(SRAM)进行块计算,减少全局内存(HBM)访问。在多GPU中,序列可以分区,每个GPU计算本地注意力,但需要全局通信来聚合结果(如模型并行)。Flash Attention 可以结合模型并行使用。 |
注意力机制, 在线softmax, 内存优化。 |
|
AI-A0-0187 |
位置编码 |
序列建模 |
一种线性偏置方法,在注意力分数中添加一个与相对距离成比例的偏置,无需学习的位置嵌入。 |
ALiBi (Attention with Linear Biases) |
1. 偏置项: 在注意力分数 Sij=qiTkj上添加一个与相对距离 j−i成比例的负偏置:$\tilde{S}{ij} = S{ij} - m \cdot |
j-i |
,其中m是头特定的斜率。<br>∗∗2.斜率设置:∗∗对于头h(从0开始计数),m_h = 2^{-8h/H},其中H是总头数。<br>∗∗3.注意力计算:∗∗\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T - m \cdot D}{\sqrt{d_k}}\right) V,其中D_{ij} = |
j-i |
(对于自回归解码器,j > i时D_{ij} = \infty$ 或大数,以掩码未来位置)。 |
优点: 无需位置嵌入, 外推性好, 在长序列上表现优异。 |
位置编码, 相对位置。 通过添加与相对距离成比例的线性偏置来注入位置信息。 |
场景: 自回归语言模型, 如GPT-like模型, 尤其擅长外推到更长序列。 |
qi,kj: 查询和键向量。 |
j-i |
。<br>∗∗H:∗∗总头数。<br>∗∗h$:** 头索引(0-based)。 |
|
AI-A0-0188 |
归一化技术 |
层归一化 |
层归一化的变体,仅对输入进行缩放,不进行平移,且使用RMS(均方根)进行归一化。 |
RMSNorm (Root Mean Square Layer Normalization) |
1. 计算RMS: 对于输入 x∈Rd,RMS(x)=d1∑i=1dxi2。 |
特点: 去除了均值中心化, 仅使用RMS进行缩放, 计算更简单, 在有些模型中表现与LayerNorm相当。 |
归一化, 缩放。 使用均方根进行归一化,仅学习缩放参数,简化计算。 |
场景: LLaMA、T5等模型, 作为LayerNorm的替代。 |
x: 输入向量,维度 d。 |
均方根: 平方和的平均再开方。 |
描述为“计算输入向量的均方根,然后用它来缩放输入,最后乘以可学习的缩放参数”。 |
1. 计算 RMS=d1∑i=1dxi2+ϵ。 |
“RMS缩放”流: 输入流 x首先计算其均方根流 RMS(x),该流衡量了输入的总体幅度。然后,输入流被 RMS(x)缩放,得到一个单位RMS的流 x^。最后,通过可学习的缩放参数流 g对每个维度进行重新缩放,恢复模型的表达能力。与LayerNorm相比,它省略了减去均值的步骤,假设零均值已由前一层的偏置项处理。 |
RMSNorm计算比LayerNorm少一步均值计算,因此略高效。同样可并行计算。在多GPU中,每个样本独立计算RMS,然后进行缩放。 |
LayerNorm, 归一化。 |
|
AI-A0-0189 |
激活函数 |
激活函数 |
一种门控激活函数,结合了Swish(SiLU)和GLU(Gated Linear Unit)的思想。 |
SwiGLU |
1. 定义: SwiGLU(x,W,V,b,c)=Swish(xW+b)⊙(xV+c),其中 Swish(x)=xσ(x),σ是sigmoid函数,⊙是逐元素乘法。 |
优点: 比ReLU或GELU表现更好, 在PaLM等大模型中采用。 |
激活函数, 门控机制。 通过Swish激活的门控线性单元,增强非线性表达能力。 |
场景: Transformer的FFN层, 替代标准ReLU/GELU FFN。 |
x: 输入,形状 (L,dmodel)。 |
门控: 逐元素乘法。 |
描述为“对输入进行两个不同的线性变换,其中一个变换的结果经过Swish激活,然后与另一个变换的结果逐元素相乘,最后再经过一个线性变换”。 |
1. 计算 A=Swish(xW1+b)=(xW1+b)σ(xW1+b)。 |
“双路门控”流: 输入流 x被复制为两路。一路流经线性变换 W1和Swish激活,产生门控信号流 A。另一路流经线性变换 V1,产生值流 B。两路流通过逐元素乘法融合,其中Swish激活的门控信号 A调制值流 B。融合后的流 H再经过线性变换 W2输出。这种门控机制允许模型选择性地传递信息。 |
SwiGLU FFN比标准FFN多一个线性投影(V1),因此计算量和参数量更大。计算可以并行:xW1和 xV1可以同时计算。在多GPU中,线性变换可以按模型并行方式分割。 |
FFN, GELU, GLU。 |
|
AI-A0-0190 |
训练技巧 |
梯度处理 |
在多个小批量上累积梯度,然后一次性更新参数,模拟大批量训练。 |
梯度累积 (Gradient Accumulation) |
1. 过程: 对于 N个连续的小批量(micro-batch),每次前向传播后计算梯度,但不立即更新参数,而是将梯度累加到累积变量中。 |
目的: 在内存有限时模拟大批量训练, 稳定训练, 允许使用更大的有效批量大小。 |
优化技巧, 内存效率。 通过多次前向-反向传播累积梯度,实现更大的有效批量大小。 |
场景: 当GPU内存不足以容纳大批量时, 训练大模型。 |
gi: 第 i个小批量的梯度。 |
累加: G=∑i=1Ngi。 |
描述为“在多个小批量上重复前向和反向传播,累积梯度但不更新参数,累积一定步数后,用累积梯度(或平均梯度)更新一次参数”。 |
1. 初始化累积梯度 G=0,计数器 count=0。 |
“梯度缓冲”流: 在标准训练中,梯度流 gi产生后立即用于更新参数流 θ。在梯度累积中,梯度流被暂时存储到累积缓冲区 G中。经过 N个小批量,N个梯度流汇合成一个累积梯度流 G。然后这个累积流被用于更新参数流,模拟了一个批量大小为 N×micro-batch size的更新。这允许在有限内存下使用更大的有效批量。 |
梯度累积在单个GPU或数据并行中均可使用。每个GPU独立计算本地梯度并累积。在数据并行中,如果使用梯度平均,需要在累积 N步后对所有GPU的累积梯度进行AllReduce,然后更新参数。 |
批量大小, 优化器。 |
|
AI-A0-0191 |
训练技巧 |
混合精度 |
使用半精度(FP16)进行前向和反向传播,同时保留单精度(FP32)主权重副本用于更新,以加速训练并减少内存占用。 |
混合精度训练 (Mixed Precision Training) |
1. 维护FP32主权重: θfp32。 |
优点: 加速计算, 减少内存占用, 保持数值稳定性。 |
数值计算, 精度。 利用FP16加速计算,用FP32保持数值范围,通过梯度缩放防止下溢。 |
场景: 训练大型神经网络, 如Transformer, 需要加速和节省内存。 |
θfp32: FP32主权重。 |
精度转换: FP32 ↔ FP16。 |
描述为“使用半精度进行前向和反向传播以加速计算并节省内存,同时保留单精度主权重副本用于更新,并通过梯度缩放防止梯度下溢”。 |
1. 将FP32主权重 θfp32复制为FP16权重 θfp16。 |
“精度混合流”: 权重流 θ以FP32格式存储(主权重流)。在前向流中,权重流被转换为FP16流 θfp16,与FP16输入流进行运算,产生FP16激活流和损失流。损失流被缩放因子 S放大,以保留梯度信息。反向流计算FP16梯度流 gfp16,然后反缩放并转换为FP32梯度流 gfp32,最后用于更新FP32主权重流。这种流在计算密集型部分使用FP16加速,在权重更新时使用FP32保持精度。 |
混合精度训练需要GPU支持FP16计算(如Tensor Cores)。在数据并行中,每个GPU进行本地FP16前向/反向传播,梯度在FP32下进行AllReduce。梯度缩放可以动态调整(如根据梯度范数)。 |
FP16, 梯度缩放, 数值稳定性。 |
|
AI-A0-0192 |
训练技巧 |
内存优化 |
在训练中只保存部分中间激活值,在反向传播时重新计算其他激活,以节省内存。 |
激活检查点 (Activation Checkpointing) |
1. 前向传播: 将模型分成若干段(checkpoint segments)。在前向传播时,只保存每段的输入和输出(检查点),不保存中间激活值。 |
节省内存: 内存占用从 O(L)降低到 O(L)或 O(logL), 其中 L是层数。 |
内存-计算权衡。 通过重计算中间激活来减少内存占用。 |
场景: 训练极深模型, 内存受限时。 |
模型分段: 将模型分为 k段。 |
重计算: 从检查点重新运行前向传播。 |
描述为“将模型分成若干段,在前向传播时只保存每段的输入和输出作为检查点,在反向传播时根据需要从检查点重新计算中间激活,从而节省内存”。 |
1. 将模型划分为 k个段:[segment1,segment2,...,segmentk]。 |
“检查点-重计算”流: 前向流经过模型分段,每段的输入流 xi和输出流 yi被保存为检查点流,而段内的中间激活流被丢弃。在反向流中,从最后一段开始,加载检查点流 xi和 yi,重新执行该段的前向流以生成中间激活流,然后计算梯度流。梯度流传播后,中间激活流被释放。这种流以额外的计算流为代价,减少了内存中需要同时保存的激活流数量。 |
激活检查点可以在单个GPU上实施,也可以与数据并行结合。在模型并行中,检查点可以设置在设备边界。重计算会增加计算时间,但允许训练更大的模型或更大的批量。 |
重计算, 内存优化, 梯度检查点。 |
|
AI-A0-0193 |
并行策略 |
模型并行 |
将模型的不同层放置在不同的设备上,按层顺序执行,每层计算完成后将激活传递给下一层。 |
流水线并行 (Pipeline Parallelism) |
1. 模型划分: 将模型的 L层划分为 p个阶段(stage),每个阶段包含连续的若干层,放置在不同的设备上。 |
目标: 将模型分布到多个设备, 解决单个设备内存不足问题。 |
模型并行, 流水线。 将模型按层划分到多个设备,通过流水线执行提高设备利用率。 |
场景: 模型过大无法放入单个设备内存时。 |
p: 流水线阶段数。 |
流水线: 多个微批量重叠执行。 |
描述为“将模型按层划分到多个设备上,将每个批量分成多个微批量,以流水线方式执行微批量的前向和反向传播,从而重叠不同设备上的计算”。 |
1. 前向传播(以GPipe为例): |
“流水线流”: 数据流被分割为微批量流。这些微批量流依次进入流水线。每个设备(阶段)处理其对应的层流。当一个微批量流完成一个阶段后,其激活流被发送到下一个阶段,同时该阶段可以处理下一个微批量流。这样,多个微批量流在流水线中重叠流动,提高了设备利用率。然而,在流水线开始和结束时,会有气泡(空闲时间),因为并非所有阶段都同时工作。 |
流水线并行需要设备间通信传递激活和梯度。通信发生在相邻阶段之间。气泡开销可以通过增加微批量数量来减少。通常与数据并行结合,形成混合并行。 |
模型并行, 数据并行, 张量并行。 |
|
AI-A0-0194 |
并行策略 |
模型并行 |
将模型的单个层内的参数和计算分割到多个设备上,通常按维度分割矩阵乘法。 |
张量并行 (Tensor Parallelism) |
1. 列并行: 将权重矩阵 W按列分割,W=[W1,W2],输入 x广播,y=xW=x[W1,W2]=[xW1,xW2],每个设备计算一部分,结果拼接。 |
目标: 将单个层的计算分布到多个设备, 减少每个设备的内存和计算负载。 |
模型并行, 矩阵分割。 将矩阵乘法按行或列分割到多个设备,通过通信组合结果。 |
场景: 单个层过大无法放入单个设备内存时, 如大型FFN层或注意力层。 |
W: 权重矩阵,形状 (m,n)。 |
列分割: W按列分割,x广播,输出拼接。 |
描述为“将权重矩阵按行或列分割到多个设备上,每个设备计算部分结果,然后通过通信(如拼接或求和)得到完整输出”。 |
以列并行为例: |
“张量分割流”: 权重流 W被分割成多个子流 Wi分布在不同设备上。输入流 x被广播或分割到各设备。每个设备独立计算局部流 yi=xWi或 zi=xiWi。然后通过通信流(All-Gather或All-Reduce)将局部流聚合成全局流 y。这种流将单个层的计算负载分散到多个设备,但引入了通信开销。 |
张量并行需要设备间通信,通信量较大。通常用于单个层非常大的情况,如Transformer的FFN层(dff很大)。在多头注意力中,可以将不同头分布到不同设备上。 |
模型并行, 流水线并行, Megatron-LM。 |
|
AI-A0-0195 |
并行策略 |
模型并行 |
将模型的不同层放置在不同的设备上,每层计算在单个设备上完成,层间通过设备间通信传递激活和梯度。 |
模型并行 (Model Parallelism) |
1. 垂直划分: 将模型按层划分,不同层放置在不同设备上。 |
目标: 将模型分布到多个设备, 解决内存不足问题。 |
模型并行, 层划分。 将模型的不同层放置在不同设备上,串行执行。 |
场景: 模型过大无法放入单个设备内存, 且层数较多时。 |
L: 总层数。 |
串行: 一次只有一个设备在计算。 |
描述为“将模型的不同层放置在不同的设备上,前向传播时数据从一个设备流向下一个设备,每层计算完成后将激活传递给下一层,反向传播时梯度反向传递”。 |
1. 前向传播: |
“层间流”: 数据流依次流经每个设备上的层流。每个设备上的层流处理完后,激活流被发送到下一个设备。反向传播时,梯度流反向流动。这种流是纯串行的,因此设备利用率低,大部分设备处于空闲状态。 |
模型并行(纯层并行)通信量相对较小(仅层间传递激活和梯度),但设备利用率低。通常与数据并行结合,形成混合并行。 |
流水线并行, 张量并行。 |
|
AI-A0-0196 |
优化算法 |
内存优化 |
一种优化器状态分区技术,将优化器状态、梯度和参数分区到多个设备上,以节省内存。 |
ZeRO (Zero Redundancy Optimizer) |
1. ZeRO-DP: 数据并行,但将优化器状态、梯度和参数分区到多个GPU上,每个GPU只存储一部分。 |
目标: 减少数据并行中的内存冗余, 允许训练更大模型。 |
数据并行, 内存优化。 通过分区优化器状态、梯度和参数,消除数据并行中的内存冗余。 |
场景: 训练极大模型, 如万亿参数模型, 内存受限。 |
N: GPU数量。 |
分区: 将张量沿某个维度分割。 |
描述为“在数据并行中,将优化器状态、梯度和参数分区到多个GPU上,每个GPU只负责更新和存储其中一部分,从而大幅减少每个GPU的内存占用”。 |
以ZeRO-3为例: |
“分区流”: 参数流 W被分割成多个子流 Wi分布在不同GPU上。在前向流中,通过All-Gather通信流将 Wi聚合成完整参数流 W用于计算,然后释放非本地部分。梯度流同样被分区存储。优化器状态流 |
|
编号 |
类别 |
领域 |
模型配方 |
数学公式/定理/算法/模型/方法名称 |
数学公式/定理/算法/模型/方法的逐步思考推理过程及每一个步骤的数学方程式和参数选择/优化/迭代 |
精度/密度/误差/强度 |
底层规律/理论 |
典型应用场景和特征 |
变量/常量/参数列表及说明 |
数学特征 |
语言特征 |
时序和交互流程的所有细节/分步骤时序情况及数学方程式 |
流动模型和流向方法的数学描述 |
多GPU芯片执行情况和方程式列表 |
关联知识和算法 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
AI-A0-0198 |
优化算法 |
优化器 |
一种自适应学习率优化算法,为每个参数维护一个学习率,该学习率与历史梯度平方和的平方根成反比。 |
Adagrad (Adaptive Gradient Algorithm) |
1. 初始化: 累积梯度平方和 G=0。 |
特点: 自适应学习率, 稀疏梯度效果好, 但学习率可能单调下降至过小。 |
自适应学习率, 梯度平方累积。 为每个参数自适应调整学习率,梯度大的参数学习率小,梯度小的参数学习率大。 |
场景: 处理稀疏特征的模型, 如词嵌入训练。 |
θi: 第 i个参数。 |
累积和: Gt,i=∑τ=1tgτ,i2。 |
描述为“为每个参数维护一个梯度平方的累积和,并用其平方根的倒数来缩放学习率”。 |
1. 初始化参数 θ,初始化累积变量 G=0。 |
“自适应衰减”流: 每个参数 θi的梯度流 gt,i被平方后累积到历史流 Gt,i中。更新流中,学习率 α被 Gt,i缩放。梯度大的参数,Gt,i增长快,学习率迅速下降;梯度小的参数,学习率下降慢。这导致学习率单调递减,可能过早停止学习。 |
Adagrad需要为每个参数维护累积变量 G,内存开销与参数数量成正比。在数据并行中,每个GPU计算本地梯度,但累积平方梯度需要在所有GPU上同步?实际上,Adagrad的累积是基于每个参数独立的历史,在数据并行中,每个GPU有完整的模型副本和累积变量,梯度聚合后,每个GPU用相同的聚合梯度更新自己的累积变量,因此不需要额外同步累积变量。 |
RMSProp, Adam, 自适应学习率。 |
|
AI-A0-0199 |
优化算法 |
优化器 |
Adagrad的改进,使用指数移动平均代替累积和,解决学习率递减问题。 |
RMSProp (Root Mean Square Propagation) |
1. 初始化: 移动平均 E[g2]0=0。 |
特点: 自适应学习率, 解决Adagrad学习率单调下降问题, 适用于非平稳目标。 |
自适应学习率, 指数移动平均。 使用梯度平方的指数移动平均来调整学习率,避免累积和无限增长。 |
场景: 深度学习, 尤其是循环神经网络。 |
θ: 参数。 |
指数移动平均: E[g2]t=βE[g2]t−1+(1−β)gt2。 |
描述为“维护梯度平方的指数移动平均,并用其平方根的倒数来缩放学习率”。 |
1. 初始化参数 θ,初始化 E[g2]=0。 |
“指数平滑自适应”流: RMSProp引入衰减率 β,使得梯度平方的历史流 E[g2]t是指数移动平均,而不是累积和。这给旧梯度赋予衰减权重,使得 E[g2]t不会无限增长,学习率不会单调递减至零,能够适应非平稳的优化环境。 |
类似Adagrad,需要为每个参数维护移动平均状态 E[g2]。在数据并行中,每个GPU独立更新自己的状态,但梯度聚合后,所有GPU使用相同的梯度更新,因此状态保持一致。 |
Adagrad, Adam, 自适应学习率。 |
|
AI-A0-0200 |
优化算法 |
优化器 |
结合动量法和RMSProp,同时使用梯度的一阶矩和二阶矩估计。 |
Adam (Adaptive Moment Estimation) |
1. 初始化: 一阶矩 m0=0,二阶矩 v0=0,时间步 t=0。 |
优点: 自适应学习率, 动量, 偏差校正, 鲁棒性好。 |
自适应优化, 动量, 二阶矩。 结合动量法和RMSProp,并引入偏差校正。 |
场景: 深度学习广泛使用, 尤其是Transformer。 |
θ: 参数。 |
指数移动平均: 一阶和二阶矩。 |
描述为“维护梯度的一阶矩(动量)和二阶矩(梯度平方)的指数移动平均,进行偏差校正后,用校正后的矩更新参数”。 |
1. 初始化 m=0,v=0,t=0。 |
“自适应动量”流: Adam将动量流(一阶矩)和自适应学习率流(二阶矩)结合。动量流 mt提供平滑的梯度方向,自适应流 vt根据梯度幅度调整每个参数的学习率。偏差校正流消除初始零偏置。更新流中,m^t提供方向,v^t提供缩放,实现高效优化。 |
Adam需要为每个参数维护两个状态 m和 v。在数据并行中,梯度聚合后,每个GPU用相同的梯度更新本地状态,因此状态保持一致。在模型并行中,参数和状态分布在多个GPU上,更新需要通信或本地进行。 |
AdamW, RMSProp, 动量法。 |
|
AI-A0-0201 |
优化算法 |
优化器 |
Adam的变体,将权重衰减与参数更新解耦,直接添加到更新步骤中。 |
AdamW |
1. 计算梯度: gt=∇θL(θt−1)(不包含权重衰减项)。 |
优点: 权重衰减与自适应学习率解耦, 通常比Adam泛化更好。 |
自适应优化, 权重衰减。 将权重衰减从损失函数中分离,直接应用于参数更新,避免与自适应学习率耦合。 |
场景: 训练大型模型如Transformer, 需要权重衰减正则化。 |
θ: 参数。 |
加法项: 更新中直接加 λθ。 |
描述为“在Adam更新公式中,额外添加一个权重衰减项,直接作用于参数,而不是通过损失函数”。 |
1. 计算梯度 gt(不包含权重衰减)。 |
“解耦正则化”流: 在AdamW中,权重衰减流 λθ直接与自适应更新流 αm^t/(v^t+ϵ)相加。这与传统Adam(权重衰减通过损失函数影响梯度)不同,避免了权重衰减与自适应学习率之间的耦合,使得正则化效果更稳定,模型泛化更好。 |
与Adam类似,但更新步骤中多了一项权重衰减。权重衰减项可以本地计算,无需额外通信。在多GPU数据并行中,每个GPU独立计算权重衰减项并更新本地参数副本。 |
Adam, 权重衰减, L2正则化。 |
|
AI-A0-0202 |
优化算法 |
学习率调度 |
学习率在训练过程中按余弦函数从初始值衰减到最小值。 |
余弦退火 (Cosine Annealing) |
1. 学习率公式: ηt=ηmin+21(ηmax−ηmin)(1+cos(TmaxTcurπ)),其中 Tcur是当前步数,Tmax是总步数(或周期长度)。 |
特点: 平滑下降, 避免学习率突变, 有助于模型收敛到更优解。 |
学习率调度, 余弦函数。 使用余弦函数平滑调整学习率。 |
场景: 深度学习训练, 如图像分类、自然语言处理。 |
ηt: 当前学习率。 |
余弦函数: cos(πTcur/Tmax)。 |
描述为“学习率按余弦函数从最大值平滑衰减到最小值”。 |
1. 设置最大学习率 ηmax、最小学习率 ηmin、总步数 Tmax。 |
“余弦衰减”流: 学习率流 ηt随时间 t按余弦曲线从 ηmax平滑下降到 ηmin。这种平滑下降避免了阶梯式下降的突变,允许模型在初期以较大学习率快速收敛,后期以较小学习率精细调整,有助于找到更平坦的最小值。 |
学习率调度器在训练循环中每一步更新学习率。在多GPU训练中,通常由主进程计算学习率并广播,或每个进程独立计算相同值。 |
带热重启的余弦退火, 学习率调度。 |
|
AI-A0-0203 |
优化算法 |
学习率调度 |
学习率在指定步数或epoch处乘以一个衰减因子。 |
步长衰减 (Step Decay) |
1. 定义: 学习率在预定义的步数或epoch处衰减。例如,每 s步将学习率乘以 γ(如0.1)。 |
特点: 简单, 常用, 但衰减可能过于激进。 |
学习率调度, 指数衰减。 按固定步长降低学习率。 |
场景: 各种深度学习任务, 尤其是训练收敛后期。 |
ηt: 当前学习率。 |
指数衰减: ηt=η0γ⌊t/s⌋。 |
描述为“每经过固定的步数,学习率乘以一个小于1的衰减因子,呈阶梯式下降”。 |
1. 设置初始学习率 η0,衰减因子 γ,步长 s。 |
“阶梯下降”流: 学习率流 ηt在大多数时间保持恒定,每经过 s步就突然下降为原来的 γ倍。这种离散的下降允许模型在某个学习率下稳定训练一段时间,然后进入更精细的调整阶段。 |
实现简单,只需在训练循环中检查当前步数是否达到衰减点。在多GPU中,学习率值需要同步。 |
指数衰减, 学习率调度。 |
|
AI-A0-0204 |
训练技巧 |
权重初始化 |
根据输入维度调整初始化方差,保持前向传播中激活的方差不变。 |
Xavier初始化 (Glorot初始化) |
1. 均匀分布: W∼U[−nin+nout6,nin+nout6],其中 nin和 nout是输入和输出维度。 |
适用: 使用sigmoid、tanh等饱和激活函数的网络。 |
权重初始化, 方差缩放。 根据输入输出维度调整初始化范围。 |
场景: 全连接层, 卷积层(需调整维度计算), 使用sigmoid/tanh的网络。 |
W: 权重矩阵,形状 (nout,nin)。 |
均匀分布: 边界由 6/(nin+nout)决定。 |
描述为“权重从均匀或正态分布中初始化,其方差与输入和输出维度的和成反比”。 |
1. 计算缩放因子 scale=6/(nin+nout)(均匀分布)或 std=2/(nin+nout)(正态分布)。 |
“方差均衡”流: Xavier初始化确保权重矩阵 W的初始化方差与输入维度 nin和输出维度 nout相关,使得前向传播中激活的方差和反向传播中梯度的方差在各层之间大致保持稳定,避免梯度消失或爆炸。 |
初始化在训练开始前执行一次。在多GPU上,每个GPU独立初始化相同的权重(如果使用相同随机种子),或按模型并行分区初始化。 |
Kaiming初始化, 权重初始化。 |
|
AI-A0-0205 |
训练技巧 |
权重初始化 |
针对ReLU及其变体设计,保持前向传播中激活的方差不变。 |
Kaiming初始化 (He初始化) |
1. 正态分布: W∼N(0,nin2),其中 nin是输入维度。 |
适用: 使用ReLU、LeakyReLU等非饱和激活函数的网络。 |
权重初始化, 方差缩放。 针对ReLU族激活函数调整初始化方差。 |
场景: 使用ReLU的深度神经网络, 如ResNet、Transformer(FFN中的ReLU/GELU)。 |
W: 权重矩阵,形状 (nout,nin)。 |
方差: Var(W)=(1+a2)nin2,对于ReLU a=0,故为 nin2。 |
描述为“针对ReLU激活函数,权重初始化方差与输入维度成反比,并考虑激活函数的稀疏性”。 |
1. 确定激活函数参数 a(ReLU为0,LeakyReLU为负斜率)。 |
“ReLU方差校正”流: Kaiming初始化考虑了ReLU激活函数会将一半的激活置零,导致方差减半。因此,初始化时将权重方差放大一倍(nin2对比 Xavier 的 nin+nout2),以补偿这种稀疏性,确保各层激活方差稳定。 |
同Xavier初始化,在训练前执行。对于Transformer,FFN层的权重通常使用Kaiming初始化。 |
Xavier初始化, ReLU, 权重初始化。 |
|
AI-A0-0206 |
训练技巧 |
梯度裁剪 |
限制梯度范数,防止梯度爆炸。 |
梯度裁剪 (Gradient Clipping) |
1. 计算梯度范数: g=∇θL,总梯度范数 $ |
g |
_2 = \sqrt{\sum_i g_i^2}。<br>∗∗2.裁剪:∗∗如果 |
g |
_2 > threshold,则g = g \cdot \frac{threshold}{ |
g |
|||||
|
AI-A0-0207 |
训练技巧 |
正则化 |
在训练过程中,随机将一部分神经元的输出置零,防止过拟合。 |
Dropout |
1. 训练阶段: 对于每一层,每个神经元以概率 p(dropout率)被置零,否则其输出乘以 1/(1−p)(缩放)。 |
作用: 防止过拟合, 提高模型泛化能力, 相当于模型平均。 |
正则化, 模型平均。 通过随机丢弃神经元,强制网络不依赖特定神经元,提高鲁棒性。 |
场景: 全连接层, 卷积层, 注意力层(如Transformer中的dropout)。 |
x: 输入向量或矩阵。 |
随机: 伯努利分布。 |
描述为“在训练时,随机将一部分神经元的输出置零,其余神经元按比例放大,以保持期望不变;测试时直接使用所有神经元”。 |
训练时: |
“随机子网络”流: 在每次前向传播中,Dropout随机选择神经元子集构成一个“子网络”。信息流只能通过未被丢弃的神经元流动。这迫使网络学习冗余表示,不依赖于任何单个神经元。缩放操作确保信息流的总体强度在训练和测试间一致。 |
Dropout操作是逐元素乘法,可并行。掩码生成是随机的,但可以同步随机种子以确保多GPU一致性。在Transformer中,dropout常用于注意力权重和FFN激活后。 |
正则化, 模型平均。 |
|
AI-A0-0208 |
训练技巧 |
正则化 |
在标签分布中引入噪声,将硬标签(one-hot)转换为软标签,防止模型过度自信。 |
标签平滑 (Label Smoothing) |
1. 硬标签: 对于真实类别 y,one-hot向量 q满足 qy=1,其他为0。 |
效果: 防止模型对正确类别过度自信, 提高泛化能力, 减轻过拟合。 |
正则化, 校准。 通过软化标签分布,鼓励模型保留不确定性。 |
场景: 分类任务, 尤其是大规模分类(如ImageNet)。 |
q: 原始one-hot标签向量。 |
凸组合: (1−ϵ)q+ϵu。 |
描述为“将真实标签的1减去一个小量,并将这个小量均匀分配到其他类别上,得到软标签”。 |
1. 给定真实类别 y,创建one-hot向量 q。 |
“标签软化”流: 硬标签流(one-hot)包含绝对确定性,可能促使模型过度拟合。标签平滑将硬标签流与均匀噪声流混合,产生一个较软的标签流。这个软标签流鼓励模型对正确类别的预测概率接近 1−ϵ,同时对其他类别赋予小的概率 ϵ/K,从而保留一定程度的不确定性,提高泛化。 |
标签平滑在数据加载或损失计算时进行,计算简单。在多GPU数据并行中,每个GPU独立对本地数据的标签进行平滑。 |
交叉熵损失, 正则化。 |
|
AI-A0-0209 |
模型架构 |
注意力机制 |
通过线性投影将输入序列映射为查询、键、值,然后计算注意力权重和输出。 |
缩放点积注意力 (Scaled Dot-Product Attention) |
1. 线性投影: Q=XWQ, K=XWK, V=XWV,其中 WQ,WK,WV是可学习权重矩阵。 |
特点: 计算高效, 可并行, 是Transformer的核心组件。 |
注意力机制, 点积。 通过点积计算相似度,缩放后归一化,加权求和值。 |
场景: Transformer的自注意力和交叉注意力。 |
X: 输入序列,形状 (L,dmodel)。 |
点积: QKT。 |
描述为“将输入投影为查询、键、值,计算查询和键的点积并缩放,然后通过softmax得到注意力权重,最后对值加权求和”。 |
1. 计算投影:Q=XWQ, K=XWK, V=XWV。 |
“信息检索”流: 输入 X通过三个不同的线性变换流生成查询流 Q、键流 K和值流 V。查询流和键流通过点积交互,产生相似度流 S,经缩放和softmax转化为注意力权重流 A。权重流 A对值流 V进行加权求和,生成输出流 O,其中每个位置是值流的加权组合。 |
注意力计算可以高度并行。矩阵乘法 QKT复杂度 O(L2dk)。在多GPU上,可以通过张量并行将注意力头分配到不同GPU,或通过序列并行将序列分块。 |
多头注意力, 自注意力。 |
|
AI-A0-0210 |
模型架构 |
注意力机制 |
将注意力计算拆分为多个头,每个头学习不同的表示子空间,然后拼接结果。 |
多头注意力 (Multi-Head Attention) |
1. 线性投影到多个头: 对于第 i个头,Qi=XWiQ, Ki=XWiK, Vi=XWiV,其中 WiQ∈Rdmodel×dk, WiK∈Rdmodel×dk, WiV∈Rdmodel×dv,且 dk=dv=dmodel/h,h是头数。 |
优点: 允许模型共同关注来自不同位置的不同表示子空间的信息, 增强表示能力。 |
注意力机制, 并行化。 通过多个注意力头并行计算,融合不同子空间信息。 |
场景: Transformer的自注意力和交叉注意力。 |
X: 输入,形状 (L,dmodel)。 |
并行: 多个头独立计算。 |
描述为“将输入投影到多个子空间,在每个子空间独立计算注意力,然后将所有结果拼接并投影回原始维度”。 |
**1. 对于每个头 i=1到 h: |
|
编号 |
类别 |
领域 |
模型配方 |
数学公式/定理/算法/模型/方法名称 |
数学公式/定理/算法/模型/方法的逐步思考推理过程及每一个步骤的数学方程式和参数选择/优化/迭代 |
精度/密度/误差/强度 |
底层规律/理论 |
典型应用场景和特征 |
变量/常量/参数列表及说明 |
数学特征 |
语言特征 |
时序和交互流程的所有细节/分步骤时序情况及数学方程式 |
流动模型和流向方法的数学描述 |
多GPU芯片执行情况和方程式列表 |
关联知识和算法 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
AI-A0-0211 |
模型架构 |
前馈网络 |
Transformer中每个位置独立应用的两层全连接网络,带激活函数。 |
位置式前馈网络 (Position-wise Feed-Forward Network, FFN) |
1. 第一层线性变换: F1=ReLU(XW1+b1),其中 W1∈Rdmodel×dff,b1∈Rdff,dff是中间维度(通常 dff=4×dmodel)。 |
作用: 对每个位置的表示进行非线性变换, 增加模型容量。 |
前馈网络, 非线性变换。 每个位置独立应用相同的两层全连接网络,实现逐位置非线性变换。 |
场景: Transformer编码器和解码器层中, 位于自注意力层之后。 |
X: 输入,形状 (L,dmodel)。 |
线性变换: 矩阵乘法加偏置。 |
描述为“一个两层的全连接网络,对输入序列的每个位置独立进行变换,第一层进行线性变换并应用ReLU激活,第二层进行线性变换”。 |
1. 输入 X形状 (L,dmodel)。 |
“逐位置非线性流”: 输入流 X的每个位置向量独立地流经第一层线性变换,被映射到高维空间(dff),然后经过ReLU激活流引入非线性,再通过第二层线性变换流映射回原始维度 dmodel。这个流在每个位置上是独立的,但参数共享。 |
FFN计算可以完全并行于序列长度 L。矩阵乘法 XW1和 HW2是密集计算,适合GPU加速。在多GPU数据并行中,FFN层参数在所有GPU上复制,输入 X被分割。在模型并行中,W1和 W2可以按行或列分割。 |
自注意力, 残差连接, 层归一化。 |
|
AI-A0-0212 |
位置编码 |
序列建模 |
通过正弦和余弦函数为序列中每个位置生成固定编码,注入位置信息。 |
正弦位置编码 (Sinusoidal Positional Encoding) |
1. 定义: 对于位置 pos和维度 i(i为偶数或奇数),编码为: |
特点: 固定, 非学习, 可泛化到任意长度, 但无法适应训练数据。 |
位置编码, 三角函数。 使用正弦和余弦函数生成位置编码,使模型能够感知序列中token的顺序。 |
场景: 原始Transformer, 需要位置信息的序列模型。 |
pos: 位置索引,从0到 L−1。 |
三角函数: sin和 cos。 |
描述为“使用正弦和余弦函数为每个位置生成一个固定向量,其频率随维度增加而降低,然后与词嵌入相加”。 |
1. 对于每个位置 pos=0,1,...,L−1: |
“位置信号注入”流: 位置编码流 PE是一个固定的、预先计算好的矩阵,其中每个位置对应一个独特的 dmodel维向量。这个向量通过正弦和余弦函数生成,确保不同位置和不同维度有不同的模式。该流与词嵌入流 X相加,将绝对位置信息注入到输入表示中,使模型能够区分序列顺序。 |
位置编码可以预先计算并存储,或在前向传播时实时计算。计算涉及三角函数,但可以向量化。在多GPU中,每个GPU获得序列的一部分,需要知道其全局位置以计算或获取对应的位置编码。 |
学习的位置嵌入, 相对位置编码。 |
|
AI-A0-0213 |
位置编码 |
序列建模 |
将位置编码作为可学习参数,随模型一起训练。 |
学习的位置嵌入 (Learned Positional Embedding) |
1. 定义: 创建一个可学习的嵌入矩阵 P∈RLmax×dmodel,其中 Lmax是预设的最大序列长度。 |
特点: 可学习, 能适应训练数据, 但无法处理超过 Lmax的序列。 |
位置编码, 可学习参数。 将位置编码视为可训练的参数,通过梯度下降学习。 |
场景: BERT、GPT等模型, 序列长度固定或有限。 |
P: 位置嵌入矩阵,可学习参数,形状 (Lmax,dmodel)。 |
嵌入查找: 根据位置索引查找向量。 |
描述为“创建一个可学习的位置嵌入矩阵,每个位置对应一个向量,训练时与词嵌入相加”。 |
1. 初始化位置嵌入矩阵 P(随机或零)。 |
“可学习位置流”: 位置嵌入流 P是一个可学习的参数流,其每一行对应一个绝对位置。在前向流中,根据token的位置索引,从 P中提取对应的位置向量流,然后与词嵌入流 X相加。这个流通过训练可以学习到数据中位置相关的模式,但仅限于训练中见过的位置(不超过 Lmax)。 |
学习的位置嵌入作为模型参数的一部分。在数据并行中,参数 P在所有GPU上复制。在模型并行中,P可以按维度 dmodel分割。 |
正弦位置编码, 相对位置编码。 |
|
AI-A0-0214 |
位置编码 |
序列建模 |
通过旋转位置编码,将绝对位置信息融入注意力计算中的查询和键。 |
旋转位置编码 (Rotary Position Embedding, RoPE) |
1. 将位置信息融入查询和键: 对于位置 m的查询向量 qm和位置 n的键向量 kn,通过旋转矩阵 RΘ,m和 RΘ,n进行变换:q~m=RΘ,mqm, k~n=RΘ,nkn,其中 RΘ,m是一个旋转矩阵,Θ是预设的频率参数。 |
优点: 保持相对位置关系, 可外推, 在长序列上表现好。 |
位置编码, 相对位置, 复数旋转。 通过旋转操作将绝对位置信息注入查询和键,使注意力分数仅依赖于相对位置。 |
场景: LLaMA、GPT-NeoX等现代大语言模型。 |
qm,kn: 位置 m和 n的查询和键向量,维度 d。 |
旋转矩阵: 块对角矩阵,每个块是2D旋转矩阵。 |
描述为“将查询和键向量视为复数,根据其位置进行旋转,使得点积注意力分数仅依赖于相对位置”。 |
1. 将查询 q和键 k重塑为复数形式:将每两个连续维度视为一个复数(实部和虚部)。 |
“旋转流”: 查询流 qm和键流 kn根据其绝对位置 m和 n分别进行旋转操作流。旋转角度由预设的频率 θi和位置决定。旋转后的查询 q~m和键 k~n的点积结果只依赖于相对位置 m−n,因为旋转操作在复数乘法中表现为相位差。这使得模型能够自然地捕捉相对位置信息,并具有良好的外推性。 |
RoPE在计算注意力之前应用于查询和键。计算可以向量化。在多GPU中,每个GPU持有序列的一部分,需要知道其全局位置以进行旋转。旋转操作是逐元素的,可以并行计算。 |
相对位置编码, 注意力机制。 |
|
AI-A0-0215 |
归一化技术 |
层归一化 |
层归一化的变体,仅对输入进行缩放,不进行平移,且使用RMS(均方根)进行归一化。 |
RMSNorm (Root Mean Square Layer Normalization) |
1. 计算RMS: 对于输入 x∈Rd,RMS(x)=d1∑i=1dxi2。 |
特点: 去除了均值中心化, 仅使用RMS进行缩放, 计算更简单, 在有些模型中表现与LayerNorm相当。 |
归一化, 缩放。 使用均方根进行归一化,仅学习缩放参数,简化计算。 |
场景: LLaMA、T5等模型, 作为LayerNorm的替代。 |
x: 输入向量,维度 d。 |
均方根: 平方和的平均再开方。 |
描述为“计算输入向量的均方根,然后用它来缩放输入,最后乘以可学习的缩放参数”。 |
1. 计算 RMS=d1∑i=1dxi2+ϵ。 |
“RMS缩放”流: 输入流 x首先计算其均方根流 RMS(x),该流衡量了输入的总体幅度。然后,输入流被 RMS(x)缩放,得到一个单位RMS的流 x^。最后,通过可学习的缩放参数流 g对每个维度进行重新缩放,恢复模型的表达能力。与LayerNorm相比,它省略了减去均值的步骤,假设零均值已由前一层的偏置项处理。 |
RMSNorm计算比LayerNorm少一步均值计算,因此略高效。同样可并行计算。在多GPU中,每个样本独立计算RMS,然后进行缩放。 |
LayerNorm, 归一化。 |
|
AI-A0-0216 |
激活函数 |
激活函数 |
一种门控激活函数,结合了Swish(SiLU)和GLU(Gated Linear Unit)的思想。 |
SwiGLU |
1. 定义: SwiGLU(x,W,V,b,c)=Swish(xW+b)⊙(xV+c),其中 Swish(x)=xσ(x),σ是sigmoid函数,⊙是逐元素乘法。 |
优点: 比ReLU或GELU表现更好, 在PaLM等大模型中采用。 |
激活函数, 门控机制。 通过Swish激活的门控线性单元,增强非线性表达能力。 |
场景: Transformer的FFN层, 替代标准ReLU/GELU FFN。 |
x: 输入,形状 (L,dmodel)。 |
门控: 逐元素乘法。 |
描述为“对输入进行两个不同的线性变换,其中一个变换的结果经过Swish激活,然后与另一个变换的结果逐元素相乘,最后再经过一个线性变换”。 |
1. 计算 A=Swish(xW1+b)=(xW1+b)σ(xW1+b)。 |
“双路门控”流: 输入流 x被复制为两路。一路流经线性变换 W1和Swish激活,产生门控信号流 A。另一路流经线性变换 V1,产生值流 B。两路流通过逐元素乘法融合,其中Swish激活的门控信号 A调制值流 B。融合后的流 H再经过线性变换 W2输出。这种门控机制允许模型选择性地传递信息。 |
SwiGLU FFN比标准FFN多一个线性投影(V1),因此计算量和参数量更大。计算可以并行:xW1和 xV1可以同时计算。在多GPU中,线性变换可以按模型并行方式分割。 |
FFN, GELU, GLU。 |
|
AI-A0-0217 |
训练技巧 |
梯度处理 |
在多个小批量上累积梯度,然后一次性更新参数,模拟大批量训练。 |
梯度累积 (Gradient Accumulation) |
1. 过程: 对于 N个连续的小批量(micro-batch),每次前向传播后计算梯度,但不立即更新参数,而是将梯度累加到累积变量中。 |
目的: 在内存有限时模拟大批量训练, 稳定训练, 允许使用更大的有效批量大小。 |
优化技巧, 内存效率。 通过多次前向-反向传播累积梯度,实现更大的有效批量大小。 |
场景: 当GPU内存不足以容纳大批量时, 训练大模型。 |
gi: 第 i个小批量的梯度。 |
累加: G=∑i=1Ngi。 |
描述为“在多个小批量上重复前向和反向传播,累积梯度但不更新参数,累积一定步数后,用累积梯度(或平均梯度)更新一次参数”。 |
1. 初始化累积梯度 G=0,计数器 count=0。 |
“梯度缓冲”流: 在标准训练中,梯度流 gi产生后立即用于更新参数流 θ。在梯度累积中,梯度流被暂时存储到累积缓冲区 G中。经过 N个小批量,N个梯度流汇合成一个累积梯度流 G。然后这个累积流被用于更新参数流,模拟了一个批量大小为 N×micro-batch size的更新。这允许在有限内存下使用更大的有效批量。 |
梯度累积在单个GPU或数据并行中均可使用。每个GPU独立计算本地梯度并累积。在数据并行中,如果使用梯度平均,需要在累积 N步后对所有GPU的累积梯度进行AllReduce,然后更新参数。 |
批量大小, 优化器。 |
|
AI-A0-0218 |
训练技巧 |
混合精度 |
使用半精度(FP16)进行前向和反向传播,同时保留单精度(FP32)主权重副本用于更新,以加速训练并减少内存占用。 |
混合精度训练 (Mixed Precision Training) |
1. 维护FP32主权重: θfp32。 |
优点: 加速计算, 减少内存占用, 保持数值稳定性。 |
数值计算, 精度。 利用FP16加速计算,用FP32保持数值范围,通过梯度缩放防止下溢。 |
场景: 训练大型神经网络, 如Transformer, 需要加速和节省内存。 |
θfp32: FP32主权重。 |
类型转换: FP32 ↔FP16。 |
描述为“使用半精度权重和激活进行前向和反向传播以加速,但保留单精度主权重副本用于更新,并通过梯度缩放防止小梯度下溢”。 |
1. 初始化FP32主权重 θfp32。 |
“精度混合流”: 权重流 θfp32存储在FP32中以保证精度。在前向流中,权重被转换为FP16流 θfp16,与FP16输入流进行高速计算。损失流 Lfp16被放大 S倍以防止梯度下溢。反向梯度流 gfp16计算后,被缩小 S倍并转换为FP32流 gfp32。最后,优化器使用FP32梯度流更新FP32主权重流。这样既利用了FP16的计算速度,又保持了FP32的数值稳定性。 |
混合精度训练需要GPU支持FP16计算(如Tensor Cores)。在数据并行中,每个GPU进行本地FP16前向/反向传播,梯度在FP32下进行AllReduce,然后更新本地FP32主权重。 |
FP16, BF16, 梯度缩放。 |
|
AI-A0-0219 |
训练技巧 |
混合精度 |
一种半精度浮点数格式,比FP16具有更大的动态范围,更适合深度学习训练。 |
BFloat16 (Brain Floating Point 16) |
1. 格式: 1位符号位,8位指数位,7位尾数位(而FP16是1位符号,5位指数,10位尾数)。 |
优点: 动态范围大, 与FP32指数位相同, 训练更稳定, 简化混合精度训练流程。 |
数值格式, 浮点数。 提供与FP32相同的指数范围,但使用16位存储,平衡范围和精度。 |
场景: 训练大型模型, 如Transformer, 在TPU和现代GPU上使用。 |
符号位: 1 bit。 |
指数范围: 与FP32相同(2−126到 2127)。 |
描述为“一种16位浮点数格式,具有与32位浮点数相同的指数范围,但尾数精度较低,适用于深度学习训练”。 |
1. 将权重、激活、梯度存储为BFloat16格式。 |
“大范围半精度”流: BFloat16数据流具有与FP32相同的指数范围,因此可以表示非常小和非常大的数,避免了FP16中容易出现的梯度下溢(值太小变为0)和溢出(值太大变为inf)问题。这使得BFloat16流可以直接用于训练,无需复杂的梯度缩放,简化了混合精度训练流程。计算流在BFloat16下进行,速度与FP16相当,但稳定性更好。 |
BFloat16得到现代AI加速器(如TPU、NVIDIA Ampere GPU)原生支持。在混合精度训练中,可以使用BFloat16代替FP16,简化流程。在多GPU中,通信可以使用BFloat16减少带宽。 |
FP16, FP32, 混合精度训练。 |
|
AI-A0-0220 |
解码策略 |
文本生成 |
从模型输出的概率分布中随机采样下一个token,采样概率与softmax后的概率成正比。 |
随机采样 (Random Sampling) |
1. 模型输出: 给定上下文,模型输出下一个token的logits $z \in \mathbb{R}^{ |
V |
}。<br>∗∗2.计算概率:∗∗p = \text{softmax}(z),得到概率分布。<br>∗∗3.采样:∗∗根据概率分布p随机采样一个tokenw,即w \sim \text{Categorical}(p)。<br>∗∗4.将w$ 作为下一个token,并添加到上下文中,重复过程。 |
特点: 生成结果多样, 但可能不连贯或不合逻辑。 |
采样, 概率分布。 根据模型输出的概率分布随机选择下一个token,引入随机性。 |
场景: 创造性文本生成, 如故事、诗歌, 需要多样性。 |
z: logits向量,长度 $ |
V |
(词汇表大小)。<br>∗∗p:∗∗概率分布,p_i = \frac{e^{z_i}}{\sum_j e^{z_j}}。<br>∗∗w$:** 采样的token索引。 |
softmax: 将logits转换为概率。 |
描述为“将模型输出的logits通过softmax转换为概率分布,然后根据该分布随机采样下一个token”。 |
|
AI-A0-0221 |
解码策略 |
文本生成 |
在采样前,通过温度参数调整概率分布的平滑度,控制生成的随机性。 |
温度采样 (Temperature Sampling) |
1. 模型输出logits z。 |
作用: 控制生成多样性, T越小生成越确定, T越大生成越随机。 |
采样, 温度缩放。 通过温度参数缩放logits,改变softmax输出的概率分布形状。 |
场景: 与随机采样结合, 控制文本生成的创造性和连贯性。 |
z: logits向量。 |
缩放: z′=z/T。 |
描述为“将模型输出的logits除以一个温度参数,然后再进行softmax和采样,温度参数控制分布的平滑度”。 |
1. 给定上下文,模型输出logits z。 |
“温度调节流”: logits流 z经过温度缩放流 T,产生缩放后的logits流 z′=z/T。当 T较小时,z′的数值范围相对扩大,经过softmax后,概率流 p会变得更加尖锐(高概率更高,低概率更低),采样流更倾向于高概率token,生成更确定。当 T较大时,z′数值范围缩小,概率流 p更平滑,采样流更随机,生成更多样。 |
温度采样在softmax之前进行简单的逐元素除法,计算轻量。在批量生成中,可以对所有样本应用相同温度,或每个样本不同。 |
随机采样, softmax。 |
|
AI-A0-0222 |
解码策略 |
文本生成 |
从概率最高的k个token中随机采样,限制采样空间,提高生成质量。 |
Top-k采样 |
1. 模型输出logits z,计算概率 p=softmax(z)。 |
优点: 避免从低概率token中采样, 提高生成连贯性。 |
采样, 截断。 将采样空间限制在概率最高的k个token内,避免低概率token。 |
场景: 文本生成, 需要平衡多样性和质量。 |
z: logits向量。 |
选择: 取top-k个最大概率。 |
描述为“从模型输出的概率分布中选出概率最高的k个token,将其概率重新归一化,然后从这k个token中采样”。 |
1. 计算 p=softmax(z)。 |
“截断采样流”: 原始概率流 p包含整个词汇表的概率。Top-k采样流首先过滤掉概率较低的token,只保留概率最高的k个token,形成截断的概率流。然后对这个截断流进行重新归一化,使得剩余token的概率和为1,产生新的分布流 p′。采样流从 p′中抽取,确保不会采样到低概率的无关token,提高了生成质量。 |
Top-k采样需要找到top-k个最大概率,可以通过快速选择算法或排序部分元素实现。在批量生成中,可以对每个样本独立进行。 |
Top-p采样, 随机采样。 |
|
AI-A0-0223 |
解码策略 |
文本生成 |
从累积概率超过阈值p的最小token集合中采样,动态调整候选集大小。 |
Top-p采样 (Nucleus Sampling) |
1. 模型输出logits z,计算概率 p=softmax(z)。 |
|
编号 |
类别 |
领域 |
模型配方 |
数学公式/定理/算法/模型/方法名称 |
数学公式/定理/算法/模型/方法的逐步思考推理过程及每一个步骤的数学方程式和参数选择/优化/迭代 |
精度/密度/误差/强度 |
底层规律/理论 |
典型应用场景和特征 |
变量/常量/参数列表及说明 |
数学特征 |
语言特征 |
时序和交互流程的所有细节/分步骤时序情况及数学方程式 |
流动模型和流向方法的数学描述 |
多GPU芯片执行情况和方程式列表 |
关联知识和算法 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
AI-A0-0223 |
解码策略 |
文本生成 |
从累积概率超过阈值p的最小token集合中采样,动态调整候选集大小。 |
核采样 (Top-p采样, Nucleus Sampling) |
1. 计算概率分布: 给定语言模型输出的logits,通过softmax得到概率分布 P(x)。 |
优点: 动态调整候选集大小, 避免在概率分布平坦时采样到低概率token, 或在尖锐时过度限制。 |
概率采样, 动态阈值。 通过累积概率阈值动态选择候选集,平衡多样性和质量。 |
场景: 文本生成, 如故事创作、对话生成, 需要多样性和连贯性。 |
P(x): 原始概率分布,x∈V(词表)。 |
排序: 概率降序排列。 |
描述为“将概率从大到小排序,选择累积概率达到阈值p的最小token集合,然后在这个集合内重新归一化概率并采样”。 |
1. 输入:概率分布 P(x),阈值 p。 |
“概率累积流”: 概率流 P(x)被排序为降序流 p(i)。累积流 C(k)逐步累加,直到达到阈值 p。此时,前 k个token形成核心流(nucleus),其余token被截断。核心流内的概率被重新归一化,形成新的概率流 P′,采样流从 P′中产生输出token。 |
核采样在单个GPU上执行,涉及排序和累积操作,计算复杂度 O(VlogV)。在分布式生成中,每个GPU可以独立采样,但需要同步随机种子以确保一致性(如果要求)。 |
Top-k采样, 温度采样, 束搜索。 |
|
AI-A0-0224 |
解码策略 |
文本生成 |
从概率最高的k个token中采样,候选集大小固定。 |
Top-k采样 |
1. 计算概率分布: P(x)通过softmax得到。 |
优点: 简单, 避免采样到低概率token。 |
概率采样, 固定候选集。 通过固定大小的候选集限制采样范围,提高生成质量。 |
场景: 文本生成, 需要限制采样空间时。 |
P(x): 原始概率分布。 |
Top-k选择: 选择概率最大的k个元素。 |
描述为“选择概率最高的k个token,然后在这个集合内重新归一化概率并采样”。 |
**1. 输入:概率分布 P(x),参数 k。 |
S |
=k} \sum{x \in S} P(x)。<br>3.计算候选集总概率:Z = \sum{x \in V{\text{top-k}}} P(x)。<br>4.重新归一化:对于每个x \in V{\text{top-k}},P'(x) = P(x) / Z。<br>5.根据P'$ 采样一个token输出。** |
“Top-k截断流”: 概率流 P(x)经过排序,保留前 k个最大的概率流,其余被截断。然后对保留的概率流进行重新归一化,形成新的概率流 P′,采样流从 P′中产生输出。 |
|
AI-A0-0225 |
解码策略 |
文本生成 |
通过温度参数调整概率分布的平滑度,控制生成多样性。 |
温度采样 (Temperature Sampling) |
1. 计算logits: 语言模型输出logits zi对于每个token i。 |
温度效应: T=1保持原分布;T>1平滑分布(增加多样性);T<1锐化分布(减少多样性,趋向贪婪)。 |
概率变换, 平滑控制。 通过温度参数控制概率分布的熵,调节生成多样性。 |
场景: 文本生成, 需要控制生成结果的随机性时。 |
zi: logits,未归一化的分数。 |
缩放: zi′=zi/T。 |
描述为“将logits除以温度参数后再进行softmax,温度越高概率分布越平滑,采样越多样;温度越低分布越尖锐,采样越确定”。 |
1. 输入:logits向量 z,温度 T。 |
“温度调节流”: logits流 z被温度参数 T缩放,得到 z′。然后通过softmax流转换为概率流 P。温度 T作为一个控制阀:当 T大时,缩放后的 logits 流 z′差异变小,softmax 流输出更平滑的概率流,采样流更随机;当 T小时,z′差异放大,概率流更尖锐,采样流更确定。 |
温度采样计算简单,只需除法和softmax。在分布式生成中,每个GPU独立应用温度并采样。 |
核采样, Top-k采样, 贪婪解码。 |
|
AI-A0-0226 |
解码策略 |
文本生成 |
在每一步选择概率最高的token,确定性解码。 |
贪婪解码 (Greedy Decoding) |
1. 计算概率分布: P(x)通过softmax得到。 |
优点: 简单, 快速, 确定性。 |
确定性解码, 最大似然。 每一步选择当前最可能的token,但不保证全局最优序列。 |
场景: 需要快速、确定性生成的场景, 如机器翻译、摘要。 |
P(x): 概率分布。 |
argmax: x∗=argmaxP(x)。 |
描述为“每一步都选择概率最高的token作为输出”。 |
1. 输入:概率分布 P(x)。 |
“贪婪选择流”: 概率流 P(x)直接流向argmax操作,输出最大概率token流。没有随机性,每一步都是确定性的选择。 |
贪婪解码只需argmax操作,计算简单。在分布式生成中,每个GPU可以独立生成,但需要同步以确保一致性(如果使用束搜索则需通信)。 |
束搜索, 采样方法。 |
|
AI-A0-0227 |
解码策略 |
文本生成 |
维护多个候选序列(束),每一步扩展所有候选序列,保留总体概率最高的k个序列。 |
束搜索 (Beam Search) |
1. 初始化: 包含一个空序列,分数为0。 |
优点: 比贪婪解码更可能找到全局最优序列。 |
启发式搜索, 广度优先剪枝。 维护固定大小的候选集,近似全局最优序列。 |
场景: 序列生成任务, 如机器翻译、文本摘要, 需要高质量序列。 |
k: 束宽,候选序列数量。 |
累积对数概率: s=∑logP。 |
描述为“维护k个最有可能的候选序列,每一步扩展这些序列,然后从所有扩展序列中再选择k个分数最高的,直到生成结束”。 |
1. 初始化束 B=[(空序列,分数=0)]。 |
“束流”: 初始时,一个空序列流开始。每一步,每个序列流扩展为多个子流(每个token一个),形成扩展流集合。然后通过排序和选择,保留分数最高的k个流,其余被剪枝。这些流继续迭代,直到结束。束流通过并行探索多条路径,增加了找到高质量序列的可能性。 |
束搜索需要维护k个候选序列,每个序列需要独立进行前向传播,计算量大。在分布式生成中,每个GPU可以处理部分序列,但需要通信来同步分数和选择全局top-k。 |
贪婪解码, 长度惩罚, 重复惩罚。 |
|
AI-A0-0228 |
解码策略 |
文本生成 |
在束搜索中引入长度归一化,避免偏向短序列。 |
长度惩罚 (Length Penalty) |
1. 序列分数: 原始分数为对数概率之和 s=∑i=1LlogP(xi∣x<i)。 |
目的: 纠正束搜索倾向于短序列的偏差(因为对数概率为负,越长分数越低)。 |
分数归一化, 偏差校正。 通过对数概率之和除以长度相关因子,使不同长度序列可比。 |
场景: 束搜索中, 需要公平比较不同长度序列时。 |
s: 原始分数,对数概率之和。 |
归一化: snorm=s/(L+c)α。 |
描述为“将序列的对数概率之和除以长度的幂次方,以消除长度偏差,使得束搜索能够公平比较不同长度的序列”。 |
在束搜索的每一步,当计算新序列分数时: |
“长度归一化流”: 原始分数流 s与长度流 L结合,通过归一化函数 f(L)=(L+c)α进行缩放,得到归一化分数流 snorm。这个流使得长序列的分数不会被过度惩罚,从而在束搜索中公平竞争。 |
长度惩罚在束搜索中简单应用,只需在计算分数时增加归一化步骤。在分布式束搜索中,每个GPU本地计算归一化分数,然后全局排序。 |
束搜索, 重复惩罚。 |
|
AI-A0-0229 |
解码策略 |
文本生成 |
在生成过程中惩罚重复的n-gram,避免重复文本。 |
重复惩罚 (Repetition Penalty) |
1. 识别重复: 对于已生成的序列,检测出现的n-gram(如unigram, bigram)。 |
目的: 减少生成文本中的重复短语。 |
概率调整, 重复抑制。 通过降低重复token的概率来避免生成重复内容。 |
场景: 文本生成, 特别是对话、故事生成, 容易产生重复时。 |
P(x): 原始概率分布。 |
概率缩放: P′(x)=P(x)/max(1,λ⋅count(gram))。 |
描述为“如果下一个token会导致重复的n-gram,则将其概率除以一个惩罚因子,从而降低重复的可能性”。 |
1. 输入:已生成序列 seq,当前步的概率分布 P(x),惩罚因子 λ,n-gram大小 n。 |
“重复抑制流”: 原始概率流 P(x)经过重复检测器,对于每个候选token x,检查其与历史流形成的n-gram是否重复。如果重复,则概率流被惩罚因子 λ缩放降低;否则保持不变。调整后的概率流 P′(x)被重新归一化,然后用于生成流。这抑制了重复流,促进多样性流。 |
重复惩罚需要在生成过程中维护n-gram计数,计算开销较小。在分布式生成中,每个GPU需要知道完整的历史序列,可能需要通信。 |
束搜索, 长度惩罚。 |
|
AI-A0-0230 |
解码策略 |
文本生成 |
在束搜索中,对已生成的序列进行分组,避免多样性不足。 |
束搜索分组 (Beam Search with Grouping) |
1. 分组: 将束中的序列根据某些特征(如前缀、语义)分成若干组。 |
目的: 增加束搜索的多样性, 避免所有序列都相似。 |
多样性促进, 分组平衡。 通过分组确保候选集覆盖不同区域,提高多样性。 |
场景: 需要多样生成的束搜索, 如对话生成、 故事生成。 |
k: 束宽。 |
分组: 将序列划分为不相交的子集。 |
描述为“将候选序列分组,从每组中选择最好的序列,确保最终束包含不同组的序列,以增加多样性”。 |
**1. 初始化束 B包含 k个序列(或空序列)。 |
B' |
< k$,则从剩余序列中补足分数最高的。 |
“分组选择流”: 候选序列流 C被分组函数分成多个子流。每个子流内,分数最高的序列流被选出,代表该组。这些代表流组成新的束流 B′。这样,束流包含了来自不同组的流,增加了多样性。 |
|
AI-A0-0231 |
解码策略 |
文本生成 |
在生成过程中,同时考虑模型概率和与之前生成的token的相似性,鼓励多样性。 |
对比搜索 (Contrastive Search) |
1. 候选生成: 在每一步,从模型概率分布中选择 top-k 候选token。 |
目的: 在保持生成质量的同时, 减少重复, 增加多样性。 |
多样性解码, 对比惩罚。 通过惩罚与上下文相似的token来鼓励多样性。 |
场景: 文本生成, 需要多样且连贯的文本。 |
P(x∣context): 模型给定上下文的概率。 |
加权和: s(x)=(1−α)⋅logP−α⋅max similarity。 |
描述为“从概率最高的k个候选token中,选择模型概率高且与已生成token相似度低的token,通过加权分数进行平衡”。 |
1. 输入:上下文 c,模型概率分布 P(x∣c),嵌入函数 f,参数 α, k。 |
“对比分数流”: 模型概率流 logP与相似度惩罚流 max similarity结合。对于每个候选token,其嵌入流 f(x)与历史token的嵌入流计算相似度,取最大值作为惩罚。总分数流 s(x)是概率流与惩罚流的加权差。选择流选取总分最高的token。这鼓励选择概率高但与历史不重复的token。 |
对比搜索需要计算每个候选token与历史token的相似度,计算开销随历史长度增加。嵌入向量 f(x)可以是预训练的token嵌入。在分布式生成中,每个GPU需要访问完整历史嵌入。 |
核采样, 重复惩罚。 |
|
AI-A0-0232 |
解码策略 |
文本生成 |
在生成过程中,同时考虑多个候选序列,通过比较选择最佳下一个token。 |
集束采样 (Beam Sampling) |
1. 维护束: 类似束搜索,维护 k个候选序列。 |
特点: 结合了束搜索的序列维护和采样的随机性, 增加多样性。 |
随机束搜索, 采样与选择结合。 通过采样扩展增加探索,通过分数选择保持质量。 |
场景: 文本生成, 需要多样性但又不失连贯性。 |
k: 束宽。 |
采样: 从 P(x)中随机采样。 |
描述为“维护k个候选序列,每一步对每个序列采样下一个token生成多个扩展序列,然后选择分数最高的k个序列继续”。 |
1. 初始化束 B包含 k个序列(如空序列)。 |
“采样-选择流”: 每个序列流通过采样产生多个分支流,每个分支流对应一个采样token。然后所有分支流根据分数排序,选择top-k流继续。这结合了随机探索和确定性选择。 |
集束采样需要为每个序列采样多个token,计算量较大。在分布式生成中,每个GPU可以独立处理部分序列,但需要通信进行全局选择。 |
束搜索, 核采样。 |
|
AI-A0-0233 |
解码策略 |
文本生成 |
在每一步,从模型概率分布中随机采样一个token,完全随机。 |
随机采样 (Random Sampling) |
1. 计算概率分布: P(x)通过softmax得到。 |
特点: 完全随机, 多样性最高, 但可能生成不连贯的文本。 |
概率采样, 完全随机。 根据概率分布随机选择下一个token。 |
场景: 需要高多样性的创意写作, 或与温度采样结合控制随机性。 |
P(x): 概率分布。 |
采样: x∼P(x)。 |
描述为“根据模型输出的概率分布随机选择一个token作为输出”。 |
1. 输入:概率分布 P(x)。 |
“随机采样流”: 概率流 P(x)直接作为采样分布,随机生成一个token流。没有确定性选择,完全随机。 |
随机采样只需从分布中采样,计算简单。在分布式生成中,每个GPU独立采样,但需要同步随机种子以确保一致性(如果要求)。 |
温度采样, 贪婪解码。 |
|
AI-A0-0234 |
解码策略 |
文本生成 |
在每一步,从模型概率分布中采样,但通过调整概率分布避免重复。 |
重复惩罚采样 (Repetition Penalty Sampling) |
1. 计算原始概率 P(x)。 |
目的: 减少重复token的出现。 |
概率调整, 重复抑制。 通过降低已出现token的概率来避免重复。 |
场景: 文本生成, 容易产生重复token时。 |
P(x): 原始概率分布。 |
概率缩放: P′(x)=P(x)/λ如果 x∈H。 |
描述为“降低已生成token的概率,然后重新归一化并采样,以减少重复”。 |
1. 输入:原始概率 P(x),历史token集合 H,惩罚因子 λ。 |
“重复抑制采样流”: 原始概率流 P(x)经过惩罚过滤器,历史token的概率流被缩小 λ倍。然后重新归一化流产生 P′′(x),采样流从 P′′中产生输出。这降低了重复token被选中的概率。 |
重复惩罚采样需要维护历史token集合,计算开销小。在分布式生成中,每个GPU需要知道历史token,可能需要通信。 |
核采样, 对比搜索。 |
|
AI-A0-0235 |
解码策略 |
文本生成 |
在每一步,从模型概率分布中采样,但通过调整概率分布鼓励多样性。 |
多样性促进采样 (Diversity-Promoting Sampling) |
1. 计算原始概率 P(x)。 |
效果: α=1为原始分布;α<1增加多样性;α>1减少多样性。 |
概率变换, 熵调整。 通过指数 α调整概率分布的熵,控制多样性。 |
场景: 文本生成, 需要控制多样性时。 |
P(x): 原始概率分布。 |
指数变换: P′(x)∝P(x)α。 |
描述为“将原始概率分布进行指数变换,指数小于1时平滑分布增加多样性,大于1时锐化分布减少多样性,然后采样”。 |
1. 输入:原始概率 P(x),参数 α。 |
“指数平滑流”: 原始概率流 P(x)经过指数变换 (⋅)α。当 α<1时,概率流被平滑,低概率token的相对概率提升,增加多样性流;当 α>1时,概率流被锐化,高概率token更突出,减少多样性流。然后归一化流产生 P′′(x),采样流从中选择。 |
多样性促进采样涉及指数运算和归一化,计算开销中等。在分布式生成中,每个GPU独立计算。 |
温度采样, 核采样。 |
|
AI-A0-0236 |
解码策略 |
文本生成 |
在每一步,从模型概率分布中采样,但通过调整概率分布避免生成特定token(如不良词汇)。 |
禁止token采样 (Forbidden Token Sampling) |
1. 计算原始概率 P(x)。 |
目的: 避免生成不希望出现的token, 如脏话、 敏感词等。 |
概率过滤, 内容控制。 通过将禁止token的概率置零来避免生成它们。 |
场景: 内容安全, 避免生成不良内容。 |
P(x): 原始概率分布。 |
概率置零: P′(x)=0for x∈F。 |
|
编号 |
类别 |
领域 |
模型配方 |
数学公式/定理/算法/模型/方法名称 |
数学公式/定理/算法/模型/方法的逐步思考推理过程及每一个步骤的数学方程式和参数选择/优化/迭代 |
精度/密度/误差/强度 |
底层规律/理论 |
典型应用场景和特征 |
变量/常量/参数列表及说明 |
数学特征 |
语言特征 |
时序和交互流程的所有细节/分步骤时序情况及数学方程式 |
流动模型和流向方法的数学描述 |
多GPU芯片执行情况和方程式列表 |
关联知识和算法 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
AI-A0-0223 |
解码策略 |
Token领域 |
从累积概率超过阈值p的最小token集合中采样,动态调整候选集大小。 |
核采样 (Top-p采样, Nucleus Sampling) |
1. 计算概率分布: 给定语言模型输出的logits,通过softmax得到概率分布 P(x)。 |
优点: 动态调整候选集大小, 避免在概率分布平坦时采样到低概率token, 或在尖锐时过度限制。 |
概率采样, 动态阈值。 通过累积概率阈值动态选择候选集,平衡多样性和质量。 |
场景: 文本生成, 如故事创作、对话生成, 需要多样性和连贯性。 |
P(x): 原始概率分布,x∈V(词表)。 |
排序: 概率降序排列。 |
描述为“将概率从大到小排序,选择累积概率达到阈值p的最小token集合,然后在这个集合内重新归一化概率并采样”。 |
1. 输入:概率分布 P(x),阈值 p。 |
“概率累积流”: 概率流 P(x)被排序为降序流 p(i)。累积流 C(k)逐步累加,直到达到阈值 p。此时,前 k个token形成核心流(nucleus),其余token被截断。核心流内的概率被重新归一化,形成新的概率流 P′,采样流从 P′中产生输出token。 |
核采样在单个GPU上执行,涉及排序和累积操作,计算复杂度 O(VlogV)。在分布式生成中,每个GPU可以独立采样,但需要同步随机种子以确保一致性(如果要求)。 |
Top-k采样, 温度采样, 束搜索。 |
|
AI-A0-0224 |
解码策略 |
Token领域 |
从概率最高的k个token中采样,候选集大小固定。 |
Top-k采样 |
1. 计算概率分布: P(x)通过softmax得到。 |
优点: 简单, 避免采样到低概率token。 |
概率采样, 固定候选集。 通过固定大小的候选集限制采样范围,提高生成质量。 |
场景: 文本生成, 需要限制采样空间时。 |
P(x): 原始概率分布。 |
Top-k选择: 选择概率最大的k个元素。 |
描述为“选择概率最高的k个token,然后在这个集合内重新归一化概率并采样”。 |
**1. 输入:概率分布 P(x),参数 k。 |
S |
=k} \sum{x \in S} P(x)。<br>3.计算候选集总概率:Z = \sum{x \in V{\text{top-k}}} P(x)。<br>4.重新归一化:对于每个x \in V{\text{top-k}},P'(x) = P(x) / Z。<br>5.根据P'$ 采样一个token输出。** |
“Top-k截断流”: 概率流 P(x)经过排序,保留前 k个最大的概率流,其余被截断。然后对保留的概率流进行重新归一化,形成新的概率流 P′,采样流从 P′中产生输出。 |
|
AI-A0-0225 |
解码策略 |
Token领域 |
通过温度参数调整概率分布的平滑度,控制生成多样性。 |
温度采样 (Temperature Sampling) |
1. 计算logits: 语言模型输出logits zi对于每个token i。 |
温度效应: T=1保持原分布;T>1平滑分布(增加多样性);T<1锐化分布(减少多样性,趋向贪婪)。 |
概率变换, 平滑控制。 通过温度参数控制概率分布的熵,调节生成多样性。 |
场景: 文本生成, 需要控制生成结果的随机性时。 |
zi: logits,未归一化的分数。 |
缩放: zi′=zi/T。 |
描述为“将logits除以温度参数后再进行softmax,温度越高概率分布越平滑,采样越多样;温度越低分布越尖锐,采样越确定”。 |
1. 输入:logits向量 z,温度 T。 |
“温度调节流”: logits流 z被温度参数 T缩放,得到 z′。然后通过softmax流转换为概率流 P。温度 T作为一个控制阀:当 T大时,缩放后的 logits 流 z′差异变小,softmax 流输出更平滑的概率流,采样流更随机;当 T小时,z′差异放大,概率流更尖锐,采样流更确定。 |
温度采样计算简单,只需除法和softmax。在分布式生成中,每个GPU独立应用温度并采样。 |
核采样, Top-k采样, 贪婪解码。 |
|
AI-A0-0226 |
解码策略 |
Token领域 |
在每一步选择概率最高的token,确定性解码。 |
贪婪解码 (Greedy Decoding) |
1. 计算概率分布: P(x)通过softmax得到。 |
优点: 简单, 快速, 确定性。 |
确定性解码, 最大似然。 每一步选择当前最可能的token,但不保证全局最优序列。 |
场景: 需要快速、确定性生成的场景, 如机器翻译、摘要。 |
P(x): 概率分布。 |
argmax: x∗=argmaxP(x)。 |
描述为“每一步都选择概率最高的token作为输出”。 |
1. 输入:概率分布 P(x)。 |
“贪婪选择流”: 概率流 P(x)直接流向argmax操作,输出最大概率token流。没有随机性,每一步都是确定性的选择。 |
贪婪解码只需argmax操作,计算简单。在分布式生成中,每个GPU可以独立生成,但需要同步以确保一致性(如果使用束搜索则需通信)。 |
束搜索, 采样方法。 |
|
AI-A0-0227 |
解码策略 |
Token领域 |
维护多个候选序列(束),每一步扩展所有候选序列,保留总体概率最高的k个序列。 |
束搜索 (Beam Search) |
1. 初始化: 包含一个空序列,分数为0。 |
优点: 比贪婪解码更可能找到全局最优序列。 |
启发式搜索, 广度优先剪枝。 维护固定大小的候选集,近似全局最优序列。 |
场景: 序列生成任务, 如机器翻译、文本摘要, 需要高质量序列。 |
k: 束宽,候选序列数量。 |
累积对数概率: s=∑logP。 |
描述为“维护k个最有可能的候选序列,每一步扩展这些序列,然后从所有扩展序列中再选择k个分数最高的,直到生成结束”。 |
1. 初始化束 B=[(空序列,分数=0)]。 |
“束流”: 初始时,一个空序列流开始。每一步,每个序列流扩展为多个子流(每个token一个),形成扩展流集合。然后通过排序和选择,保留分数最高的k个流,其余被剪枝。这些流继续迭代,直到结束。束流通过并行探索多条路径,增加了找到高质量序列的可能性。 |
束搜索需要维护k个候选序列,每个序列需要独立进行前向传播,计算量大。在分布式生成中,每个GPU可以处理部分序列,但需要通信来同步分数和选择全局top-k。 |
贪婪解码, 长度惩罚, 重复惩罚。 |
|
AI-A0-0228 |
解码策略 |
Token领域 |
在束搜索中引入长度归一化,避免偏向短序列。 |
长度惩罚 (Length Penalty) |
1. 序列分数: 原始分数为对数概率之和 s=∑i=1LlogP(xi∣x<i)。 |
目的: 纠正束搜索倾向于短序列的偏差(因为对数概率为负,越长分数越低)。 |
分数归一化, 偏差校正。 通过对数概率之和除以长度相关因子,使不同长度序列可比。 |
场景: 束搜索中, 需要公平比较不同长度序列时。 |
s: 原始分数,对数概率之和。 |
归一化: snorm=s/(L+c)α。 |
描述为“将序列的对数概率之和除以长度的幂次方,以消除长度偏差,使得束搜索能够公平比较不同长度的序列”。 |
在束搜索的每一步,当计算新序列分数时: |
“长度归一化流”: 原始分数流 s与长度流 L结合,通过归一化函数 f(L)=(L+c)α进行缩放,得到归一化分数流 snorm。这个流使得长序列的分数不会被过度惩罚,从而在束搜索中公平竞争。 |
长度惩罚在束搜索中简单应用,只需在计算分数时增加归一化步骤。在分布式束搜索中,每个GPU本地计算归一化分数,然后全局排序。 |
束搜索, 重复惩罚。 |
|
AI-A0-0229 |
解码策略 |
Token领域 |
在生成过程中惩罚重复的n-gram,避免重复文本。 |
重复惩罚 (Repetition Penalty) |
1. 识别重复: 对于已生成的序列,检测出现的n-gram(如unigram, bigram)。 |
目的: 减少生成文本中的重复短语。 |
概率调整, 重复抑制。 通过降低重复token的概率来避免生成重复内容。 |
场景: 文本生成, 特别是对话、故事生成, 容易产生重复时。 |
P(x): 原始概率分布。 |
概率缩放: P′(x)=P(x)/max(1,λ⋅count(gram))。 |
描述为“如果下一个token会导致重复的n-gram,则将其概率除以一个惩罚因子,从而降低重复的可能性”。 |
1. 输入:已生成序列 seq,当前步的概率分布 P(x),惩罚因子 λ,n-gram大小 n。 |
“重复抑制流”: 原始概率流 P(x)经过重复检测器,对于每个候选token x,检查其与历史流形成的n-gram是否重复。如果重复,则概率流被惩罚因子 λ缩放降低;否则保持不变。调整后的概率流 P′(x)被重新归一化,然后用于生成流。这抑制了重复流,促进多样性流。 |
重复惩罚需要在生成过程中维护n-gram计数,计算开销较小。在分布式生成中,每个GPU需要知道完整的历史序列,可能需要通信。 |
束搜索, 长度惩罚。 |
|
AI-A0-0230 |
解码策略 |
Token领域 |
在束搜索中,对已生成的序列进行分组,避免多样性不足。 |
束搜索分组 (Beam Search with Grouping) |
1. 分组: 将束中的序列根据某些特征(如前缀、语义)分成若干组。 |
目的: 增加束搜索的多样性, 避免所有序列都相似。 |
多样性促进, 分组平衡。 通过分组确保候选集覆盖不同区域,提高多样性。 |
场景: 需要多样生成的束搜索, 如对话生成、 故事生成。 |
k: 束宽。 |
分组: 将序列划分为不相交的子集。 |
描述为“将候选序列分组,从每组中选择最好的序列,确保最终束包含不同组的序列,以增加多样性”。 |
**1. 初始化束 B包含 k个序列(或空序列)。 |
B' |
< k$,则从剩余序列中补足分数最高的。 |
“分组选择流”: 候选序列流 C被分组函数分成多个子流。每个子流内,分数最高的序列流被选出,代表该组。这些代表流组成新的束流 B′。这样,束流包含了来自不同组的流,增加了多样性。 |
|
AI-A0-0231 |
解码策略 |
Token领域 |
在生成过程中,同时考虑模型概率和与之前生成的token的相似性,鼓励多样性。 |
对比搜索 (Contrastive Search) |
1. 候选生成: 在每一步,从模型概率分布中选择 top-k 候选token。 |
目的: 在保持生成质量的同时, 减少重复, 增加多样性。 |
多样性解码, 对比惩罚。 通过惩罚与上下文相似的token来鼓励多样性。 |
场景: 文本生成, 需要多样且连贯的文本。 |
P(x∣context): 模型给定上下文的概率。 |
加权和: s(x)=(1−α)⋅logP−α⋅max similarity。 |
描述为“从概率最高的k个候选token中,选择模型概率高且与已生成token相似度低的token,通过加权分数进行平衡”。 |
1. 输入:上下文 c,模型概率分布 P(x∣c),嵌入函数 f,参数 α, k。 |
“对比分数流”: 模型概率流 logP与相似度惩罚流 max similarity结合。对于每个候选token,其嵌入流 f(x)与历史token的嵌入流计算相似度,取最大值作为惩罚。总分数流 s(x)是概率流与惩罚流的加权差。选择流选取总分最高的token。这鼓励选择概率高但与历史不重复的token。 |
对比搜索需要计算每个候选token与历史token的相似度,计算开销随历史长度增加。嵌入向量 f(x)可以是预训练的token嵌入。在分布式生成中,每个GPU需要访问完整历史嵌入。 |
核采样, 重复惩罚。 |
|
AI-A0-0232 |
解码策略 |
Token领域 |
在生成过程中,同时考虑多个候选序列,通过比较选择最佳下一个token。 |
集束采样 (Beam Sampling) |
1. 维护束: 类似束搜索,维护 k个候选序列。 |
特点: 结合了束搜索的序列维护和采样的随机性, 增加多样性。 |
随机束搜索, 采样与选择结合。 通过采样扩展增加探索,通过分数选择保持质量。 |
场景: 文本生成, 需要多样性但又不失连贯性。 |
k: 束宽。 |
采样: 从 P(x)中随机采样。 |
描述为“维护k个候选序列,每一步对每个序列采样下一个token生成多个扩展序列,然后选择分数最高的k个序列继续”。 |
1. 初始化束 B包含 k个序列(如空序列)。 |
“采样-选择流”: 每个序列流通过采样产生多个分支流,每个分支流对应一个采样token。然后所有分支流根据分数排序,选择top-k流继续。这结合了随机探索和确定性选择。 |
集束采样需要为每个序列采样多个token,计算量较大。在分布式生成中,每个GPU可以独立处理部分序列,但需要通信进行全局选择。 |
束搜索, 核采样。 |
|
AI-A0-0233 |
解码策略 |
Token领域 |
在每一步,从模型概率分布中随机采样一个token,完全随机。 |
随机采样 (Random Sampling) |
1. 计算概率分布: P(x)通过softmax得到。 |
特点: 完全随机, 多样性最高, 但可能生成不连贯的文本。 |
概率采样, 完全随机。 根据概率分布随机选择下一个token。 |
场景: 需要高多样性的创意写作, 或与温度采样结合控制随机性。 |
P(x): 概率分布。 |
采样: x∼P(x)。 |
描述为“根据模型输出的概率分布随机选择一个token作为输出”。 |
1. 输入:概率分布 P(x)。 |
“随机采样流”: 概率流 P(x)直接作为采样分布,随机生成一个token流。没有确定性选择,完全随机。 |
随机采样只需从分布中采样,计算简单。在分布式生成中,每个GPU独立采样,但需要同步随机种子以确保一致性(如果要求)。 |
温度采样, 贪婪解码。 |
|
AI-A0-0234 |
解码策略 |
Token领域 |
在每一步,从模型概率分布中采样,但通过调整概率分布避免重复。 |
重复惩罚采样 (Repetition Penalty Sampling) |
1. 计算原始概率 P(x)。 |
目的: 减少重复token的出现。 |
概率调整, 重复抑制。 通过降低已出现token的概率来避免重复。 |
场景: 文本生成, 容易产生重复token时。 |
P(x): 原始概率分布。 |
概率缩放: P′(x)=P(x)/λ如果 x∈H。 |
描述为“降低已生成token的概率,然后重新归一化并采样,以减少重复”。 |
1. 输入:原始概率 P(x),历史token集合 H,惩罚因子 λ。 |
“重复抑制采样流”: 原始概率流 P(x)经过惩罚过滤器,历史token的概率流被缩小 λ倍。然后重新归一化流产生 P′′(x),采样流从 P′′中产生输出。这降低了重复token被选中的概率。 |
重复惩罚采样需要维护历史token集合,计算开销小。在分布式生成中,每个GPU需要知道历史token,可能需要通信。 |
核采样, 对比搜索。 |
|
AI-A0-0235 |
解码策略 |
Token领域 |
在每一步,从模型概率分布中采样,但通过调整概率分布鼓励多样性。 |
多样性促进采样 (Diversity-Promoting Sampling) |
1. 计算原始概率 P(x)。 |
效果: α=1为原始分布;α<1增加多样性;α>1减少多样性。 |
概率变换, 熵调整。 通过指数 α调整概率分布的熵,控制多样性。 |
场景: 文本生成, 需要控制多样性时。 |
P(x): 原始概率分布。 |
指数变换: P′(x)∝P(x)α。 |
描述为“将原始概率分布进行指数变换,指数小于1时平滑分布增加多样性,大于1时锐化分布减少多样性,然后采样”。 |
1. 输入:原始概率 P(x),参数 α。 |
“指数平滑流”: 原始概率流 P(x)经过指数变换 (⋅)α。当 α<1时,概率流被平滑,低概率token的相对概率提升,增加多样性流;当 α>1时,概率流被锐化,高概率token更突出,减少多样性流。然后归一化流产生 P′′(x),采样流从中选择。 |
多样性促进采样涉及指数运算和归一化,计算开销中等。在分布式生成中,每个GPU独立计算。 |
温度采样, 核采样。 |
|
AI-A0-0236 |
解码策略 |
Token领域 |
在每一步,从模型概率分布中采样,但通过调整概率分布避免生成特定token(如不良词汇)。 |
禁止token采样 (Forbidden Token Sampling) |
1. 计算原始概率 P(x)。 |
目的: 避免生成不希望出现的token, 如脏话、 敏感词等。 |
概率过滤, 内容控制。 通过将禁止token的概率置零来避免生成它们。 |
场景: 内容安全, 避免生成不良内容。 |
P(x): 原始概率分布。 |
概率置零: P′(x)=0for x∈F。 |
描述为“将禁止token的概率设为0,然后重新归一化并采样,以确保不会生成这些token”。 |
1. 输入:原始概率 P(x),禁止token集合 F。 |
“禁止过滤流”: 原始概率流 P(x)经过禁止过滤器,属于集合 F的token的概率流被截断为0。然后重新归一化流产生 P′′(x),采样流从 P′′中产生输出,确保禁止token不会被选中。 |
禁止token采样需要维护禁止集合,计算开销小。在分布式生成中,禁止集合需要同步到所有GPU。 |
重复惩罚采样。 |
|
AI-A0-0237 |
解码策略 |
Token领域 |
在生成过程中,根据上下文动态调整温度参数,以控制随机性。 |
动态温度采样 (Dynamic Temperature Sampling) |
1. 计算上下文的不确定性: 例如,使用概率分布的熵 H(P)=−∑xP(x)logP(x),或最大概率值 pmax。 |
目的: 在模型不确定时增加多样性(高温), 在模型确定时减少多样性(低温)。 |
自适应温度, 不确定性感知。 根据模型输出的不确定性动态调整温度参数。 |
场景: 文本生成, 需要自适应控制随机性时。 |
P(x): 原始概率分布。 |
熵计算: H(P)=−∑PlogP。 |
描述为“根据当前概率分布的熵或最大概率值动态计算温度参数,然后进行温度采样”。 |
**1. 输入:logits z,调整参数 α,β。 |
|
编号 |
类别 |
领域 |
模型配方 |
数学公式/定理/算法/模型/方法名称 |
数学公式/定理/算法/模型/方法的逐步思考推理过程及每一个步骤的数学方程式和参数选择/优化/迭代 |
精度/密度/误差/强度 |
底层规律/理论 |
典型应用场景和特征 |
变量/常量/参数列表及说明 |
数学特征 |
语言特征 |
时序和交互流程的所有细节/分步骤时序情况及数学方程式 |
流动模型和流向方法的数学描述 |
多GPU芯片执行情况和方程式列表 |
关联知识和算法 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
AI-A0-0237 |
解码策略 |
Token领域 |
在生成过程中,根据上下文动态调整温度参数,以控制随机性。 |
动态温度采样 (Dynamic Temperature Sampling) |
1. 计算上下文的不确定性: 例如,使用概率分布的熵 H(P)=−∑xP(x)logP(x),或最大概率值 pmax。 |
目的: 在模型不确定时增加多样性(高温), 在模型确定时减少多样性(低温)。 |
自适应温度, 不确定性感知。 根据模型输出的不确定性动态调整温度参数。 |
场景: 文本生成, 需要自适应控制随机性时。 |
P(x): 原始概率分布。 |
熵计算: H(P)=−∑PlogP。 |
描述为“根据当前概率分布的熵或最大概率值动态计算温度参数,然后进行温度采样”。 |
1. 输入:logits z,调整参数 α,β。 |
“自适应温度流”: 概率流 P的熵流 H反映了不确定性。不确定性高时,熵流大,温度流 T增大,导致缩放后的logits流 z′差异缩小,概率流 P′更平滑,采样流更随机;反之,不确定性低时,温度流小,概率流更尖锐,采样流更确定。 |
动态温度采样需要计算熵,增加了一些计算开销。在分布式生成中,每个GPU独立计算熵和温度。 |
温度采样, 熵。 |
|
AI-A0-0238 |
解码策略 |
Token领域 |
在生成过程中,使用多个采样结果,通过投票或平均选择最终输出。 |
集束投票采样 (Beam Vote Sampling) |
1. 独立采样: 从同一个模型中独立采样 N个序列(使用相同的采样方法,如核采样)。 |
目的: 通过集成多个采样结果来提高生成质量和稳定性。 |
集成采样, 投票。 通过多个独立采样的结果进行投票,减少随机性的不利影响。 |
场景: 需要更稳定、 更可靠生成的场景。 |
N: 采样次数。 |
计数: 统计每个token的出现次数。 |
描述为“独立采样多个序列,然后在每个时间步对token进行投票,选择得票最多的token作为最终输出”。 |
1. 初始化 N个空序列。 |
“投票集成流”: 多个独立的采样流并行进行,每个流产生一个token流。在每一步,这些token流进行投票,票数最高的token流被选为最终输出流,并反馈到所有采样流中以确保同步。 |
集束投票采样需要并行运行多个采样过程,计算开销是单次采样的 N倍。在分布式生成中,可以将不同采样分配到不同GPU上,然后通过AllReduce进行投票。 |
核采样, 集成方法。 |
|
AI-A0-0239 |
解码策略 |
Token领域 |
在生成过程中,通过调整概率分布,使生成文本的风格或内容符合特定要求。 |
引导生成 (Guided Generation) |
1. 定义引导函数: g(x,c)衡量token x在上下文 c下符合引导目标的程度(如情感、主题)。 |
目的: 引导生成文本朝特定方向, 如积极情感、 特定主题等。 |
概率调整, 引导控制。 通过外部信号调整概率分布,实现可控生成。 |
场景: 可控文本生成, 如情感控制、 主题控制。 |
P(x): 原始概率分布。 |
指数加权: P′(x)∝P(x)⋅exp(λg(x,c))。 |
描述为“将原始概率乘以引导函数的指数权重,然后重新归一化,以引导生成符合特定目标的文本”。 |
1. 输入:原始概率 P(x),引导函数 g(x,c),强度 λ。 |
“引导加权流”: 原始概率流 P(x)与引导分数流 exp(λg(x,c))相乘,得到调整后的概率流 P′(x)。引导分数流根据外部信号放大或缩小某些token的概率,从而引导生成流朝向期望的方向。 |
引导生成需要计算引导函数,可能引入额外模型(如分类器)的开销。在分布式生成中,引导函数可能需要跨GPU计算。 |
条件生成, 可控生成。 |
|
AI-A0-0240 |
并行训练 |
PD分离领域 |
将数据分片到多个设备,每个设备持有完整的模型,独立计算梯度,然后同步梯度。 |
数据并行 (Data Parallelism) |
1. 复制模型: 每个设备拥有完整的模型副本。 |
优点: 简单, 适用于模型能放入单个设备的情况。 |
分布式训练, 数据分割。 通过数据划分并行计算梯度,同步更新。 |
场景: 模型可放入单设备, 需要加速训练。 |
N: 设备数。 |
划分: 数据划分。 |
描述为“将模型复制到多个设备,每个设备处理一部分数据,计算梯度后同步平均梯度,然后各自更新参数”。 |
1. 将模型复制到每个设备。 |
“数据分流,梯度合流”: 训练数据流被分割成多个子流,分别流入不同的设备。在每个设备上,完整的模型副本独立处理子流,产生局部梯度流。然后,所有局部梯度流通过通信网络汇合,聚合成全局平均梯度流。这个全局梯度流再分流到每个设备,用于更新本地模型副本,确保所有副本同步演进。 |
深度学习框架(如PyTorch的 |
模型并行, 流水线并行, All-Reduce。 |
|
AI-A0-0241 |
并行训练 |
PD分离领域 |
将模型的不同层分配到不同设备上,按层顺序计算,每层计算完成后将激活传递给下一层。 |
模型并行 (Model Parallelism) |
1. 垂直划分: 将模型按层划分,不同层放置在不同设备上。 |
目标: 将模型分布到多个设备, 解决内存不足问题。 |
模型并行, 层划分。 将模型的不同层放置在不同设备上,串行执行。 |
场景: 模型过大无法放入单个设备内存, 且层数较多时。 |
L: 总层数。 |
串行: 一次只有一个设备在计算。 |
描述为“将模型的不同层放置在不同的设备上,前向传播时数据从一个设备流向下一个设备,每层计算完成后将激活传递给下一层,反向传播时梯度反向传递”。 |
1. 前向传播: |
“层间流”: 数据流依次流经每个设备上的层流。每个设备上的层流处理完后,激活流被发送到下一个设备。反向传播时,梯度流反向流动。这种流是纯串行的,因此设备利用率低,大部分设备处于空闲状态。 |
模型并行(纯层并行)通信量相对较小(仅层间传递激活和梯度),但设备利用率低。通常与数据并行结合,形成混合并行。 |
流水线并行, 张量并行。 |
|
AI-A0-0242 |
并行训练 |
PD分离领域 |
将模型按层划分到多个设备,并通过微批量和流水线调度提高设备利用率。 |
流水线并行 (Pipeline Parallelism) |
1. 模型划分: 将模型的 L层划分为 p个阶段(stage),每个阶段包含连续的若干层,放置在不同的设备上。 |
目标: 将模型分布到多个设备, 解决单个设备内存不足问题, 提高设备利用率。 |
模型并行, 流水线。 将模型按层划分到多个设备,通过流水线执行提高设备利用率。 |
场景: 模型过大无法放入单个设备内存时。 |
p: 流水线阶段数。 |
流水线: 多个微批量重叠执行。 |
描述为“将模型按层划分到多个设备上,将每个批量分成多个微批量,以流水线方式执行微批量的前向和反向传播,从而重叠不同设备上的计算”。 |
1. 前向传播(以GPipe为例): |
“流水线流”: 数据流被分割为微批量流。这些微批量流依次进入流水线。每个设备(阶段)处理其对应的层流。当一个微批量流完成一个阶段后,其激活流被发送到下一个阶段,同时该阶段可以处理下一个微批量流。这样,多个微批量流在流水线中重叠流动,提高了设备利用率。然而,在流水线开始和结束时,会有气泡(空闲时间),因为并非所有阶段都同时工作。 |
流水线并行需要设备间通信传递激活和梯度。通信发生在相邻阶段之间。气泡开销可以通过增加微批量数量来减少。通常与数据并行结合,形成混合并行。 |
模型并行, 数据并行, 张量并行。 |
|
AI-A0-0243 |
并行训练 |
PD分离领域 |
将模型的单个层内的参数和计算分割到多个设备上,通常按维度分割矩阵乘法。 |
张量并行 (Tensor Parallelism) |
1. 列并行: 将权重矩阵 W按列分割,W=[W1,W2],输入 x广播,y=xW=x[W1,W2]=[xW1,xW2],每个设备计算一部分,结果拼接。 |
目标: 将单个层的计算分布到多个设备, 减少每个设备的内存和计算负载。 |
模型并行, 矩阵分割。 将矩阵乘法按行或列分割到多个设备,通过通信组合结果。 |
场景: 单个层过大无法放入单个设备内存时, 如大型FFN层或注意力层。 |
W: 权重矩阵,形状 (m,n)。 |
列分割: W按列分割,x广播,输出拼接。 |
描述为“将权重矩阵按行或列分割到多个设备上,每个设备计算部分结果,然后通过通信(如拼接或求和)得到完整输出”。 |
以列并行为例: |
“张量分割流”: 权重流 W被分割成多个子流 Wi分布在不同设备上。输入流 x被广播或分割到各设备。每个设备独立计算局部流 yi=xWi或 zi=xiWi。然后通过通信流(All-Gather或All-Reduce)将局部流聚合成全局流 y。这种流将单个层的计算负载分散到多个设备,但引入了通信开销。 |
张量并行需要设备间通信,通信量较大。通常用于单个层非常大的情况,如Transformer的FFN层(dff很大)。在多头注意力中,可以将不同头分布到不同设备上。 |
模型并行, 流水线并行, Megatron-LM。 |
|
AI-A0-0244 |
并行训练 |
PD分离领域 |
一种优化器状态分区技术,将优化器状态、梯度和参数分区到多个设备上,以节省内存。 |
ZeRO (Zero Redundancy Optimizer) |
1. ZeRO-DP: 数据并行,但将优化器状态、梯度和参数分区到多个GPU上,每个GPU只存储一部分。 |
目标: 减少数据并行中的内存冗余, 允许训练更大模型。 |
数据并行, 内存优化。 通过分区优化器状态、梯度和参数,消除数据并行中的内存冗余。 |
场景: 训练极大模型, 如万亿参数模型, 内存受限。 |
N: GPU数量。 |
分区: 将张量沿某个维度分割。 |
描述为“在数据并行中,将优化器状态、梯度和参数分区到多个GPU上,每个GPU只负责更新和存储其中一部分,从而大幅减少每个GPU的内存占用”。 |
以ZeRO-3为例: |
“分区流”: 参数流 W被分割成多个子流 Wi分布在不同GPU上。在前向流中,通过All-Gather通信流将 Wi聚合成完整参数流 W用于计算,然后释放非本地部分。梯度流同样被分区存储。优化器状态流(如动量)也被分区。更新流只在每个GPU本地进行。这大大减少了每个GPU的内存占用,但增加了通信开销。 |
ZeRO-3 需要在前向和反向传播时进行All-Gather收集参数,通信开销较大。ZeRO-2 只需要在梯度更新时通信。ZeRO-1 通信开销最小。通常与数据并行结合使用。 |
数据并行, 模型并行, 内存优化。 |
|
AI-A0-0245 |
并行训练 |
PD分离领域 |
一种混合并行策略,结合数据并行、流水线并行和张量并行,以训练极大模型。 |
3D并行 (3D Parallelism) |
1. 数据并行 (DP): 复制整个模型到多个设备,数据分片。 |
目标: 最大化模型规模和训练效率, 适应超大规模模型训练。 |
混合并行, 三维并行。 结合数据、流水线和张量并行,实现极大规模模型训练。 |
场景: 训练千亿、万亿参数模型, 如Megatron-Turing NLG。 |
DP degree: 数据并行度。 |
乘积: 总设备数为三个维度的乘积。 |
描述为“同时使用数据并行、流水线并行和张量并行,将模型分布到大量设备上,以训练超大规模模型”。 |
1. 将设备组织成三维网格:DP、PP、TP。 |
“三维并行流”: 数据流在DP维度上被复制多份,每个副本处理不同的数据子流。每个数据副本的模型被切分成多个阶段流(PP维度),每个阶段流在TP维度上进一步切分成多个设备流。计算流在TP组内进行张量并行计算,在PP组间进行流水线传递,在DP组间独立进行。梯度流在DP组内进行All-Reduce,在TP组内进行All-Reduce,在PP组间反向传递。 |
3D并行需要复杂的通信模式。TP需要组内All-Reduce,PP需要相邻阶段间点对点通信,DP需要跨组All-Reduce。通信优化至关重要。 |
Megatron-LM, DeepSpeed, ZeRO。 |
|
AI-A0-0246 |
并行训练 |
PD分离领域 |
一种异步数据并行方法,每个设备独立计算梯度并异步更新中央参数服务器,无需等待同步。 |
异步数据并行 (Asynchronous Data Parallelism) |
1. 参数服务器: 维护全局参数 W。 |
优点: 无需同步等待, 设备利用率高。 |
异步并行, 参数服务器。 通过异步更新全局参数,避免同步开销。 |
场景: 大规模分布式训练, 通信带宽受限, 对收敛精度要求不高时。 |
W: 全局参数。 |
异步更新: W←W−αgi,当收到梯度时立即更新。 |
描述为“多个工作者异步地从参数服务器拉取参数,计算梯度后推送更新,参数服务器立即应用更新,不等待其他工作者”。 |
1. 初始化全局参数 W。 |
“异步流”: 参数流 W存储在参数服务器中。工作者流异步地拉取参数流,计算梯度流,然后推送更新流。参数服务器流立即应用更新流,导致参数流被多个工作者流交错更新,可能产生冲突。梯度流可能基于过时的参数流,导致更新方向不一致。 |
异步数据并行中,每个工作者可以独立运行,无需同步,因此可扩展性好。但梯度陈旧可能影响收敛。需要处理参数版本冲突,如使用延迟更新补偿。 |
同步数据并行, 参数服务器。 |
|
AI-A0-0247 |
并行训练 |
PD分离领域 |
一种同步数据并行方法,使用All-Reduce同步梯度,所有设备同步更新。 |
同步数据并行 (Synchronous Data Parallelism) |
1. 复制模型: 每个设备拥有完整的模型副本。 |
优点: 梯度准确, 收敛稳定。 |
同步并行, All-Reduce。 通过全局同步梯度,确保所有设备使用相同的梯度更新。 |
场景: 大多数数据并行训练, 如使用DistributedDataParallel。 |
N: 设备数。 |
平均: 梯度平均。 |
描述为“所有设备同步计算梯度,然后通过All-Reduce计算平均梯度,最后所有设备使用平均梯度更新参数”。 |
1. 将模型复制到每个设备。 |
“同步流”: 数据流被分割到多个设备流。每个设备流独立计算梯度流,然后通过All-Reduce通信流聚合成平均梯度流。所有设备流同步等待通信完成,然后使用相同的平均梯度流更新本地参数流。这保证了参数流的一致性,但速度受限于最慢的设备流。 |
同步数据并行使用All-Reduce进行梯度同步,通信开销与参数量成正比。在GPU集群中,使用NCCL库进行高效的All-Reduce。 |
异步数据并行, All-Reduce。 |
|
AI-A0-0248 |
并行训练 |
PD分离领域 |
一种梯度压缩方法,在通信前对梯度进行量化,减少通信量。 |
梯度量化 (Gradient Quantization) |
1. 量化: 将梯度从32位浮点数量化为低位表示,如8位整数。例如,对梯度 g,计算最大值 gmax和最小值 gmin,然后线性量化:gquant=round(gmax−gming−gmin⋅(2b−1)),其中 b是量化位数(如8)。 |
目的: 减少梯度通信带宽, 加速分布式训练。 |
通信压缩, 量化。 通过降低梯度精度减少通信量。 |
场景: 分布式训练, 通信带宽受限时。 |
g: 原始梯度,浮点数。 |
线性量化: 将浮点数映射到整数区间。 |
描述为“将梯度量化为低比特整数进行通信,接收方再反量化为浮点数,以减少通信量”。 |
1. 计算梯度 g。 |
“量化压缩流”: 梯度流 g被量化为低比特流 gquant,同时额外传输范围流 gmin和 gmax。通信流传输压缩后的数据流。接收方通过反量化流恢复出近似梯度流 g′。量化流引入了误差,但大幅减少了通信流量。 |
梯度量化可以将通信量减少为原来的 b/32(如8位量化减少4倍)。在All-Reduce中,需要对量化后的梯度进行通信。多GPU中,每个GPU独立量化,然后通信,最后反量化。 |
梯度稀疏化, 通信压缩。 |
|
AI-A0-0249 |
并行训练 |
PD分离领域 |
一种梯度压缩方法,只通信绝对值大的梯度(超过阈值),减少通信量。 |
梯度稀疏化 (Gradient Sparsification) |
1. 选择重要梯度: 根据梯度绝对值选择前 k% 的梯度(或超过阈值 τ的梯度)进行通信,其余梯度置零。 |
目的: 通过只通信重要梯度减少通信量。 |
通信压缩, 稀疏化。 通过只通信部分梯度减少通信量。 |
场景: 分布式训练, 梯度稀疏时。 |
g: 原始梯度。 |
Top-k选择: 保留绝对值最大的 k% 梯度。 |
描述为“只选择绝对值最大的部分梯度进行通信,其余梯度不通信,从而减少通信量”。 |
1. 计算梯度 g。 |
“稀疏化流”: 梯度流 g经过选择器,只保留重要梯度流,形成稀疏梯度流 gsparse。通信流只传输非零值和索引流。接收方重建稀疏梯度流。为了减少误差,未传输的梯度流可以被累积到本地,在后续步骤中补偿。 |
梯度稀疏化可以大幅减少通信量,尤其当梯度稀疏时。在All-Reduce中,需要通信稀疏矩阵,可以使用专门的稀疏All-Reduce算法。 |
梯度量化, 通信压缩。 |
|
AI-A0-0250 |
并行训练 |
PD分离领域 |
一种通信压缩方法,将多个小梯度打包成一个大的消息进行通信,减少通信次数。 |
梯度打包 (Gradient Packing) |
1. 打包: 将多个小张量(如每层的梯度)拼接成一个大张量。 |
优点: 减少通信启动开销, 提高带宽利用率。 |
通信优化, 打包。 通过合并多个小张量通信减少通信次数。 |
场景: 分布式训练, 梯度由多个小张量组成时。 |
g1,g2,...,gn: 各层的梯度张量。 |
拼接: G=[g1,g2,...,gn]。 |
描述为“将多个梯度张量拼接成一个大张量进行通信,以减少通信次数”。 |
1. 前向和反向传播后,得到各层梯度 gi。 |
“打包流”: 多个小梯度流 gi被拼接成一个大梯度流 G。通信流传输 G,然后接收方拆分成原始流。这减少了通信次数,提高了带宽利用率。 |
梯度打包通常由深度学习框架自动完成(如PyTorch的DistributedDataParallel会将所有梯度拼接成一个张量进行All-Reduce)。 |
All-Reduce, 通信优化。 |
|
AI-A0-0251 |
并行训练 |
PD分离领域 |
一种重叠通信和计算的技术,在计算梯度的同时通信已计算好的梯度。 |
梯度通信重叠 (Gradient Communication Overlapping) |
1. 流水线: 在反向传播过程中,一旦某一层的梯度计算完成,立即开始通信该层的梯度,同时继续计算后面层的梯度。 |
目的: 隐藏通信延迟, 加速训练。 |
通信计算重叠, 流水线。 通过重叠梯度通信和梯度计算,隐藏通信延迟。 |
场景: 分布式训练, 通信开销较大时。 |
反向传播顺序: 从输出层到输入层。 |
重叠: 通信和计算同时进行。 |
描述为“在反向传播中,一旦某层的梯度可用,就立即开始通信该层的梯度,同时继续计算其他层的梯度,从而重叠通信和计算”。 |
1. 反向传播开始。 |
“重叠流”: 梯度计算流和梯度通信流并行进行。一旦一层梯度计算流产生,立即启动通信流,同时计算流继续流向下一层。这样,通信流和计算流在时间上重叠,减少了总时间。 |
梯度通信重叠需要非阻塞通信原语。在数据并行中,可以对每层梯度分别进行All-Reduce。通信可能需要额外的内存缓冲区。 |
流水线并行, 计算通信重叠。 |
|
AI-A0-0252 |
并行训练 |
PD分离领域 |
一种内存优化技术,在训练中只保存部分中间激活值,在反向传播时重新计算其他激活。 |
激活检查点 (Activation Checkpointing) |
1. 分段: 将模型分成若干段(checkpoint segments)。 |
节省内存: 内存占用从 O(L)降低到 O(L)或 O(logL), 其中 L是层数。 |
内存-计算权衡。 通过重计算中间激活来减少内存占用。 |
场景: 训练极深模型, 内存受限时。 |
模型分段: 将模型分为 k段。 |
重计算: 从检查点重新运行前向传播。 |
描述为“将模型分成若干段,在前向传播时只保存每段的输入和输出作为检查点,在反向传播时根据需要从检查点重新计算中间激活,从而节省内存”。 |
1. 将模型划分为 k个段:[segment1,segment2,...,segmentk]。 |
“检查点-重计算”流: 前向流经过模型分段,每段的输入流 xi和输出流 yi被保存为检查点流,而段内的中间激活流被丢弃。在反向流中,从最后一段开始,加载检查点流 xi和 yi,重新执行该段的前向流以生成中间激活流,然后计算梯度流。梯度流传播后,中间激活流被释放。这种流以额外的计算流为代价,减少了内存中需要同时保存的激活流数量。 |
激活检查点可以在单个GPU上实施,也可以与数据并行结合。在模型并行中,检查点可以设置在设备边界。重计算会增加计算时间,但允许训练更大的模型或更大的批量。 |
重计算, 内存优化, 梯度检查点。 |
|
AI-A0-0253 |
并行训练 |
PD分离领域 |
一种混合精度训练方法,使用半精度(FP16)进行前向和反向传播,同时保留单精度(FP32)主权重副本。 |
混合精度训练 (Mixed Precision Training) |
1. 维护FP32主权重: θfp32。 |
优点: 加速计算, 减少内存占用, 保持数值稳定性。 |
数值计算, 精度。 利用FP16加速计算,用FP32保持数值范围,通过梯度缩放防止下溢。 |
场景: 训练大型神经网络, 如Transformer, 需要加速和节省内存。 |
θfp32: FP32主权重。 |
精度转换: FP32 ↔ FP16。 |
描述为“使用半精度进行前向和反向传播以加速计算并节省内存,同时保留单精度主权重副本用于更新,并通过梯度缩放防止梯度下溢”。 |
1. 将FP32主权重 θfp32复制为FP16权重 θfp16。 |
“精度混合流”: 权重流 θ以FP32格式存储(主权重流)。在前向流中,权重流被转换为FP16流 θfp16,与FP16输入流进行运算,产生FP16激活流和损失流。损失流被缩放因子 S放大,以保留梯度信息。反向流计算FP16梯度流 gfp16,然后反缩放并转换为FP32梯度流 gfp32,最后用于更新FP32主权重流。这种流在计算密集型部分使用FP16加速,在权重更新时使用FP32保持精度。 |
混合精度训练需要GPU支持FP16计算(如Tensor Cores)。在数据并行中,每个GPU进行本地FP16前向/反向传播,梯度在FP32下进行All-Reduce。梯度缩放可以动态调整(如根据梯度范数)。 |
FP16, 梯度缩放, 数值稳定性。 |
|
AI-A0-0254 |
并行训练 |
PD分离领域 |
一种半精度浮点数格式,比FP16具有更大的动态范围,更适合深度学习训练。 |
BFloat16 (Brain Floating Point 16) |
1. 格式: 1位符号位,8位指数位,7位尾数位(而FP16是1位符号,5位指数,10位尾数)。 |
优点: 动态范围大, 与FP32指数位相同, 训练更稳定, 简化混合精度训练流程。 |
数值格式, 浮点数。 提供与FP32相同的指数范围,但使用16位存储,平衡范围和精度。 |
场景: 训练大型模型, 如Transformer, 在TPU和现代GPU上使用。 |
符号位: 1 bit。 |
指数范围: 与FP32相同(2−126到 2127)。 |
描述为“一种16位浮点数格式,具有与32位浮点数相同的指数范围,但尾数精度较低,适用于深度学习训练”。 |
1. 将权重、激活、梯度存储为BFloat16格式。 |
“大范围半精度”流: BFloat16数据流具有与FP32相同的指数范围,因此可以表示非常小和非常大的数,避免了FP16中容易出现的梯度下溢(值太小变为0)和溢出(值太大变为inf)问题。这使得BFloat16流可以直接用于训练,无需复杂的梯度缩放,简化了混合精度训练流程。计算流在BFloat16下进行,速度与FP16相当,但稳定性更好。 |
BFloat16得到现代AI加速器(如TPU、NVIDIA Ampere GPU)原生支持。在混合精度训练中,可以使用BFloat16代替FP16,简化流程。在多GPU中,通信可以使用BFloat16减少带宽。 |
FP16, FP32, 混合精度训练。 |
|
AI-A0-0255 |
并行训练 |
PD分离领域 |
一种优化器,将权重衰减与参数更新解耦,直接添加到更新步骤中。 |
AdamW |
1. 计算梯度: gt=∇θL(θt−1)(不包含权重衰减项)。 |
优点: 权重衰减与自适应学习率解耦, 通常比Adam泛化更好。 |
自适应优化, 权重衰减。 将权重衰减从损失函数中分离,直接应用于参数更新,避免与自适应学习率耦合。 |
场景: 训练大型模型如Transformer, 需要权重衰减正则化。 |
θ: 参数。 |
加法项: 更新中直接加 λθ。 |
描述为“在Adam更新公式中,额外添加一个权重衰减项,直接作用于参数,而不是通过损失函数”。 |
1. 计算梯度 gt(不包含权重衰减)。 |
“解耦正则化”流: 在AdamW中,权重衰减流 λθ直接与自适应更新流 αm^t/(v^t+ϵ)相加。这与传统Adam(权重衰减通过损失函数影响梯度)不同,避免了权重衰减与自适应学习率之间的耦合,使得正则化效果更稳定,模型泛化更好。 |
与Adam类似,但更新步骤中多了一项权重衰减。权重衰减项可以本地计算,无需额外通信。在多GPU数据并行中,每个GPU独立计算权重衰减项并更新本地参数副本。 |
Adam, 权重衰减, L2正则化。 |
|
AI-A0-0256 |
并行训练 |
PD分离领域 |
一种学习率调度策略,学习率在训练过程中按余弦函数从初始值衰减到最小值。 |
余弦退火 (Cosine Annealing) |
1. 学习率公式: ηt=ηmin+21(ηmax−ηmin)(1+cos(TmaxTcurπ)),其中 Tcur是当前步数,Tmax是总步数(或周期长度)。 |
特点: 平滑下降, 避免学习率突变, 有助于模型收敛到更优解。 |
学习率调度, 余弦函数。 使用余弦函数平滑调整学习率。 |
场景: 深度学习训练, 如图像分类、自然语言处理。 |
ηt: 当前学习率。 |
余弦函数: cos(πTcur/Tmax)。 |
描述为“学习率按余弦函数从最大值平滑衰减到最小值”。 |
1. 设置最大学习率 ηmax、最小学习率 ηmin、总步数 Tmax。 |
“余弦衰减”流: 学习率流 ηt随时间 t按余弦曲线从 ηmax平滑下降到 ηmin。这种平滑下降避免了阶梯式下降的突变,允许模型在初期以较大学习率快速收敛,后期以较小学习率精细调整,有助于找到更平坦的最小值。 |
学习率调度器在训练循环中每一步更新学习率。在多GPU训练中,通常由主进程计算学习率并广播,或每个进程独立计算相同值。 |
带热重启的余弦退火, 学习率调度。 |
|
AI-A0-0257 |
并行训练 |
PD分离领域 |
一种学习率调度策略,学习率在指定步数或epoch处乘以一个衰减因子。 |
步长衰减 (Step Decay) |
1. 定义: 学习率在预定义的步数或epoch处衰减。例如,每 s步将学习率乘以 γ(如0.1)。 |
特点: 简单, 常用, 但衰减可能过于激进。 |
学习率调度, 指数衰减。 按固定步长降低学习率。 |
场景: 各种深度学习任务, 尤其是训练收敛后期。 |
ηt: 当前学习率。 |
指数衰减: ηt=η0γ⌊t/s⌋。 |
描述为“每经过固定的步数,学习率乘以一个小于1的衰减因子,呈阶梯式下降”。 |
1. 设置初始学习率 η0,衰减因子 γ,步长 s。 |
“阶梯下降”流: 学习率流 ηt在大多数时间保持恒定,每经过 s步就突然下降为原来的 γ倍。这种离散的下降允许模型在某个学习率下稳定训练一段时间,然后进入更精细的调整阶段。 |
实现简单,只需在训练循环中检查当前步数是否达到衰减点。在多GPU中,学习率值需要同步。 |
指数衰减, 学习率调度。 |
|
AI-A0-0258 |
并行训练 |
PD分离领域 |
一种学习率调度策略,学习率随训练步数线性增加,然后线性或余弦衰减。 |
带热重启的余弦退火 (Cosine Annealing with Warm Restarts) |
1. 周期: 训练分为多个周期,每个周期内学习率按余弦函数从初始值衰减到最小值。 |
优点: 周期性重启有助于跳出局部最优, 提高模型性能。 |
学习率调度, 周期性重启。 通过余弦衰减和周期性重启来调整学习率。 |
场景: 训练深度神经网络, 尤其是图像分类和自然语言处理。 |
ηt: 当前学习率。 |
余弦函数: 学习率按余弦变化。 |
描述为“学习率在每个周期内按余弦函数从最大值衰减到最小值,周期结束后重启到最大值,并可能延长周期”。 |
1. 初始化周期长度 Ti,最大学习率 ηmax,最小学习率 ηmin。 |
“余弦振荡”流: 学习率流在每个周期内遵循余弦曲线,从高点 ηmax平滑下降到低点 ηmin。这种下降允许模型在初期快速收敛,后期精细调整。周期结束时,学习率流突然跳回高点(重启),模拟“重启”训练,有助于模型跳出可能的局部最优点,探索新的区域。 |
学习率调度器在训练循环中每一步更新学习率。在多GPU训练中,通常由主进程(rank 0)计算学习率并广播给所有进程,或每个进程独立计算相同值。 |
余弦退火, 学习率调度, 热重启。 |
|
AI-A0-0259 |
并行训练 |
PD分离领域 |
一种优化技巧,在多个小批量上累积梯度,然后一次性更新参数,模拟更大的批量大小。 |
梯度累积 (Gradient Accumulation) |
1. 过程: 对于 N个连续的小批量(micro-batch),每次前向传播后计算梯度,但不立即更新参数,而是将梯度累加到累积变量中。 |
目的: 在内存有限时模拟大批量训练, 稳定训练, 允许使用更大的有效批量大小。 |
优化技巧, 内存效率。 通过多次前向-反向传播累积梯度,实现更大的有效批量大小。 |
场景: 当GPU内存不足以容纳大批量时, 训练大模型。 |
gi: 第 i个小批量的梯度。 |
累加: G=∑i=1Ngi。 |
描述为“在多个小批量上重复前向和反向传播,累积梯度但不更新参数,累积一定步数后,用累积梯度(或平均梯度)更新一次参数”。 |
1. 初始化累积梯度 G=0,计数器 count=0。 |
“梯度缓冲”流: 在标准训练中,梯度流 gi产生后立即用于更新参数流 θ。在梯度累积中,梯度流被暂时存储到累积缓冲区 G中。经过 N个小批量,N个梯度流汇合成一个累积梯度流 G。然后这个累积流被用于更新参数流,模拟了一个批量大小为 N×micro-batch size的更新。这允许在有限内存下使用更大的有效批量。 |
梯度累积在单个GPU或数据并行中均可使用。每个GPU独立计算本地梯度并累积。在数据并行中,如果使用梯度平均,需要在累积 N步后对所有GPU的累积梯度进行AllReduce,然后更新参数。 |
批量大小, 优化器。 |
|
AI-A0-0260 |
并行训练 |
PD分离领域 |
一种优化技巧,限制梯度范数,防止梯度爆炸。 |
梯度裁剪 (Gradient Clipping) |
|
编号 |
类别 |
领域 |
模型配方 |
数学公式/定理/算法/模型/方法名称 |
数学公式/定理/算法/模型/方法的逐步思考推理过程及每一个步骤的数学方程式和参数选择/优化/迭代 |
精度/密度/误差/强度 |
底层规律/理论 |
典型应用场景和特征 |
变量/常量/参数列表及说明 |
数学特征 |
语言特征 |
时序和交互流程的所有细节/分步骤时序情况及数学方程式 |
流动模型和流向方法的数学描述 |
多GPU芯片执行情况和方程式列表 |
关联知识和算法 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
AI-A0-0260 |
优化技巧 |
PD分离领域 |
在训练过程中限制梯度范数,防止梯度爆炸。 |
梯度裁剪 (Gradient Clipping) |
1. 计算梯度范数: g=∇θL,总梯度范数 $ |
g |
_2 = \sqrt{\sum_i g_i^2}。<br>∗∗2.裁剪:∗∗如果 |
g |
_2 > threshold,则g = g \cdot \frac{threshold}{ |
g |
|||||
|
AI-A0-0261 |
优化技巧 |
PD分离领域 |
在训练过程中,将部分模型参数或激活从GPU内存转移到CPU内存或硬盘,以节省GPU内存。 |
卸载 (Offloading) |
1. 识别: 选择可以卸载的数据,如前向传播中的中间激活、优化器状态、梯度等。 |
目的: 在有限的GPU内存下训练更大模型。 |
内存优化, 计算换内存。 通过将数据暂时移到低速存储来节省GPU内存。 |
场景: 训练极大模型, GPU内存严重不足时。 |
MGPU: GPU内存容量。 |
数据传输: GPU ↔ CPU。 |
描述为“将部分模型数据(如激活、梯度)从GPU内存转移到CPU内存,需要时再移回,以节省GPU内存”。 |
1. 在前向传播中,将某些层的输出激活从GPU复制到CPU内存,并释放GPU内存。 |
“卸载流”: 数据流在GPU和CPU之间流动。在前向流中,部分激活流被转移到CPU存储流中保存。在反向流中,这些激活流被取回GPU用于梯度计算。这扩大了可用内存流,但引入了数据传输延迟流。 |
卸载通常通过异步传输和计算重叠来减少开销。在多GPU中,每个GPU可以独立卸载自己的数据,但需要注意同步。 |
激活检查点, 内存优化。 |
|
AI-A0-0262 |
优化技巧 |
PD分离领域 |
一种权重初始化方法,根据输入和输出维度调整初始化方差,保持前向和反向传播的方差稳定。 |
Xavier初始化 (Glorot初始化) |
1. 均匀分布: W∼U[−nin+nout6,nin+nout6],其中 nin和 nout是输入和输出维度。 |
适用: 使用sigmoid或tanh等饱和激活函数的网络。 |
权重初始化, 方差缩放。 根据输入输出维度调整初始化范围,防止梯度消失或爆炸。 |
场景: 全连接层, 卷积层(需调整维度计算), 使用sigmoid/tanh的网络。 |
W: 权重矩阵,形状 (nout,nin)。 |
均匀分布: 边界由 6/(nin+nout)决定。 |
描述为“权重从均匀或正态分布中初始化,其方差与输入和输出维度的和成反比”。 |
1. 计算缩放因子 scale=6/(nin+nout)(均匀分布)或 std=2/(nin+nout)(正态分布)。 |
“方差均衡”流: Xavier初始化确保权重矩阵 W的初始化方差与输入维度 nin和输出维度 nout相关,使得前向传播中激活的方差和反向传播中梯度的方差在各层之间大致保持稳定,避免梯度消失或爆炸。 |
初始化在训练开始前执行一次。在多GPU上,每个GPU独立初始化相同的权重(如果使用相同随机种子),或按模型并行分区初始化。 |
Kaiming初始化, 权重初始化。 |
|
AI-A0-0263 |
优化技巧 |
PD分离领域 |
针对ReLU及其变体设计的权重初始化方法,保持前向传播中激活的方差不变。 |
Kaiming初始化 (He初始化) |
1. 正态分布: W∼N(0,nin2),其中 nin是输入维度。 |
适用: 使用ReLU、LeakyReLU等非饱和激活函数的网络。 |
权重初始化, 方差缩放。 针对ReLU族激活函数调整初始化方差。 |
场景: 使用ReLU的深度神经网络, 如ResNet、Transformer(FFN中的ReLU/GELU)。 |
W: 权重矩阵,形状 (nout,nin)。 |
方差: Var(W)=(1+a2)nin2,对于ReLU a=0,故为 nin2。 |
描述为“针对ReLU激活函数,权重初始化方差与输入维度成反比,并考虑激活函数的稀疏性”。 |
1. 确定激活函数参数 a(ReLU为0,LeakyReLU为负斜率)。 |
“ReLU方差校正”流: Kaiming初始化考虑了ReLU激活函数会将一半的激活置零,导致方差减半。因此,初始化时将权重方差放大一倍(nin2对比 Xavier 的 nin+nout2),以补偿这种稀疏性,确保各层激活方差稳定。 |
同Xavier初始化,在训练前执行。对于Transformer,FFN层的权重通常使用Kaiming初始化。 |
Xavier初始化, ReLU, 权重初始化。 |
|
AI-A0-0264 |
正则化 |
Token领域 |
在标签分布中引入噪声,将硬标签(one-hot)转换为软标签,防止模型过度自信。 |
标签平滑 (Label Smoothing) |
1. 硬标签: 对于真实类别 y,one-hot向量 q满足 qy=1,其他为0。 |
效果: 防止模型对正确类别过度自信, 提高泛化能力, 减轻过拟合。 |
正则化, 校准。 通过软化标签分布,鼓励模型保留不确定性。 |
场景: 分类任务, 尤其是大规模分类(如ImageNet)。 |
q: 原始one-hot标签向量。 |
凸组合: (1−ϵ)q+ϵu。 |
描述为“将真实标签的1减去一个小量,并将这个小量均匀分配到其他类别上,得到软标签”。 |
1. 给定真实类别 y,创建one-hot向量 q。 |
“标签软化”流: 硬标签流(one-hot)包含绝对确定性,可能促使模型过度拟合。标签平滑将硬标签流与均匀噪声流混合,产生一个较软的标签流。这个软标签流鼓励模型对正确类别的预测概率接近 1−ϵ,同时对其他类别赋予小的概率 ϵ/K,从而保留一定程度的不确定性,提高泛化。 |
标签平滑在数据加载或损失计算时进行,计算简单。在多GPU数据并行中,每个GPU独立对本地数据的标签进行平滑。 |
交叉熵损失, 正则化。 |
|
AI-A0-0265 |
正则化 |
Token领域 |
在训练过程中,随机将一部分神经元的输出置零,防止过拟合。 |
Dropout |
1. 训练阶段: 对于每一层,每个神经元以概率 p(dropout率)被置零,否则其输出乘以 1/(1−p)(缩放)。 |
作用: 防止过拟合, 提高模型泛化能力, 相当于模型平均。 |
正则化, 模型平均。 通过随机丢弃神经元,强制网络不依赖特定神经元,提高鲁棒性。 |
场景: 全连接层, 卷积层, 注意力层(如Transformer中的dropout)。 |
x: 输入向量或矩阵。 |
随机: 伯努利分布。 |
描述为“在训练时,随机将一部分神经元的输出置零,其余神经元按比例放大,以保持期望不变;测试时直接使用所有神经元”。 |
训练时: |
“随机子网络”流: 在每次前向传播中,Dropout随机选择神经元子集构成一个“子网络”。信息流只能通过未被丢弃的神经元流动。这迫使网络学习冗余表示,不依赖于任何单个神经元。缩放操作确保信息流的总体强度在训练和测试间一致。 |
Dropout操作是逐元素乘法,可并行。掩码生成是随机的,但可以同步随机种子以确保多GPU一致性。在Transformer中,dropout常用于注意力权重和FFN激活后。 |
正则化, 模型平均。 |
|
AI-A0-0266 |
正则化 |
Token领域 |
在注意力权重上应用dropout,随机丢弃一些注意力连接。 |
注意力Dropout (Attention Dropout) |
1. 位置: 在softmax之后,对注意力权重矩阵 A应用dropout。 |
作用: 防止注意力机制过拟合, 提高泛化, 增加注意力头的多样性。 |
Dropout, 注意力机制。 在注意力权重上随机丢弃,减少特定注意力连接的依赖。 |
场景: Transformer的注意力层。 |
A: 注意力权重矩阵,形状 (L,L)或 (h,L,L)(多头)。 |
随机: 元素级丢弃。 |
描述为“对softmax后的注意力权重矩阵进行dropout,随机将一部分注意力权重置零”。 |
1. 计算注意力分数 S=QKT/dk。 |
“注意力连接随机化”流: 注意力权重流表示不同位置间的重要性分配。注意力dropout随机切断一部分注意力连接(权重置零),迫使模型不过度依赖某些特定的注意力模式,从而学习更鲁棒的表示。这可以看作是在注意力图上进行随机子图采样。 |
同标准dropout,逐元素操作,可并行。在多GPU上,每个头独立应用dropout,掩码可以不同,但通常同步随机种子以确保一致性。 |
Dropout, 注意力机制。 |
|
AI-A0-0267 |
模型架构 |
Token领域 |
一种稀疏注意力模式,将序列划分为块,每个块内进行局部注意力,块之间通过全局token连接。 |
BigBird (稀疏注意力) |
1. 注意力模式: 结合三种注意力:随机注意力、局部窗口注意力、全局token注意力。 |
优点: 将注意力复杂度从 O(L2)降低到 O(L), 可处理更长序列。 |
稀疏注意力, 图论。 通过限制每个token的注意力范围,实现线性复杂度,同时保持全局信息流。 |
场景: 长文本建模, 如文档分类、长序列问答。 |
L: 序列长度。 |
稀疏矩阵: A是稀疏的,非零元素数 O(L)。 |
描述为“每个token只关注三类token:随机选择的少数token、相邻的局部窗口内的token、以及一些全局token,从而大幅减少注意力计算量”。 |
**1. 构建稀疏注意力矩阵 A: |
“稀疏信息流”: 注意力流被限制在稀疏图 A定义的路径上。局部窗口流确保每个token能感知其邻近上下文;随机流引入远程连接,允许信息在任意两个token间以一定概率流动;全局流通过少数全局token作为枢纽,收集和分发全局信息。这三种流的组合使得整个序列的信息可以在线性复杂度内有效传递。 |
BigBird的稀疏注意力模式允许使用稀疏矩阵乘法或掩码实现。在多头注意力中,每个头可以共享相同的稀疏模式或使用不同的随机模式。在多GPU中,序列可以按块划分,但全局token需要特殊处理(如广播)。 |
Longformer, Sparse Transformer。 |
|
AI-A0-0268 |
模型架构 |
Token领域 |
一种稀疏注意力模式,结合局部滑动窗口注意力和任务特定的全局注意力(如全局token)。 |
Longformer (稀疏注意力) |
1. 注意力模式: 主要使用局部滑动窗口注意力,每个token关注其前后 w个token(窗口大小为 2w+1)。 |
优点: 线性复杂度 O(L×w), 可处理数千token的序列。 |
稀疏注意力, 滑动窗口。 通过局部窗口注意力捕获局部上下文,通过全局注意力捕获长距离依赖。 |
场景: 长文档建模, 如文本分类、问答、摘要。 |
L: 序列长度。 |
带状矩阵: 局部注意力对应带状稀疏矩阵。 |
描述为“使用滑动窗口注意力,每个token只关注其附近固定窗口内的token,同时为一些特定token(如问题token)添加全局注意力,使其关注所有token并被所有token关注”。 |
1. 对于每个位置 i: |
“局部+全局流”: 大多数token的信息流被限制在局部窗口内,形成局部流。全局token作为信息枢纽,形成全局流:所有token的信息流向全局token,全局token的信息也流向所有token。这种设计使得模型既能高效处理长序列,又能通过全局token捕获整个序列的上下文。 |
Longformer的滑动窗口注意力可以通过带状矩阵乘法或因果掩码实现。全局注意力需要全连接计算,但全局token数量很少。在多GPU中,序列可以分区,但全局token可能需要跨GPU通信。 |
BigBird, Sparse Transformer。 |
|
AI-A0-0269 |
模型架构 |
Token领域 |
将注意力计算分解为多个块,通过局部和全局交互来近似标准注意力。 |
Reformer (局部敏感哈希注意力) |
1. 局部敏感哈希(LSH): 将查询和键投影到低维空间,并使用哈希函数将相似的向量分配到相同的桶中。 |
优点: 将注意力复杂度从 O(L2)降低到 O(LlogL), 内存效率高。 |
稀疏注意力, 局部敏感哈希。 利用LSH将相似的查询和键分组,只在组内计算注意力,减少计算量。 |
场景: 极长序列, 如蛋白质序列、长文档。 |
Q,K: 查询和键矩阵,形状 (L,dk)。 |
LSH: 近似最近邻搜索技术。 |
描述为“使用局部敏感哈希将查询和键映射到哈希桶中,使得相似的向量落入同一个桶,然后只在每个桶内计算注意力,从而大幅减少计算量”。 |
1. 计算查询 Q和键 K。 |
“哈希分桶流”: 查询流 Q和键流 K通过LSH函数被映射到哈希桶中。相似度高的向量流倾向于落入同一个桶。注意力流被限制在每个桶内部以及相邻块之间。这样,每个token只与同一桶内和相邻块的token进行注意力交互,避免了全序列的成对计算,实现了近似但高效的注意力。 |
Reformer需要计算LSH哈希和分桶排序,这些操作在GPU上可能效率较低。桶内注意力可以并行计算,但负载可能不均衡。在多GPU中,需要根据哈希值重新分布序列,通信开销较大。 |
LSH, 稀疏注意力。 |
|
AI-A0-0270 |
模型架构 |
Token领域 |
将注意力计算分解为块稀疏形式,通过组合局部和全局注意力块来近似全注意力。 |
Block-Sparse Transformer |
1. 分块: 将序列划分为多个块(如每块64个token)。 |
优点: 通过减少块间注意力计算, 降低计算和内存复杂度。 |
稀疏注意力, 块计算。 在块级别进行稀疏注意力,减少计算量。 |
场景: 长序列建模, 如图像、音频、长文本。 |
L: 序列长度。 |
块矩阵: 注意力矩阵是块稀疏的。 |
描述为“将序列分成块,每个块只与预先定义的一组其他块计算注意力,而不是与所有块计算,从而减少计算量”。 |
1. 将输入序列划分为 N个块,每块 B个token。 |
“块稀疏流”: 序列流被划分为块流。注意力流只在被允许的块对之间流动。例如,局部模式中,每个块只关注相邻的几个块;随机模式中,每个块随机关注几个其他块;全局模式中,某些块关注所有块。这种块级别的稀疏流大大减少了注意力计算的总量,同时保留了重要的长距离依赖。 |
块稀疏注意力可以利用块矩阵乘法优化。在多头注意力中,每个头可以使用不同的稀疏模式。在多GPU中,序列块可以分布在不同GPU上,注意力计算需要跨GPU通信相关块。 |
Sparse Transformer, BigBird。 |
|
AI-A0-0271 |
模型架构 |
Token领域 |
通过低秩分解近似注意力矩阵,将复杂度从 O(L2)降为 O(L)。 |
Linformer (线性注意力) |
1. 低秩投影: 将键 K和值 V从 L×d投影到 k×d,其中 k是投影维度(k≪L)。 |
核心思想: 注意力矩阵 P=softmax(QKT/d)是低秩的, 可以用低维投影近似。 |
低秩近似, 线性复杂度。 通过将键和值投影到低维空间,实现线性复杂度的注意力。 |
场景: 长序列编码, 如文档分类, 但仅适用于编码器(非自回归)。 |
Q,K,V: 查询、键、值矩阵,形状 (L,d)。 |
低秩投影: K∈RL×d→K~∈Rk×d。 |
描述为“将键和值矩阵通过投影压缩到固定长度,然后与查询矩阵计算注意力,使计算复杂度与序列长度呈线性关系”。 |
1. 输入 Q,K,V,形状 (L,d)。 |
“压缩流”: 键流 K和值流 V被投影矩阵 E和 F压缩到低维空间,形成压缩的键流 K~和值流 V~。注意力流变为:查询流 Q与压缩键流 K~交互,产生注意力权重流 P(L×k),然后与压缩值流 V~聚合。由于 k是固定的,整个流程的复杂度与序列长度 L成线性关系。 |
Linformer的投影操作是矩阵乘法,可以高效并行。投影矩阵 E和 F可以是可学习的参数。在多GPU中,序列可以按长度划分,但投影操作可能需要全局聚合(如果 E和 F是全局的)。 |
低秩近似, 线性注意力。 |
|
AI-A0-0272 |
模型架构 |
Token领域 |
通过核函数将注意力计算重写为查询和键的特征映射的点积,然后利用矩阵乘法的结合律实现线性复杂度。 |
Linear Attention (线性注意力,核函数方法) |
1. 标准注意力: O=softmax(dQKT)V。 |
关键: 找到合适的特征映射 ϕ来近似softmax核。 |
核方法, 线性复杂度。 通过核技巧将注意力分解为线性运算。 |
场景: 需要线性复杂度的自回归或非自回归模型。 |
Q,K,V: 查询、键、值,形状 (L,d)。 |
核函数: k(q,k)=ϕ(q)Tϕ(k)近似 exp(qTk/d)。 |
描述为“使用核函数将注意力中的指数点积转化为特征映射的点积,然后利用矩阵乘法的结合律先计算键和值的聚合,再与查询相乘,实现线性复杂度”。 |
1. 计算特征映射:Q~=ϕ(Q), K~=ϕ(K),形状 (L,m)。 |
“核化线性流”: 查询流 Q和键流 K通过特征映射 ϕ转换为高维特征流 Q~和 K~。注意力计算被分解为两个流:键值聚合流 K~TV和键和流 K~T1。然后,查询流 Q~分别与这两个聚合流相乘,并通过除法归一化。这个流程将二次复杂度转化为线性复杂度,因为聚合操作 (K~TV)和 (K~T1)的计算与 L无关(m固定)。 |
Linear Attention需要计算特征映射,可能增加计算开销,但整体复杂度仍是线性的。特征映射 ϕ可以是简单的函数(如elu+1)。在自回归情况下,需要因果掩码,但线性注意力仍然可以应用,因为聚合可以递归计算。在多GPU中,序列可以分区,但聚合操作可能需要跨GPU归约。 |
核方法, 高效注意力。 |
|
AI-A0-0273 |
模型架构 |
Token领域 |
使用正交随机特征(ORF)近似softmax核,实现线性注意力。 |
Performer (随机特征注意力) |
1. 随机特征映射: 使用随机特征来近似softmax核。具体地,exp(qTk)=Eω∼N(0,I)[exp(ωTq−∥q∥2/2)exp(ωTk−∥k∥2/2)]。 |
优点: 无偏近似softmax, 线性复杂度, 支持自回归训练和推理。 |
随机特征, 核近似, 线性复杂度。 使用随机特征映射来近似softmax核,实现线性注意力。 |
场景: 长序列建模, 需要精确softmax近似的场景。 |
Q,K,V: 查询、键、值,形状 (L,d)。 |
随机特征: ϕ(x)=m1exp(Wx−∥x∥2/2)。 |
描述为“使用正交随机特征来近似softmax核函数,将注意力计算转化为线性形式,从而实现线性复杂度”。 |
1. 生成随机正交矩阵 W(或从正态分布采样后正交化)。 |
“随机特征流”: 查询流 Q和键流 K通过随机特征映射 ϕ转换,其中 ϕ使用随机正交矩阵 W和指数函数。这个映射流将原始的指数点积核近似为随机特征的点积。然后,与线性注意力相同,进行键值聚合流和键和聚合流,最后与查询特征流结合。随机特征流提供了对softmax核的无偏估计,且方差较小。 |
Performer需要生成随机矩阵 W,可以在训练前固定或定期更新。特征映射涉及指数计算,可能数值不稳定,需要小心实现。在多GPU中,W在所有GPU上一致,特征映射可以独立计算。 |
线性注意力, 随机特征。 |
|
AI-A0-0274 |
模型架构 |
Token领域 |
在多头注意力中,将键和值在多个头之间共享,减少参数和计算量。 |
分组查询注意力 (Grouped-Query Attention, GQA) |
1. 分组: 将 h个头分为 g组,每组共享相同的键和值投影。设 h是头数,g是组数(g<h)。 |
优点: 减少键值缓存的内存占用, 加快推理速度, 同时保持与多头注意力相近的性能。 |
注意力机制, 参数共享。 多个查询头共享相同的键和值投影,减少参数和推理时键值缓存。 |
场景: 大语言模型推理, 如LLaMA-2 70B, 用于减少内存和加速。 |
h: 总头数。 |
共享: 每组共享键值投影。 |
描述为“将注意力头分成若干组,每组内的头共享相同的键和值投影,但每个头仍有独立的查询投影,从而在推理时减少键值缓存的大小”。 |
1. 将 h个头分为 g组,每组有 h/g个头(假设可整除)。 |
“分组共享流”: 键流 K和值流 V被投影到 g组共享的流 Kj和 Vj。查询流 Q被投影到 h个独立的流 Qi。在注意力计算流中,属于同一组的多个查询流 Qi与同一组键值流 Kj,Vj交互。这减少了需要存储的键值流的数量,从而降低了内存带宽需求,加速了推理。 |
GQA在推理时显著减少键值缓存的内存占用,因为只需要缓存 g组键值,而不是 h组。在训练时,键值投影的梯度会被组内所有头共享。在多GPU中,分组可以结合张量并行来分配。 |
多头注意力, 多查询注意力。 |
|
AI-A0-0275 |
模型架构 |
Token领域 |
分组查询注意力的极端情况,所有头共享同一组键和值投影。 |
多查询注意力 (Multi-Query Attention, MQA) |
1. 共享键值: 所有头共享相同的键投影 WK和值投影 WV,即 g=1。 |
优点: 极大减少键值缓存, 显著加速推理, 但可能轻微降低模型质量。 |
注意力机制, 参数共享。 所有查询头共享同一组键和值投影,极大减少内存占用。 |
场景: 对推理速度和内存有严格要求的场景, 如大规模部署。 |
h: 头数。 |
共享: 所有头共享 K′和 V′。 |
描述为“所有注意力头共享同一组键和值投影,但每个头有自己独立的查询投影,从而大幅减少推理时的键值缓存”。 |
1. 计算共享键和值:K′=KWK, V′=VWV。 |
“单键值流”: 键流 K和值流 V只被投影一次,生成共享的键流 K′和值流 V′。查询流 Q被投影 h次,生成 h个独立的查询流 Qi。在注意力流中,所有查询流 Qi都与同一个键流 K′和值流 V′交互。这极大地减少了需要缓存和传输的键值数据量,提高了推理效率,但限制了不同头关注不同键值子空间的能力。 |
MQA在推理时键值缓存最小,只需存储一份键值。在训练时,键值投影的梯度来自所有头。在多GPU中,共享键值可以存储在单个GPU上或广播,减少通信。 |
分组查询注意力, 多头注意力。 |
|
AI-A0-0276 |
模型架构 |
Token领域 |
一种IO感知的精确注意力算法,通过分块和重计算减少内存访问,提高计算效率。 |
Flash Attention |
1. 目标: 计算注意力输出 O=softmax(QKT)V,同时减少高带宽内存(HBM)与片上内存(SRAM)之间的数据传输。 |
优点: 大幅减少内存访问, 加速注意力计算, 支持长序列。 |
算法优化, 内存层次。 利用GPU内存层次,通过分块和重计算优化注意力计算的内存效率。 |
场景: 训练和推理大模型, 尤其是长序列场景。 |
Q,K,V: 查询、键、值矩阵,形状 (L,d)。 |
分块矩阵乘法: QKT分块计算。 |
描述为“将注意力计算分块进行,在片上内存中逐块计算注意力分数和输出,并使用在线softmax避免存储整个注意力矩阵,从而减少内存访问”。 |
1. 初始化输出 O=0,softmax分母 l=0,最大值 m=−∞。 |
“分块流”: 查询流 Q被分成小块流 Qi,键值流 K,V被分成小块流 Kj,Vj。注意力计算流在SRAM中进行:对于每个 Qi,依次与所有 Kj,Vj块流交互,通过在线softmax流逐步更新输出流 Oi。这种流避免了将整个 QKT矩阵流经HBM,减少了数据移动。 |
Flash Attention 利用GPU的共享内存(SRAM)进行块计算,减少全局内存(HBM)访问。在多GPU中,序列可以分区,每个GPU计算本地注意力,但需要全局通信来聚合结果(如模型并行)。Flash Attention 可以结合模型并行使用。 |
注意力机制, 在线softmax。 |
|
AI-A0-0277 |
模型架构 |
Token领域 |
一种线性偏置方法,在注意力分数中添加一个与相对距离成比例的偏置,无需学习的位置嵌入。 |
ALiBi (Attention with Linear Biases) |
1. 偏置项: 在注意力分数 Sij=qiTkj上添加一个与相对距离 j−i成比例的负偏置:$\tilde{S}{ij} = S{ij} - m \cdot |
j-i |
,其中m是头特定的斜率。<br>∗∗2.斜率设置:∗∗对于头h(从0开始计数),m_h = 2^{-8h/H},其中H是总头数。<br>∗∗3.注意力计算:∗∗\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T - m \cdot D}{\sqrt{d_k}}\right) V,其中D_{ij} = |
j-i |
(对于自回归解码器,j > i时D_{ij} = \infty$ 或大数,以掩码未来位置)。 |
优点: 无需位置嵌入, 外推性好, 在长序列上表现优异。 |
位置编码, 相对位置。 通过添加与相对距离成比例的线性偏置来注入位置信息。 |
场景: 自回归语言模型, 如GPT-like模型, 尤其擅长外推到更长序列。 |
qi,kj: 查询和键向量。 |
j-i |
。<br>∗∗H:∗∗总头数。<br>∗∗h$:** 头索引(0-based)。 |
|
AI-A0-0278 |
模型架构 |
Token领域 |
一种位置编码方法,通过旋转位置编码将绝对位置信息注入到注意力机制中,保持相对位置的相对性。 |
旋转位置编码 (Rotary Position Embedding, RoPE) |
1. 将位置信息融入查询和键: 对于位置 m的查询向量 qm和位置 n的键向量 kn,通过旋转矩阵 RΘ,m和 RΘ,n进行变换:q~m=RΘ,mqm, k~n=RΘ,nkn,其中 RΘ,m是一个旋转矩阵,Θ是预设的频率参数。 |
优点: 保持相对位置关系, 可外推, 在长序列上表现好。 |
位置编码, 相对位置, 复数旋转。 通过旋转操作将绝对位置信息注入查询和键,使注意力分数仅依赖于相对位置。 |
场景: LLaMA、GPT-NeoX等现代大语言模型。 |
qm,kn: 位置 m和 n的查询和键向量,维度 d。 |
旋转矩阵: 块对角矩阵,每个块是2D旋转矩阵。 |
描述为“将查询和键向量视为复数,根据其位置进行旋转,使得点积注意力分数仅依赖于相对位置”。 |
1. 将查询 q和键 k重塑为复数形式:将每两个连续维度视为一个复数(实部和虚部)。 |
“旋转流”: 查询流 qm和键流 kn根据其绝对位置 m和 n分别进行旋转操作流。旋转角度由预设的频率 θi和位置决定。旋转后的查询 q~m和键 k~n的点积结果只依赖于相对位置 m−n,因为旋转操作在复数乘法中表现为相位差。这使得模型能够自然地捕捉相对位置信息,并具有良好的外推性。 |
RoPE在计算注意力之前应用于查询和键。计算可以向量化。在多GPU中,每个GPU持有序列的一部分,需要知道其全局位置以进行旋转。旋转操作是逐元素的,可以并行计算。 |
相对位置编码, 注意力机制。 |
|
AI-A0-0279 |
模型架构 |
Token领域 |
层归一化的变体,仅对输入进行缩放,不进行平移,且使用RMS(均方根)进行归一化。 |
RMSNorm (Root Mean Square Layer Normalization) |
1. 计算RMS: 对于输入 x∈Rd,RMS(x)=d1∑i=1dxi2。 |
特点: 去除了均值中心化, 仅使用RMS进行缩放, 计算更简单, 在有些模型中表现与LayerNorm相当。 |
归一化, 缩放。 使用均方根进行归一化,仅学习缩放参数,简化计算。 |
场景: LLaMA、T5等模型, 作为LayerNorm的替代。 |
x: 输入向量,维度 d。 |
均方根: 平方和的平均再开方。 |
描述为“计算输入向量的均方根,然后用它来缩放输入,最后乘以可学习的缩放参数”。 |
1. 计算 RMS=d1∑i=1dxi2+ϵ。 |
“RMS缩放”流: 输入流 x首先计算其均方根流 RMS(x),该流衡量了输入的总体幅度。然后,输入流被 RMS(x)缩放,得到一个单位RMS的流 x^。最后,通过可学习的缩放参数流 g对每个维度进行重新缩放,恢复模型的表达能力。与LayerNorm相比,它省略了减去均值的步骤,假设零均值已由前一层的偏置项处理。 |
RMSNorm计算比LayerNorm少一步均值计算,因此略高效。同样可并行计算。在多GPU中,每个样本独立计算RMS,然后进行缩放。 |
LayerNorm, 归一化。 |
|
AI-A0-0280 |
模型架构 |
Token领域 |
一种门控激活函数,结合了Swish(SiLU)和GLU(Gated Linear Unit)的思想。 |
SwiGLU |
1. 定义: SwiGLU(x,W,V,b,c)=Swish(xW+b)⊙(xV+c),其中 Swish(x)=xσ(x),σ是sigmoid函数,⊙是逐元素乘法。 |
优点: 比ReLU或GELU表现更好, 在PaLM等大模型中采用。 |
激活函数, 门控机制。 通过Swish激活的门控线性单元,增强非线性表达能力。 |
场景: Transformer的FFN层, 替代标准ReLU/GELU FFN。 |
x: 输入,形状 (L,dmodel)。 |
门控: 逐元素乘法。 |
|
编号 |
类别 |
领域 |
模型配方 |
数学公式/定理/算法/模型/方法名称 |
数学公式/定理/算法/模型/方法的逐步思考推理过程及每一个步骤的数学方程式和参数选择/优化/迭代 |
精度/密度/误差/强度 |
底层规律/理论 |
典型应用场景和特征 |
变量/常量/参数列表及说明 |
数学特征 |
语言特征 |
时序和交互流程的所有细节/分步骤时序情况及数学方程式 |
流动模型和流向方法的数学描述 |
多GPU芯片执行情况和方程式列表 |
关联知识和算法 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
AI-A0-0280 |
推理优化 |
推理领域 |
一种用于自回归模型推理的优化技术,通过维护键值缓存来避免重复计算。 |
键值缓存 (Key-Value Cache) |
1. 缓存结构: 对于每个Transformer层,维护两个缓存:键缓存 Kcache和值缓存 Vcache,分别存储历史时间步的键和值。 |
优点: 大幅减少自回归推理时的计算量, 从 O(n2)降为 O(n)(每个时间步)。 |
动态规划, 缓存。 通过缓存历史键值避免重复计算,提高自回归生成效率。 |
场景: 自回归语言模型推理, 如GPT、LLaMA等。 |
kt,vt: 当前时间步的键和值向量。 |
追加: 将新向量追加到缓存矩阵。 |
描述为“在自回归生成过程中,将每个时间步计算出的键和值保存起来,后续时间步直接使用缓存,避免重新计算历史token的键值”。 |
1. 初始化:Kcache=[], Vcache=[]。 |
“缓存流”: 键流和值流在生成过程中被持续存入缓存流。每个新时间步,查询流与整个缓存流进行注意力计算,生成输出流。缓存流随着生成不断增长,但避免了重新计算历史流。 |
键值缓存需要为每个层和每个头维护缓存,内存占用与序列长度和层数成正比。在多GPU推理中,如果使用模型并行,每个GPU维护自己部分的缓存。 |
自回归生成, 注意力机制。 |
|
AI-A0-0281 |
推理优化 |
推理领域 |
一种推理加速技术,通过跳过部分层或头的计算来减少推理时间。 |
层跳跃 (Layer Skipping) |
1. 决策: 对于每个输入样本,动态决定跳过哪些层或注意力头。决策可以基于输入特征、中间激活的阈值等。 |
优点: 减少计算量, 加速推理。 |
动态计算, 自适应推理。 根据输入难度自适应跳过部分计算,提高效率。 |
场景: 对推理速度要求高, 且可以接受轻微性能下降的场景。 |
xl: 第 l层的输入。 |
条件执行: yl=zl⋅fl(xl)+(1−zl)⋅xl。 |
描述为“根据输入样本的特征,动态决定是否执行某些层或注意力头,跳过不必要的计算”。 |
1. 对于每个输入样本,逐层处理: |
“条件计算流”: 网络流在每一层经过一个决策节点,决定是否进入该层的计算流。如果跳过,则输入流直接绕过该层流;否则,输入流进入该层流进行变换。这使得简单样本可以快速通过,复杂样本经历更多计算流。 |
层跳跃在推理时可以减少计算量,但决策本身可能引入开销。在多GPU中,跳跃决策可能导致负载不均衡。 |
动态网络, 条件计算。 |
|
AI-A0-0282 |
推理优化 |
推理领域 |
一种推理加速技术,将模型量化为低精度(如INT8)以减少内存占用和加速计算。 |
训练后量化 (Post-Training Quantization, PTQ) |
1. 校准: 使用少量校准数据,计算每一层激活的统计量(如最大值、最小值)。 |
优点: 减少模型大小, 加速推理, 降低内存带宽需求。 |
模型压缩, 量化。 将模型参数和激活从高精度浮点数量化为低精度整数,以加速推理。 |
场景: 边缘设备部署, 需要减少模型大小和加速推理。 |
x: 原始FP32张量。 |
x |
)}{127}。<br>∗∗x_{\text{int8}}$:** 量化后的INT8张量。 |
线性量化: xint8=round(x/s)。 |
描述为“使用校准数据确定缩放因子,将训练好的模型权重和激活量化为低精度整数,推理时再进行反量化或直接使用整数计算”。 |
1. 准备少量校准数据。 |
“量化压缩流”: 原始高精度权重流和激活流通过量化操作被压缩为低精度整数流。在推理时,整数流通过反量化恢复为近似的高精度流进行计算,或者直接使用整数运算流。这减少了数据流的大小,提高了计算效率。 |
|
AI-A0-0283 |
推理优化 |
推理领域 |
一种推理加速技术,在训练过程中模拟量化操作,使模型适应量化误差。 |
量化感知训练 (Quantization-Aware Training, QAT) |
1. 插入伪量化节点: 在训练的前向传播中,在权重和激活后插入伪量化操作,模拟量化过程。伪量化包括量化和反量化:xquant=quantize(x)=dequantize(round(x/s))。 |
优点: 相比PTQ, 通常精度损失更小, 模型更适应量化。 |
量化, 训练模拟。 在训练中模拟量化过程,使模型参数适应低精度表示。 |
场景: 对精度要求较高的量化部署。 |
x: 原始张量。 |
伪量化: xquant=dequantize(round(x/s))。 |
描述为“在训练过程中插入模拟量化的操作,使模型在训练时就适应量化带来的误差,从而在真正量化时保持更高精度”。 |
1. 在训练图中插入伪量化节点:在权重和激活后加入量化和反量化操作。 |
“量化模拟流”: 在训练流中,权重流和激活流经过伪量化模块,该模块模拟了量化噪声流。模型参数在噪声流下调整,使得最终模型对量化不敏感。训练完成后,真正的量化流取代模拟流。 |
QAT训练时需要模拟量化操作,可能增加训练时间。在推理时,与PTQ类似,可以使用低精度计算。 |
训练后量化, 模型压缩。 |
|
AI-A0-0284 |
推理优化 |
推理领域 |
一种推理加速技术,将多个小矩阵乘法合并为一个大矩阵乘法,以提高GPU利用率。 |
矩阵乘法融合 (Matrix Multiplication Fusion) |
1. 识别: 在计算图中识别可以融合的连续矩阵乘法操作。例如,多个线性层可以合并为一个更大的线性层。 |
优点: 减少内核启动开销, 提高GPU利用率, 加速计算。 |
计算图优化, 算子融合。 将多个连续的线性变换合并为一个,减少计算和内存访问开销。 |
场景: 深度学习模型推理, 尤其是Transformer中的线性层。 |
W1,W2: 两个权重矩阵。 |
矩阵乘法结合律: W2(W1x)=(W2W1)x。 |
描述为“将多个连续的线性变换合并为一个线性变换,通过矩阵乘法的结合律减少计算步骤”。 |
1. 分析计算图,找到连续的线性变换(中间无非线性激活)。 |
“融合流”: 多个线性变换流被合并为一个等效的线性变换流。输入流直接与融合后的权重流相乘,得到输出流,跳过了中间流,减少了计算和内存流。 |
矩阵乘法融合可以在编译时或运行时进行。在GPU上,大矩阵乘法可以更高效地利用Tensor Core。在多GPU中,融合后的矩阵可能更大,需要相应的并行策略。 |
算子融合, 计算图优化。 |
|
AI-A0-0285 |
推理优化 |
推理领域 |
一种推理加速技术,将多个小操作(如加法、乘法、激活函数)融合为一个内核,减少内核启动开销。 |
算子融合 (Operator Fusion) |
1. 识别模式: 识别计算图中经常连续出现的小操作,如卷积后接批归一化再接激活函数。 |
优点: 减少内核启动和内存访问开销, 加速推理。 |
计算图优化, 内核融合。 将多个逐元素操作或小操作合并为一个内核执行。 |
场景: 深度学习模型推理, 尤其是移动端和边缘设备。 |
多个小操作: 如 y=ReLU(BatchNorm(Conv(x)))。 |
组合函数: 将多个函数合并为一个复合函数。 |
描述为“将多个小的、连续的操作合并为一个内核执行,以减少内核启动次数和中间结果的内存读写”。 |
1. 分析计算图,找到可以融合的操作序列。 |
“内核融合流”: 多个小操作流被合并为一个复合操作流。数据流在融合内核中连续处理,避免了中间结果流写回和读取,提高了数据局部性。 |
算子融合通常由深度学习编译器(如TVM、TensorRT)自动完成。在GPU上,融合内核可以减少全局内存访问,提高带宽利用率。 |
矩阵乘法融合, 计算图优化。 |
|
AI-A0-0286 |
训练优化 |
训练领域 |
一种优化器,结合了动量和自适应学习率,并进行了偏差校正。 |
Adam (Adaptive Moment Estimation) |
1. 初始化: 一阶矩 m0=0,二阶矩 v0=0,时间步 t=0。 |
优点: 自适应学习率, 对噪声鲁棒, 通常收敛快。 |
自适应优化, 动量, 二阶矩。 结合动量法和RMSProp,并引入偏差校正。 |
场景: 深度学习训练, 尤其是Transformer。 |
θ: 模型参数。 |
指数移动平均: 一阶和二阶矩。 |
描述为“维护梯度的一阶矩(动量)和二阶矩(梯度平方)的指数移动平均,进行偏差校正后,用校正后的矩更新参数”。 |
1. 初始化 m=0,v=0,t=0。 |
“自适应动量”流: 梯度流 gt被两个指数移动平均流捕获:一阶矩流 mt(动量)和二阶矩流 vt(梯度平方)。偏差校正流消除初始零偏置。更新流中,每个参数的学习率自适应地由 v^t的平方根倒数缩放,使得梯度大的参数更新小,梯度小的参数更新大。动量流 m^t提供平滑的更新方向。 |
Adam需要为每个参数维护两个状态 m和 v。在数据并行中,梯度聚合后,每个GPU用相同的梯度更新本地状态,因此状态保持一致。在模型并行中,参数和状态分布在多个GPU上,更新需要通信或本地进行。 |
AdamW, RMSProp, 动量法。 |
|
AI-A0-0287 |
训练优化 |
训练领域 |
Adam的变体,将权重衰减与参数更新解耦,直接添加到更新步骤中。 |
AdamW |
1. 计算梯度: gt=∇θL(θt−1)(不包含权重衰减项)。 |
优点: 权重衰减与自适应学习率解耦, 通常比Adam泛化更好。 |
自适应优化, 权重衰减。 将权重衰减从损失函数中分离,直接应用于参数更新,避免与自适应学习率耦合。 |
场景: 训练大型模型如Transformer, 需要权重衰减正则化。 |
θ: 参数。 |
加法项: 更新中直接加 λθ。 |
描述为“在Adam更新公式中,额外添加一个权重衰减项,直接作用于参数,而不是通过损失函数”。 |
1. 计算梯度 gt(不包含权重衰减)。 |
“解耦正则化”流: 在AdamW中,权重衰减流 λθ直接与自适应更新流 αm^t/(v^t+ϵ)相加。这与传统Adam(权重衰减通过损失函数影响梯度)不同,避免了权重衰减与自适应学习率之间的耦合,使得正则化效果更稳定,模型泛化更好。 |
与Adam类似,但更新步骤中多了一项权重衰减。权重衰减项可以本地计算,无需额外通信。在多GPU数据并行中,每个GPU独立计算权重衰减项并更新本地参数副本。 |
Adam, 权重衰减, L2正则化。 |
|
AI-A0-0288 |
训练优化 |
训练领域 |
一种学习率调度策略,学习率在训练过程中按余弦函数从初始值衰减到最小值。 |
余弦退火 (Cosine Annealing) |
1. 学习率公式: ηt=ηmin+21(ηmax−ηmin)(1+cos(TmaxTcurπ)),其中 Tcur是当前步数,Tmax是总步数(或周期长度)。 |
特点: 平滑下降, 避免学习率突变, 有助于模型收敛到更优解。 |
学习率调度, 余弦函数。 使用余弦函数平滑调整学习率。 |
场景: 深度学习训练, 如图像分类、自然语言处理。 |
ηt: 当前学习率。 |
余弦函数: cos(πTcur/Tmax)。 |
描述为“学习率按余弦函数从最大值平滑衰减到最小值”。 |
1. 设置最大学习率 ηmax、最小学习率 ηmin、总步数 Tmax。 |
“余弦衰减”流: 学习率流 ηt随时间 t按余弦曲线从 ηmax平滑下降到 ηmin。这种平滑下降避免了阶梯式下降的突变,允许模型在初期以较大学习率快速收敛,后期以较小学习率精细调整,有助于找到更平坦的最小值。 |
学习率调度器在训练循环中每一步更新学习率。在多GPU训练中,通常由主进程计算学习率并广播,或每个进程独立计算相同值。 |
带热重启的余弦退火, 学习率调度。 |
|
AI-A0-0289 |
训练优化 |
训练领域 |
一种学习率调度策略,学习率在指定步数或epoch处乘以一个衰减因子。 |
步长衰减 (Step Decay) |
1. 定义: 学习率在预定义的步数或epoch处衰减。例如,每 s步将学习率乘以 γ(如0.1)。 |
特点: 简单, 常用, 但衰减可能过于激进。 |
学习率调度, 指数衰减。 按固定步长降低学习率。 |
场景: 各种深度学习任务, 尤其是训练收敛后期。 |
ηt: 当前学习率。 |
指数衰减: ηt=η0γ⌊t/s⌋。 |
描述为“每经过固定的步数,学习率乘以一个小于1的衰减因子,呈阶梯式下降”。 |
1. 设置初始学习率 η0,衰减因子 γ,步长 s。 |
“阶梯下降”流: 学习率流 ηt在大多数时间保持恒定,每经过 s步就突然下降为原来的 γ倍。这种离散的下降允许模型在某个学习率下稳定训练一段时间,然后进入更精细的调整阶段。 |
实现简单,只需在训练循环中检查当前步数是否达到衰减点。在多GPU中,学习率值需要同步。 |
指数衰减, 学习率调度。 |
|
AI-A0-0290 |
训练优化 |
训练领域 |
一种学习率调度策略,学习率随训练步数线性增加,然后线性或余弦衰减。 |
带热重启的余弦退火 (Cosine Annealing with Warm Restarts) |
1. 周期: 训练分为多个周期,每个周期内学习率按余弦函数从初始值衰减到最小值。 |
优点: 周期性重启有助于跳出局部最优, 提高模型性能。 |
学习率调度, 周期性重启。 通过余弦衰减和周期性重启来调整学习率。 |
场景: 训练深度神经网络, 尤其是图像分类和自然语言处理。 |
ηt: 当前学习率。 |
余弦函数: 学习率按余弦变化。 |
描述为“学习率在每个周期内按余弦函数从最大值衰减到最小值,周期结束后重启到最大值,并可能延长周期”。 |
1. 初始化周期长度 Ti,最大学习率 ηmax,最小学习率 ηmin。 |
“余弦振荡”流: 学习率流在每个周期内遵循余弦曲线,从高点 ηmax平滑下降到低点 ηmin。这种下降允许模型在初期快速收敛,后期精细调整。周期结束时,学习率流突然跳回高点(重启),模拟“重启”训练,有助于模型跳出可能的局部最优点,探索新的区域。 |
学习率调度器在训练循环中每一步更新学习率。在多GPU训练中,通常由主进程(rank 0)计算学习率并广播给所有进程,或每个进程独立计算相同值。 |
余弦退火, 学习率调度, 热重启。 |
|
AI-A0-0291 |
训练优化 |
训练领域 |
一种优化技巧,在多个小批量上累积梯度,然后一次性更新参数,模拟更大的批量大小。 |
梯度累积 (Gradient Accumulation) |
1. 过程: 对于 N个连续的小批量(micro-batch),每次前向传播后计算梯度,但不立即更新参数,而是将梯度累加到累积变量中。 |
目的: 在内存有限时模拟大批量训练, 稳定训练, 允许使用更大的有效批量大小。 |
优化技巧, 内存效率。 通过多次前向-反向传播累积梯度,实现更大的有效批量大小。 |
场景: 当GPU内存不足以容纳大批量时, 训练大模型。 |
gi: 第 i个小批量的梯度。 |
累加: G=∑i=1Ngi。 |
描述为“在多个小批量上重复前向和反向传播,累积梯度但不更新参数,累积一定步数后,用累积梯度(或平均梯度)更新一次参数”。 |
1. 初始化累积梯度 G=0,计数器 count=0。 |
“梯度缓冲”流: 在标准训练中,梯度流 gi产生后立即用于更新参数流 θ。在梯度累积中,梯度流被暂时存储到累积缓冲区 G中。经过 N个小批量,N个梯度流汇合成一个累积梯度流 G。然后这个累积流被用于更新参数流,模拟了一个批量大小为 N×micro-batch size的更新。这允许在有限内存下使用更大的有效批量。 |
梯度累积在单个GPU或数据并行中均可使用。每个GPU独立计算本地梯度并累积。在数据并行中,如果使用梯度平均,需要在累积 N步后对所有GPU的累积梯度进行AllReduce,然后更新参数。 |
批量大小, 优化器。 |
|
AI-A0-0292 |
训练优化 |
训练领域 |
一种优化技巧,限制梯度范数,防止梯度爆炸。 |
梯度裁剪 (Gradient Clipping) |
1. 计算梯度范数: g=∇θL,总梯度范数 $ |
g |
_2 = \sqrt{\sum_i g_i^2}。<br>∗∗2.裁剪:∗∗如果 |
g |
_2 > threshold,则g = g \cdot \frac{threshold}{ |
g |
|||||
|
AI-A0-0293 |
训练优化 |
训练领域 |
一种内存优化技术,在训练中只保存部分中间激活值,在反向传播时重新计算其他激活。 |
激活检查点 (Activation Checkpointing) |
1. 分段: 将模型分成若干段(checkpoint segments)。 |
节省内存: 内存占用从 O(L)降低到 O(L)或 O(logL), 其中 L是层数。 |
内存-计算权衡。 通过重计算中间激活来减少内存占用。 |
场景: 训练极深模型, 内存受限时。 |
模型分段: 将模型分为 k段。 |
重计算: 从检查点重新运行前向传播。 |
描述为“将模型分成若干段,在前向传播时只保存每段的输入和输出作为检查点,在反向传播时根据需要从检查点重新计算中间激活,从而节省内存”。 |
1. 将模型划分为 k个段:[segment1,segment2,...,segmentk]。 |
“检查点-重计算”流: 前向流经过模型分段,每段的输入流 xi和输出流 yi被保存为检查点流,而段内的中间激活流被丢弃。在反向流中,从最后一段开始,加载检查点流 xi和 yi,重新执行该段的前向流以生成中间激活流,然后计算梯度流。梯度流传播后,中间激活流被释放。这种流以额外的计算流为代价,减少了内存中需要同时保存的激活流数量。 |
激活检查点可以在单个GPU上实施,也可以与数据并行结合。在模型并行中,检查点可以设置在设备边界。重计算会增加计算时间,但允许训练更大的模型或更大的批量。 |
重计算, 内存优化, 梯度检查点。 |
|
AI-A0-0294 |
训练优化 |
训练领域 |
一种混合精度训练方法,使用半精度(FP16)进行前向和反向传播,同时保留单精度(FP32)主权重副本。 |
混合精度训练 (Mixed Precision Training) |
1. 维护FP32主权重: θfp32。 |
优点: 加速计算, 减少内存占用, 保持数值稳定性。 |
数值计算, 精度。 利用FP16加速计算,用FP32保持数值范围,通过梯度缩放防止下溢。 |
场景: 训练大型神经网络, 如Transformer, 需要加速和节省内存。 |
θfp32: FP32主权重。 |
精度转换: FP32 ↔ FP16。 |
描述为“使用半精度进行前向和反向传播以加速计算并节省内存,同时保留单精度主权重副本用于更新,并通过梯度缩放防止梯度下溢”。 |
1. 将FP32主权重 θfp32复制为FP16权重 θfp16。 |
“精度混合流”: 权重流 θ以FP32格式存储(主权重流)。在前向流中,权重流被转换为FP16流 θfp16,与FP16输入流进行运算,产生FP16激活流和损失流。损失流被缩放因子 S放大,以保留梯度信息。反向流计算FP16梯度流 gfp16,然后反缩放并转换为FP32梯度流 gfp32,最后用于更新FP32主权重流。这种流在计算密集型部分使用FP16加速,在权重更新时使用FP32保持精度。 |
混合精度训练需要GPU支持FP16计算(如Tensor Cores)。在数据并行中,每个GPU进行本地FP16前向/反向传播,梯度在FP32下进行All-Reduce。梯度缩放可以动态调整(如根据梯度范数)。 |
FP16, 梯度缩放, 数值稳定性。 |
|
AI-A0-0295 |
训练优化 |
训练领域 |
一种半精度浮点数格式,比FP16具有更大的动态范围,更适合深度学习训练。 |
BFloat16 (Brain Floating Point 16) |
1. 格式: 1位符号位,8位指数位,7位尾数位(而FP16是1位符号,5位指数,10位尾数)。 |
优点: 动态范围大, 与FP32指数位相同, 训练更稳定, 简化混合精度训练流程。 |
数值格式, 浮点数。 提供与FP32相同的指数范围,但使用16位存储,平衡范围和精度。 |
场景: 训练大型模型, 如Transformer, 在TPU和现代GPU上使用。 |
符号位: 1 bit。 |
指数范围: 与FP32相同(2−126到 2127)。 |
描述为“一种16位浮点数格式,具有与32位浮点数相同的指数范围,但尾数精度较低,适用于深度学习训练”。 |
1. 将权重、激活、梯度存储为BFloat16格式。 |
“大范围半精度”流: BFloat16数据流具有与FP32相同的指数范围,因此可以表示非常小和非常大的数,避免了FP16中容易出现的梯度下溢(值太小变为0)和溢出(值太大变为inf)问题。这使得BFloat16流可以直接用于训练,无需复杂的梯度缩放,简化了混合精度训练流程。计算流在BFloat16下进行,速度与FP16相当,但稳定性更好。 |
BFloat16得到现代AI加速器(如TPU、NVIDIA Ampere GPU)原生支持。在混合精度训练中,可以使用BFloat16代替FP16,简化流程。在多GPU中,通信可以使用BFloat16减少带宽。 |
FP16, FP32, 混合精度训练。 |
|
AI-A0-0296 |
训练优化 |
训练领域 |
一种权重初始化方法,根据输入和输出维度调整初始化方差,保持前向和反向传播的方差稳定。 |
Xavier初始化 (Glorot初始化) |
1. 均匀分布: W∼U[−nin+nout6,nin+nout6],其中 nin和 nout是输入和输出维度。 |
适用: 使用sigmoid或tanh等饱和激活函数的网络。 |
权重初始化, 方差缩放。 根据输入输出维度调整初始化范围,防止梯度消失或爆炸。 |
场景: 全连接层, 卷积层(需调整维度计算), 使用sigmoid/tanh的网络。 |
W: 权重矩阵,形状 (nout,nin)。 |
均匀分布: 边界由 6/(nin+nout)决定。 |
描述为“权重从均匀或正态分布中初始化,其方差与输入和输出维度的和成反比”。 |
1. 计算缩放因子 scale=6/(nin+nout)(均匀分布)或 std=2/(nin+nout)(正态分布)。 |
“方差均衡”流: Xavier初始化确保权重矩阵 W的初始化方差与输入维度 nin和输出维度 nout相关,使得前向传播中激活的方差和反向传播中梯度的方差在各层之间大致保持稳定,避免梯度消失或爆炸。 |
初始化在训练开始前执行一次。在多GPU上,每个GPU独立初始化相同的权重(如果使用相同随机种子),或按模型并行分区初始化。 |
Kaiming初始化, 权重初始化。 |
|
AI-A0-0297 |
训练优化 |
训练领域 |
针对ReLU及其变体设计的权重初始化方法,保持前向传播中激活的方差不变。 |
Kaiming初始化 (He初始化) |
1. 正态分布: W∼N(0,nin2),其中 nin是输入维度。 |
适用: 使用ReLU、LeakyReLU等非饱和激活函数的网络。 |
权重初始化, 方差缩放。 针对ReLU族激活函数调整初始化方差。 |
场景: 使用ReLU的深度神经网络, 如ResNet、Transformer(FFN中的ReLU/GELU)。 |
W: 权重矩阵,形状 (nout,nin)。 |
方差: Var(W)=(1+a2)nin2,对于ReLU a=0,故为 nin2。 |
描述为“针对ReLU激活函数,权重初始化方差与输入维度成反比,并考虑激活函数的稀疏性”。 |
1. 确定激活函数参数 a(ReLU为0,LeakyReLU为负斜率)。 |
“ReLU方差校正”流: Kaiming初始化考虑了ReLU激活函数会将一半的激活置零,导致方差减半。因此,初始化时将权重方差放大一倍(nin2对比 Xavier 的 nin+nout2),以补偿这种稀疏性,确保各层激活方差稳定。 |
同Xavier初始化,在训练前执行。对于Transformer,FFN层的权重通常使用Kaiming初始化。 |
Xavier初始化, ReLU, 权重初始化。 |
|
AI-A0-0298 |
训练优化 |
训练领域 |
一种正则化技术,在训练过程中随机将一部分神经元的输出置零,防止过拟合。 |
Dropout |
1. 训练阶段: 对于每一层,每个神经元以概率 p(dropout率)被置零,否则其输出乘以 1/(1−p)(缩放)。 |
作用: 防止过拟合, 提高模型泛化能力, 相当于模型平均。 |
正则化, 模型平均。 通过随机丢弃神经元,强制网络不依赖特定神经元,提高鲁棒性。 |
场景: 全连接层, 卷积层, 注意力层(如Transformer中的dropout)。 |
x: 输入向量或矩阵。 |
随机: 伯努利分布。 |
描述为“在训练时,随机将一部分神经元的输出置零,其余神经元按比例放大,以保持期望不变;测试时直接使用所有神经元”。 |
训练时: |
“随机子网络”流: 在每次前向传播中,Dropout随机选择神经元子集构成一个“子网络”。信息流只能通过未被丢弃的神经元流动。这迫使网络学习冗余表示,不依赖于任何单个神经元。缩放操作确保信息流的总体强度在训练和测试间一致。 |
Dropout操作是逐元素乘法,可并行。掩码生成是随机的,但可以同步随机种子以确保多GPU一致性。在Transformer中,dropout常用于注意力权重和FFN激活后。 |
正则化, 模型平均。 |
|
AI-A0-0299 |
训练优化 |
训练领域 |
一种正则化技术,在标签分布中引入噪声,将硬标签(one-hot)转换为软标签,防止模型过度自信。 |
标签平滑 (Label Smoothing) |
1. 硬标签: 对于真实类别 y,one-hot向量 q满足 qy=1,其他为0。 |
效果: 防止模型对正确类别过度自信, 提高泛化能力, 减轻过拟合。 |
正则化, 校准。 通过软化标签分布,鼓励模型保留不确定性。 |
场景: 分类任务, 尤其是大规模分类(如ImageNet)。 |
q: 原始one-hot标签向量。 |
凸组合: (1−ϵ)q+ϵu。 |
描述为“将真实标签的1减去一个小量,并将这个小量均匀分配到其他类别上,得到软标签”。 |
1. 给定真实类别 y,创建one-hot向量 q。 |
“标签软化”流: 硬标签流(one-hot)包含绝对确定性,可能促使模型过度拟合。标签平滑将硬标签流与均匀噪声流混合,产生一个较软的标签流。这个软标签流鼓励模型对正确类别的预测概率接近 1−ϵ,同时对其他类别赋予小的概率 ϵ/K,从而保留一定程度的不确定性,提高泛化。 |
标签平滑在数据加载或损失计算时进行,计算简单。在多GPU数据并行中,每个GPU独立对本地数据的标签进行平滑。 |
交叉熵损失, 正则化。 |
|
AI-A0-0300 |
训练优化 |
训练领域 |
一种权重衰减技术,在损失函数中添加L2正则化项,防止过拟合。 |
权重衰减 (Weight Decay) |
1. 损失函数: Ltotal=Ltask+2λ∑iθi2,其中 λ是权重衰减系数。 |
作用: 惩罚大权重, 鼓励简单模型, 防止过拟合。 |
正则化, L2正则化。 通过添加权重的平方和到损失中,限制模型复杂度。 |
场景: 几乎所有深度学习模型训练。 |
θi: 模型参数。 |
加法: 损失函数加L2惩罚项。 |
描述为“在损失函数中添加模型权重的L2范数作为正则化项,惩罚大的权重值”。 |
1. 计算任务损失 Ltask。 |
“权重收缩”流: 权重衰减在损失流中添加了一个与权重平方成正比的惩罚流。这导致在梯度流中,每个权重都会受到一个指向零的拉力 λθi。这种拉力流使得权重倾向于变小,除非任务梯度流强烈要求它们变大,从而控制模型复杂度,防止过拟合。 |
权重衰减项的计算需要对所有权重平方求和,在数据并行中需要跨GPU聚合。通常优化器(如AdamW)内置权重衰减,无需显式添加到损失中。 |
L2正则化, 过拟合, AdamW。 |
|
编号 |
类别 |
领域 |
模型配方 |
数学公式/定理/算法/模型/方法名称 |
数学公式/定理/算法/模型/方法的逐步思考推理过程及每一个步骤的数学方程式和参数选择/优化/迭代 |
精度/密度/误差/强度 |
底层规律/理论 |
典型应用场景和特征 |
变量/常量/参数列表及说明 |
数学特征 |
语言特征 |
时序和交互流程的所有细节/分步骤时序情况及数学方程式 |
流动模型和流向方法的数学描述 |
多GPU芯片执行情况和方程式列表 |
关联知识和算法 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
AI-A0-0301 |
推理优化 |
推理领域 |
一种用于自回归模型推理的批处理技术,通过动态调整批次大小提高GPU利用率。 |
持续批处理 (Continuous Batching) |
1. 请求队列: 维护一个等待推理的请求队列。 |
优点: 提高GPU利用率, 减少请求延迟, 适用于在线服务。 |
动态批处理, 在线推理。 通过动态添加和移除请求,使批次大小保持稳定,提高吞吐量。 |
场景: 大语言模型在线服务, 如聊天机器人、API服务。 |
B: 批次大小(动态变化)。 |
动态调整: 批次大小 B随时间变化。 |
描述为“在推理过程中,动态地将新请求加入批次,并为每个序列单独管理键值缓存和注意力掩码,以提高GPU利用率”。 |
1. 初始化一个空批次,维护请求队列。 |
“动态批处理流”: 请求流不断进入队列流。批次流是一个动态容器,当序列流完成时被释放,新序列流加入。前向传播流对整个批次流进行计算,但每个序列流有独立的掩码流和缓存流。这确保了GPU计算流持续饱和,提高了吞吐量。 |
持续批处理需要高效管理不同序列的键值缓存,可能涉及非连续内存访问。在多GPU中,如果使用模型并行,需要跨GPU协调缓存。 |
批处理, 键值缓存, 注意力掩码。 |
|
AI-A0-0302 |
推理优化 |
推理领域 |
一种推理加速技术,将模型中的矩阵乘法分解为低秩矩阵的乘积,减少计算量。 |
低秩分解 (Low-Rank Decomposition) |
1. 分解: 将权重矩阵 W∈Rm×n分解为两个小矩阵的乘积:W≈UV,其中 U∈Rm×r, V∈Rr×n,r≪min(m,n)。 |
优点: 减少参数和计算量, 加速推理。 |
模型压缩, 矩阵近似。 通过低秩近似减少矩阵乘法的计算复杂度。 |
场景: 模型部署, 资源受限环境。 |
W: 原始权重矩阵。 |
矩阵分解: W≈UV。 |
描述为“将大权重矩阵分解为两个小矩阵的乘积,推理时依次进行两次小矩阵乘法,以减少计算量”。 |
1. 对权重矩阵 W进行低秩分解,得到 U和 V(例如通过SVD)。 |
“低秩近似流”: 权重流 W被分解为两个低秩流 U和 V。输入流 x先与 V流相乘,得到中间流 z,再与 U流相乘,得到输出流 y。这减少了计算流的数据量,但引入了近似误差。 |
低秩分解减少了矩阵乘法的计算量,但可能增加内存访问次数。在GPU上,两个小矩阵乘法可能不如一个大矩阵乘法高效,需要权衡。在多GPU中,分解后的矩阵可以分布存储。 |
奇异值分解, 模型压缩。 |
|
AI-A0-0303 |
推理优化 |
推理领域 |
一种推理加速技术,将模型中的多个小卷积核合并为一个大卷积核。 |
卷积核融合 (Kernel Fusion) |
1. 识别: 对于连续的卷积层(中间无非线性激活),可以将它们的卷积核合并。 |
优点: 减少卷积次数, 加速推理。 |
算子融合, 卷积。 将多个连续卷积合并为一个卷积,减少计算量。 |
场景: 卷积神经网络推理, 如MobileNet、EfficientNet。 |
W1,W2: 两个卷积层的权重(卷积核)。 |
卷积结合律: (W2∗W1)∗x=W2∗(W1∗x)。 |
描述为“将多个连续的卷积层合并为一个卷积层,通过卷积核的卷积运算实现”。 |
1. 检查卷积层序列,确保中间没有非线性激活。 |
“卷积融合流”: 多个卷积核流被合并为一个等效的卷积核流。输入流直接与融合后的卷积核流进行卷积,跳过了中间的特征图流,减少了计算和内存流。 |
卷积核融合需要计算卷积核的卷积,可能增加离线计算开销。在GPU上,融合后的大卷积可能效率更高。 |
算子融合, 卷积神经网络。 |
|
AI-A0-0304 |
推理优化 |
推理领域 |
一种推理加速技术,通过提前退出机制,对于简单样本提前输出结果,减少计算量。 |
提前退出 (Early Exiting) |
1. 退出点: 在模型中间层设置多个退出点,每个退出点对应一个分类器。 |
优点: 对简单样本减少计算量, 加速推理。 |
动态推理, 条件计算。 根据样本难度自适应选择计算深度。 |
场景: 分类任务, 特别是计算资源受限的场景。 |
x: 输入样本。 |
条件判断: 如果 max(pi)>τ,则退出。 |
描述为“在模型中间层添加分类器,如果某个中间分类器的置信度足够高,就提前输出结果,不再继续后续计算”。 |
1. 在模型第 i=1,...,T−1层后添加分类器 Ci。 |
“条件深度流”: 输入流依次流过各层。在每层后,分类器流计算置信度流。如果置信度流超过阈值,则输出流提前产生,否则继续流向下一层流。这使得简单样本流快速退出,复杂样本流深入计算。 |
提前退出需要额外的分类器参数,但节省了后续层的计算。在多GPU中,如果模型并行,提前退出可能导致负载不均衡。 |
动态网络, 条件计算。 |
|
AI-A0-0305 |
训练优化 |
训练领域 |
一种学习率调度策略,在训练开始时线性增加学习率,帮助稳定训练。 |
学习率预热 (Learning Rate Warmup) |
1. 策略: 在前 N个训练步(或epoch)内,将学习率从0线性增加到初始学习率 η。 |
作用: 避免训练初期梯度不稳定导致模型发散, 尤其适用于大模型和大批量训练。 |
学习率调度, 稳定训练。 在训练初期逐步增加学习率,使模型平稳进入训练。 |
场景: 大规模深度学习训练, 如Transformer。 |
ηt: 第 t步的学习率。 |
线性增长: ηt=(t/N)⋅η。 |
描述为“在训练开始阶段,将学习率从0线性增加到目标值,以稳定初始训练”。 |
1. 设置目标学习率 η,预热步数 N。 |
“线性预热”流: 学习率流从0开始,随着训练步流线性增长到目标值。这避免了训练初期由于学习率过大导致的梯度流不稳定,让模型参数流平稳更新。 |
学习率预热在训练循环中实现简单。在多GPU训练中,每个进程独立计算相同的学习率,或由主进程广播。 |
学习率调度, 余弦退火。 |
|
AI-A0-0306 |
训练优化 |
训练领域 |
一种正则化技术,在训练过程中随机跳过某些层,通过捷径连接传递输入。 |
随机深度 (Stochastic Depth) |
1. 训练: 对于每个训练样本,以概率 p随机跳过某些层(如残差块)。跳过的层被替换为恒等连接(或缩放连接)。 |
作用: 正则化, 加速训练, 提高模型泛化能力。 |
正则化, 随机丢弃。 通过随机跳过层,强制模型不依赖特定层,类似Dropout但作用于层。 |
场景: 深度残差网络(ResNet)训练。 |
xl: 第 l层的输入。 |
伯努利选择: bl∼Bernoulli(1−pl)。 |
描述为“在训练时,每个残差块以一定概率被跳过,直接传递输入;测试时,所有块都使用,但输出乘以生存概率”。 |
训练时: |
“随机深度流”: 在训练流中,每个残差块流有一个随机开关。如果开关打开,输入流经过残差函数流;否则,输入流直接绕过。这迫使网络流学习更鲁棒的特征,不依赖任何特定层流。推理时,所有块流都启用,但残差流被缩放了生存概率。 |
随机深度在训练时增加随机性,但计算量略有减少(跳过某些层)。在多GPU中,每个GPU独立生成掩码,但需要同步随机种子以确保一致性(如果要求)。 |
Dropout, 残差网络, 正则化。 |
|
AI-A0-0307 |
训练优化 |
训练领域 |
一种数据增强技术,通过混合两个样本的特征和标签生成新样本。 |
MixUp |
1. 混合: 对于两个样本 (xi,yi)和 (xj,yj),生成新样本 (x~,y~): |
作用: 正则化, 提高模型泛化能力, 减轻过拟合。 |
数据增强, 正则化。 通过线性插值生成新样本,鼓励模型在样本之间线性行为。 |
场景: 图像分类, 文本分类等。 |
(xi,yi),(xj,yj): 两个随机样本。 |
线性插值: x~=λxi+(1−λ)xj。 |
描述为“随机选择两个样本,对它们的输入和标签进行线性插值,生成新样本用于训练”。 |
1. 从当前批次中随机选择两个样本 (xi,yi)和 (xj,yj)。 |
“样本混合”流: 两个样本流 xi和 xj被混合成一个新样本流 x~,标签流 yi和 yj混合成 y~。模型在混合流上训练,被迫学习更平滑的决策边界。 |
MixUp在数据加载时实现,计算简单。在多GPU数据并行中,每个GPU独立进行混合,但需要确保Beta分布采样的一致性(如果要求)。 |
数据增强, 标签平滑。 |
|
AI-A0-0308 |
训练优化 |
训练领域 |
一种数据增强技术,通过在一个批次内混合样本的特征和标签。 |
CutMix |
1. 裁剪和粘贴: 对于两个样本 (xi,yi)和 (xj,yj),从 xj随机裁剪一个区域,粘贴到 xi的对应区域,生成新图像 x~。 |
优点: 结合了CutOut和MixUp的优点, 更好地利用局部特征。 |
数据增强, 正则化。 通过裁剪和粘贴混合图像区域,鼓励模型利用局部特征。 |
场景: 图像分类, 目标检测。 |
(xi,yi),(xj,yj): 两个图像样本。 |
区域替换: x~=Mask⊙xi+(1−Mask)⊙xj。 |
描述为“从一个图像中裁剪一个区域,粘贴到另一个图像上,并按照区域面积比例混合标签,生成新样本”。 |
1. 随机选择两个样本 (xi,yi)和 (xj,yj)。 |
“区域混合”流: 两个图像流被切割和组合成一个新图像流,其中一部分来自一个流,其余来自另一个流。标签流按面积比例混合。这迫使模型流同时关注局部和全局特征。 |
CutMix在数据加载时实现,需要图像操作。在多GPU中,每个GPU独立进行。 |
MixUp, CutOut, 数据增强。 |
|
AI-A0-0309 |
训练优化 |
训练领域 |
一种数据增强技术,随机擦除输入图像中的矩形区域,迫使模型关注其他区域。 |
随机擦除 (Random Erasing) |
1. 擦除: 以概率 p对输入图像 x随机选择一个矩形区域,将该区域的像素值设置为随机数或均值。 |
作用: 正则化, 减轻过拟合, 提高模型对遮挡的鲁棒性。 |
数据增强, 正则化。 通过随机遮挡部分图像,鼓励模型不依赖局部特征。 |
场景: 图像分类, 目标检测, 行人重识别。 |
x: 输入图像。 |
区域置零: xerase=x⊙(1−M)+v⋅M,其中 M是掩码,v是填充值。 |
描述为“以一定概率随机选择图像中的一个矩形区域,将其像素值替换为随机数,以模拟遮挡”。 |
1. 以概率 p决定是否进行擦除。 |
“随机遮挡”流: 图像流被随机擦除一块区域,该区域像素流被噪声流替代。这迫使模型流不能依赖被擦除的特征,必须从其他区域流中提取信息。 |
随机擦除在数据加载时实现,计算简单。在多GPU中,每个GPU独立进行。 |
CutOut, 数据增强。 |
|
AI-A0-0310 |
训练优化 |
训练领域 |
一种优化器,通过累积梯度平方的移动平均来自适应调整每个参数的学习率。 |
RMSProp |
1. 计算梯度: gt=∇θL(θt−1)。 |
特点: 自适应学习率, 解决AdaGrad学习率单调下降的问题。 |
自适应优化, 梯度平方。 通过梯度平方的指数移动平均调整学习率。 |
场景: 深度学习训练, 尤其是非凸优化问题。 |
θ: 模型参数。 |
指数移动平均: E[g2]t=βE[g2]t−1+(1−β)gt2。 |
描述为“维护梯度平方的指数移动平均,并用其平方根的倒数缩放学习率,实现自适应学习率”。 |
1. 初始化 E[g2]0=0。 |
“自适应缩放”流: 梯度流 gt的平方被指数平滑,得到梯度平方流 E[g2]t。更新流中,学习率被 E[g2]t缩放,梯度大的参数更新小,梯度小的参数更新大,从而自适应调整学习率流。 |
RMSProp需要为每个参数维护一个状态 E[g2]。在数据并行中,梯度聚合后,每个GPU用相同梯度更新本地状态。 |
AdaGrad, Adam。 |
|
AI-A0-0311 |
训练优化 |
训练领域 |
一种优化器,累积所有历史梯度的平方和,使学习率逐渐下降。 |
AdaGrad |
1. 计算梯度: gt=∇θL(θt−1)。 |
特点: 自适应学习率, 适合稀疏梯度问题, 但学习率单调下降可能过早停止。 |
自适应优化, 梯度平方累积。 通过累积历史梯度平方调整学习率。 |
场景: 稀疏梯度问题, 如自然语言处理。 |
θ: 模型参数。 |
累加: Gt=∑i=1tgi2。 |
描述为“累积历史梯度的平方和,用其平方根的倒数缩放学习率,使得频繁更新的参数学习率小,稀疏更新的参数学习率大”。 |
1. 初始化 G0=0。 |
“累积缩放”流: 梯度平方流 gt2被不断累加到累积流 Gt中。更新流中,学习率被 Gt缩放,使得更新幅度随时间减小。这适合稀疏问题,但可能导致学习率过早衰减。 |
AdaGrad需要为每个参数维护累积和 Gt,内存占用随训练步数增加。在数据并行中,梯度聚合后,每个GPU更新本地累积和。 |
RMSProp, Adam。 |
|
AI-A0-0312 |
训练优化 |
训练领域 |
一种优化器,结合了动量法和自适应学习率,但没有偏差校正。 |
Adam (无偏差校正) |
1. 计算梯度: gt=∇θL(θt−1)。 |
注意: 缺少偏差校正, 在训练初期矩估计有偏, 可能影响收敛。 |
自适应优化, 动量。 Adam的简化版本,省略偏差校正步骤。 |
场景: 深度学习训练, 当训练步数足够多时偏差影响小。 |
同Adam, 但没有 m^t,v^t。 |
指数移动平均: 一阶和二阶矩。 |
描述为“维护梯度的一阶矩和二阶矩的指数移动平均,直接用它们更新参数,不进行偏差校正”。 |
1. 初始化 m=0,v=0。 |
“有偏自适应动量”流: 与Adam类似,但矩估计流 mt和 vt未进行偏差校正,因此在训练初期,矩估计流偏向零,可能导致更新流偏小。随着训练步数增加,偏差逐渐消失。 |
实现比标准Adam少一步除法,略高效。在多GPU中,同Adam。 |
Adam, 动量法。 |
|
AI-A0-0313 |
训练优化 |
训练领域 |
一种优化器,使用Nesterov动量加速梯度下降,在动量更新前计算梯度。 |
NAG (Nesterov Accelerated Gradient) |
1. 临时更新: θtemp=θt−1+γvt−1,其中 γ是动量系数。 |
优点: 在动量更新前计算梯度, 具有前瞻性, 减少振荡, 加速收敛。 |
动量法, 加速梯度下降。 Nesterov动量的梯度下降,在动量方向上前瞻一步计算梯度。 |
场景: 凸优化, 深度学习。 |
θ: 参数。 |
临时点: θtemp=θ+γv。 |
描述为“先根据当前动量方向前进一步,在该点计算梯度,然后用这个梯度更新动量,最后用动量更新参数”。 |
1. 初始化速度 v0=0。 |
“前瞻动量”流: 参数流先沿着动量方向 vt−1移动一步,得到临时点流。梯度流在临时点计算,然后更新动量流 vt。参数流再根据新动量流更新。这使得梯度流具有前瞻性,能更准确地调整方向。 |
NAG需要计算临时点的梯度,增加了一次前向传播(但通常不需要额外反向传播)。在数据并行中,梯度聚合后,每个GPU独立更新本地速度和参数。 |
动量法, SGD。 |
|
AI-A0-0314 |
训练优化 |
训练领域 |
一种优化器,通过累积历史梯度的平方来调整学习率,但使用指数移动平均而非累加。 |
Adadelta |
1. 计算梯度: gt=∇θL(θt−1)。 |
特点: 自适应学习率, 无需手动设置学习率, 自动调整更新量。 |
自适应优化, 自动学习率。 通过累积梯度平方和更新平方来自适应调整学习率。 |
场景: 深度学习训练, 无需调整学习率。 |
θ: 参数。 |
指数移动平均: 用于 E[g2]和 E[Δθ2]。 |
描述为“维护梯度平方和参数更新平方的指数移动平均,用它们的比值自动缩放更新量,无需设置学习率”。 |
1. 初始化 E[g2]0=0, E[Δθ2]0=0。 |
“自动缩放”流: 梯度平方流 E[g2]t和更新平方流 E[Δθ2]t被维护。更新流 Δθt的大小由历史更新流和当前梯度流共同决定,自动适应。这消除了手动设置学习率的需要。 |
Adadelta需要为每个参数维护两个状态 E[g2]和 E[Δθ2]。在数据并行中,梯度聚合后,每个GPU独立更新本地状态。 |
RMSProp, Adam。 |
|
AI-A0-0315 |
训练优化 |
训练领域 |
一种学习率调度策略,当验证集性能不再提升时,将学习率乘以一个因子。 |
按需调整学习率 (ReduceLROnPlateau) |
1. 监控指标: 在验证集上监控某个指标(如损失、准确率)。 |
作用: 动态降低学习率, 帮助模型在后期收敛到更优点。 |
学习率调度, 动态调整。 根据验证集表现动态降低学习率。 |
场景: 深度学习训练, 尤其是当模型收敛缓慢时。 |
η: 当前学习率。 |
条件判断: 如果 metric在 N个epoch内未改善,则 η=γη。 |
描述为“当验证集指标在连续多个epoch内没有改善时,将学习率乘以一个衰减因子”。 |
1. 初始化学习率 η,设置 γ, N, ηmin。 |
“按需衰减”流: 学习率流 η在训练过程中保持不变,直到验证指标流在连续多个epoch内没有改善流。此时,学习率流被衰减,以允许模型更精细地调整。 |
该调度器在每个epoch后评估验证集,需要额外的计算。在多GPU中,通常由主进程评估指标并决定是否调整学习率,然后广播给所有进程。 |
学习率调度, 步长衰减。 |
|
AI-A0-0316 |
训练优化 |
训练领域 |
一种权重初始化方法,从截断的正态分布中采样权重,避免过大或过小的初始值。 |
截断正态初始化 (Truncated Normal Initialization) |
1. 分布: 从正态分布 N(μ,σ2)采样,但将值限制在 [μ−2σ,μ+2σ]内,超出的重新采样。 |
优点: 避免初始权重中的极端值, 有助于训练稳定。 |
权重初始化, 截断分布。 通过截断正态分布避免初始化中的异常值。 |
场景: 深度学习权重初始化。 |
W: 权重矩阵。 |
截断: 采样值限制在 [a,b]内。 |
描述为“从正态分布中采样权重,但将采样值限制在均值附近两个标准差的范围内,避免过大或过小的初始权重”。 |
1. 确定均值 μ和标准差 σ(例如,Xavier初始化中 σ=2/(nin+nout))。 |
“截断采样”流: 权重初始化流从正态分布流中采样,但通过截断操作流过滤掉尾部值,确保初始权重流在合理范围内,防止梯度流异常。 |
截断正态初始化在训练前执行一次。在多GPU中,每个GPU独立初始化,但需要同步随机种子以确保一致性。 |
Xavier初始化, Kaiming初始化。 |
|
AI-A0-0317 |
训练优化 |
训练领域 |
一种权重初始化方法,从均匀分布中采样权重。 |
均匀初始化 (Uniform Initialization) |
1. 分布: W∼U[−a,a],其中 a是边界。 |
简单常用, 但可能不如正态初始化有效。 |
权重初始化, 均匀分布。 从均匀分布中采样初始权重。 |
场景: 深度学习权重初始化。 |
W: 权重矩阵。 |
均匀分布: W∼U[−a,a]。 |
描述为“从均匀分布中采样权重,权重值在正负边界之间均匀分布”。 |
1. 计算边界 a(例如,Xavier均匀初始化中 a=6/(nin+nout))。 |
“均匀采样”流: 权重初始化流从均匀分布流中采样,所有值在 [−a,a]内等概率出现。这提供了简单的初始化,但可能不考虑方差守恒。 |
同其他初始化方法,在训练前执行。 |
Xavier初始化, 正态初始化。 |
|
AI-A0-0318 |
训练优化 |
训练领域 |
一种权重初始化方法,将权重初始化为单位矩阵(或缩放单位矩阵)。 |
单位初始化 (Identity Initialization) |
1. 定义: 对于权重矩阵 W∈Rn×n,设置 W=I(单位矩阵)。对于非方阵,可以使用近似(如主对角线为1,其余为0)。 |
适用: 残差网络, 确保初始时恒等映射。 |
权重初始化, 恒等映射。 将权重初始化为单位矩阵,使得初始变换接近恒等映射。 |
场景: 残差块中的卷积层或线性层初始化。 |
W: 权重矩阵。 |
单位矩阵: W=I或 W=αI。 |
描述为“将权重矩阵初始化为单位矩阵(或缩放单位矩阵),使得初始变换近似恒等映射”。 |
1. 如果权重矩阵是方阵 n×n,则设置 W=I(对角线为1,其余为0)。 |
“恒等初始化”流: 权重流被初始化为单位矩阵流,使得输入流经过该层后基本保持不变(恒等映射流)。这有助于深层网络的训练,特别是残差网络。 |
单位初始化简单,但只适用于某些特定层。在多GPU中,每个GPU初始化自己部分的权重。 |
残差网络, 权重初始化。 |
|
AI-A0-0319 |
训练优化 |
训练领域 |
一种权重初始化方法,从正交矩阵中采样权重,保持输入向量的范数。 |
正交初始化 (Orthogonal Initialization) |
1. 采样: 从随机高斯矩阵 A∈Rm×n开始,进行QR分解或SVD得到正交矩阵 Q。 |
优点: 保持输入向量的范数, 有助于训练深度网络。 |
权重初始化, 正交矩阵。 初始化权重为正交矩阵,保持输入输出的范数关系。 |
场景: 循环神经网络, 深度前馈网络。 |
W: 权重矩阵。 |
正交性: QTQ=I(如果 m≥n)。 |
描述为“从随机高斯矩阵构造正交矩阵,并用它初始化权重,以保持输入输出的范数”。 |
1. 生成随机矩阵 A∈Rm×n,元素从 N(0,1)采样。 |
“正交变换”流: 权重流被初始化为正交矩阵流,这种变换流保持输入向量的范数流,有助于梯度流在深层网络中保持稳定。 |
正交初始化需要矩阵分解,计算开销较大。通常在训练前执行一次。在多GPU中,每个GPU可以独立初始化,但需要同步随机种子。 |
单位初始化, 权重初始化。 |
|
AI-A0-0320 |
训练优化 |
训练领域 |
一种正则化技术,在训练过程中随机断开神经元之间的连接,而不是丢弃神经元。 |
DropConnect |
1. 训练: 对于权重矩阵 W,生成一个二进制掩码 M∼Bernoulli(p),将 W的元素以概率 p置零:Wmasked=M⊙W。然后计算 y=(M⊙W)x。 |
与Dropout区别: Dropout丢弃激活, DropConnect丢弃权重连接。 |
正则化, 随机断开。 通过随机丢弃权重连接,防止过拟合。 |
场景: 全连接层, 卷积层。 |
W: 权重矩阵。 |
元素级乘法: Wmasked=M⊙W。 |
描述为“随机将权重矩阵中的一部分元素置零,从而断开神经元之间的连接,训练和测试时进行缩放校正”。 |
训练时: |
“连接丢弃”流: 权重流 W的每个元素以概率 p被丢弃(置零),形成稀疏权重流 Wmasked。输入流与稀疏权重流相乘,产生输出流。这相当于每次训练使用不同的子网络流,正则化效果类似Dropout但作用于权重流。 |
DropConnect需要对权重矩阵进行逐元素乘法,计算开销与Dropout类似。在多GPU中,每个GPU独立生成掩码。 |
Dropout, 正则化。 |
|
AI-A0-0321 |
模型架构 |
Token领域 |
一种相对位置编码方法,在注意力分数中添加可学习的相对位置偏置。 |
相对位置编码 (Relative Position Encoding) |
1. 定义相对位置: 对于序列中位置 i和 j,相对距离 d=i−j(有界,如 [−k,k])。 |
优点: 更好地建模相对位置关系, 外推性好。 |
位置编码, 相对位置。 通过可学习的相对位置偏置注入位置信息。 |
场景: Transformer, 尤其是自回归模型。 |
qi,kj: 查询和键向量。 |
加法偏置: Sij=qiTkj/dk+bi−j。 |
描述为“在注意力分数上添加一个可学习的偏置,该偏置只与查询和键的相对位置有关,从而引入相对位置信息”。 |
**1. 为每个相对距离 d∈[−k,k]初始化可学习参数 bd。 |
i-j |
> k,则使用b_{\text{clip}}$)。 |
“相对偏置”流: 注意力分数流 Sij被加上一个相对位置偏置流 bi−j。这个偏置流只依赖于相对距离,使得模型能够区分“前一个词”和“后一个词”等相对关系。 |
|
AI-A0-0322 |
模型架构 |
Token领域 |
一种位置编码方法,将位置信息通过加法融入输入嵌入。 |
绝对位置编码 (Absolute Position Encoding) |
1. 定义位置编码: 为每个位置 pos学习一个向量 ppos∈Rd,或将 pos映射到向量的函数(如正弦函数)。 |
简单直接, 但外推性差。 |
位置编码, 绝对位置。 为每个绝对位置分配一个向量,与词嵌入相加。 |
场景: Transformer, 尤其是编码器。 |
ei: 词嵌入向量。 |
加法: xi=ei+pi。 |
描述为“为序列中的每个位置分配一个向量(可学习或固定),然后将其加到词嵌入上,作为Transformer的输入”。 |
1. 对于序列位置 i=1,...,L,获取词嵌入 ei。 |
“位置注入”流: 词嵌入流和位置编码流相加,形成输入流。位置编码流为每个位置提供唯一的标识,使模型能够感知绝对位置。 |
绝对位置编码简单,但可学习的位置嵌入需要存储 Lmax×d的参数。在多GPU中,参数在所有GPU上复制。 |
相对位置编码, 正弦位置编码。 |
|
AI-A0-0323 |
模型架构 |
Token领域 |
一种位置编码方法,使用正弦和余弦函数生成位置编码。 |
正弦位置编码 (Sinusoidal Positional Encoding) |
1. 公式: 对于位置 pos和维度 i(i为偶数或奇数): |
特点: 固定, 非学习, 可外推到更长序列, 但可能不如可学习编码适应数据。 |
位置编码, 三角函数。 使用正弦和余弦函数生成位置编码,波长形成几何序列。 |
场景: 原始Transformer, 需要外推能力的场景。 |
pos: 位置索引。 |
三角函数: sin和 cos。 |
描述为“使用正弦和余弦函数为每个位置生成一个向量,其频率随维度增加而降低,然后与词嵌入相加”。 |
1. 对于每个位置 pos: |
“正弦波注入”流: 位置编码流由不同频率的正弦和余弦波流组成。每个位置对应一个独特的波形组合。与词嵌入流相加后,输入流同时携带词汇和位置信息。 |
正弦位置编码可以预先计算并存储,或在前向传播时实时计算。在多GPU中,每个GPU需要知道序列的全局位置以计算编码。 |
绝对位置编码, 可学习位置嵌入。 |
|
AI-A0-0324 |
模型架构 |
Token领域 |
一种位置编码方法,将位置信息通过乘法(缩放)融入输入嵌入。 |
位置缩放 (Positional Scaling) |
1. 定义缩放向量: 为每个位置 i学习一个缩放向量 si∈Rd(或标量)。 |
与加法不同, 乘法可以调制词嵌入的幅度。 |
位置编码, 乘法。 通过逐元素乘法将位置信息融入词嵌入。 |
场景: 需要位置调制词嵌入幅度的场景。 |
ei: 词嵌入。 |
逐元素乘法: xi=ei⊙si。 |
描述为“为每个位置学习一个缩放向量,将词嵌入与该向量逐元素相乘,以注入位置信息”。 |
1. 对于位置 i,获取词嵌入 ei。 |
“位置调制”流: 位置缩放流 si逐元素调制词嵌入流 ei的幅度,产生输入流 xi。这允许位置信息以乘法方式影响表示。 |
位置缩放需要为每个位置存储向量,参数量与绝对位置嵌入相同。在多GPU中,参数在所有GPU上复制。 |
绝对位置编码, 加法融合。 |
|
AI-A0-0325 |
模型架构 |
Token领域 |
一种位置编码方法,将位置信息与词嵌入拼接,然后通过线性投影融合。 |
位置拼接 (Positional Concatenation) |
1. 定义位置向量: 为每个位置 i学习一个向量 pi∈Rdp。 |
优点: 位置和词汇信息在拼接后融合, 更灵活。 |
位置编码, 拼接投影。 将位置向量与词嵌入拼接,然后线性投影到模型维度。 |
场景: 需要更灵活位置融合的场景。 |
ei: 词嵌入,维度 d。 |
拼接: xi=[ei;pi]。 |
描述为“将词嵌入和位置向量拼接起来,然后通过一个线性层投影到模型维度,作为输入”。 |
1. 对于每个位置 i,获取词嵌入 ei和位置向量 pi。 |
“拼接融合”流: 词嵌入流和位置向量流被拼接成宽流,然后通过投影流 W融合并降维,产生输入流。这允许模型学习更复杂的交互。 |
位置拼接增加了一个线性投影层,增加了参数和计算。在多GPU中,投影层参数在所有GPU上复制。 |
绝对位置编码, 加法融合。 |
|
AI-A0-0326 |
模型架构 |
Token领域 |
一种位置编码方法,将位置信息作为注意力机制的键和值的一部分。 |
位置感知注意力 (Position-Aware Attention) |
1. 定义位置键/值: 为每个位置 i学习位置键 kip和值 vip。 |
将位置信息直接融入注意力机制, 更显式地建模位置。 |
位置编码, 注意力机制。 将位置信息作为键和值的一部分,使注意力能够感知位置。 |
场景: 需要强位置感知的注意力模型。 |
kic,vic: 内容键和值。 |
拼接或加法: k~i=kic+kip或 [kic;kip]。 |
描述为“为每个位置学习独立的键和值向量,将其与内容键值融合,然后计算注意力”。 |
1. 计算内容键 Kc和值 Vc。 |
“位置增强注意力”流: 键流和值流由内容流和位置流相加组成。注意力机制流同时基于内容和位置信息计算权重,使得模型能够区分不同位置的相同内容。 |
位置感知注意力需要为每个位置存储键和值向量,参数量较大。在多头注意力中,可以为每个头设置独立的位置键值。 |
相对位置编码, 注意力机制。 |
|
AI-A0-0327 |
模型架构 |
Token领域 |
一种激活函数 |
|
编号 |
类别 |
领域 |
模型配方 |
数学公式/定理/算法/模型/方法名称 |
数学公式/定理/算法/模型/方法的逐步思考推理过程及每一个步骤的数学方程式和参数选择/优化/迭代 |
精度/密度/误差/强度 |
底层规律/理论 |
典型应用场景和特征 |
变量/常量/参数列表及说明 |
数学特征 |
语言特征 |
时序和交互流程的所有细节/分步骤时序情况及数学方程式 |
流动模型和流向方法的数学描述 |
多GPU芯片执行情况和方程式列表 |
关联知识和算法 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
AI-A0-0327 |
模型架构 |
Token领域 |
一种激活函数,结合了Sigmoid和线性函数,具有平滑的非线性。 |
Swish (SiLU) |
1. 定义: Swish(x)=x⋅σ(x),其中 σ(x)=1/(1+e−x)是sigmoid函数。 |
特点: 非单调, 平滑, 在零附近线性, 负区域有小的负值。 |
激活函数, 平滑非线性。 结合线性函数和sigmoid门控,提供平滑非线性。 |
场景: 神经网络激活函数, 在Transformer的FFN中有时替代ReLU。 |
x: 输入标量。 |
乘积: x⋅σ(x)。 |
描述为“将输入与它的sigmoid相乘,产生一个平滑的非线性激活”。 |
1. 输入 x。 |
“自门控”流: 输入流 x经过sigmoid流产生一个门控信号流 σ(x),其值在0到1之间。然后输入流与门控信号流逐元素相乘,产生输出流。这允许网络以平滑的方式关闭或通过信息。 |
Swish计算涉及sigmoid和乘法,比ReLU计算量大,但更平滑。在GPU上,有优化的实现。在多GPU中,逐元素操作,可并行。 |
SiLU, GELU。 |
|
AI-A0-0328 |
模型架构 |
Token领域 |
一种激活函数,结合了高斯误差函数和线性函数,被GPT等模型采用。 |
GELU (Gaussian Error Linear Unit) |
1. 定义: GELU(x)=xΦ(x),其中 Φ(x)是标准正态分布的累积分布函数。 |
特点: 平滑, 非单调, 在负区域非零, 被BERT、GPT等使用。 |
激活函数, 高斯误差。 通过乘以输入被“丢弃”的概率(根据输入大小)来激活。 |
场景: Transformer的FFN层, 如BERT、GPT。 |
x: 输入标量。 |
乘积: x⋅Φ(x)。 |
描述为“将输入乘以它在正态分布下的累积概率,可以理解为按输入的大小随机地保留或丢弃”。 |
1. 输入 x。 |
“随机门控”流: 输入流 x被一个依赖于 x的门控流 Φ(x)缩放,门控流表示 x被“保留”的概率。这可以看作是随机正则化的确定性版本。 |
GELU计算涉及复杂的函数,通常使用近似公式。在GPU上,有高效的实现。 |
Swish, ReLU。 |
|
AI-A0-0329 |
模型架构 |
Token领域 |
一种门控激活函数,通过逐元素乘法对两个线性变换进行门控。 |
GLU (Gated Linear Unit) |
1. 定义: GLU(x,W,V,b,c)=(xW+b)⊙σ(xV+c),其中 σ是sigmoid函数,⊙是逐元素乘法。 |
优点: 门控机制可以控制信息流动, 提高表达能力。 |
激活函数, 门控机制。 通过一个线性变换的门控信号调制另一个线性变换。 |
场景: 语言模型的FFN层, 如T5、PaLM。 |
x: 输入向量。 |
门控: A⊙σ(B)。 |
描述为“对输入进行两个不同的线性变换,其中一个变换的结果经过sigmoid作为门控信号,与另一个变换的结果逐元素相乘”。 |
1. 计算 A=xW+b。 |
“双路门控”流: 输入流分成两路,一路产生值流 A,另一路产生门控信号流 g。值流被门控流调制后输出,允许网络选择性地传递信息。 |
GLU需要两个线性变换,计算量较大。在GPU上,可以并行计算两个线性变换。 |
SwiGLU, GeGLU。 |
|
AI-A0-0330 |
模型架构 |
Token领域 |
一种注意力机制,通过线性层将输入映射到多个子空间,然后计算注意力。 |
多头注意力 (Multi-Head Attention) |
1. 线性投影: 对查询、键、值进行 h次不同的线性投影,得到 h组查询、键、值:Qi=QWiQ, Ki=KWiK, Vi=VWiV,其中 i=1,...,h,WiQ,WiK∈Rdmodel×dk, WiV∈Rdmodel×dv,通常 dk=dv=dmodel/h。 |
优点: 允许模型共同关注来自不同位置的不同表示子空间的信息。 |
注意力机制, 并行化。 将注意力分解为多个头,并行计算,增强模型表达能力。 |
场景: Transformer的核心组件, 广泛用于各种序列任务。 |
Q,K,V: 输入查询、键、值,形状 (L,dmodel)。 |
投影: 线性变换到 dk和 dv维。 |
描述为“将查询、键和值分别投影到多个子空间,在每个子空间内独立计算注意力,然后将所有头的输出拼接起来,再经过一个线性投影得到最终输出”。 |
1. 对每个头 i: |
“多头并行流”: 输入流 Q,K,V被复制到 h个流,每个流经过不同的线性投影流 WiQ,WiK,WiV,映射到低维子空间。在每个子空间流中,独立进行注意力流计算。然后,h个头的输出流被拼接成一个宽流,再经过输出投影流 WO融合信息。这种并行流允许模型同时关注不同类型的信息模式。 |
多头注意力可以高度并行化,每个头的计算相互独立。在GPU上,可以将多个头的计算批量进行。在多GPU中,可以将头分布到不同GPU上(张量并行),或者将序列分布到不同GPU上(数据并行)。 |
缩放点积注意力, Transformer。 |
|
AI-A0-0331 |
模型架构 |
Token领域 |
一种稀疏注意力模式,每个位置只关注局部邻居和少数全局位置。 |
局部-全局注意力 (Local-Global Attention) |
1. 局部注意力: 每个位置 i关注其前后 w个位置(窗口大小为 2w+1)。 |
优点: 线性复杂度, 同时捕获局部和全局依赖。 |
稀疏注意力, 局部和全局。 结合局部窗口注意力和全局注意力,平衡效率和表达能力。 |
场景: 长序列建模, 如文档、图像。 |
L: 序列长度。 |
带状矩阵: 局部注意力对应带状矩阵。 |
描述为“每个位置只关注其附近窗口内的位置,同时每隔一定间隔设置全局位置,全局位置与所有位置相互关注”。 |
**1. 确定每个位置的注意力集合: |
i-j |
\le w。<br>b.全局位置:如果i是全局位置(i \mod g = 0),则关注所有j;如果j是全局位置,则i关注j$。 |
“局部-全局混合流”: 大多数位置的信息流只在局部窗口内流动。全局位置作为信息枢纽,收集和分发全局信息流。这种设计使得长距离依赖可以通过全局位置中转,同时保持了线性复杂度。 |
|
AI-A0-0332 |
模型架构 |
Token领域 |
一种线性复杂度的注意力机制,通过核函数近似softmax。 |
线性注意力 (Linear Attention) |
1. 核函数: 定义特征映射 ϕ,使得 ϕ(q)Tϕ(k)≈exp(qTk/dk)。 |
复杂度: O(Ld2)或 O(Ldm), 其中 m是特征维度, 线性于 L。 |
注意力机制, 核方法。 通过核技巧将注意力分解为线性运算,实现线性复杂度。 |
场景: 长序列建模, 需要线性复杂度的注意力。 |
Q,K,V: 查询、键、值,形状 (L,d)。 |
核近似: exp(qTk)≈ϕ(q)Tϕ(k)。 |
描述为“使用核函数近似softmax中的指数函数,然后通过交换求和顺序,先聚合键和值,再与查询相乘,实现线性复杂度”。 |
1. 计算特征映射:K~=ϕ(K), Q~=ϕ(Q),形状 (L,m)。 |
“核化线性流”: 键流 K和查询流 Q通过特征映射流 ϕ转换到高维空间。键流与值流 V聚合为 S流,键流自身聚合为 Z流。查询流 Q~与 S流和 Z流交互,得到输出流。由于聚合与 L无关,整体复杂度线性。 |
线性注意力需要计算特征映射,可能增加计算开销。聚合操作可以并行计算。在多GPU中,需要跨GPU聚合 S和 Z,然后广播。 |
Performer, Random Feature Attention。 |
|
AI-A0-0333 |
模型架构 |
Token领域 |
一种线性复杂度的注意力机制,通过低秩投影近似注意力矩阵。 |
Linformer |
1. 低秩投影: 将键和值投影到低维空间:K~=EK, V~=FV,其中 E,F∈Rk×L,k≪L。 |
核心思想: 注意力矩阵是低秩的, 可以用低维投影近似。 |
低秩近似, 线性复杂度。 通过将键和值投影到低维空间,实现线性复杂度的注意力。 |
场景: 长序列编码, 如文档分类, 但仅适用于编码器(非自回归)。 |
Q,K,V: 查询、键、值,形状 (L,d)。 |
低秩投影: K∈RL×d→K~∈Rk×d。 |
描述为“将键和值矩阵通过投影压缩到固定长度,然后与查询矩阵计算注意力,使计算复杂度与序列长度呈线性关系”。 |
1. 输入 Q,K,V,形状 (L,d)。 |
“压缩流”: 键流 K和值流 V被投影矩阵 E和 F压缩到低维空间,形成压缩的键流 K~和值流 V~。注意力流变为:查询流 Q与压缩键流 K~交互,产生注意力权重流 P(L×k),然后与压缩值流 V~聚合。由于 k是固定的,整个流程的复杂度与序列长度 L成线性关系。 |
Linformer的投影操作是矩阵乘法,可以高效并行。投影矩阵 E和 F可以是可学习的参数。在多GPU中,序列可以按长度划分,但投影操作可能需要全局聚合(如果 E和 F是全局的)。 |
低秩近似, 线性注意力。 |
|
AI-A0-0334 |
模型架构 |
Token领域 |
一种线性复杂度的注意力机制,通过随机特征近似softmax核。 |
Performer (随机特征注意力) |
1. 随机特征映射: 使用正交随机特征(ORF)近似softmax核。ϕ(x)=m1exp(Wx−2∥x∥2),其中 W∈Rm×d的行是随机正交向量。 |
随机特征数 m: 通常64~256, 控制近似精度。 |
随机特征, 核近似, 线性复杂度。 使用正交随机特征映射来近似softmax核,实现线性注意力。 |
场景: 长序列建模, 需要精确softmax近似的场景。 |
Q,K,V: 查询、键、值,形状 (L,d)。 |
随机特征: ϕ(x)=m1exp(Wx−∥x∥2/2)。 |
描述为“使用正交随机特征来近似softmax核函数,将注意力计算转化为线性形式,从而实现线性复杂度”。 |
1. 生成随机正交矩阵 W(或从正态分布采样后正交化)。 |
“随机特征流”: 查询流 Q和键流 K通过随机特征映射 ϕ转换,其中 ϕ使用随机正交矩阵 W和指数函数。这个映射流将原始的指数点积核近似为随机特征的点积。然后,与线性注意力相同,进行键值聚合流和键和聚合流,最后与查询特征流结合。随机特征流提供了对softmax核的无偏估计,且方差较小。 |
Performer需要生成随机矩阵 W,可以在训练前固定或定期更新。特征映射涉及指数计算,可能数值不稳定,需要小心实现。在多GPU中,W在所有GPU上一致,特征映射可以独立计算。 |
线性注意力, 随机特征。 |
|
AI-A0-0335 |
模型架构 |
Token领域 |
一种稀疏注意力模式,将序列划分为块,每个块内计算注意力,块之间通过全局token连接。 |
块稀疏注意力 (Block Sparse Attention) |
1. 分块: 将序列划分为 N个块,每块大小 B。 |
优点: 通过控制块间注意力数量, 降低计算复杂度。 |
稀疏注意力, 块计算。 在块级别进行稀疏注意力,减少计算量。 |
场景: 长序列建模, 如图像、音频、长文本。 |
L: 序列长度。 |
块矩阵: 注意力矩阵是块稀疏的。 |
描述为“将序列分成块,每个块只与预先定义的一组其他块计算注意力,而不是与所有块计算,从而减少计算量”。 |
1. 将输入序列划分为 N个块,每块 B个token。 |
“块稀疏流”: 序列流被划分为块流。注意力流只在被允许的块对之间流动。例如,局部模式中,每个块只关注相邻的几个块;随机模式中,每个块随机关注几个其他块;全局模式中,某些块关注所有块。这种块级别的稀疏流大大减少了注意力计算的总量,同时保留了重要的长距离依赖。 |
块稀疏注意力可以利用块矩阵乘法优化。在多头注意力中,每个头可以使用不同的稀疏模式。在多GPU中,序列块可以分布在不同GPU上,注意力计算需要跨GPU通信相关块。 |
BigBird, Longformer。 |
|
AI-A0-0336 |
模型架构 |
Token领域 |
一种线性复杂度的注意力机制,通过可学习的记忆token来捕获全局信息。 |
记忆压缩注意力 (Memory Compressed Attention) |
1. 记忆token: 引入一组可学习的记忆token M∈Rm×d,其中 m≪L。 |
优点: 将长序列压缩到固定大小的记忆, 实现线性复杂度。 |
注意力机制, 记忆压缩。 通过可学习记忆token压缩序列信息,减少注意力计算量。 |
场景: 长序列建模, 需要固定计算预算的场景。 |
Q,K,V: 查询、键、值,形状 (L,d)。 |
压缩: 将 L个token压缩到 m个记忆token。 |
描述为“引入一组可学习的记忆token,将键和值信息压缩到这些记忆token上,然后查询与压缩后的键计算注意力,从而减少计算量”。 |
1. 通过可学习记忆token M与键 K计算注意力权重,将值 V聚合到记忆:V~=softmax(MKT)V。 |
“记忆压缩”流: 键流 K和值流 V被压缩到记忆流 M中,形成压缩的键流 K~和值流 V~。查询流 Q与压缩键流交互,然后与压缩值流聚合。这相当于通过记忆流这个瓶颈传递信息,减少了计算流。 |
记忆压缩注意力需要额外的记忆参数。压缩步骤可以通过注意力实现,复杂度 O(Lmd)。在多GPU中,记忆token在所有GPU上复制,但压缩需要跨GPU聚合。 |
Set Transformer, Compressive Transformer。 |
|
AI-A0-0337 |
模型架构 |
Token领域 |
一种递归注意力机制,将序列分段处理,并通过递归传递隐藏状态。 |
Transformer-XL (超长Transformer) |
1. 分段递归: 将序列划分为段,每段单独处理,但将上一段的隐藏状态作为额外上下文传递给当前段。 |
优点: 可以建模长距离依赖, 支持更长的上下文。 |
递归注意力, 长上下文。 通过分段递归和相对位置编码,扩展Transformer的上下文长度。 |
场景: 长文本建模, 如语言建模。 |
Sτ: 第 τ段输入,形状 (L,d)。 |
递归: Hτ=TransformerLayer([Hτ−1,Sτ])。 |
描述为“将序列分成段,每段处理时利用上一段的隐藏状态作为额外上下文,并通过相对位置编码处理位置信息,从而建模长距离依赖”。 |
1. 初始化 H0=0。 |
“分段递归流”: 序列流被分成段流。每段流处理时,除了当前段流,还接收上一段流产生的隐藏状态流。注意力流中,查询流来自当前段,键值流来自上一段和当前段的拼接。相对位置编码流确保位置信息正确。这允许信息流跨段传递,建模长距离依赖。 |
Transformer-XL需要缓存上一段的隐藏状态,内存占用随段数增加。在训练时,可以并行处理多个段,但推理时需要递归进行。在多GPU中,段可以分布在不同GPU上,但需要传递隐藏状态。 |
相对位置编码, 递归神经网络。 |
|
AI-A0-0338 |
模型架构 |
Token领域 |
一种压缩Transformer,通过压缩历史隐藏状态来扩展上下文长度。 |
Compressive Transformer |
1. 压缩记忆: 除了像Transformer-XL那样维护最近段的隐藏状态,还将更早的隐藏状态压缩成压缩记忆。 |
优点: 进一步扩展上下文长度, 保留更长的历史信息。 |
记忆压缩, 长上下文。 通过压缩历史状态,扩展Transformer的上下文长度。 |
场景: 需要极长上下文建模的语言任务。 |
Hrecent: 最近隐藏状态(如最近 n段)。 |
压缩: c=fc(h1,...,hk)。 |
描述为“维护一个最近隐藏状态队列和一个压缩记忆库,将更早的隐藏状态压缩后存储,注意力时同时使用两者,以扩展上下文长度”。 |
1. 维护两个记忆:最近记忆 Mrecent和压缩记忆 Mcomp。 |
“压缩记忆流”: 隐藏状态流被分为最近流和压缩流。最近流保持原始分辨率,压缩流通过压缩函数降采样。注意力流可以同时从两个流中检索信息,从而以较低成本扩展上下文窗口。 |
Compressive Transformer需要管理两个记忆,并定期进行压缩操作。压缩操作可以是计算密集型的。在多GPU中,记忆可能需要跨GPU同步。 |
Transformer-XL, 记忆网络。 |
|
AI-A0-0339 |
模型架构 |
Token领域 |
一种线性复杂度的注意力机制,通过状态空间模型(SSM)替代注意力。 |
状态空间模型 (State Space Model) |
1. 状态空间模型: 使用线性时不变系统建模序列:ht=Aht−1+Bxt, yt=Cht+Dxt,其中 A,B,C,D是可学习参数。 |
优点: 线性复杂度, 长程依赖, 并行训练。 |
状态空间模型, 序列建模。 使用线性时不变系统建模序列,实现线性复杂度。 |
场景: 长序列建模, 如语言、音频、基因组。 |
xt: 时刻 t的输入。 |
线性递归: ht=Aht−1+Bxt。 |
描述为“使用线性时不变系统建模序列,通过递归计算隐藏状态,然后映射到输出,实现线性复杂度的序列变换”。 |
1. 给定输入序列 x1,...,xL。 |
“状态空间流”: 输入流 xt通过线性递归流 Aht−1+Bxt更新隐藏状态流 ht,然后通过输出流 Cht+Dxt产生输出流 yt。这种流是线性的,但通过非线性激活和深度堆叠可以建模复杂模式。 |
SSM可以通过并行扫描算法并行化,但需要额外的计算。在GPU上,可以使用高效的CUDA内核。在多GPU中,序列需要分区,但递归需要跨GPU通信边界状态。 |
Mamba, S4, 线性递归。 |
|
AI-A0-0340 |
模型架构 |
Token领域 |
一种选择性状态空间模型,根据输入动态调整参数,提高表达能力。 |
Mamba |
1. 选择性SSM: 参数 B,C,Δ是输入 xt的函数,从而模型可以根据输入选择性地传播或忽略信息。 |
优点: 线性复杂度, 输入依赖, 长上下文, 训练和推理快。 |
状态空间模型, 选择性。 通过输入依赖的参数,使状态空间模型具有选择机制,提高表达能力。 |
场景: 长序列建模, 如语言、音频、DNA。 |
xt: 输入。 |
输入依赖: Bt=Linear(xt), Ct=Linear(xt), Δt=softplus(Linear(xt))。 |
描述为“将状态空间模型的参数设置为输入的函数,使得模型可以根据输入选择性地传播信息,并通过硬件感知算法高效计算”。 |
1. 对于每个时间步 t,从输入 xt计算 Δt,Bt,Ct。 |
“选择性状态流”: 输入流 xt不仅用于更新状态,还用于生成参数流 Δt,Bt,Ct。离散化流产生当前步的递归参数,状态流根据这些参数更新。这使得模型可以基于输入流选择性地记忆或忽略信息。 |
Mamba设计了硬件感知的并行扫描算法,充分利用GPU层次内存。在训练和推理中都非常高效。在多GPU中,序列分区需要处理递归依赖。 |
S4, 状态空间模型。 |
|
AI-A0-0341 |
推理优化 |
推理领域 |
一种推理加速技术,将模型中的多个层合并为一层,减少计算图节点。 |
层融合 (Layer Fusion) |
1. 识别模式: 寻找可以融合的层序列,如线性层后接激活函数,或卷积层后接批归一化和激活函数。 |
优点: 减少内核启动开销, 减少中间结果存储, 加速推理。 |
计算图优化, 算子融合。 将多个连续的层合并为一个内核执行。 |
场景: 深度学习模型推理, 尤其是移动端和边缘设备。 |
多个层: 如 y=fn(...f2(f1(x)))。 |
复合函数: 将多个函数合并为一个函数。 |
描述为“将多个连续的层合并为一个层,通过编写一个融合内核一次性计算,减少内核调用和内存访问”。 |
1. 分析计算图,找到可以融合的层序列。 |
“多层融合流”: 多个层的计算流被合并为一个复合计算流。输入流直接经过复合流产生输出流,跳过了中间结果的存储和读取流,提高了数据局部性和计算效率。 |
层融合通常由深度学习编译器(如TVM、TensorRT)自动完成。在GPU上,融合内核可以减少全局内存访问,提高带宽利用率。 |
算子融合, 矩阵乘法融合。 |
|
AI-A0-0342 |
推理优化 |
推理领域 |
一种推理加速技术,将模型中的浮点权重转换为整数权重,并使用整数运算进行计算。 |
整数量化推理 (Integer Quantization Inference) |
1. 量化: 将权重和激活量化为INT8(或更低精度)。缩放因子 s和零点 z通过校准得到。 |
优点: 减少内存占用, 加速计算, 降低功耗。 |
量化, 整数运算。 将模型量化为整数,并使用整数运算进行推理。 |
场景: 边缘设备, 移动设备, 需要高效推理的场景。 |
W: 浮点权重。 |
整数矩阵乘法: yq=INT_MATMUL(Wq,xq,sw,sx,sy,zw,zx,zy)。 |
描述为“将权重和激活量化为整数,然后使用整数矩阵乘法进行计算,最后反量化为浮点数,以减少计算和内存开销”。 |
1. 校准:确定缩放因子和零点。 |
“整数计算流”: 浮点权重流和激活流被量化为整数流。计算流在整数域进行,利用整数运算单元的高效性。结果流再反量化为浮点流。这大幅减少了计算和内存流的数据量。 |
整数量化推理需要GPU支持整数运算(如INT8 Tensor Core)。在GPU上,可以使用CUDA的整数指令。在多GPU中,每个GPU独立进行整数计算。 |
训练后量化, 量化感知训练。 |
|
AI-A0-0343 |
推理优化 |
推理领域 |
一种推理加速技术,将模型编译为特定硬件的高效代码。 |
模型编译 (Model Compilation) |
1. 计算图优化: 对模型计算图进行优化,如常量折叠、算子融合、内存规划等。 |
优点: 生成高度优化的代码, 充分利用硬件特性, 提高推理速度。 |
编译器, 代码生成。 将模型编译为硬件特定的高效代码。 |
场景: 模型部署, 追求极致推理性能。 |
计算图: 模型的计算图表示。 |
优化: 图优化、算子融合、内存布局优化等。 |
描述为“将模型的计算图进行优化,并针对目标硬件生成高度优化的内核代码,以最大化推理性能”。 |
1. 将模型转换为计算图。 |
“编译优化流”: 模型计算图流经过多轮优化流,包括图级优化流和算子级优化流。最终生成硬件特定的高效代码流,在目标硬件上执行。 |
模型编译通常需要离线进行,编译时间可能较长。编译后的模型可以高效运行在目标GPU上。多GPU编译需要考虑数据并行和模型并行的代码生成。 |
TVM, TensorRT, XLA。 |
|
AI-A0-0344 |
推理优化 |
推理领域 |
一种推理引擎,针对NVIDIA GPU进行优化,提供高性能推理。 |
TensorRT |
1. 优化: 对模型进行图优化、层融合、精度校准(INT8量化)、内核自动调优等。 |
优点: 高度优化, 支持多种精度, 自动调优, 广泛使用。 |
推理引擎, GPU优化。 NVIDIA推出的深度学习推理优化器和运行时引擎。 |
场景: NVIDIA GPU上的深度学习推理。 |
模型: 输入模型(如ONNX)。 |
优化: 包括算子融合、内存优化、内核选择等。 |
描述为“将训练好的模型通过TensorRT进行优化,包括图优化、层融合、量化等,生成优化后的引擎,在NVIDIA GPU上高效推理”。 |
1. 将训练好的模型转换为ONNX格式。 |
“TensorRT优化流”: 模型流经过TensorRT优化器流,进行图优化流、融合流、量化流等,生成高度优化的引擎流。推理时,输入流经过引擎流高效计算。 |
TensorRT针对NVIDIA GPU进行深度优化,支持多种GPU架构。在多GPU中,可以每个GPU加载一个引擎实例,进行数据并行推理。 |
模型编译, 推理引擎。 |
|
AI-A0-0345 |
推理优化 |
推理领域 |
一种分布式推理技术,将模型分布到多个GPU上,协同处理推理请求。 |
分布式推理 (Distributed Inference) |
1. 模型并行: 将模型的不同层放置在不同的GPU上,按流水线或张量并行方式执行推理。 |
优点: 处理大模型或高吞吐量推理。 |
分布式系统, 模型并行, 数据并行。 将推理任务分布到多个GPU上,加速推理。 |
场景: 大模型推理, 高吞吐量服务。 |
模型划分: 将模型划分为多个部分,分配到不同GPU。 |
并行: 模型并行、数据并行、流水线并行。 |
描述为“将模型或数据分布到多个GPU上,通过并行计算和协作,加速推理过程”。 |
1. 根据模型大小和请求负载,选择并行策略(模型并行、数据并行或混合)。 |
“分布式推理流”: 模型流或数据流被分布到多个GPU流上。在模型并行中,每个GPU流处理模型的一部分,数据流在GPU间流动。在数据并行中,每个GPU流处理不同的数据流,结果流被聚合。 |
分布式推理需要GPU间通信,例如通过NCCL。通信延迟可能成为瓶颈。需要仔细设计并行策略以最小化通信。 |
模型并行, 数据并行, 流水线并行。 |
|
AI-A0-0346 |
推理优化 |
推理领域 |
一种推理优化技术,通过动态选择计算路径,根据输入调整计算量。 |
动态计算 (Dynamic Computation) |
1. 多出口网络: 在网络的多个中间层设置分类器,根据中间分类器的置信度提前退出。 |
优点: 对简单样本减少计算量, 加速推理。 |
动态网络, 条件计算。 根据输入样本动态调整计算量。 |
场景: 计算资源有限, 输入样本难度差异大的场景。 |
x: 输入样本。 |
条件判断: 如果 ci>τ,则退出或跳过。 |
描述为“根据输入样本的特征,动态决定计算路径,例如提前退出或跳过某些层,以减少计算量”。 |
1. 输入样本 x。 |
“动态计算流”: 输入流经过网络,在决策点评估置信度流。如果置信度流足够高,输出流提前产生;否则,继续流向更深的层流。这使得简单样本流快速通过,复杂样本流深入计算。 |
动态计算在GPU上可能导致控制流分歧,降低并行效率。需要仔细设计以保持GPU线程的同步。 |
提前退出, 条件计算。 |
|
AI-A0-0347 |
推理优化 |
推理领域 |
一种推理优化技术,将多个小算子合并为一个大算子,减少内核启动开销。 |
算子融合 (Operator Fusion) |
1. 识别模式: 寻找计算图中可以融合的算子序列,如卷积+批归一化+激活函数。 |
优点: 减少内核启动次数, 减少中间结果存储, 提高数据局部性。 |
计算图优化, 内核融合。 将多个小算子合并为一个算子,减少开销。 |
场景: 深度学习推理, 尤其是移动端和边缘设备。 |
算子序列: 如 y=激活(批归一化(卷积(x)))。 |
复合函数: 将多个函数合并为一个函数。 |
描述为“将多个连续的小算子合并为一个大的自定义算子,一次性计算,减少内核调用和内存访问”。 |
1. 分析计算图,找到可以融合的算子序列。 |
“算子融合流”: 多个小算子流被合并为一个融合算子流。输入流经过融合算子流,直接产生最终输出流,跳过了中间结果的存储和读取流。 |
算子融合通常由深度学习编译器自动完成。在GPU上,融合内核可以减少全局内存访问,提高带宽利用率。 |
层融合, 矩阵乘法融合。 |
|
AI-A0-0348 |
推理优化 |
推理领域 |
一种推理优化技术,将模型中的常量预先计算,减少运行时计算。 |
常量折叠 (Constant Folding) |
1. 识别常量: 在计算图中识别输入为常量的节点。 |
优点: 减少运行时计算, 简化计算图。 |
计算图优化, 常量传播。 将计算图中的常量表达式预先计算,并用结果替换。 |
场景: 任何深度学习模型推理优化。 |
常量节点: 输入为常量的计算节点。 |
常量传播: 如果节点的所有输入都是常量,则节点可以折叠为常量。 |
描述为“在计算图优化阶段,将输入为常量的节点预先计算,并用计算结果替换该节点,从而减少运行时计算”。 |
1. 遍历计算图,标记所有常量节点(如权重、偏置)。 |
“常量折叠流”: 在计算图流中,常量节点流被预先计算,其输出流被直接替换为常量流。这消除了运行时计算流,简化了数据流图。 |
常量折叠在编译时进行,不增加运行时开销。在多GPU中,每个GPU独立进行常量折叠。 |
计算图优化, 死代码消除。 |
|
AI-A0-0349 |
推理优化 |
推理领域 |
一种推理优化技术,移除计算图中对输出没有影响的节点。 |
死代码消除 (Dead Code Elimination) |
1. 识别死代码: 在计算图中,识别那些输出不被任何输出节点使用的节点。 |
优点: 减少不必要的计算, 简化计算图。 |
计算图优化, 无用代码删除。 删除计算图中对最终输出没有贡献的节点。 |
场景: 计算图优化, 如训练后模型可能包含未使用的节点。 |
计算图: 包含节点和边。 |
图可达性: 从输出节点反向遍历,标记所有可达节点,不可达的即为死代码。 |
描述为“从输出节点反向遍历计算图,标记所有对输出有贡献的节点,然后删除未标记的节点,从而消除死代码”。 |
1. 从计算图的输出节点开始,反向遍历,标记所有可达的节点。 |
“死代码消除流”: 在计算图流中,从输出流反向追溯,标记所有对流有贡献的节点流。未标记的节点流被删除,从而消除无效计算流。 |
死代码消除是编译器的标准优化,可以在模型编译时进行。在多GPU中,每个GPU独立进行。 |
常量折叠, 计算图优化。 |
|
AI-A0-0350 |
推理优化 |
推理领域 |
一种推理优化技术,将模型中的矩阵乘法与偏置加法融合为一个算子。 |
矩阵乘法-偏置融合 (MatMul-Bias Fusion) |
1. 模式: 矩阵乘法 Y=XW后接偏置加法 Z=Y+b。 |
优点: 减少一次内核启动, 减少中间结果 Y的存储和读取。 |
算子融合, 矩阵乘法。 将矩阵乘法和偏置加法融合为一个算子。 |
场景: 深度学习中的全连接层和卷积层(卷积可视为矩阵乘法)。 |
X: 输入矩阵。 |
融合: 将两个线性操作合并为一个。 |
描述为“将矩阵乘法和偏置加法合并为一个算子,一次性计算 XW+b,减少内核调用和内存访问”。 |
1. 在计算图中识别矩阵乘法节点和后继的偏置加法节点。 |
“乘加融合流”: 矩阵乘法流和偏置加法流被合并为一个融合计算流。输入流 X经过融合流直接输出 XW+b,跳过了中间结果 XW的存储流。 |
矩阵乘法-偏置融合是常见的优化,GPU上的矩阵乘法库(如cuBLAS)通常支持带有偏置的矩阵乘法。在多GPU中,融合操作可以本地进行。 |
算子融合, 层融合。 |
|
AI-A0-0351 |
推理优化 |
推理领域 |
一种推理优化技术,将模型中的批归一化与卷积融合,减少计算量。 |
卷积-批归一化融合 (Conv-BN Fusion) |
1. 融合原理: 卷积 y=w∗x+b和批归一化 z=γσ2+ϵy−μ+β可以合并为一个卷积:z=w′∗x+b′,其中 w′=σ2+ϵγw, b′=σ2+ϵγ(b−μ)+β。 |
优点: 减少层数, 加速推理, 减少内存访问。 |
算子融合, 卷积, 批归一化。 将卷积和批归一化合并为一个卷积,减少计算量。 |
场景: 卷积神经网络推理。 |
w,b: 卷积的权重和偏置。 |
线性变换合并: 两个线性变换合并为一个。 |
描述为“将卷积和批归一化两个线性变换合并为一个卷积,通过调整权重和偏置,使得输出与顺序执行两者相同”。 |
1. 训练完成后,固定卷积和批归一化的参数。 |
“卷积-批归一化融合流”: 卷积流和批归一化流被合并为一个等效的卷积流。输入流经过融合卷积流,直接得到批归一化后的输出流,跳过了中间流和归一化计算流。 |
卷积-批归一化融合是常见的推理优化,可以显著加速卷积网络。在GPU上,融合后的卷积可以使用高效的卷积内核。 |
算子融合, 批归一化。 |
|
AI-A0-0352 |
推理优化 |
推理领域 |
一种推理优化技术,将模型中的多个小全连接层合并为一个大全连接层。 |
全连接层融合 (Fully Connected Layer Fusion) |
1. 识别: 对于连续的多个全连接层(中间无非线性激活),可以将它们合并为一个全连接层。 |
优点: 减少矩阵乘法次数, 加速推理。 |
算子融合, 矩阵乘法。 将多个连续的线性变换合并为一个线性变换。 |
场景: 全连接网络, Transformer中的线性层。 |
W1,b1: 第一层的权重和偏置。 |
矩阵乘法: W=W2W1。 |
描述为“将多个连续的全连接层合并为一个全连接层,通过矩阵乘法结合律和偏置的线性变换实现”。 |
1. 检查全连接层序列,确保中间没有非线性激活。 |
“全连接融合流”: 多个线性变换流被合并为一个等效的线性变换流。输入流直接与融合权重流相乘,加上融合偏置流,得到输出流,跳过了中间变换流。 |
全连接层融合可以通过矩阵乘法实现,在GPU上,大矩阵乘法可能更高效。但融合后的矩阵可能很大,需要注意内存。 |
矩阵乘法融合, 层融合。 |
|
AI-A0-0353 |
推理优化 |
推理领域 |
一种推理优化技术,将模型中的多个小卷积层合并为一个大卷积层。 |
卷积层融合 (Convolution Layer Fusion) |
1. 识别: 对于连续的多个卷积层(中间无非线性激活),可以将它们合并为一个卷积层。 |
优点: 减少卷积次数, 加速推理。 |
算子融合, 卷积。 将 |
|
编号 |
类别 |
领域 |
模型配方 |
数学公式/定理/算法/模型/方法名称 |
数学公式/定理/算法/模型/方法的逐步思考推理过程及每一个步骤的数学方程式和参数选择/优化/迭代 |
精度/密度/误差/强度 |
底层规律/理论 |
典型应用场景和特征 |
变量/常量/参数列表及说明 |
数学特征 |
语言特征 |
时序和交互流程的所有细节/分步骤时序情况及数学方程式 |
流动模型和流向方法的数学描述 |
多GPU芯片执行情况和方程式列表 |
关联知识和算法 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
AI-A0-353 |
超长上下文 |
Token领域 |
一种基于层次化注意力机制的模型,将长序列划分为多个块,在块内和块间分别进行注意力计算,以线性复杂度处理长序列。 |
Hiera (Hierarchical Attention) |
1. 分块: 将长度为 L的序列划分为 N个块,每块长度为 B,L=N×B。 |
优点: 将 O(L2)复杂度降低为 O(NB2+N2d),当 B固定、d较小时接近线性。 |
层次化注意力, 线性复杂度。 通过分块和层次化注意力减少计算量。 |
场景: 长文档、 基因组序列等超长序列建模。 |
L: 序列长度。 |
分块: 将序列划分为块。 |
描述为“将长序列分块,先在每个块内进行局部注意力,再在块的代表向量上进行全局注意力,以线性复杂度处理长序列”。 |
**1. 输入序列 X∈RL×d。 |
“层次化注意力流”: 输入流被分割成多个块流。每个块流内部进行局部注意力流。然后,每个块流产生一个代表流,这些代表流进行全局注意力流。全局信息流被分发到各个块流,与局部信息流融合,形成最终的层次化表示流。 |
块内注意力可以在每个GPU上独立计算(如果每个GPU处理若干块)。块间注意力需要跨GPU通信代表向量。通过合理分配块到GPU,可以实现较好的并行性。 |
Longformer, BigBird。 |
|
AI-A0-354 |
超长上下文 |
Token领域 |
一种基于状态空间模型(SSM)的序列建模方法,通过线性时不变系统对长序列进行建模,实现线性复杂度。 |
S4 (Structured State Space Sequence Model) |
1. 状态空间模型: 将序列映射到隐状态,通过线性微分方程建模:h′(t)=Ah(t)+Bx(t), y(t)=Ch(t)+Dx(t)。 |
优点: 线性复杂度, 可并行训练, 递归推理。 |
状态空间模型, 线性时不变系统。 通过线性微分方程和离散化建模长程依赖。 |
场景: 长序列建模, 如语音、 时间序列、 基因组。 |
x(t): 连续输入。 |
线性微分方程: h′=Ah+Bx。 |
描述为“使用状态空间模型(线性微分方程)对序列进行建模,离散化为线性递归形式,通过卷积计算输出,实现线性复杂度”。 |
**1. 初始化状态矩阵 A,B,C,D(可学习)。 |
“状态空间流”: 输入流 x(t)通过线性系统流(A,B,C,D)映射到输出流 y(t)。隐状态流 h(t)积累历史信息。离散化后,系统流变为线性递归流,可以高效计算。卷积视角下,系统流等价于一个卷积核流,与输入流卷积得到输出流。 |
S4的卷积模式可以并行计算(利用FFT),递归模式适合自回归推理。在多GPU中,卷积操作可以利用并行卷积算法。状态矩阵 A的结构化设计(如对角矩阵)可以减少参数和计算量。 |
HiPPO, S5, Mamba。 |
|
AI-A0-355 |
超长上下文 |
Token领域 |
一种基于结构化状态空间模型的变体,通过选择性扫描机制实现数据依赖的状态转移,提高建模能力。 |
Mamba |
1. 选择性扫描: 状态矩阵 B,C和步长 Δ成为输入 x的函数,实现数据依赖:B(x),C(x),Δ(x)。 |
优点: 数据依赖, 建模能力更强, 硬件高效。 |
状态空间模型, 选择性扫描。 通过输入依赖的状态矩阵实现上下文感知的序列建模。 |
场景: 长序列建模, 语言建模, 基因组。 |
x: 输入序列。 |
数据依赖: B,C,Δ是 x的函数。 |
描述为“在状态空间模型中,使参数 B,C,Δ成为输入的函数,实现数据依赖的序列建模,并通过硬件感知的并行扫描算法高效计算”。 |
**1. 给定输入 x,通过线性投影计算 B(x),C(x),Δ(x)。 |
“选择性状态空间流”: 参数流 B,C,Δ根据输入流动态变化,使得状态转移流和输出流适应输入内容。隐状态流通过并行扫描流更新,允许高效并行计算。 |
Mamba的并行扫描算法利用GPU的并行计算能力,将递归转化为并行前缀和操作。在多GPU中,需要跨GPU通信进行扫描操作,但可以通过分段扫描和合并减少通信。 |
S4, 并行扫描。 |
|
AI-A0-356 |
超长上下文 |
Token领域 |
一种基于滑动窗口的注意力机制,每个token只关注其前后固定窗口内的token,实现线性复杂度。 |
滑动窗口注意力 (Sliding Window Attention) |
1. 窗口定义: 对于位置 i,其注意力窗口为 [i−w,i+w],其中 w是窗口半径。 |
优点: 线性复杂度 O(L×w), 保留局部上下文。 |
局部注意力, 滑动窗口。 通过限制每个token的注意力范围减少计算量。 |
场景: 长序列建模, 如文本、 时间序列。 |
w: 窗口半径。 |
带状矩阵: 注意力矩阵是带状稀疏矩阵。 |
描述为“每个token只关注其前后固定窗口内的token,计算局部注意力,实现线性复杂度”。 |
**1. 对于每个位置 i,计算查询 qi。 |
“滑动窗口流”: 每个token的注意力流被限制在一个固定大小的窗口流内。信息在局部窗口内流动,无法直接跨越长距离。可以通过堆叠多层来扩大感受野。 |
滑动窗口注意力可以通过带状矩阵乘法或掩码实现。在GPU上,可以利用优化过的带状矩阵乘法。在多GPU中,序列可以分区,但边界处需要重叠窗口。 |
Longformer, 局部注意力。 |
|
AI-A0-357 |
超长上下文 |
Token领域 |
一种基于局部敏感哈希(LSH)的注意力机制,将相似的token分配到同一个桶中,只在桶内计算注意力,实现近似注意力。 |
LSH注意力 (Locality-Sensitive Hashing Attention) |
1. LSH哈希: 使用随机投影哈希函数 h(x)=argmax([xR;−xR]),其中 R是随机矩阵。 |
优点: 近似全局注意力, 复杂度 O(LlogL)。 |
近似注意力, 局部敏感哈希。 通过哈希将相似token聚簇,减少注意力计算量。 |
场景: 极长序列, 如文档、 基因组。 |
x: 查询或键向量。 |
哈希: h(x)=argmax([xR;−xR])。 |
描述为“使用局部敏感哈希将查询和键映射到哈希桶,使得相似向量落入同一桶,然后只在每个桶内计算注意力”。 |
**1. 计算查询 Q和键 K的LSH哈希值。 |
“哈希-桶注意力流”: 查询流和键流通过LSH哈希函数映射到桶流。每个桶流内的token流计算注意力流。分块机制确保局部连续性。这样,每个token只与同桶及相邻块的token交互,近似全局注意力流。 |
LSH注意力需要计算哈希和排序,在GPU上可能效率较低。桶内注意力可以并行计算,但负载可能不均衡。在多GPU中,需要根据哈希值重新分布序列,通信开销大。 |
Reformer, 近似注意力。 |
|
AI-A0-358 |
超长上下文 |
Token领域 |
一种基于线性注意力的变体,通过核函数近似注意力,实现线性复杂度,并保持因果性。 |
线性注意力 (Linear Attention) |
1. 核函数: 定义特征映射 ϕ,使得 sim(q,k)=ϕ(q)Tϕ(k)近似 exp(qTk/d)。 |
优点: 线性复杂度 O(Ld2)(若特征维度固定), 可并行训练, 递归推理。 |
核方法, 线性复杂度。 通过核技巧将注意力分解为线性运算。 |
场景: 长序列建模, 自回归生成。 |
Q,K,V: 查询、键、值。 |
核近似: exp(qTk)≈ϕ(q)Tϕ(k)。 |
描述为“使用核函数将注意力中的指数点积转化为特征映射的点积,然后利用矩阵乘法的结合律先计算键和值的聚合,再与查询相乘,实现线性复杂度”。 |
**训练(并行): |
“线性化注意力流”: 查询流和键流通过特征映射 ϕ转换。注意力计算流被分解为两个流:键值聚合流 KV和键聚合流 K1。然后查询流与这两个聚合流相互作用,得到输出流。递归版本中,状态流 S和 z累积历史信息,实现线性时间推理。 |
线性注意力训练时可以并行计算,推理时递归计算,内存占用低。在多GPU中,训练时聚合操作需要跨GPU归约。递归推理难以并行,但可以分段并行。 |
Performer, 因果注意力。 |
|
AI-A0-359 |
超长上下文 |
Token领域 |
一种基于线性注意力的变体,使用随机正交特征(ORF)近似softmax核,提供无偏估计。 |
Performer (Random Feature Attention) |
1. 随机特征: 使用随机正交矩阵 W和函数 ϕ(x)=m1exp(Wx−∥x∥2/2),使得 E[ϕ(q)Tϕ(k)]=exp(qTk)。 |
优点: 无偏近似softmax, 线性复杂度, 支持自回归训练和推理。 |
随机特征, 核近似。 使用正交随机特征近似softmax核,实现线性注意力。 |
场景: 长序列建模, 需要精确softmax近似的场景。 |
W: 随机正交矩阵,W∈Rm×d。 |
随机特征: ϕ(x)=m1exp(Wx−∥x∥2/2)。 |
描述为“使用正交随机特征来近似softmax核函数,将注意力计算转化为线性形式,从而实现线性复杂度”。 |
**1. 生成随机正交矩阵 W(从正态分布采样后正交化)。 |
“随机特征注意力流”: 查询流和键流通过随机特征映射 ϕ转换,其中 ϕ使用随机正交矩阵 W和指数函数。这个映射流将原始的指数点积核近似为随机特征的点积。然后,与线性注意力相同,进行键值聚合流和键和聚合流,最后与查询特征流结合。随机特征流提供了对softmax核的无偏估计,且方差较小。 |
Performer需要生成随机矩阵 W,可以在训练前固定或定期更新。特征映射涉及指数计算,可能数值不稳定。在多GPU中,W在所有GPU上一致,特征映射可以独立计算。 |
线性注意力, 随机特征。 |
|
AI-A0-360 |
超长上下文 |
Token领域 |
一种基于循环神经网络的序列模型,通过门控机制和循环连接处理长序列,实现线性复杂度。 |
RWKV (Receptance Weighted Key Value) |
1. 时间混合: 类似注意力,但通过递归计算:ot=∑i=1twt−iki∑i=1twt−ikivi,其中 wt−i是衰减权重。 |
优点: 线性复杂度, 可并行训练, 递归推理, 无注意力机制。 |
循环神经网络, 线性注意力。 通过递归加权和替代注意力,实现线性复杂度。 |
场景: 长序列语言建模, 替代Transformer。 |
xt: 输入向量。 |
递归加权和: St=St−1+ktvt, Zt=Zt−1+kt。 |
描述为“通过时间混合和通道混合两个模块处理序列,时间混合使用递归加权和模拟注意力,通道混合使用门控前馈网络,实现线性复杂度”。 |
**训练(并行): |
“递归加权流”: 输入流 xt通过线性变换产生键流 kt、值流 vt和接收门流 rt。状态流 S和 Z累积加权键值流。输出流 ot是接收门流调制的状态流比例。这模拟了注意力流,但通过递归实现线性复杂度。 |
RWKV训练时可以利用并行前缀和计算,推理时递归计算。在多GPU中,训练时前缀和需要跨GPU扫描。递归推理难以并行,但可以分段处理。 |
线性注意力, 循环神经网络。 |
|
AI-A0-361 |
超长上下文 |
Token领域 |
一种基于卷积的序列模型,使用扩张卷积扩大感受野,以对数复杂度处理长序列。 |
扩张卷积 (Dilated Convolution) |
1. 扩张卷积: 卷积核在输入上间隔采样,间隔由扩张率 d控制。对于一维输入 x和核 w,输出 y[i]=∑kw[k]⋅x[i−d⋅k]。 |
优点: 并行计算, 感受野大, 线性复杂度。 |
卷积神经网络, 扩张卷积。 通过间隔采样扩大感受野,高效捕获长程依赖。 |
场景: 序列建模, 如WaveNet、 时间序列预测。 |
x: 输入序列。 |
扩张卷积: y[i]=∑k=0K−1w[k]x[i−d⋅k]。 |
描述为“使用扩张卷积,卷积核在输入上间隔采样,通过堆叠多层扩张率指数增长的卷积层,实现对数复杂度的长序列建模”。 |
**1. 定义扩张卷积层,扩张率 d,核大小 K,因果填充(左侧填充 (K−1)∗d)。 |
“扩张卷积流”: 输入流通过多层扩张卷积流。每层卷积流的感受野流以指数速度扩大,使得高层可以捕获长距离依赖。信息流通过卷积核在序列上传播,但由于扩张,可以跳过近距离直接关注远距离。 |
扩张卷积可以并行计算(利用卷积算子)。在GPU上,可以使用cuDNN中的扩张卷积实现。在多GPU中,序列可以分区,但边界处需要重叠区域以满足卷积需求。 |
因果卷积, WaveNet。 |
|
AI-A0-362 |
超长上下文 |
Token领域 |
一种基于记忆网络的模型,将长序列的信息压缩到固定大小的记忆向量中,通过读写记忆实现长程依赖。 |
记忆网络 (Memory Network) |
1. 记忆存储: 将输入序列编码为记忆向量 mi=f(xi),存储到记忆矩阵 M中。 |
优点: 记忆大小固定, 可处理无限长序列(理论上)。 |
记忆增强, 外部记忆。 通过外部记忆存储历史信息,实现长程依赖。 |
场景: 问答、 对话系统, 需要长时记忆的场景。 |
xi: 输入token。 |
注意力: p=softmax(qTM)。 |
描述为“将输入序列编码为记忆向量存储到外部记忆中,查询时通过注意力读取相关记忆,实现长程信息访问”。 |
**1. 编码记忆:对于每个输入 xi,计算 mi=f(xi),存入记忆 M。 |
“记忆流”: 输入流被编码为记忆流存入记忆库。查询流与记忆流进行注意力交互,产生加权记忆流。输出流基于加权记忆流生成。记忆库可以不断更新,存储长历史信息。 |
记忆网络的记忆矩阵大小固定,因此计算复杂度与序列长度无关(除了编码记忆)。在多GPU中,记忆可以分布存储,但查询时需要全局注意力。 |
注意力机制, 键值缓存。 |
|
AI-A0-363 |
超长上下文 |
Token领域 |
一种基于Transformer的模型,通过稀疏注意力机制和局部-全局注意力处理长序列,实现线性复杂度。 |
Longformer |
1. 滑动窗口注意力: 每个token关注其前后 w个token。 |
优点: 线性复杂度, 可处理数千token的序列。 |
稀疏注意力, 滑动窗口。 通过局部窗口注意力和任务特定全局注意力处理长序列。 |
场景: 长文档建模, 如文本分类、 问答、 摘要。 |
w: 窗口大小。 |
带状矩阵: 局部注意力对应带状稀疏矩阵。 |
描述为“使用滑动窗口注意力,每个token只关注其附近固定窗口内的token,同时为一些特定token添加全局注意力,使其关注所有token并被所有token关注”。 |
**1. 对于每个位置 i: |
“局部+全局流”: 大多数token的信息流被限制在局部窗口内,形成局部流。全局token作为信息枢纽,形成全局流:所有token的信息流向全局token,全局token的信息也流向所有token。这种设计使得模型既能高效处理长序列,又能通过全局token捕获整个序列的上下文。 |
Longformer的滑动窗口注意力可以通过带状矩阵乘法或因果掩码实现。全局注意力需要全连接计算,但全局token数量很少。在多GPU中,序列可以分区,但全局token可能需要跨GPU通信。 |
BigBird, 滑动窗口注意力。 |
|
AI-A0-364 |
超长上下文 |
Token领域 |
一种基于Transformer的模型,通过稀疏注意力机制结合随机、局部和全局注意力处理长序列。 |
BigBird |
1. 随机注意力: 每个token随机关注 r个其他token。 |
优点: 将注意力复杂度从 O(L2)降低到 O(L), 可处理更长序列。 |
稀疏注意力, 图论。 通过限制每个token的注意力范围,实现线性复杂度,同时保持全局信息流。 |
场景: 长文本建模, 如文档分类、 长序列问答。 |
L: 序列长度。 |
稀疏矩阵: 注意力矩阵是稀疏的,非零元素数 O(L)。 |
描述为“每个token只关注三类token:随机选择的少数token、相邻的局部窗口内的token、以及一些全局token,从而大幅减少注意力计算量”。 |
**1. 构建稀疏注意力矩阵 A: |
“稀疏信息流”: 注意力流被限制在稀疏图 A定义的路径上。局部窗口流确保每个token能感知其邻近上下文;随机流引入远程连接,允许信息在任意两个token间以一定概率流动;全局流通过少数全局token作为枢纽,收集和分发全局信息。这三种流的组合使得整个序列的信息可以在线性复杂度内有效传递。 |
BigBird的稀疏注意力模式允许使用稀疏矩阵乘法或掩码实现。在多头注意力中,每个头可以共享相同的稀疏模式或使用不同的随机模式。在多GPU中,序列可以按块划分,但全局token需要特殊处理(如广播)。 |
Longformer, Sparse Transformer。 |
|
AI-A0-365 |
超长上下文 |
Token领域 |
一种基于线性注意力的变体,通过可分解核函数实现线性复杂度,并保持因果性。 |
Causal Linear Attention |
1. 核函数: 使用可分解核函数,如 ϕ(x)=elu(x)+1,使得 ϕ(q)Tϕ(k)≈exp(qTk/d)。 |
优点: 线性复杂度, 可并行训练, 递归推理, 保持因果性。 |
线性注意力, 因果性。 通过可分解核函数实现因果线性注意力。 |
场景: 自回归语言建模, 长序列生成。 |
qt,kt,vt: 查询、键、值向量。 |
递归: St=St−1+ϕ(kt)vtT, zt=zt−1+ϕ(kt)。 |
描述为“使用可分解核函数将注意力线性化,通过递归累积状态实现因果注意力,线性复杂度”。 |
**训练(并行): |
“因果线性注意力流”: 与线性注意力类似,但递归流确保每个token只关注历史token。状态流 S和 z累积历史键值流。查询流与状态流交互,产生输出流。这模拟了因果注意力,但计算复杂度线性。 |
训练时可以利用并行前缀和计算,推理时递归计算。在多GPU中,训练时前缀和需要跨GPU扫描。递归推理难以并行,但可以分段处理。 |
线性注意力, 自回归生成。 |
|
AI-A0-366 |
超长上下文 |
Token领域 |
一种基于状态空间模型的变体,通过高维投影和结构化状态矩阵高效处理长序列。 |
S5 (Structured State Space Sequence Model) |
1. 状态空间模型: 同S4,使用线性微分方程。 |
优点: 线性复杂度, 可并行训练, 递归推理, 表达能力强。 |
状态空间模型, 结构化矩阵。 通过高维投影和结构化状态矩阵增强S4。 |
场景: 长序列建模, 如语音、 视频、 基因组。 |
同S4, 但 A是DPLR矩阵。 |
DPLR矩阵: A=Λ−PP∗,其中 Λ是对角矩阵,P是低秩矩阵。 |
描述为“在状态空间模型中使用高维投影和结构化状态矩阵(对角加低秩),并通过并行扫描高效计算,实现线性复杂度长序列建模”。 |
**1. 将输入投影到高维空间:x′=Wx。 |
“增强状态空间流”: 输入流先经过高维投影流,然后进入状态空间模型流。状态矩阵流 A采用DPLR结构,允许更复杂的动态。并行扫描流使得计算高效。 |
S5的并行扫描可以利用GPU并行计算。在多GPU中,需要跨GPU通信进行扫描操作。 |
S4, 并行扫描。 |
|
AI-A0-367 |
超长上下文 |
Token领域 |
一种基于注意力机制的模型,通过可学习稀疏注意力模式,动态选择每个查询要关注的键,实现线性复杂度。 |
Adaptive Sparse Attention |
1. 学习注意力模式: 为每个查询学习一个稀疏注意力掩码 Mi,其中 Mij=1表示查询 i关注键 j。 |
优点: 自适应, 可学习长距离依赖, 线性复杂度。 |
稀疏注意力, 动态选择。 通过可学习函数动态决定每个查询的注意力范围。 |
场景: 长序列建模, 需要自适应注意力的场景。 |
qi,kj: 查询和键向量。 |
稀疏: 只有部分位置计算注意力。 |
描述为“通过可学习函数为每个查询动态选择要关注的键,只计算这些位置的注意力分数,实现线性复杂度”。 |
**1. 给定查询 qi和所有键 kj,通过函数 f计算注意力掩码 Mi=f(qi,{kj}),其中 Mij∈{0,1}。 |
“自适应稀疏注意力流”: 对于每个查询流,掩码预测流根据查询和键流动态选择一小部分键流进行交互。注意力流只在被选中的键流上计算,大大减少了计算量。掩码预测流需要轻量级以避免过大开销。 |
自适应稀疏注意力的掩码预测需要额外计算,但整体仍是线性复杂度。在多GPU中,掩码预测可能需要全局键信息,通信开销大。 |
稀疏注意力, 动态注意力。 |
|
AI-A0-368 |
推理优化 |
推理领域 |
一种推理加速技术,通过跳过部分层或头的计算来减少推理时间。 |
层跳跃 (Layer Skipping) |
1. 决策: 对于每个输入样本,动态决定跳过哪些层或注意力头。决策可以基于输入特征、中间激活的阈值等。 |
优点: 减少计算量, 加速推理。 |
动态计算, 自适应推理。 根据输入难度自适应跳过部分计算,提高效率。 |
场景: 对推理速度要求高, 且可以接受轻微性能下降的场景。 |
xl: 第 l层的输入。 |
条件执行: yl=zl⋅fl(xl)+(1−zl)⋅xl。 |
描述为“根据输入样本的特征,动态决定是否执行某些层或注意力头,跳过不必要的计算”。 |
1. 对于每个输入样本,逐层处理: |
“条件计算流”: 网络流在每一层经过一个决策节点,决定是否进入该层的计算流。如果跳过,则输入流直接绕过该层流;否则,输入流进入该层流进行变换。这使得简单样本可以快速通过,复杂样本经历更多计算流。 |
层跳跃在推理时可以减少计算量,但决策本身可能引入开销。在多GPU中,跳跃决策可能导致负载不均衡。 |
动态网络, 条件计算。 |
|
AI-A0-369 |
推理优化 |
推理领域 |
一种推理加速技术,将模型量化为低精度(如INT8)以减少内存占用和加速计算。 |
训练后量化 (Post-Training Quantization, PTQ) |
1. 校准: 使用少量校准数据,计算每一层激活的统计量(如最大值、最小值)。 |
优点: 减少模型大小, 加速推理, 降低内存带宽需求。 |
模型压缩, 量化。 将模型参数和激活从高精度浮点数量化为低精度整数,以加速推理。 |
场景: 边缘设备部署, 需要减少模型大小和加速推理。 |
x: 原始FP32张量。 |
x |
)}{127}。<br>∗∗x_{\text{int8}}$:** 量化后的INT8张量。 |
线性量化: xint8=round(x/s)。 |
描述为“使用校准数据确定缩放因子,将训练好的模型权重和激活量化为低精度整数,推理时再进行反量化或直接使用整数计算”。 |
1. 准备少量校准数据。 |
“量化压缩流”: 原始高精度权重流和激活流通过量化操作被压缩为低精度整数流。在推理时,整数流通过反量化恢复为近似的高精度流进行计算,或者直接使用整数运算流。这减少了数据流的大小,提高了计算效率。 |
|
AI-A0-370 |
推理优化 |
推理领域 |
一种推理加速技术,在训练过程中模拟量化操作,使模型适应量化误差。 |
量化感知训练 (Quantization-Aware Training, QAT) |
1. 插入伪量化节点: 在训练的前向传播中,在权重和激活后插入伪量化操作,模拟量化过程。伪量化包括量化和反量化:xquant=quantize(x)=dequantize(round(x/s))。 |
优点: 相比PTQ, 通常精度损失更小, 模型更适应量化。 |
量化, 训练模拟。 在训练中模拟量化过程,使模型参数适应低精度表示。 |
场景: 对精度要求较高的量化部署。 |
x: 原始张量。 |
伪量化: xquant=dequantize(round(x/s))。 |
描述为“在训练过程中插入模拟量化的操作,使模型在训练时就适应量化带来的误差,从而在真正量化时保持更高精度”。 |
1. 在训练图中插入伪量化节点:在权重和激活后加入量化和反量化操作。 |
“量化模拟流”: 在训练流中,权重流和激活流经过伪量化模块,该模块模拟了量化噪声流。模型参数在噪声流下调整,使得最终模型对量化不敏感。训练完成后,真正的量化流取代模拟流。 |
QAT训练时需要模拟量化操作,可能增加训练时间。在推理时,与PTQ类似,可以使用低精度计算。 |
训练后量化, 模型压缩。 |
|
AI-A0-371 |
推理优化 |
推理领域 |
一种推理加速技术,将多个小矩阵乘法合并为一个大矩阵乘法,以提高GPU利用率。 |
矩阵乘法融合 (Matrix Multiplication Fusion) |
1. 识别: 在计算图中识别可以融合的连续矩阵乘法操作。例如,多个线性层可以合并为一个更大的线性层。 |
优点: 减少内核启动开销, 提高GPU利用率, 加速计算。 |
计算图优化, 算子融合。 将多个连续的线性变换合并为一个,减少计算和内存访问开销。 |
场景: 深度学习模型推理, 尤其是Transformer中的线性层。 |
W1,W2: 两个权重矩阵。 |
矩阵乘法结合律: W2(W1x)=(W2W1)x。 |
描述为“将多个连续的线性变换合并为一个线性变换,通过矩阵乘法的结合律减少计算步骤”。 |
1. 分析计算图,找到连续的线性变换(中间无非线性激活)。 |
“融合流”: 多个线性变换流被合并为一个等效的线性变换流。输入流直接与融合后的权重流相乘,得到输出流,跳过了中间流,减少了计算和内存流。 |
矩阵乘法融合可以在编译时或运行时进行。在GPU上,大矩阵乘法可以更高效地利用Tensor Core。在多GPU中,融合后的矩阵可能更大,需要相应的并行策略。 |
算子融合, 计算图优化。 |
|
AI-A0-372 |
推理优化 |
推理领域 |
一种推理加速技术,将多个小操作(如加法、乘法、激活函数)融合为一个内核,减少内核启动开销。 |
算子融合 (Operator Fusion) |
1. 识别模式: 识别计算图中经常连续出现的小操作,如卷积后接批归一化再接激活函数。 |
优点: 减少内核启动和内存访问开销, 加速推理。 |
计算图优化, 内核融合。 将多个逐元素操作或小操作合并为一个内核执行。 |
场景: 深度学习模型推理, 尤其是移动端和边缘设备。 |
多个小操作: 如 y=ReLU(BatchNorm(Conv(x)))。 |
组合函数: 将多个函数合并为一个复合函数。 |
描述为“将多个小的、连续的操作合并为一个内核执行,以减少内核启动次数和中间结果的内存读写”。 |
1. 分析计算图,找到可以融合的操作序列。 |
“内核融合流”: 多个小操作流被合并为一个复合操作流。数据流在融合内核中连续处理,避免了中间结果流写回和读取,提高了数据局部性。 |
算子融合通常由深度学习编译器(如TVM、TensorRT)自动完成。在GPU上,融合内核可以减少全局内存访问,提高带宽利用率。 |
矩阵乘法融合, 计算图优化。 |
|
AI-A0-373 |
推理优化 |
推理领域 |
一种推理加速技术,通过提前退出机制,对于简单样本提前输出结果,减少计算量。 |
提前退出 (Early Exiting) |
1. 退出点: 在模型中间层设置多个退出点,每个退出点对应一个分类器。 |
优点: 对简单样本减少计算量, 加速推理。 |
动态推理, 条件计算。 根据样本难度自适应选择计算深度。 |
场景: 分类任务, 特别是计算资源受限的场景。 |
x: 输入样本。 |
条件判断: 如果 max(pi)>τ,则退出。 |
描述为“在模型中间层添加分类器,如果某个中间分类器的置信度足够高,就提前输出结果,不再继续后续计算”。 |
1. 在模型第 i=1,...,T−1层后添加分类器 Ci。 |
“条件深度流”: 输入流依次流过各层。在每层后,分类器流计算置信度流。如果置信度流超过阈值,则输出流提前产生,否则继续流向下一层流。这使得简单样本流快速退出,复杂样本流深入计算。 |
提前退出需要额外的分类器参数,但节省了后续层的计算。在多GPU中,如果模型并行,提前退出可能导致负载不均衡。 |
动态网络, 条件计算。 |
|
AI-A0-374 |
推理优化 |
推理领域 |
一种推理加速技术,通过跳过部分注意力头或前馈网络的计算来减少推理时间。 |
头剪枝/头跳过 (Head Pruning/Skipping) |
1. 重要性评估: 评估每个注意力头或前馈网络的重要性(例如,基于权重范数或梯度)。 |
优点: 减少计算量, 加速推理。 |
模型压缩, 动态计算。 通过跳过不重要的头或前馈网络减少计算。 |
场景: 对推理速度要求高的场景, 如实时应用。 |
hi: 第 i个头。 |
条件执行: 如果 si<τ,则跳过该头。 |
描述为“根据注意力头或前馈网络的重要性,在推理时跳过不重要的头或前馈网络,以减少计算量”。 |
**1. 计算每个头的重要性分数 si(例如,权重范数)。 |
“选择性头流”: 注意力头流中,只有重要的头流被激活,不重要的头流被跳过。这减少了注意力计算流的总量。 |
头跳过需要评估重要性,可能离线进行。在多GPU中,每个GPU独立跳过本地头,但需要确保一致性。 |
模型压缩, 注意力机制。 |
|
AI-A0-375 |
推理优化 |
推理领域 |
一种推理加速技术,将模型中的矩阵乘法分解为低秩矩阵的乘积,减少计算量。 |
低秩分解 (Low-Rank Decomposition) |
1. 分解: 将权重矩阵 W∈Rm×n分解为两个小矩阵的乘积:W≈UV,其中 U∈Rm×r, V∈Rr×n,r≪min(m,n)。 |
优点: 减少参数和计算量, 加速推理。 |
模型压缩, 矩阵近似。 通过低秩近似减少矩阵乘法的计算复杂度。 |
场景: 模型部署, 资源受限环境。 |
W: 原始权重矩阵。 |
矩阵分解: W≈UV。 |
描述为“将大权重矩阵分解为两个小矩阵的乘积,推理时依次进行两次小矩阵乘法,以减少计算量”。 |
1. 对权重矩阵 W进行低秩分解,得到 U和 V(例如通过SVD)。 |
“低秩近似流”: 权重流 W被分解为两个低秩流 U和 V。输入流 x先与 V流相乘,得到中间流 z,再与 U流相乘,得到输出流 y。这减少了计算流的数据量,但引入了近似误差。 |
低秩分解减少了矩阵乘法的计算量,但可能增加内存访问次数。在GPU上,两个小矩阵乘法可能不如一个大矩阵乘法高效,需要权衡。在多GPU中,分解后的矩阵可以分布存储。 |
奇异值分解, 模型压缩。 |
|
AI-A0-376 |
推理优化 |
推理领域 |
一种推理加速技术,将模型中的多个小卷积核合并为一个大卷积核。 |
卷积核融合 (Kernel Fusion) |
1. 识别: 对于连续的卷积层(中间无非线性激活),可以将它们的卷积核合并。 |
优点: 减少卷积次数, 加速推理。 |
算子融合, 卷积。 将多个连续卷积合并为一个卷积,减少计算量。 |
场景: 卷积神经网络推理, 如MobileNet、EfficientNet。 |
W1,W2: 两个卷积层的权重(卷积核)。 |
卷积结合律: (W2∗W1)∗x=W2∗(W1∗x)。 |
描述为“将多个连续的卷积层合并为一个卷积层,通过卷积核的卷积运算实现”。 |
1. 检查卷积层序列,确保中间没有非线性激活。 |
“卷积融合流”: 多个卷积核流被合并为一个等效的卷积核流。输入流直接与融合后的卷积核流进行卷积,跳过了中间的特征图流,减少了计算和内存流。 |
卷积核融合需要计算卷积核的卷积,可能增加离线计算开销。在GPU上,融合后的大卷积可能效率更高。 |
算子融合, 卷积神经网络。 |
|
AI-A0-377 |
推理优化 |
推理领域 |
一种推理加速技术,通过模型蒸馏将大模型的知识转移到小模型,小模型推理更快。 |
模型蒸馏 (Model Distillation) |
1. 教师模型: 训练一个大的教师模型。 |
优点: 小模型推理快, 保持教师模型大部分性能。 |
知识蒸馏, 模型压缩。 将大模型的知识转移到小模型,加速推理。 |
场景: 模型部署, 资源受限环境。 |
T: 温度参数,软化softmax。 |
软标签: pit=∑jexp(zjt/T)exp(zit/T)。 |
描述为“训练一个大模型作为教师,然后用教师模型的软标签训练一个小模型,使学生模型模仿教师的行为,实现小模型快速推理”。 |
1. 训练教师模型。 |
“知识蒸馏流”: 教师模型流产生的软标签流(包含类别间关系)作为监督信号,与学生模型流的输出流计算KL散度流。学生模型流同时拟合硬标签流和软标签流,从而获得教师模型流的知识。 |
模型蒸馏训练时需要教师模型的前向传播生成软标签,增加训练开销。推理时使用学生模型,速度快。在多GPU中,教师模型可以并行训练,学生模型也可以并行训练。 |
知识蒸馏, 模型压缩。 |
|
AI-A0-378 |
推理优化 |
推理领域 |
一种推理加速技术,将模型中的浮点权重转换为整数权重,并利用整数运算单元加速。 |
整数量化 (Integer Quantization) |
1. 量化: 将权重和激活量化为INT8( |

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
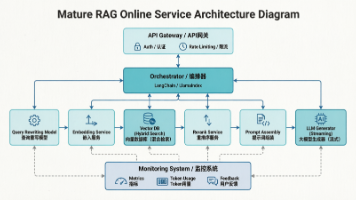
 2
2 0
0- 0



 已为社区贡献181条内容
已为社区贡献181条内容

所有评论(0)