一句 idea,直接出论文——AutoResearchClaw 是怎么做到的?
一句话出论文?AutoResearchClaw 这个全自动研究系统有点东西
最近 AI 圈子里流行一个话题:Karpathy 搞了个 autoresearch,把实验循环给自动化了。结果马上就有人说,那算什么,老子把整个实验室都自动化了。
这个项目叫 AutoResearchClaw,🦞,一只"会做研究"的龙虾。项目出自 aiming-lab,核心卖点就一句话:你说一个研究方向,它给你一篇会议论文,文献真实、实验真跑、引用可验证,全程不需要人工干预。
听起来有点离谱,但它确实把流程全打通了。下面来拆一拆。
它到底做了什么
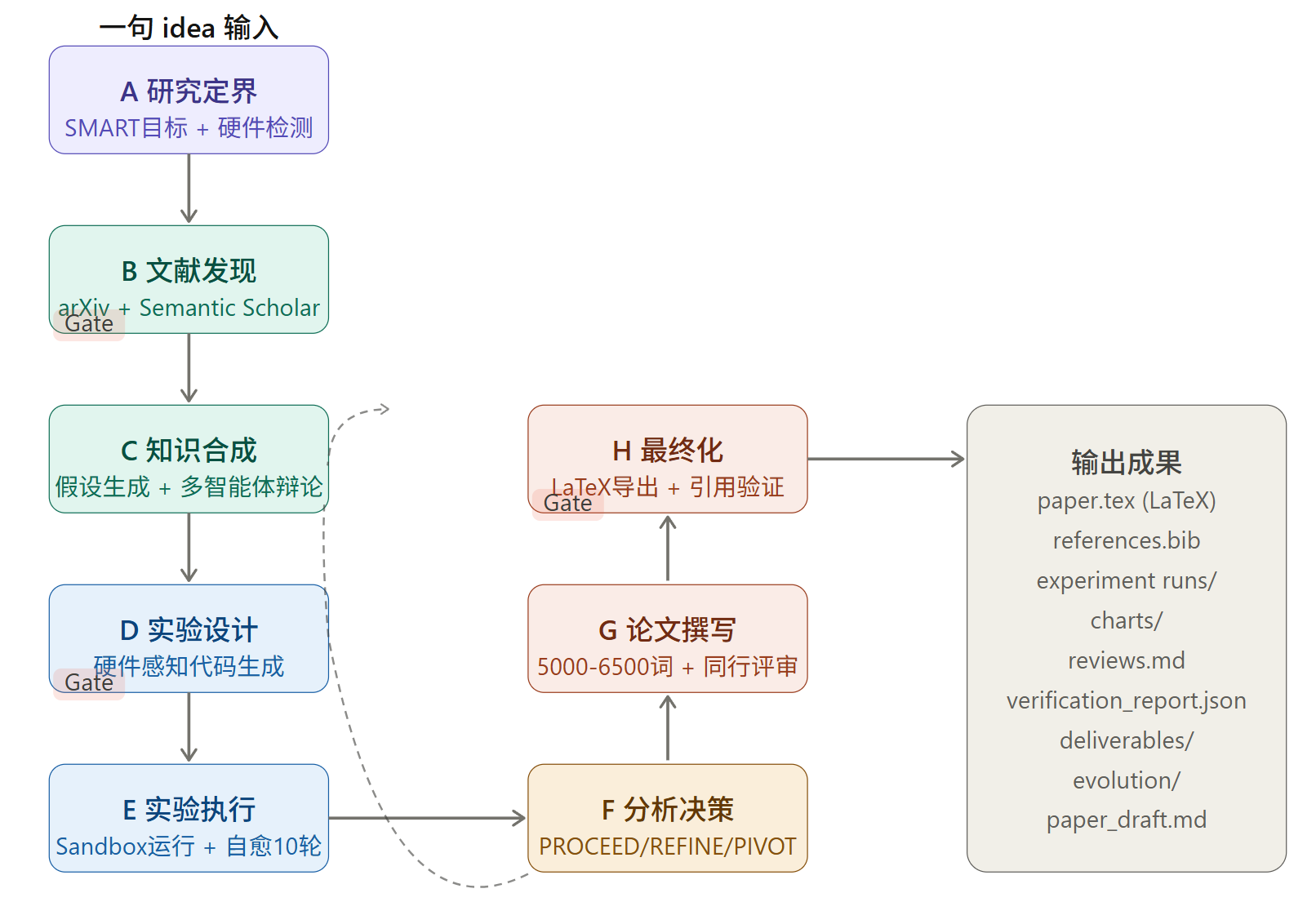
简单说,AutoResearchClaw 把一个 AI 研究员的工作流拆成了 8 大阶段、23 个子阶段,然后用多智能体 + 工具调用的方式把每个阶段都自动化掉。
上面那张图就是整个流水线的结构。从"一句话输入"出发,依次经过研究定界、文献发现、知识合成、实验设计与执行、结果分析决策,再到论文撰写和最终化,最后吐出一整套可直接投会的材料。三个 Gate 节点是人工确认点,如果你不想管,加上 --auto-approve 参数,让它自己跑完。
整个逻辑链条走完,输出目录里会有 paper.tex、references.bib、实验代码与跑出来的 JSON 结果、带误差棒的图表、模拟同行评审记录、引用验证报告,以及打包好的 deliverables/ 文件夹,Overleaf 直接导入就能编译。
文献这块怎么解决幻觉问题
LLM 做研究最大的硬伤就是引用——大模型编造引用这件事已经不是秘密了。AutoResearchClaw 用了一套 4 层验证机制来对抗这个问题:
首先通过 arXiv + Semantic Scholar API 实时抓取 50+ 篇真实论文,然后对每一条引用跑四道关卡:arXiv ID 验证、CrossRef/DataCite DOI 查询、Semantic Scholar 标题匹配、最后再用 LLM 做相关性评分。只要有一条过不了,这篇引用就直接被干掉,最终输出的 BibTeX 只保留经过验证的内容。
这个设计思路不新鲜,但把它集成进自动化 pipeline 里,而且做到 inline citations 和 .bib 文件自动对齐剪枝,执行起来还是有点工程量的。
实验执行:代码崩了怎么办
这大概是整个项目里最有意思的部分——它不只是生成代码,而是真的去跑代码。
AutoResearchClaw 在 sandbox 环境里执行生成的 Python 实验代码,支持自动检测 NVIDIA CUDA、Apple MPS 和 CPU 三种硬件,代码和参数规模会根据硬件条件自适应调整。
如果代码在凌晨三点崩了怎么办?它会自动读取 traceback,让 LLM 生成修复方案,重新跑,最多迭代 10 轮。如果结果不理想、假设站不住脚,就触发 PIVOT 决策,整个流程回退到假设生成阶段,换一个方向重来。这个"自愈 + 自我否定"的闭环,是跟传统代码生成工具最大的区别之一。
多智能体辩论:假设生成不是一个 agent 的事
知识合成阶段有一个比较有意思的设计——三个智能体对撞:
Hypothesis Agent 负责激进地提假设,追求新颖性;Sanity Agent 是保守派,专门挑逻辑漏洞;Killer Agent 的职责更极端,专门把各种假设往死里怼,看看能不能被一刀毙命。三个 agent 结构化辩论,过了辩论关的假设才进入实验设计阶段。
这种对抗式生成的思路,比单个 LLM 自问自答要鲁棒不少,至少在形式上给假设质量加了一道过滤网。
自学习与哨兵机制
每次跑完流水线,系统会从本次运行里提取"教训",包括决策依据、运行时 warning、指标异常等,写入一个带时间衰减(30天)的知识库。下次运行新课题时,这些历史经验会作为上下文被复用,相当于系统在积累"实验室肌肉记忆"。
另外还有一个 Sentinel 哨兵在后台实时监控,盯着 NaN/Inf 这类数值异常、论文内容和实验证据的一致性、以及引用相关性得分,一旦发现问题就触发预警或干预。
怎么上手
安装和运行非常直接:
git clone https://github.com/aiming-lab/AutoResearchClaw.git
cd AutoResearchClaw
python3 -m venv .venv && source .venv/bin/activate
pip install -e .
cp config.researchclaw.example.yaml config.arc.yaml
# 编辑 config.arc.yaml,填写 LLM API endpoint 和 key
export OPENAI_API_KEY="sk-..."
researchclaw run --config config.arc.yaml --topic "你的研究方向" --auto-approve
最简配置只需要设置项目名、研究主题、LLM 的 API 地址和 key,以及 sandbox Python 路径。支持 OpenAI 兼容 API,也支持通过 ACP 协议对接 Claude Code、Gemini CLI、Codex CLI 等本地 agent,这种模式不需要另外配 API key,直接走 agent 自己的认证就行。
论文模板支持 NeurIPS 2025、ICLR 2026、ICML 2026 三种格式,在 config 里切换 target_conference 参数即可。
几个客观的注意点
项目目前还很新,v0.2.0 在 2026 年 3 月 16 日才发布,1183 个测试用例已通过,但生产环境表现如何还有待更多实测反馈。从文档来看,实验质量高度依赖 LLM 本身的推理能力——如果底层模型不够强,生成的实验设计和分析结论可能会有明显偏差,论文内容也需要人工仔细核查,特别是在涉及领域专业知识的部分。
不过作为一个 MIT 协议的开源框架,它把整条 research pipeline 的工程化思路都摆出来了,参考价值还是很高的。团队也在招募测试者,不同领域都欢迎,有兴趣可以去 GitHub 上提 issue 或者翻翻 Testing Guide。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 10
10 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)