视频分类模型汇总
|
|
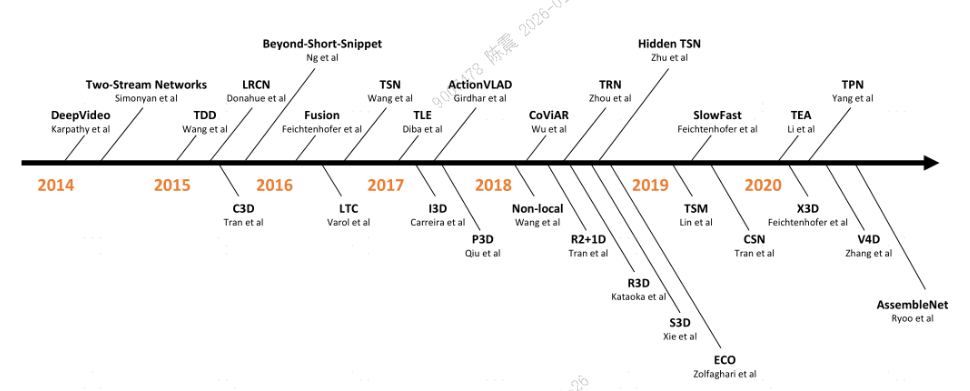
视频分类模型架构:
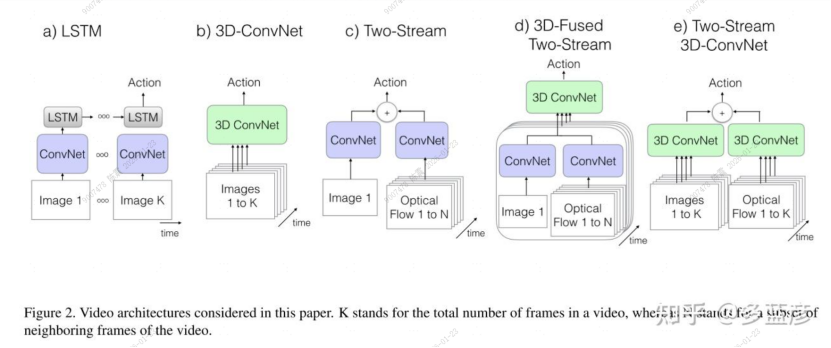
CNN+LSTM:即CNN抽取关键帧特征,LSTM进行时序建模
具体来说,就是先抽取视频中的关键帧得到K张图,然后将这K张图输入CNN网络得到图片特征。再将这些特征全部输入LSTM网络,进行各个时间戳上图片特征的融合,得到整个视频的融合特征。最后将LSTM最终时刻的特征接一个FC层得到分类结果。
3D Conv:将视频帧(分割好的一个个的视频段,每段含有K张图片)直接输入3D 的CNN网络进行时空学习。
此时卷积核必须是3维的(比如每个卷积核都是t×3×3,加入了时间维度),网络不光学习空间信息,还需要学习时序信息(运动信息)。最后3D Conv输出的特征也是接一个全连接层得到分类结果。因为多了一个维度,模型的参数量很大,不太好训练,而且效果也不好。
Two stream(late fusion):如果不想用LSTM进行时序建模,也不想用3D网络直接进行时空学习,那么还可以使用光流来得到时序信息(运动信息)。
双流网络整体还是2D网络结构,但额外引入一个时间流网络。通过巧妙的利用光流来提供的物体运动信息,而不用神经网络自己去隐式地学习运动特征,大大提高了模型的性能。
3D Fused Two stream(early fusion):双流网络的改进。作者认为双流网络中,两个网络的输出只是进行简单的加权平均来处理,效果还不够。所以将其替换为一个较小的3D网络,进一步融合特征。实验证明这种先进行2D卷积网络训练,再进行3D卷积网络融合的效果更好。
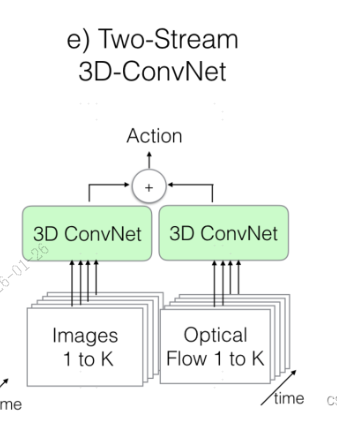
Two stream 3D ConvNet:I3D是3D网络和双流网络的结合。因为单纯的使用3D网络,模型效果还是不好,加上光流之后,可以大大提高模型性能。所以可以说I3D=Two stream+3D Conv。另外两个分支网络都已经是3D网络了,也就不需要另外加一个3D网络进行融合,直接加权平均得到最终的结果就行。
1 CNN架构
1.1Two-Stream:加入了光流信息
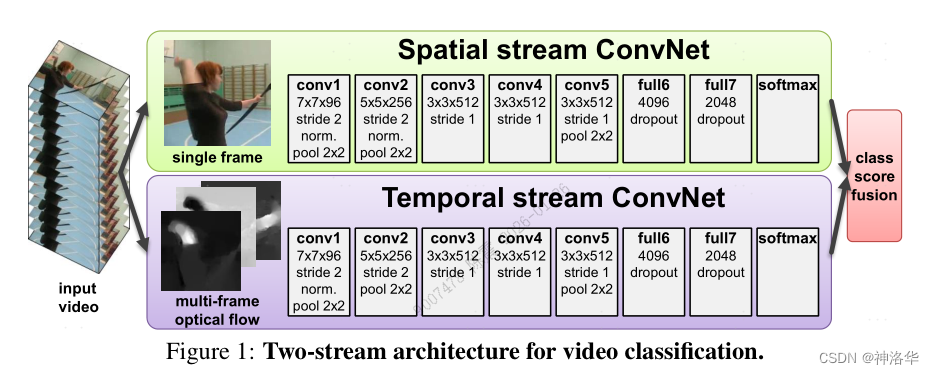
Spatio Stream:空间流卷积网络,输入是单个帧画面,主要学习场景信息。因为是处理静态图片,所以可以使用预训练的模型来做,更容易优化
temporal stream :时间流卷积网络(光流网络),输入是光流图像,通过多帧画面的光流位移来获取画面中物体的运动信息
Two stream +LSTM(CVPR 2015 )
从双流网络抽取特征之后直接做softmax分类,改为抽取特征后进行LSTM融合,再做softmax分类
Two-Stream+Early Fusion(CVPR 2016 )
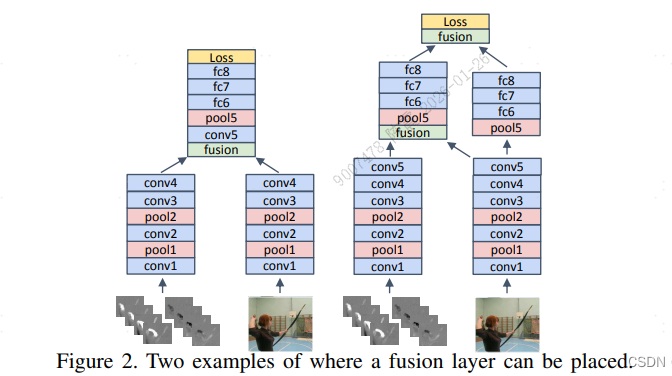
TSN(Temporal Segment Networks)
之前的双流网络,输入是单帧或几帧视频帧和10帧光流图像(大概只有半秒),只能处理很短的视频段,TSN相比之前可以处理更长的视频
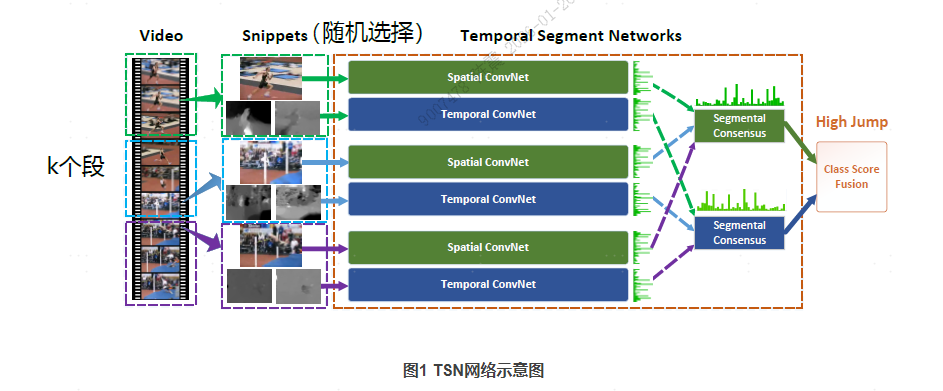
1.将长视频分成K段,在每一段里随机抽取一帧当做RGB图像输入,后续连续的10帧计算光流图像作为光流输入。
分别通过K个双流网络得到2K组logits(一组有时空两个logits,这些双流网络共享参数)。
2.将K个空间流网络输出特征做一次融合(Segmental Consensus,达成共识),时间流输出特征也如此操作。融合方式有很多种,取平均、
3.最后将两个融合特征做一次late fusion(加权平均)得到最终结果。
1.2 3D conv
C3D(14年)https://arxiv.org/pdf/1412.0767v4

- 统一使用使用3×3×3卷积(3D卷积)
- 5个卷积层和5个池化层,两个全连接层,一个softmax预测动作
- 池化层内核大小为2 × 2 × 2

优点:可以同时提取时空信息
缺点:参数量大难训练,所以一般3D网络的深度都较浅,但这样影响了模型的表达能力,而且不能有效的把2D网络的预训练权重迁移到3D网络。
I3D(Two-Stream Inflating 3D ConvNet17年google)(Two-Stream+3D ConvNet)
其它网络结构都不变,就是把2D的卷积核加一维变为3D(K*K —> K*K*K),2D池化改为3D池化,I3D使用的是Inception-V1进行3D扩张。 不用再重新设计3D网络
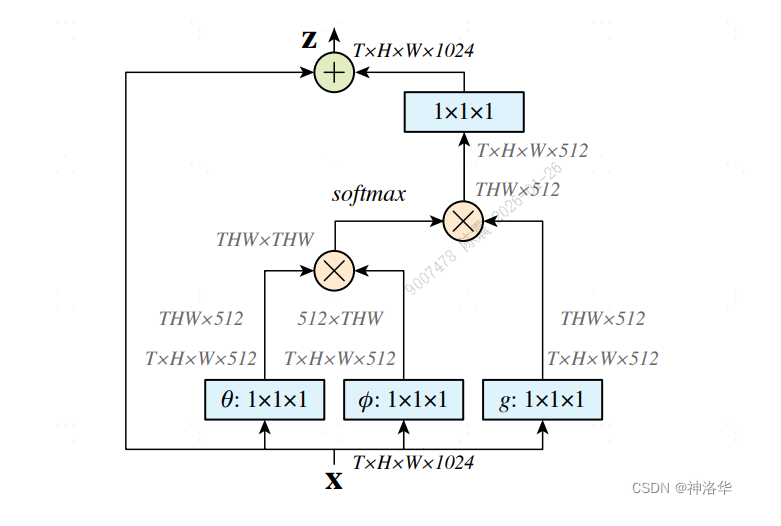
Non-local Neural Networks(CVPR 2018)
将non-local(self attention)融入I3D和其他模型中增加长距离建模能力,便于处理长视频。non-local block如下
1.3 因子分解 R(2+1)D(CVPR2018) 、S3D
为了缓解3D卷积的负担,提出了Factorization的思想
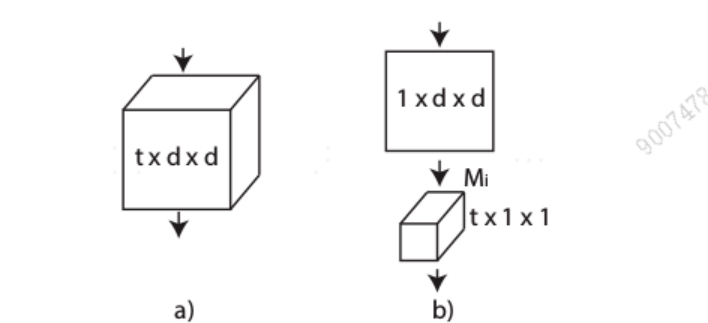
R(2+1)D
- 将3D卷积 N × t × d × d 拆分为 N × 1 × d × d 的 2D 空间卷积和 M ×t × 1 × 1 的 1D 时间卷积
S3D(ECCV2018):
- 只在高层或者底层使用只在高层或者底层使用3Dconv
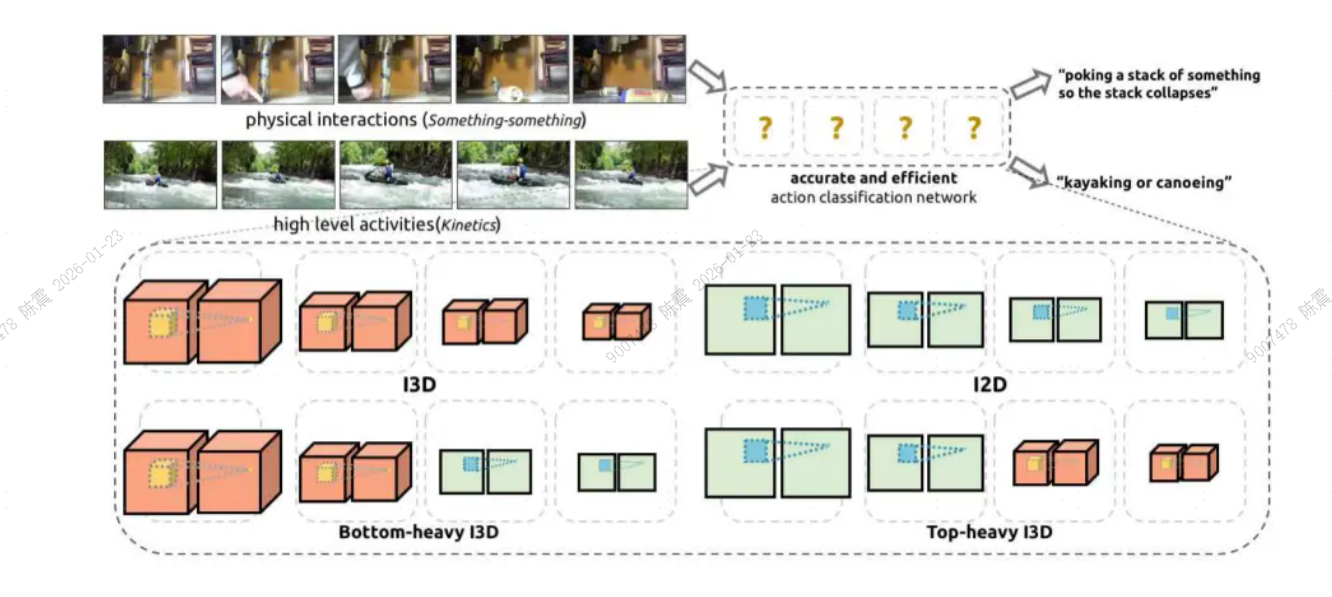
- 把3Dconv拆分成空间+时间卷积如图(c),(a)为inception模块,(b)为3D inception模块
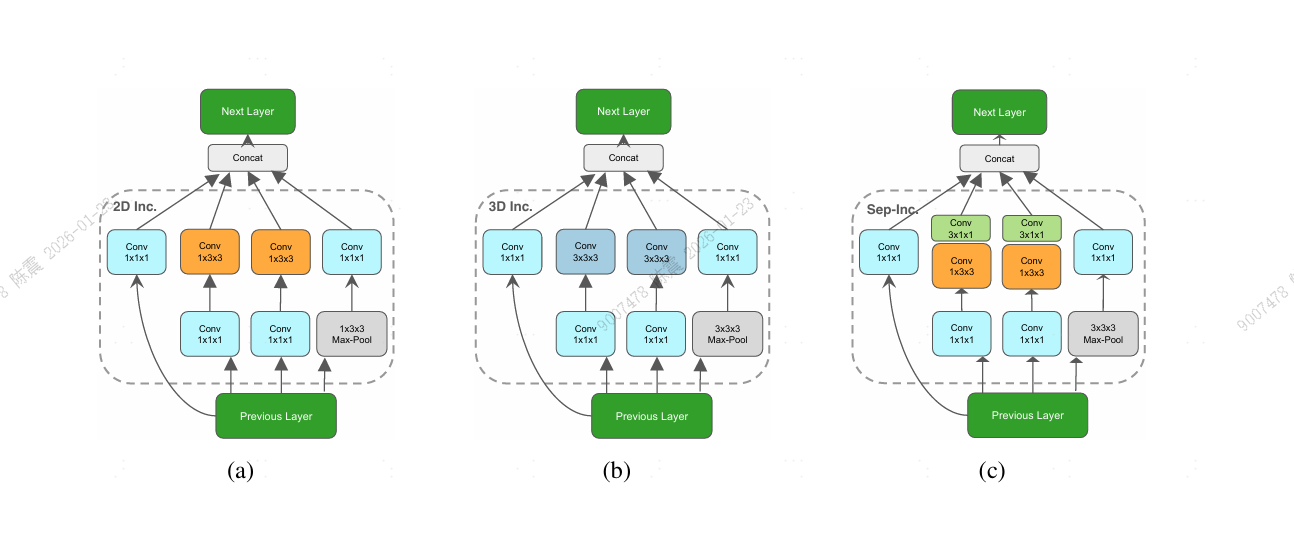
- 加入时空门机制设计了一个新的模型结构称为S3D-G
1.4 X3D和Slowfast
X3D:在帧率、持续时间、分辨率、网络深度、宽度和瓶颈宽度六个维度上对X2D进行联合扩展,这些扩展操作提升了X2D的性能(神经网络搜索)
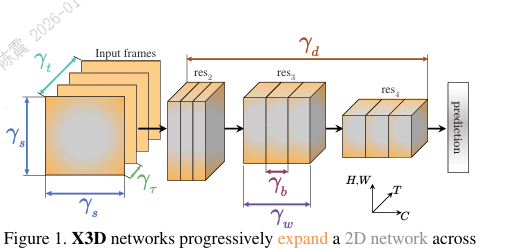
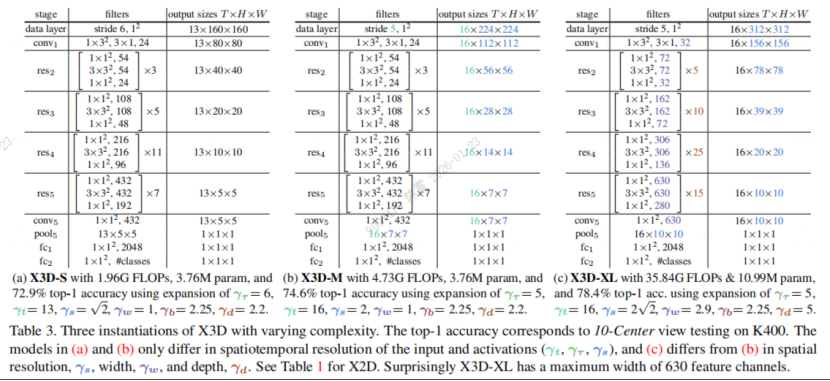
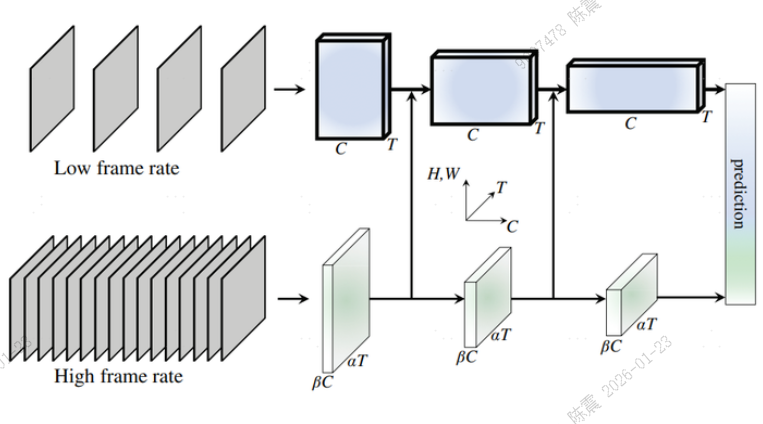
Slowfast:
Slow路径以低帧率处理空间细节,Fast路径以高帧率(但通道数极少)捕捉运动信息。这种非对称设计显著降低了计算量,但是SlowFast的双流架构需要同时维护两个不同分辨率和帧率的输入流,增加了数据预处理和内存管理的复杂性。
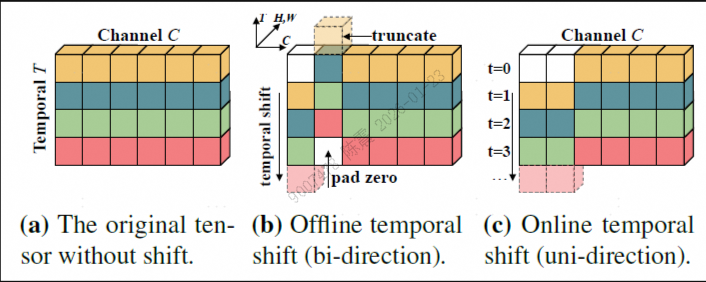
时序移位模块(TSM):2D CNN + 时间偏移 (MobileNetV3 /Resnet18+ TSM效率高)
https://github.com/mit-han-lab/temporal-shift-module
- 对于离线视频,移动通道的前1/4特征图,其中1/8移动到前一帧,另外1/8移动到后一帧;
- 对于在线视频,由于没办法获得未来帧,所以单向移动特征图,将前一帧前1/8特征图移动到当前帧;
- TSM模块比较灵活,可以轻松插入各种骨干网,带来效率的提升;
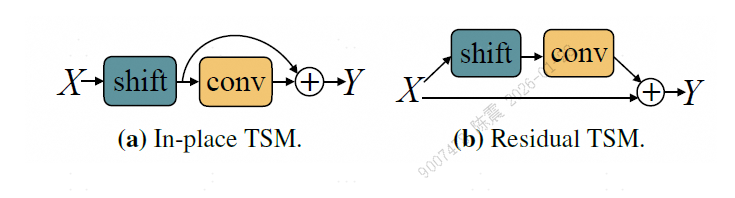
- 固定偏移范围:只能看到 ±1 帧,难以建模长时依赖;
1.5 MoViNets:流式缓冲网络
https://github.com/Atze00/MoViNet-pytorch
传统的视频分类模型通常需要攒够一个视频片段再一次性输入网络,导致Peak Memory Usage(显存占用峰值大),而且攒帧时会有显著延迟。MoViNets(Mobile Video Networks) 通过引入Stream Buffers(流式缓冲) 解决这一问题
- 使用Causal Conv(因果卷积)如下图,并配备了状态缓冲区。每处理一帧,网络不仅输出当前的特征,还更新缓冲区中的状态,供下一帧使用
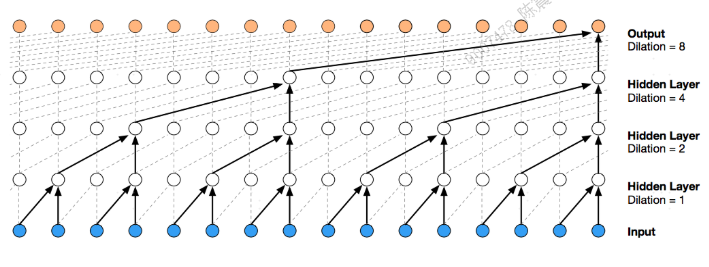
- 尽管是逐帧处理,但通过深层的缓冲传递,MoViNets依然能够拥有覆盖整个视频序列的有效时序感受野
- 与 X3D相同的精度,同时减少80%的FLOPs和65%的内存
FlashLightNet (2025):2D CNN+LSTM
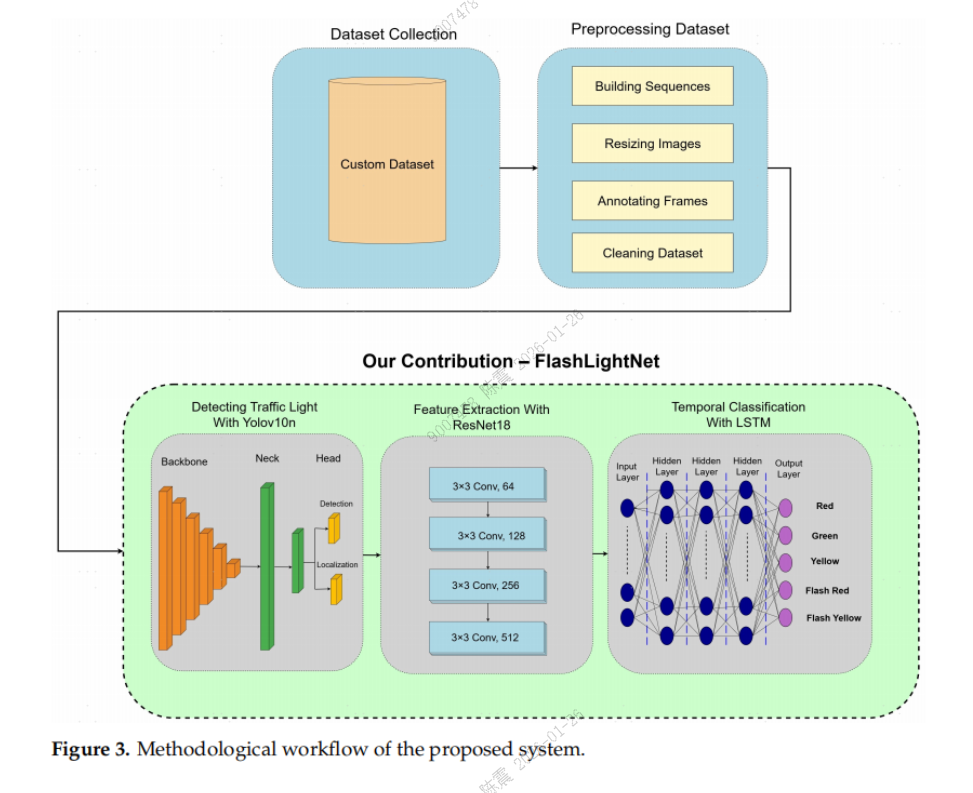
交通灯检测:使用 YOLOv10n 定位帧中的交通灯,输出精确边界框(ROI);
空间特征提取:通过 ResNet-18 对 ROI 区域进行特征提取,生成高维空间特征向量;
时序分类:将序列帧的特征向量输入 LSTM 网络,捕捉 “亮 - 灭” 时序模式,分类为红、绿、黄、闪红、闪黄五种状态。
2.Transformer架构
2.1 Timesformer:分割时空注意力(类似X3D)
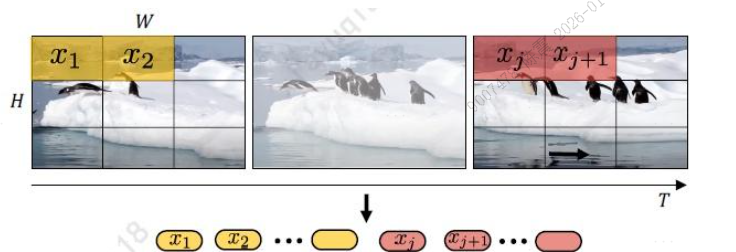
和VIT的嵌入方式一样,但采用T×H×W
Transformer的训练非常消耗资源,为了缓解这一问题,TimeSformer通过两个方式来减少计算量:
1)将视频拆解为不相交的图像块序列的子集;
2)使用一种独特的自注意力方式,来避免所有的图像块序列之间进行复杂计算。文中把这项技术叫做分开的时空注意力机制(divided space-time attention)。在时间attention中,每个图像块仅和其余帧在对应位置提取出的图像块进行attention。在空间attention中,这个图像块仅和同一帧的提取出的图像块进行attention。作者还发现,分开的时空注意力机制,效果要好于共同使用的时空注意力机制。
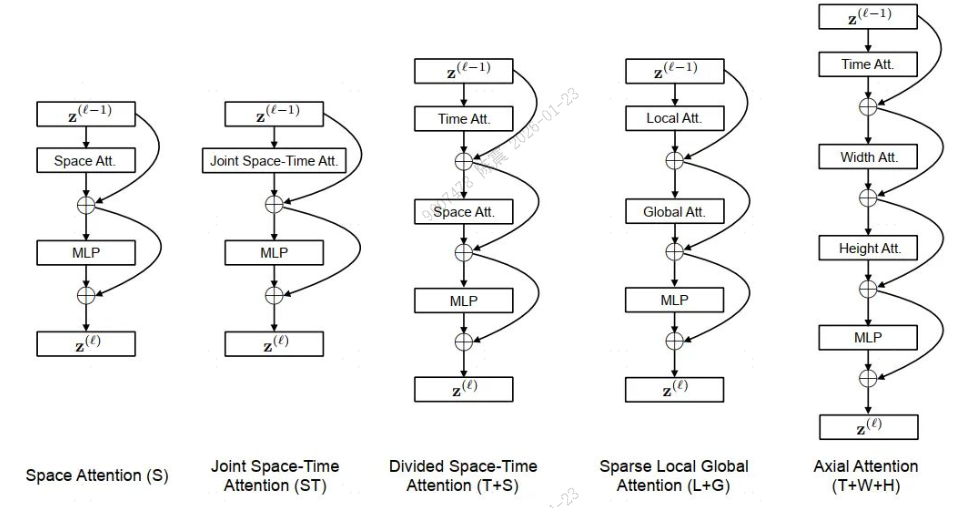
通过对输入图像进行分块,论文中一共研究了五种不同的注意力机制:
空间注意力机制(S):只取同一帧内的图像块进行自注意力机制
时空共同注意力机制(ST):取所有帧中的所有图像块进行注意力机制
分开的时空注意力机制(T+S):先对同一帧中的所有图像块进行自注意力机制,然后对不同帧中对应位置的图像块进行注意力机制
稀疏局部全局注意力机制(L+G):先利用所有帧中,相令的H/2和W/2的图像块计算局部的注意力,然后在空间上,使用2个图像块的步长,在整个序列中计算自注意力机制,这个可以看做全局的时空注意力更快的近似
轴向的注意力机制(T+W+H):先在时间维度上进行自注意力机制,然后在纵坐标相同的图像块上进行自注意力机制,最后在横坐标相同的图像块上进行自注意力机制

与slowfast架构相似算力下精度更高
2.2 VIVIT(Video Vision Transformers):强调embed方式
两种embed方式:
1.每张和vit一样,最后conact
因子编码器(Factorised Encoder)
- 第 1 阶段:在空间维度上做自注意力(帧内空间 self-attention),输出空间特征。
- 第 2 阶段:在时间维度上做自注意力(对相同空间位置的 tubelet 做 time-only attention)。
2.tuble embedding:采用 t * h * w的tubes最后conact
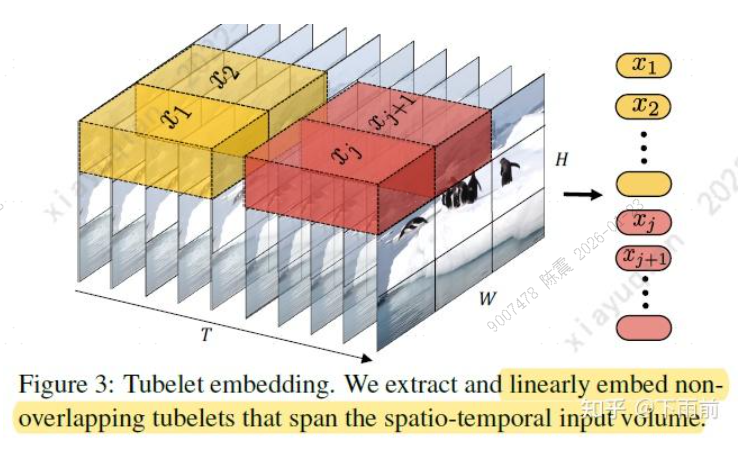
联合编码器(Joint Encoder)
- 把所有 tubelet token 视作一个长序列,做全局时空自注意力。
- 算法上与 TimeSformer 的 ST 注意力类似,计算量较大,但理论上表达能力更强。
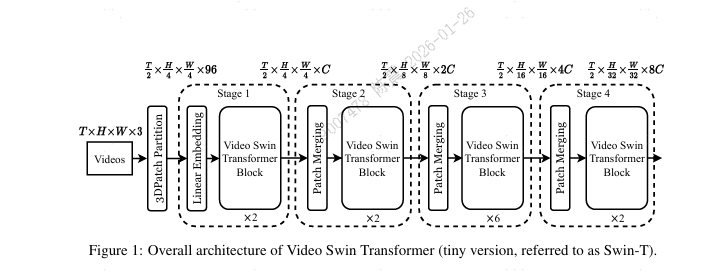
2.3 Video Swin Transformer:
将图像 Swin Transformer 的“移位窗口自注意力 + 层级结构”扩展到 3D(时间+空间),用局部偏置降低计算复杂度,同时保持全局感受野的能力
2.4 SVFormer:半监督学习(SSL)
2.5VideoMAE V2:自监督学习

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 6
6 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)