收藏必备!小白程序员轻松入门大模型核心技术:Embedding与向量数据库
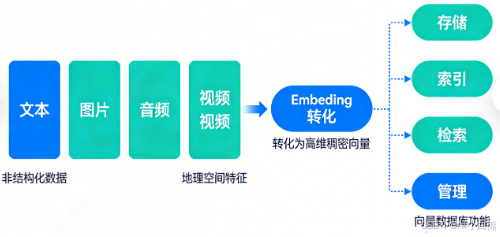
Embedding(向量嵌入)是将非结构化数据(文本、图片、音频、视频、地理空间特征等)转化为高维稠密向量的过程,向量则是数据在高维空间的 “数字指纹”;向量数据库是专门用于存储、索引、检索和管理高维向量的数据库,核心能力是高效完成相似性检索(而非传统数据库的精确匹配)。
二者是 “数据表示 + 数据管理” 的组合,解决了传统数据库无法高效处理非结构化数据相似性查询的核心痛点,同时让 AI 模型(如 LLM、CV 模型)能直接理解和运算非结构化数据,成为大模型、多模态 AI、智能检索等场景的技术基石。
一、核心解决的问题
传统关系型 / 非关系型数据库的设计核心是精确匹配(如 SQL 的=/like、MongoDB 的文档匹配),面对非结构化数据存在天然缺陷,而 Embedding + 向量数据库从根本上解决了以下问题:
- 非结构化数据的 “可计算化” 问题
文本、图片、语音等非结构化数据无法被计算机直接运算和比较(比如无法直接判断 “农业干旱监测” 和 “作物水分胁迫分析” 是否语义相关),Embedding 通过语义 / 特征映射,将其转化为数值化的高维向量,向量间的距离(欧氏、余弦)直接代表数据的相似程度,让非结构化数据具备了 “可计算、可比较” 的属性。
- 传统数据库的相似性检索效率问题
若用传统数据库存储向量,做相似性检索时需对全量数据逐一计算距离(暴力检索),当数据量达到百万 / 千万级时,耗时会飙升至秒级 / 分钟级,无法满足实时业务需求。向量数据库通过专用索引算法(如 HNSW、FAISS、IVF_FLAT)对高维向量做分层 / 聚类处理,将检索复杂度从 O (n) 降至 O (log n),实现亿级向量的毫秒级相似性检索,同时支持批量插入、更新、过滤等操作,兼顾性能和工程化。
- AI 模型的 “数据关联与上下文理解” 问题
大模型(如 LLM)本身具备推理能力,但缺乏对私有 / 领域数据的理解能力(如农业 GIS 的田间监测数据、行业知识库),Embedding 将私有数据转化为向量后存入向量数据库,可通过相似性检索快速匹配与用户查询相关的上下文(即 RAG 技术的核心),让大模型能结合私有数据生成精准答案,解决大模型 “幻觉” 和 “知识过时” 问题。
- 多模态数据的 “跨类型匹配” 问题
传统数据库无法直接实现跨模态的相似性查询(如用文字 “郑州农业墒情地图” 匹配相关的 GIS 栅格图、卫星影像),而 Embedding 可通过多模态嵌入模型(如 CLIP、BLIP)将不同类型的非结构化数据映射到同一高维向量空间,实现 “文找图、图找文、图找图” 的跨模态检索,打破数据类型的壁垒。
二、核心使用场景
Embedding + 向量数据库的组合已广泛应用于 AI、大数据、物联网、GIS 等领域,尤其在需要相似性检索、智能匹配、个性化推荐、领域知识赋能的场景中成为核心组件,以下是典型场景及行业落地案例:
- 大模型应用:RAG(检索增强生成)
这是当前最主流的场景,解决大模型 “无领域知识、易幻觉、知识固定” 的问题。
核心逻辑
将领域知识库(如农业大数据文档、GIS 技术手册、企业私有资料)通过 Embedding 转化为向量,存入向量数据库;用户提问后,先将问题转化为向量,在向量数据库中检索语义最相似的知识库片段,再将片段作为上下文传入大模型,大模型基于上下文生成答案。
落地案例
农业 GIS 智能问答机器人(检索农业墒情、作物种植的 GIS 数据文档)、企业内部智能助手、法律 / 医疗领域的专业问答模型。
- 智能检索:语义检索 / 跨模态检索
替代传统的 “关键词检索”,实现按语义 / 特征检索,大幅提升检索的精准度和体验,支持跨类型数据匹配。
文本语义检索
如搜索引擎(百度 / 谷歌的智能检索)、文献库检索(知网按语义找相关论文)、GIS 文档检索(按 “农田地形分析” 语义找相关的 GIS 操作文档),解决关键词检索 “漏检、错检” 的问题(比如关键词 “干旱” 无法检索到含 “水分胁迫” 的文档)。
跨模态检索
如电商平台的 “拍图找同款”、卫星影像检索(用文字 “黄河流域农业种植区” 匹配相关卫星图)、GIS 多源数据检索(用矢量数据特征匹配对应的栅格数据)、短视频平台的 “文找视频 / 图找视频”。
音视频检索
如语音助手的 “相似语音指令匹配”、监控视频的 “相似画面检索”(如检索某一农田的相似监测画面)。
- 个性化推荐:内容 / 商品 / 服务推荐

基于用户行为的特征相似性做精准推荐,替代传统的协同过滤(解决协同过滤 “冷启动、稀疏性” 问题)。
核心逻辑
将用户(用户画像、行为记录)、内容(商品、文章、视频、GIS 服务)分别 Embedding 为向量,通过向量数据库计算用户向量与内容向量的相似性,推荐相似性最高的内容。
落地案例
电商平台的商品推荐、资讯平台的文章推荐、农业 GIS 平台的服务推荐(为种植户推荐相似地块的 GIS 分析服务)、短视频平台的视频推荐。
- 计算机视觉:图像 / 视频分析与匹配

处理 CV 领域的非结构化视觉数据,实现相似特征匹配、目标检索、去重等功能。
落地案例
人脸识别(人脸特征向量的相似性匹配)、卫星影像 / 无人机影像的相似地块检索(农业 GIS 的核心场景)、图片去重(社交平台过滤重复图片)、工业质检(产品缺陷特征的相似性匹配,快速定位缺陷类型)。
- 地理空间(GIS):空间特征相似性分析
这是 GIS / 农业大数据领域的特色场景,解决空间非结构化数据的特征匹配与检索问题。
核心逻辑
将 GIS 空间数据(矢量地块、栅格影像、GPS 轨迹、农业监测点特征)通过地理空间 Embedding 模型转化为向量,存入支持空间属性的向量数据库(如 PGVector+PostGIS),通过相似性检索找到空间特征相似的地理对象。
落地案例
农业地块相似性分析(检索与目标地块土壤、气候、地形相似的种植地块,用于品种试种推荐)、GPS 轨迹匹配(检索相似的农机作业轨迹)、城市地理单元检索(检索相似的商圈 / 社区空间特征)。
- 异常检测:工业 / 物联网 / 安防的异常识别

基于正常数据的向量分布,检测偏离分布的异常数据,解决传统规则检测 “覆盖不全、易漏检” 的问题。
核心逻辑
将正常的设备运行数据、传感器数据、安防监控数据 Embedding 为向量,构建正常数据的向量空间;实时将新数据转化为向量,在向量数据库中计算其与正常向量的距离阈值,超过阈值则判定为异常。
落地案例
工业设备故障检测(电机运行数据的异常向量检测)、农业物联网监测(土壤传感器 / 气象传感器的异常数据识别)、安防监控的异常行为检测、网络安全的恶意流量检测。
- 聚类与分类:非结构化数据的无监督 / 半监督分析

利用向量数据库的聚类索引能力,对高维向量做无监督聚类,实现非结构化数据的自动分类和标签化。
落地案例
文本自动分类(将新闻、文档按语义聚类为不同主题)、农业影像分类(将卫星影像向量聚类,实现地块种植类型的自动划分)、用户分群(将用户向量聚类,实现精准的用户分层运营)。
- 其他小众场景
代码检索
按自然语言描述的需求,检索语义 / 功能相似的代码片段(如 GitHub Copilot 的底层能力);
药物研发
将药物分子结构转化为向量,检索相似的分子结构,快速筛选候选药物;
推荐系统冷启动
当新用户 / 新商品无行为数据时,通过 Embedding 生成的特征向量做相似性推荐,解决冷启动问题。
三、关键补充:主流工具与技术栈
- 主流 Embedding 工具 / 模型
文本 Embedding
OpenAI Embeddings、BERT/ERNIE(开源)、Sentence-BERT(轻量开源,适合语义匹配)、智谱 AI / 百度文心的开源嵌入模型;
多模态 Embedding
CLIP(OpenAI,文图跨模态)、BLIP(商汤 / 微软);
地理空间 Embedding
GeoBERT、基于 GIS 特征的自定义嵌入模型(如结合经纬度、地形、土壤特征的向量生成);
工具库
Hugging Face Transformers(加载开源模型)、LangChain(封装 Embedding 调用,适配大模型 RAG)。
- 主流向量数据库
| 类型 | 代表产品 | 特点 | 适用场景 |
|---|---|---|---|
| 开源轻量 | PGVector(PostgreSQL 插件)、SQLite-Vector | 基于传统数据库,易部署、支持 SQL + 向量检索 | 中小数据量、轻量化业务 |
| 开源高性能 | Milvus、FAISS(Facebook)、Weaviate | 专为向量设计,支持亿级数据、多索引算法 | 大数据量、高并发业务 |
| 云原生商用 | Pinecone、Chroma、阿里云向量数据库、腾讯云向量数据库 | 托管式、免运维、支持弹性扩容 | 企业级业务、快速上线 |
| GIS 融合型 | PGVector+PostGIS、Milvus+GIS 插件 | 支持空间属性过滤 + 向量相似性检索 | 农业 GIS、地理空间分析业务 |
四、总结
Embedding 的核心价值是实现非结构化数据的数值化和语义 / 特征映射,让计算机能理解非结构化数据的 “内涵”;向量数据库的核心价值是解决高维向量的高效相似性检索和工程化管理,让 Embedding 的能力能落地到百万 / 亿级数据的实际业务中。
二者的组合是连接非结构化数据与 AI 模型的桥梁,不仅解决了传统数据库的技术痛点,更成为大模型 RAG、智能检索、个性化推荐、GIS 空间分析等现代 AI 业务的基础设施,也是未来多模态 AI、通用人工智能(AGI)的核心技术组件之一。
普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。
随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:
人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
最后
只要你真心想学习AI大模型技术,这份精心整理的学习资料我愿意无偿分享给你,但是想学技术去乱搞的人别来找我!
在当前这个人工智能高速发展的时代,AI大模型正在深刻改变各行各业。我国对高水平AI人才的需求也日益增长,真正懂技术、能落地的人才依旧紧缺。我也希望通过这份资料,能够帮助更多有志于AI领域的朋友入门并深入学习。
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发
【附赠一节免费的直播讲座,技术大佬带你学习大模型的相关知识、学习思路、就业前景以及怎么结合当前的工作发展方向等,欢迎大家~】
大模型全套学习资料展示
自我们与MoPaaS魔泊云合作以来,我们不断打磨课程体系与技术内容,在细节上精益求精,同时在技术层面也新增了许多前沿且实用的内容,力求为大家带来更系统、更实战、更落地的大模型学习体验。

希望这份系统、实用的大模型学习路径,能够帮助你从零入门,进阶到实战,真正掌握AI时代的核心技能!
01 教学内容

-
从零到精通完整闭环:【基础理论 →RAG开发 → Agent设计 → 模型微调与私有化部署调→热门技术】5大模块,内容比传统教材更贴近企业实战!
-
大量真实项目案例: 带你亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!
02适学人群
应届毕业生: 无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型: 非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能突破瓶颈: 传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。

vx扫描下方二维码即可
【附赠一节免费的直播讲座,技术大佬带你学习大模型的相关知识、学习思路、就业前景以及怎么结合当前的工作发展方向等,欢迎大家~】
本教程比较珍贵,仅限大家自行学习,不要传播!更严禁商用!
03 入门到进阶学习路线图
大模型学习路线图,整体分为5个大的阶段:
04 视频和书籍PDF合集

从0到掌握主流大模型技术视频教程(涵盖模型训练、微调、RAG、LangChain、Agent开发等实战方向)

新手必备的大模型学习PDF书单来了!全是硬核知识,帮你少走弯路(不吹牛,真有用)
05 行业报告+白皮书合集
收集70+报告与白皮书,了解行业最新动态!
06 90+份面试题/经验
AI大模型岗位面试经验总结(谁学技术不是为了赚$呢,找个好的岗位很重要)

07 deepseek部署包+技巧大全

由于篇幅有限
只展示部分资料
并且还在持续更新中…
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发
【附赠一节免费的直播讲座,技术大佬带你学习大模型的相关知识、学习思路、就业前景以及怎么结合当前的工作发展方向等,欢迎大家~】

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 9
9 0
0- 0



 已为社区贡献77条内容
已为社区贡献77条内容

所有评论(0)