掌握AI Agent能力赋予的四种范式:从Prompt到AgentSkill的进阶指南(收藏版)
AI Agent 能力赋予的四种范式:从 Prompt 到 AgentSkill 的演进之路
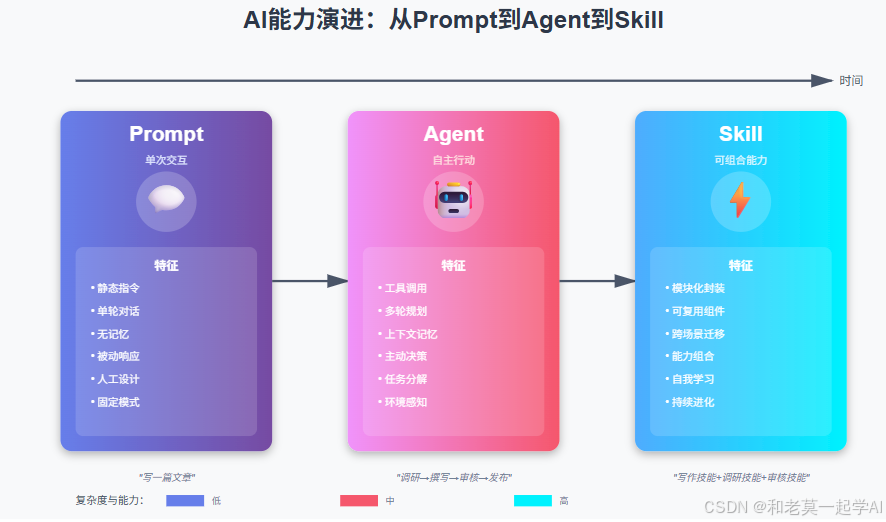
在 AI Agent 系统设计中,如何赋予 Agent 能力是一个核心问题。本文将深入探讨四种主要的能力赋予方式:Prompt Engineering、Tool Call、Agent Skills 和 Workflow,帮助你理解它们的本质区别和适用场景。
一、为什么需要关注 Agent 能力赋予方式?
当我们构建 AI Agent 时,常常会遇到这样的困惑:
-
如何在不让上下文爆炸的情况下赋予 Agent 更多能力?
-
为什么有些场景用 Prompt 就够了,有些却需要复杂的工作流?
-
Agent Skills 和普通函数调用有什么本质区别?
这些问题的答案,藏在对四种能力赋予范式的深入理解中。让我们从最简单的 Prompt Engineering 开始。
二、Prompt Engineering:自然语言的魔法
Prompt Engineering 是最直观的方式——通过精心设计的自然语言指令,引导大语言模型完成特定任务。
基本原理
想象你在指导一个新员工,你会详细描述任务、给出示例、说明注意事项。Prompt Engineering 就是这样,通过系统提示词定义角色、能力和约束条件。
# 一个典型的代码审查 Prompt
system\_prompt = """
你是一位资深的 Python 代码审查专家。
请分析提供的代码,关注:
1. 代码风格是否符合 PEP8
2. 是否存在潜在 bug
3. 性能优化建议
"""
user\_input = """
def calculate(x, y):
return x/y
"""
response = llm.chat(system=system\_prompt, user=user\_input)
# 输出: "该函数存在除零风险,建议添加 y != 0 的检查..."
优势与挑战
Prompt Engineering 的最大优势是快速、零代码。你不需要编写任何函数,只需要用自然语言描述需求即可。这使得它特别适合原型验证和创造性任务。
但问题也很明显:输出不稳定,难以保证结构化格式。更关键的是,当你需要赋予 Agent 大量能力时,上下文会急剧膨胀。
假设你要赋予 Agent 100 个技能,如果每个技能用 500 tokens 描述,总共就需要 50,000 tokens。以 Claude 3.5 Sonnet 为例,每次请求成本约 0.15 美元,100 次请求就是 15 美元。而且这些描述在每次请求时都要重复发送。
最致命的是:Prompt 无法执行真实的系统操作。它不能读写文件、调用 API、查询数据库。这就引出了我们的第二种范式。
三、Tool Call:从想象到真实执行
Tool Call(也叫 Function Calling)是 LLM 的一个重大突破。它允许模型不仅"想象"自己有某种能力,而是真正调用预定义的函数来完成任务。
工作机制
Tool Call 的核心是结构化的函数定义。你不是用自然语言描述"你可以查天气",而是提供一个标准的 Schema:
import anthropic
# 定义工具(注意:这是结构化的 Schema,不是自然语言描述)
tools = [
{
"name": "get\_weather",
"description": "获取指定城市的天气信息",
"input\_schema": {
"type": "object",
"properties": {
"city": {"type": "string", "description": "城市名称"},
"unit": {"type": "string", "enum": ["celsius", "fahrenheit"]}
},
"required": ["city"]
}
}
]
client = anthropic.Anthropic()
response = client.messages.create(
model="claude-3-5-sonnet-20241022",
tools=tools,
messages=[{"role": "user", "content": "北京今天天气怎么样?"}]
)
# LLM 会返回一个结构化的函数调用请求
for block in response.content:
if block.type == "tool\_use":
# 执行真实函数
result = get\_weather(block.input["city"])
# 将结果返回给 LLM 继续处理
关键优势
Tool Call 相比 Prompt 有三个关键优势:
**第一,真实执行能力**。LLM 不再是"假装"查天气,而是真正调用天气 API 获取实时数据。
**第二,结构化输出**。函数调用的格式是标准的 JSON,参数类型通过 Schema 验证,避免了 Prompt 输出格式不稳定的问题。
**第三,Token 效率**。工具定义远小于自然语言描述。同样赋予 100 个能力,Tool Call 可能只需要 5,000 tokens,相比 Prompt 的 50,000 tokens,成本降低 90%。
多轮调用的威力
Tool Call 真正的威力在于多轮调用。以"分析 main.py 性能并生成报告"为例:
# Round 1: LLM 决定先读取文件
# LLM 生成: read\_file(path="main.py")
code = execute\_tool("read\_file", {"path": "main.py"})
# Round 2: LLM 决定进行性能分析
# LLM 生成: profile\_code(code="...", language="python")
analysis = execute\_tool("profile\_code", {"code": code, "language": "python"})
# Round 3: LLM 决定生成报告
# LLM 生成: generate\_report(template="performance\_analysis", data={...})
report = execute\_tool("generate\_report", {"template": "performance\_analysis", "data": analysis})
LLM 像一个思考者,根据上一步的结果决定下一步的行动。这种链式调用使得复杂任务得以实现。
局限性
但 Tool Call 也有局限。首先,不是所有 LLM 都支持,这依赖模型的原生能力。其次,工具数量通常有限制(一般小于 128 个)。最关键的是,Tool Call 本身是无状态的——每次调用都是独立的,无法跨调用保持上下文。
这就引出了第三种范式:Agent Skills。
四、Agent Skills:能力的高级封装
如果说 Tool Call 是"函数",那 Agent Skills 就是"对象"。它不仅包含函数,还包含状态、上下文和领域知识。
核心特征
一个 Agent Skill 通常包含五个部分:
**1. 元数据**:技能的名称、版本、描述、依赖的工具列表。
**2. 专用 Prompt 模板**:不同于全局 Prompt,这是针对该技能定制的提示词。
**3. 工具组合**:一个技能可能需要调用多个底层工具。
**4. 执行逻辑**:如何组织这些工具和 Prompt 来完成任务。
**5. 上下文访问**:可以访问 Agent 的记忆、状态和历史。
实战案例:代码审查技能
让我们看一个完整的例子:
from typing import Dict, Any
from dataclasses import dataclass
@dataclass
classSkillMetadata:
name: str
description: str
version: str
required\_tools: list[str]
classCodeReviewSkill:
def\_\_init\_\_(self):
self.metadata = SkillMetadata(
name="code\_review",
description="深度代码审查,包含安全、性能、可维护性分析",
version="1.0.0",
required\_tools=["read\_file", "parse\_ast", "run\_static\_analysis"]
)
# 专用 Prompt 模板
self.prompt\_template = """
你是资深代码审查专家,请对以下代码进行全面分析:
代码语言: {language}
项目类型: {project\_type}
代码内容: {code}
静态分析结果: {static\_analysis}
请提供:
1. 严重问题(安全漏洞、明显 bug)
2. 性能优化建议
3. 代码风格改进
4. 可维护性评分(1-10)
"""
defexecute(self, input\_data: Dict[str, Any], context: Dict[str, Any]) -> Dict[str, Any]:
file\_path = input\_data["file\_path"]
# 步骤 1: 使用工具读取文件
code = self.tools["read\_file"](file\_path)
# 步骤 2: 解析 AST
ast\_info = self.tools["parse\_ast"](code)
# 步骤 3: 运行静态分析
static\_analysis = self.tools["run\_static\_analysis"](file\_path)
# 步骤 4: 从 Agent 上下文获取项目信息
project\_type = context.get("project\_type", "unknown")
language = context.get("language", "python")
# 步骤 5: 组装 Prompt 并调用 LLM
prompt = self.prompt\_template.format(
language=language,
project\_type=project\_type,
code=code,
static\_analysis=static\_analysis
)
llm\_result = self.llm.generate(prompt)
# 步骤 6: 结构化返回
return {
"file": file\_path,
"review": llm\_result,
"metrics": ast\_info["complexity"],
"issues\_count": len(static\_analysis["errors"])
}
与 Tool Call 的本质区别
乍一看,这和简单地调用几个工具有什么区别?区别在于:
**封装性**:CodeReviewSkill 封装了"如何进行代码审查"的完整知识。它不仅调用工具,还知道以什么顺序、如何组合结果、用什么样的 Prompt。
**状态感知**:它可以访问 Agent 上下文,获取项目类型、编程语言等信息,从而动态调整审查策略。
**可组合性**:技能可以调用其他技能。比如 CodeRefactorSkill 可以先调用 CodeReviewSkill 分析问题,再生成重构方案。
**领域知识**:Prompt 模板、工具选择、逻辑编排都蕴含了"如何审查代码"的专业知识。
动态技能加载:解决上下文爆炸
Agent Skills 面临的挑战是:当技能很多时,如何避免上下文爆炸?
答案是动态加载。不要一次性加载所有技能,而是根据用户查询选择相关的技能:
classDynamicSkillLoader:
def\_\_init\_\_(self):
self.all\_skills = self.\_load\_skill\_registry()
# 为每个技能创建向量索引
self.skill\_embeddings = {
skill\_name: embed\_text(skill.metadata.description)
for skill\_name, skill inself.all\_skills.items()
}
defselect\_relevant\_skills(self, user\_query: str, max\_skills: int = 5):
"""基于用户查询选择相关技能"""
query\_embedding = embed\_text(user\_query)
# 计算相似度
similarities = {
skill\_name: cosine\_similarity(query\_embedding, skill\_emb)
for skill\_name, skill\_emb inself.skill\_embeddings.items()
}
# 返回 top-k 技能
top\_skills = sorted(similarities.items(), key=lambdax: x[1], reverse=True)[:max\_skills]
return [self.all\_skills[name] for name, \_ in top\_skills]
# 使用
loader = DynamicSkillLoader()
user\_query = "帮我分析这段 Python 代码的性能问题"
relevant\_skills = loader.select\_relevant\_skills(user\_query, max\_skills=3)
# 只加载 [CodeReviewSkill, PerformanceProfilerSkill, OptimizationSuggestionSkill]
这样,即使有 100 个技能,每次也只加载最相关的 3-5 个,Token 消耗从 50,000 降到约 2,000,成本节省 96%。
五、Workflow:可靠性的保障
前面三种方式解决了"能做什么"的问题,但在生产环境中,我们还需要考虑"如何可靠地做"。这就是 Workflow 的价值所在。
什么是 Workflow?
Workflow(工作流)是预定义的、结构化的任务执行序列。它通过有向图或状态机描述复杂业务流程,提供自动重试、错误恢复、状态持久化等能力。
实战案例:自动化数据分析
假设我们要构建一个每天自动运行的数据分析系统:抓取数据、清洗、用 LLM 分析趋势、生成报告、发送邮件。
from prefect import flow, task
import pandas as pd
@task(retries=3, retry\_delay\_seconds=300)
deffetch\_daily\_data(data\_source: str) -> pd.DataFrame:
"""抓取数据 - 自动重试 3 次"""
return pd.read\_sql(f"SELECT \* FROM {data\_source} WHERE date = CURRENT\_DATE")
@task
defclean\_data(df: pd.DataFrame) -> pd.DataFrame:
"""清洗数据"""
return df.dropna().drop\_duplicates()
@task
defllm\_analyze\_trends(df: pd.DataFrame) -> dict:
"""使用 LLM 分析趋势"""
summary\_stats = df.describe().to\_string()
analysis = llm.generate(f"""
基于以下统计数据分析业务趋势:
{summary\_stats}
请指出:
1. 关键指标变化
2. 异常模式
3. 业务建议
""")
return {"analysis": analysis, "stats": summary\_stats}
@task
defsend\_email(report: str, recipients: list):
"""发送邮件"""
email.send(to=recipients, subject="每日数据报告", body=report)
@flow(name="Daily Data Analysis")
defdaily\_analysis\_workflow(data\_source: str, recipients: list):
"""每日分析工作流"""
raw\_data = fetch\_daily\_data(data\_source)
clean\_df = clean\_data(raw\_data)
analysis = llm\_analyze\_trends(clean\_df)
report = generate\_report(analysis)
send\_email(report, recipients)
# 定时调度:每天上午 9 点运行
daily\_analysis\_workflow.serve(
name="daily-analysis",
cron="0 9 \* \* \*",
parameters={
"data\_source": "sales\_data",
"recipients": ["team@company.com"]
}
)
Workflow 的核心价值
这个例子展示了 Workflow 的三大价值:
**可靠性**:fetch\_daily\_data 标注了 retries=3,如果数据源不稳定,会自动重试,而不是直接失败。
**可观测性**:Workflow 引擎会记录每个步骤的执行状态、耗时、错误信息。你可以清楚地看到哪个环节失败了、为什么失败。
**持久化**:如果服务器在执行到一半时崩溃,Workflow 可以从中断点恢复,而不是从头开始。
何时需要 Workflow?
Workflow 适用于这些场景:
-
多步骤复杂流程(如 CI/CD、数据处理管道)
-
需要定时调度的任务
-
长时运行的任务(可能跨越数小时甚至数天)
-
需要完整执行历史追踪的场景
-
对可靠性要求高的生产环境
但要注意避免过度工程。如果只是一个简单的加法运算,引入 Workflow 就是杀鸡用牛刀。
六、如何选择?实战选型指南
现在我们理解了四种范式,但在实际项目中如何选择?这里提供一个决策框架。
任务特征分析
**问题 1:任务是否需要外部系统交互?**
-
否 → 考虑 Prompt Engineering
-
是 → 继续下一步
**问题 2:是否需要组合多个工具或包含领域知识?**
-
否 → 使用 Tool Call
-
是 → 考虑 Agent Skills
**问题 3:是否需要多步骤编排、错误恢复或定时调度?**
-
否 → 使用 Agent Skills
-
是 → 使用 Workflow
实战案例
**案例 1:智能客服**
需求:查询订单、处理退款、升级到人工。
选型:Tool Call + 简单路由
理由:每个操作相对独立,不需要复杂编排。Tool Call 足以处理,引入 Workflow 会增加延迟。
**案例 2:代码审查助手**
需求:理解代码、识别问题、生成测试、自动修复。
选型:Agent Skills + Workflow
理由:代码审查需要组合多个工具和领域知识(Agent Skills),而自动修复流程需要可靠性保证(修复失败需要回滚,Workflow)。
**案例 3:RAG 文档问答**
需求:用户上传文档,系统索引后支持智能问答。
选型:Agent Skills + Tool Call
理由:文档索引和检索涉及复杂的 RAG 逻辑(分块、向量化、重排序),适合用 Skills 封装。同时通过 Tool Call 让 Agent 自主决定何时索引、何时查询。不需要 Workflow,因为对话是实时的。
成本对比
以赋予 Agent 100 个能力为例:
-**Prompt 方式**:50,000 tokens/请求,100 次请求 = 15 美元
-**Tool Call 方式**:5,000 tokens/请求,100 次请求 = 1.5 美元(节省 90%)
-**Agent Skills(按需加载)**:2,000 tokens/请求,100 次请求 = 0.6 美元(节省 96%)
七、最佳实践与常见陷阱
最佳实践 1:分层设计
清晰的抽象层次能让系统更易维护:
# L1: 工具层(原子操作)
defread\_file(path: str) -> str: ...
defwrite\_file(path: str, content: str): ...
# L2: 技能层(业务逻辑)
classCodeReviewSkill:
defexecute(self, file\_path):
code = read\_file(file\_path) # 使用 L1
# 复杂逻辑...
return review
# L3: 工作流层(编排)
@workflow.defn
classCIWorkflow:
asyncdefrun(self):
await execute\_skill(CodeReviewSkill()) # 使用 L2
# 编排逻辑...
最佳实践 2:按需加载
不要一次性加载所有技能,根据请求动态选择:
classSmartAgent:
defhandle\_request(self, user\_request):
# 只加载相关的技能
relevant\_skills = self.\_select\_skills(user\_request)
returnself.\_execute\_with\_skills(relevant\_skills)
常见陷阱 1:Prompt 堆砌
避免在 Prompt 中硬编码所有能力描述:
# 错误做法
system\_prompt = """
你有以下 100 个技能:
1. 技能A: 详细描述...(500 tokens)
2. 技能B: 详细描述...(500 tokens)
...
""" # 总计 50,000 tokens 被浪费!
常见陷阱 2:过度使用 Workflow
简单任务不要引入 Workflow:
# 错误做法:为简单加法创建工作流
@workflow.defn
classSimpleAdditionWorkflow:
asyncdefrun(self, a: int, b: int):
returnawait workflow.execute\_activity(add, a, b)
# 正确做法:直接计算
defsimple\_addition(a: int, b: int) -> int:
return a + b
常见陷阱 3:Tool Call 参数依赖
不要在一次调用中执行依赖的工具:
# 错误做法:并行调用依赖的工具
[
{"name": "read\_file", "input": {"path": "main.py"}},
{"name": "analyze\_file", "input": {"content": "???"}} # content 依赖 read\_file!
]
# 正确做法:顺序调用
result1 = call\_tool("read\_file", {"path": "main.py"})
result2 = call\_tool("analyze\_file", {"content": result1})
八、架构演进建议
实际项目中,技术选型不是一蹴而就的,而是随需求演进的:
**阶段 1:MVP(最小可行产品)**
纯 Prompt Engineering,快速验证想法,无需基础设施。
**阶段 2:引入结构化输出**
当输出不稳定时,引入 Tool Call,关键操作使用工具,保证输出格式。
**阶段 3:能力模块化**
当能力过多时,使用 Agent Skills + Tool Call,封装复杂逻辑,按需加载技能。
**阶段 4:生产级系统**
当需要可靠性时,引入 Workflow Engine,提供完整的可观测性、自动错误恢复、分布式执行。
九、总结
我们探讨了 AI Agent 能力赋予的四种范式:
**Prompt Engineering**:自然语言指令,快速灵活,但输出不稳定,无法真实执行,成本高。
**Tool Call**:结构化函数调用,真实执行能力,Token 高效,但无状态,数量受限。
**Agent Skills**:高级能力封装,组合工具和 Prompt,状态感知,可组合,但实现复杂。
**Workflow**:流程编排,可靠性高,可观测,支持持久化,但学习成本高,不够灵活。
它们不是互斥的,而是互补的。实际系统中,通常会组合使用:
-
基础对话使用 Prompt
-
操作使用 Tool Call
-
复杂能力封装为 Skills
-
关键流程使用 Workflow
选择的核心原则是:**用最简单的方案解决问题,随需求演进逐步升级**。从 Prompt 开始快速验证,当遇到瓶颈时再引入更高级的范式。
希望这篇文章能帮助你在构建 AI Agent 时做出明智的技术选择。记住,没有最好的技术,只有最合适的技术。
普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。
随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:
人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
最后
只要你真心想学习AI大模型技术,这份精心整理的学习资料我愿意无偿分享给你,但是想学技术去乱搞的人别来找我!
在当前这个人工智能高速发展的时代,AI大模型正在深刻改变各行各业。我国对高水平AI人才的需求也日益增长,真正懂技术、能落地的人才依旧紧缺。我也希望通过这份资料,能够帮助更多有志于AI领域的朋友入门并深入学习。
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发
【附赠一节免费的直播讲座,技术大佬带你学习大模型的相关知识、学习思路、就业前景以及怎么结合当前的工作发展方向等,欢迎大家~】
大模型全套学习资料展示
自我们与MoPaaS魔泊云合作以来,我们不断打磨课程体系与技术内容,在细节上精益求精,同时在技术层面也新增了许多前沿且实用的内容,力求为大家带来更系统、更实战、更落地的大模型学习体验。

希望这份系统、实用的大模型学习路径,能够帮助你从零入门,进阶到实战,真正掌握AI时代的核心技能!
01 教学内容

-
从零到精通完整闭环:【基础理论 →RAG开发 → Agent设计 → 模型微调与私有化部署调→热门技术】5大模块,内容比传统教材更贴近企业实战!
-
大量真实项目案例: 带你亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!
02适学人群
应届毕业生: 无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型: 非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能突破瓶颈: 传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。

vx扫描下方二维码即可
【附赠一节免费的直播讲座,技术大佬带你学习大模型的相关知识、学习思路、就业前景以及怎么结合当前的工作发展方向等,欢迎大家~】
本教程比较珍贵,仅限大家自行学习,不要传播!更严禁商用!
03 入门到进阶学习路线图
大模型学习路线图,整体分为5个大的阶段:
04 视频和书籍PDF合集

从0到掌握主流大模型技术视频教程(涵盖模型训练、微调、RAG、LangChain、Agent开发等实战方向)

新手必备的大模型学习PDF书单来了!全是硬核知识,帮你少走弯路(不吹牛,真有用)
05 行业报告+白皮书合集
收集70+报告与白皮书,了解行业最新动态!
06 90+份面试题/经验
AI大模型岗位面试经验总结(谁学技术不是为了赚$呢,找个好的岗位很重要)

07 deepseek部署包+技巧大全

由于篇幅有限
只展示部分资料
并且还在持续更新中…
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发
【附赠一节免费的直播讲座,技术大佬带你学习大模型的相关知识、学习思路、就业前景以及怎么结合当前的工作发展方向等,欢迎大家~】

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 4
4 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)