Stata向量自回归模型(VAR)实操指南:从基础到论文应用
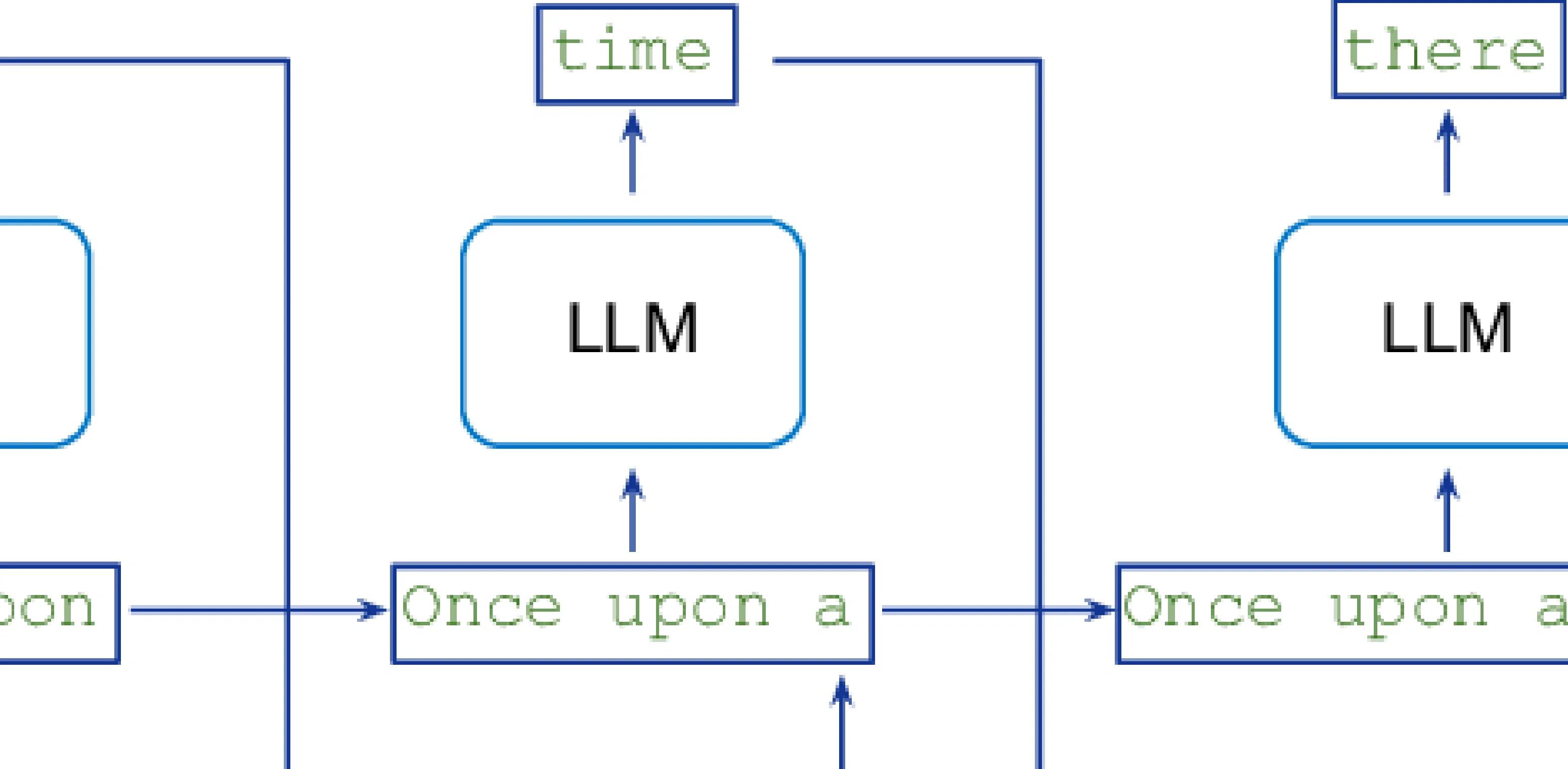
作为一个用Stata做时间序列研究快4年的“老玩家”,我必须说VAR模型是我处理多变量时间序列数据的“王牌工具”——它完美解决了传统单变量自回归模型无法捕捉变量间动态关系的痛点,比如GDP、通货膨胀率、利率之间的相互影响。今天就结合我自己的实操经验,把VAR模型的原理、Stata代码、避坑指南和论文应用技巧整理出来,新手也能直接上手。
一、先搞懂VAR模型的核心逻辑
很多人刚接触VAR模型时会有疑问:“我已经跑了单变量自回归模型,为什么还要做VAR模型?”其实两者的核心差异在于:
- 单变量自回归模型:只能分析单个变量的动态变化,忽略了变量之间的相互影响
- VAR模型:专门处理多变量时间序列数据,将系统中每个内生变量视为所有内生变量滞后值的函数,能更准确地揭示变量间的动态互动关系
VAR模型的原理也很简单:它通过建立多个方程联立的模型,来捕捉变量之间的相互影响。比如我们可以用它来分析“GDP、通货膨胀率、利率之间的动态关系”,或者“股价、汇率、利率之间的相互影响”。
二、Stata实操:从基础到进阶
1. 序列平稳性检验
VAR模型要求变量平稳,需先进行单位根检验(如ADF检验)。如果变量非平稳但存在协整关系,需采用VECM(向量误差修正模型)。 Stata代码:
// 用Stata自带时间序列数据(以lutkepohl2.dta为例)
help q_time // 加载数据
tsset qtr // 设定时间变量(若数据已设定可省略)
tsline inv inc consump // 绘制时序图观察趋势
// 单位根检验(对变量一阶差分后检验平稳性)
dfuller dln_inv
dfuller dln_inc
dfuller dln_consump2. 确定滞后阶数
根据信息准则(如AIC、BIC)选择最优滞后阶数,需平衡模型拟合优度与自由度,避免过拟合或欠拟合。 Stata代码:
// 设定最大滞后期为13,计算不同阶数的信息准则
varsoc dln_inv dln_inc dln_consump if _n<=80, maxlag(13)3. 估计VAR模型并检验残差
估计VAR模型后,需检验残差是否存在自相关(白噪声检验),若p值>0.05,残差无自相关,模型有效。 Stata代码:
// 估计VAR模型(以滞后1-4期为例)
var dln_inv dln_inc dln_consump if _n<=80, lags(1/4)
// 小样本情况下可添加选项:
var x y z, lags(1/#) dfk small exog(w1 w2) // exog指定外生变量
// 检验残差自相关(白噪声检验)
varlmar // 若p值>0.05,残差无自相关,模型有效4. VAR系统平稳性检验
确保模型特征根均在单位圆内,若所有根模<1则平稳。 Stata代码:
varstable, graph // 绘制特征根图,所有根模<1则平稳5. 预测与结果分析
预测未来变量值,并对比实际值与预测值,检验残差是否服从正态分布。 Stata代码:
// 预测未来15期变量值
fcast compute p_, step(15) // p_为预测值前缀
fcast graph p_dln_inv p_dln_inc p_dln_consump, observed lpattern("_") // 对比实际值与预测值
// 残差正态性检验
varnorm // 若p值>0.05,残差服从正态分布6. 格兰杰因果关系检验
分析变量间的预测关系,检验某变量是否为另一变量的格兰杰原因。 Stata代码:
vargranger // 检验某变量是否为另一变量的格兰杰原因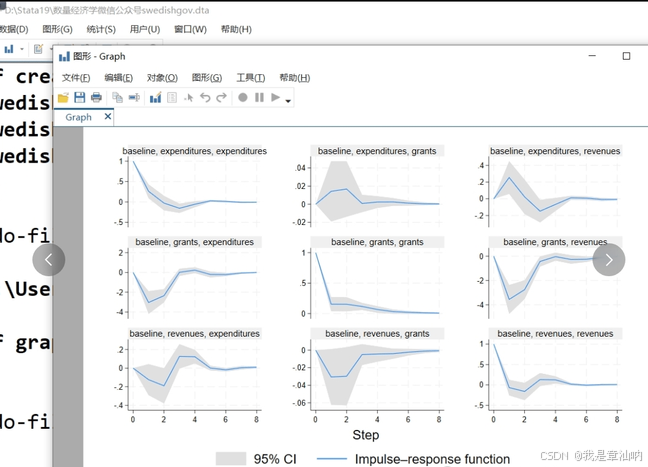
三、VAR模型结果怎么看?重点看这几个指标
每次跑出来回归结果,我都会先看这几个关键指标:
- 系数(Coefficient):自变量对因变量的影响,比如系数是0.5,就表示x的滞后值增加1单位,y会增加0.5
- p值(P>|z|):判断系数是否显著,一般p<0.05就说明显著
- 信息准则(AIC、BIC):选择最优滞后阶数,AIC或BIC越小说明模型拟合效果越好
- 特征根图:判断VAR系统是否平稳,所有根模<1则平稳
- 格兰杰因果关系检验结果:判断变量间的预测关系,若p值<0.05,说明某变量是另一变量的格兰杰原因
四、VAR模型的适用场景
VAR模型不是万能的,我一般在这几种场景下会用它:
- 宏观经济分析:解释GDP、通货膨胀、失业率等变量间的动态关系并预测走势
- 货币政策评估:分析利率等政策变量对经济指标(如通胀、增长)的影响
- 金融市场分析:研究股价、汇率、利率等金融变量的相互影响及冲击传播效应
- 资产组合优化:估计资产间的相关性和波动率,辅助构建风险较低的投资组合
- 跨国比较研究:分析不同国家和地区的经济比较研究,揭示不同经济体之间的相互影响和动态关系
五、论文应用技巧
- 结果呈现:论文里建议同时报告系数、p值、信息准则等信息,特征根图和格兰杰因果关系检验结果也可以放在附录里
- 稳健性检验:可以换不同的滞后阶数、不同的变量排序、不同的模型类型(比如从VAR模型换成VECM模型),验证结果的稳健性
- 可视化:可以用脉冲响应函数图、方差分解图展示变量间的动态关系,让结果更直观
- 解释技巧:解释系数时,比如“GDP的滞后1期值每增加1单位,通货膨胀率会增加0.5单位”,比直接解释数学公式更易懂
六、实操避坑指南
- 变量排序要合理:脉冲响应函数(IRF)依赖变量顺序,需结合经济理论或格兰杰因果检验结果调整
- 滞后阶数选择要谨慎:信息准则(AIC/BIC)需平衡模型拟合优度与自由度,避免过拟合或欠拟合
- 平稳性要求要注意:若变量非平稳但存在协整关系,需采用VECM(向量误差修正模型)
- 结果解释要客观:VAR模型只是一种量化分析方法,结果需要结合实际情况进行解释,不能盲目相信量化结果

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 7
7 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)