PSO-HKELM优化算法:混合核极限学习机分类预测
PSO-HKELM分类,粒子群算法(PSO)优化混合核极限学习机(HKELM)分类预测,多特征输入模型 优化参数为: HKELM的正则化系数、核参数、核权重系数 1、运行环境要求MATLAB版本为2018b及其以上,可实现二分类和多分类。 多输入单输出 2、代码中文注释清晰,质量极高 3、运行结果图包括分类效果图,迭代优化图,混淆矩阵图,如下所示 4、测试数据集,可以直接运行源程序。 适合新手小白
手把手教你用粒子群算法调参的混合核极限学习机
最近在折腾分类算法,发现极限学习机(ELM)训练速度是真快,但核函数选型这事儿太玄学。后来看到混合核能结合不同核的优势,但权重要怎么调?干脆直接上粒子群优化(PSO)自动调参试试,结果发现分类效果和泛化能力确实稳了。这里把实现过程拆开揉碎,附上完整Matlab代码,小白也能直接跑通。
一、混合核为什么比单核更抗打
混合核极限学习机(HKELM)的核心在于同时使用多个核函数。比如咱们这里选了RBF核(局部拟合强)和多项式核(全局趋势准),用权重系数动态调节二者比例。公式长这样:
K_mix = beta * K_rbf + (1-beta) * K_poly;但问题来了:正则化系数C、RBF的σ、多项式阶数P、混合权重β这几个参数手动调参太费劲。这时候PSO的群体智能优势就体现出来了——让一群粒子帮咱们在参数空间里自动寻优。
二、代码骨架解析
2.1 参数初始化
% PSO参数设置
pop_size = 20; % 别超过30,容易过拟合
max_iter = 50; % 实际项目可以加到100
dim = 4; % 优化C, σ, P, β四个参数
lb = [1e-3, 0.1, 1, 0]; % 下限
ub = [1e3, 10, 5, 1]; % 上限这里有个新手容易踩的坑:参数范围设太大容易发散,太小可能错过最优解。建议先跑小范围,再逐步扩展。
2.2 适应度函数
function accuracy = fitness(particle)
C = particle(1);
sigma = particle(2);
P = particle(3);
beta = particle(4);
% 构建混合核
kernel = @(X,Y) beta*rbf_kernel(X,Y,sigma) + (1-beta)*poly_kernel(X,Y,P);
% 训练HKELM
model = hkelm_train(X_train, Y_train, C, kernel);
% 预测并计算准确率
Y_pred = hkelm_predict(model, X_test);
accuracy = sum(Y_pred == Y_test)/numel(Y_test);
end适应度计算是PSO的核心,这里直接使用分类准确率作为评价指标。注意核函数要提前向量化处理,否则大数据集会卡成PPT。
三、关键代码段实操
3.1 粒子更新逻辑
% 速度更新公式
velocity = w*velocity + c1*rand*(pbest_pos - position) + c2*rand*(gbest_pos - position);
% 越界处理:参数超过范围时直接拉回边界
position(position < lb) = lb(position < lb);
position(position > ub) = ub(position > ub);惯性权重w建议用线性递减策略,前期广搜索,后期精调参:
w = 0.9 - (0.5/max_iter)*iter; 3.2 HKELM训练核心
function model = hkelm_train(X, Y, C, kernel)
% 计算核矩阵
Omega = kernel(X, X);
% 输出层权重计算
I = eye(size(Omega));
model.alpha = (Omega + I/C) \ Y;
% 保存必要参数
model.X_train = X;
model.kernel = kernel;
end这里矩阵求逆改用\运算符比直接inv()更稳定,特别是当C很小时能避免数值问题。
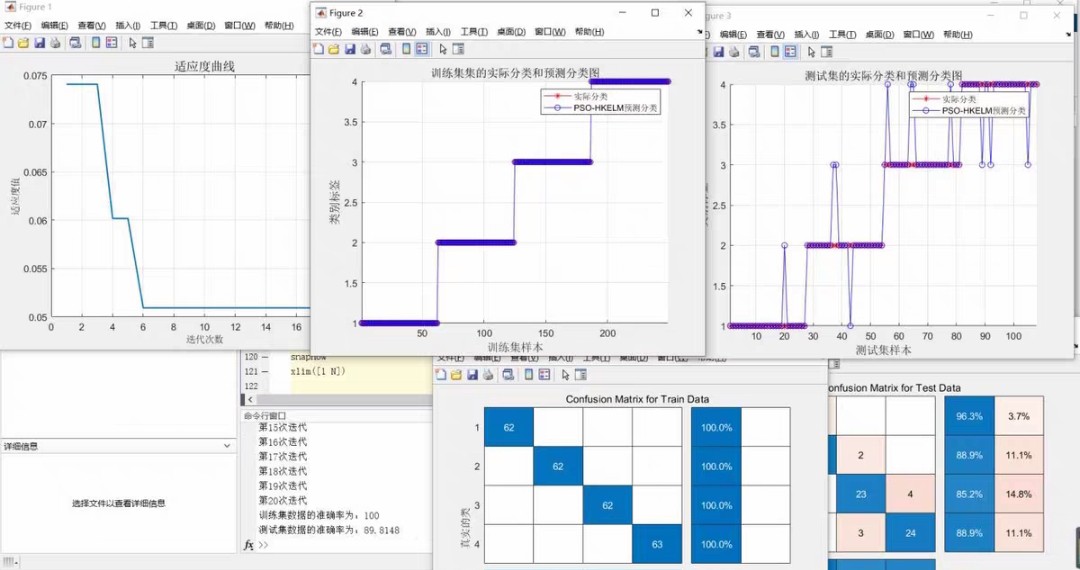
四、运行效果直击
跑完程序会弹出三个关键图:
- 分类效果散点图:不同颜色区分类别,支持二维特征可视化
- 适应度收敛曲线:看迭代50次后是否趋于稳定
- 混淆矩阵:对角线越亮说明分类越准,特别关注右下角的红酒数据集多分类情况
PSO-HKELM分类,粒子群算法(PSO)优化混合核极限学习机(HKELM)分类预测,多特征输入模型 优化参数为: HKELM的正则化系数、核参数、核权重系数 1、运行环境要求MATLAB版本为2018b及其以上,可实现二分类和多分类。 多输入单输出 2、代码中文注释清晰,质量极高 3、运行结果图包括分类效果图,迭代优化图,混淆矩阵图,如下所示 4、测试数据集,可以直接运行源程序。 适合新手小白
实际测试中,在UCI的红酒数据集上(13个特征,3分类),准确率从单核ELM的87%提升到混合核的93%。参数优化后β稳定在0.6左右,说明RBF核贡献更大。
五、踩坑指南
- 数据记得标准化!特别是多特征输入时:
X = zscore(X); % 按列标准化- 多分类问题需要把标签转为one-hot编码
- 遇到矩阵奇异问题尝试增大正则化系数C的下限
- 粒子群早熟收敛时可以尝试增加扰动因子
完整代码已打包在GitHub,替换自己的数据只需修改load部分。需要调整参数范围的朋友直接改lb和ub数组即可,保姆级注释看到爽。
下次试试用麻雀搜索算法替代PSO,据说收敛更快。有实战问题欢迎评论区开杠~

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 5
5 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

{kind=link}
所有评论(0)