MySQL Explain 执行计划详解:别只盯着 key,带你看懂索引为什么失效
Explain 执行计划详解:一条慢 SQL 到底慢在哪,索引为什么会失效
真正会用
Explain的人,不是能把字段含义背下来的人,而是能顺着执行计划,把一条 SQL 的访问路径讲明白的人。
很多人第一次学 MySQL Explain,都会很快进入一种“背字段模式”。
看到执行计划,先找 key 是不是 NULL,再看有没有走索引;看到 type=ALL 就紧张,看到 Using filesort 就觉得完了,最后把整份 Explain 学成一张“字段翻译表”。
但真实项目里,SQL 优化往往不是这样做的。
真正让人头疼的场景通常是:
- 索引明明建了,查询还是慢。
Explain里明明显示用了索引,但接口时间还是很难看。- 两条看起来很像的 SQL,执行代价却完全不一样。
- 一改成
select *、like '%xx%'、date(create_time),性能就明显掉下来了。
我后来慢慢意识到,Explain 的核心价值,从来不是告诉你“有没有索引”,而是告诉你:
- 这条 SQL 打算怎么走。
- 它为什么要这么走。
- 它慢在扫描、过滤、排序,还是回表。
- 你下一步到底应该改 SQL,还是改索引。
这篇文章我会把内容重新按“实战排查”的视角来讲,不再只是字段罗列,而是按下面这个顺序:
- 先用几张图把
Explain背后的索引逻辑补齐。 - 再讲
Explain真正该重点看的字段。 - 再用一组高频 SQL 场景,把索引失效和执行计划读法串起来。
- 最后补上 MySQL 8+ 更值得掌握的新能力。
如果你最近正在补 MySQL 性能优化,这篇文章尽量让你看完之后,不只是“知道”,而是“能上手分析”。
1. 为什么 Explain 值得重学
很多人对 Explain 的第一印象是:“查执行计划的工具。”
这个定义没错,但它太轻了。
如果把 SQL 查询看成一次出行,Explain 更像一张路线图。它不负责告诉你结果是什么,而是告诉你数据库准备怎么到达结果。
同样是“从 A 点到 B 点”:
- 有的人走高速,代价低。
- 有的人绕远路,扫描了很多无效数据。
- 有的人虽然上了高速,但最后下匝道又堵住了,比如回表、排序、临时表。
所以 Explain 真正要看的,从来不是“是否用了索引”这一个点,而是整条访问路径是否合理。
2. 先别急着看字段,先把索引背后的 3 张图补齐
如果不先理解索引结构,后面很多 Explain 现象都会变成死记硬背。
2.1 B+Tree 为什么适合范围查找
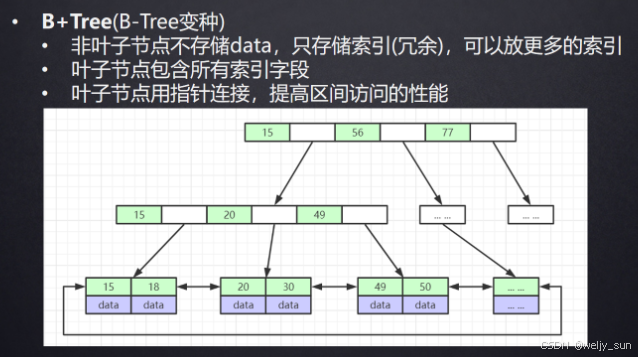
这张图特别适合用来理解两个问题:
- 为什么 MySQL 索引特别擅长等值查询和范围查询。
- 为什么一旦你破坏了索引本身的有序性,优化器就很难继续走这条路径。
核心点在于:
- 非叶子节点主要存键值和指针,不存完整数据,所以一页能放更多索引项。
- 叶子节点天然有序,并且通常彼此相连,所以范围扫描会很高效。
- 只要条件还能顺着这棵树往下定位,索引就能发挥价值。
也正因为这样,像 where id > 100、between、like 'abc%' 这种条件通常比较适合索引;而 like '%abc'、date(create_time) 这种写法,则很容易让优化器放弃这条有序路径。
2.2 联合索引为什么强调最左前缀
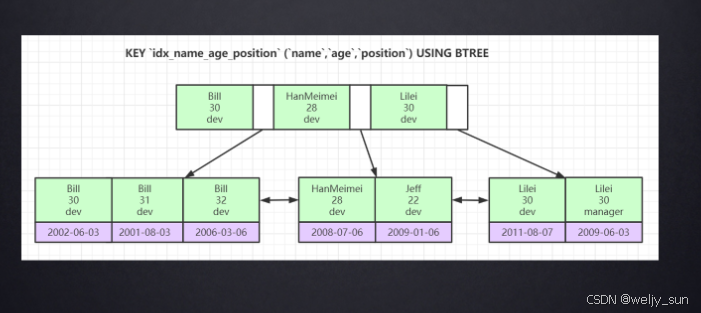
很多人把“最左前缀法则”当口诀来背,但真正有用的是理解它为什么存在。
假设有联合索引:
KEY idx_name_age_position (name, age, position)
那么这棵索引树的组织顺序,其实就是:
- 先按
name排。 name相同,再按age排。name和age都相同,再按position排。
所以你写:
WHERE name = 'LiLei' AND age = 30
优化器能顺着树很快定位。
但如果你写:
WHERE age = 30 AND position = 'dev'
你等于一上来就跳过了入口列 name,数据库很难高效利用这棵树的有序性。
这就是为什么“最左前缀”不是玄学,而是 B+Tree 排序规则的直接结果。
2.3 为什么 select * 往往更贵:覆盖索引和回表
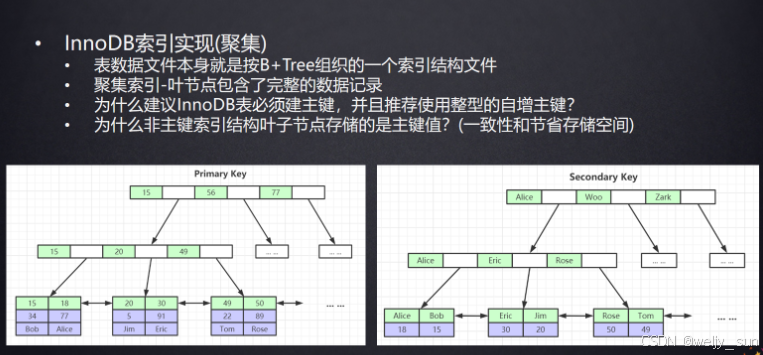
InnoDB 下最容易被忽略的一件事是:二级索引叶子节点里存的不是整行数据,而是“索引列 + 主键值”。
这会直接带来两种完全不同的查询路径:
- 如果你查询的字段刚好都在二级索引里,那就是覆盖索引,数据库可以直接返回结果。
- 如果你还要别的列,数据库就得先命中二级索引,再根据主键回到聚簇索引里把整行捞出来,这就是回表。
为什么这件事重要?
因为很多 SQL 慢,不是“没走索引”,而是“虽然走了索引,但回表太多”。
这一点后面我们会专门再展开。
3. Explain 到底是什么:它不是结果,而是访问路径的预判
Explain 本质上是让优化器把“准备怎么执行这条 SQL”先展示给你看。
所以它最适合解决的问题是:
- 先判断执行路径对不对。
- 再决定优化动作该落在 SQL 还是索引上。
我现在读 Explain,一般不会从左到右把所有列都看一遍,而是先按下面这条路线走。
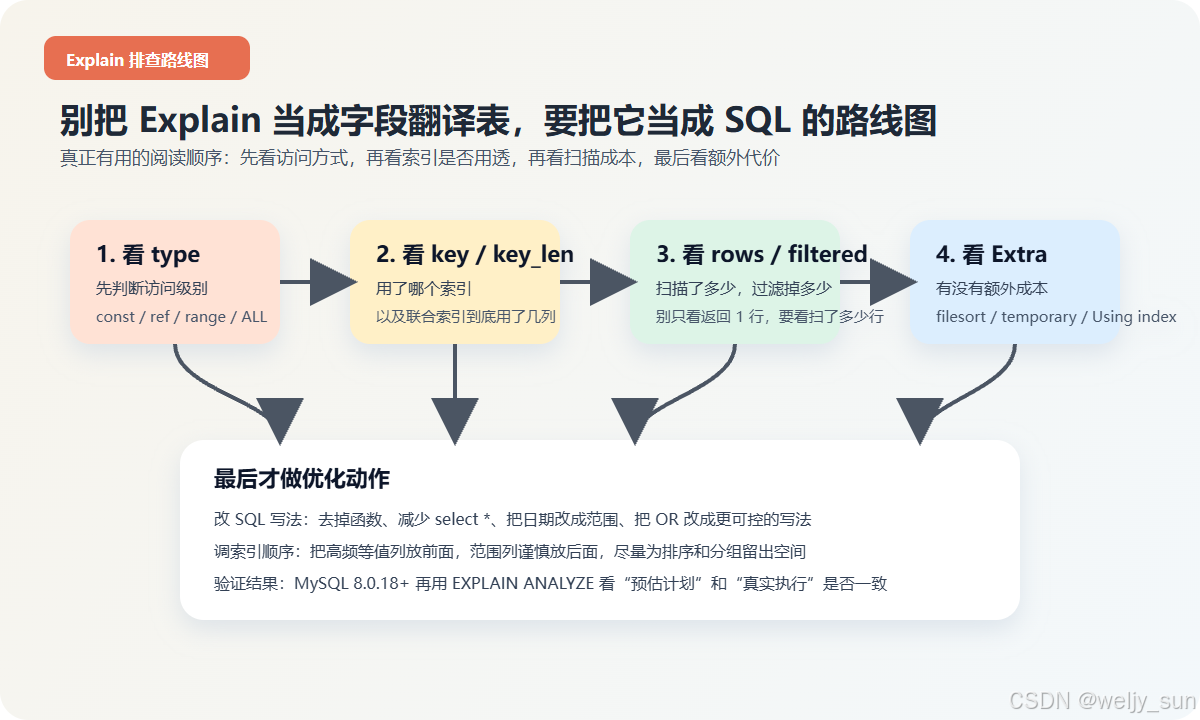
这张图背后对应的是一个很实用的顺序:
- 先看
type,判断访问级别是不是太差。 - 再看
key和key_len,确认索引到底有没有真正用透。 - 再看
rows和filtered,判断扫描成本是否过高。 - 最后看
Extra,判断是不是慢在排序、分组、回表、临时表这些额外动作上。
如果你一上来先盯着 key 看,很多时候会误判。因为“用了索引”和“用了一个合适的索引”,完全不是一回事。
4. 先放一张示例表,后面所有场景都围绕它来讲
为了让后面的例子更顺,我们先用一张很典型的员工表:
CREATE TABLE employees (
id INT NOT NULL AUTO_INCREMENT,
name VARCHAR(24) NOT NULL DEFAULT '' COMMENT '姓名',
age INT NOT NULL DEFAULT 0 COMMENT '年龄',
position VARCHAR(20) NOT NULL DEFAULT '' COMMENT '职位',
hire_time DATETIME NOT NULL COMMENT '入职时间',
PRIMARY KEY (id),
KEY idx_name_age_position (name, age, position),
KEY idx_hire_time (hire_time)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
我们重点关注两个索引:
- 主键
PRIMARY KEY (id) - 联合索引
idx_name_age_position (name, age, position)
为什么只用这张表就够了?
因为单表已经足够把 Explain 最常见的 80% 场景吃透:
- 主键查询
- 联合索引最左前缀
- 范围条件截断
- 函数导致索引失效
- 覆盖索引和回表
后面我会再补一个 orders 场景,专门讲 Using filesort 和 Using temporary。
5. 真正值得重点看的字段,不是全部,而是这几组
Explain 字段不少,但实战里真正值得花力气看的,主要是下面这些。
| 字段 | 它在回答什么问题 | 你应该怎么读 | 常见误区 |
|---|---|---|---|
id |
谁先执行,谁后执行 | id 越大通常优先级越高;相同 id 一般从上到下执行 |
只会背顺序,不会放到子查询和 union 里理解 |
select_type |
这是简单查询还是复杂查询 | 重点识别 SIMPLE、PRIMARY、SUBQUERY、DERIVED |
看到子查询就慌,其实关键还是看访问路径 |
type |
数据是怎么找到的 | 核心看访问级别,经验上至少尽量达到 range,更理想是 ref / eq_ref |
把 ALL 机械等同于“绝对有问题” |
possible_keys |
理论上哪些索引可能可用 | 只是候选,不等于真的会用 | 以为这里有值,key 就一定不为空 |
key |
实际用了哪个索引 | 先确认有没有用索引,再确认是不是你希望的那条 | 只看 key,不看 key_len |
key_len |
联合索引到底用了多少 | 能帮你判断索引是否只用到了前几列 | 以为“用了联合索引”就等于“用满了联合索引” |
rows |
预计要扫描多少行 | 这是成本判断的重要依据 | 只看返回行数,不看扫描行数 |
filtered |
扫描到的数据有多少比例能通过过滤 | 能帮助你判断过滤动作是不是发生得太晚 | 把它当成结果集准确统计值 |
Extra |
有没有额外动作 | 重点看 Using index、Using where、Using filesort、Using temporary |
看到 Using where 就误以为是坏事 |
这一张表如果要压成一句话,我会这样记:
type看访问级别。key/key_len看索引是否用对、用透。rows/filtered看成本。Extra看额外代价。
6. 从 6 个高频场景里,看懂 Explain 到底该怎么用
下面这些场景,几乎是平时排查 SQL 时最常见的一批问题。
需要说明一下,rows、filtered、Extra 的具体细节会受到版本、数据量和统计信息影响,所以这里重点讲“现象”和“分析思路”,不把某一个数值写死。
6.1 场景一:主键等值查询,为什么通常最稳
EXPLAIN
SELECT *
FROM employees
WHERE id = 1001;
这类 SQL 一般是单表查询里最理想的类型之一。
你通常会看到的现象是:
key=PRIMARYrows很小,很多时候接近 1type非常好,通常接近const
为什么它这么稳?
因为主键本身就是最强定位条件。优化器不用扫一大片范围,只需要沿着聚簇索引快速命中目标行。
这类 SQL 给我们的启发不是“主键真好”,而是:当你的查询条件能把扫描范围压得足够小,执行计划通常就不会太差。
6.2 场景二:联合索引全值匹配,为什么这是最舒服的单表场景
EXPLAIN
SELECT name, age, position
FROM employees
WHERE name = 'LiLei'
AND age = 22
AND position = 'manager';
这条 SQL 的舒服之处在于,它和联合索引的顺序完全一致:
- 先按
name - 再按
age - 再按
position
这时你应该重点看两个点:
key是否命中了idx_name_age_positionkey_len是否足够长,说明三个列都被真正利用到了
如果查询列也刚好都在索引里,那 Extra 还有机会出现 Using index,这意味着它不需要回表,代价会更小。
很多人喜欢用一句话概括这个场景:命中联合索引。
但我更愿意把它理解成:优化器既找到了正确的入口,也顺着正确的顺序把范围压到了足够小。
6.3 场景三:跳过最左列,为什么索引像“突然没用了一样”
EXPLAIN
SELECT *
FROM employees
WHERE age = 22
AND position = 'manager';
这类 SQL 很容易让人困惑:“我不是明明建了 (name, age, position) 吗,为什么效果还是一般?”
问题就出在你跳过了最左列 name。
对于这棵索引树来说,name 是第一层组织顺序。你不先给出 name,数据库就很难直接定位到一小段连续范围内去找数据。
这时常见的结果是:
- 要么走不了你期待的联合索引。
- 要么即使看起来用了索引,利用程度也很有限。
rows可能明显上升。
所以“最左前缀”真正要解决的问题,不是记忆规则,而是理解索引树的入口。
如果业务里这类查询非常高频,就别指望原来的联合索引兼顾一切了,往往需要为新场景补一条更合适的索引。
6.4 场景四:在索引列上做函数,为什么执行计划会变难看
先看这条:
EXPLAIN
SELECT *
FROM employees
WHERE DATE(hire_time) = '2018-09-30';
很多项目里的慢 SQL,都是这样写出来的。
从业务角度看,这条 SQL 当然没问题;但从索引角度看,它的问题很明显:你不是直接拿 hire_time 去匹配,而是先对它做了一次 DATE() 计算。
一旦你把索引列加工了,数据库就很难继续沿着原本的有序索引去定位。
更稳的写法通常是改成范围查询:
EXPLAIN
SELECT *
FROM employees
WHERE hire_time >= '2018-09-30 00:00:00'
AND hire_time < '2018-10-01 00:00:00';
这两条 SQL 的语义很接近,但执行计划可能完全不同。
根本原因不是第二条“更高级”,而是它保留了索引列原本的有序性,让优化器有机会做范围扫描。
这类问题在真实项目里特别常见:
DATE(create_time)YEAR(create_time)LEFT(name, 3)- 隐式类型转换
你可以把它们统一理解成一类问题:不是索引没建,而是你把索引入口给改坏了。
6.5 场景五:为什么 select * 往往会把一条本来还不错的 SQL 拖慢
先看这条:
EXPLAIN
SELECT name, age, position
FROM employees
WHERE name = 'LiLei'
AND age = 23;
再看这条:
EXPLAIN
SELECT *
FROM employees
WHERE name = 'LiLei'
AND age = 23;
这两条 SQL 看起来只是“查的列多一点、少一点”,但从执行路径上看,它们可能完全不是一个成本级别。
下面这张图可以直观看这个差别:
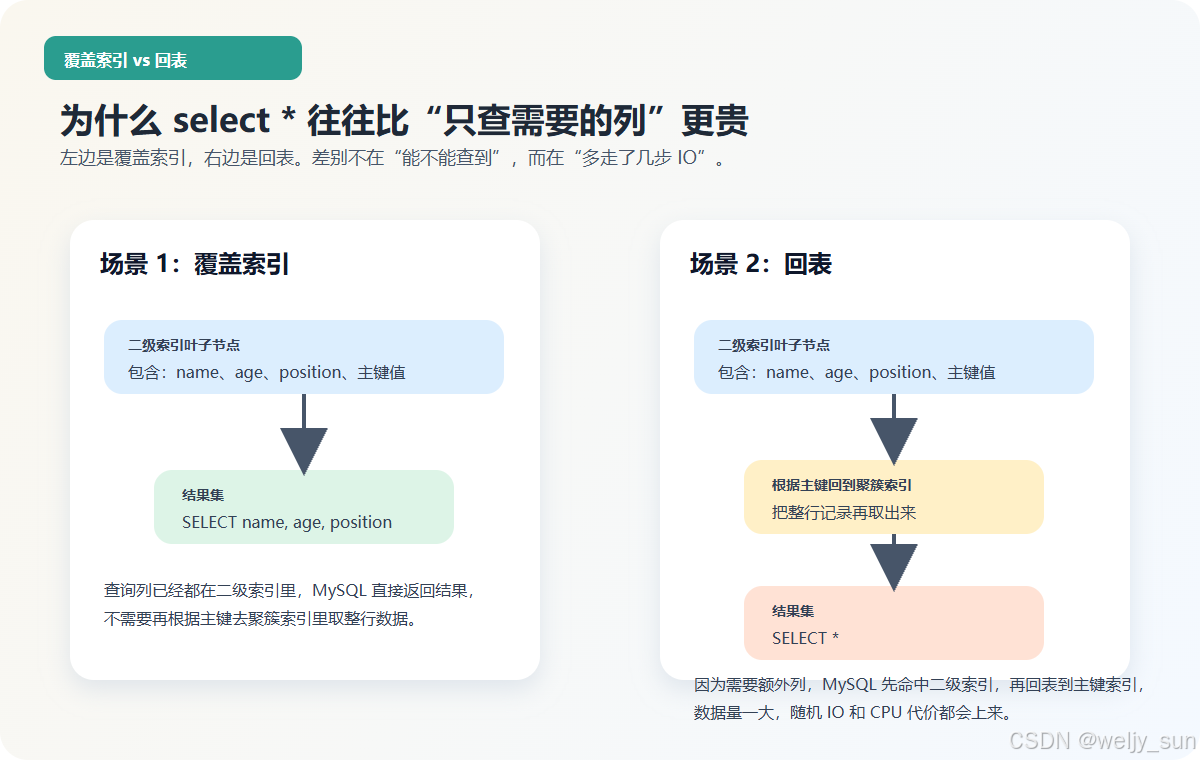
第一条查询更容易形成覆盖索引,因为 name、age、position 都已经在 idx_name_age_position 里。
这意味着:
- 数据库命中二级索引后,直接就能把结果返回出来。
Extra更容易出现Using index。
而第二条 select * 则很可能需要回表:
- 先命中二级索引。
- 再根据主键去聚簇索引里把整行数据拿回来。
当数据量很小时,这个差别不明显;但一旦扫描行数上来,回表带来的随机 IO 成本就会非常明显。
所以我现在对 select * 的态度一直比较谨慎:
- 不是绝对不能写。
- 但它不应该成为默认写法。
- 如果一条 SQL 本来有机会走覆盖索引,
select *往往就是把这份红利主动放掉了。
6.6 场景六:为什么用了索引,还是会出现 Using filesort 和 Using temporary
很多人学到这一步会发现另一个困惑:
“我的 SQL 不是已经走索引了吗,为什么 Extra 里还是有 Using filesort 或 Using temporary?”
这通常发生在排序和分组场景里。
比如下面这类查询:
EXPLAIN
SELECT *
FROM orders
WHERE order_status = 2
ORDER BY total_amount DESC
LIMIT 20;
哪怕你在 order_status 上有索引,这条 SQL 也未必能靠索引直接把排序做完。
原因很简单:
- 过滤条件用的是
order_status - 排序条件用的是
total_amount
如果没有一条能够同时兼顾“过滤顺序”和“排序顺序”的索引,数据库就很可能先筛出一批数据,再额外排序,于是你会看到 Using filesort。
再比如分组:
EXPLAIN
SELECT city, COUNT(*) AS order_cnt
FROM orders
WHERE pay_status = 1
GROUP BY city
ORDER BY order_cnt DESC;
这类 SQL 很容易在 Extra 里出现 Using temporary,因为数据库需要先聚合,再生成中间结果,最后还要排序。
这时真正应该想的不是“为什么它这么笨”,而是:
- 当前索引有没有同时覆盖过滤列和分组列。
- 聚合后的排序能不能被索引天然接住。
- 这是不是本来就更适合报表表、汇总表、缓存层来承接的查询。
也就是说,Using filesort 和 Using temporary 不一定代表你写错了 SQL,但它们一定是在提醒你:这里有额外成本。
7. 为什么“有索引”不等于“会走索引”,更不等于“性能就一定好”
这是很多人学 SQL 优化时最容易掉进去的误区。
数据库选择执行路径,看的是成本,不是面子。
下面这些情况,都可能导致“明明建了索引,但优化器不愿意按你想的方式走”:
7.1 选择性太差
如果一个条件一查就命中表里很大一部分数据,优化器可能会判断:既然反正要拿很多行,不如直接扫表。
7.2 范围太大
比如:
WHERE age >= 1 AND age <= 2000
如果这个范围本身就很大,优化器会重新计算成本,索引未必占优。
7.3 对索引列做了函数、运算或隐式转换
这会破坏索引列原本的有序性,前面已经讲过,这是最典型的一类索引失效原因。
7.4 OR、IN、!=、NOT IN、NOT EXISTS
这些条件不是绝对不能用索引,但它们经常会让执行路径变复杂,优化器也更容易在多个候选路径之间权衡后选择别的方案。
7.5 回表代价太高
有时 key 明明不是 NULL,但整条 SQL 还是很慢,原因可能不是没索引,而是回表太多。
7.6 统计信息不准确
优化器做决策依赖统计信息。如果统计信息不准确,也可能导致路径判断不理想。
所以 SQL 优化最怕的一种思维就是:
- 建索引
- 跑
Explain - 看到
key不为空 - 觉得已经优化完成
这套流程太粗了。真正的关键,是看这条索引路径到底有没有把扫描范围、过滤成本和额外动作一起压下来。
8. 我现在更推荐的 Explain 排查顺序
以前我读执行计划,习惯从左到右一列列看。后来发现这样很容易陷进细节里,却抓不住主线。
现在我更愿意按下面这套顺序排查:
第一步:先看 type
先判断访问方式是不是太差。
如果一上来就是 ALL,先别急着下结论,但至少说明你该警觉了。
第二步:再看 key 和 key_len
确认到底用了哪条索引,以及联合索引是不是只用了前一部分。
很多“看起来用了索引”的 SQL,其实只是“浅浅用了第一列”。
第三步:再看 rows
这是判断成本的关键线索。
结果只返回 1 行,不等于它只扫描了 1 行。真正贵的地方,往往就藏在这里。
第四步:最后看 Extra
重点关注:
Using indexUsing whereUsing index conditionUsing filesortUsing temporary
这里最重要的不是死记硬背它们的字面意思,而是把它们翻译成“数据库额外做了什么事”。
9. MySQL 8+ 之后,更值得补进来的 Explain 能力
如果你现在学 Explain,还停留在很早期的旧资料里,那我很建议把下面这几件事一起补上。
9.1 普通 EXPLAIN 依然是入口,但不再是终点
普通 EXPLAIN 依然很重要,因为它给你的是执行前的路线预判。
但如果你只停留在这里,很多时候就只能“猜”问题在哪。
9.2 FORMAT=TREE 更适合看执行路径
相比传统表格结果,FORMAT=TREE 更适合用来观察优化器的执行层级。
例如:
EXPLAIN FORMAT=TREE
SELECT *
FROM employees
WHERE name = 'LiLei';
你会更容易从树形结构里看出:
- 先做了什么
- 后做了什么
- 哪一步是过滤,哪一步是扫描
对于刚从“字段阅读”转向“路径阅读”的同学,这个格式很有帮助。
9.3 FORMAT=JSON 更适合做结构化分析
如果你想把执行计划接到平台、脚本或工具里,FORMAT=JSON 会更友好,因为它更适合结构化解析。
例如:
EXPLAIN FORMAT=JSON
SELECT *
FROM employees
WHERE name = 'LiLei';
这对做 SQL 巡检、自动化分析或者内部诊断平台都很有价值。
9.4 EXPLAIN ANALYZE 最大的价值,不是“更高级”,而是“能验证”
这是我最建议补进来的能力。
EXPLAIN ANALYZE
SELECT *
FROM employees
WHERE name = 'LiLei';
它和普通 EXPLAIN 的差别在于:
- 普通
EXPLAIN看的是优化器“预计怎么做” EXPLAIN ANALYZE看的是数据库“实际怎么做”
这一步为什么重要?
因为很多 SQL 的问题,恰恰就出在“预估和实际不一致”。
不过这里要特别提醒一句:
EXPLAIN ANALYZE 会实际执行查询,所以在线上对重 SQL 使用时一定要谨慎。
9.5 旧资料里常见的 EXPLAIN EXTENDED,现在不用当重点了
如果你在一些老资料里还能看到 EXPLAIN EXTENDED,知道它是老语法背景就够了,不需要把它当成今天学习的重点。
对现在的日常分析来说,更值得掌握的是:
- 普通
EXPLAIN FORMAT=TREEFORMAT=JSONEXPLAIN ANALYZE
10. 3 个最容易踩的 Explain 误区
10.1 误区一:key 不为空,就说明 SQL 已经优化好了
不对。
key 不为空,只能说明数据库选了一条索引路径,不代表这条路径就是最优的,更不代表扫描行数、回表次数和排序代价都已经合理。
10.2 误区二:看到 ALL 就一定是严重问题
也不对。
小表全表扫描,有时候比走索引还划算。判断问题要结合表大小、rows、查询频率和整体代价。
10.3 误区三:索引优化就是“多建几个索引”
这更危险。
索引不是越多越好。你真正需要的是:
- 让高频查询有合适入口
- 让联合索引顺序尽量贴合查询条件
- 让排序、分组、覆盖索引也被一起考虑进去
11. 如果把整篇文章压成一份排查清单,我会这么用
线上遇到慢 SQL 时,我现在更习惯按这份清单过一遍:
- 先跑
EXPLAIN,不要先猜。 - 先看
type,判断访问方式是不是太差。 - 再看
key和key_len,判断索引有没有用对、用透。 - 再看
rows,判断扫描成本是不是过高。 - 再看
Extra,判断是不是慢在排序、分组、临时表或回表。 - 对照 SQL 本身,排查是不是有函数、隐式转换、
select *、前置通配符、过大范围、OR等问题。 - 再决定是改 SQL 写法,还是补索引,还是重构查询路径。
- 如果是 MySQL 8+,再用
EXPLAIN ANALYZE验证预估和实际是否一致。
这套顺序最大的价值,是让 SQL 优化不再只是“凭经验试错”,而更像一个有步骤的工程过程。
12. 写在最后
我现在越来越觉得,Explain 真正难的地方,从来不是记住每一列的名字,而是把执行计划翻译成一条完整的访问路径。
你要能看出:
- 数据是怎么找到的。
- 索引为什么有效,或者为什么失效。
- SQL 是慢在扫描、过滤、回表,还是排序和分组。
- 下一步应该改 SQL、改索引,还是换查询思路。
如果把这篇文章再压缩成一句话,那就是:
Explain 的重点,不是“有没有索引”,而是“这条 SQL 到底是怎么跑的”。
当你真正开始顺着这条线去看执行计划时,索引优化这件事就不会再只是背口诀,而会慢慢变成一件能分析、能解释、也能落地的事。
参考资料
- MySQL 8.0 Reference Manual - EXPLAIN Statement
- MySQL 9.6 Reference Manual - Obtaining Information with EXPLAIN ANALYZE
- MySQL 9.6 Reference Manual - Obtaining Execution Plan Information
- MySQL Blog - MySQL EXPLAIN ANALYZE in JSON format

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 17
17 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)