ICCV 2025 | VSSD:具有非因果状态空间对偶性的 Vision Mamba
文章目录
- 1.论文信息
- 2.论文主要贡献
- 3.论文创新点
- 4.研究方法
- 5.实验分析
- 6.个人声明
1.论文信息
- 论文题目
VSSD: Vision Mamba with Non-Causal State Space Duality 具有非因果空间对偶性的vision mamba - 论文作者
Yuheng Shi,Minjing Dong,Mingjia Li,Chang Xu - 发表单位
香港大学,香港城市大学,天津大学,悉尼大学 - 发表会议 ICCV2025
- 论文地址
https://openaccess.thecvf.com/content/ICCV2025/html/Shi_VSSD_Vision_Mamba_with_Non-Causal_State_Space_Duality_ICCV_2025_paper.html - 代码链接
https://github.com/YuHengsss/VSSD
2.论文主要贡献
a. 提出了NC-SSD,既保留了原始SSD的全局感受野和线性复杂度优势,又融入了固有的非因果特性(全局感受野:模型的一个输出节点,能否看到整个输入,整张图、整个序列等 非因果:模型在生成第t个输出时,能不能用到t之后的未来信息)
b. 以NC-SSD为基础组件提出了VSSD模型,在分类、目标检测和分割等多个公认基准测试中性能由于其他基于SSM的SOTA模型
3.论文创新点
3.1 非因果状态空间对偶
提出了非因果状态空间对偶(NC-SSD),突破SSM和SSD的因果性瓶颈;
因果->非因果:图像没有先后顺序,可访问使用未来时刻的信息
改动模型中关键参数A的作用:保留多少之前的信息->当前的图像块能贡献多少信息到模型里,每一个图像块的作用都由本身决定,不依赖于上文内容
3.2 解决2D特征扁平化的结构破坏问题
二维的图片扁平化为一维的序列会破坏图像的空间信息结构,模型无法识别相邻的两块图像块,为了缓解这个问题需要给模型设置各种复杂的扫描路线,增加了模型的计算负担。
论文中提出的NC-SSD让每个图像块对模型的贡献与其位置距离无关,不会破坏图像原本的结构关系
3.3 VSSD
设计了VSSD模型架构,实现了计算效率和训练速度的双重提升。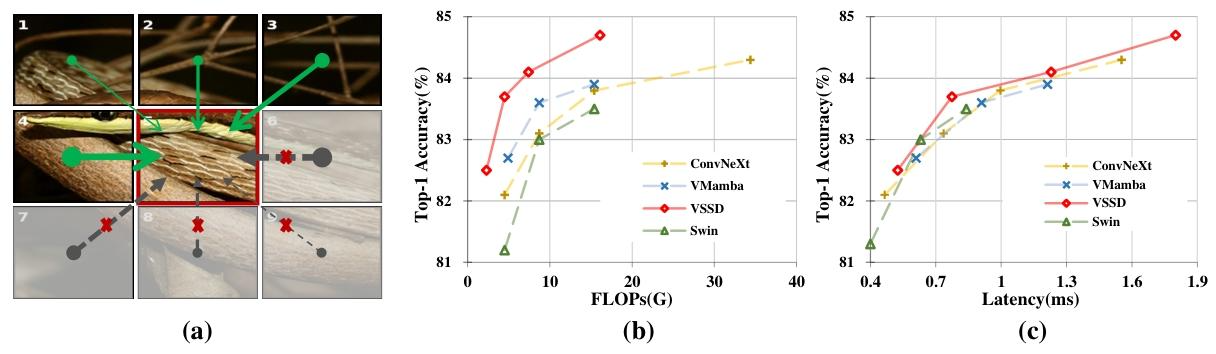
*(a)*将SSM/SSD应用于图像数据时的两个挑战。
第一,展平后的一维序列中的中心标记只能访问之前的标记,无法整合后续标记所提供的信息;
第二,在二维图片中与中心标记相邻的标记1,在展平后的一维序列中距离很远,这极大地破坏了像块之间固有的结构关系
(b) 和 (c) 是在ImageNet上的对比。
与基于CNN的ConvNeXt、基于ViT的Swin Transformer以及基于SSM的VMamba相比,VSSD模型实现了领先的精度和效率。所有模型的延迟均在A100 GPU上以128的批量大小和FP16精度进行测量。
4.研究方法
4.1 Preliminaries 预备知识:状态空间模型(SSM)基础
4.1.1 连续时间SSM
SSM原本是控制论里的模型,用来描述随时间变化的系统,比如水温随加热时间升高、小车速度随油门变化。在深度学习领域,它用来处理序列数据(比如文字、语音),核心公式:
h ′ ( t ) = A ∘ h ( t ) + B ∘ x ( t ) , y ( t ) = C h ( t ) h'(t)=\stackrel{\circ}{A} h(t)+\stackrel{\circ}{B} x(t),\ y(t)=C h(t) h′(t)=A∘h(t)+B∘x(t), y(t)=Ch(t)
参数含义
- x ( t ) x(t) x(t):第t时刻的输入(比如一句话里的第t个词、图像里的第t个token);
- h ( t ) h(t) h(t):模型的隐藏状态,可以理解成模型记住的上下文信息(比如看到第t个词时,记住前面所有词的意思);
- h ′ ( t ) h'(t) h′(t): h ( t ) h(t) h(t)的变化率(比如记忆随时间的更新速度);
- A ∘ \stackrel{\circ}{A} A∘/ B ∘ \stackrel{\circ}{B} B∘:连续版的参数矩阵, A ∘ \stackrel{\circ}{A} A∘控制旧记忆怎么影响新记忆, B ∘ \stackrel{\circ}{B} B∘控制新输入怎么融入记忆;
- C C C:把「记忆」转换成最终输出的矩阵(比如把记忆转换成分类结果)。
总之,SSM就是模型一边看输入,一边更新记忆,最后用记忆输出结果的过程。
4.1.2 连续→离散化:让SSM能在电脑上跑
离散化的原因:
电脑只能处理离散的、一步一步的数据(比如1秒算一次、一个token算一次),但上面的公式是连续的(每时每刻都在变),所以要做离散化处理,核心公式:
h ( t ) = A h ( t − 1 ) + B x ( t ) , y ( t ) = C h ( t ) , where A = e Δ A ∘ , B = ( Δ A ∘ ) − 1 ( e Δ A ∘ − I ) Δ B ∘ ≈ Δ B ∘ , \begin{split} &h(t)=Ah(t-1)+Bx(t),\ y(t)=Ch(t),\\ &\text{where } A=e^{\Delta \stackrel {\circ }{A}},\ B=(\Delta \stackrel {\circ }{A})^{-1}(e^{\Delta \stackrel {\circ }{A}}-I)\Delta \stackrel {\circ }{B}\approx \Delta \stackrel {\circ }{B}, \end{split} h(t)=Ah(t−1)+Bx(t), y(t)=Ch(t),where A=eΔA∘, B=(ΔA∘)−1(eΔA∘−I)ΔB∘≈ΔB∘,
参数含义
- Δ \Delta Δ:时间步长(比如处理图像token时, Δ \Delta Δ就是一个token的间隔);
- e Δ A ∘ e^{\Delta \stackrel {\circ }{A}} eΔA∘:矩阵指数(把连续变化压缩成一步更新);
- 简化后: A A A是连续版 A ∘ \stackrel{\circ}{A} A∘变离散的结果, B B B近似等于 Δ × B ∘ \Delta \times \stackrel{\circ}{B} Δ×B∘;
- 最终离散公式: h ( t ) = A × h ( t − 1 ) + B × x ( t ) h(t) = A×h(t-1) + B×x(t) h(t)=A×h(t−1)+B×x(t) → 当前记忆 = 上一步记忆×衰减系数 + 当前输入×注入系数。
4.1.3 SSM的卷积实现形式:适配深度学习框架
离散化的SSM还能转换成卷积形式
y = x ⊙ K , K = ( C B , C A B , . . . , C A L − 1 B ) y=x \odot K,\ K=\left(C B, C A B, ..., C A^{L-1} B\right) y=x⊙K, K=(CB,CAB,...,CAL−1B)
参数含义
- K K K:卷积核(长度等于序列长度L),里面的每个值都是历史输入对当前输出的权重;
- ⊙ \odot ⊙:卷积操作 → 把SSM的一步一步迭代算记忆,变成用卷积核扫一遍输入序列,速度更快(卷积能并行计算)。
4.1.4 Mamba对基础SSM的改进
传统SSM的 B 、 C 、 Δ B、C、\Delta B、C、Δ是固定值(不管输入是什么,参数都不变),Mamba把这些参数改成输入依赖(不同输入对应不同参数),比如看到 猫 这个token, B B B变大;看到 的 这个token, B B B变小。从而使模型更灵活,能适配不同输入,是后续SSD的基础。
4.2 Non-Causal State Space Duality 非因果状态空间对偶性(NC-SSD)
4.2.1 基础:Mamba2提出的SSD(状态空间对偶性)
Mamba2做了一个关键简化:把SSM里的矩阵A改成标量(单个数字),简化后的SSM就是SSD,有两种实现形式:
4.2.1.1. SSD的矩阵变换形式
y ( t ) = ∑ i = 1 t C t T A t : i + 1 B i x ( i ) , where A t : i = ∏ k = i + 2 t A k , y = SSM ( A , B , C ) ( x ) = F x , where F j i = C j T A j : i B i . \begin{split} &y(t)=\sum _{i=1}^{t}C_{t}^{T}A_{t:i+1}B_{i}x(i),\ \text{where } A_{t: i}=\prod _{k=i+2}^{t}A_{k},\\ &y=\text{SSM}(A,B,C)(x)=Fx,\ \text{where } F_{j i}=C_{j}^{T}A_{j: i}B_{i} . \end{split} y(t)=i=1∑tCtTAt:i+1Bix(i), where At:i=k=i+2∏tAk,y=SSM(A,B,C)(x)=Fx, where Fji=CjTAj:iBi.
参数含义
- 第一行: y ( t ) y(t) y(t)(第t时刻输出)= 从1到t时刻所有输入的加权和 → 现在的输出,由前面所有输入共同决定; C t T C_{t}^{T} CtT是时刻 t t t输出矩阵 C t C_{t} Ct的转置,实现了将隐藏状态映射到观测空间,B是输入矩阵,将输入 x ( i ) x(i) x(i)映射到隐藏状态,A是状态转移矩阵,描述隐藏状态的时序演化;
- A t : i + 1 A_{t:i+1} At:i+1:从i+2到t时刻的A连乘 → 历史输入的衰减系数(比如第1个输入到第5个时刻,要乘A2×A3×A4×A5,越远的输入衰减越多);
- 第二行:把整个序列的输入输出写成矩阵乘法 y = F x y=Fx y=Fx,F矩阵的每个元素 F j i F_{ji} Fji表示第i个输入对第j个输出的贡献,方便批量计算。
4.2.1.2. 标量化后的SSD二次形式
y = F x = M ⋅ ( C T B ) x , where M i j = { A i + 1 × ⋯ × A j i > j 1 i = j 0 i < j y=F x=M \cdot\left(C^{T} B\right) x,\ \text{where } M_{i j}= \begin{cases} A_{i+1} × \cdots × A_{j} & i>j \\ 1 & i=j \\ 0 & i<j \end{cases} y=Fx=M⋅(CTB)x, where Mij=⎩ ⎨ ⎧Ai+1×⋯×Aj10i>ji=ji<j
参数含义
- M是下三角矩阵:只有i>j时有值,i<j时为0,即第j个输出只能受第1到j个输入影响,后面的输入影响不到前面的输出->因果性
- 比如j=3(第3个输出),只能用i=1、2、3的输入,i=4、5的输入没用
4.2.1.3 SSD的线性形式
h ( t ) = A t h ( t − 1 ) + B t x ( t ) , y ( t ) = C t h ( t ) h(t)=A_{t}h(t-1)+B_{t}x(t),\ y(t)=C_{t}h(t) h(t)=Ath(t−1)+Btx(t), y(t)=Cth(t)
参数含义
- 即最初的SSD公式:
- h ( t ) h(t) h(t):第t时刻的记忆;
- A t A_t At:上一步记忆的衰减系数( A t A_t At越小,上一步记忆忘得越快);
- B t B_t Bt:当前输入的注入系数( B t B_t Bt越大,当前输入越重要);
- 举个例子:
A t A_t At=0.8 → 上一步记忆保留80%;
B t B_t Bt=2 → 当前输入放大2倍融入记忆。
4.2.2 SSD应用于视觉任务的两大核心挑战
4.2.2.1:因果性限制
- 因果性的产生原因:SSD只能从左到右处理数据,每个token只能看前面的token,看不到后面的token;
- 图像不适用:图像是非因果数据,比如看一张猫的图片,你看左边的像素时,也能看右边的像素,上下左右的像素是平等的,没有先后顺序;
- 后果:用SSD处理图像,模型只能看到左边的像素,看不到右边的,造成准确性下降
4.2.2.2:2D特征图转为1D序列破坏空间结构
- 图像是2D的(比如224×224),SSD只能处理1D序列,所以要把2D图拉成1D长条(比如224×224=50176个token,排成一列);
- 2D图里相邻的像素(比如猫的眼睛像素和鼻子像素),拉成1D后可能隔了几百个token,模型认不出来它们是相邻的;
- 后果:模型丢失了图像的空间结构信息,比如分不清猫的耳朵在左边还是右边。
4.2.3 第一步改进:SSD线性形式的简化
为了缓解上面的问题,论文先简化SSD的线性形式,核心是舍弃幅值,只保留相对权重,公式:
h ( t ) = h ( t − 1 ) + 1 A t B t x ( t ) = ∑ i = 1 t 1 A i B i x ( i ) h(t)=h(t-1)+\frac{1}{A_{t}} B_{t} x(t)=\sum_{i=1}^{t} \frac{1}{A_{i}} B_{i} x(i) h(t)=h(t−1)+At1Btx(t)=i=1∑tAi1Bix(i)
推导过程
- 原公式: h ( t ) = A t × h ( t − 1 ) + B t × x ( t ) h(t) = A_t×h(t-1) + B_t×x(t) h(t)=At×h(t−1)+Bt×x(t) → 「记忆=旧记忆× A t A_t At + 新输入× B t B_t Bt」;
- 两边除以 A t A_t At: h ( t ) / A t = h ( t − 1 ) + ( B t / A t ) × x ( t ) h(t)/A_t = h(t-1) + (B_t/A_t)×x(t) h(t)/At=h(t−1)+(Bt/At)×x(t);
- 论文简化:只关注相对权重比例,舍弃 A t A_t At,得到 h ( t ) = h ( t − 1 ) + ( 1 / A t ) × B t × x ( t ) h(t) = h(t-1) + (1/A_t)×B_t×x(t) h(t)=h(t−1)+(1/At)×Bt×x(t);
- 展开迭代:从 t = 1 t=1 t=1到 t = T t=T t=T,最终 h ( t ) = 所有输入 × ( 1 / A i ) × B i h(t) = 所有输入×(1/A_i)×B_i h(t)=所有输入×(1/Ai)×Bi的和。
改进的好处与局限
- 好处:每个输入对记忆的贡献是 ( 1 / A i ) × B i (1/A_i)×B_i (1/Ai)×Bi,不用再算A的连乘(比如A2×A3×A4),每个token的贡献解耦了 → 稍微缓解了「2D→1D破坏结构」的问题;
- 局限:还是没解决因果性问题。
4.2.4 第二步改进:双向扫描+全局隐藏状态,实现非因果
H i = ∑ j = 1 i 1 A j Z j + ∑ j = − L − i 1 A − j Z − j = ∑ j = 1 L 1 A j Z j + 1 A i Z i , where Z j = B j x ( j ) H_{i}=\sum_{j=1}^{i} \frac{1}{A_{j}} Z_{j}+\sum_{j=-L}^{-i} \frac{1}{A_{-j}} Z_{-j}=\sum_{j=1}^{L} \frac{1}{A_{j}} Z_{j}+\frac{1}{A_{i}} Z_{i} ,\ \text{where } Z_{j}=B_{j} x(j) Hi=j=1∑iAj1Zj+j=−L∑−iA−j1Z−j=j=1∑LAj1Zj+Ai1Zi, where Zj=Bjx(j)
思路解读
- 核心思路:双向扫描→ 先从左到右扫一遍(正向),再从右到左扫一遍(反向);
- 正向扫描: ∑ j = 1 i ( 1 / A j ) × Z j \sum_{j=1}^{i} (1/A_j)×Z_j ∑j=1i(1/Aj)×Zj → 看前面的token;
- 反向扫描: ∑ j = − L − i ( 1 / A − j ) × Z − j \sum_{j=-L}^{-i} (1/A_{-j})×Z_{-j} ∑j=−L−i(1/A−j)×Z−j → 看后面的token;
- 合并结果: H i H_i Hi = 正向结果 + 反向结果 → 每个token既能看前面,又能看后面,即因果性限制被打破。
论文把公式里的 1 A i × Z i \frac{1}{A_i}×Z_i Ai1×Zi(当前token的偏置)去掉,得到所有token共享的全局隐藏状态:
H = ∑ j = 1 L 1 A j Z j H=\sum_{j=1}^{L} \frac{1}{A_{j}} Z_{j} H=j=1∑LAj1Zj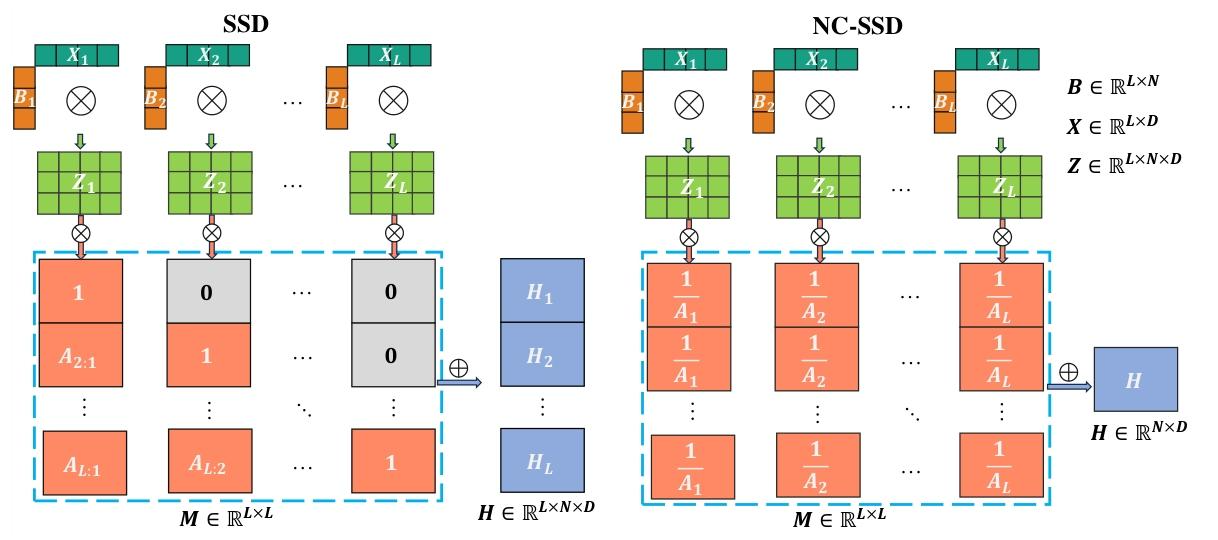
图2:SSD和NC-SSD的隐藏状态生成过程示意图。在隐藏状态更新过程中,NC-SSD利用标量A来确定当前标记的信息增量程度,而在SSD中,A决定了要保留的隐藏状态的比例。与生成逐标记隐藏状态的SSD不同,NC-SSD仅生成一个全局隐藏状态,以适应非因果图像数据。
输入特征向量 X X X->叉乘得到中间特征 Z Z Z->与引入的权重矩阵 M M M做矩阵乘法得到隐藏状态矩阵 H H H
M M M从下三角矩阵->每列权重相同,表示输入j的特征对所有输入i的贡献权重一致->非因果特性
本步骤的重要性
- 解决挑战1(因果性):H是所有token的加权和,每个token都能用到全局信息,没有前后限制;
- 解决挑战2(空间结构):H和token的位置无关,不管2D图怎么拉成1D,每个token的贡献都是 ( 1 / A j ) × Z j (1/A_j)×Z_j (1/Aj)×Zj,不会因为位置变了就丢信息;
- 速度快:不用一步一步迭代算H,而是一次性把所有token加起来,能并行计算(GPU提速的关键)。
4.2.5 NC-SSD的张量收缩与简化形式
4.2.5.1. 张量收缩形式
Z = contract ( L D , L N → L N D ) ( X , B ) H = contract ( L L , L D N → N D ) ( M , Z ) Y = contract ( L N , N D → L D ) ( C , H ) \begin{split} &Z=\text{contract}(LD,LN\to LND)(X,B)\\ &H=\text{contract}(LL,LDN\to ND)(M,Z)\\ &Y=\text{contract}(LN,ND \to LD)(C, H) \end{split} Z=contract(LD,LN→LND)(X,B)H=contract(LL,LDN→ND)(M,Z)Y=contract(LN,ND→LD)(C,H)
参数含义
- contract:张量收缩(高维矩阵的乘法);
- 三步流程:
1. Z Z Z = 输入X和参数B做收缩 → 把输入扩展成高维特征;
2. H H H = Z和权重矩阵M做收缩 → 生成全局隐藏状态;
3. Y Y Y = H和参数C做收缩 → 转换成最终输出; - 核心:全程并行计算,没有迭代,速度比传统SSM快很多。
4.2.5.2. 简化形式
Y = C ( B T ( X ⋅ m ) ) Y=C(B^{T}(X\cdot m)) Y=C(BT(X⋅m))
参数含义
- m m m:权重向量(从矩阵M降维来的, m j = 1 / A j m_j=1/A_j mj=1/Aj);
- X ⋅ m X·m X⋅m:输入X和权重m逐元素相乘 → 给每个输入token加权;
- B T B^T BT:参数B的转置 → 把加权后的输入映射到状态空间;
- C C C:把状态空间的结果映射成输出Y;
Y = C × B T × ( X × m ) Y = C × B^T × (X×m) Y=C×BT×(X×m) →普通的矩阵乘法,工程上好实现
4.3 Vision State Space Duality Model 视觉状态空间对偶性模型(VSSD)
前面的NC-SSD解决了SSM用在图像上的核心问题,接下来论文基于NC-SSD搭建了完整的VSSD模型,适配图像分类、检测、分割等任务。
4.3.1 VSSD Block 核心模块
NC-SSD是核心,但只靠它还不够,论文给它加了几个视觉模型常用的部件,组成VSSD Block:
| 组件 | 作用(通俗版) |
|---|---|
| 3×3深度可分离卷积(DWConv) | 替换NC-SSD里的1D卷积,专门捕捉图像的局部特征(比如猫的眼睛、鼻子这些小区域) |
| 前馈网络(FFN) | 对特征做升维+降维,让不同通道的特征交互(比如把颜色特征和形状特征结合) |
| 局部感知单元(LPU) | 强化模型对局部细节的捕捉能力(比如区分猫和狗的耳朵形状) |
| 残差连接 | 防止模型训练时梯度消失 |
VSSD Block
就像搭积木:NC-SSD(负责全局特征) + DWConv(负责局部特征) + FFN(融合特征) + 残差连接(稳定训练)→ 既看得懂全局(整张图),又看得清细节(局部)。
4.3.2 混合注意力机制:NC-SSD + 多头自注意力(MSA)
-
前3个阶段:用NC-SSD(速度快,全局特征);
-
最后1个阶段:换成MSA(自注意力擅长捕捉高层语义特征,比如区分猫和老虎)。
-
混搭:兼顾速度和性能(前3阶段快,最后阶段补性能)。
4.3.3 重叠下采样层
-
下采样的概念
图像从224×224→112×112→56×56,就是下采样(缩小尺寸,减少计算量)。 -
传统方法的问题
用非重叠卷积下采样(比如步长2,卷积核2×2),会丢失边缘信息(比如猫的爪子边缘)。 -
论文的改进
用重叠卷积下采样(比如步长2,卷积核3×3),卷积核之间有重叠,能保留更多空间结构信息。
非重叠卷积:用剪刀把图片剪成4块,每块单独缩小 → 边缘丢了;
重叠卷积:用放大镜先看一部分,再挪一点看另一部分,有重叠 → 边缘保留了。
4.3.4 VSSD整体架构
VSSD是分层结构,就像搭积木,一层一层处理图像:
- Stem层:先用重叠卷积做初始下采样和通道扩展,把输入变成小尺寸特征图;
- 阶段1-3:每个阶段用 N N N个VSSD Block(核心NC-SSD+DWConv+FFN),逐步提取低级特征→中级特征(比如从像素点→边缘→形状),然后通过Down层做2倍下采样;
- 阶段4:把VSSD Block里的NC-SSD换成多头自注意力MSA,提取高级特征(比如从形状→猫/狗);
- 输出层:把最后一层的特征图平均池化,接分类头/检测头/分割头,完成任务。
NC-SSD Block详细拆解
- 输入预处理:Layer Normalization(LN)
- 输入:来自上一层的视觉特征图(形状为 [ B , C , H , W ] [B, C, H, W] [B,C,H,W], B B B 为批次大小、 C C C 为通道数、 H / W H/W H/W 为空间分辨率)。
- 操作:对输入特征执行Layer Normalization(层归一化)。
- 作用:沿通道维度将特征分布归一化为均值0、方差1,消除不同通道/空间位置的数值波动,稳定训练过程,避免梯度消失或爆炸。
- 残差旁路:原始输入特征会被保留,用于后续残差连接。
- SSM参数生成
LN输出的特征被拆分为两条核心路径,分别生成NC-SSD所需的关键参数:
路径1:生成标量权重 A A A
- 流程: Linear → Conv → Sigmoid ( σ ) \text{Linear} \rightarrow \text{Conv} \rightarrow \text{Sigmoid}(\sigma) Linear→Conv→Sigmoid(σ)
- Linear层:对归一化特征做线性变换,适配后续卷积操作的维度要求;
- Conv层:使用1×1卷积提取局部空间信息,引入CNN的局部归纳偏置,适配图像的空间结构特性;
- Sigmoid激活:将输出压缩到 ( 0 , 1 ) (0,1) (0,1)区间,得到标量权重 A A A,对应公式中的 1 A i \frac{1}{A_i} Ai1,用于控制每个输入位置的信息贡献度。
路径2:并行生成 X / B / C / Z X/B/C/Z X/B/C/Z四个参数
该路径通过四个独立的Linear层并行生成NC-SSD的核心输入与投影参数:
- X X X:将图像特征展平为1D序列,作为NC-SSD的输入序列;
- B B B:输入映射矩阵,负责将输入 X X X映射到状态空间;
- C C C:状态到输出的映射矩阵,控制状态空间到观测空间的转换;
- Z Z Z:输出投影矩阵,用于将NC-SSD的结果映射回原始视觉特征维度。
- 核心计算:NC-SSD全局建模
将路径1生成的 A A A与路径2生成的 X / B / C X/B/C X/B/C输入NC-SSD核心:
- 基于简化后的SSM公式
h ( t ) = ∑ i = 1 t 1 A i B i X i h(t) = \sum_{i=1}^{t} \frac{1}{A_i} B_i X_i h(t)=i=1∑tAi1BiXi
对所有输入位置的特征进行全局加权求和; - 关键特性:
- 非因果性:每个位置的输出都能直接访问所有输入位置的信息,完美适配图像“无时间顺序”的特性;
- 线性复杂度:计算量为 O ( n ) O(n) O(n),远低于Transformer自注意力的 O ( n 2 ) O(n^2) O(n2),可高效处理高分辨率图像;
- 全局感受野:一步到位实现全局交互,无需像CNN那样逐层扩大感受野。
- 输出:得到中间状态 Y Y Y。
-
归一化与残差融合
NC-SSD输出 Y Y Y后,进入残差融合阶段:
LN归一化:对 Y Y Y执行Layer Normalization,稳定特征分布;
逐元素乘( ⊗ \otimes ⊗):将归一化后的 Y Y Y与路径2生成的 Z Z Z逐元素相乘,完成输出投影;
Linear层:对相乘结果做线性变换,确保维度与原始输入一致;
残差加( ⊕ \oplus ⊕):将变换后的结果与最开始的原始输入特征相加,构建残差连接,保证梯度能顺畅回传,避免深层网络梯度消失。 -
特征增强:FFN前馈网络
残差融合后的特征进入FFN(Feed Forward Network)模块做最终增强:
- 流程: LN → FFN → 残差加 \text{LN} \rightarrow \text{FFN} \rightarrow \text{残差加} LN→FFN→残差加
- LN归一化:再次对特征做归一化;
- FFN层:由Linear升维 → 激活函数 → Linear降维组成,对全局特征做非线性变换,提升模型的特征表达能力;
- 残差加:将FFN输出与输入再次相加,保留原始特征信息,进一步稳定训练。
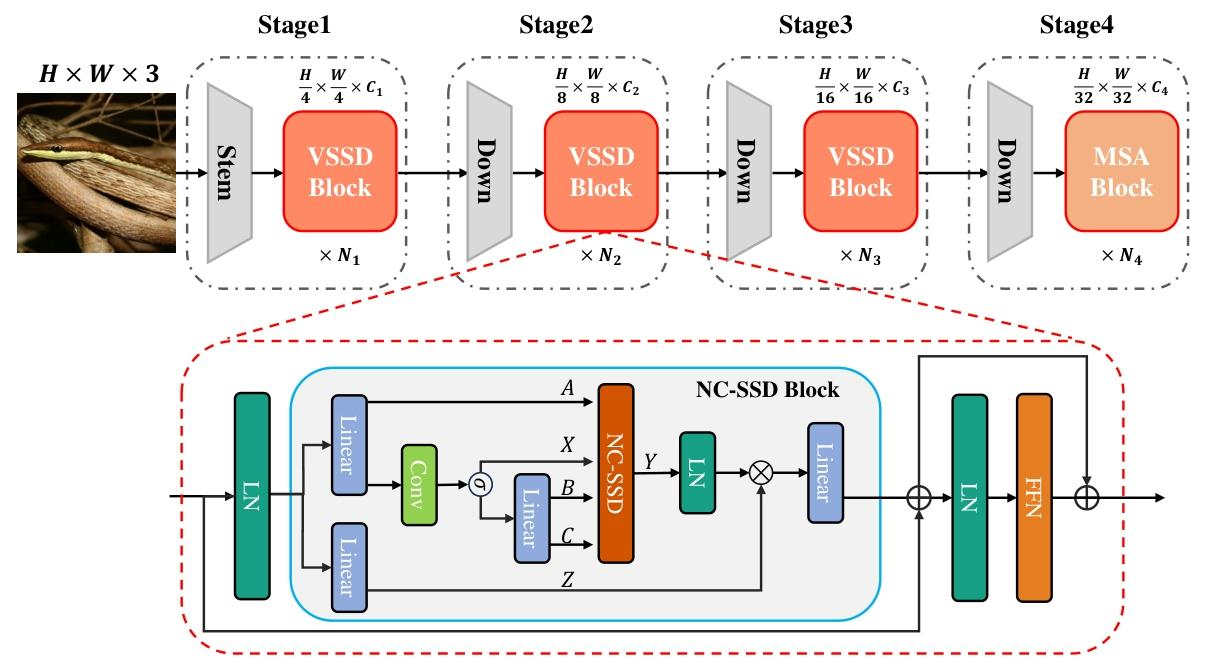
图4:所提出的VSSD模型的整体架构。VSSD模型以一系列重叠卷积作为主干开始,随后是四个渐进式处理阶段。前三个阶段配备了VSSD模块,该模块在图的下半部分详细说明,包括一个NC-SSD模块和一个FFN。为简洁起见,本可视化中省略了局部感知单元(LPU)。
模型变体
论文做了4种规格(Micro/Tiny/Small/Base)
- Micro/Tiny:参数量小,速度快,适合边缘设备(比如手机);
- Small/Base:参数量大,性能好,适合服务器。

表1:VSSD变体的模型规格。
Blocks:4个stage中堆叠的模块数量,数值越大,代表该stage特征提取深度越深,模型表达能力越强
channels:4个stage对应的输出通道数,保证高分辨率信息被充分编码
heads:多头注意力的头数
#Param:模型总参数量,单位百万,M
FLOPs:模型计算量,单位十亿,G
4.3.5 VSSD核心优势
- 解决了SSM的「因果性」问题,适配图像的非因果特性;
- 缓解了「2D→1D破坏空间结构」的问题,保留图像细节;
- 计算是线性复杂度(O(L)),比Transformer的平方复杂度(O(L²))快很多;
- 混搭了MSA和重叠卷积,性能比纯SSM模型好,接近Transformer。

图3:输入图像及其对应热图的可视化,这些热图是通过对NC-SSD中不同头的向量m取平均值得到的。
上行是 4 张自然图像输入,下行是对应生成的特征热图。
热图生成方式
热图通过对 NC-SSD 中不同注意力头(head)的特征向量 m \boldsymbol{m} m 逐元素取平均值得到,颜色从深蓝(低响应)到黄(高响应)渐变,直观反映模型对图像各区域的关注程度。
结果解读
- 高响应区域(黄色/亮青色):精准聚焦于图像中的目标主体(如鸟类躯干、动物头部),证明模型能有效识别并提取前景目标的关键特征;
- 低响应区域(深蓝色):对应背景区域(如地面、树枝),说明模型能有效抑制无关背景信息,避免干扰;
- 空间定位能力:热图与目标轮廓大致匹配,体现了 NC-SSD 在全局建模的同时,保留了良好的空间位置感知能力。
验证了 VSSD 模型的两大核心优势:
- 全局建模有效性:热图完整覆盖目标区域,证明 O ( n ) O(n) O(n) 复杂度的 NC-SSD 能高效捕捉全局语义信息;
- 非因果适配:热图不依赖时序顺序,完美适配图像这类非因果数据的建模需求。
5.实验分析
5.1 实验基础配置
5.1.1 数据集与评测指标
| 任务 | 数据集 | 核心评测指标 | 通俗说明 |
|---|---|---|---|
| 图像分类 | ImageNet-1K | Top-1 准确率(%) | 正确分类的图片占比,越高越好 |
| 目标检测/实例分割 | MS COCO | Box AP / Mask AP | AP 是“平均精度”,衡量检测/分割的准度,越高越好 |
| 语义分割 | ADE20K | mIoU(均值交并比) | 分割结果与真实标签的重叠程度,越高越好 |
视觉任务核心评测指标
1. 图像分类:Top-1 准确率(%)
公式:
Top-1 Acc = 预测标签与真实标签完全一致的样本数 总样本数 × 100 % \text{Top-1 Acc} = \frac{\text{预测标签与真实标签完全一致的样本数}}{\text{总样本数}} \times 100\% Top-1 Acc=总样本数预测标签与真实标签完全一致的样本数×100%
计算流程:
- 模型对每张图片输出所有类别的概率分布,取概率最大的类别作为预测标签;
- 统计预测标签与真实标签完全匹配的样本数量;
- 用正确样本数除以总样本数,得到百分比形式的 Top-1 准确率。
2. 目标检测/实例分割:Box AP / Mask AP
核心概念:
- Precision(精确率): T P T P + F P \frac{TP}{TP+FP} TP+FPTP,即预测为正的样本中真实为正的比例;
- Recall(召回率): T P T P + F N \frac{TP}{TP+FN} TP+FNTP,即所有真实正样本中被正确预测的比例;
- AP(Average Precision):Precision-Recall 曲线下的面积,衡量模型在全召回区间的综合精度。
Box AP 计算步骤:
- 对每个类别,将所有检测框按置信度从高到低排序;
- 逐步选取框,计算不同召回率下的精确率,绘制 PR 曲线;
- 用插值法计算 PR 曲线下的面积,得到该类别的 AP;
- 对所有类别取平均,得到 COCO 标准下的 Box AP(通常指 mAP@[0.5:0.95])。
Mask AP 计算步骤:
与 Box AP 流程一致,仅将检测框替换为分割掩码:
- 用掩码与真实标签的 IoU(交并比)判断是否为正样本;
- 最终衡量分割掩码的定位精度,数值越高代表分割越准确。
3. 语义分割:mIoU(均值交并比)
公式:
IoU i = 类别 i 的预测区域 ∩ 真实区域 类别 i 的预测区域 ∪ 真实区域 \text{IoU}_i = \frac{\text{类别}i\text{的预测区域} \cap \text{真实区域}}{\text{类别}i\text{的预测区域} \cup \text{真实区域}} IoUi=类别i的预测区域∪真实区域类别i的预测区域∩真实区域
mIoU = 1 K ∑ i = 1 K IoU i \text{mIoU} = \frac{1}{K} \sum_{i=1}^K \text{IoU}_i mIoU=K1i=1∑KIoUi
( K K K 为总类别数)
计算流程:
- 模型对每个像素预测类别,生成分割结果图;
- 对每个类别 i i i,计算预测区域与真实区域的交集除以并集,得到该类别的 IoU;
- 对所有类别取平均,得到 mIoU,数值越高代表分割结果与真实标签的重叠程度越高。
5.1.2 对比模型
实验对比了三类主流模型,保证公平性:
- CNN 类:ConvNeXt、EfficientNet(传统视觉模型标杆);
- Transformer 类:Swin Transformer、DeiT(注意力机制标杆);
- SSM/Mamba 类:VMamba、LocalVMamba、PMamba(当前最先进的序列模型,论文的主要对比对象)。
5.2 核心实验一:图像分类(ImageNet-1K)
5.2.1 实验目的
验证 VSSD 在基础视觉任务上的性能和效率,看它是否能超越现有模型。
5.2.2 实验结果

不同模型在ImageNet-1K上的准确率对比。†表示结果通过MESA(模型增强与可扩展训练策略)获得。LAttn是线性注意力(linear attention)的缩写。
5.2.3 结果分析
- 性能碾压同类型 SSM 模型:VSSD-S 参数量 40M(比 VMamba-S 少 4M),计算量 7.4G(比 VMamba-S 少 3.8G),但准确率高 0.6%,实现“更小、更快、更强”;
- 比肩甚至超越 CNN/Transformer:VSSD-S 准确率 84.1%,比 ConvNeXt-S(83.1%)、Swin-S(83.0%)都高,打破了“SSM 模型性能不如 Transformer”的固有印象;
- 扩展性好:大参数量的 VSSD-B + MESA 后准确率达 85.4%,接近当前 SOTA 水平,说明模型架构有潜力。
5.2.4 额外验证:有效感受野(ERF)分析
- ERF:模型能“看到”的图像范围(比如中心像素能影响多大区域的输出);

图5:VSSD、基于CNN的模型(ResNet和ConvNeXt)、基于注意力的模型(Swin和DeiT)以及基于SSM的VMamba之间的有效感受野(ERF)对比。与基于SSM的VMamba相比,我们的VSSD有效消除了令牌间距对信息贡献的影响。
这张图对比了各模型在训练前(Before Training)和训练后(After Training)的特征响应热力图。颜色越深代表特征响应/激活强度越高,反映了模型的信息传播与特征表达能力。
- 训练前:除 VMamba-T 呈现十字结构外,其他模型均为单点或微弱中心响应,代表随机初始化下的权重分布。
- 训练后:
- CNN/ViT 类:ResNet50、ConvNeXt-T、Swin-T 的特征响应均发生扩散,形成块状/网状有效区域,说明模型学习到了特征交互模式。
- DeiT-S:响应微弱,说明纯 ViT 小模型在该配置下特征表达能力有限。
- VMamba-T:保持十字结构不变,说明 SSM 的固有结构偏置极强,训练过程难以改变其核心传播模式,可训练性较弱。
- VSSD-T:特征响应大面积扩散,形成了最显著的高亮区域。这证明 VSSD 架构不仅被成功训练,且具备了比对比模型更广的感受野和更强的特征激活能力。
5.3 核心实验二:目标检测与实例分割(MS COCO)
5.3.1 实验目的
验证 VSSD 作为视觉骨干网络,在复杂下游任务中的迁移能力(分类是基础,检测/分割需要更强的特征表达)。
5.3.2 实验设置
用 Mask R-CNN 框架作为检测/分割头,VSSD 作为骨干网络提取特征,对比其他模型在相同框架下的表现(保证公平)。
5.3.3 实验结果

表3:在MS COCO数据集[33]上使用Mask R-CNN框架23进行目标检测和实例分割。FLOPs的测试输入尺寸为1280×800。
- 核心指标:
- A P b AP^b APb:边界框检测平均精度;
- A P 50 b / A P 75 b AP^b_{50}/AP^b_{75} AP50b/AP75b:IoU=0.5/0.75 时的检测 AP
- A P m AP^m APm:实例分割掩码平均精度;
- A P 50 m / A P 75 m AP^m_{50}/AP^m_{75} AP50m/AP75m:IoU=0.5/0.75 时的分割 AP
- 训练策略:
1x:标准 12 epoch 训练3x + MS:增强 36 epoch 训练 + 多尺度微调
1. Micro 规格(VSSD-M)
| 训练设置 | A P b AP^b APb | A P 50 b AP^b_{50} AP50b | A P 75 b AP^b_{75} AP75b | A P m AP^m APm | A P 50 m AP^m_{50} AP50m | A P 75 m AP^m_{75} AP75m | #Param | FLOPs |
|---|---|---|---|---|---|---|---|---|
| 1x | 45.4 | 67.5 | 49.8 | 41.3 | 64.5 | 44.6 | 33M | 220G |
| 3x + MS | 47.7 | 69.7 | 52.1 | 42.8 | 66.5 | 46.0 | 33M | 220G |
轻量组最优,全面超越同规模 PVT-T、EffVMamba-S 等模型。
2. Tiny 规格(VSSD-T)
| 训练设置 | A P b AP^b APb | A P 50 b AP^b_{50} AP50b | A P 75 b AP^b_{75} AP75b | A P m AP^m APm | A P 50 m AP^m_{50} AP50m | A P 75 m AP^m_{75} AP75m | #Param | FLOPs |
|---|---|---|---|---|---|---|---|---|
| 1x | 46.9 | 69.4 | 51.4 | 42.6 | 66.4 | 45.9 | 44M | 265G |
| 3x + MS | 48.8 | 70.4 | 53.4 | 43.6 | 67.6 | 46.9 | 44M | 265G |
小模型组最优,超越 Swin-T、ConvNeXt-T、VMamba-T 等主流模型。
3. Small 规格(VSSD-S)
| 训练设置 | A P b AP^b APb | A P 50 b AP^b_{50} AP50b | A P 75 b AP^b_{75} AP75b | A P m AP^m APm | A P 50 m AP^m_{50} AP50m | A P 75 m AP^m_{75} AP75m | #Param | FLOPs |
|---|---|---|---|---|---|---|---|---|
| 1x | 48.4 | 70.1 | 53.1 | 43.5 | 67.2 | 47.1 | 59M | 325G |
中等模型组领先, A P 50 b AP^b_{50} AP50b 达 70.1,为组内最高。
5.3.4 结果分析
- 下游任务迁移能力强:VSSD 作为骨干网络,在检测/分割任务中依然保持优势,说明它提取的特征具有强表达力;
- 效率优势更明显:复杂任务中,VSSD 的计算量优势被放大(比如 VSSD-S 比 VMamba-S 少 75G FLOPs),但性能还更高,适合实际部署;
- 碾压传统骨干:VSSD-T 比 Swin-T 的 Box AP 高 4.2,Mask AP 高 3.3,差距非常显著,证明 SSM 经过优化后完全可以替代 Transformer/CNN 作为复杂任务骨干。
5.4 核心实验三:语义分割(ADE20K)
5.4.1 实验目的
进一步验证 VSSD 在像素级精细任务中的表现(分割需要捕捉局部细节和全局上下文,对模型要求更高)。
5.4.2 实验结果

表4:使用UperNet框架在ADE20K数据集上的语义分割结果。所有模型的FLOPs均使用512×2048的输入维度计算。表中,“SS”代表单尺度测试,“MS”代表多尺度测试。
- mIoU SS:单尺度(一个图只变一张尺寸)测试下的均值交并比
- mIoU MS:多尺度(一个图变多个尺寸)测试下的均值交并比;
1. Micro 规格(VSSD-M)
| 模型 | mIoU SS | mIoU MS | #Param | FLOPs |
|---|---|---|---|---|
| EffVMamba-S | 41.5 | 42.1 | 29M | 505G |
| MSVMamba-M | 45.1 | 45.4 | 42M | 875G |
| VSSD-M | 45.6 | 46.0 | 42M | 893G |
轻量组最优,mIoU 超越同规模所有对比模型。
2. Tiny 规格(VSSD-T)
| 模型 | mIoU SS | mIoU MS | #Param | FLOPs |
|---|---|---|---|---|
| Swin-T | 44.4 | 45.8 | 60M | 945G |
| ConvNeXt-T | 46.0 | 46.7 | 60M | 939G |
| VMamba-T | 47.3 | 48.3 | 55M | 964G |
| LocalVMamba-T | 47.9 | 49.1 | 57M | 970G |
| VSSD-T | 47.9 | 48.7 | 53M | 941G |
小模型组最优,以更少参数量取得最高 mIoU MS(48.7),全面领先主流 Conv/Attention/SSM 模型。
5.5 消融实验:验证核心模块的有效性
5.5.1 核心模块验证

表5:VSSD-Micro在ImageNet-1K上的消融研究。我们的NC-SSD在准确性和效率方面始终优于普通SSD和Bi-SSD。其他技术进一步提升了性能。
架构配置类指标
- Op. Type:操作类型,用于区分 SSD 架构变体(如基础 SSD、Bi-SSD、NC-SSD、Hybrid 混合架构)。
- Downsampler:下采样器,指特征图分辨率降低的实现方式,
Patch代表分块下采样(转为序列),Conv代表卷积下采样(保留局部信息)。 - Layers:4 个 Stage 的模块堆叠数量,越大代表特征提取深度越深。
性能效率类指标
Thru.:推理吞吐量(单位:imgs/sec),指模型每秒能处理的图片数量,数值越高代表推理速度越快、实时性越强。
Train Thru.:训练吞吐量(单位:imgs/sec),指模型训练阶段每秒能处理的图片数量,数值越高代表训练效率越高。
-
SSD (Baseline)
作为基准模型,参数量 14.8M,FLOPs 2.1G,推理速度最快,但 Top-1 Acc 仅 81.0%,为基础性能下限。 -
Bi-SSD
在参数量(15.2M)与计算量(2.2G)微增的情况下,准确率提升至 81.4%,验证了双向结构设计的有效性。 -
NC-SSD(核心改进)
实现了零成本涨点:参数量与 FLOPs 与 SSD 完全一致(14.8M / 2.1G),但准确率提升至 81.6%,且推理速度(1843 imgs/sec)更快。证明非因果状态空间建模能有效增强特征表达。 -
Hybrid 架构(最优解)
- Patch Downsampler:以 13.4M 的最小参数量,取得 81.8% 的最高基础准确率,实现了“小模型高性能”。
- Conv Downsampler:结合卷积下采样,准确率大幅提升至 82.5%,同时参数量仅 13.5M。证明 Hybrid 混合架构能结合 CNN 局部性与 SSD 全局性,突破性能瓶颈。
VSSD 系列架构在极小参数量(~14M) 与 低计算量(~2.1G) 下,取得了远超传统 SSD 与主流 SSM 模型的分类精度(最高 82.5%),验证了 NC-SSD 核心模块与 Hybrid 混合架构设计的优越性
5.5.2 权重向量 m 的必要性验证

该实验验证了 NC-SSD 模块中参数 m 对模型性能与可训练性的影响。
-
m:核心消融变量,✗表示不使用该设计,✓表示使用; -
†:表示遇到 N.A. 之前能达到的最佳准确率; -
N.A.:Not Available,模型训练不收敛,无有效结果。 -
实验结果:
- 去掉 m:Tiny 模型准确率仅 32.6%,Small 模型直接训练崩溃
- 保留 m:Tiny 模型准确率 81.8%,训练稳定;
-
结论:m 不仅能让模型关注重要特征,还能稳定训练,是不可或缺的模块。
5.6 实验总结
- 性能:VSSD 在分类、检测、分割三大任务中,均超越当前 SOTA SSM 模型(VMamba 等),部分任务超越 CNN/Transformer;
- 效率:相同性能下,VSSD 参数量更少、计算量更低,训练速度比 Bi-SSD 快 50%;
- 设计:NC-SSD 解决了 SSM 的因果性和空间结构问题,混合 MSA 和重叠下采样进一步提升性能,每个模块都经得住验证。
VSSD 既继承了 SSM 线性计算的高效性,又通过非因果设计和视觉适配,解决了它在图像任务中的核心痛点,最终实现“又快又准”,是当前 SSM 类视觉模型的最优解之一。
5.7 模型局限性
- 下游任务增量收益有限:相比其他 SSM 模型,VSSD 在检测/分割任务上的提升幅度(0.4-0.6 个点)比分类任务小;
- 缺乏大规模数据验证:没有在 ImageNet-22K 等更大数据集上测试,模型 scalability 有待验证;
- 对比 SOTA Transformer 有差距:和当前最顶尖的 Transformer 变体(如 TransNeXt)相比,下游任务性能还有提升空间。
6.个人声明
本文为作者对原论文的学习笔记与心得分享,受个人学识与理解所限,文中对论文内容的解读或有不够周全之处,一切以原论文正式表述为主。本文仅用于学术交流与传播,内容均为作者独立整理完成,不代表本博客或公众号立场,如文中所涉文字、图片等内容存在版权争议,请及时与作者联系,作者将在第一时间核实并妥善处理。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)