同是顶尖LLM,Qwen3.5凭什么比GPT-5.3快19倍、成本省一半?
阿里巴巴刚刚发布了其最新一代大语言模型——Qwen3.5。 这款模型的推出,正是为了应对GPT-5.3 Codex、Claude Opus 4.6等近期表现亮眼的新品。
阿里巴巴表示,Qwen3.5是为智能体AI时代(Agentic AI Era)量身打造的模型。这款多模态视觉语言模型相比前代成本更低、效率更高,在多项基准测试中交出了顶尖水准的成绩。
与此同时,阿里巴巴还推出了Qwen3.5-Plus,作为该模型的高阶版本,上下文窗口达到100万token,直接对标Gemini 3。
本文将带你详细了解Qwen3.5与Qwen3.5-Plus的核心新特性,对比它们与竞品的差距,展示最新的测试数据,并说明如何使用这些新模型。
什么是Qwen3.5?
Qwen3.5是阿里巴巴Qwen大模型系列的最新一代产品,型号为Qwen3.5-397B-A17B。 与上一代Qwen3系列不同,Qwen3.5将多个专用模型整合为单一原生视觉语言模型。和此前的Qwen模型一样,它采用Apache 2.0开源协议。
该模型定位为面向消费端与企业级场景的通用基座模型,专为原生多模态与智能体工作流设计。 Qwen3.5-397B-A17B提供两种运行模式:
- • Thinking(思考模式):适用于需要深度推理的任务
- • Fast(快速模式):适用于常规任务的快速推理
Qwen3.5 与 Qwen3.5-Plus 对比
Qwen3.5-Plus是基于Qwen3.5-397B-A17B的云端托管服务,仅提供API调用,本身并非开源权重模型。 官方发布说明在这一点上容易让人混淆:文中提到的Qwen3.5-Plus看似是独立模型,实际上是阿里巴巴基于同款基座打造的专属服务。
尽管Qwen3.5-Plus基于Qwen3.5-397B-A17B,但两者存在明显区别:
- • Qwen3.5-Plus仅可通过阿里云Model Studio调用,按token计费,同时也可通过Qwen Chat界面有限度使用
- • 标准版Qwen3.5上下文窗口为256K token,而Qwen3.5-Plus扩展至100万token
- • 除Thinking与Fast模式外,Qwen3.5-Plus额外提供Auto(自动模式),支持自适应思考,并可调用搜索、代码解释器等工具
Qwen3.5 核心特性
下面我们来看Qwen3.5带来的几项关键新特性:
原生多模态能力
与OpenAI在最新GPT-5.3 Codex中将标准模型与Codex模型合并类似,阿里巴巴将文本、视觉、UI交互能力整合进单一模型。
Qwen3.5在文本、图像、UI截图与结构化内容上进行联合训练,支持:
- • 视觉问答
- • 文档理解
- • 图表/表格解析
- • 像素级定位,识别并交互屏幕元素
视觉智能体能力
这是Qwen3.5的另一大核心亮点。 得益于在大量UI截图上的训练,模型能够识别并操作移动端与桌面端界面,可执行多步骤自动化工作流,例如:
- • 填写表单
- • 操作应用
- • 修改系统设置
- • 整理文件
这让Qwen3.5非常适合生产力自动化场景。 你只需通过自然语言指令,就能让Qwen视觉智能体跨多个应用完成复杂流程,甚至能在长交互序列中保持状态,实现稳定的工具与应用调度。
性能与效率大幅提升
Qwen3.5是一个参数量庞大的模型,总参数3970亿,但得益于混合专家架构(MoE),每个token仅激活170亿参数。 简单来说,它拥有超大模型的智能水平,却只有小模型的速度与成本效率。
实际表现上:
- • 相比Qwen3-Max,Qwen3.5 397B-A17B在长上下文任务(256k token)解码速度提升19倍
- • 标准工作流速度提升8.6倍
更重要的是,速度提升没有牺牲智能水平: 它的推理与代码能力与Qwen3-Max持平,同时因文本与视觉早期融合,效果优于Qwen3-VL。
成本效率优化
伴随性能提升,模型的使用成本也进一步下降。
Qwen3.5采用原生FP8精度计算(替代标准的16位),运行所需内存直接减少50%,计算速度更快,在万亿token规模下速度提升超10%。
同时,模型拥有25万词表,能用更少token表达复杂概念;配合多token预测能力,可一步“预判”多个后续词汇,在201种语言中降低10%–60%的token成本。
Qwen3.5 是如何研发的
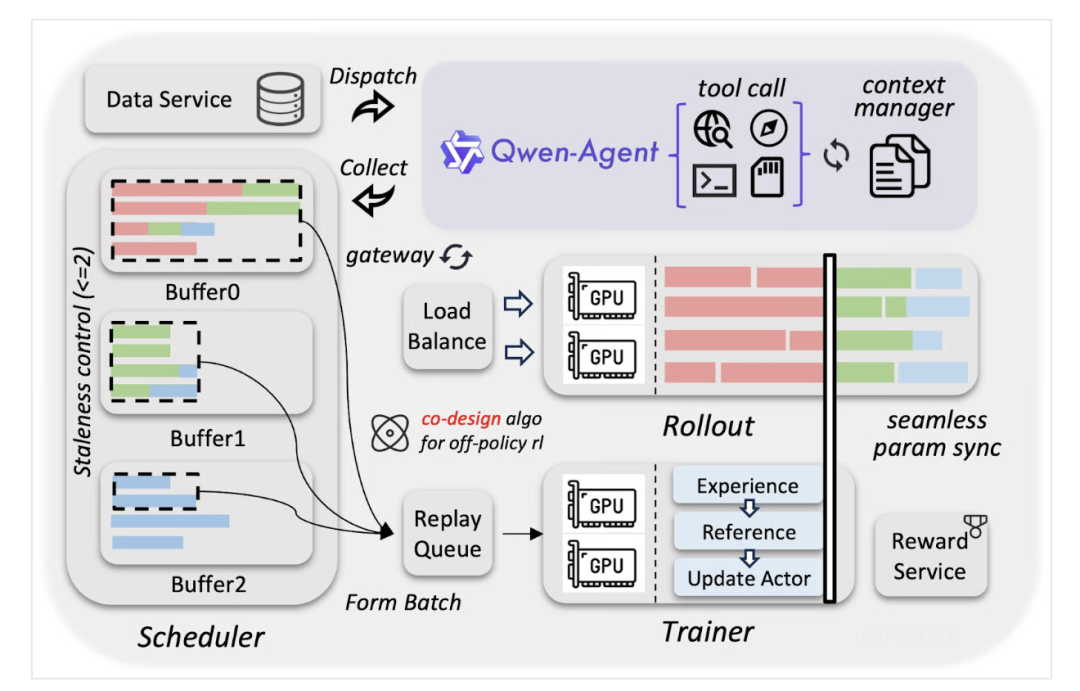
Qwen3.5的研发采用了定制化基础设施,让多模态与智能体模型的训练速度、成本几乎接近纯文本模型。 其训练方案的核心在于三大关键点:
-
- 数据质量
-
- 异构基础设施
-
- 异步强化学习(RL)
数据质量
阿里巴巴团队收集的图文数据远超Qwen3系列,并进行了严格筛选,保证输入质量。 最终的高质量数据集,让3970亿参数的模型能够对标万亿参数模型(如Qwen3-Max)的智能水平。
异构基础设施
视觉模块与语言模块分开训练、同步进行,双方无需等待彼此计算,训练效率几乎达到纯文本模型的100%。
异步强化学习
结合FP8压缩与推测解码(Speculative Decoding),智能体可同时执行数千项任务,训练在后台异步完成,无需等待。 这让训练速度大幅提升且质量损失极小,Qwen3.5学习UI点击、多步骤任务等Agent Skills的速度提升3–5倍。
下图为Qwen3.5训练基础设施架构。
Qwen3.5 基准测试
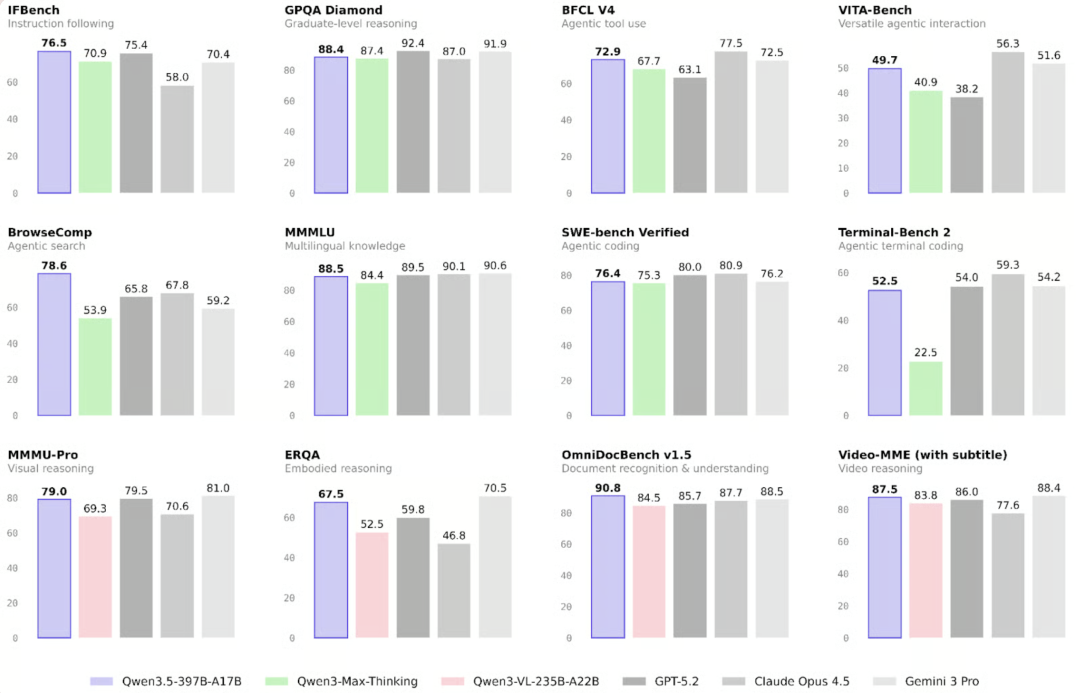
阿里巴巴这款新模型的性能已在多项任务中得到验证。 我们重点关注智能体工作流、多模态能力、通用推理三大方向的结果,并与Qwen3-Max-Thinking、Qwen3-VL-235B-A22B、GPT-5.2、Claude Opus 4.5、Gemini 3 Pro进行对比。
智能体工作流
相比Qwen3系列,Qwen3.5提升最明显的就是智能体工作流能力。
- • 智能体终端代码:在Terminal-Bench 2.0中,Qwen3.5得分52.5,远高于Qwen3-Max-Thinking的22.5,与Gemini 3 Pro(54.2)接近,但仍落后于当前领先的GPT-5.3 Codex(77.3)
- • 智能体搜索:这是Qwen3.5的最大优势,在BrowseComp中得分78.6,大幅超越Gemini 3 Pro(59.2),仅次于Claude Opus 4.6(84.0),位列第二
多模态能力
多模态能力相比前代同样有显著提升,尤其在具身推理与文档识别上:
- • 具身推理:ERQA得分67.5,远高于Qwen3-VL(52.5),几乎追平Gemini 3 Pro(70.5)
- • 文档识别:在OmniDocBench v1.5中突破90%大关,达到90.8,超过GPT-5.2(85.7)、Claude Opus 4.5(87.7)、Gemini 3 Pro(88.5)
- • 视觉推理:MMMU-Pro得分79.0,Video-MME得分87.5,仅略低于Gemini 3 Pro的81.0与88.4
推理、知识与可靠性
推理与知识并非本次升级的核心重点,但仍有小幅提升,尤其在可靠性方面:
- • 指令遵循:IFBench得分76.5,可靠性表现优秀,当前领先者为AWS Nova 2.0 Pro(79.0)
- • 研究生级别推理:GPQA Diamond得分88.4,相比Qwen3-Max-Thinking(87.4)小幅提升
- • 多语言知识:MMMLU得分88.5,低于Gemini 3 Pro(90.6),但相比前代(84.4)提升明显
如何使用Qwen3.5
与前代模型一致,Qwen3.5系列支持多种使用方式:聊天界面直接使用、API调用、本地部署下载、集成到自定义系统中。
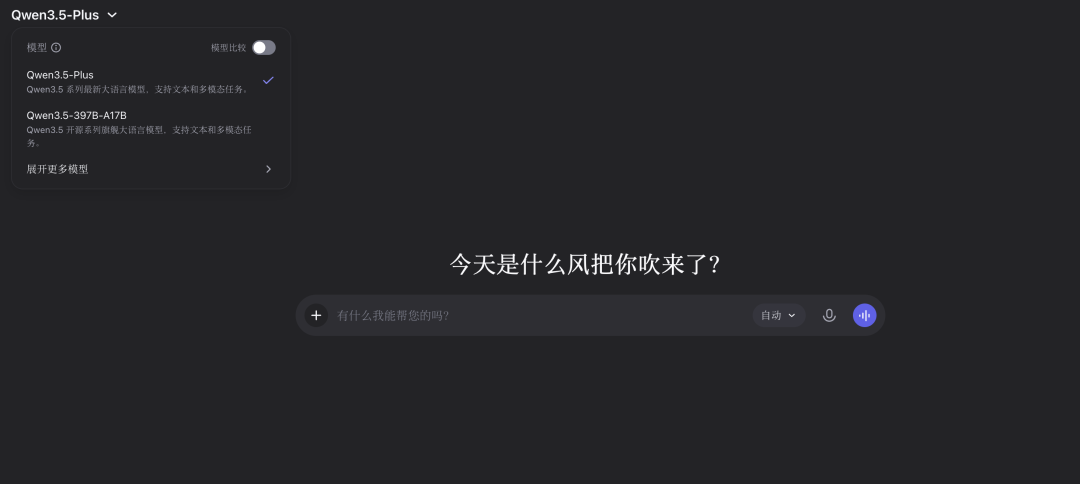
聊天界面
你可以直接访问 chat.qwen.ai 使用Qwen3.5。 模型选择下拉菜单中提供Qwen3.5-397B-A17B、Qwen3.5-Plus,以及Qwen3系列、Qwen2.5-Max等历史版本。
API调用
Qwen3.5的API调用方式与Qwen3基本一致: 通过ModelScope(免费额度,每日限额)或DashScope/Model Studio(付费,包含Qwen3.5-Plus)提供兼容OpenAI的接口。 只需将模型ID更新为:
- •
qwen3.5-397b-a17b - •
qwen3.5-plus
即可正常调用。
开源权重与本地部署
如前所述,Qwen3.5-397B-A17B模型权重已开源,采用Apache 2.0协议。 你可以通过Ollama、LM Studio、vLLM等工具本地运行。
权重下载渠道:
- • Hugging Face
- • GitHub
- • ModelScope
写在最后
凭借全新的视觉智能体、更强的性能与成本优化,Qwen3.5的发布堪称亮眼,不仅对国内其他模型形成压力,也直接挑战OpenAI、Anthropic等海外产品。
与今年其他新品(如GPT-5.3-Codex、Claude Opus 4.6)一样,行业重心正在明显向智能体AI转移。OpenClaw的快速走红证明,用户对AI的实用化落地需求强烈。 而Qwen3.5、Seedance 2.0,以及传闻中即将发布的DeepSeek等模型,也显示出中国正在快速成为AI模型领域的领跑者。
这里给大家精心整理了一份全面的AI大模型学习资源,包括:AI大模型全套学习路线图(从入门到实战)、精品AI大模型学习书籍手册、视频教程、实战学习、面试题等,资料免费分享!
👇👇扫码免费领取全部内容👇👇

1. 成长路线图&学习规划
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
这里,我们为新手和想要进一步提升的专业人士准备了一份详细的学习成长路线图和规划。可以说是最科学最系统的学习成长路线。
2. 大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

3. 大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。

4. 2026行业报告
行业分析主要包括对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。

5. 大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。

6. 大模型面试题
面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

7. 资料领取:全套内容免费抱走,学 AI 不用再找第二份
不管你是 0 基础想入门 AI 大模型,还是有基础想冲刺大厂、了解行业趋势,这份资料都能满足你!
现在只需按照提示操作,就能免费领取:
👇👇扫码免费领取全部内容👇👇

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 9
9 0
0- 0



 已为社区贡献65条内容
已为社区贡献65条内容

所有评论(0)