从混淆矩阵理解分类指标-以医学影像为例
在医学人工智能研究中,我们经常会遇到分类模型的评估问题。最常见的工具就是 混淆矩阵 及其衍生的性能指标。然而,很多初学者在解读这些指标时容易产生误区。本文将结合实际案例,系统梳理混淆矩阵中的关键指标,并解释它们在医学影像中的意义。
混淆矩阵基础
混淆矩阵的基本形式如下(以二分类为例):
| 预测为正类 | 预测为负类 | |
|---|---|---|
| 真实为正类 | TP | FN |
| 真实为负类 | FP | TN |
- TP (True Positive):真实为正,预测为正
- FN (False Negative):真实为正,预测为负(漏诊)
- FP (False Positive):真实为负,预测为正(误诊)
- TN (True Negative):真实为负,预测为负
常见指标及公式
基于混淆矩阵,可以推导出多个性能指标:
-
Accuracy(准确率)
Accuracy=TP+TNTP+TN+FP+FN Accuracy = \frac{TP + TN}{TP + TN + FP + FN} Accuracy=TP+TN+FP+FNTP+TN
衡量总体预测正确的比例。类别均衡时有参考价值,但在医学场景中若类别不平衡,容易被高估。 -
Precision(精确率,阳性预测值)
Precision=TPTP+FP Precision = \frac{TP}{TP + FP} Precision=TP+FPTP
在所有预测为正类的样本中,真正为正的比例。对应“预测结果的可信度”。 -
Recall(召回率,敏感性 Sensitivity)
Sensitivity=Recall=TPTP+FN Sensitivity = Recall = \frac{TP}{TP + FN} Sensitivity=Recall=TP+FNTP在所有真实正类样本中,能被正确预测出来的比例。医学里常称“敏感性”,对应“漏诊率”的反面。
-
Specificity(特异性)
Specificity=TNTN+FP Specificity = \frac{TN}{TN + FP} Specificity=TN+FPTN
在所有真实负类样本中,能被正确识别为负的比例。对应“误诊率”的反面。 -
F1-score
F1=2×(Precision×Recall)(Precision+Recall) F1 = \frac{2 × (Precision × Recall)}{(Precision + Recall)} F1=(Precision+Recall)2×(Precision×Recall)
Precision 与 Recall 的调和平均数,在样本不均衡时尤其有参考价值。

常见分类指标对照表: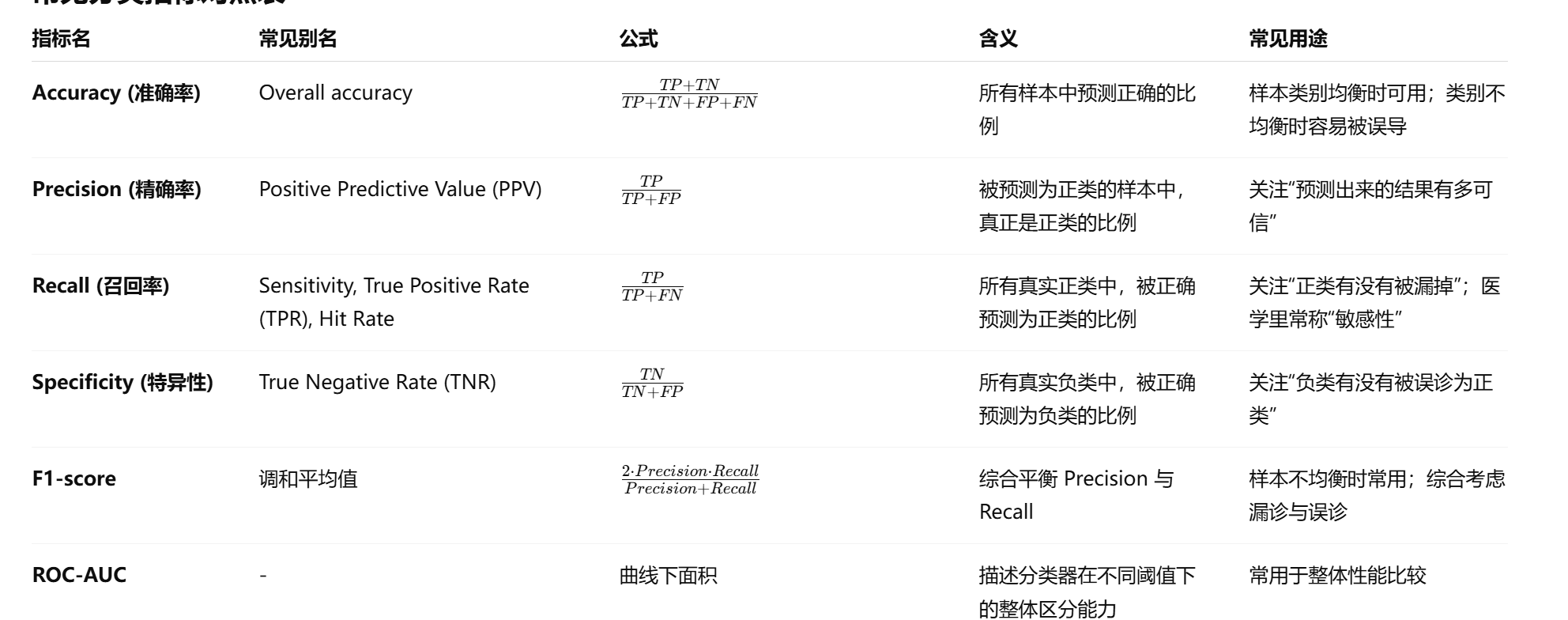
案例分析:四分类腹部 CT 疾病诊断
我们在一个腹部 CT 数据集上训练了疾病分类模型,类别包括:
- 肝癌 (HCC)
- 肝囊肿 (Liver cyst)
- 胰腺癌 (Pancreatic cancer)
- 健康/无明显病变 (Normal)
模型在测试集上的混淆矩阵如下:
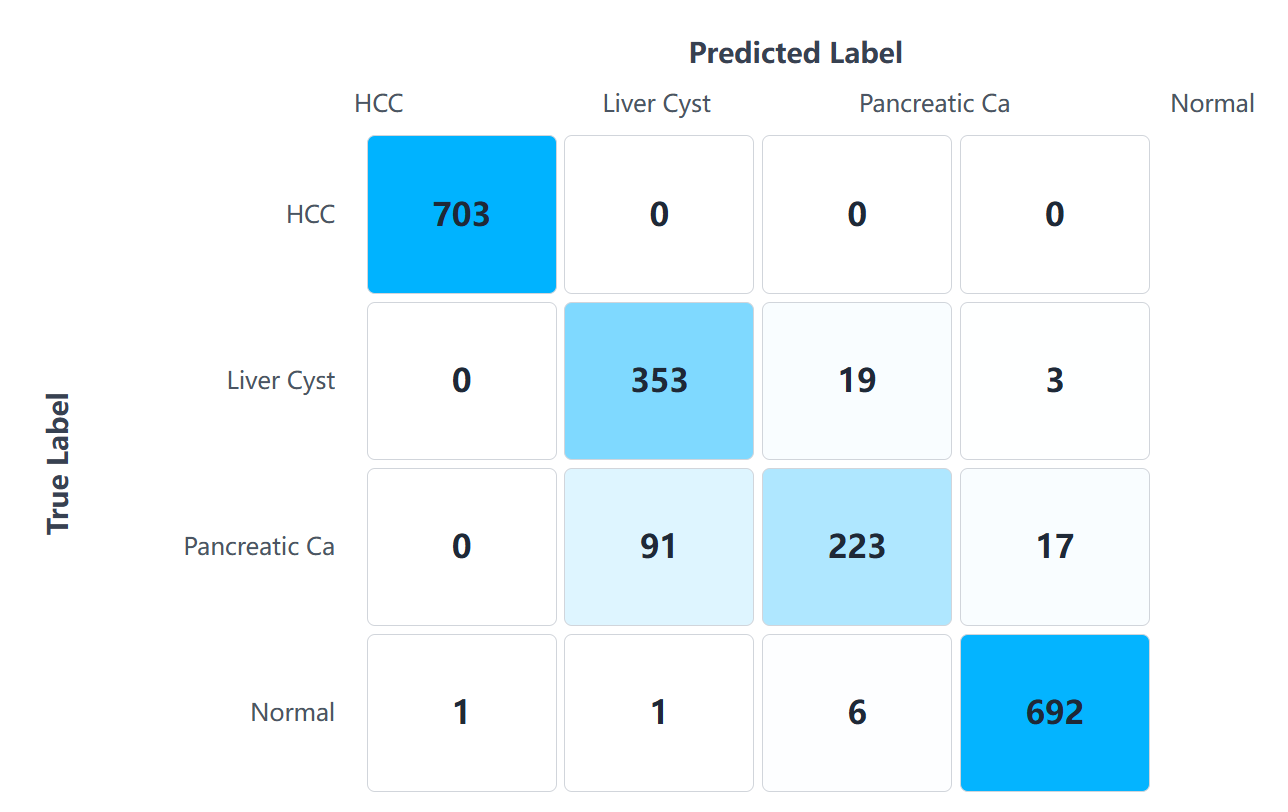
针对 胰腺癌 类别:
- TP = 223
- FN = 108
- FP = 25
- TN = 1753
- 总样本数 = 2109
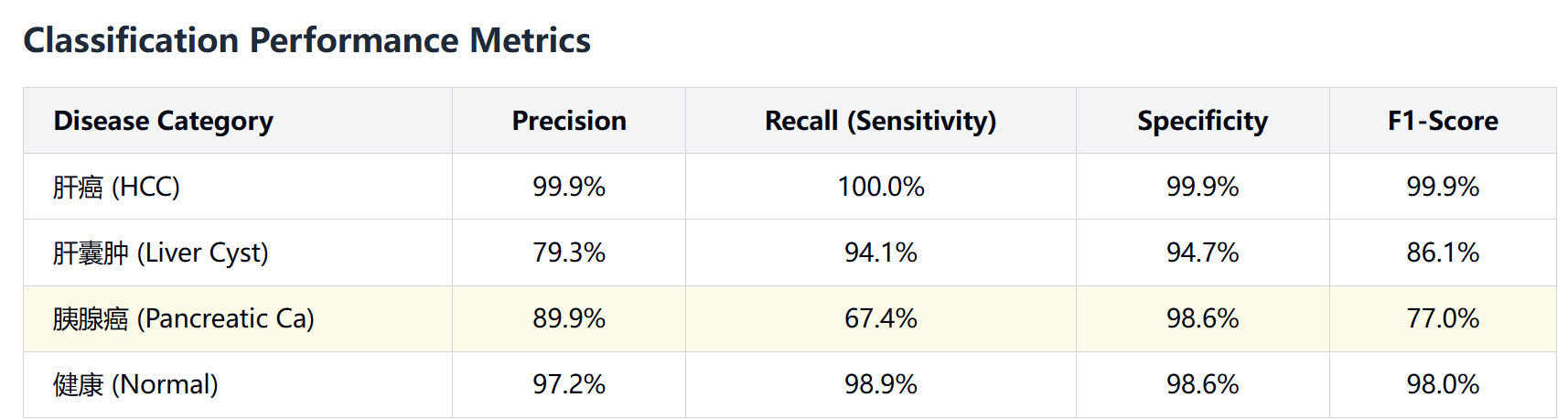
计算指标:
- Accuracy = (223 + 1753) / 2109 ≈ 0.937
- Precision = 223 / (223 + 25) ≈ 0.899
- Recall (Sensitivity) = 223 / (223 + 108) ≈ 0.673
- Specificity = 1753 / (1753 + 25) ≈ 0.986
- F1-score ≈ 0.770
结果解读
-
为什么 Accuracy 高达 0.937?
因为大多数样本不属于胰腺癌,TN 数量巨大,从而抬高了总体正确率。 -
真正反映模型检测胰腺癌能力的指标是 Recall ≈ 0.67,说明约三分之一的胰腺癌病例被漏诊。
-
Precision 较高(0.90),说明模型预测为胰腺癌的病例大多确实属于胰腺癌,但 Recall 较低,意味着仍有不少漏诊病例。
混淆矩阵可视化建议
- 行归一化混淆矩阵:对每一行(真实标签)做归一化,直接展示每类样本的 Recall。
- 同时报告 Precision/Recall/F1:避免只用 Accuracy 掩盖模型在少数类上的不足。
- 结合医学背景解读:如对“漏诊”高度敏感的任务,更应关注 Recall/Sensitivity;而对“避免误诊”要求更高的任务,则需关注 Specificity。
总结
- 敏感性 (Sensitivity) = 召回率 (Recall),描述模型检出正类的能力。
- 特异性 (Specificity),描述模型避免误诊的能力。
- Accuracy 往往容易被 TN 拉高,不应单独作为评价依据。
- 在医学应用中,Precision、Recall、F1、Specificity 都是不可或缺的指标。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 6
6 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)