【AI + DICOM无损压缩】基于Google NotebookLM,深入浅出了解DICOM JPEGLossless压缩算法
本文由Markdown语法编辑器编辑完成。
1.背景:
在上一篇博文<【DICOM Transfer Syntax UID】DICOM传输中一个非常重要却易被忽略的TAG>https://blog.csdn.net/inter_peng/article/details/158853403?spm=1001.2014.3001.5501
中,提到了在DICOM传输过程中,一个非常重要的概念——传输语法(Transfer Syntax UID)。
而Transfer Syntax UID, 主要会定义两个内容,byte ordering 和 compress,也就是:字节序和压缩算法。
这一篇,我们借助Google的一个AI工具,来学习DICOM中比较常见的一种无损压缩算法(JPEG Lossless)。
2.学习过程:
2.1 找权威论文
要学习图像的压缩算法,首先需要找到这个算法的来源,比如论文,专利等等。
因此,我首先在chatgpt里面询问,如果我想要了解JPEG Lossless无损压缩,需要看哪几篇论文。

| 序号 | 论文/文档 | 作者 | 备注 |
|---|---|---|---|
| 1 | The LOCO-I Lossless Image Compression Algorithm: Principles and Standardization into JPEG-LS | 作者: Marcelo J. Weinberger, Gadiel Seroussi, Guillermo Sapiro 发表: IEEE Transactions on Image Processing, 2000 |
这篇论文是 JPEG-LS 最被引用的权威论文,完整讲解了 JPEG-LS 的基础算法 LOCO-I(LOw COmplexity LOssless COmpression for Images) 1. 如何对像素进行预测; 2.残差(预测误差)的统计建模; 3.上下文相关编码(Context-based coding); 4.使用可自适应的 Golomb / Rice 编码进行熵编码, 它同时解释了算法如何从概率建模逼近最优压缩,并且作为 ISO/ITU 标准的核心技术。 该论文通常作为学习 JPEG-LS 算法原理的首选材料。 |
| 2 | Information technology – Lossless and near-lossless compression of continuous-tone still images | ISO/IEC 14495-1: JPEG-LS 标准文档 | 1. 详细规定了 JPEG-LS 在无损与近无损模式下的所有编码细节 2.定义了预测器、上下文建模规则与压缩参数格式 3.说明了编码后的位流结构 4. 该标准是 DICOM 中 JPEG-LS 压缩必须遵从的技术规范。 |
| 3 | From LOCO-I to the JPEG-LS Standard (ICIP’99) | 作者: 同 Weinberger 等 会议: IEEE ICIP 1999 |
作为早期科研报告,简要介绍 JPEG-LS 规范如何从最初的 LOCO-I 发展而来,包括上下文预测、码本选择、Golomb 编码策略等原理 |
以下是 chatgpt给出的关于三篇文献的推荐指数。
2.2 Google scholar (Google学术)
使用chatgpt, 找到了与DICOM JPEGLossless算法的三篇文章。为了确认这几篇文献的含金量,我依次把这三篇文章的题目,输入进了Google scholar的搜索框中。Google scholar是专门用来搜学术报告的网站,在每一篇文章下面,还会显示该篇文章被引用的次数。
如果一篇文章被引用的次数越多,那么说明它在本领域内的地位就越高。类似于Google搜索结果,使用的Page Rank的算法。

当我把第一篇论文的题目输入进去后,便出现了文章的摘要。更我我惊讶的是,这篇论文被引用的次数,达到了 2471次。那说明这篇论文的含金量非常高。

2.3 Google NotebookLM
紧接着出场的,是本篇文章的主角 —— Google NotebookLM (https://notebooklm.google/)。
官网给它的定位是: Your AI-Powered Research Partner. 你的AI加持(赋能)科研搭档。
读过研究生或博士的,都了解做科研,要经常阅读论文,写摘要,时刻关注相关领域内的科研进展,而且要求创新。而且一般导师下面的每个学生,研究的方向也不会完全相同。因此,更多的是要读国外的论文,寻找灵感和思路。做科研,是一条略显孤独的路。
而现在有了AI后,它就能时刻陪伴你了。
那么如果想快速了解以上几篇论文的内容要点,我们便可以使用 NotebookLM了。
进入笔记本后,既可以直接把论文的题目,贴在对话框里面,然后笔记本会自动联网搜索与输入框内相关的文献;也可以直接本地上传相关的论文文献。
上传完成后,它便会把所有相关的文献内容,都加载到它的知识库里。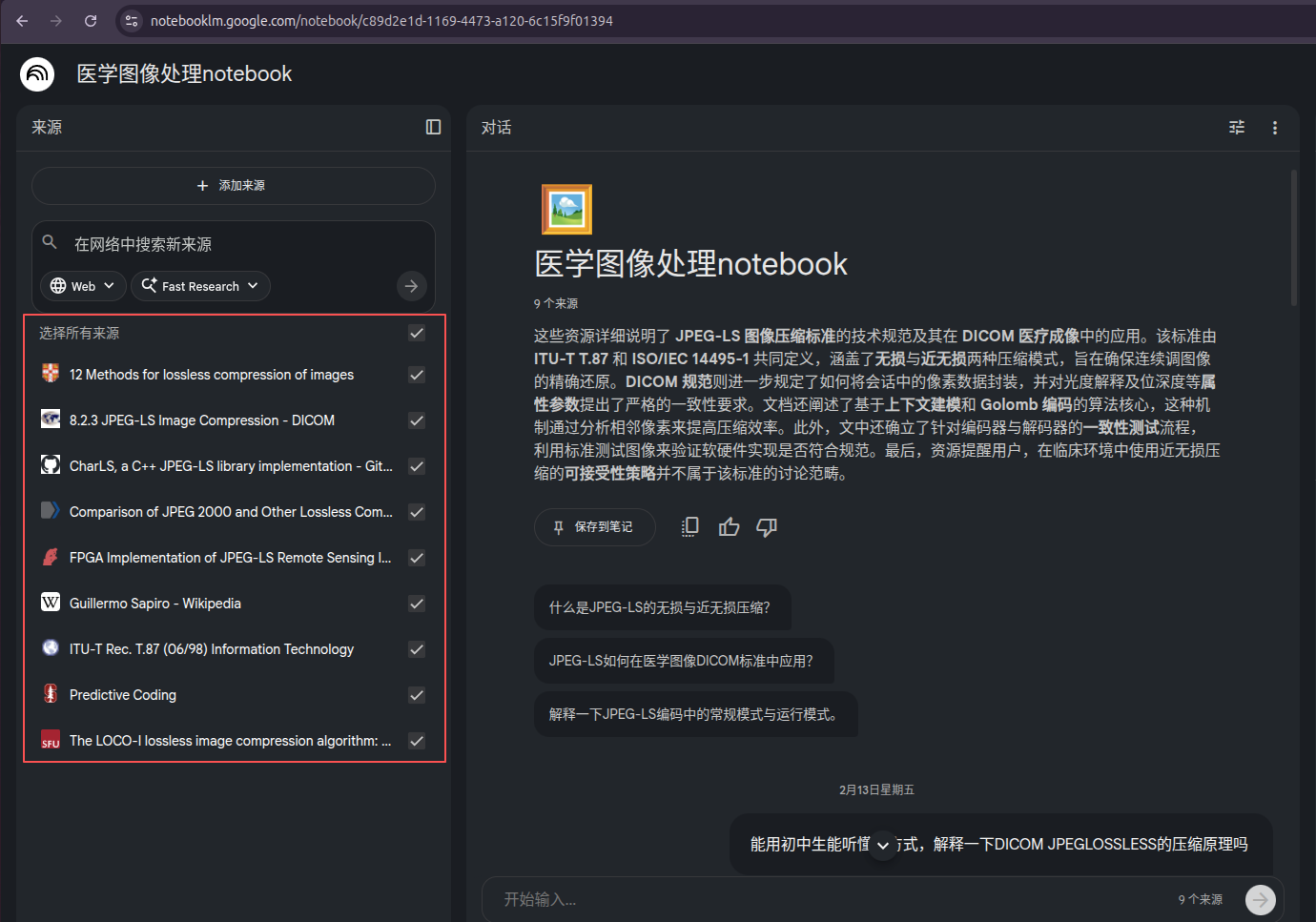
当左侧所有的 checkbox都自动划上勾后,在中间的"对话"区域内,便会出现一个简短的摘要,来说明这些资料的概要内容。
由于我是把三篇与DICOM JPEGLossless的文章题目依次输入进入,NotebookLM又自动联网搜索了其他几篇相关的文献,因此它给出的摘要,也是介绍了这个算法的定义,来历和应用。
接下来,我们便可以在下面的对话框,来提问相关的问题。
比如,我输入: “能用初中生能听懂的方式,解释一下DICOM JPEGLOSSLESS的压缩原理吗?”
接下来它便开始按照初中生能理解的方式,开始普及这个算法知识。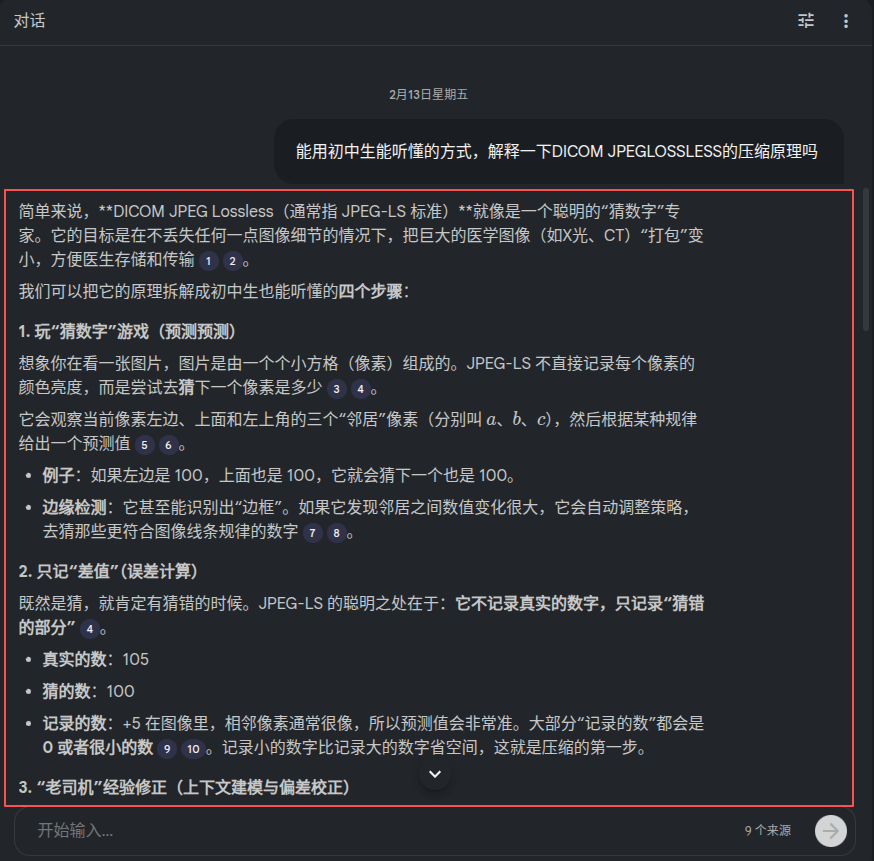
我又问了,DICOM JPEGLossless和传统的JPEG 2000压缩算法的区别是什么?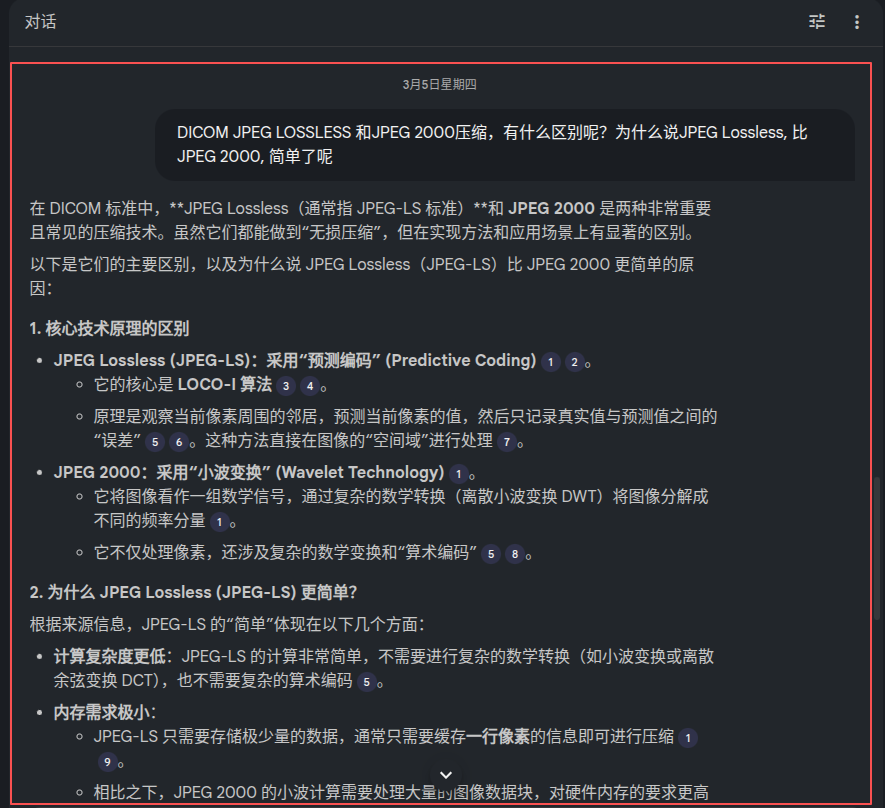
经过几轮的对话,我对这个算法便有了一个大致的了解。
但是我怎么和别人分享呢? 这时NotebookLM的最右侧,便给了我们很多的选择。可以生成视频讲解,音频概览,思维导图,PPT等。
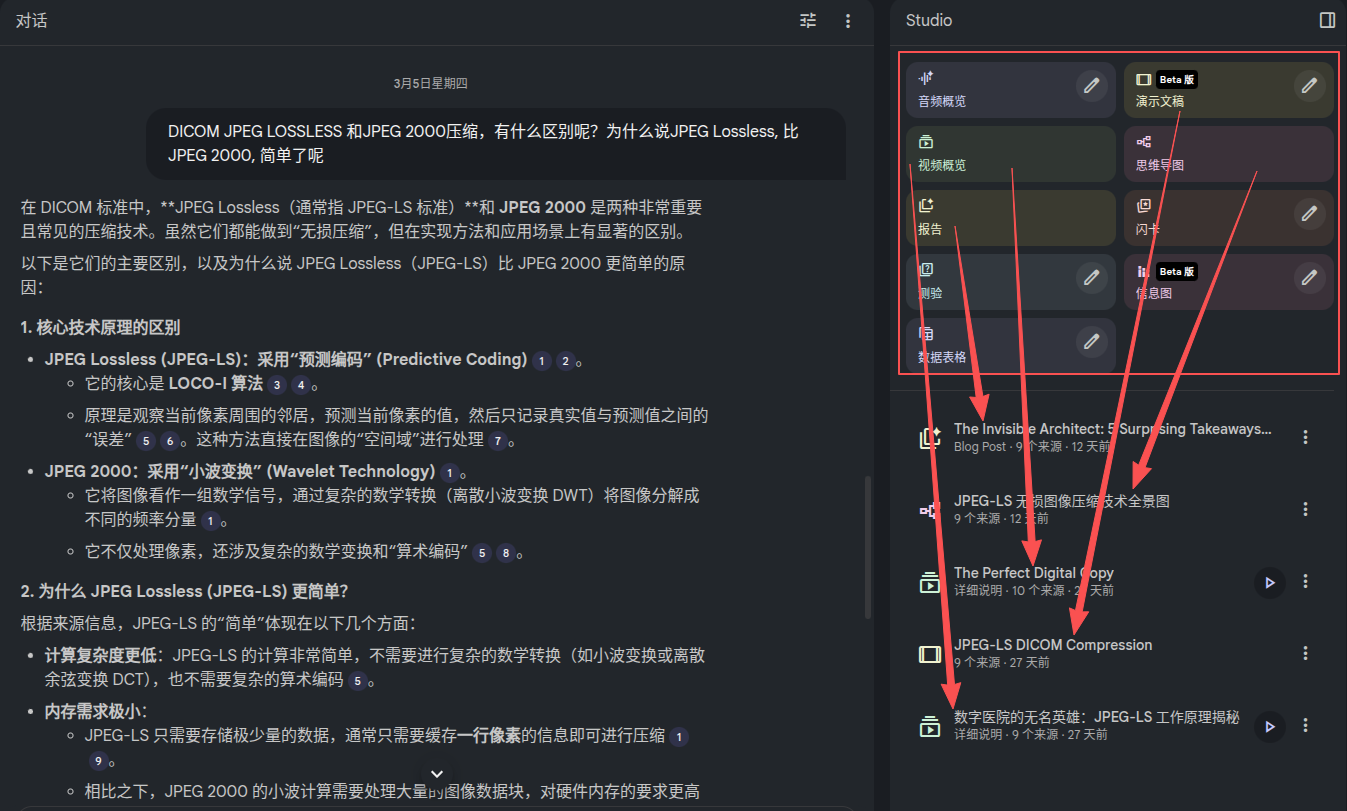
右上角区域是可以选择的传播媒介。右下角区域便是生成的结果,包括视频,音频,演示文稿,博客文章等等。
生成视频时,可以选择不同的语言,视频的风格,甚至你可以告诉它,希望视频里面能够侧重讲解哪些内容。当这些都规定好后,它便开始默默地根据你的要求,来生成一篇像样的视频。
我分别生成了中文和英文两个视频。这两个视频,题目和讲解的侧重点各不相同。我还把中文和英文的视频,分别上传到了B站和Youtube上面。作为我在这两个视频平台上面的第一份视频稿件。
以下是两个视频在网站上的播放链接:
B站: https://www.bilibili.com/video/BV131AkzYEu4/?vd_source=952e0eacb46ee6d573b9f01638c0a293
Youtube: https://youtu.be/nGVYFVGU7zs
3 代码实践
接下来,我们主要利用pydicom, 来演示,如何进行JPEG Lossless的无损压缩。以及无损压缩可以达到的图像的压缩比例。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)