OpenCL 编程系列(二)《OpenCL 编程抽象与语法》
目录
本文主要讲解 OpenCL 的核心抽象、编程语法、常用操作。
OpenCL 核心抽象模型
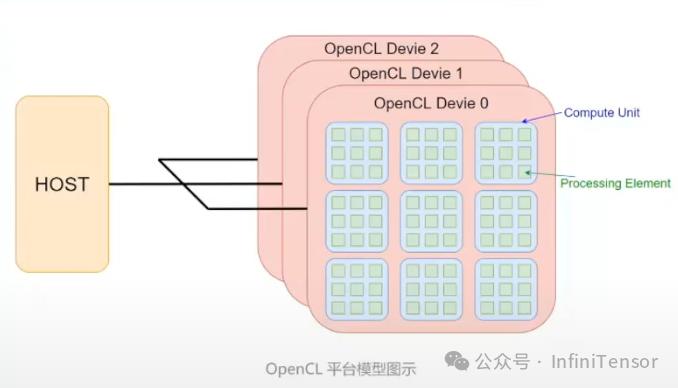
1. 平台模型—— 硬件抽象
-
• 核心概念: 主机(Host)与设备(Device)的异构架构。
-
• 层级结构:
-
• 主机 (Host):通常指CPU,负责控制中心、任务调度和数据同步。
-
• 设备 (Device):异构计算硬件(如GPU、多核CPU、DSP)。
-
• 计算单元 (Compute Unit):设备中的并行计算模块。
-
• 处理单元 (Processing Element, PE):最小的执行单元,对应硬件线程。
-
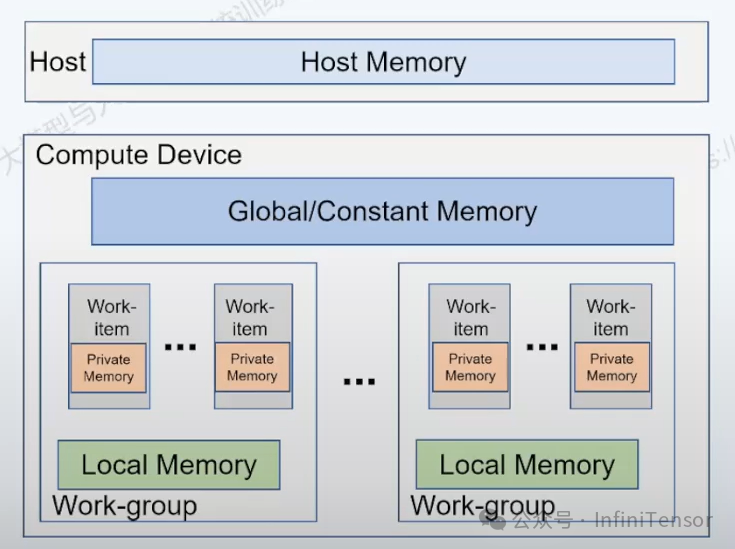
2. 内存模型 —— 存储规范
-
• 存储分级:
-
• 主机内存
-
• 全局内存:类似显存,所有工作项可读写。
-
• 常量内存:独立的地址空间,用于存储在内核执行期间保持不变的数据。通过专门的常量缓存(Constant Cache)实现高速访问。
-
• 局部内存:计算单元内共享,工作组内所有线程共享。
-
• 私有内存:线程独有,仅自己使用。
-
-
• 内存对象 (Memory Objects):
-
• Buffer:连续线性内存,通过指针访问(类似 C 语言数组)。
-
• Image:带坐标和格式信息的图像内存。
-
• Pipe:队列型内存对象,用于设备端内核之间实现生产者-消费者通信模型。
-
• 数据交互方式:读/写、填充 (Fill)、映射/解映射 (Map/Unmap)、拷贝 (Copy)。
-
-
• 共享虚拟内存(SVM):
-
• 粗粒度 SVM:共享地址空间,但需显式映射/解映射切换使用权。
-
• 细粒度 SVM:允许主机和设备在无需映射的情况下访问共享地址空间,但并发访问需要通过同步或原子操作保证一致性。
-
• 细粒度系统 SVM:最强形态,主机malloc的指针可直接在设备使用,无需申请,运行时自动同步。
-

3. 执行模型 —— 运行流程
-
• 三大核心概念:
-
• 上下文:资源仓库与隔离边界(包含设备、内核对象、程序对象、内存对象)。
-
• 命令队列 :设备的执行清单(内核入队、存储器入队、同步命令)。
-
• 执行模式:顺序执行 vs 乱序执行(需依赖 Event同步)。
-
-
• 内核:在设备上执行的计算函数。
-
-
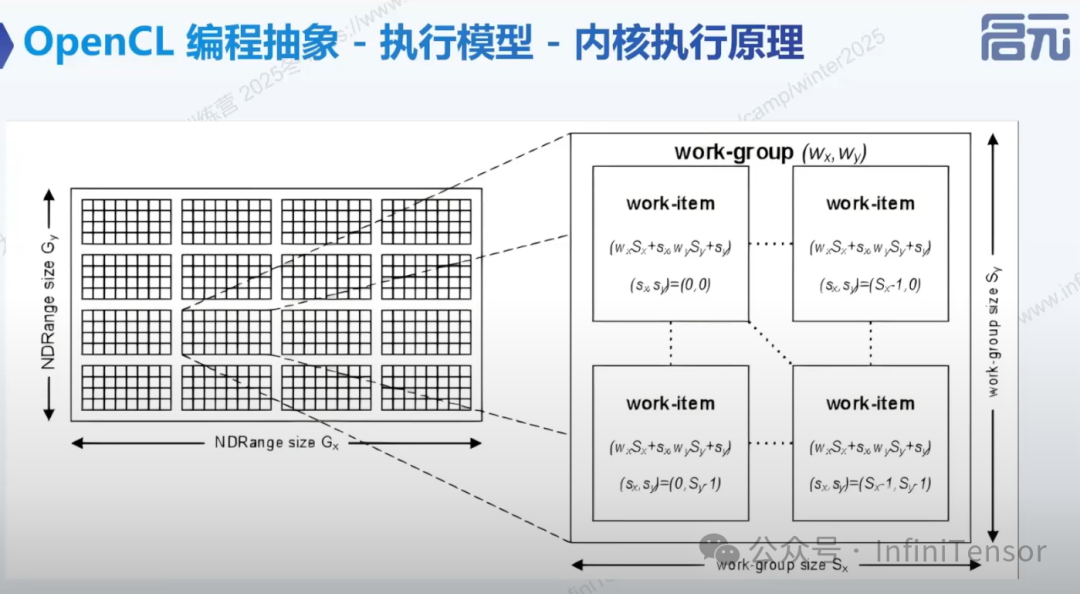
• 内核执行原理:
-
• 索引空间 (NDRange): 全局尺寸、局部尺寸和偏移 。
-
4. 编程模型
-
• 数据并行 :划分数据分配给不同计算单元(常用模型)。
-
• 任务并行 :将程序拆分为独立任务单元。利用 Event机制组织有依赖关系的任务执行。
OpenCL C 基础语法
1. 代码基本规则
-
• 必须使用
__kernel(或kernel) 为前置符。 -
• 必须返回 void 类型,即无返回值。
-
• 通过指针参数传递结果。
2. 限定符
-
• 2.1 函数限定符:
__kernel,以及__attribute__(用于编译优化,如工作组大小)。 -
• 2.2 地址空间限定符:
global,local,constant,private。-
• (1)特殊规则:
-

①函数参数及局部变量默认为 `private`
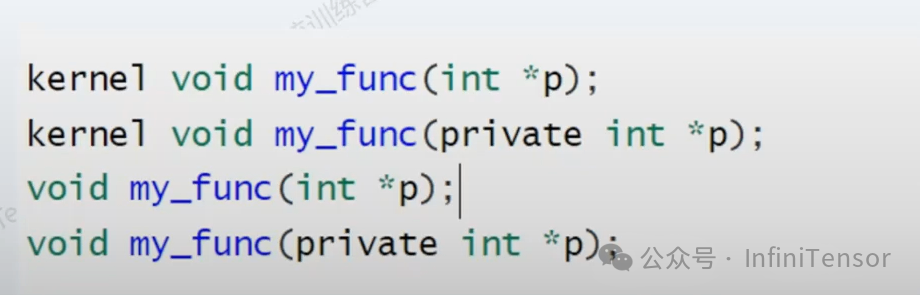
②内核参数不能声明为 private 地址空间类型;private 对象只能在内核内部定义和使用;
-
• (2)全局地址空间:

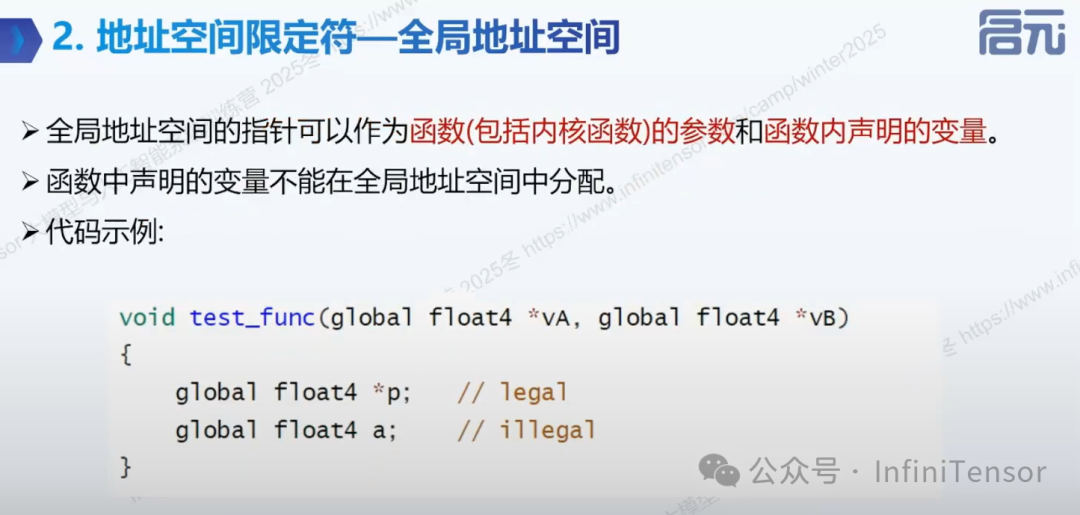
-
• (3)常量地址空间:
-
• 全局
-
• 只读
-
• 初始化
-

-
• 2.3 访问限定符:
read_only,write_only,read_write(主要用于图像类型)。

3. 运算符
标量与向量:支持类似 C 的运算符,并扩展了向量操作(硬件级优化,类似 Python 数组运算但更底层)。
4. 矢量数据拷贝:
-
• 标量 ↔ 矢量:使用内建函数
vload/vstore。

-
• 矢量 ↔ 矢量:使用“=”直接赋值。
5. 原子函数
-
• 作用:解决多线程读写共享内存的数据一致性问题。
-
• 特性:不可分割性、支持内存范围、性能影响(类似加锁)。
-
• 常用操作:原子读写、原子算术操作、原子逻辑运算(与/或/异或)、原子比较交换。
6.工作组函数
-
• 背景:利用工作组内共享内存进行高效协同。
-
• 常用函数:

OpenCL 常用内核操作
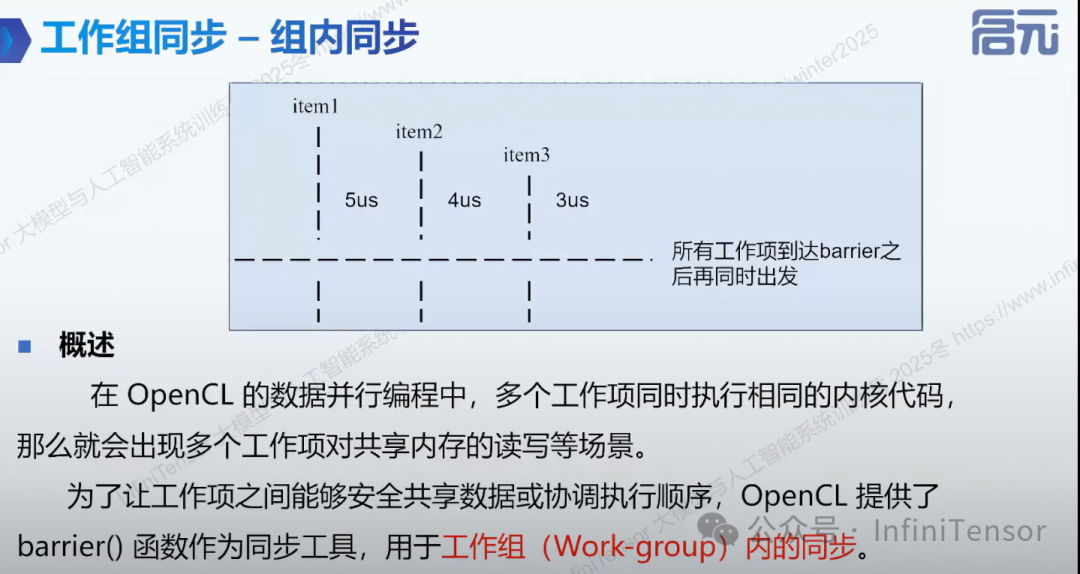
1. 工作组同步
-
• 组内同步 barrier:
限制:仅适用于工作组内,不支持工作组间全局同步(硬件限制)
-
• 组间同步:
-
• OpenCL 不支持组间同步(硬件限制)。
-
• 替代方案:
①原子操作:可用于全局求和,但性能瓶颈、扩展性差。
②主机端处理:GPU做局部归约,CPU做最终归约。
③ 模拟锁:结合原子操作和全局标志位(复杂且性能差)。
-
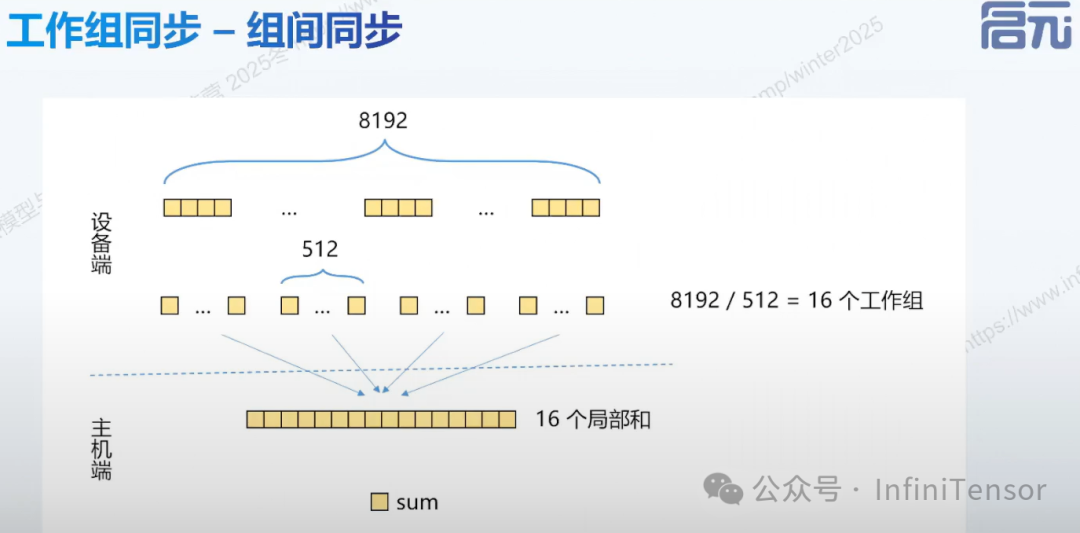
主机端处理
2. 归约操作
-
• 核心思想:通过多次“合并”逐步减少数据量,最终将结果聚合成一个单一输出。

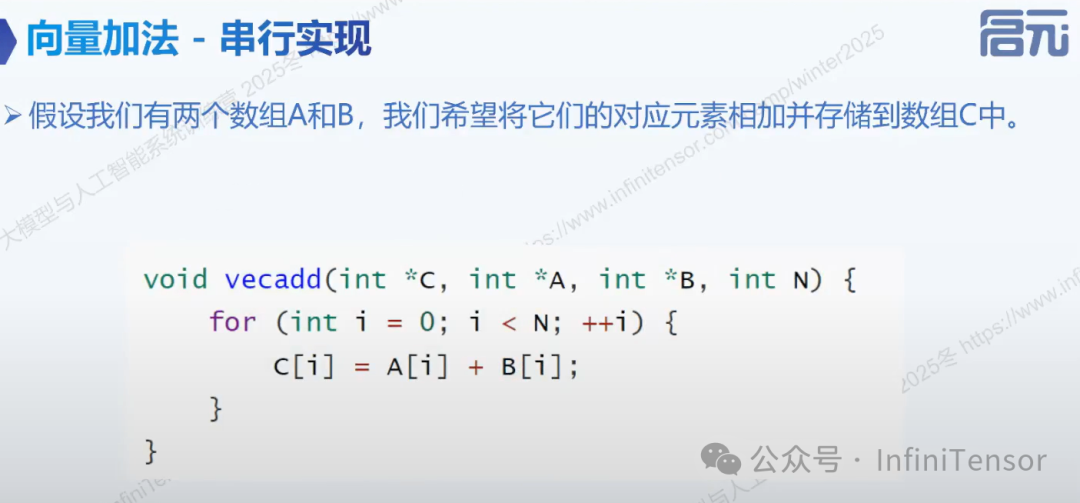
OpenCL 基础算子示例
1. 向量加法——串行实现

2. 多线程实现
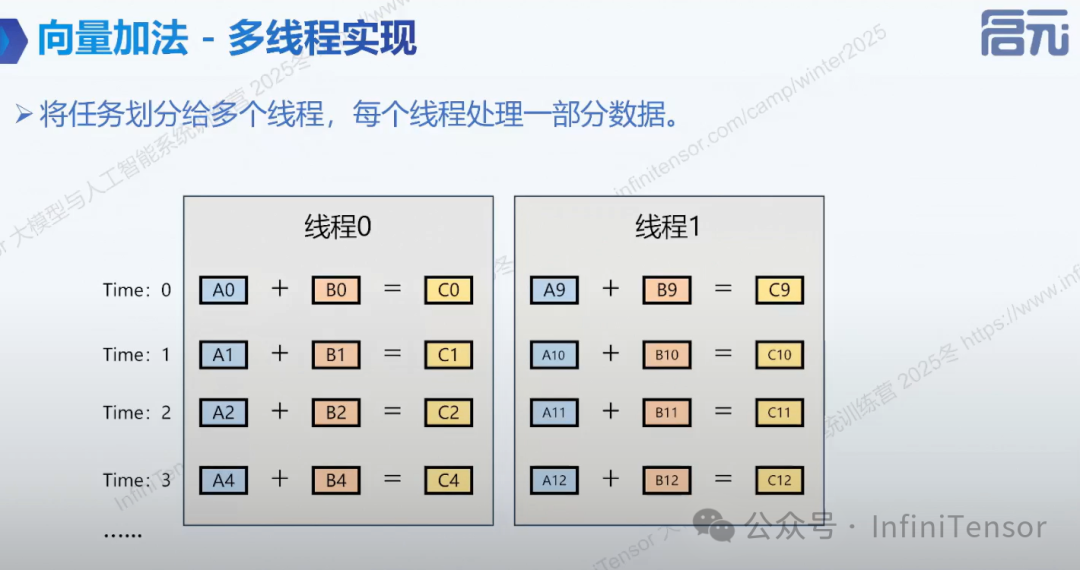
在多核 CPU 架构中,利用多线程技术优化向量加法的核心逻辑——数据并行 (Data Parallelism):与串行实现不同,这里将整个计算任务划分成了独立的“块” (Chunks)。任务分配:线程 0 (Thread 0):负责处理数据的一个子集(如图中的索引 0-4)。线程 1 (Thread 1):同时负责处理数据的另一个子集(如图中的索引 9-12)。并发执行:在 Time 0 时刻,线程 0 正在计算 ,而同一时刻,线程 1 也在计算 。两个线程互不干扰,并行推进。优势:理论上,使用 个线程可以将计算时间缩短为原来的 (不考虑线程创建和上下文切换的开销)。这是高性能计算的基础思想——通过增加计算资源来换取时间。

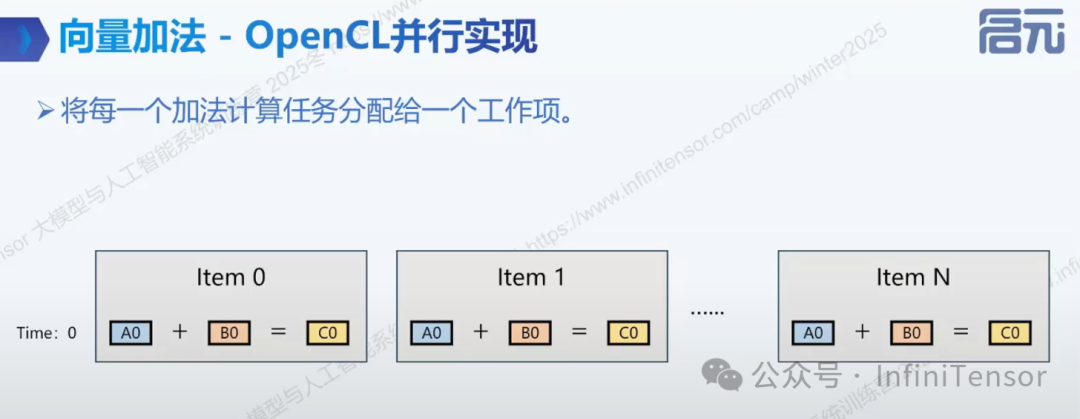
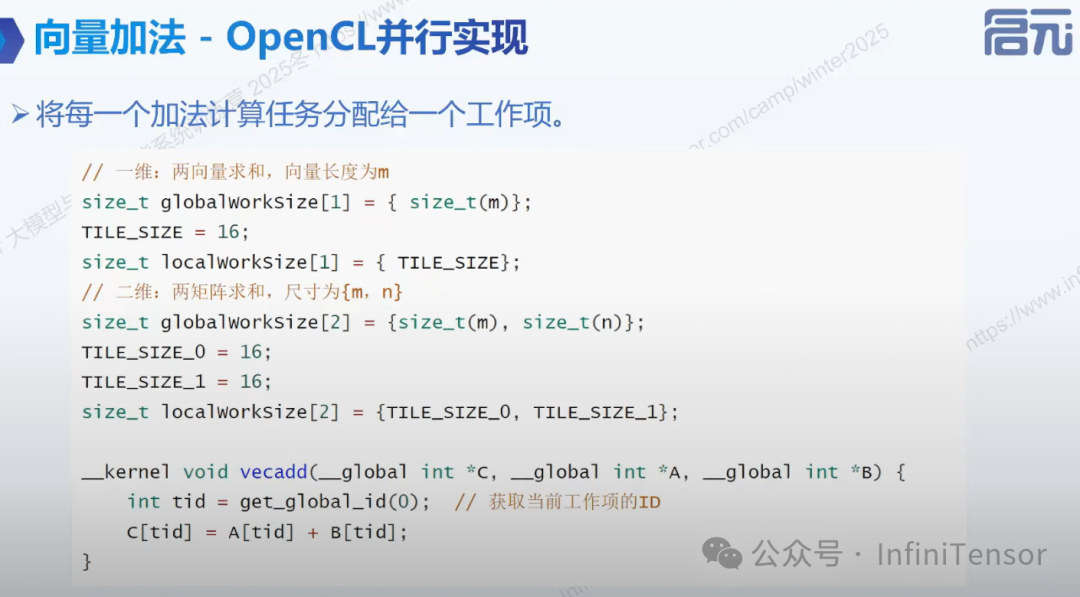
3.OpencL 并行实现
与 CPU 多线程将数据切分为大块不同,OpenCL 的策略是将计算任务切分到最细粒度(Fine-grained)。工作项 (Work-item):我们将每一个独立的加法操作()分配给一个独立的“工作项”(类似 CUDA 中的 Thread)。映射关系:Item 0:负责计算索引 0 的数据。Item 1:负责计算索引 1 的数据。...Item N:负责计算索引 N 的数据。
执行时序:如图所示,所有工作项在 Time 0 处于活跃状态(取决于硬件核心数,逻辑上是同时启动的)。这种架构消除了代码中的显式循环结构,将循环的迭代“展开”到了硬件的并行度上。
总结
本文主要讲解了 OpenCL 的核心抽象、编程语法、常用操作。下节课将讲解复杂算子实践与性能优化方法。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 17
17 0
0- 0



 已为社区贡献29条内容
已为社区贡献29条内容

所有评论(0)