EAAI | 西工大夏明坤,张伟伟等:分层无量纲学习:一种物理和数据混合驱动的无量纲关联参数提取方法
分层无量纲学习:一种物理和数据混合驱动的无量纲关联参数提取方法
Hierarchical Dimensionless Learning: A physics-data hybrid-driven approach for discovering dimensionless parameter combinations
夏明坤,林海涛,张伟伟

引用格式:Xia, M., Lin, H., & Zhang, W. Hierarchical Dimensionless Learning: A physics-data hybrid-driven approach for discovering dimensionless parameter combinations[J]. Engineering Applications of Artificial Intelligence, 2026, 170, 114190.
导读:
在流体力学等复杂物理系统的研究中,如何从高维数据中提取具有物理意义的低维表征,一直是理论分析与工程应用的核心问题。针对这一挑战,本文提出的分层无量纲学习方法(Hi-π),一种物理-数据混合驱动的参数降维框架,通过量纲分析确保物理一致性,并借助符号回归在无预设函数形式的前提下自动发现关键无量纲参数组合。该方法能通过复杂度-精度权衡机制,实现最优参数提取和最优参数变换,在处理多参数耦合、变参数敏感性、噪声干扰等场景时均表现出稳健性能。该工作为复杂系统的参数降维与物理知识发现提供了一种更具普适性的方法论框架,也为量纲分析的智能化拓展奠定了方法基础。
一、研究背景及现状
随着测量技术和高性能数值模拟的发展,流体力学领域积累了规模可观的数据。然而,这些数据受控制方程的强约束,存在显著高维冗余,不仅增加了模型分析的复杂度,也影响了实验计算成本与预测效率。
量纲分析基于物理定律不依赖于单位制选择的原理,提供了一种物理降维的通用框架。通过Buckingham II定理,研究者可以将多个物理量组合为更少的无量纲参数,从而简化复杂物理问题、降低实验成本、提升物理可解释性,并具备跨尺度外推能力。
然而,面对高维复杂系统,经典量纲分析仍面临两方面局限:其一,缺乏对输出参数的映射约束,导致提取的无量纲参数未必是最优组合;其二,未能有效利用现有数据捕捉高维参数空间中的低维流形结构。因此,如何将量纲分析与数据驱动方法相结合,建立更精确、更具普适性的参数降维方法,成为当前研究的重要方向。
近年来,数据驱动的量纲分析研究取得了多项进展。从方法学角度,现有工作可分为不变性学习、主动子空间、神经网络、KAN网络、符号回归、概率统计、流形学习等多个方向,见图1。然而,这些方法仍存在不同程度的局限性:部分方法假设无量纲参数必须满足幂次乘积形式,限制了其在复杂场景中的应用;部分方法仅能提取单一主导参数组合,在多参数耦合系统中失效;神经网络等方法虽表达能力强,但训练复杂、超参数调优困难。
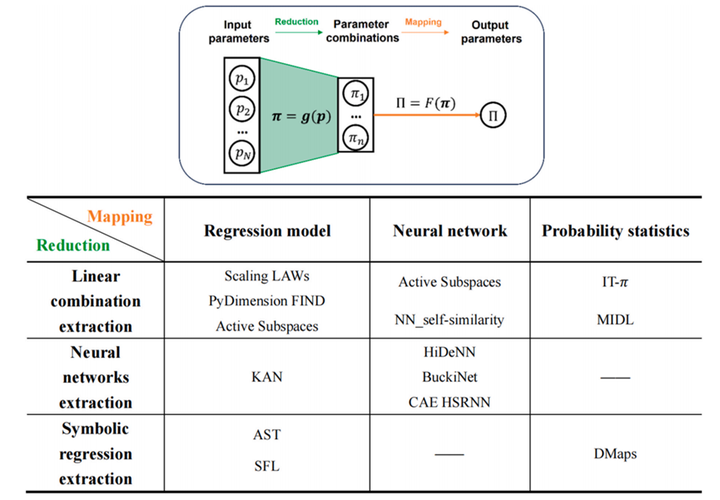
二、研究方法
基于上述研究背景,本文提出分层无量纲学习(Hi-π)方法,通过物理层(通过量纲分析对输入参数进行初步降维,确保物理一致性)、压缩层(借助PySR符号回归方法的多分支树结构同时搜索多个参数组合π)、映射层(建立参数组合与输出变量之间的关系)的三层递进架构,实现关键无量纲参数组合的自动提取,如图2所示。
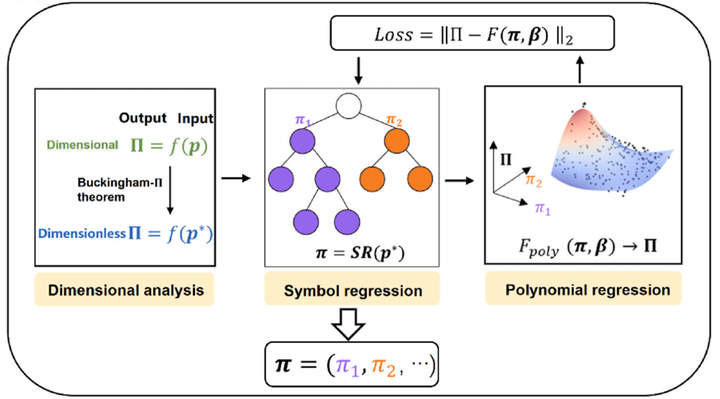
三、结果分析
本推文重点以粗糙圆管流动、瑞利伯纳德对流及压缩性修正三个典型算例展开分享,深入解析Hi-π方法的核心机制与应用效果。限于篇幅,数学算例及其他物理案例的详细结果请参阅原文,方法实现的补充细节与对比分析详见附录。
3.1 粗糙圆管流动
如何从众多可能的无量纲形式中筛选出最具物理意义的最优组合,是参数降维的核心任务之一。以粗糙圆管流动为例,其提取过程遵循如图3所示的分层筛选流程。首先,确定输入参数关系并进行量纲分析,选取任意一组无量纲参数组合作为初始输入(亦可选择其他量纲指数矩阵
,最终结果保持一致性)。随后,采用符号回归方法对参数组合进行系统提取:从1阶到8阶多项式逐次扫描,测试不同阶数下对应的拟合误差,并记录各阶次提取的参数组合表达式。通过绘制“阶数-损失”关系曲线发现,4阶以下随阶数增加拟合误差快速下降(欠拟合区),4阶以上误差变化趋于平缓(过拟合区)。据此,以4阶对应的参数组合作为复杂度和精度的平衡点——即雷诺数Re和相对粗糙度
,这一组合不仅实现了最简洁的数学表达,同时保证了最高的预测精度,充分体现了最优参数变换的思想。
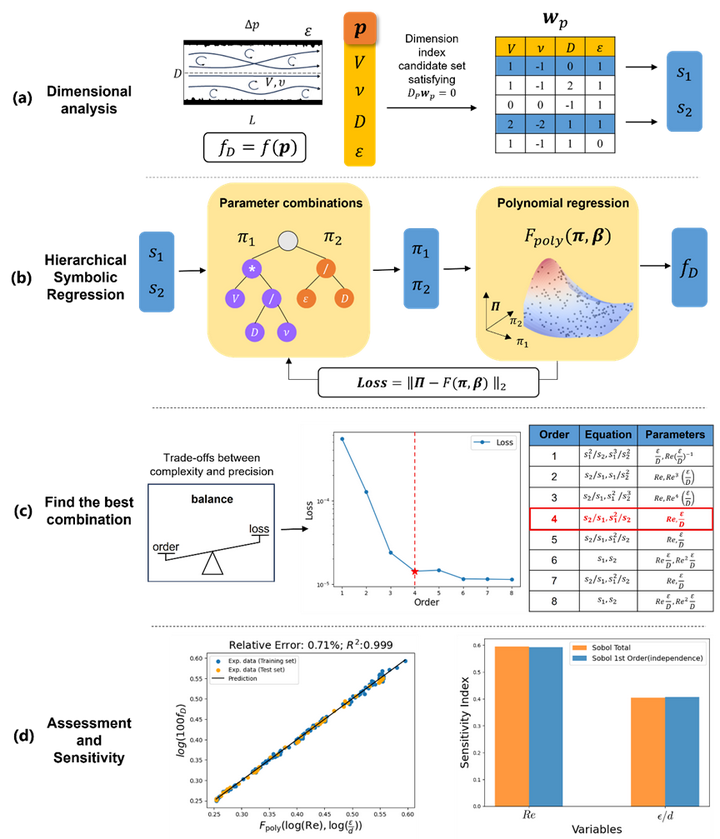
3.2瑞利伯纳德对流
准确识别系统的本征维度,是参数降维的另一个核心任务。以瑞利-伯纳德热对流为例,其控制参数的内在重要性常随数据范围而变化,通过Sobol方法对参数敏感性进行分析发现,当参数组合之间存在强、弱敏感性差异时,弱参数在特定数据范围内近似恒定,导致经典的PyDimension方法陷入局部最优解,仅能捕获强敏感参数,无法识别系统的本征维度。Hi-π方法则不受此影响,通过迭代扩参策略确定系统的本征维度,从而准确识别出低维流形结构的真实维数。在瑞利-伯纳德对流算例中(图4),数据集1下Pr数表现为弱敏感性,PyDimension仅提取Ra数,误将本征维度识别为1;而Hi-π同时提取Ra数和Pr数,正确揭示本征维度为2,更符合物理认知。在数据集2中,PyDimension因两参数敏感性差异缩小,结果随之变化不稳定,而Hi-π仍稳定提取两个参数组合。Hi-π通过对本征维度的刻画,从根本上规避了参数敏感性干扰。
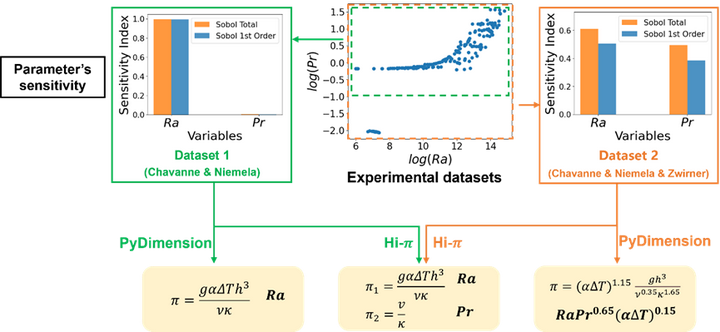
3.3 压缩性修正中的参数组合与知识发现
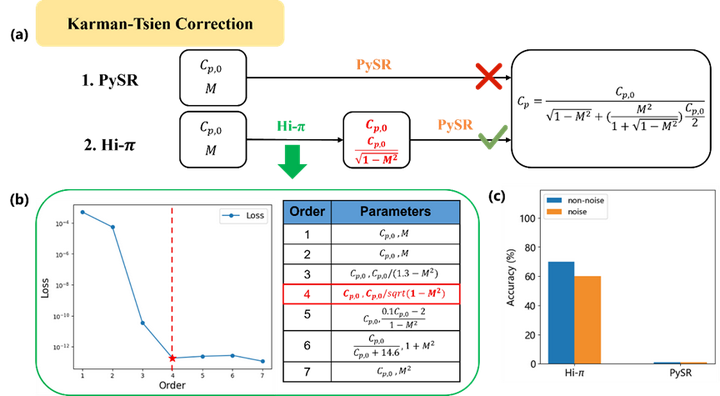
在完成最优参数提取与本征维度识别后,压缩性修正算例进一步凸显了Hi-π方法在知识发现中的独特价值:通过提取最优参数组合对输入空间进行变换,有效引导后续符号回归绕过局部最优解,从而显著提升对复杂数学结构的发现准确率。如图5所示,分层符号回归从数据集中提取的最优参数组合为不可压缩压力系数与Prandtl-Glauert修正项
。基于这一参数变换,Hi-π方法在面对结构复杂的Karman-Tsien修正公式时,显著提升了符号回归的发现准确率,而直接符号回归的PySR方法则完全失效。
四、结论
本研究提出的Hi-π方法是一种基于量纲分析的物理-数据混合驱动框架,通过符号回归与模型映射,提取对输出有关键影响、具有物理意义的参数组合。该方法能够准确捕获系统内在维度,平衡模型精度与复杂度,在高维参数空间、变参数敏感性和噪声条件下均展现出稳健性能,同时通过参数变换提升对复杂数学结构的准确发现。然而,该方法也存在局限性:多参数提取对数据量与质量要求较高;高度非线性映射模型表征能力有限。未来研究将探索根据物理问题和数据特征自动适配的发现策略,并结合先进的表征方法提升复杂映射的表征能力,为物理规律发现与白箱模型泛化提供更具普适性的方法论框架。
公众号原文链接(文末附论文资源):
https://mp.weixin.qq.com/s/nDFb-cghtTkBeJblBzQDOA
相关论文推荐:
CJA|西工大林海涛、张伟伟等:关联函数学习:适用飞行器外形泛化的稀疏气动数据重构方法
注:文章由原作者投稿分享,向本公众号授权发布。
更多精彩内容,敬请关注微信公众号“力学与人工智能”

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 12
12 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)