MULTIMODALQA: COMPLEX QUESTION ANSWERING OVER TEXT, TABLES AND IMAGES
这是一篇由艾伦人工智能研究所(AI2)、特拉维夫大学与华盛顿大学联合撰写的研究论文,发表于ICLR 2021,核心聚焦跨文本、表格、图像的复杂多模态问答任务。论文提出了首个大规模多模态问答数据集 MMQA,设计了一套可扩展的复杂多模态问题生成框架,并提出 ImplicitDecomp 多跳推理模型,首次系统性解决了需要整合三种模态信息的复杂问答挑战,为多模态推理领域奠定了重要基础。
一、研究背景与核心问题
1.1 研究动机
人类在解决复杂问题时,能无缝整合文本、表格、图像等多模态信息(如通过文本了解人物关系、表格查询时间数据、图像识别关键特征后综合作答)。然而,现有问答研究存在明显局限:
- 单模态聚焦:多数工作仅针对单一模态(文本 QA、表格 QA、图像 VQA),缺乏跨模态推理支持;
- 伪多模态局限:现有多模态数据集(如 MANYMODALQA)仅需识别相关模态,无需跨模态信息整合;
- 模态覆盖不全:HYBRIDQA 虽支持文本与表格跨模态推理,但未包含图像模态,限制了复杂场景的覆盖。
因此,亟需构建一个真正需要整合文本、表格、图像三种模态信息的复杂问答数据集,并设计对应的多跳推理模型。
1.2 核心问题
- 如何规模化生成需要跨文本、表格、图像推理的复杂问题,解决人工标注成本高、场景覆盖有限的问题?
- 如何设计模型,实现对三种模态信息的隐式分解与多跳推理,无需显式拆分问题即可整合多源信息?
- 量化现有模型在跨模态复杂问答任务中的性能上限,明确与人类表现的差距。
1.3 研究贡献
- 提出MMQA 数据集:包含 29,918 个问答样本,35.7% 的问题需要跨模态推理,是首个覆盖文本、表格、图像三种模态的大规模复杂问答数据集;
- 设计规模化问题生成框架:通过 “锚定表格 + 关联多模态上下文 + 形式化语言组合 + 人工改写” 的流程,高效生成跨模态复杂问题;
- 提出ImplicitDecomp 模型:通过隐式分解问题类型,实现多跳跨模态推理,在跨模态问题上 F1 分数达 51.7,显著超越单跳基线(38.2);
- 验证了任务的挑战性:人类在 MMQA 上的 F1 分数达 90.1,与模型表现存在显著差距,为后续研究提供了明确方向。
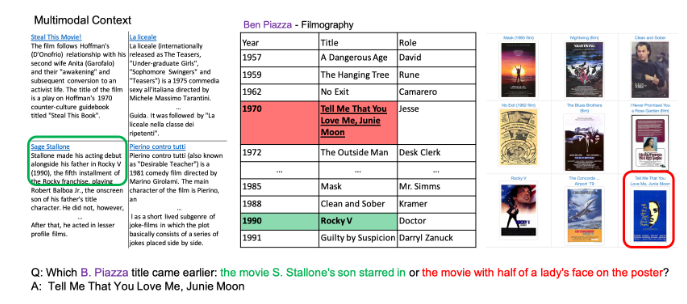
二、MMQA 数据集构建
MMQA 的核心创新在于 “规模化生成跨模态复杂问题”,构建流程分为 6 个关键步骤,确保数据质量与场景多样性。

2.1 数据集构建流程
(1)锚定 Wikipedia 表格
从 2020 年 1 月英文 Wikipedia 快照中提取 300 万张表格,筛选出满足以下条件的表格作为锚点:
- 行数 10-25 行(保证信息密度适中);
- 至少关联 3 张图像(确保多模态扩展潜力);最终筛选得到 70 万张表格,表格中的 Wikipedia 实体(WikiEntities)作为连接不同模态的核心枢纽。
(2)关联多模态上下文
基于表格中的 WikiEntities,为每张表格补充图像与文本上下文:
- 图像上下文:分为表格内图像(单元格内嵌图像,889 张)与实体关联图像(WikiEntities 对应的 Wikipedia 页面配图,56,824 张),总计 57,713 张图像;
- 文本上下文:从现有阅读理解数据集(Natural Questions、BoolQ、HotpotQA)中筛选含相同 WikiEntities 的文本段落,最终获取 12,623 个文本问答对(含 1-2 个黄金段落)。
(3)生成单模态问题
为每种模态单独生成基础问题,作为复杂问题的 “构建模块”:
- 表格问题(TableQ):自动生成伪语言问题,支持数值计算(如最大值、最小值),示例:“In [Doubles] of [WCT Tournament of Champions], what was the MOST RECENT [Year] where the [Location] was [Forest Hills]”;
- 图像问题(ImageQ/ImageListQ):通过众包生成,ImageQ 针对单张图像(如 “Roger Federer 的头发颜色是什么?”),ImageListQ 针对多张图像(如 “哪些雕像包含马匹元素?”),共生成 10,537 个图像问题;
- 文本问题(TextQ):直接复用筛选后的 12,623 个现有文本问答对,涵盖事实查询、是非判断等类型。
(4)形式化语言组合生成复杂问题
设计一套形式化语言(PL),通过 7 种逻辑操作组合单模态问题,生成跨模态复杂问题,共支持 16 种组合模板(如表 2 所示),核心逻辑操作包括:
- COMPOSE (・,・):将一个问题的答案(WikiEntity)作为另一个问题的输入,实现多跳推理,示例:COMPOSE (“奥巴马出生于哪里?”, “美国第 44 任总统是谁?”) → “美国第 44 任总统出生于哪里?”;
- INTERSECT (・,・):取两个问题答案集合的交集,示例:“谁出生于夏威夷且是萨沙・奥巴马的父母?”;
- COMPARE (・,・):对比两个问题答案在表格中对应的数值 / 日期列,示例:“阿波罗计划的火箭与双子座计划的火箭,哪个创建年份更新?”。
(5)众包改写为自然语言
通过 Amazon Mechanical Turk(AMT)工人将形式化语言问题改写为流畅的自然语言:
- 激励机制:改写与原 PL 问题的归一化编辑距离 > 0.7 可获奖金,鼓励多样化表达;
- 质量控制:每个问题由 1 名工人改写、1-3 名工人验证,确保语义一致性;
- 最终产出:29,918 个自然语言问答样本,拆分为训练集 23,817 个、验证集 2,441 个、测试集 3,660 个(验证集与测试集的上下文组件与训练集完全 disjoint)。
(6)添加干扰项
为增强任务挑战性,为文本与图像上下文添加干扰项:
- 文本干扰项:使用 DPR 模型检索与问题语义相似但不含答案的段落,每个文本上下文包含 1-2 个黄金段落 + 8-9 个干扰段落,总计 10 个段落;
- 图像干扰项:对单图像问题(ImageQ),随机添加表格关联的 WikiEntities 图像作为干扰项,最多 15 个干扰图像;图像列表问题(ImageListQ)无需额外干扰项。
2.2 数据集核心特征
(1)基础统计信息
表格
| 统计指标 | 数值 | 关键说明 |
|---|---|---|
| 总样本数 | 29,918 | 含 29,918 个独特问题 |
| 跨模态问题占比 | 35.7% | 训练集 40.1%,验证 + 测试集 34.6%(适度上采样跨模态样本) |
| 复杂组合问题占比 | 60.5% | 训练集 58.8%,验证 + 测试集 62.3% |
| 平均问题长度 | 18.2 词 | 自然语言表达流畅,复杂度高于单模态问题 |
| 平均答案长度 | 2.1 词 | 答案以短文本为主,支持单答案与列表答案(占比 7.4%) |
| 覆盖领域 | 12 + 领域 | 包括电影(36%)、电视(19%)、体育、地理、科学等 |
| 模态组合类型 | 7 种 | 文本 + 表格、文本 + 图像、表格 + 图像、文本 + 表格 + 图像等 |
(2)问题类型分布
16 种组合模板覆盖不同推理类型,高频类型包括:
- 纯文本问题(TextQ):31.0%;
- 纯表格问题(TableQ):18.3%;
- 纯图像问题(ImageQ):8.9%;
- 文本 + 表格组合(Compose (TextQ,TableQ)):7.8%;
- 表格 + 图像组合(Compose (TableQ,ImageQ)):5.4%。
三、模型设计
论文设计了单模态 QA 模块与多模态推理模型,其中 ImplicitDecomp 是核心创新,实现跨模态隐式多跳推理。
3.1 单模态 QA 模块
作为多模态模型的基础组件,分别处理文本、表格、图像三种模态的问答任务:
(1)文本 QA 模块
- 核心逻辑:基于 RoBERTa-large,输入问题与段落,预测答案跨度(start/end 位置),同时输出 “答案在段落中 / 是 / 否 / 不在段落中” 四种置信度;
- 推理策略:选择 “不在段落中” 置信度最低的段落,提取答案跨度。
(2)表格 QA 模块
- 核心逻辑:将表格按行线性化(列名 + 单元格值,如 “Row 1: year is 1957; title is a dangerous age”),拼接问题后通过 RoBERTa-large 编码;
- 输出:预测选中的单元格(概率 > 0.5)与聚合操作(SUM/MEAN/COUNT/YES/NO/NONE),聚合操作应用于选中单元格得到最终答案。
(3)图像 QA 模块
- 核心逻辑:基于 VILBERT-MT(多任务预训练视觉语言模型),输入问题、图像特征(Faster R-CNN 提取自 Visual Genome)与图像关联的 WikiEntity 名称;
- 输出:从固定词汇表中预测答案(适用于 ImageQ),或判断图像是否为答案子集(适用于 ImageListQ,输出 “正例 / 负例”)。
3.2 多模态推理模型
(1)单跳基线:AutoRouting
- 核心逻辑:先通过问题类型分类器(RoBERTa-large)预测问题对应的目标模态,再将问题路由至对应单模态 QA 模块,输出结果;
- 本质:无跨模态推理能力,仅实现 “模态识别 + 单模态问答”,作为基准对比。
(2)多跳模型:ImplicitDecomp(核心创新)
- 设计理念:无需显式拆分问题为子问题,通过预测问题类型(16 种组合模板),隐式确定推理步骤与模态顺序,实现多跳跨模态推理;
- 核心流程:
- 问题类型分类:用 RoBERTa-large 预测问题对应的组合模板(如 Compose (TextQ,TableQ)),准确率达 91.5%;
- 多跳推理:根据问题类型确定模态顺序与推理步骤,例如 Compose (TextQ,TableQ) 对应 “表格模态(第 1 跳)→文本模态(第 2 跳)”;
- 中间结果传递:第 1 跳的输出(如表格中提取的 WikiEntity)作为第 2 跳的输入,与问题结合后送入对应模态 QA 模块;
- 输出最终答案:整合第 2 跳结果,生成最终答案;
- 参数共享:同一模态的 QA 模块在第 1 跳与第 2 跳中共享参数,减少训练开销。
(3)其他基线
- Question-only:基于 BART-large,仅输入问题直接生成答案,测试模型的 “记忆能力”;
- Context-only:输入上下文(替换问题为空字符串),测试模型的 “无问题推理能力”。
3.3 训练设置
- 监督信号:利用数据集提供的黄金答案、问题类型、中间推理结果,进行有监督训练;
- 损失函数:问题类型分类器采用交叉熵损失,各 QA 模块采用跨度预测损失(文本 / 表格)或分类损失(图像);
- 硬件与优化:基于 PyTorch 实现,使用单随机种子训练,测试集仅运行一次。
四、实验结果与分析
4.1 核心实验结果
实验分为 “单模态问题”“跨模态问题”“所有问题” 三类场景,采用 F1 分数与精确匹配(EM)作为评估指标(支持列表答案的对齐计算),人类表现由 9 名专家标注 145 个样本得到。
表格
| 模型 | 单模态问题(F1) | 跨模态问题(F1) | 所有问题(F1) | 所有问题(EM) |
|---|---|---|---|---|
| Question-only | 17.0 | 19.5 | 18.0 | 15.3 |
| Context-only | 10.2 | 8.5 | 9.5 | 7.4 |
| AutoRouting(单跳) | 57.1 | 38.2 | 49.5 | 42.1 |
| ImplicitDecomp(多跳) | 58.8 | 51.7 | 55.9 | 49.3 |
| 人类表现 | 92.5 | 90.1 | 91.2 | 86.2 |
关键结论:
- ImplicitDecomp 显著超越所有基线,跨模态问题上 F1 提升 13.5 个百分点,证明多跳推理的有效性;
- 单模态问题上,ImplicitDecomp 与 AutoRouting 差距较小(58.8 vs 57.1),跨模态问题差距显著,验证模型针对性解决了跨模态推理痛点;
- 人类表现远超模型,跨模态问题 F1 达 90.1,说明任务仍有巨大优化空间;
- Open-domain 场景测试:在全 Wikipedia 范围内检索上下文,人类 F1 降至 84.8,但仍远高于模型。
4.2 模型推理有效性分析
为验证 ImplicitDecomp 确实实现了多跳推理,分析其在核心组合操作上的表现:
表格
| 组合操作 | 第 1 跳 F1 | 最终 F1 | 关键发现 |
|---|---|---|---|
| Compose(组合) | 62.3 | 50.8 | 第 1 跳正确时,最终 F1 达 63.9;第 1 跳错误时仅 37.4,证明模型依赖中间结果推理 |
| Compare(对比) | 55.7 | 61.1 | 对比操作依赖表格数值,模型在数值比较上表现更优 |
| Intersect(交集) | 33.5 | 55.1 | 交集操作对中间结果准确性要求较低,模型容错性更强 |
定性分析显示,92% 的组合问题确实需要多跳推理,仅 6% 为 “弱干扰项” 问题(如上下文仅含一个年份,无需复杂推理),2% 为 “冗余证据” 问题(如仅一个符合条件的实体)。
4.3 人类表现细节
人工评估 145 个样本发现:
- 94.5% 的人类答案与黄金答案完全一致或语义等价;
- 0.7% 的样本存在问题表述错误;
- 4.8% 的人类错误源于上下文过长导致的疲劳,模型无此类限制。
五、相关工作对比
表格
| 数据集 / 模型 | 模态覆盖 | 跨模态推理需求 | 样本规模 | 核心差异 |
|---|---|---|---|---|
| MANYMODALQA | 文本、表格、图像 | 无(仅需模态识别) | 10K | 不要求跨模态信息整合,仅测试模态路由能力 |
| HYBRIDQA | 文本、表格 | 有(文本 - 表格) | 70K | 无图像模态,问题类型仅 6 种,生成方式无形式化语言组合 |
| MMQA(本文) | 文本、表格、图像 | 有(支持 7 种模态组合) | 30K | 首个覆盖三种模态的复杂问答数据集,16 种问题类型,支持 open-domain 场景 |
| ImplicitDecomp(本文) | 文本、表格、图像 | 隐式多跳推理 | - | 无需显式拆分问题,通过问题类型预测实现跨模态推理,参数共享效率高 |
六、局限性与未来方向
6.1 局限性
- 问题分布偏向娱乐领域:电影(36%)、电视(19%)占比过高,科学、技术等领域覆盖不足;
- 形式化语言生成的局限性:问题逻辑结构受限于 16 种模板,缺乏更灵活的自然语言复杂推理场景;
- 模型依赖问题类型标注:ImplicitDecomp 需要问题类型作为监督信号,泛化到未见过的问题类型时性能可能下降。
6.2 未来方向
- 扩展领域覆盖:增加科学、工程、医疗等专业领域的多模态问答样本;
- 优化问题生成:引入更灵活的自然语言复杂问题生成方法,减少对形式化模板的依赖;
- 无监督跨模态推理:探索无需问题类型标注的模型,提升对未知场景的泛化能力;
- 多模态融合优化:改进图像与文本 / 表格的融合机制,减少图像特征与文本特征的语义鸿沟。
七、结论
MMQA 数据集首次实现了文本、表格、图像三种模态的复杂跨模态问答任务,通过创新的规模化生成框架,高效产出了近 3 万个高质量样本。ImplicitDecomp 模型通过隐式分解问题类型,成功实现了多跳跨模态推理,显著超越单跳基线,但与人类表现仍存在巨大差距(跨模态问题 F1 51.7 vs 90.1)。
论文的核心价值在于:构建了标准化的跨模态复杂问答基准,验证了任务的挑战性,为后续多模态推理研究提供了数据集、模型范式与评估标准,推动了 QA 系统从 “单模态单跳” 向 “多模态多跳” 的演进。
数据集与代码开源地址:https://allenai.github.io/multimodalqa

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 16
16 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)