【Java程序员转大模型开发 基础篇-文本向量模型 看这一篇全盘掌握】
前期知识回顾
Java程序员转大模型开发 基础篇
Java程序员转大模型开发 实战篇-rag系统连接redis
Java程序员转大模型开发 基础篇-向量数据库 看这一篇全盘掌握
前言
本文将为大家介绍智能体开发中的关键组件——文本向量模型。我们将从基本概念入手,系统地讲解文本向量模型的定义、核心价值及应用场景。
什么是文本向量模型
文本向量模型本质上是通过数学转换,将文本信息表示为固定维度的数值向量(如768维或1024维)。这种表示方式使计算机能够理解语义信息,并计算文本间的相似度。
为什么要使用向量模型
在RAG项目开发中,我们需要借助向量数据库实现信息检索功能(关于向量数据库的详细介绍,可参考这篇文章:Java程序员转大模型开发 基础篇-向量数据库 看这一篇全盘掌握)。为了将数据存入向量数据库,我们需要使用各厂商提供的向量模型进行数据向量化转换。
相关网站推荐
Hugging Face 是一个专注于开源 AI 模型的平台,该网站汇集了大量优质的开源模型代码资源。(需要科学上网)
https://huggingface.co/maidalun1020/bce-embedding-base_v1/tree/main
文本向量模型
今天为大家介绍有道团队开源的文本向量模型BCE-Embedding-Base_v1。该模型已在Hugging Face平台开源,接下来我将详细说明其使用方法。
1.如何下载
首先我们要下载这个BCE-Embedding-Base_v 推荐大家使用的方法是通过sentence_transformers 这个开源库进行模型下载。
from sentence_transformers import SentenceTransformer
# 自定义模型缓存路径(替换成你想要的路径)
custom_cache_path = "D:/trace/RagText/bce-embedding-base_v1"
# 加载模型(自动下载到指定路径,首次需联网)
model = SentenceTransformer(
"maidalun1020/bce-embedding-base_v1",
cache_folder=custom_cache_path
)
# 验证:生成向量,说明模型下载成功
vec = model.encode("模型下载成功测试")
print(f"向量维度:{len(vec)}")
print(f"模型已保存到:{custom_cache_path}")
成功下载模型后,所需的可执行模型目录路径为: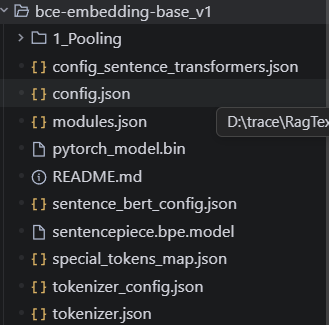
2.如何使用文本向量模型
首先我们需要引入的库为:
from sentence_transformers import SentenceTransformer
import json
import numpy as np
import chromadb
在这里我们chromad的知识以及在之前的文章里面有过讲述,感兴趣的朋友可以查看-Java程序员转大模型开发 基础篇-向量数据库 看这一篇全盘掌握。
使用方式
#创建初始模型
modle=SentenceTransformer(r'bce-embedding-base_v1')
# 对指令进行向量化 convert_to_numpy=True 输出格式为 NumPy 数组
instruction_embeddings = modle.encode(instruction, convert_to_numpy=True)
#对转换的向量进行保存
np.save(r'./instruction_embeddings.npy',instruction_embeddings)
以下是文本向量模型转换与存储的核心代码步骤。接下来我将演示一个简单示例:使用bce-embedding-base_v1模型进行向量转换,并通过chromadb向量数据库实现本地存储。
#创建初始模型
modle=SentenceTransformer(r'bce-embedding-base_v1')
with open (r'./health_qa_500.json',encoding='utf-8') as f:
#将文本读取成字典
data=json.load(f)
#问题 data 其实是一个字典
instruction=[i["instruction"]for i in data]
#答案
output=[i["output"]for i in data]
# 对指令进行向量化 convert_to_numpy=True 输出格式为 NumPy 数组
instruction_embeddings = modle.encode(instruction, convert_to_numpy=True)
np.save(r'./instruction_embeddings.npy',instruction_embeddings)
#指定数据库路径
client = chromadb.PersistentClient(path='./collection.pkl')
#从向量数据库中创建一个集合
collection = client.create_collection(name="health_qa")
for i,(sen,emb) in enumerate(zip(instruction,instruction_embeddings)):
collection.add(
documents=[sen],#原始文本(问题) 相当于书的标题
embeddings=[emb.tolist()],#向量(问题生成)相当于书的目录
ids=[f"id{i}"],
metadatas=[{'output':output[i]}] # 存储原始文本(答案)相当于书的正文
)
我整理了 health_qa_500.json 文件,有需要的朋友可以关注后私信我获取。
总结
以上就是关于文本向量数据库的介绍,以及常见的使用方式。如有任何疑问,欢迎通过私信或留言的方式联系我。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 20
20 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)