Efficient Agent: Optimizing Planning Capability for MultimodalRetrieval Augmented Generation

这是一篇由 OPPO 研究院与 OPPO AI 中心联合撰写的研究论文,发布于 arXiv(2025 年 8 月更新),核心聚焦多模态检索增强生成(mRAG) 系统的规划能力优化。针对现有 mRAG 方法检索策略僵化、视觉信息利用不足、冗余搜索严重等问题,论文提出了 E-Agent 智能体框架,并构建了 RemPlan 基准数据集,实现了检索效率与问答准确性的双重提升,为真实场景下的多模态问答提供了高效解决方案。
一、研究背景与核心问题
1.1 研究动机
多模态检索增强生成(mRAG)通过融合外部多模态知识,有效弥补了多模态大语言模型(MLLMs)在时效性、专业领域知识上的局限,广泛应用于新闻分析、热点话题问答等真实场景。但现有 mRAG 方法存在三大核心缺陷:
- 检索策略僵化:采用固定流程(如先图像 caption 再文本检索),无法根据查询特性动态选择模态与工具;
- 视觉信息利用不足:以文本为中心的处理范式,难以直接利用图像特征,导致信息检索不完整;
- 冗余搜索严重:迭代式规划方法(如 OmniSearch)需多次工具调用,计算开销大、 latency 高,且易引入噪声。
1.2 核心问题
- 如何设计动态规划机制,让 mRAG 系统根据查询与图像上下文,自适应选择检索工具与流程?
- 如何构建标准化基准,全面评估 mRAG 系统的规划能力(而非仅关注答案准确性)?
- 如何在提升问答准确性的同时,减少冗余工具调用,实现高效检索?
1.3 研究贡献
- 提出E-Agent 框架:采用 “规划 - 执行” 分离架构,通过单轮动态规划协调多模态工具,平衡准确性与效率;
- 构建RemPlan 基准数据集:首个聚焦 mRAG 规划能力的评估基准,包含 4 类问题与明确的工具调用标注;
- 实证验证优势:在 RemPlan 及 3 个主流数据集上,E-Agent 比 SOTA 方法准确率提升 13%,冗余搜索减少 37%。
二、RemPlan 基准数据集构建
为解决现有 mRAG 评估 “重答案、轻规划” 的问题,论文设计了 RemPlan 基准,专门用于评估系统的动态规划与工具协调能力。
2.1 数据集构建流程
采用 “图像收集 - 问题标注 - 计划生成 - 人工验证” 四阶段流程,确保数据质量与实用性:
- 图像收集:整合真实场景 VQA 数据与网络新闻图像,经自动去重与专家审核,筛选高分辨率、多样化视觉内容;
- 问题标注:标注员针对图像撰写问题,并标记是否需要视觉识别或外部检索;
- 计划生成:利用 GPT-4o 生成标准化 mRAG 执行计划,明确工具调用序列与参数;
- 人工验证:由具备研究生学历与英语高级水平的专家团队,验证计划可行性、问题 - 计划一致性,并标注标准答案。
最终数据集包含 200 个 “图像 - 问题 - 计划 - 答案” 四元组,覆盖真实场景中的多模态检索需求。
2.2 数据集核心特征
(1)四类问题类型
按检索需求分类,全面覆盖 mRAG 场景,比例分布如图 3a 所示:
表格
| 问题类型 | 核心定义 | 示例 | 占比 |
|---|---|---|---|
| 基础型(Fundamental) | 无需外部检索,仅依赖 MLLM 预训练知识即可回答 | “图中男孩乐队来自哪个国家?” | 19% |
| 视觉识别型(Visual-Recognition) | 需图像检索识别实体(人物、地点等),无需文本检索 | “为什么图中男士的背心是橙色的?” | 37% |
| 信息查询型(Information-Seeking) | 需文本检索获取实时 / 专业知识,无需图像检索 | “该景点的门票价格是多少?” | 30% |
| 多维度型(Multi-Faceted) | 需图像检索 + 文本检索协同,复杂推理 | “该球员当前的转会价值是多少?” | 14% |
(2)关键创新:解耦式评估标注
每个样本包含双重标注,实现 “规划能力” 与 “执行效果” 的分离评估:
- 答案标注:基于网络信息的标准答案;
- 计划标注:明确的工具调用序列(如图像检索、文本检索、MLLM 响应)与参数,示例:“image_search (I) → requery (Q’, I) → text_search (Q’) → response (Q, I, ts_res)”。
(3)数据多样性
- 图像多样性:采用香农熵计算图像相似度矩阵,多样性显著高于 MMSearch、Dyn-VQA 等数据集(图 3b);
- 答案长度:平均答案长度更长,更贴近真实场景的详细回答需求。
2.3 评估指标
设计五维评估指标,全面量化规划能力,突破传统仅关注答案准确性的局限:
表格
| 指标 | 核心定义 | 说明 |
|---|---|---|
| 工具精确率 / 召回率(IS-P/IS-R、TS-P/TS-R) | 图像 / 文本检索工具的调用精准度与覆盖度 | 评估工具选择的合理性 |
| 计划准确率(Plan-acc) | 完整规划流程与标注计划的一致性 | 评估整体规划逻辑的正确性 |
| 参数准确率(Param-acc) | 工具调用参数的有效性 | 评估参数设置的合理性 |
| 参数语义相似度(Param-sim) | 生成参数与标注参数的语义一致性 | 评估参数语义的准确性 |
| 答案质量(Ans.) | GPT-4o 评分(0-2 分) | 0 分错误、1 分部分正确、2 分完全正确 |
三、E-Agent 框架设计
E-Agent 采用 “计划 - 执行” 两阶段架构,核心目标是通过单轮动态规划,实现多模态工具的高效协调,避免冗余调用。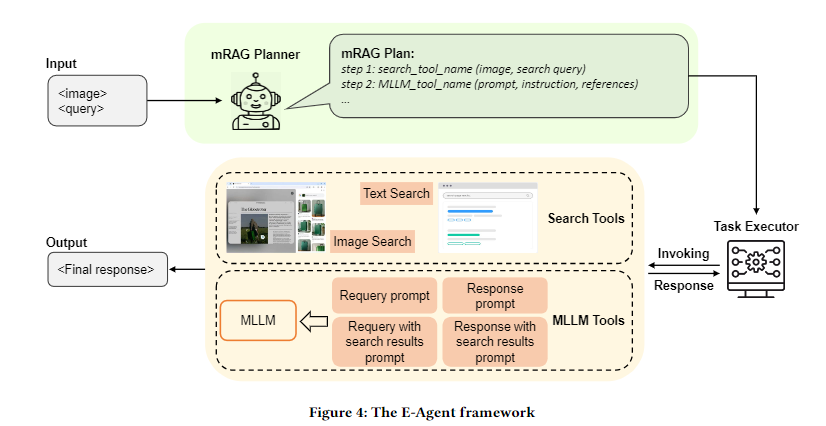
3.1 整体架构
框架包含两大核心模块:mRAG 规划器(mRAG Planner)与任务执行器(Task Executor),流程如图 4 所示:
- 输入:用户查询(文本)+ 图像上下文;
- 规划:mRAG 规划器生成单轮完整 mRAG 计划,明确工具调用序列、参数与 MLLM 功能;
- 执行:任务执行器按计划调用工具,生成最终响应。
3.2 核心模块 1:mRAG 规划器(mRAG Planner)
核心创新在于 “单轮动态规划”,通过一次前向传播完成三大决策:
- 工具选择:决定是否调用图像检索、文本检索,或直接使用 MLLM 响应;
- MLLM 功能配置:指定 MLLM 作为 “重新查询工具(Requery)” 或 “响应工具(Response)”;
- 参数生成:生成工具调用的关键参数(如文本检索关键词、图像检索条件)。
规划器基于 InternVL2-8B 模型,通过 10K “图像 - 问题 - 计划” 样本微调得到,能精准理解多模态上下文并生成优化计划。
3.3 核心模块 2:任务执行器(Task Executor)
负责解析并执行规划器生成的计划,包含四类核心工具,工具调用参数与功能明确:
表格
| 工具类型 | 核心功能 | 应用场景 |
|---|---|---|
| 重新查询工具(Requery) | 结合图像、查询与图像检索结果,生成优化的文本检索关键词 | 多维度型问题,需将视觉实体转化为文本查询 |
| 响应工具(Response) | 整合图像、查询、检索结果,生成最终用户响应 | 所有问题的终端处理,确保回答连贯准确 |
| 图像检索工具(Image Search) | 基于反向图像搜索 API(百度图像搜索),返回相关网页内容 | 视觉识别型问题,识别图像中的实体(人物、地点等) |
| 文本检索工具(Text Search) | 基于关键词的网络检索(Tavily),获取实时 / 专业知识 | 信息查询型问题,补充 MLLM 未掌握的外部知识 |
执行器会根据计划自动选择适配的 MLLM 提示模板,确保工具协同与结果整合的有效性。
3.4 关键优势
- 单轮规划:避免迭代式规划的冗余调用,降低计算开销;
- 工具感知:明确各类工具的功能边界,实现精准调用;
- 多模态协同:直接利用图像检索工具,充分挖掘视觉信息,突破文本中心范式。
四、实验设计与结果
4.1 实验设置
(1)数据集与评估指标
- 核心数据集:RemPlan(规划能力评估);
- 对比数据集:MMSearch、Dyn-VQA(mRAG 专用)、A-OKVQA(传统信息型 VQA);
- 评估指标:RemPlan 采用五维规划指标 + 答案质量,其他数据集采用答案质量(Ans.)或准确率。
(2)模型配置
- MLLM 骨干:Qwen2-VL-72B;
- 规划器:InternVL2-8B(微调后);
- 检索工具:百度图像搜索(图像检索)、Tavily(文本检索);
- 对比方法:Qwen2-VL-72B(无检索)、MMSearch(静态 mRAG)、OmniSearch(迭代式动态 mRAG)。
4.2 核心实验结果
(1)RemPlan 基准上的表现
表 2 与表 3 展示了 E-Agent 与对比方法的性能与工具调用情况:
表格
| 方法 | 答案质量(Ans.) | 计划准确率(Plan-acc) | 平均工具调用次数 |
|---|---|---|---|
| Qwen2-VL-72B | 1.09 | - | 0(无检索) |
| MMSearch | 0.55 | - | 2.00(检索)+3.00(MLLM) |
| OmniSearch | 0.82 | 0.49 | 1.96(检索)+1.96(MLLM)+2.96(规划器) |
| E-Agent-fewshot | 1.23 | 0.32 | 1.05(检索)+1.77(MLLM) |
| E-Agent-sft | 1.25 | 0.86 | 1.05(检索)+1.54(MLLM) |
关键结论:
- E-Agent-sft 在答案质量与计划准确率上均居首位,计划准确率达 86%,远超 OmniSearch 的 49%;
- 工具调用次数显著减少:检索工具调用从 2.0 次降至 1.05 次,MLLM 调用从 3.0 次降至 1.54 次,冗余搜索大幅减少。
(2)不同问题类型的表现
- 基础型问题:E-Agent 表现最优(Ans.1.65),而 MMSearch/OmniSearch 因冗余检索引入噪声,性能低于纯 MLLM;
- 视觉识别型 / 信息查询型问题:E-Agent 凭借精准工具选择,答案质量分别达 1.17、1.00,显著超越对比方法;
- 多维度型问题:虽因复杂度高表现略低(Ans.0.89),但仍领先于所有对比方法。
(3)其他数据集的泛化性验证
表格
| 数据集 | 方法 | 答案质量 / 准确率 | 平均检索工具调用次数 |
|---|---|---|---|
| Dyn-VQA | E-Agent-sft | 0.89(Ans.) | 1.26 |
| Dyn-VQA | OmniSearch | 0.82(Ans.) | 2.03 |
| MMSearch | E-Agent-sft | 0.76(Ans.) | 1.42 |
| MMSearch | MMSearch | 0.65(Ans.) | 2.00 |
| A-OKVQA | E-Agent-sft | 88%(准确率) | 0.13 |
| A-OKVQA | Qwen2-VL-72B | 88%(准确率) | 0.00 |
关键结论:
- E-Agent 在 mRAG 专用数据集(Dyn-VQA、MMSearch)上均实现 SOTA,且工具调用次数减少 38%-49%;
- 在传统 VQA 数据集(A-OKVQA)上,E-Agent 准确率与纯 MLLM 持平(88%),但检索工具调用仅 0.13 次,避免了过度检索的性能损耗。
4.3 案例分析
(1)成功案例
问题:“该人物目前效力于哪支俱乐部?”
- 计划:图像检索(识别人物)→ 重新查询(生成关键词)→ 文本检索(获取转会信息)→ 响应(整合结果);
- 结果:正确识别球员为杨政,检索到其 2024 年 CBA 选秀加盟四川金强蓝鲸俱乐部,回答准确。
(2)失败案例
- 案例 1(工具执行失败):问题 “该瀑布高度多少米?”,计划正确但图像检索错误(误判瀑布为安赫尔瀑布),导致答案错误;
- 案例 2(规划失败):问题 “该食物适合减脂期食用吗?”,规划器未调用图像检索识别食物,也未检索营养信息,MLLM 无法给出确定答案。
案例证明:E-Agent 的规划能力关键,但工具执行质量(如检索准确性)也直接影响最终结果。
五、相关工作对比
表格
| 研究方向 | 代表工作 | 核心差异 |
|---|---|---|
| 静态 mRAG 方法 | MMSearch | 固定检索流程,无动态规划,冗余调用多 |
| 迭代式 mRAG 方法 | OmniSearch | 迭代式规划, latency 高,计算开销大 |
| 多模态 VQA 基准 | A-OKVQA、INFOSEEK | 仅关注答案准确性,无规划能力评估 |
| 本研究(E-Agent+RemPlan) | - | 单轮动态规划 + 规划能力专用基准,平衡准确性与效率 |
六、局限性与未来方向
6.1 局限性
- 复杂推理能力不足:单轮规划难以处理多跳推理任务,缺乏中间验证步骤;
- 工具依赖性强:依赖预定义工具集,难以适配新增多模态工具;
- 数据集规模较小:RemPlan 仅含 200 个样本,需扩大规模以提升评估可靠性。
6.2 未来方向
- 层级化规划:设计 “高层策略 + 低层调整” 架构,支持复杂多跳推理;
- 动态反思模块:引入检索反馈机制,实时优化规划;
- 自适应工具管理:支持新增工具的自动适配与集成;
- 扩展 RemPlan 规模:增加更多领域、更多复杂场景的样本。
七、结论
E-Agent 通过 “单轮动态规划 + 工具感知执行” 的创新架构,有效解决了现有 mRAG 系统的僵化与冗余问题。其核心优势在于:通过 mRAG 规划器实现多模态工具的自适应协调,在提升问答准确性的同时减少冗余调用;配套的 RemPlan 基准填补了 mRAG 规划能力评估的空白,为该领域的标准化研究提供了关键工具。
实验证明,E-Agent 在多个数据集上均显著超越现有方法,准确率提升 13%、冗余搜索减少 37%,为真实场景下的多模态问答提供了高效、可靠的解决方案。未来通过层级化规划与动态反思模块的优化,有望进一步提升复杂推理能力,拓展应用场景。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 9
9 0
0- 0



 已为社区贡献33条内容
已为社区贡献33条内容

所有评论(0)