多变量电价预测实战:随机森林递推建模
多变量电价预测实战:随机森林递推建模

导读
上一篇文章我们围绕 predict_power.py 讲了一条 Chronos 风格的单变量预测链路:
只用历史电价序列作为上下文,调用预训练模型去预测未来走势。
但在真实业务里,很多人很快就会遇到一个更现实的问题:
电价真的只由历史电价自己决定吗?
通常不是。
在电价预测场景中,价格往往还会受到很多外部因素影响,例如:
- 当前负荷水平
- 工作日与周末差异
- 日内峰平谷时段
- 时间周期特征
- 最近一段价格的惯性和波动状态
也正因为如此,项目里又新增了一份 predict_power_multivariate.py 脚本。它不再走 Chronos 预训练推理路线,而是切换到一条更偏监督学习的方案:
用多变量特征作为输入,用随机森林回归器预测单一目标 price,并通过递推方式完成未来 96 个 15 分钟点的电价回测。
如果你正好在思考下面这些问题,这篇文章会适合你:
- 为什么单变量脚本不一定够用
- 多变量输入到底应该怎么构造
- 随机森林为什么也能做时间序列预测
- 什么叫递推式多步预测
- 这类脚本为什么离真实生产更近,但又还不够
一、先说结论:这份脚本和 predict_power.py 的差别到底在哪
最核心的差别只有一句话:
predict_power.py是 单变量 + 预训练模型推理predict_power_multivariate.py是 多变量 + 监督学习回归
这意味着两份脚本解决问题的方式完全不同。
predict_power.py 的思路
- 输入:历史价格序列
- 核心模型:Chronos 预训练模型
- 目标:不重新训练,直接推理未来
predict_power_multivariate.py 的思路
- 输入:负荷、分时标签、工作日信息、时间周期特征、历史价格滞后特征
- 核心模型:
RandomForestRegressor - 目标:显式构造特征,训练一个监督学习模型来预测
price
所以如果你问“多变量脚本相较于单变量脚本,到底多了什么”,答案其实很直接:
它多了“解释世界的变量”,而不再只靠价格自己去解释价格。
二、这份脚本为什么选择随机森林
很多人看到时间序列预测,会自然想到:
- LSTM
- GRU
- Transformer
- 时序大模型
但这份脚本没有继续上深度学习,而是选了:
RandomForestRegressor
这不是退步,而是很典型的工程取舍。
1. 它对表格型特征非常友好
这份脚本的输入,本质上已经不是“裸时间序列”,而是经过特征工程整理后的表格数据。
在这种场景下,随机森林本来就是一个非常务实的基线模型。
2. 它不依赖复杂训练过程
你不需要:
- 设计神经网络结构
- 调学习率
- 配训练轮数
- 处理显卡训练过程
对很多原型项目来说,这意味着更低的试错成本。
3. 它天然适合先做“有用的基线”
很多项目一开始就想用最复杂的模型,结果反而忽略了一个事实:
如果一个随机森林基线都做不出稳定效果,更复杂的模型往往也不会 magically 把问题解决掉。
因此,从工程角度看,随机森林非常适合作为多变量电价预测的第一站。
三、代码里到底构造了哪些输入特征
这份脚本最值得看的,其实不是模型本身,而是特征工程。
它把输入特征拆成了两大类:
- 当前时刻可直接获得的外生变量
- 基于历史价格构造的滞后与滚动统计特征
1. 外生变量:解释“此时此刻是什么环境”
在 build_known_feature_dict() 中,脚本构造了这些特征:
load_mwinterval_15mis_workdayhour_sinhour_cosdow_sindow_cosmonthperiod_type的 one-hot 编码
这几类特征分别解决不同问题。
load_mw
这是最关键的外生变量之一。
对电价来说,负荷通常不只是一个相关特征,而往往是最核心的驱动因子之一。
interval_15m
这是日内位置特征。
它告诉模型当前是一天中的第几个 15 分钟点,这对峰谷规律建模非常重要。
is_workday
工作日和周末的价格行为通常不同。
这个字段相当于给模型补了一层最基础的业务日历。
hour_sin/hour_cos、dow_sin/dow_cos
这里用的是周期编码,而不是直接把小时、星期几作为整数硬塞进去。
这样做的原因是:
- 23 点和 0 点在业务上其实很接近
- 星期日和星期一在时间周期上也是相邻的
如果直接用整数编码,模型不一定能自然理解这种周期邻近关系;而正余弦编码能更平滑地表达周期结构。
period_type one-hot
valley / flat / peak / critical_peak 这类时段标签,本质上是在给模型补一层规则知识:
- 当前是不是低谷
- 当前是不是峰段
- 当前是不是尖峰
这类信息在电价场景里通常非常有价值。
2. 价格滞后特征:解释“价格本身刚刚发生了什么”
脚本在 build_lag_feature_dict() 中又构造了另一组特征:
price_lag_1price_lag_4price_lag_8price_lag_16price_lag_96
以及滚动统计:
price_roll_mean_4price_roll_mean_16price_roll_mean_96price_roll_std_4price_roll_std_16price_roll_std_96
再加上两个变化量:
price_change_lag_1price_change_lag_4
这组特征解决的是另一个问题:
就算你知道当前负荷、时段和工作日信息,你仍然需要知道价格最近是往上走、往下走,还是在高波动状态里。
所以外生变量和目标滞后特征不是二选一,而是互补关系。
四、训练样本是怎么构造出来的
时间序列监督学习里,一个非常常见的误区是“有数据就能直接喂给模型”。
事实上,监督学习模型需要的是清晰定义的“特征-标签”对。
这份脚本在 build_train_dataset() 里完成了这件事。
样本的定义方式
对于训练区间中的每一个时刻 t:
- 标签是当前时刻的真实
price - 特征由两部分组成:
- 当前时刻已知的外生变量
- 当前时刻之前的历史价格特征
这意味着模型学到的是:
在当前这一组外生环境和历史价格状态下,此刻的电价大概率会是多少
为什么有 warmup
脚本里有一行:
warmup = max(PRICE_LAGS + ROLLING_WINDOWS)
当前取值实际上是 96。
它的作用很简单:
因为你要构造 price_lag_96 和 price_roll_mean_96 这类特征,所以在序列最开始的那一段,历史长度还不够,根本无法生成完整特征。
因此必须先跳过这部分样本。
这是一种非常典型而且必要的时序监督学习处理方式。
五、什么叫“递推式多步预测”
这份脚本最有工程含义的一段,不在训练,而在预测阶段的 recursive_predict()。
这里采用的是 递推式多步预测。
它的逻辑是:
- 先预测未来第 1 个点
- 把这个预测值追加到历史价格序列里
- 再用更新后的历史去预测未来第 2 个点
- 如此循环,直到把未来 96 个点都预测出来
这就是为什么代码里会有:
history_prices.append(prediction)
递推式预测的好处
- 实现简单
- 只需要训练一个一步式回归器
- 很适合做多步预测原型
递推式预测的代价
它最大的问题是 误差会传递。
一旦前面某一步预测偏了,后面使用这个预测值作为滞后输入时,就会继续把偏差带下去。
因此预测 horizon 越长,误差累积风险通常越大。
这也是多步预测里最典型的工程难点之一。
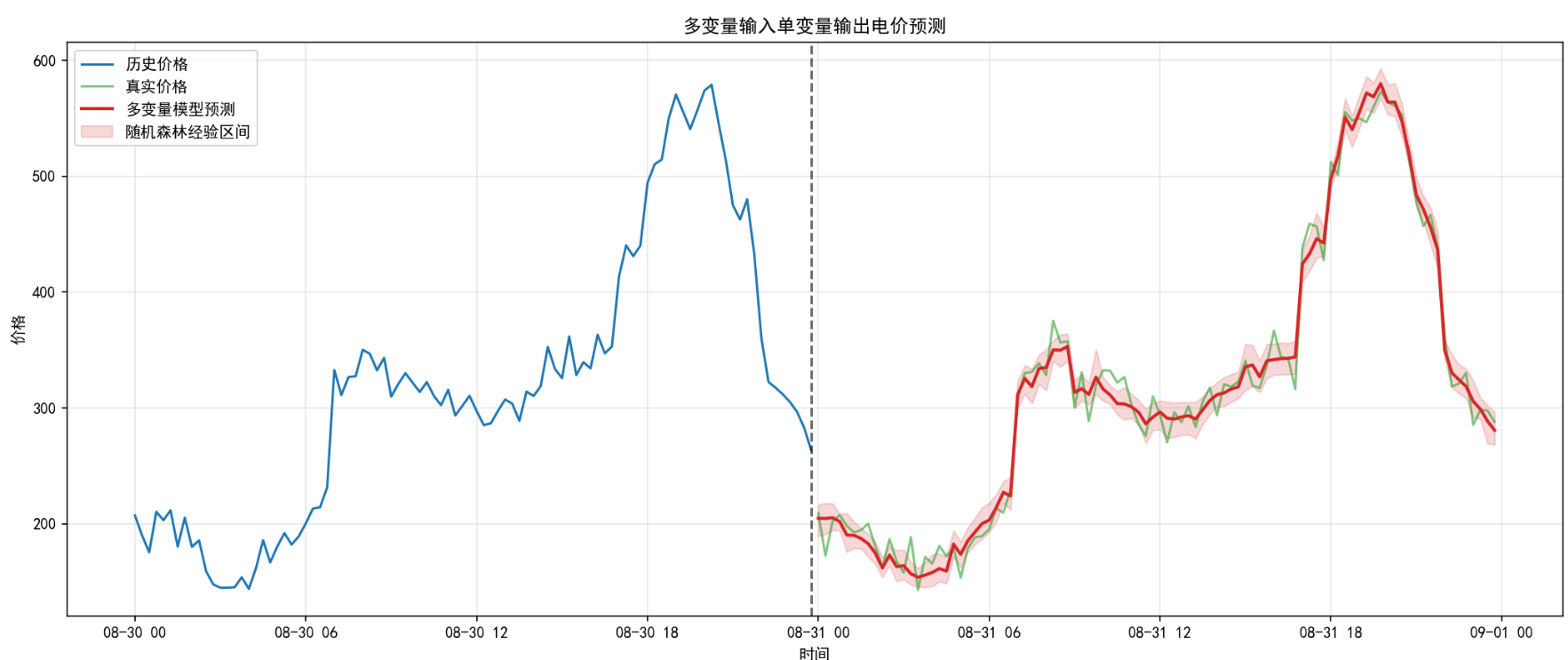
六、为什么这份脚本能给出“区间”,即使它不是概率模型
很多人第一次看到这份脚本时,会问一个问题:
随机森林不是普通回归器吗?为什么这里还能画出上下区间?
答案在这段实现里:
tree_predictions = np.array([tree.predict(x_step_np)[0] for tree in model.estimators_], dtype=float)
low = float(np.quantile(tree_predictions, 0.1))
high = float(np.quantile(tree_predictions, 0.9))
它不是像 Chronos 那样输出真正意义上的概率分位数,而是:
- 把随机森林里每棵树对同一个样本的预测值取出来
- 再对这些树的预测结果做经验分位数统计
从严格意义上说,这不是完整的概率预测框架;但从工程展示和不确定性粗估的角度看,它是一个非常实用的近似方案。
你可以把它理解成:
不是模型给了我们一个严格置信区间,而是我们利用森林内部多棵树的分歧程度,近似刻画了一下预测的不确定性。
七、评估指标为什么比单变量脚本更多
这份脚本在结尾同时输出了三类指标:
MAERMSEMAPE
相比单变量 Chronos 脚本只输出 MAE,这里明显更完整。
MAE
适合回答“平均偏差大概有多大”。
RMSE
对大误差更敏感,适合看模型是否在某些时段出现严重偏差。
MAPE
适合从相对误差角度理解预测质量,尤其在不同价格水平之间比较时更直观。
对一个多变量监督学习脚本来说,这三个指标一起看会比只看 MAE 更合理。
八、这份脚本为什么更接近真实业务,但还不能等同于真实生产
这是理解这份代码最重要的一层。
和 predict_power.py 相比,这份脚本显然更接近业务,因为它已经开始显式使用:
- 负荷
- 工作日
- 分时标签
- 时间周期
这说明它不再把电价看成“只和自己有关”的目标。
但它仍然不能直接等同于真实未来生产预测,原因在于:
它在测试区间里使用了真实未来协变量
例如:
- 测试区间的
load_mw - 测试区间的
period_type - 测试区间的
is_workday
其中像 is_workday、interval_15m 这类未来信息,是可以提前知道的;
但像 load_mw 这类特征,在真实未来时刻并不天然已知,通常需要先做负荷预测。
这意味着当前多变量脚本回答的问题更准确地说是:
如果未来协变量已知,随机森林能把电价预测到什么程度?
这个问题有价值,但它仍然比真实生产场景更理想化。
九、这份脚本最适合扮演什么角色
从工程视角看,我认为它最适合扮演三种角色。
1. 单变量模型的对照基线
如果你已经有了 predict_power.py 这样的单变量基线,那这份多变量脚本可以直接帮助你回答:
加入外生变量之后,误差有没有明显下降?
2. 真实业务特征的第一轮验证器
很多时候,团队会知道“负荷可能很重要”,但不知道重要到什么程度。
这份脚本能很快验证特征工程是否带来实际收益。
3. 后续复杂模型的基准参照物
未来你无论是继续上:
- XGBoost / LightGBM
- 更复杂的时序网络
- Chronos-2 协变量方案
都应该先和这类“够强但不复杂”的基线对比。
如果复杂模型还跑不过这个基线,那往往不是模型不够新,而是问题定义还没理顺。
十、如果继续往下做,下一步最值得优化什么
如果你准备继续把这条路线做深,我建议优先优化这三件事。
1. 先把未来协变量问题解决掉
尤其是 load_mw。
真实未来里,这个字段通常要先预测,再送给电价模型。
2. 再把回测方式做严谨
当前脚本仍然主要是单次尾部回测。
如果要认真评估模型稳定性,应该做多窗口、滚动式验证。
3. 再考虑换更强模型
在这之前,先把:
- 特征定义
- 回测方式
- 未来信息边界
理清楚,往往比直接更换模型更重要。
结语
predict_power_multivariate.py 的价值,并不在于它已经是“最终答案”,而在于它帮我们把一个非常重要的工程问题讲清楚了:
电价预测如果想更接近真实业务,就不能只看价格本身,而要把影响价格的环境变量一起放进来。
这份脚本用一套非常务实的方式实现了这件事:
- 用随机森林做回归
- 用多变量特征解释价格
- 用递推方式完成多步预测
- 用多指标和图表一起评估结果
如果说 predict_power.py 是“把预测流程跑起来”,那么 predict_power_multivariate.py 更像是“开始把预测问题讲得更像业务问题”。
这也是为什么我非常建议,任何想把时间序列预测往业务方向推进的人,都至少应该做一版这样的多变量基线。
预测效果图
读者互动 & 获取源码
-
如果你在阅读、写作、整理资料过程中,需要定制其他小工具,欢迎在公众号「码海寻道」后台留言,我会尽量安排。
-
获取源码:
-
在公众号「码海寻道」后台回复 “电价预测2”,即可获得项目源码链接。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 10
10 0
0- 0



 已为社区贡献25条内容
已为社区贡献25条内容

所有评论(0)