大模型底层生成原理(基于Transformer框架)
示例图:
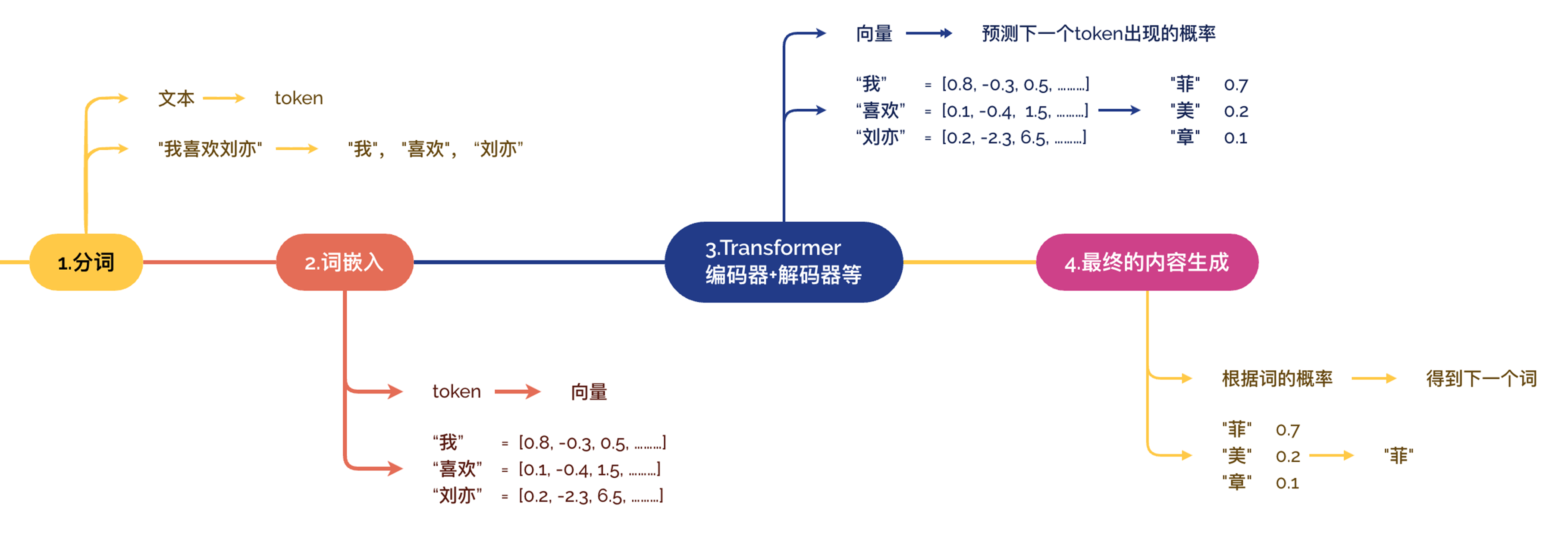
1. 分词(Tokenization)
1.1 分词的作用以及过程
将输入文字分割成模型输入的最小单位,即token。后续每个token会进行词嵌入转换成向量矩阵,然后通过Transformer架构不断预测下一个token,最终生成完整回答。
- 过程: 输入文本(例如:"Hello world")被分词器(Tokenizer)切分成一个个片段。
- 例子:
"Hello world"→["Hello", " world"] - 映射: 每个 Token 被映射为一个唯一的整数 ID(基于词表 Vocab)。
"Hello"→15496" world"→3186
- 输出: 一个整数序列
[15496, 3186]。
举个中文分词的例子:
测试句子:“中华人民共和国成立于 1949 年。”
Qwen 分词器极有可能将其切分为 5 到 7 个 Token。以下是一种典型的切分方式:
| Token 内容 | 推测 Token ID | 说明 |
|---|---|---|
中华人民共和国 |
(例如 12345) | 1 个 Token。这是高频专有名词,直接被收入词表。 |
成立 |
(例如 6789) | 1 个 Token。高频动词。 |
于 |
(例如 101) | 1 个 Token。高频介词。 |
1949 |
(例如 2024) | 1 个 Token。数字通常整体编码。 |
年 |
(例如 303) | 1 个 Token。高频量词。 |
。 |
(例如 505) | 1 个 Token。标点符号。 |
1.2 为什么会分词成这个,背后使用的算法?
核心算法是 BPE(Byte Pair Encoding,字节对编码)
BPE 的核心思想非常简单:“出现频率最高的相邻字符对,优先合并”。
分词器的构建过程(注意:是分词器的构建,不是大模型的训练),就是一个不断合并字符的过程。
模拟分词器构建过程:
假设我们的训练数据里有 1 亿篇中文新闻,其中“中华人民共和国”这个词出现了 500 万次。
-
初始状态(Level 0): 所有文本都被拆成最小的单元(字节或字符)。 序列:
['中', '华', '人', '民', '共', '和', '国', ...]此时,每个字都是一个 Token。 -
第 1 轮统计与合并: 算法统计所有相邻字符对的频率。
('中', '华')出现了 500 万次。('的', ' ')出现了 800 万次。- ... 假设
('的', ' ')频率最高,它们先合并成的。 接着,('中', '华')频率也很高,被合并成中华。 现在序列变成了:['中华', '人', '民', '共', '和', '国', ...]
-
第 2 轮统计与合并: 继续统计新的相邻对。
('中华', '人')现在出现了 500 万次(因为“中华”已经绑定了)。- 如果这个频率在当前剩余的对子里是最高的,它们就会合并成
中华人。 - 同理,
('民', '共')可能合并成民共(如果频率够高)。
-
第 N 轮合并(直到词表满): 这个过程不断重复。
中华人+民→中华人民中华人民+共和国→中华人民共和国
注意:终止条件通常是词表的大小
最终结果: 如果在分词器构建结束前,这个合并链条没有被中断,且词表还有空间,那么 中华人民共和国 就会作为一个整体被写入词表(Vocab),分配一个唯一的 ID。
2. 嵌入(Embedding)
2.1 词嵌入
词嵌入将整数序列 [15496, 3186](即Token ID),通过嵌入矩阵(Embedding Table)映射为实数向量矩阵(如 768 维或 4096 维)。
嵌入矩阵(Embedding Table):矩阵里的数字初始是随机的。在训练过程中,通过反向传播不断更新,使得语义相近的词(如“猫”和“狗”),它们的向量在空间中的距离(余弦相似度)更近。训练完成后,矩阵参数固定,推理时直接查表使用。
推理时使用过程如下:
- 查找: 模型有一个巨大的嵌入矩阵,形状为
(词表大小,向量维度),例如:词表 15 万,隐藏层维度 4096 → 矩阵大小150,000 × 4,096。 - 操作: 根据输入的整数序列 ID 查表,取出对应的向量。
- 输出: 形状为
(N, d_model)的矩阵 X 。- N = 分词后Token 数量(整数序列长度)
d_model= 嵌入矩阵的向量维度(如 4096)
2.2 位置嵌入(Positional Encoding)
为什么需要位置编码?
Transformer 的核心是 Self-Attention(自注意力机制),自注意力机制是 排列不变(Permutation Invariant) 的。
数学角度:

注意:这里的QK相乘,会得到注意力分数矩阵,这个矩阵里面,每个token只关注自己所在的一行,如果没有位置信息,这个顺序你随意变换是没有任何影响的,有了位置信息你变换位置计算的注意力分数矩阵就会不一样。
直观案例:“猫吃鱼”vs“鱼吃猫”
假设我们有两个句子,词嵌入完全相同(没有位置编码):
- 句子 1:
[猫,吃,鱼] - 句子 2:
[鱼,吃,猫] -
对于“吃”这个 Token,(仅针对这个字,其他字计算注意力机制是没有影响的):
- 在句子 1 中,“吃”会去计算它和“猫”的相似度,以及它和“鱼”的相似度。
- 在句子 2 中,“吃”依然会去计算它和“猫”的相似度,以及它和“鱼”的相似度。
- 结果: “吃”这个词最终生成的向量表示(Output Vector)在两个句子里是完全一样的。
-
对于“猫”这个 Token:
- 在句子 1 中,“猫”是主语,它关注“吃”。
- 在句子 2 中,“猫”是宾语,它依然关注“吃”(猫所在行的向量没变,相似度没变)。
- 结果: 模型无法区分“猫”是施动者还是受动者。
后果: 模型认为 [猫,吃,鱼] 和 [鱼,吃,猫] 表达的是同一个意思。这显然违背了语言逻辑。
嵌入过程如下:
- 操作: 给每一个token生成一个位置向量(如第 1 个词是 [1,0,0...] (维度和上面词嵌入的维度一直,1*4096维),第 2 个词是 [0,1,0...] 或更复杂的 RoPE 旋转编码)。
- 融合(就是相加): 将位置向量加到输入嵌入向量 X 上,Hinput=Etoken+Epos。
- 结果: : 输出相加结果Hinput(保持不变4096 维)。
- 原理: 虽然向量混合了,但模型具有强大的拟合能力,可以在后续层中将“语义”和“位置”信息解耦(Disentangle)
位置编码方式有三个大方向:绝对位置编码、相对位置编码和旋转位置编码
| 编码方式 | 核心思想 | 实现方式 | 典型模型 | 外推能力 |
|---|---|---|---|---|
| 绝对位置编码 | 为每个位置赋予唯一向量,加到词嵌入上 | 正弦/余弦函数 或 可学习嵌入 | Transformer, BERT, GPT | 正弦函数可外推,可学习嵌入不可外推 |
| 相对位置编码 | 在注意力计算中引入相对位置偏置 | 可学习的相对嵌入或函数 | Transformer-XL, Shaw et al. | 通常可处理任意长序列 |
| 旋转位置编码 | 通过旋转矩阵使内积包含相对位置 | 对 Query/Key 进行二维旋转 | LLaMA, PaLM, GPT-NeoX | 良好外推性 |
3. Transformer架构训练以及底层原理
论文:Attention Is All You Need arxiv.org/pdf/1706.03762https://arxiv.org/abs/1706.03762arxiv.org/pdf/1706.03762
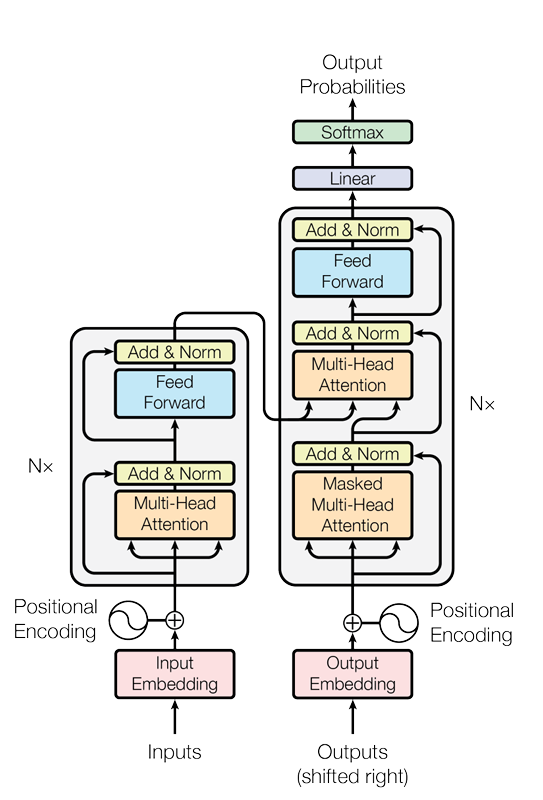
matmul 是 Matrix Multiplication(矩阵乘法)
标准的 Transformer 分为 Encoder(编码器) 和 Decoder(解码器),但现代大模型(如 GPT, Llama)大多采用 Decoder-only 架构。
3.1 标准的 Transformer架构
1. 输入层
-
Tokenization:将文本切分为 Token(如 BPE, WordPiece)。
-
Embedding:将 Token 映射为稠密向量。
-
Position Embedding:注入位置信息。
2. Encoder (用于理解任务,如 BERT)
-
Masked Self-Attention:双向注意力,每个词可以看到所有词。
-
Feed-Forward Network (FFN):两个线性层中间加激活函数(GELU/ReLU),对每个位置独立处理,增加非线性能力。
-
堆叠:通常 6-12 层。
3. Decoder (用于生成任务,如 GPT)
-
Masked Self-Attention (Causal Mask):关键区别。使用上三角矩阵掩码,确保位置 t 只能看到 0…t 的词,不能看到未来。这是自回归生成的基础。
-
Cross-Attention(仅 Encoder-Decoder 架构有):Decoder 的 Q 来自上一步输出,K, V 来自 Encoder 输出。用于机器翻译等任务。
-
FFN:同 Encoder。
4. 输出层
-
Linear Projection:将隐藏层向量映射到词表大小 (Vocab Size)。
-
Softmax:计算下一个 Token 的概率分布。
3.2 为什么现代 LLM 首选 Decoder-only 架构?
A. 任务天然契合(自回归生成)
LLM 的核心能力是 Chat(对话) 和 Completion(续写)。
- 这本质上是 P(xt∣x<t) 的概率预测问题。
- Decoder 结构天然带有 Causal Mask(因果掩码),强制模型只能利用过去的信息预测未来,这完美契合“生成”任务。
- Encoder-Decoder 架构虽然也能做生成,但它的优势在于“理解源序列 + 生成目标序列”(如翻译),对于单纯的对话任务,Encoder 部分显得冗余。
B. 推理效率与 KV Cache
- Decoder-only:在推理时,每一个新生成的 Token,只需要计算一次 Attention。由于结构统一,KV Cache(键值缓存) 技术非常容易实现,极大地加速了推理。
- Encoder-Decoder:推理时需要先跑一遍 Encoder 编码 Prompt,再跑 Decoder。虽然也可以缓存,但架构更复杂,显存管理更麻烦。
C. 扩展性(Scaling Laws)
- 业界经验表明(如 GPT-3, Chinchilla 论文),在同样的参数量和数据量下,Decoder-only 架构在通用语言任务上的扩展性更好。
- 去掉 Encoder 和 Cross-Attention 层,减少了计算图的复杂度,使得在有限的显存下可以堆叠更多的层数或增加更大的隐藏层维度。
D. 训练数据的利用
- Decoder-only 可以直接在原始文本上进行训练(从左读到右)。
- Encoder-Decoder 通常需要构造“输入 - 输出”对(例如把一句话的前半段当输入,后半段当输出),数据处理相对麻烦一些(虽然也可以做,但 Decoder-only 更直接)。
3.3 大模型Decoder-only 架构训练和推理过程
答案的核心在于 因果掩码(Causal Mask) 和 并行计算。
下面我将基于你的例子 ["I", "love", "AI", "<eos>"],一步步拆解训练时的前向传播(Forward)、**损失计算(Loss)和反向传播(Backward)**全过程。
第一步:数据构造(Input & Label)
训练的本质是监督学习。我们需要构造“题目”和“答案”。
- Input (题目):
[I, love, AI, <eos>]- 这是模型实际看到的输入。
- Label (答案):
[love, AI, <eos>, <pad>]- 这是我们希望模型输出的目标。
- 注意:Label 是 Input 向右移动一位。
- <pad>:最后一个位置没有“下一个词”了,所以通常计算 Loss 时会忽略这个位置。
第二步:前向传播(Forward Pass)—— 并行计算
这是最关键的一步。虽然推理是串行的,但训练是并行的。模型一次性处理整个序列。
1. Embedding 层
模型首先将 Input 中的每个 Token 转化为向量,并加上位置编码。 X=[I,love,AI,<eos>] 此时,X 是一个 4×dmodel 的矩阵(假设序列长度 4,隐藏层维度 dmodel )。
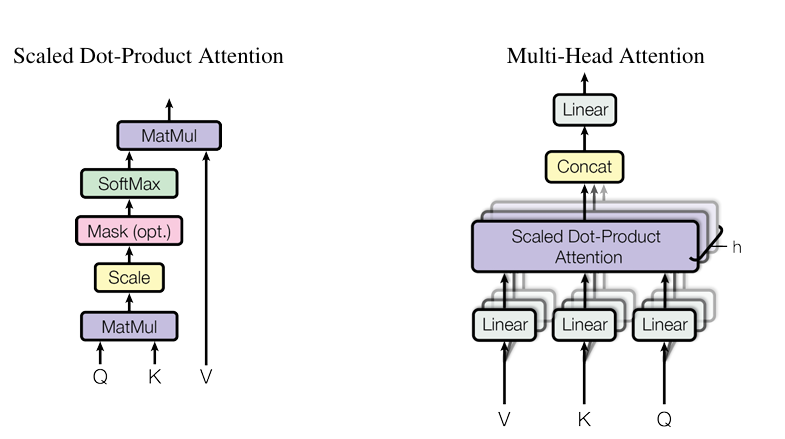
2. Self-Attention 层(核心魔法)
模型计算 Q, K, V。如前所述,它们都来自 X 。 Q=XWQ,K=XWK,V=XWV
接下来计算注意力分数 QKT 。此时得到一个 4×4 的矩阵。如果没有掩码,每个词都能看到所有词。 为了模拟“只能看过去”,我们应用 Causal Mask(因果掩码)。
掩码矩阵示意(1 表示可见,0 表示屏蔽):
| 查询 \ 键 | I (1) | love (2) | AI (3) | <eos> (4) |
|---|---|---|---|---|
| I (1) | 1 | 0 | 0 | 0 |
| love (2) | 1 | 1 | 0 | 0 |
| AI (3) | 1 | 1 | 1 | 0 |
| <eos> (4) | 1 | 1 | 1 | 1 |
- 第 1 行 (对应 "I"):只能看到 "I"。
- 任务:基于 "I" 的信息,预测下一个词。
- 目标:对应 Label 的第 1 位
"love"。
- 第 2 行 (对应 "love"):能看到 "I" 和 "love"。
- 任务:基于 "I love" 的上下文,预测下一个词。
- 目标:对应 Label 的第 2 位
"AI"。
- 第 3 行 (对应 "AI"):能看到 "I", "love", "AI"。
- 任务:基于 "I love AI" 的上下文,预测下一个词。
- 目标:对应 Label 的第 3 位
"<eos>"。
- 第 4 行 (对应 "<eos>"):能看到全部。
- 任务:预测结束后的词。
- 目标:对应 Label 的第 4 位
"<pad>"(通常忽略 Loss)。
经过 Softmax 和加权 V 后,模型输出了 4 个隐藏状态向量 H=[h1,h2,h3,h4] 。
- h1 包含了预测 "love" 所需的信息。
- h2 包含了预测 "AI" 所需的信息。
- h3 包含了预测 "<eos>" 所需的信息。
3. 输出层 (Logits)
最后,通过线性层将隐藏状态映射到词表大小(假设词表只有 5 个词方便理解): Logits=H⋅Wout 输出形状为 4×VocabSize 。这意味着模型同时给出了 4 个位置的预测概率分布。
第三步:损失计算(Loss Calculation)
现在模型输出了 4 组概率,我们需要检查它猜得对不对。
- 位置 1 预测:模型认为下一个词是 "love" 的概率是 P1 。
- 真实 Label:
"love"。 - Loss 1:交叉熵损失 −log(P1) 。
- 真实 Label:
- 位置 2 预测:模型认为下一个词是 "AI" 的概率是 P2 。
- 真实 Label:
"AI"。 - Loss 2:交叉熵损失 −log(P2) 。
- 真实 Label:
- 位置 3 预测:模型认为下一个词是 "<eos>" 的概率是 P3 。
- 真实 Label:
"<eos>"。 - Loss 3:交叉熵损失 −log(P3) 。
- 真实 Label:
- 位置 4 预测:忽略(因为 Label 是
<pad>,没有实际意义)。
总 Loss: Total Loss=3Loss1+Loss2+Loss3
关键点: 通过一次前向传播,我们实际上完成了 3 个训练样本 的学习:
- 样本 1: Context="I", Target="love"
- 样本 2: Context="I love", Target="AI"
- 样本 3: Context="I love AI", Target="<eos>"
这就是为什么 Transformer 训练效率比 RNN 高得多的原因:RNN 必须串行算 3 次,Transformer 并行算 1 次。
第四步:反向传播(Backward Pass)
- 计算梯度:根据 Total Loss,计算损失函数对每个参数的梯度(∂W∂Loss )。
- 这包括 WQ,WK,WV (注意力权重)。
- 包括 WFFN (前馈网络权重)。
- 包括 Wout (输出层权重)。
- 包括 Embedding 权重。
- 更新参数:使用优化器(如 AdamW)更新参数。 Wnew=Wold−LearningRate×Gradient
- 效果:
- 如果位置 1 没预测对 "love",梯度会传回,调整 WQ,WK 等,让 "I" 的向量表示在未来能更倾向于关联到 "love"。
- 如果位置 2 没预测对 "AI",梯度会调整模型,让 "I love" 的上下文组合能更倾向于 "AI"。
第五步:为什么训练时“并行”不影响推理时“串行”?
这是最容易混淆的地方。
- 训练时:我们用 Mask 强行模拟了“只能看过去”的环境。模型参数 W 学到的规律是:“在只能看到前文的情况下,下一个词最可能是什么”。
- 推理时:我们真的只给模型前文(例如只给 "I"),模型根据训练好的 W ,算出下一个词 "love"。然后把 "I love" 再喂进去,算出 "AI"。
- 一致性:因为训练时 Mask 的存在,模型从来没有见过未来,所以它在推理时即使真的没有未来数据,也能正常工作。如果训练时不用 Mask,模型就会“作弊”偷看答案,推理时一旦没有答案可看,模型就废了。
总结图解
训练步骤全景图 (基于 "I love AI <eos>")
1. 输入:[I, love, AI, <eos>]
| | | |
v v v v
2. 并行计算 (带 Mask):
- 位置 1 (I) : 只关注 [I] --> 输出分布 1 --> 对比 Label "love"
- 位置 2 (love) : 只关注 [I, love] --> 输出分布 2 --> 对比 Label "AI"
- 位置 3 (AI) : 只关注 [I, love, AI]--> 输出分布 3 --> 对比 Label "<eos>"
- 位置 4 (<eos>): 只关注 [全部] --> 输出分布 4 --> 忽略 (Label <pad>)
3. 计算 Loss:
Loss = (Loss_1 + Loss_2 + Loss_3) / 3
4. 反向传播:
更新所有权重 (Q, K, V, FFN...),让下次预测更准。通过这种方式,Decoder-only 模型在海量文本上不断重复这个过程,最终学会了语言的语法、逻辑和世界知识。
4、生成token以及结束
大模型(LLM)的生成过程(推理/Inference)与训练过程截然不同。训练是并行的(一次性看全文),而生成是串行的(一个字一个字蹦)。
以下详细解析 生成流程、核心优化(KV Cache)、采样策略 以及 停止条件。
4.1 大模型生成流程(Step-by-Step)
生成过程是一个 自回归(Autoregressive) 的循环。假设用户输入提示词(Prompt):"请介绍一下"。
1. 预处理(Prefill 阶段)
-
Tokenization:将 Prompt
"请介绍一下"切分为 Token 序列,例如[请,介绍,一,下]。 -
一次性计算:模型将这 4 个 Token 一次性 输入网络。
-
KV Cache 初始化:计算这 4 个 Token 对应的所有层的 Key (K) 和 Value (V) 向量,并缓存到显存中。
-
输出 Logits:模型输出第 5 个位置(下一个 Token)的概率分布。
2. 采样(Sampling)
-
模型输出的是一个概率分布(例如:“了”30%,“人工智能”20%,“中国”10%...)。
-
根据采样策略(见下文),从中选出一个 Token,比如
"人工智能"。
3. 循环生成(Decoding 阶段)
-
追加:将选出的
"人工智能"追加到序列末尾。 -
新输入:此时序列变为
[请,介绍,一,下,人工智能]。 -
增量计算:
-
关键点:不需要重新计算前 4 个 Token 的 Q/K/V!直接从 KV Cache 中读取。
-
只计算新 Token
"人工智能"的 Q/K/V。 -
新 Token 的 Q 与 Cache 中所有旧的 K 做注意力计算。
-
-
输出:预测下一个 Token(例如
"。")。 -
重复:重复“追加 -> 计算 -> 采样”的过程,直到触发停止条件。
4.2 核心优化:KV Cache(为什么生成这么快?)
如果没有 KV Cache,每生成一个新字,都要把前面所有字重新算一遍,速度会极慢(O(N2) )。
|
步骤 |
输入序列 |
计算内容 |
显存操作 |
|---|---|---|---|
|
第 1 轮 |
|
计算 A, B, C 的 K, V |
缓存 K_A, K_B, K_C... |
|
第 2 轮 |
|
只计算 D 的 K, V |
读取缓存,追加 K_D... |
|
第 3 轮 |
|
只计算 E 的 K, V |
读取缓存,追加 K_E... |
-
原理:因为前面的 Token 不变,它们的 K 和 V 向量也不变。
-
收益:将每次生成的计算量从 O(N2) 降低到 O(N) ,显存占用随长度线性增加。
4.3 采样策略(如何决定下一个词?)
模型输出的是概率,选哪个词决定了生成的质量。
1. 贪婪搜索 (Greedy Search)
-
规则:永远选概率最大的那个词(Top-1)。
-
缺点:容易重复、枯燥,缺乏创造性。
-
例:一直生成“的的的的..."。
-
2. 随机采样 (Random Sampling)
-
规则:按概率分布随机抽取。
-
缺点:可能抽到低概率的乱码。
3. 温度采样 (Temperature)
-
规则:在 Softmax 之前,将 Logits 除以温度系数 T 。
-
T<1 (如 0.1):概率分布更尖锐,模型更保守、确定。
-
T>1 (如 1.5):概率分布更平滑,模型更随机、有创造性。
-
T=1 :原始分布。
-
4. Top-K 采样
-
规则:只在概率最高的 K 个词中采样(例如只在前 50 个词里选)。
-
作用:过滤掉低概率的垃圾词。
5. Top-P (Nucleus Sampling) —— 最常用
-
规则:动态选择词。累加概率,直到达到阈值 P (如 0.9)。
-
如果前 3 个词概率和就超过 0.9,只在这 3 个里选。
-
如果前 100 个词概率和才到 0.9,就在这 100 个里选。
-
-
作用:比 Top-K 更灵活,兼顾了确定性和多样性。
4.4 什么时候停止生成?(停止条件)
生成不会无限进行下去,通常由以下条件触发停止(满足任一即可):
1. 预测出结束符 (EOS Token) —— 自然停止
-
原理:模型在训练时学习了
<eos>(End of Sequence) token。当模型认为“话说完了”,它会预测出这个 token。 -
表现:一旦生成
<eos>,系统立即截断,不再继续。 -
示例:
-
用户:“今天天气不错”
-
模型:“是的,适合出门。<eos>" -> 停止
-
2. 达到最大长度限制 (Max Tokens / Max Length) —— 强制停止
-
原理:为了防止模型死循环、节省算力或控制成本,系统会设置一个硬上限。
-
表现:如果生成了 2048 个 Token 还没出现
<eos>,强制切断。 -
后果:回答可能没说完,句子截断。
3. 遇到特定停止字符串 (Stop Sequences) —— 用户定义
-
原理:用户或系统指定某些字符串作为停止信号。
-
场景:
-
多轮对话:设置
"User:"为停止符。模型生成完回答后,一旦检测到它想生成"User:"(模拟用户说话),立即停止,把控制权交还给用户。 -
代码生成:设置
"\n\n"或"}"为停止符,防止模型生成无关的注释。
-
4. 内容安全拦截 (Safety Filter)
-
原理:在生成过程中或生成后,安全系统检测到违规内容(色情、暴力、政治敏感)。
-
表现:立即中断生成,并替换为“我无法回答该问题”等标准回复。
5. 时间或预算超时 (Timeout / Budget)
-
原理:API 调用设置的时间限制(如 30 秒)或 Token 预算耗尽。
4.5 生成过程全景图解
用户输入:[请,介绍,一,下]
|
v
+-----------------------------+
| 1. Prefill (预填充) |
| - 计算所有层的 KV Cache |
| - 输出第 1 个 Logits |
+-----------------------------+
|
v
+-----------------------------+
| 2. 采样 (Sampling) |
| - 应用 Temperature/Top-P |
| - 选出 Token: "Python" |
+-----------------------------+
|
v
+-----------------------------+
| 3. 检查停止条件 |
| - 是 <eos> 吗?No |
| - 达到 Max Length 吗?No |
| - 命中 Stop String 吗?No |
+-----------------------------+
|
v
+-----------------------------+
| 4. 更新 KV Cache |
| - 追加 "Python" 的 K, V |
+-----------------------------+
|
+------> 回到步骤 2 (预测下一个词)4.6 总结
-
生成是串行的:一个字一个字生成,依赖之前的所有历史(通过 KV Cache 加速)。
-
停止主要由 EOS 控制:模型自己决定什么时候说完(预测
<eos>)。 -
系统限制是兜底:Max Length 防止无限生成,Stop Strings 用于控制对话轮次。
-
采样决定风格:Temperature 和 Top-P 决定了模型是“严谨”还是“发散”。
理解了这个流程,你就明白了为什么大模型有时候会**“话没说完就停了”(触发了 Max Length),或者“一直在重复”**(采样策略 Temperature 太低或模型陷入循环)。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 15
15 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)