一文吃透瀑布模型:软件工程的“线性通关指南”
一文吃透瀑布模型:软件工程的“线性通关指南”
如果你刚接触软件工程,大概率会被各种模型、术语绕得头晕——而瀑布模型,就是这一切的起点。它不是什么高深莫测的理论,而是一种“一步一步走、做完不回头”的线性开发思路,就像瀑布从高处倾泻而下,只能顺着一个方向流动,每一个环节都要完成后,才能进入下一个环节。
今天我们不聊复杂的理论框架,只把瀑布模型的核心过程拆解开,用最直白的语言讲清楚:它到底是什么、每个环节要做什么、为什么它能成为软件工程的经典模型(哪怕现在有了更多灵活的方法)。
一、瀑布模型的核心逻辑:线性递进,环环相扣
瀑布模型的核心就是“顺序执行”,没有捷径可走,也没有回头路可走。它把一个软件从无到有的过程,拆成了5个明确的(最核心的)阶段,每个阶段都有明确的输入和输出,就像工厂生产产品,先备料、再加工、再质检、最后出厂,一步都不能乱。
这5个阶段依次是:需求分析 → 设计 → 开发 → 测试 → 运行维护。接下来我们逐个拆解,搞懂每个阶段的核心任务和意义。
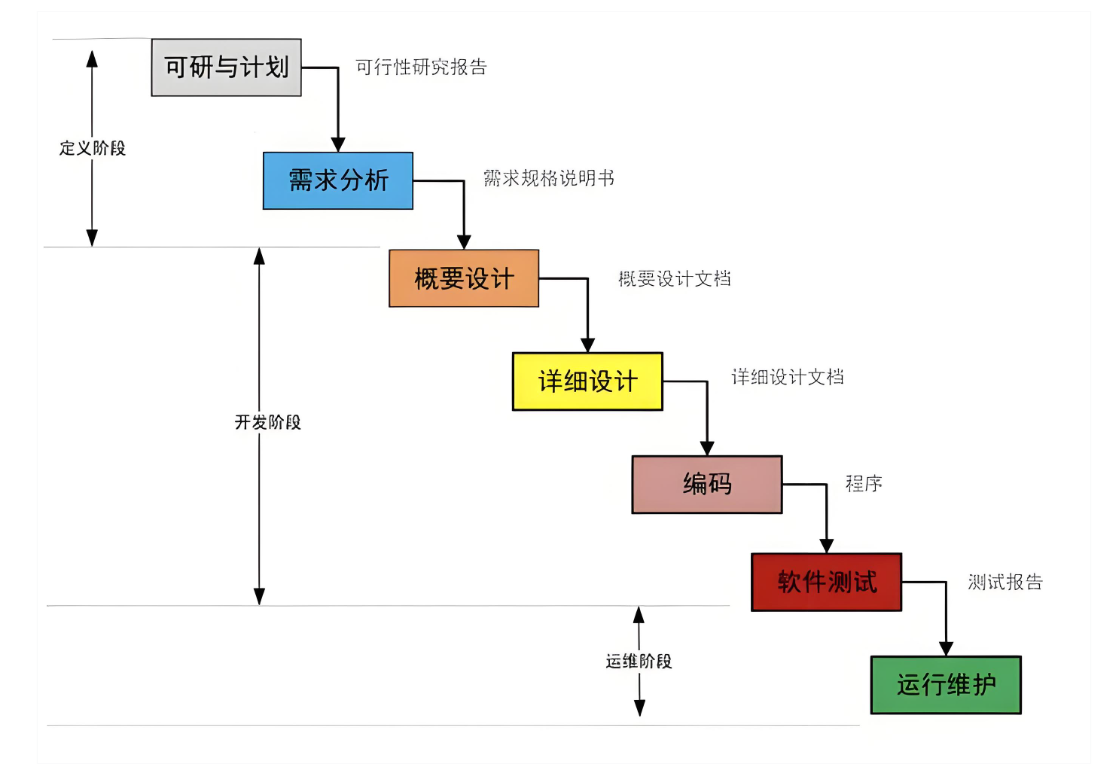
二、拆解瀑布模型5大核心过程
1. 需求分析:搞清楚“用户到底要什么”
这是瀑布模型的第一步,也是最关键的一步——如果这一步没做好,后面所有的工作都可能白费。就像盖房子,先得问清楚业主“要盖几层高、几间房、要不要阳台”,而不是上来就砌墙。
需求分析的核心任务,就是和用户(或产品方)沟通,把用户模糊的需求,变成清晰、可落地、可验证的“需求文档”。比如用户说“我要一个好用的购物APP”,这就是模糊需求;我们要把它拆解成:能浏览商品、能加入购物车、能下单支付、能查看物流、能退货退款,还要支持手机号登录、密码找回等具体功能。
这个阶段的输出物是《需求规格说明书》,相当于整个项目的“指南针”,后面所有的设计、开发、测试,都要以这份文档为标准——不能用户说“要好用”,我们就凭感觉做,最后做完用户说“这不是我想要的”。
这里要注意:需求分析阶段一定要“抠细节”,比如用户说“支付要安全”,就要明确“支持指纹支付、密码支付,支付过程加密,支付失败要提示原因”,避免后续出现理解偏差。
2. 设计:规划“怎么把需求实现出来”
需求定好了,接下来就要想“怎么干”——这就是设计阶段的核心。就像盖房子,知道了要盖几间房,接下来就要画设计图:哪里砌墙、哪里装窗户、水管怎么铺、电线怎么拉。
设计阶段又分为两个核心部分,缺一不可:
一是概要设计(总体设计):确定软件的整体架构。比如购物APP,要拆分成“用户模块”“商品模块”“购物车模块”“支付模块”“物流模块”,每个模块之间怎么交互(比如用户下单后,购物车模块要通知支付模块,支付模块要联动物流模块),用什么技术框架(比如后端用Java,前端用Vue),数据库怎么设计(比如用户表、商品表、订单表的字段是什么)。
二是详细设计:细化每个模块的具体实现方案。比如“用户登录模块”,要明确登录流程(输入手机号→获取验证码→验证验证码→登录成功),每个步骤的逻辑(验证码有效期5分钟,连续输错3次锁定账号),甚至要画出流程图、写出伪代码,让开发人员一看就知道“该怎么写代码”。
这个阶段的输出物是《概要设计说明书》和《详细设计说明书》,相当于给开发人员的“施工图纸”,确保所有人都按照同一个标准去开发,避免出现“你写你的、我写我的”,最后无法整合。
3. 开发:把“设计图”变成“实际产品”
设计图纸画好后,就进入了最核心的“动手环节”——开发阶段。这个阶段的核心任务,就是开发人员按照详细设计说明书,用代码把每个模块实现出来,把“想法”变成“可运行的软件”。
比如按照设计要求,开发用户登录模块、商品列表模块、购物车功能,把各个模块的代码写好、调试好,然后整合在一起,形成一个完整的软件版本。这个过程就像工人按照设计图砌墙、装门窗,把房子的主体结构搭起来。
这里要注意两个点:一是开发过程要遵循设计文档,不能随意修改设计(如果确实需要修改,要回到设计阶段重新评审,避免混乱);二是开发过程中要做好版本管理,比如用Git记录每一次代码修改,防止代码丢失或出现错误无法回滚。
这个阶段的输出物,就是“可运行的软件原型”(也叫alpha版本),虽然可能还有bug,但已经能实现核心功能了。
4. 测试:找出“bug”,确保软件能用、好用
软件开发完,不能直接交给用户——谁也不想用一个满是bug的软件(比如点下单没反应、支付失败、登录不上)。测试阶段的核心任务,就是“找问题、改问题”,确保软件符合需求规格说明书的要求,没有明显的bug,运行稳定。
测试的核心逻辑,就是“模拟用户使用场景”,把所有可能出现的情况都测一遍:比如正常登录、输错密码、网络中断时下单、多个人同时下单,等等。测试人员会对照需求文档和设计文档,逐一验证每个功能是否正常,是否符合预期。
测试过程中,会把发现的bug记录下来,反馈给开发人员,开发人员修改后,测试人员再重新测试,直到bug被全部修复(或达到可接受的范围)。这个过程就像盖房子完工后,质检员检查房子是否漏水、墙面是否平整、门窗是否好用,有问题就返工。
这个阶段的输出物是《测试报告》,记录测试的过程、发现的bug、修复情况,以及最终的测试结论——如果测试通过,软件就可以准备上线;如果没通过,就回到开发阶段修改,再重新测试。
5. 运行维护:软件上线后,持续“保驾护航”
很多人以为,软件上线就结束了——其实不然。瀑布模型的最后一个阶段,是运行维护,也是一个“长期任务”。就像房子盖好后,还要定期维修、保养,避免水管漏水、墙面开裂。
运行维护的核心任务,主要有3件事:
一是纠错维护:软件上线后,可能会出现一些测试阶段没发现的bug(比如特定场景下的闪退、数据异常),维护人员要及时排查、修复,确保软件正常运行。
二是适应性维护:随着环境变化,软件需要调整——比如操作系统更新了、数据库升级了,软件要适配新的环境,避免出现无法运行的情况;或者用户的需求有微小调整(比如增加“优惠券使用规则”),也要进行小范围的修改。
三是完善性维护:根据用户的使用反馈,优化软件体验——比如用户觉得“下单流程太繁琐”,就简化流程;觉得“页面加载太慢”,就优化代码,提升速度。
这个阶段没有明确的“结束时间”,只要软件还在使用,就需要持续维护,直到软件被淘汰、替换。
三、瀑布模型的优势与局限
了解完核心过程,我们再简单说说瀑布模型的好坏,帮你更全面地理解它:
优势:流程清晰、阶段明确,每个环节都有明确的输入输出,适合需求稳定、变化少的项目(比如一些政府、企业的办公系统),新手也容易上手,便于管理和控制。
局限:灵活性差,一旦需求发生变化(比如用户中途说“我要加一个功能”),就要回到前面的阶段重新来,成本高、效率低;而且测试阶段太晚,一旦发现核心问题,可能需要推翻前面的开发工作,耗时耗力。
四、总结:瀑布模型的核心价值
虽然现在有敏捷开发、迭代开发等更灵活的模型,但瀑布模型依然是软件工程的“基础”——它教会我们:做软件要“有章法、有顺序”,先明确需求、再设计、再开发、再测试,最后持续维护,一步一个脚印,才能做出符合用户需求、稳定可靠的软件。
如果你是刚接触软件工程的新手,先吃透瀑布模型的这5个过程,再去学习其他更复杂的模型,会轻松很多——毕竟,万丈高楼平地起,瀑布模型就是那个“打地基”的方法。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 5
5 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)