WSL和LLamaFactory框架微调千问3大模型
WSL和LLamaFactory框架微调千问大模型
windows10安装WSL
1.1 什么是 WSL
WSL(Windows Subsystem for Linux)是微软推出的 Windows 系统 Linux 子系统技术,无需单独安装 Linux 系统或依赖虚拟机,即可在 Windows 中直接运行完整的 Linux 环境。它支持原生 Linux 命令行工具、软件包管理器(如 apt)及各类 Linux 应用程序,实现了 Windows 与 Linux 文件系统的无缝集成,极大消除了两大系统的开发隔阂,尤其适合需要在 Windows 平台使用 Linux 工具的开发者。
二、WSL2 安装步骤
2.1 启用 Windows 必备功能
方式一:
打开「开始菜单」,点击「应用与程序」;
滚动到页面底部,点击「程序与功能」;
点击左侧「启用或关闭 Windows 功能」;
在弹出的窗口中,勾选「虚拟机平台」和「适用于 Linux 的 Windows 子系统」两个选项(如图所示),点击「确定」。

方式二:使用PowerShell命令
dism.exe /online /enable-feature /featurename:Microsoft-Windows-Subsystem-Linux /all /norestart
dism.exe /online /enable-feature /featurename:VirtualMachinePlatform /all /norestart
2.2 重启电脑
配置完成后必须重启电脑,确保上述功能生效,否则后续安装可能失败。接下来还需要更新wsl的内核。
-
安装/更新 WSL 内核
wsl --update -
安装 Linux 发行版(比如 Ubuntu 22.04)
-
设置默认版本为 WSL2,例如:
wsl --set-default-version 2
2.3 命令安装 WSL 并初始化和安装ubuntu
- 以管理员身份打开命令提示符(CMD)或运行(WIN 键 + R)输入
cmd; - 输入安装命令
wsl --install # 网络良好时使用,默认安装Ubuntu
它会自动:
1. 启用 WSL
2. 启用虚拟机平台
3. 安装 WSL2 内核
4. 安装 Ubuntu
5. 设置 WSL2 为默认
# 若下载速度慢,使用以下命令通过网络下载安装 或者手动安装
wsl --install --web-download
-
首次启动会自动安装 Ubuntu,等待几分钟后,需要设置 Linux 用户名和密码:
- 输入自定义 UNIX 用户名(无需与 Windows 用户名一致);
- 输入密码(输入时不显示明文,正常输入即可);
- 再次确认密码,提示passwd: password updated successfully即为设置成功。
出现Installation successful!提示后,Ubuntu 已启动成功,可通过sudo <命令>执行管理员操作。
2.4 验证 WSL 运行状态
- 可通过 Windows PowerShell 启动 WSL(快捷键
Ctrl+Shift+6直接打开 Ubuntu,需提前配置 PowerShell); - 输入以下命令验证 WSL 是否正常运行:
wsl --list --verbose # 查看已安装的WSL分发版及状态
若显示 Ubuntu 及运行状态,则说明安装成功。
2.5 (推荐手动)安装Ubuntu系统
下载 Ubuntu 22.04:
官方地址:https://aka.ms/wslubuntu2204
下载后得到:
Ubuntu_2204.appx
2.6 把 Ubuntu 解压到 D 盘
例如:
创建目录:
D:\WSL\Ubuntu2204
然后解压:
Ubuntu_2204.appx
得到:
ubuntu.exe
2.7 运行 Ubuntu
进入目录:
D:\WSL\Ubuntu2204
运行:
ubuntu.exe
第一次运行会自动创建 Linux 文件系统:
ext4.vhdx
这个文件就是:
Linux系统盘
例如:
D:\WSL\Ubuntu2204\ext4.vhdx
在WSL的ubuntu环境中安装LLaMA-Factory 的依赖
检查环境,查询显卡驱动
-
执行命令nvidia-smi
-
验证GPU驱动是否可用
-
如果系统提示:
Command 'nvidia-smi' not found原因是:
Ubuntu 系统里 没有安装 NVIDIA 工具包。
-
在 Ubuntu 里只需要安装:nvidia-utils
-
执行下面的命令
-
sudo apt update sudo apt install -y nvidia-utils-535
-
-
然后再执行下面的命令,可以看到显卡的信息表示成功。
nvidia-smi
LLaMA-Factory 安装指南(WSL + GPU)
环境准备
本文档介绍在 Windows + WSL2 + Ubuntu + GPU 环境中安装 LLaMA-Factory 的完整流程。
推荐环境:
| 组件 | 推荐版本 |
|---|---|
| Windows | Windows 10 / 11 |
| WSL | WSL2 |
| Ubuntu | 22.04 |
| Python | 3.11 |
| CUDA | 12.x |
| GPU | NVIDIA |
安装 Miniconda
下载 Miniconda:
cd ~
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
按提示:yes
初始化 Conda:
~/miniconda3/bin/conda init
source ~/.bashrc
验证:
conda --version
创建 Python 环境
LLaMA-Factory 要求:
Python >= 3.11
创建环境:
conda create -n llamafactory_py311 python=3.11 -y
激活环境:
conda activate llamafactory_py311
查看环境:能够看到刚刚创建的虚拟环境信息,说明创建成功。
conda env list
安装 PyTorch GPU
安装 GPU 版 PyTorch:
pip install torch torchvision torchaudio \
--index-url https://download.pytorch.org/whl/cu121
验证 GPU:
python -c "import torch;print(torch.cuda.is_available())"
如果输出:
True
说明 GPU 可用。
进一步检查:
python -c "import torch;print(torch.__version__);print(torch.version.cuda);print(torch.cuda.get_device_name(0))"
下载 LLaMA-Factory
创建项目目录:
mkdir -p ~/project
cd ~/project
下载源码:
git clone https://github.com/hiyouga/LLaMA-Factory.git
进入目录:
cd LLaMA-Factory
安装 LLaMA-Factory
安装训练依赖:
pip install -e ".[torch,metrics]"
说明:
| 参数 | 含义 |
|---|---|
| -e | editable 安装 |
| . | 当前项目 |
| torch | 训练依赖 |
| metrics | 评估依赖 |
验证安装
检查版本:
llamafactory-cli version
查看帮助:
llamafactory-cli help
如果命令能正常输出说明安装成功。
启动 WebUI
运行:
llamafactory-cli webui
成功后会显示:
Running on http://127.0.0.1:7860
打开浏览器:
http://localhost:7860
即可进入 LLaMA-Factory WebUI。
通过web页面下载Qwen3-0.6B-Base模型,模型下载源选择为modelscope,然后点击中间为chat模式,点击 加载模型 按钮。
如图:

如何windowS访问WSL的Ubuntu系统文件目录
示例:
- Linux路径:
/home/ford/project/llamafactory/LLaMA-Factory
- windows访问路径:
\\wsl$\Ubuntu-22.04\home\ford\project\llamafactory\LLaMA-Factory
LLamaFactory的目录结构
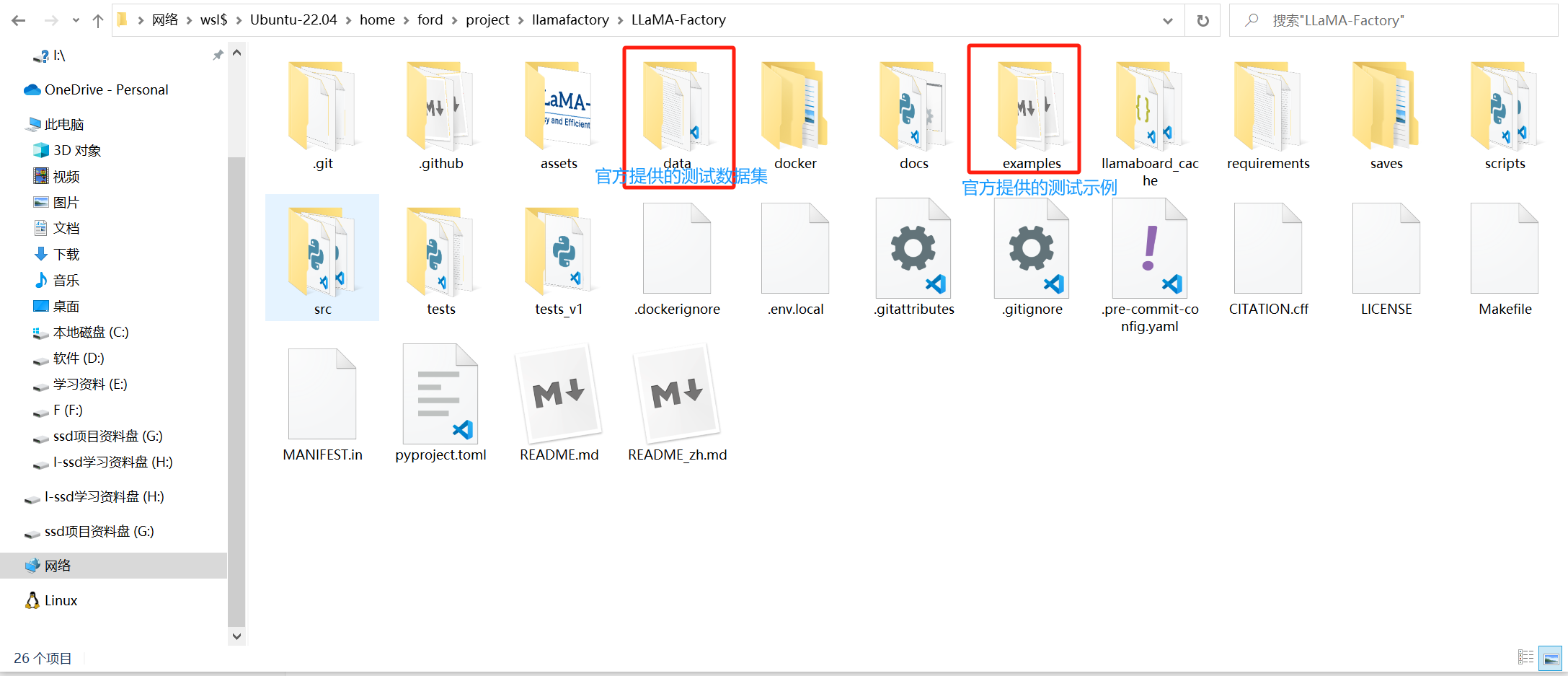
整体结构(先建立脑图)
LLaMAFactory 本质分 5 层:
1️⃣ 配置层(examples / data)
2️⃣ 训练入口(cli / scripts)
3️⃣ 核心逻辑(src)
4️⃣ 工具与扩展(docker / docs)
5️⃣ 输出结果(saves)
目录逐个解释
⭐ 1. examples(最重要之一)
👉 官方提供的训练配置模板
你刚才用的就是:
examples/train_lora/xxx.yaml
里面包含:
examples/
├── train_lora/
├── train_full/
├── inference/
作用:
👉 定义训练行为(你调的都是这里)
例如:
model_name_or_path:
dataset:
learning_rate:
batch_size:
⭐ 2. data(数据目录)
👉 官方 demo 数据
data/
├── alpaca_en_demo.json
├── identity.json
作用:
👉 给你测试训练的一些数据
📌 实际项目:
比如换成:
data/
├── stock_dataset.json
├── medical_dataset.json
⭐ 3. src(核心代码 ⭐⭐⭐)
👉 整个框架的大脑
src/llamafactory/
里面核心模块:
① train(训练逻辑)
train/
├── tuner.py
├── trainer.py
👉 负责:
- LoRA训练
- SFT训练
- 参数调度
② hparams(参数解析)
hparams/
├── model_args.py
├── data_args.py
👉 把 YAML 转成 Python 参数
③ cli(入口)
cli.py
👉 你执行的:
llamafactory-cli train xxx.yaml
就是从这里进来的
④ models(模型加载)
👉 负责:
- 加载 Qwen / LLaMA
- 加载 tokenizer
⑤ data(数据处理)
👉 负责:
- dataset tokenize
- prompt 构造
📌 总结一句:
src = 训练引擎
⭐ 4. saves(训练结果)
👉 你训练完的模型在这里
saves/
├── Qwen3-0.6B/
├── lora/
├── sft/
里面:
adapter_model.safetensors
adapter_config.json
👉 LoRA 权重
⭐ 5. scripts(脚本工具)
👉 一些辅助脚本
例如:
- 数据转换
- 批处理
一般你前期用不到
⭐ 6. docs(文档)
👉 官方说明
可以当参考手册
⭐ 7. docker
👉 容器部署
你现在 WSL 用不到
⭐ 8. llamaboard_cache
👉 UI界面缓存(WebUI)
⭐ 9. tests / tests_v1
👉 测试代码
不用管
⭐ 10. requirements
👉 依赖拆分
⭐ 11. assets
👉 图片 / README 资源
训练流程(你要理解的核心)
把整个流程串起来
训练执行命令如下:
llamafactory-cli train xxx.yaml
🔁 内部流程:
1️⃣ 读取配置
examples/*.yaml
↓
2️⃣ 参数解析
src/hparams
↓
3️⃣ 加载模型
src/models
↓
4️⃣ 加载数据
data/
↓
5️⃣ 开始训练
src/train/tuner.py
↓
6️⃣ 保存模型
saves/
微调训练示例
1. 微调训练命令
这里使用官方提供的一些样例数据对模型进行Lora微调,首先进入LLaMA-Factory\examples\train_lora文件夹,找到配置文件,修改qwen3_lora_sft.yaml配置文件。
- 执行训练命令:
USE_MODELSCOPE_HUB=1 llamafactory-cli train examples/train_lora/qwen3_lora_sft.yaml
- 命令解释
使用 ModelScope 作为模型下载源,通过 LLaMA-Factory 按照指定 YAML 配置,对 qwen3 模型进行 LoRA 指令微调训练
- 如图所示:

2. Chat对话命令
- 改配置
进入LLaMA-Factory\examples\inference文件夹,找到qwen3_lora_sft.yaml,修改这个配置,把model_name_or_path模型基座改成我们微调的模型名称和模型文件的输入路径改为刚刚你微调输出的目录。template默认改为default。
windows的路径:
\\wsl$\Ubuntu-22.04\home\ford\project\llamafactory\LLaMA-Factory\examples\inference\qwen3_lora_sft.yaml
- 如图所示:

- 命令
USE_MODELSCOPE_HUB=1 llamafactory-cli chat examples/inference/qwen3_lora_sft.yaml
- 如图所示:

3.export合并模型文件
- 修改配置
进入目录LLaMA-Factory\examples\merge_lora,下面找到qwen3_lora_sft.yaml这个配置文件,然后修改内容;主要修改的是模型路径和模型名称,以及微调后的模型文件路径。
windows的路径:
\\wsl$\Ubuntu-22.04\home\ford\project\llamafactory\LLaMA-Factory\examples\merge_lora\qwen3_lora_sft.yaml
- 如图所示:
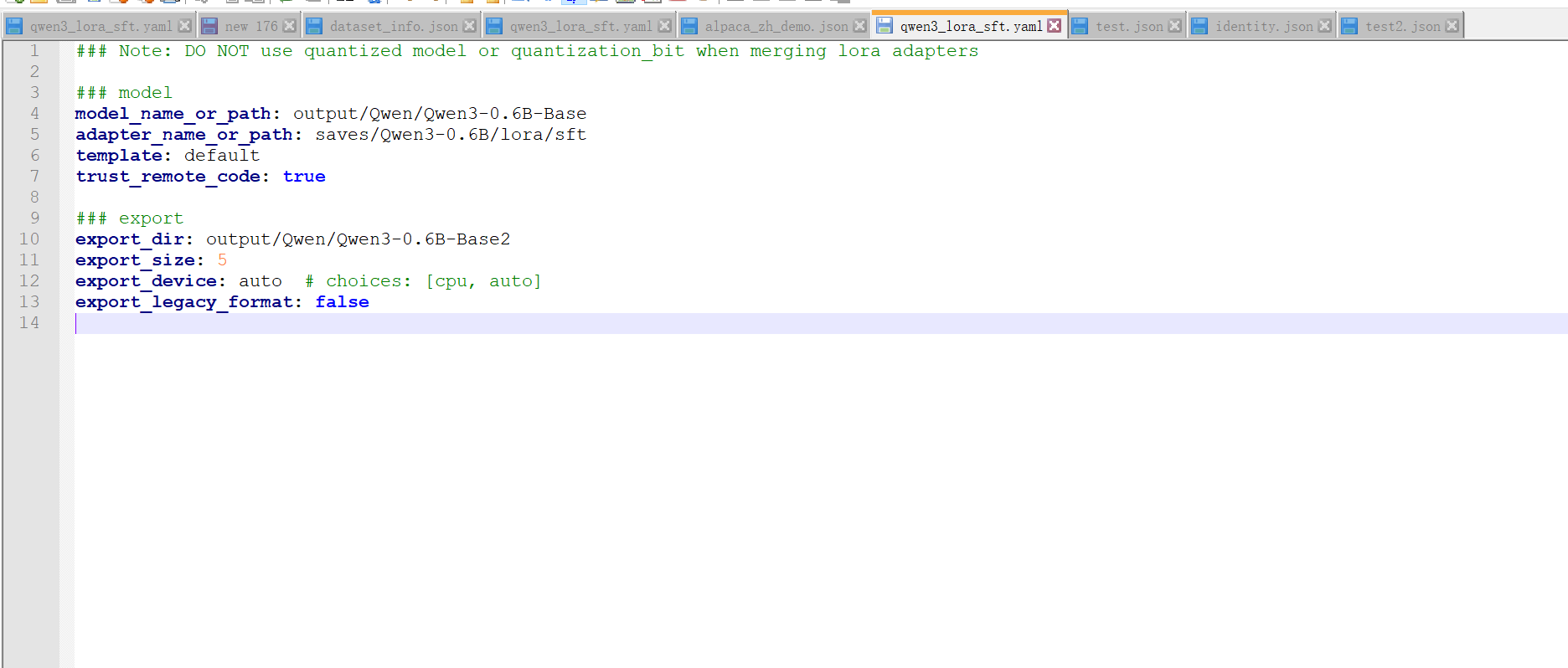
- 命令
USE_MODELSCOPE_HUB=1 llamafactory-cli export examples/merge_lora/qwen3_lora_sft.yaml
- 如图所示:

4.模型API启动命令
- 修改配置
进入目录\LLaMA-Factory\examples\inference,下面找到qwen3_lora_sft.yaml这个配置文件,然后修改内容;主要修改的是合并后的模型文件路径。假设我们最终合并的模型输出的路径为:output/Qwen/Qwen3-0.6B-Base2

windows的路径:
\\wsl$\Ubuntu-22.04\home\ford\project\llamafactory\LLaMA-Factory\examples\inference
- 命令
USE_MODELSCOPE_HUB=1 llamafactory-cli api examples/inference/qwen3_lora_sft.yaml
- curl命令尝试调用模型的API给模型发消息
curl -s http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "output/Qwen/Qwen3-0.6B-Base2",
"messages": [
{"role": "user", "content": "对暗号!一支穿云箭"}
],
"max_tokens": 64,
"temperature": 0.5
}'
- 如图:

未完待续…

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 10
10 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)