Pytorch学习笔记(1)
神经网络结构与基本概念
与人类的神经元类似,当接受刺激时,将发送信号触发神经元做出反应,当未接受刺激,即当刺激大小未超过阈值时,此时不做出反应。
此时神经元接受刺激做出反应这一个过程可以划分为:输入层、中间层、输出层。
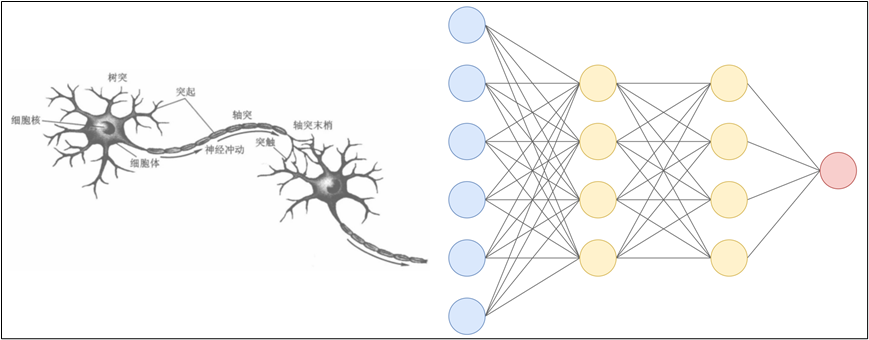
人工神经网络(Artificial Neural Network,ANN)简称 神经网络(NN),是一种模仿生物神经网络结构和功能的计算模型。大多数情况下人工神经网络能在外界信息的基础上改变内部结构,是一种自适应系统(adaptive system),通俗地讲就是具备学习功能。
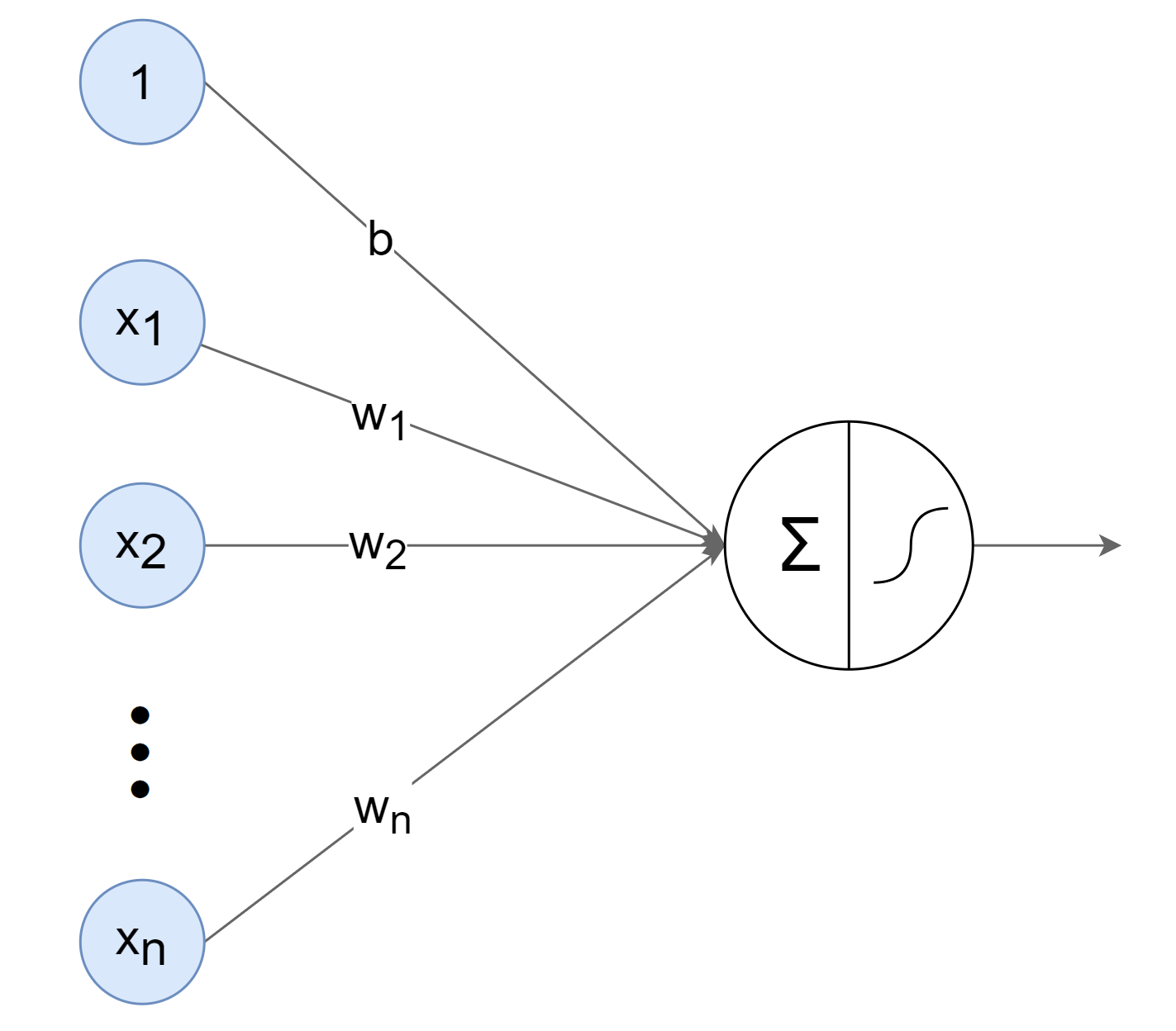
人工神经网络中的神经元,一般可以对多个输入进行加权求和,再经过特定的“激活函数”转换后输出。
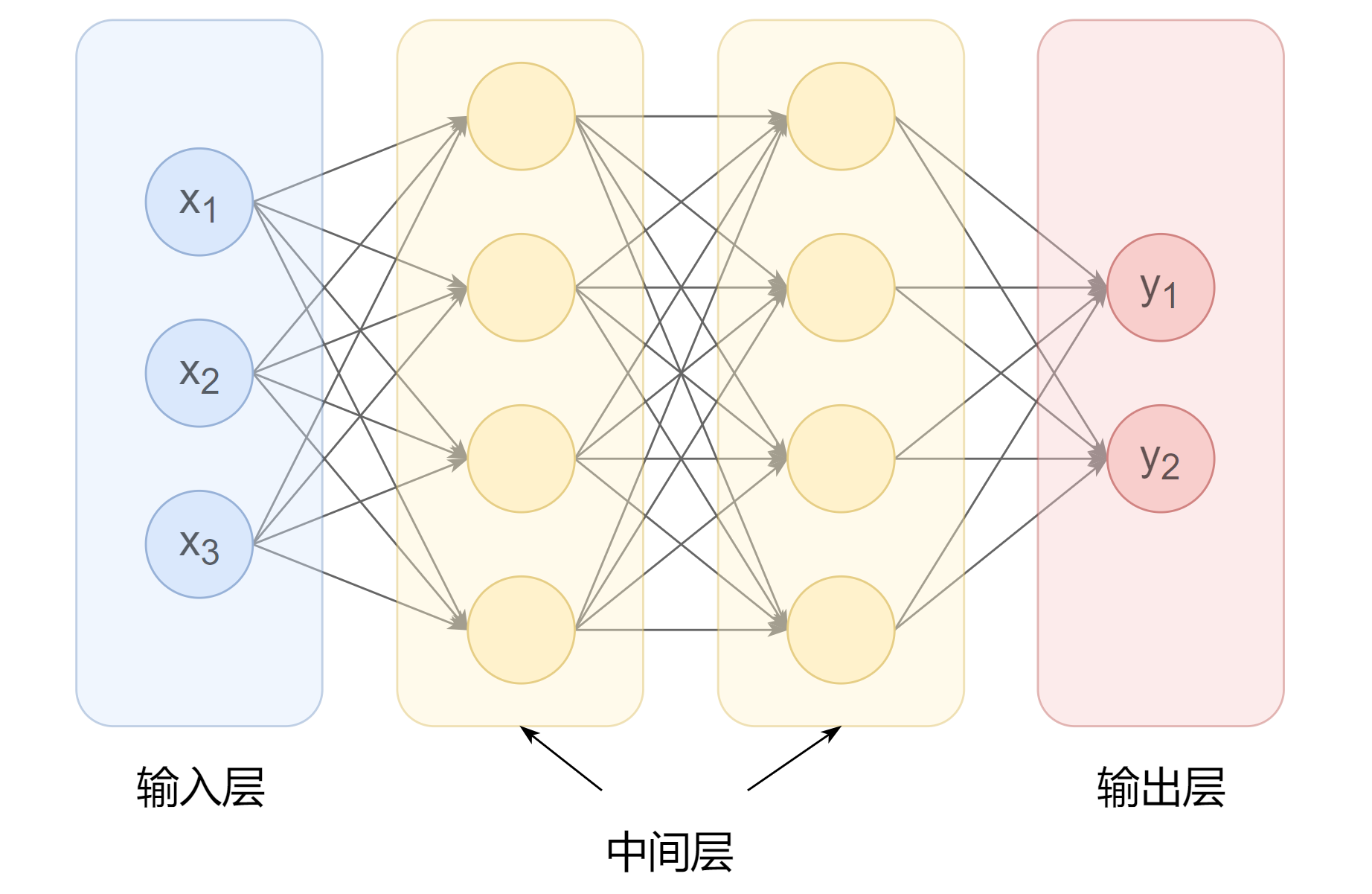
使用多个神经元就可以构建多层神经网络,最左边的一列神经元都表示输入,称为 输入层;最右边一列表示网络的输出,称为 输出层;输入层与输出层之间的层统称为 中间层(隐藏层)。
相邻层的神经元相互连接(图中下一层每个神经元都与上一层所有神经元连接,称为 全连接),每个连接都会有一个 权重。
神经元中的信息逐层传递(一般称为 前向传播forward),上一层神经元的输出作为下一层神经元的输入。
感知机
感知机(Perceptron)是二分类模型,接收多个信号,输出一个信号。感知机的信号只有0、1两种取值。
下图是一个接收两个输入信号的感知机的例子:
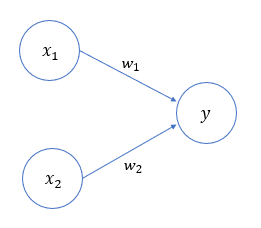
x1,x2![]() 是输入信号,y
是输入信号,y ![]() 是输出信号,w1,w2
是输出信号,w1,w2 ![]() 是权重,○ 称为神经元或节点。输入信号被送往神经元时,会分别乘以固定的权重。神经元会计算传送过来的信号的总和,只有当这个总和超过某个界限值时才会输出1,也称之为神经元被激活。
是权重,○ 称为神经元或节点。输入信号被送往神经元时,会分别乘以固定的权重。神经元会计算传送过来的信号的总和,只有当这个总和超过某个界限值时才会输出1,也称之为神经元被激活。
y=0 b+w1x1+w2x2≤01 b+w1x1+w2x2>0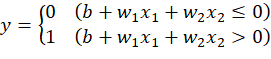 (2.1)
(2.1)
这里将界限的阈值设为0。除了权重w1,w2![]() 之外,还可以增加一个参数b
之外,还可以增加一个参数b![]() ,被称为 偏置。
,被称为 偏置。
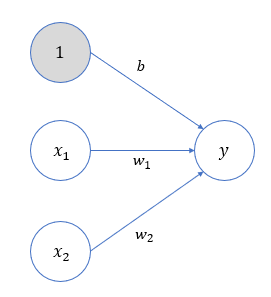
感知机的多个输入信号都有各自的权重,这些权重发挥着控制各个信号的重要性的作用,权重越大,对应信号的重要性越高。偏置则可以用来控制神经元被激活的容易程度。
引入激活函数
可以看出,式(2.1)中包含了两步处理操作:首先按照输入各自的权重及偏置,计算出一个加权总和;然后再根据这个总和与阈值的大小关系,决定输出0还是1。
如果定义一个函数:
h(x)=0 x≤01 x>0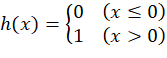 (2.2)
(2.2)
那么式(2.1)就可以简化为:
y=h(b+w1x1+w2x2)![]() (2.3)
(2.3)
为了更明显地表示出两个处理步骤,可以进一步写成:
a=b+w1x1+w2x2![]() (2.4)
(2.4)
y=h(a)![]() (2.5)
(2.5)
这里,我们将输入信号和偏置的加权总和,记作 a![]() 。
。
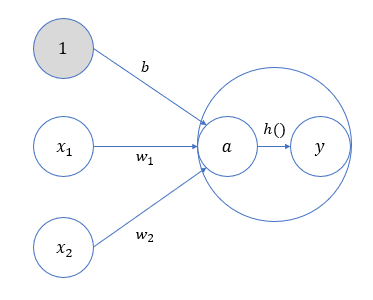
h(x)![]() 可以将输入信号的加权总和转换为输出信号,起到“激活神经元”的作用,所以被称为 激活函数。
可以将输入信号的加权总和转换为输出信号,起到“激活神经元”的作用,所以被称为 激活函数。
激活函数
激活函数是连接感知机和神经网络的桥梁,在神经网络中起着至关重要的作用。
激活函数作用
如果没有激活函数,整个神经网络就等效于单层线性变换,不论如何加深层数,总是存在与之等效的“无隐藏层的神经网络”。激活函数必须是非线性函数,也正是激活函数的存在为神经网络引入了非线性,使得神经网络能够学习和表示复杂的非线性关系。
阶跃(Binary step)函数
之前的感知机中,式(2.2)表示的 hx![]() 就是最简单的激活函数,它可以为输入设置一个“阈值”;一旦超过这个阈值,就切换输出(0或者1)。这种函数被称为“阶跃函数”。
就是最简单的激活函数,它可以为输入设置一个“阈值”;一旦超过这个阈值,就切换输出(0或者1)。这种函数被称为“阶跃函数”。
fx=0,x<01, x≥0, f'x=0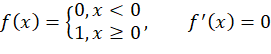
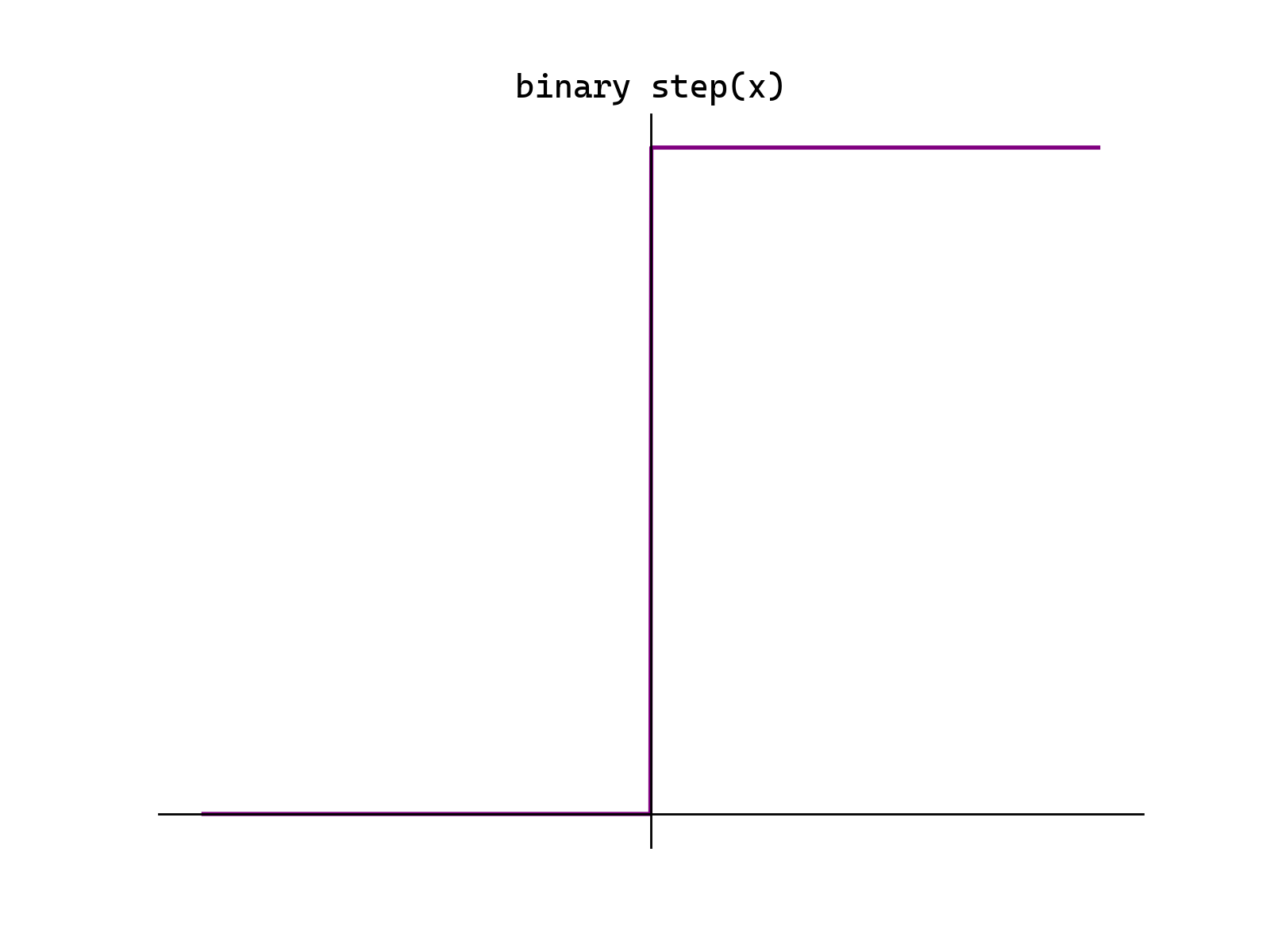
阶跃函数的导数恒为0。
阶跃函数可以用代码实现如下:
def step_function(x):
if x > 0:
return 1
else:
return 0
这里的x只能取一个数值(浮点数)。如果我们希望直接传入Numpy数组进行批量化的操作,可以改进如下:
def step_function(x):
return np.array(x > 0, dtype=int)
Sigmoid函数
fx=11+e-x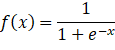
f'x=11+e-x1-11+e-x=fx1-fx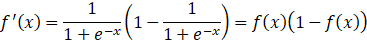
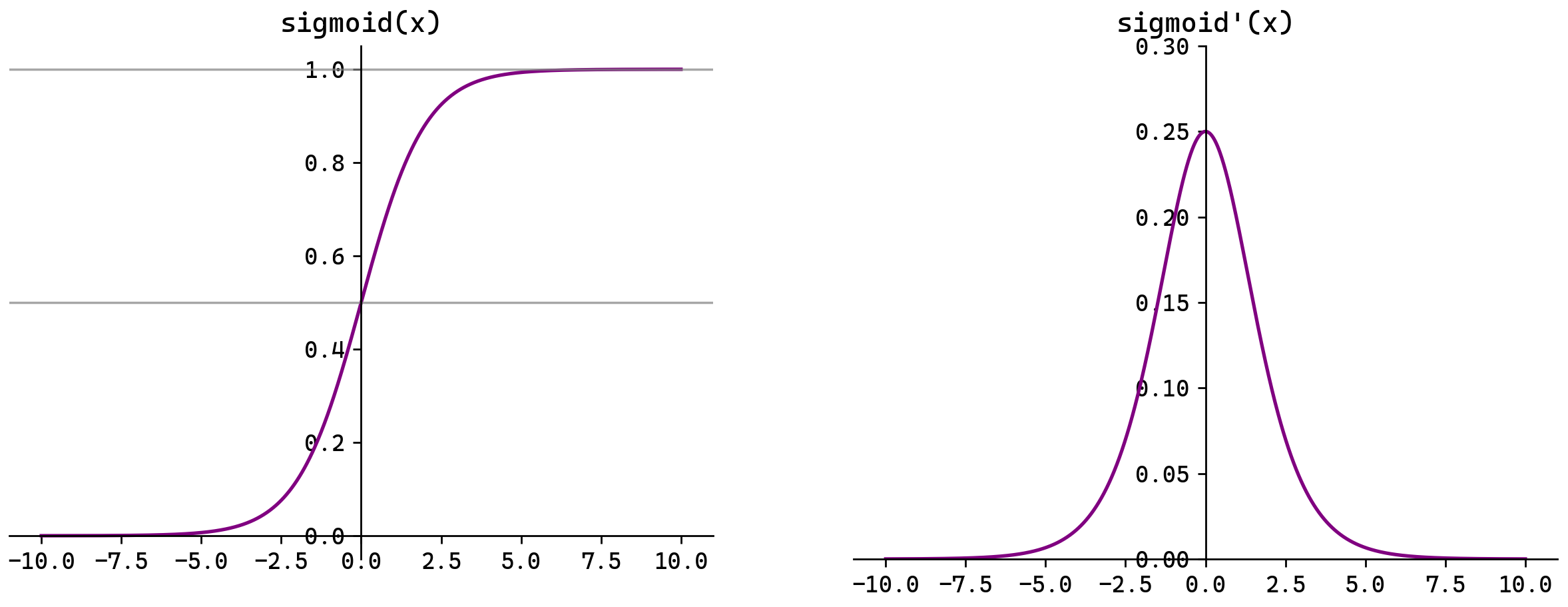
Sigmoid(也叫Logistic函数)是平滑的、可微的,能将任意输入映射到区间(0,1)。常用于二分类的输出层。但因其涉及指数运算,计算量相对较高。
Sigmoid的输入在[-6,6]之外时,其输出值变化很小,可能导致信息丢失。
Sigmoid的输出并非以0为中心,其输出值均>0,导致后续层的输入始终为正,可能影响后续梯度更新方向。
Sigmoid的导数范围为(0,0.25),梯度较小。当输入在[-6,6]之外时,导数接近0,此时网络参数的更新将会极其缓慢。使用Sigmoid作为激活函数,可能出现梯度消失(在逐层反向传播时,梯度会呈指数级衰减)。
Sigmoid函数可以用代码实现如下:
def sigmoid(x):
return 1 / (1 + np.exp(-x))
Tanh函数
fx=1-e-2x1+e-2x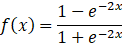
f'x=1-1-e-2x1+e-2x2=1-f2x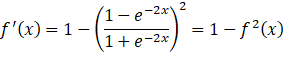
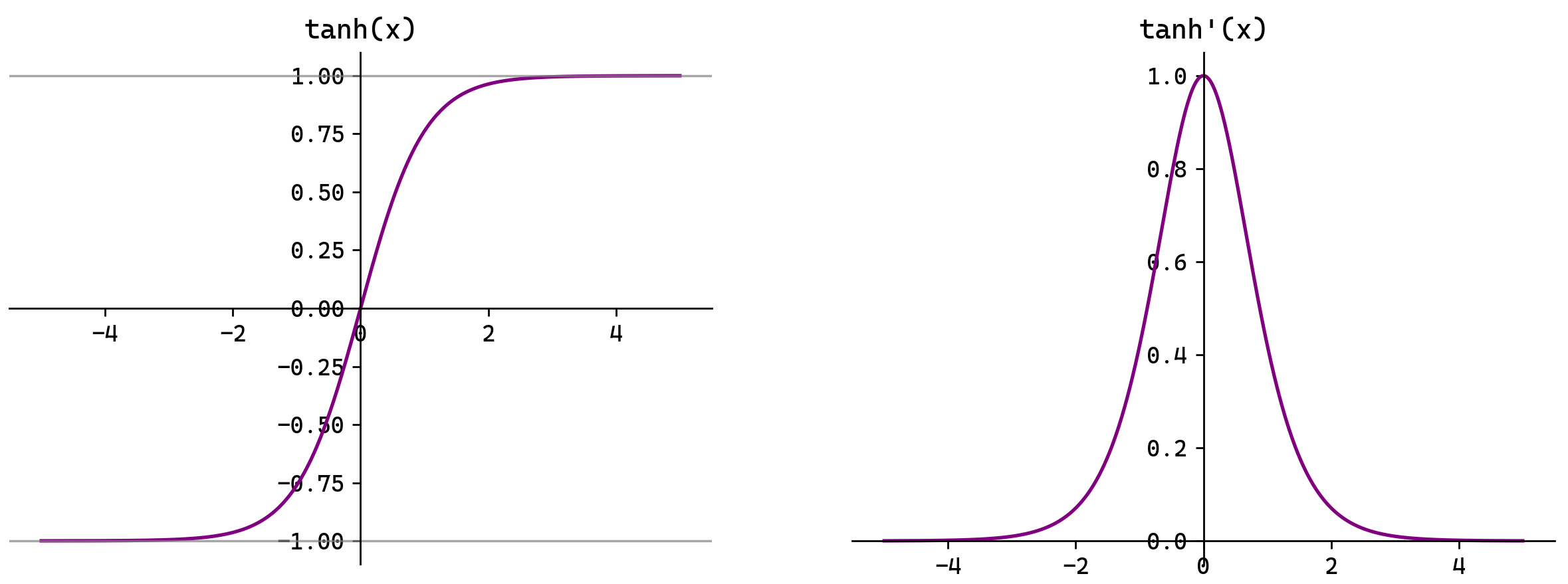
Tanh(双曲正切)将输入映射到区间(-1,1)。其关于原点中心对称。常用在隐藏层。
输入在[-3,3]之外时,Tanh的输出值变化很小,此时其导数接近0。
Tanh的输出以0为中心,且其梯度相较于Sigmoid更大,收敛速度相对更快。但同样也存在梯度消失现象。
ReLU函数
fx=max0,x= 0,x≤0x,x>0![]()
f'x=0,x≤01,x>0![]()
注意:x=0时ReLU函数不可导,此时我们默认使用左侧的函数。
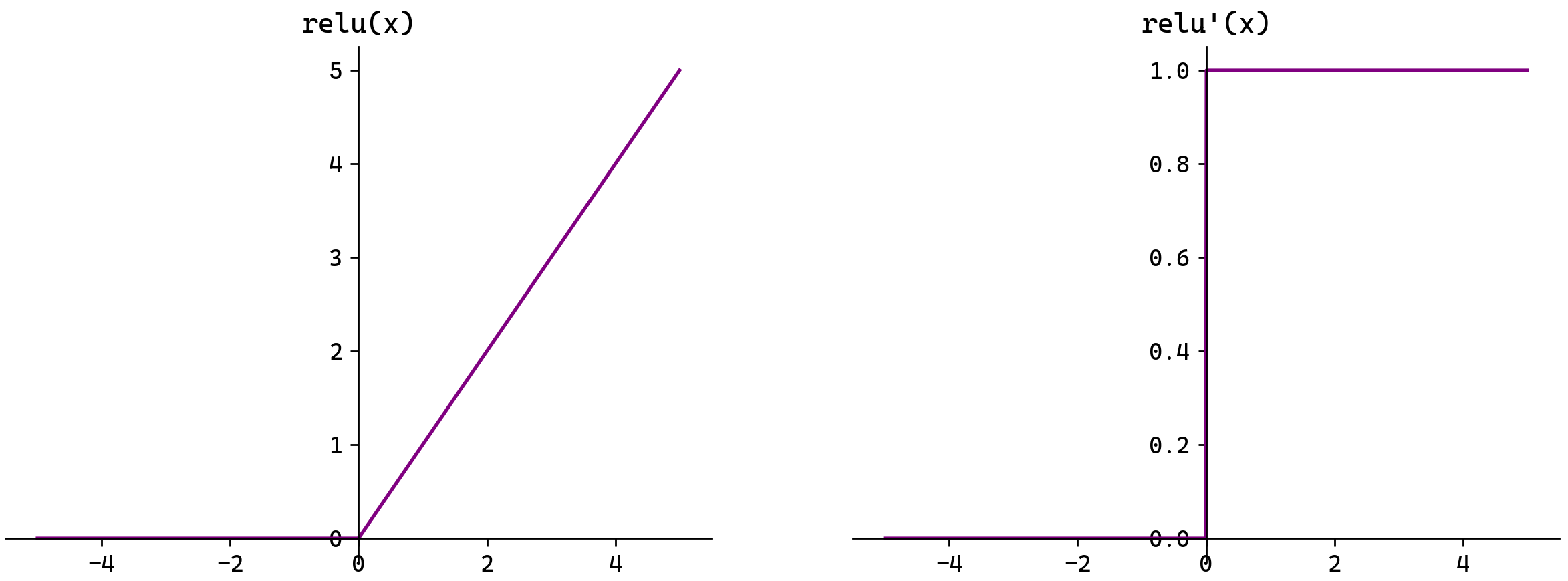
ReLU(Rectified Linear Unit,修正线性单元)会将小于0的输入转换为0,大于等于0的输入则保持不变。ReLU定义简单,计算量小。常用于隐藏层。
ReLU作为激活函数不存在梯度消失。当输入小于0时,ReLU的输出为0,这意味着在神经网络中,ReLU激活的节点只有部分是“活跃”的,这种稀疏性有助于减少计算量和提高模型的效率。
当神经元的输入持续为负数时,ReLU的输出始终为0。这意味着神经元可能永远不会被激活,从而导致“神经元死亡”问题。这会影响模型的学习能力,特别是如果大量的神经元都变成了“死神经元”。为解决此问题,可使用Leaky ReLU来代替ReLU作为激活函数。Leaky ReLUfx=αx,x≤0x,x>0,其中α是一个很小的常数![]() 在负数区域引入一个小的斜率来解决“神经元死亡”问题。
在负数区域引入一个小的斜率来解决“神经元死亡”问题。
ReLU函数可以用代码实现如下:
def relu(x):
return np.maximum(0, x)
附加(梯度相关知识):
梯度是一个表示一个三维平面沿某一方向变化率最快的一个方向。
方向导数:
函数沿某个特定方向的变化率

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)