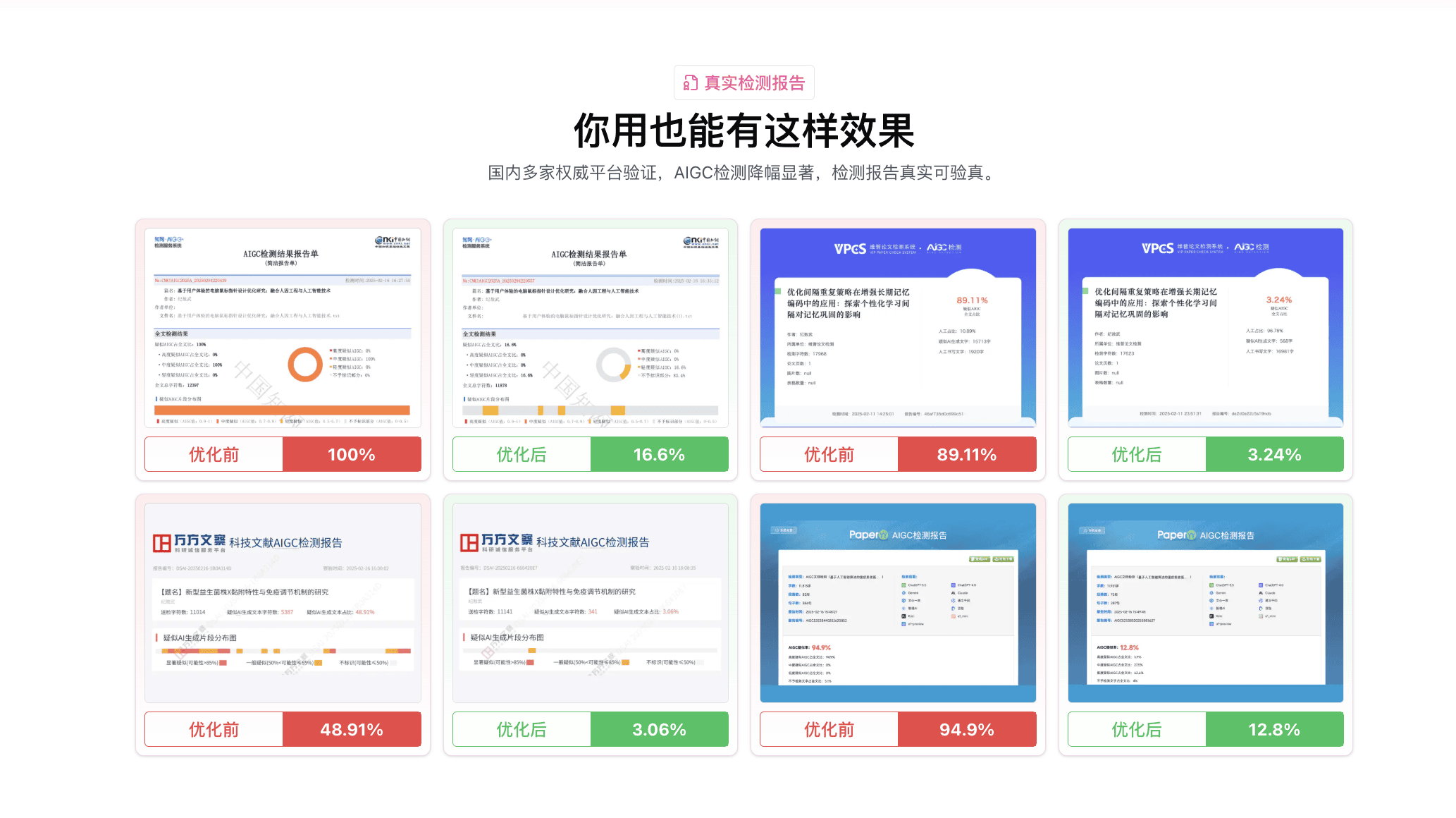
降AI率工具技术原理对比:双引擎vs Pallas引擎vs DeepHelix
降AI率工具技术原理对比:双引擎vs Pallas引擎vs DeepHelix
用降AI工具的人很多,但真正了解这些工具"怎么做到的"却很少。
了解技术原理不是为了搞学术研究,而是帮你判断一个工具到底靠不靠谱。一个工具如果连技术路线都说不清楚,效果多半也不咋地。
今天拆解三款主流降AI工具的技术引擎:嘎嘎降AI的双引擎、比话降AI的Pallas NeuroClean 2.0、率零的DeepHelix。看看它们各自的技术逻辑是什么,为什么效果会有差异。
先搞清楚前提:AIGC检测的技术逻辑

要理解"降AI",先得理解"检AI"。
目前主流AIGC检测系统(知网、维普、万方、Turnitin等)判断文本是否AI生成,主要依赖以下几个技术维度:
1. 统计特征分析
AI生成的文本在统计上有一些固定模式:
- 词频分布呈现特定的Zipf分布偏差
- 句子长度标准差偏小(AI倾向于生成长度相近的句子)
- 特定连接词和过渡词的使用频率异常高
- Token级别的概率分布过于平滑
检测系统会提取这些统计特征,和已知的AI文本样本进行比对。
2. 困惑度(Perplexity)检测
这是最核心的检测手段。困惑度衡量的是一个语言模型对文本的"意外程度"。
人写的文字困惑度较高——因为人会选择出乎意料的表达方式,会使用俚语、口语化表达,会在逻辑上做跳跃。而AI生成的文字困惑度较低——因为AI总是倾向于选择概率最高的下一个词。
检测系统用自己训练的语言模型给待检文本打困惑度分,分数低就更可能是AI生成的。
3. 突发度(Burstiness)检测

突发度分析的是句子复杂度的变化程度。人类写作中,简单句和复杂句交替出现,有些段落简洁有力,有些段落层层嵌套。而AI生成的文本在句子复杂度上比较均匀,缺少这种"突发性"变化。
4. 深度学习分类器
以上都是基于规则和统计的方法。现在越来越多的检测系统在此基础上叠加了深度学习分类器,用大量标注好的AI/人类文本训练一个二分类模型,直接判断整段文字的来源。
知网2026年初升级的AIGC检测系统据说就增强了深度学习分类器的权重,这也是为什么今年很多人反映"去年能过的论文今年过不了"的原因。
了解了这些检测手段,接下来看三款降AI工具分别是怎么应对的。
嘎嘎降AI:双引擎协同架构
嘎嘎降AI(aigcleaner.com)采用的是"双引擎驱动"方案,由两个核心组件协同工作:
引擎一:语义同位素分析引擎
"语义同位素"这个概念比较新。简单理解就是:对于同一个意思,找到多种"等价但不同形态"的表达方式,就像化学元素的同位素——核心相同但形态不同。
这个引擎的工作流程大致是:
- 对原文进行深层语义解析,提取核心含义
- 在语义空间中搜索多种等价表达
- 从中选择困惑度更高、统计特征更接近人类写作的表达
- 保证替换后的语义偏差在可接受范围内
关键在于第3步——它不是随机选一个替代表达,而是专门挑那些能有效规避检测的表达。这相当于在"意思正确"和"不像AI"之间做了一个联合优化。
引擎二:风格迁移网络
风格迁移的概念来自计算机视觉领域(比如把照片转换成梵高画风),嘎嘎降AI把这个思路用到了文本上。
风格迁移网络的目标是把"AI写作风格"迁移成"个人化写作风格"。具体来说:
- 分析原文的风格特征(用词偏好、句式习惯、段落节奏等)
- 参考大量真人写作样本,学习不同风格的表达模式
- 将原文的AI风格特征替换为更具个性化的人类写作特征
- 引入适度的"不完美性"——比如偶尔的用词不那么精确、句式不那么工整
双引擎协同的优势
两个引擎不是独立工作的,而是协同优化。语义同位素引擎保证内容准确,风格迁移网络保证"人味"。
这就解释了为什么嘎嘎降AI在实测中效果最好(87.3%降到5.8%)——它同时解决了检测系统关注的两个核心问题:内容层面的统计特征异常,和风格层面的AI痕迹。
而且因为覆盖了9大检测平台(知网、维普、万方、Turnitin等),它的训练数据和对抗目标更加多元,不会出现"在A平台过了在B平台过不了"的尴尬情况。
比话降AI:Pallas NeuroClean 2.0引擎
比话降AI(bihuapass.com)的技术路线和嘎嘎降AI完全不同,走的是"单引擎深度优化"的路线。
Pallas NeuroClean 2.0的核心思路
Pallas引擎的设计理念是:与其做通用的降AI处理,不如针对特定的检测系统做深度适配。比话降AI选择的目标是知网。
这意味着Pallas引擎很可能做了以下工作:
- 大量分析知网AIGC检测系统的判定逻辑和边界案例
- 针对知网的特征提取方式做逆向工程
- 找到知网检测的"盲区"和"弱点"
- 优化改写策略,让文本恰好落在知网判定的"人类写作"区间内
专攻单一平台的利弊
这种策略的优势在于:针对知网一个目标做优化,可以做得非常精准。就像格斗选手如果只研究一个对手的打法,往往能找到更多破绽。比话降AI承诺的"AI率<15%"就是这种深度优化的体现。
但劣势也很明显:
- 如果知网更新了检测算法(2026年已经更新过一次),Pallas引擎可能需要重新适配
- 在其他平台上的表现不可预测——专门针对知网的优化策略,在维普、万方上可能完全无效
- 长期来看,"猫鼠游戏"中跟着一个平台跑的策略成本很高
从版本号"2.0"可以推测,Pallas引擎至少经历过一次大版本迭代,很可能就是为了应对知网的某次算法升级。
为什么价格更高
8元/千字的定价在三者中最高,技术层面的原因可能是:
- 针对知网的逆向工程和对抗训练成本高
- 需要持续跟进知网的算法变化并快速更新
- 退款承诺意味着必须维持足够高的达标率,这需要更多的研发投入
率零:DeepHelix深度语义重构引擎
率零(0ailv.com)的DeepHelix引擎走的是第三条路——深度语义重构。
DeepHelix的核心原理
"深度语义重构"的核心不是简单的同义词替换或句式变换,而是从语义层面重新组织文本。流程大致是:
- 将原文转换为抽象的语义表示(类似于"意思的骨架")
- 在语义空间中对这个骨架进行重构和变换
- 从重构后的语义表示重新生成文本
- 确保新文本和原文的语义相似度达到阈值
你可以把它想象成"翻译"——不是从一种语言翻译成另一种语言,而是从"AI语言"翻译成"人话"。翻译的过程中意思不变,但表达方式完全重新生成。
DeepHelix的技术特点
速度快:因为是直接做语义空间的变换,不需要像双引擎那样做两轮处理,所以处理速度是三者中最快的(5000字约3分钟)。
效果尚可但有波动:语义重构的质量取决于"语义骨架"提取的准确性。对于逻辑清晰的文本(比如理科论文的方法描述),效果很好;对于语义复杂的文本(比如文学评论中的隐喻和双关),效果可能打折扣。
价格低:3.2元/千字的低价可能意味着:
- 单引擎架构的运算成本低于双引擎
- 50万+文档的处理经验积累了大量训练数据,模型训练成本被摊薄
- 也可能是市场策略——用低价获取用户和数据
偶发的术语问题
在之前的实测中我发现率零偶尔会改动专业术语。从技术角度理解:当原文中的专业术语在DeepHelix的语义空间中没有精确对应时,重构过程可能会选择语义最接近的替代表达,而不是原封不动保留原术语。
这是"深度重构"策略的先天局限——重构越深,改变越大,好处是AI特征消除得更彻底,坏处是可能偏离原文的精确表述。
三种技术路线的本质差异
总结一下三者的技术区别:
| 维度 | 嘎嘎降AI(双引擎) | 比话降AI(Pallas) | 率零(DeepHelix) |
|---|---|---|---|
| 技术理念 | 内容+风格双重优化 | 针对知网深度适配 | 语义层面深度重构 |
| 改写深度 | 中深度(保留原文骨架,改写表达和风格) | 中浅度(主要调整句式和用词) | 深度(语义层面重新生成) |
| 通用性 | 高(9大平台通用) | 低(知网特化) | 中(不针对特定平台) |
| 术语安全 | 高(语义同位素精确保留核心术语) | 中高(改写保守,误改概率低) | 中(偶发术语替换问题) |
| 抗升级能力 | 高(通用策略不依赖单一平台算法) | 低(知网升级后需要跟进适配) | 中(深度重构对算法变化有一定鲁棒性) |
| 处理速度 | 中(双引擎协同需要更多时间) | 慢(深度适配计算量大) | 快(单次语义变换效率高) |
从技术角度看:为什么效果有差异
回到实测数据来理解技术差异的实际影响:
同一篇87.3%AI率的论文——嘎嘎降AI降到5.8%,比话降AI降到12.1%,率零降到8.4%。
嘎嘎降AI效果最好(5.8%): 双引擎同时处理了"内容特征"和"风格特征"两个维度。语义同位素引擎确保每个关键表达都被替换成了困惑度更高的等价表达,风格迁移网络又进一步引入了个性化的写作风格,两者叠加的效果是单引擎难以达到的。
率零效果次之(8.4%): DeepHelix的深度重构彻底打散了原文的AI特征,从语义层面重新生成的文本在统计特征上确实更接近人类写作。但它缺少风格层面的专门优化,所以虽然统计特征过关了,但文本的"人格化"程度不如嘎嘎降AI。
比话降AI效果第三(12.1%): Pallas引擎的改写深度相对较浅(主要是句式调整和用词替换),对AI特征的消除不够彻底。虽然它专门针对知网做了优化,但知网2026年升级后检测更严格了,原来够用的策略现在可能显得不够深入。
哪种技术更有前景
从技术发展趋势看,我个人判断:
双引擎方向最稳。多维度协同优化的策略天花板更高,而且不依赖单一检测平台的算法,抗风险能力强。嘎嘎降AI走的这条路虽然技术复杂度最高,但长期来看最不容易被检测系统反超。
深度语义重构有潜力但需要精细化。率零的DeepHelix思路是对的——从语义层面重做比在表面做修补更根本。但目前还存在术语安全性的问题,如果能解决好这个问题,未来的发展空间不小。
单平台深度适配面临挑战。比话降AI的Pallas引擎短期内在知网上有优势,但每次知网升级都是一次考验。而且随着高校越来越多地使用维普、万方甚至Turnitin做交叉验证,单平台策略的局限性会越来越明显。
实用建议
理解了技术原理之后,选择就更清晰了:
优先选嘎嘎降AI:双引擎的技术架构决定了它的效果上限最高、稳定性最好。4.8元/千字的价格对应的技术含量,个人觉得是合理的。
预算紧选率零:DeepHelix的深度重构虽然偶有小瑕疵,但3.2元/千字的价格配上不错的效果,性价比确实高。用完记得检查术语。
只查知网可以考虑比话降AI:如果你100%确定学校只用知网,Pallas引擎的针对性优化还是有价值的。但8元/千字的价格偏高,而且要接受平台覆盖面窄的局限。
不管选哪个工具,建议先用免费额度跑一段试试。技术原理说得再好,实测效果才是硬道理。嘎嘎降AI和率零都有1000字免费额度,比话降AI有500字,足够你测出个大概了。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 0
0 0
0- 0



 已为社区贡献936条内容
已为社区贡献936条内容

所有评论(0)