用贝叶斯算法优化CNN进行分类预测:探索与实践
贝叶斯算法(Bayes)优化卷积神经网络(CNN)分类预测。 模型评价指标包括:准确率和混淆图等,代码质量极高,方便学习和替换数据。
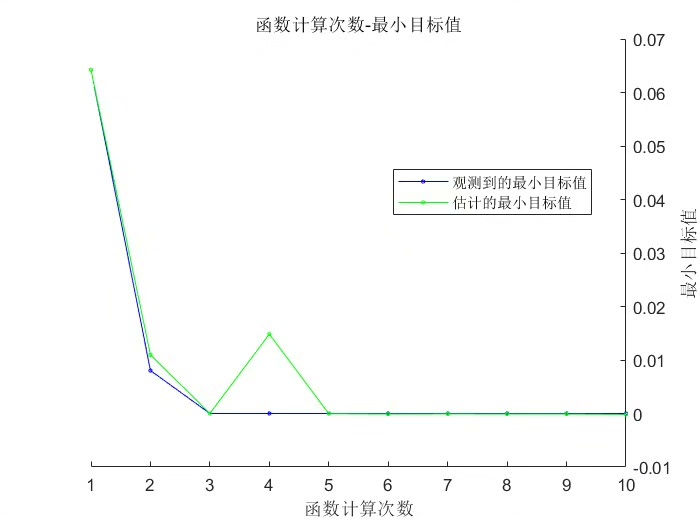
在机器学习和深度学习领域,卷积神经网络(CNN)以其在图像、音频等数据处理上的卓越表现而备受青睐,常用于分类预测任务。然而,CNN模型的超参数调整一直是个颇具挑战性的工作,超参数设置不当可能导致模型性能不佳。这时候,贝叶斯算法(Bayes)就能大显身手啦,它可以帮助我们更高效地优化CNN的超参数,提升分类预测的准确性。
贝叶斯算法优化CNN的原理
贝叶斯优化的核心思想是基于贝叶斯定理,对目标函数构建一个概率模型(通常是高斯过程)。在超参数空间中,通过不断地评估不同超参数组合下模型的性能,利用这个概率模型来预测哪些超参数组合可能带来更好的结果,从而有针对性地探索超参数空间,减少盲目尝试。
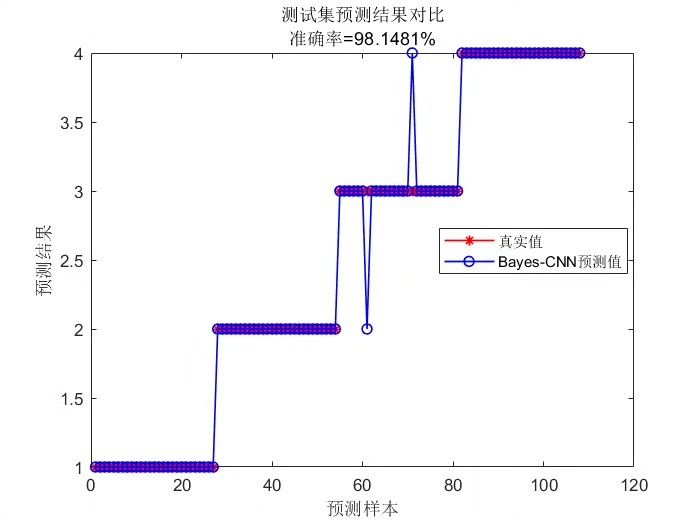
贝叶斯算法(Bayes)优化卷积神经网络(CNN)分类预测。 模型评价指标包括:准确率和混淆图等,代码质量极高,方便学习和替换数据。
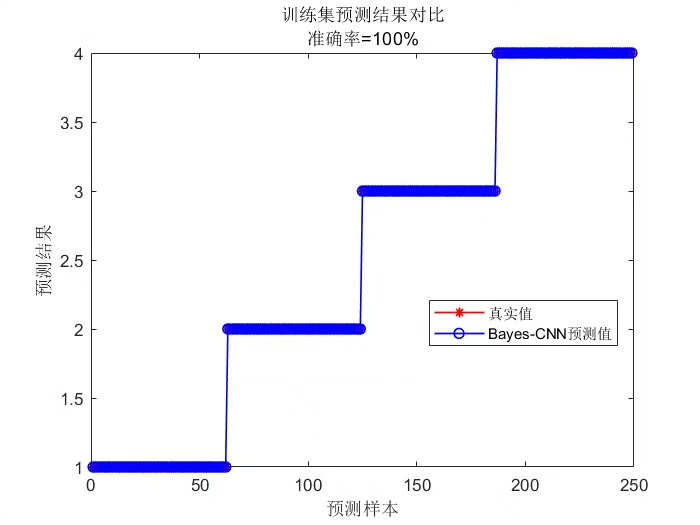
对于CNN而言,超参数比如学习率、卷积核大小、层数等,都会影响模型的性能。贝叶斯算法通过对这些超参数进行智能搜索,找到最优组合,让CNN发挥出最佳水平。
CNN分类预测模型
首先,我们来看一个简单的CNN分类预测模型代码示例(以Python和Keras框架为例):
from keras.models import Sequential
from keras.layers import Conv2D, MaxPooling2D, Flatten, Dense
model = Sequential()
model.add(Conv2D(32, (3, 3), activation='relu', input_shape=(64, 64, 3)))
model.add(MaxPooling2D((2, 2)))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(MaxPooling2D((2, 2)))
model.add(Flatten())
model.add(Dense(64, activation='relu'))
model.add(Dense(10, activation='softmax'))
model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])代码分析
- 模型构建:使用
Sequential模型,按顺序堆叠层。
-Conv2D层进行卷积操作,32表示输出的特征图数量,(3, 3)是卷积核大小,activation='relu'采用ReLU激活函数。这里的输入形状(64, 64, 3)假设输入图像是64x64像素且为RGB三通道。
-MaxPooling2D层执行最大池化操作,降低数据维度,(2, 2)是池化窗口大小。
-Flatten层将多维数据展平为一维,便于后续全连接层处理。
-Dense层是全连接层,最后一层输出10个类别(假设是10分类任务),使用softmax激活函数进行分类概率计算。 - 模型编译:使用
adam优化器,categorical_crossentropy损失函数适用于多分类任务,metrics=['accuracy']用于监控模型训练过程中的准确率。
贝叶斯优化与CNN结合
为了使用贝叶斯优化来调整CNN的超参数,我们可以借助scikit - optimize库。以下是一个简化的代码示例:
from skopt import gp_minimize
from skopt.space import Real, Integer
from skopt.utils import use_named_args
# 定义超参数搜索空间
space = [Integer(16, 128, name='num_filters1'),
Integer(16, 128, name='num_filters2'),
Real(0.0001, 0.1, 'log-uniform', name='learning_rate')]
# 定义目标函数,即使用不同超参数训练CNN并返回验证集准确率
@use_named_args(space)
def objective(num_filters1, num_filters2, learning_rate):
model = Sequential()
model.add(Conv2D(num_filters1, (3, 3), activation='relu', input_shape=(64, 64, 3)))
model.add(MaxPooling2D((2, 2)))
model.add(Conv2D(num_filters2, (3, 3), activation='relu'))
model.add(MaxPooling2D((2, 2)))
model.add(Flatten())
model.add(Dense(64, activation='relu'))
model.add(Dense(10, activation='softmax'))
model.compile(optimizer=Adam(lr=learning_rate),
loss='categorical_crossentropy',
metrics=['accuracy'])
history = model.fit(x_train, y_train, epochs=10, validation_data=(x_val, y_val))
return -history.history['val_accuracy'][-1]
# 执行贝叶斯优化
result = gp_minimize(objective, space, n_calls = 20, random_state=0)代码分析
- 定义超参数搜索空间:
-space列表中定义了三个超参数的搜索范围。Integer(16, 128, name='numfilters1')表示第一个卷积层的特征图数量在16到128之间;同理numfilters2是第二个卷积层的特征图数量范围;Real(0.0001, 0.1, 'log-uniform', name='learning_rate')表示学习率在0.0001到0.1之间,采用对数均匀分布搜索。 - 目标函数:
-@usenamedargs(space)装饰器将超参数传递给目标函数objective。
- 在objective函数内,根据传入的超参数构建CNN模型,编译并训练模型。注意这里使用Adam(lr = learningrate)来设置学习率。
- 模型训练10个epoch,并在验证集上评估,返回验证集准确率的负数,因为gpminimize默认是最小化目标函数。 - 执行贝叶斯优化:
-gpminimize函数执行贝叶斯优化过程,ncalls = 20表示尝试20次不同的超参数组合,random_state = 0设置随机种子保证结果可复现。
模型评价指标
准确率(Accuracy)
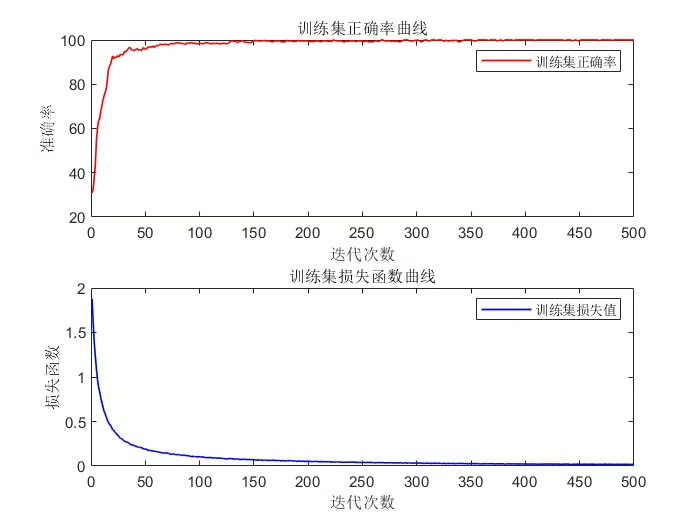
准确率是分类任务中最常用的指标之一,它表示分类正确的样本数占总样本数的比例。在上述Keras代码中,我们在model.compile时将metrics=['accuracy'],这样在模型训练过程中就能监控训练集和验证集的准确率。
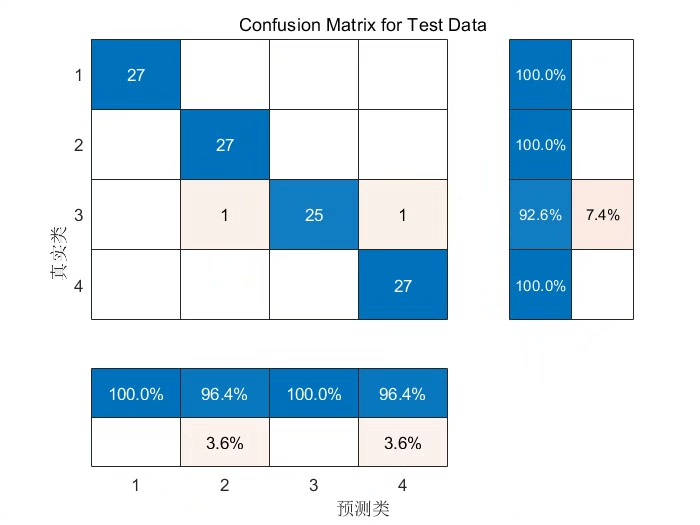
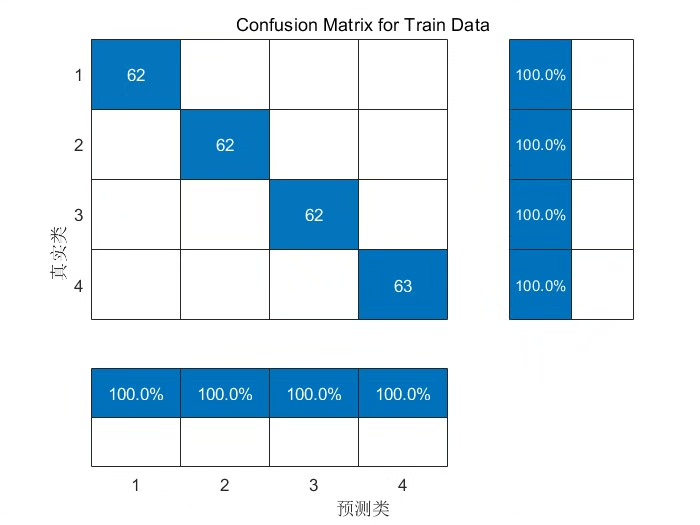
混淆矩阵(Confusion Matrix)
混淆矩阵可以直观地展示模型在各个类别上的分类情况。在Python中,我们可以使用scikit - learn库来计算和绘制混淆矩阵。
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay
import matplotlib.pyplot as plt
y_pred = model.predict(x_test).argmax(axis = 1)
y_true = y_test.argmax(axis = 1)
cm = confusion_matrix(y_true, y_pred)
disp = ConfusionMatrixDisplay(confusion_matrix = cm)
disp.plot()
plt.show()代码分析
ypred = model.predict(xtest).argmax(axis = 1):对测试集进行预测,并获取预测概率最高的类别索引。ytrue = ytest.argmax(axis = 1):获取测试集真实标签的类别索引。cm = confusionmatrix(ytrue, y_pred):计算混淆矩阵。disp = ConfusionMatrixDisplay(confusion_matrix = cm)和disp.plot()以及plt.show():绘制并展示混淆矩阵。
通过贝叶斯算法优化CNN的超参数,并使用准确率和混淆矩阵等指标进行评价,我们能够构建出性能更优的分类预测模型。无论是图像分类、声音识别还是其他相关领域,这种方法都具有很大的实用价值,而且上述代码质量较高,大家可以很方便地学习并根据自己的数据进行替换和调整。希望大家在实践中尝试这种方法,提升自己的模型性能!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 0
0 0
0- 0



 已为社区贡献30条内容
已为社区贡献30条内容

所有评论(0)