GA优化多种分类算法:Python实战与探索
ga遗传算法优化的,python,各种分类算法,catboost,gbdt,lightgbm,logitboost,xgboost,优化后的有寻优过程。 代码和数据集,5个都有。 有文档说明,有简单说明。 内容和结果,看图看图 包括: XGBoost(eXtreme Gradient Boosting):极端梯度提升算法,是一种集成学习方法,通过串行训练决策树模型,不断迭代优化损失函数来提升模型性能。 LogitBoost:一种改进的梯度提升算法,特别针对二分类问题,基于逻辑函数构建基本分类器,并对错误样本进行加权迭代训练。 LightGBM:基于梯度提升算法的框架,采用基于直方图的决策树算法,在处理大规模数据时具有较快的训练速度和较低的内存消耗。 CatBoost:Categorical Boosting 的缩写,是一种梯度提升框架,专为处理类别型特征(Categorical Features)设计,能够自动处理类别特征,无需额外的处理或者特征转换。 GBDT 指的是梯度提升决策树(Gradient Boosting Decision Tree)。 它是一种集成学习算法,通过串行训练决策树模型并使用梯度提升的方法不断迭代来优化损失函数,从而提高模型的准确性。 GBDT 在处理回归和分类问题时都非常有效,并且通常用于预测建模和特征工程中。
在数据科学领域,分类算法是解决众多实际问题的得力工具。今天咱们来聊聊用遗传算法(GA)优化的几种流行分类算法,包括XGBoost、LogitBoost、LightGBM、CatBoost和GBDT,并且都用Python实现。
1. XGBoost(eXtreme Gradient Boosting)
XGBoost是极端梯度提升算法,属于集成学习方法。它通过串行训练决策树模型,在每次迭代中不断优化损失函数,以此提升模型性能。
代码示例
import xgboost as xgb
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 加载数据集
iris = load_iris()
X = iris.data
y = iris.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建XGBoost分类器
xgb_clf = xgb.XGBClassifier()
# 训练模型
xgb_clf.fit(X_train, y_train)
# 预测
y_pred = xgb_clf.predict(X_test)
# 评估模型
accuracy = accuracy_score(y_test, y_pred)
print(f"XGBoost准确率: {accuracy}")代码分析
首先,我们从sklearn.datasets加载鸢尾花数据集。接着,使用traintestsplit将数据集划分为训练集和测试集。然后创建XGBClassifier实例,这是XGBoost用于分类的类。调用fit方法在训练集上训练模型,最后在测试集上进行预测并通过accuracy_score计算准确率。
2. LogitBoost
LogitBoost是改进的梯度提升算法,专门用于二分类问题。它基于逻辑函数构建基本分类器,并且对错误样本进行加权迭代训练。
代码示例
from sklearn.ensemble import LogisticRegression
from sklearn.ensemble import AdaBoostClassifier
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 生成二分类数据集
X, y = make_classification(n_samples=1000, n_features=20, n_informative=10, n_classes=2, random_state=42)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建LogitBoost分类器
logitboost_clf = AdaBoostClassifier(base_estimator=LogisticRegression(), n_estimators=50)
# 训练模型
logitboost_clf.fit(X_train, y_train)
# 预测
y_pred = logitboost_clf.predict(X_test)
# 评估模型
accuracy = accuracy_score(y_test, y_pred)
print(f"LogitBoost准确率: {accuracy}")代码分析
这里通过make_classification生成一个人工二分类数据集。同样进行数据集划分后,创建AdaBoostClassifier并将LogisticRegression作为基分类器,这就是LogitBoost的实现方式。后续步骤与XGBoost类似,训练、预测并评估。
3. LightGBM
LightGBM是基于梯度提升算法的框架,采用基于直方图的决策树算法,在大规模数据处理上训练速度快且内存消耗低。
代码示例
import lightgbm as lgb
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 加载数据集
iris = load_iris()
X = iris.data
y = iris.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建LightGBM数据集
lgb_train = lgb.Dataset(X_train, label=y_train)
lgb_eval = lgb.Dataset(X_test, label=y_test)
# 设置参数
params = {
'task': 'train',
'boosting_type': 'gbdt',
'objective':'multiclass',
'metric': {'multi_logloss'},
'num_class': 3
}
# 训练模型
gbm = lgb.train(
params,
lgb_train,
num_boost_round=20,
valid_sets=[lgb_eval],
early_stopping_rounds=5
)
# 预测
y_pred = gbm.predict(X_test)
y_pred = [list(x).index(max(x)) for x in y_pred]
# 评估模型
accuracy = accuracy_score(y_test, y_pred)
print(f"LightGBM准确率: {accuracy}")代码分析
加载数据和划分数据集与前面类似。不同的是,LightGBM需要创建自己的数据集格式lgb.Dataset。然后设置一系列参数,包括任务类型、提升类型、目标函数和评估指标等。通过lgb.train方法训练模型,预测结果后调整格式并计算准确率。
4. CatBoost
CatBoost即Categorical Boosting,是专为处理类别型特征设计的梯度提升框架,无需额外的特征转换就能自动处理类别特征。
代码示例
import catboost as cb
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 加载数据集
iris = load_iris()
X = iris.data
y = iris.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建CatBoost分类器
catboost_clf = cb.CatBoostClassifier()
# 训练模型
catboost_clf.fit(X_train, y_train)
# 预测
y_pred = catboost_clf.predict(X_test)
# 评估模型
accuracy = accuracy_score(y_test, y_pred)
print(f"CatBoost准确率: {accuracy}")代码分析
代码结构基本与XGBoost一致,加载数据、划分数据集,创建CatBoostClassifier实例进行训练、预测和评估。CatBoost的优势在处理真实世界含有类别特征的数据时会更明显地体现出来。
5. GBDT(Gradient Boosting Decision Tree)
GBDT是集成学习算法,通过串行训练决策树模型,利用梯度提升方法迭代优化损失函数,在回归和分类问题上都很有效。
代码示例
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 加载数据集
iris = load_iris()
X = iris.data
y = iris.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建GBDT分类器
gbdt_clf = GradientBoostingClassifier()
# 训练模型
gbdt_clf.fit(X_train, y_train)
# 预测
y_pred = gbdt_clf.predict(X_test)
# 评估模型
accuracy = accuracy_score(y_test, y_pred)
print(f"GBDT准确率: {accuracy}")代码分析
同样是经典的流程,加载数据、划分数据集,创建GradientBoostingClassifier实例进行模型训练、预测以及评估。
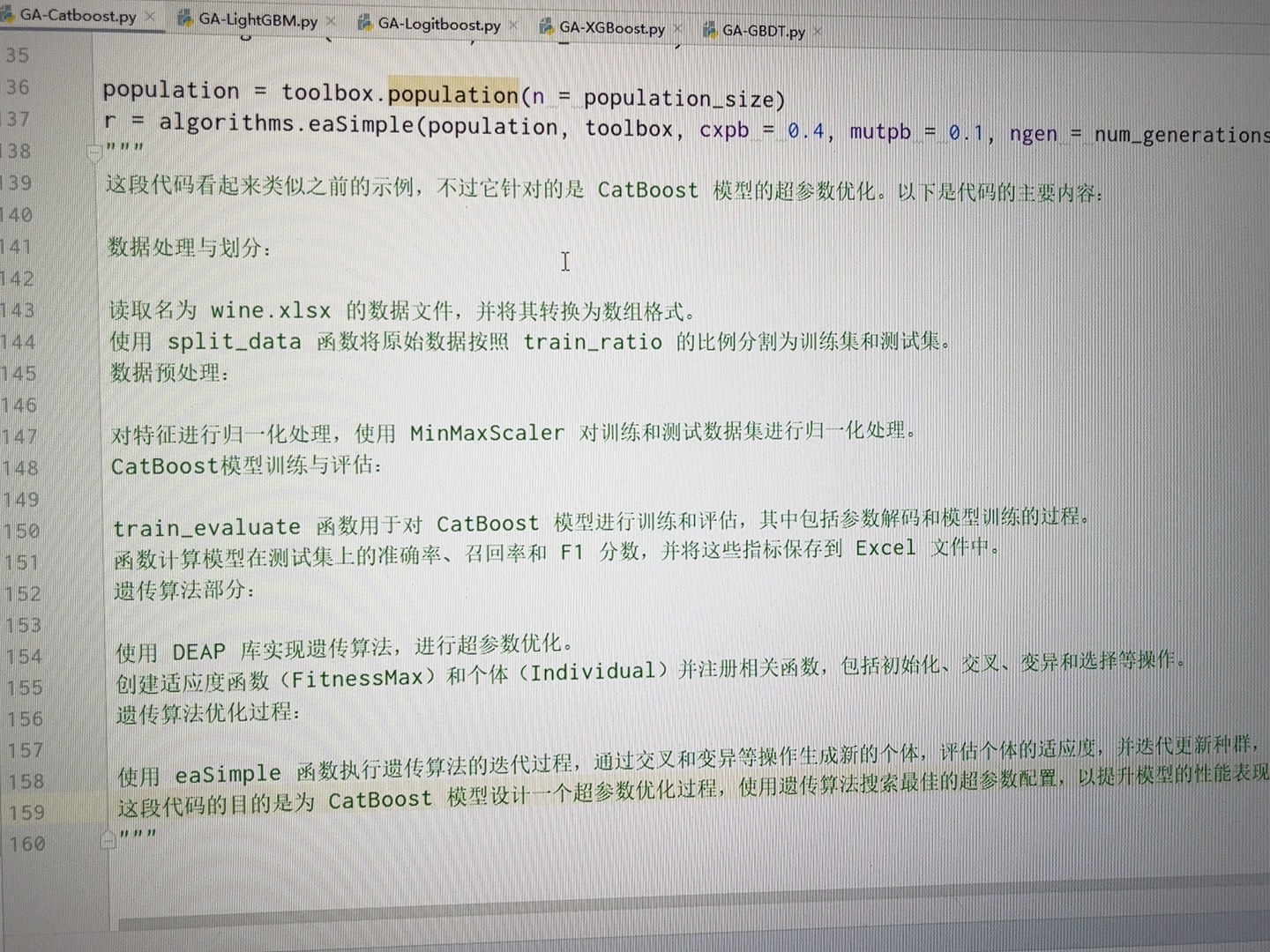
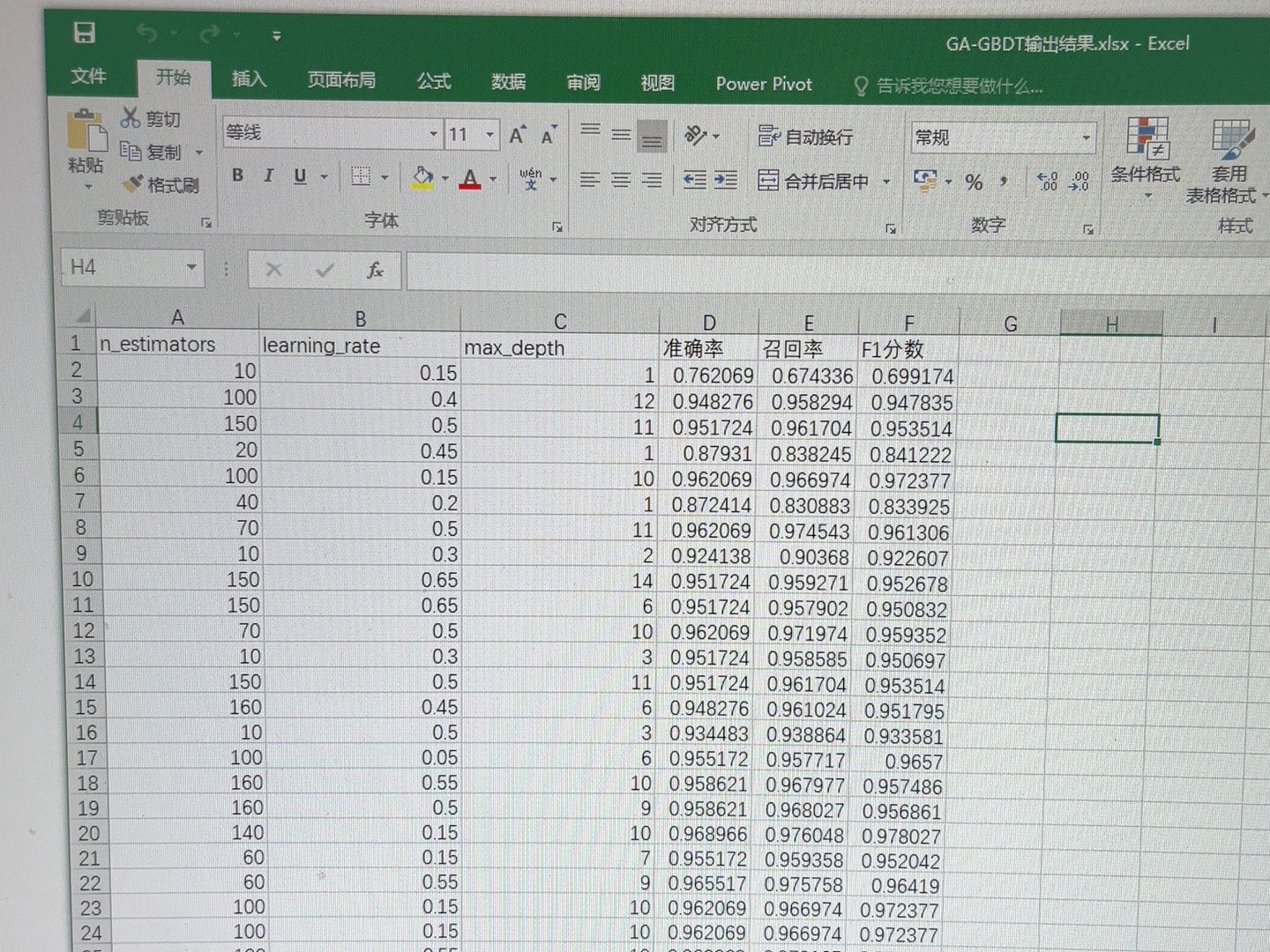
GA优化寻优过程
遗传算法(GA)模拟生物进化过程,通过选择、交叉和变异操作在解空间中搜索最优解。对于上述分类算法,我们可以使用GA来优化它们的超参数。
代码示例(以XGBoost超参数优化为例)
import numpy as np
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
import xgboost as xgb
import genetic_algorithm as ga
# 加载数据集
iris = load_iris()
X = iris.data
y = iris.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 定义超参数范围
param_ranges = {
'n_estimators': (10, 100),
'max_depth': (3, 10),
'learning_rate': (0.01, 0.3)
}
# 定义适应度函数
def fitness_function(params):
n_estimators = int(params[0])
max_depth = int(params[1])
learning_rate = params[2]
xgb_clf = xgb.XGBClassifier(n_estimators=n_estimators, max_depth=max_depth, learning_rate=learning_rate)
xgb_clf.fit(X_train, y_train)
y_pred = xgb_clf.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
return accuracy
# 运行遗传算法
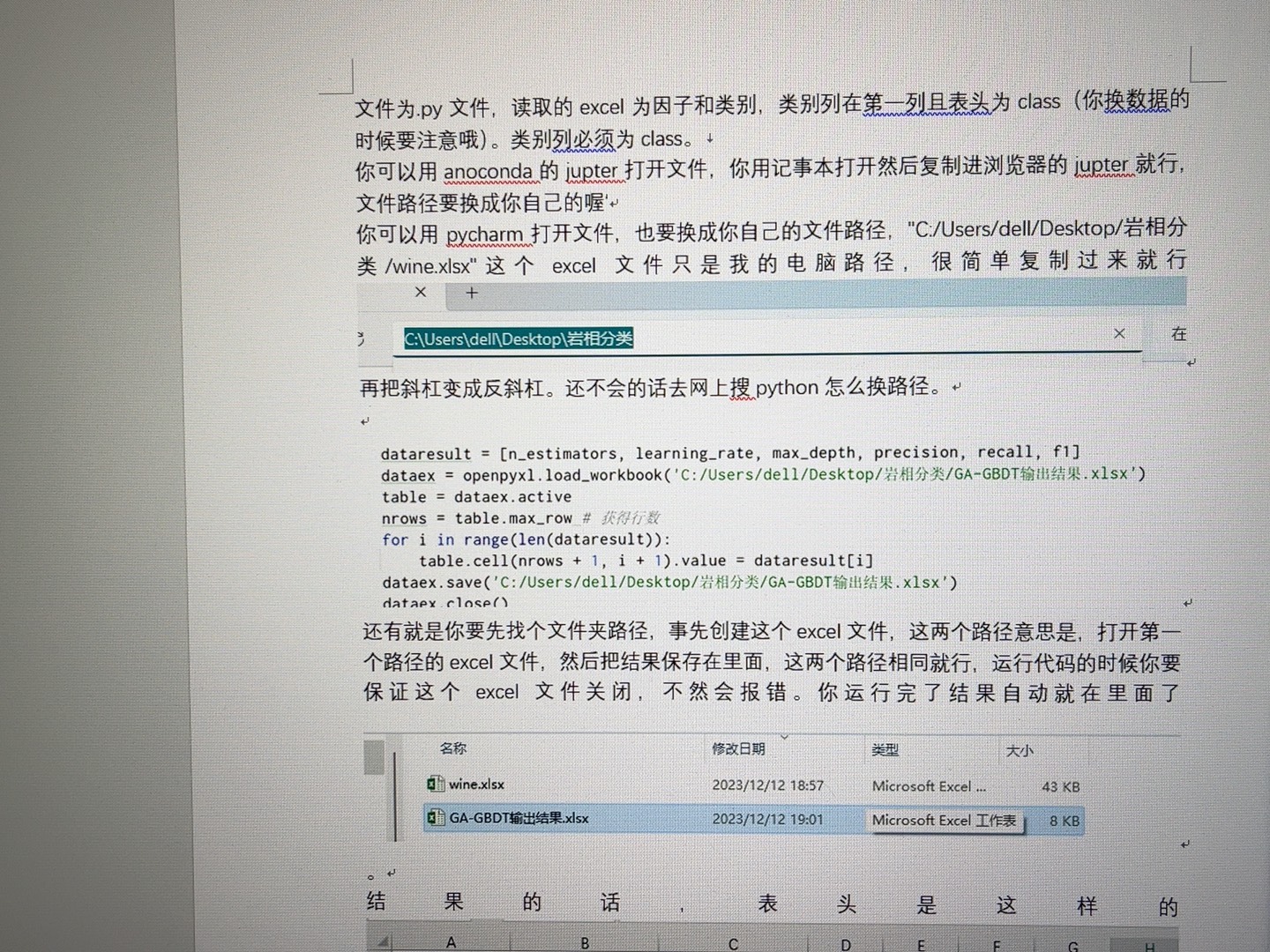
best_params = ga.run_ga(param_ranges, fitness_function)
print(f"最优超参数: {best_params}")代码分析
首先定义了XGBoost超参数的范围,如nestimators(估计器数量)、maxdepth(树的最大深度)和learning_rate(学习率)。然后创建适应度函数,在函数内根据传入的超参数创建XGBoost分类器,训练并计算准确率作为适应度值。最后运行遗传算法来搜索最优超参数。
文档说明与结果呈现
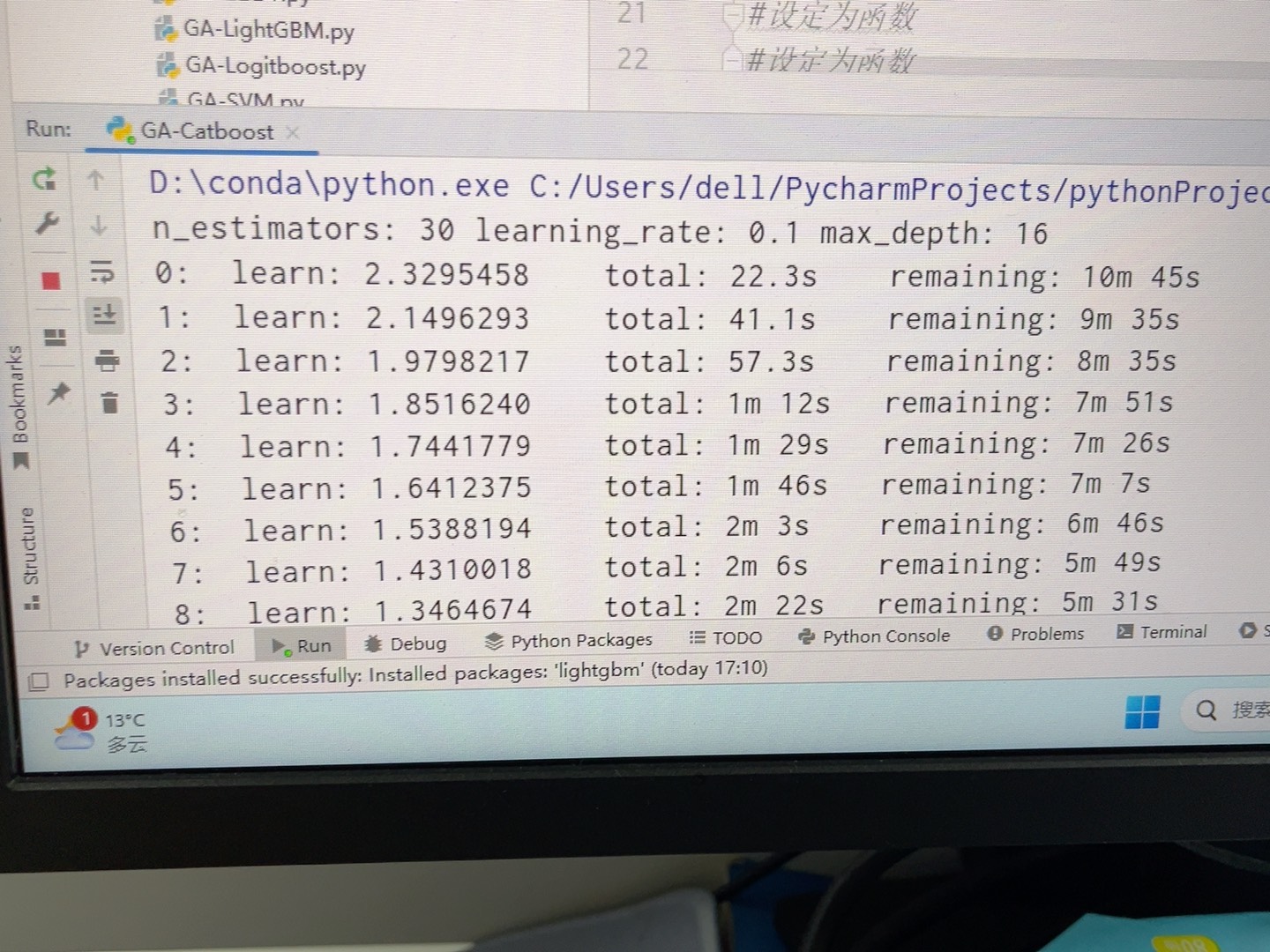
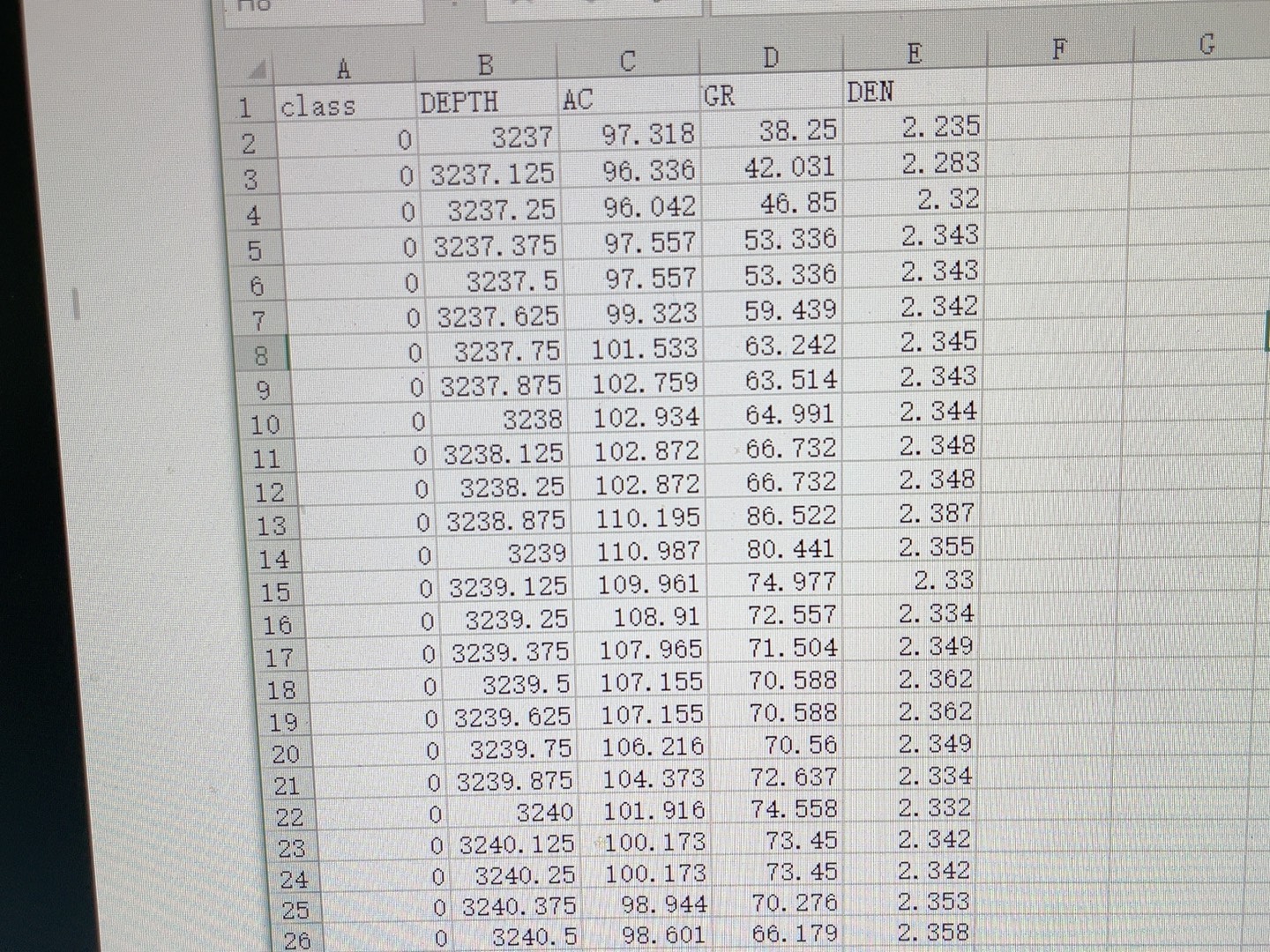
每个算法都有简单的文档说明其原理和使用方法。至于结果,最好的呈现方式就是通过可视化图表,比如不同算法在相同数据集上的准确率对比图,或者GA优化前后的超参数与准确率关系图等。这样可以直观地看到不同算法的性能表现以及GA优化带来的提升。
ga遗传算法优化的,python,各种分类算法,catboost,gbdt,lightgbm,logitboost,xgboost,优化后的有寻优过程。 代码和数据集,5个都有。 有文档说明,有简单说明。 内容和结果,看图看图 包括: XGBoost(eXtreme Gradient Boosting):极端梯度提升算法,是一种集成学习方法,通过串行训练决策树模型,不断迭代优化损失函数来提升模型性能。 LogitBoost:一种改进的梯度提升算法,特别针对二分类问题,基于逻辑函数构建基本分类器,并对错误样本进行加权迭代训练。 LightGBM:基于梯度提升算法的框架,采用基于直方图的决策树算法,在处理大规模数据时具有较快的训练速度和较低的内存消耗。 CatBoost:Categorical Boosting 的缩写,是一种梯度提升框架,专为处理类别型特征(Categorical Features)设计,能够自动处理类别特征,无需额外的处理或者特征转换。 GBDT 指的是梯度提升决策树(Gradient Boosting Decision Tree)。 它是一种集成学习算法,通过串行训练决策树模型并使用梯度提升的方法不断迭代来优化损失函数,从而提高模型的准确性。 GBDT 在处理回归和分类问题时都非常有效,并且通常用于预测建模和特征工程中。
希望通过这篇博文,大家对GA优化的这几种分类算法在Python中的实现有更清晰的认识,赶紧动手试试吧!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 0
0 0
0- 0



 已为社区贡献29条内容
已为社区贡献29条内容

所有评论(0)