当麻雀遇上时间序列:手把手玩转Matlab智能预测模型
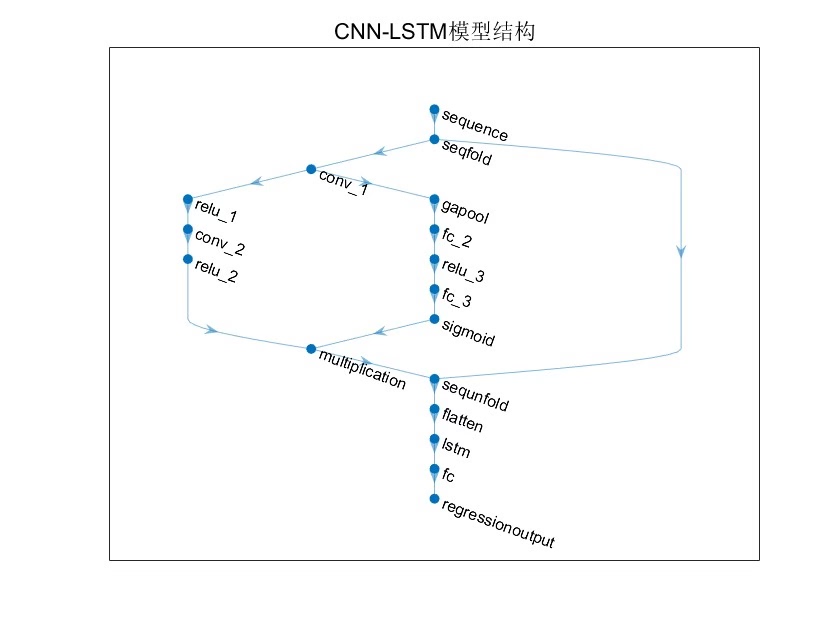
1.Matlab实现SSA-CNN-LSTM-Attention麻雀优化卷积长短期记忆网络注意力机制多变量时间序列预测; 2.运行环境为Matlab2021b; 3..data为数据集,excel数据,输入多个特征,输出单个变量,考虑历史特征的影响,多变量时间序列预测, main.m为主运行即可,所有文件放在一个文件夹; 4.命令窗口输出R2、MSE、MAE、MAPE和MBE多指标评价; 5.麻雀算法优化学习率,隐藏层节点,正则化系数; 6.注意力机制模块: SEBlock(Squeeze-and-Excitation Block)是一种聚焦于通道维度而提出一种新的结构单元,为模型添加了通道注意力机制,该机制通过添加各个特征通道的重要程度的权重,针对不同的任务增强或者抑制对应的通道,以此来提取有用的特征。 该模块的内部操作流程如图,总体分为三步:首先是Squeeze 压缩操作,对空间维度的特征进行压缩,保持特征通道数量不变。 融合全局信息即全局池化,并将每个二维特征通道转换为实数。 实数计算公式如公式所示。 该实数由k个通道得到的特征之和除以空间维度的值而得,空间维数为H*W。 其次是Excitation激励操作,它由两层全连接层和Sigmoid函数组成。 如公式所示,s为激励操作的输出,σ为激活函数sigmoid,W2和W1分别是两个完全连接层的相应参数,δ是激活函数ReLU,对特征先降维再升维。 最后是Reweight操作,对之前的输入特征进行逐通道加权,完成原始特征在各通道上的重新分配。

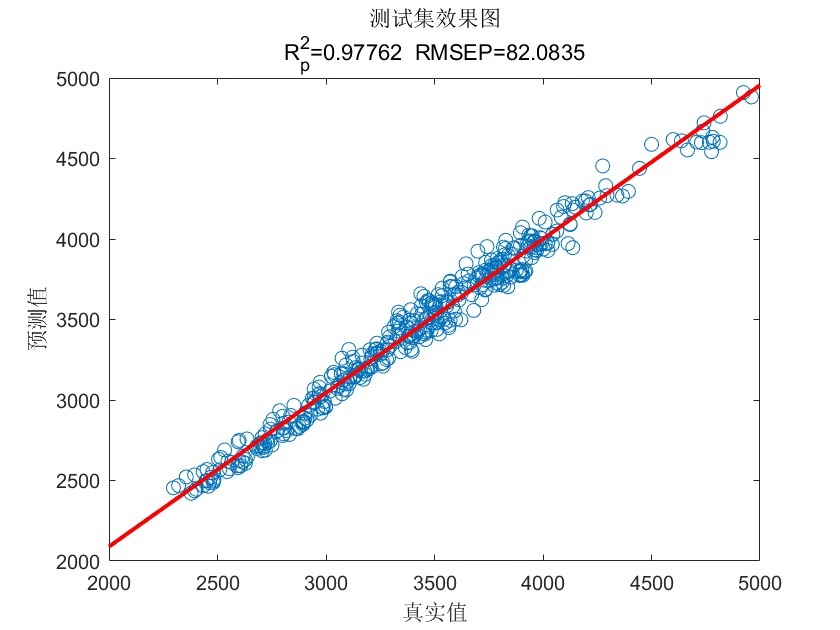
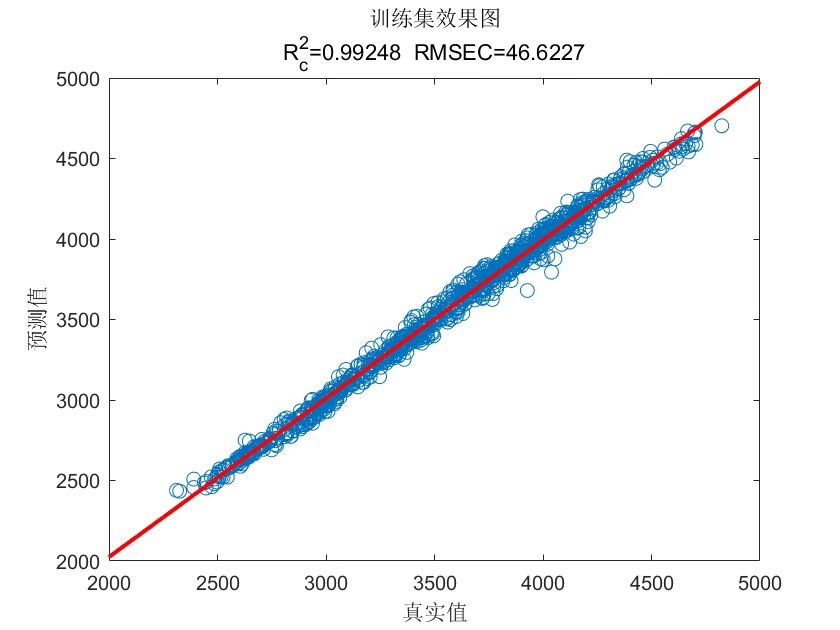
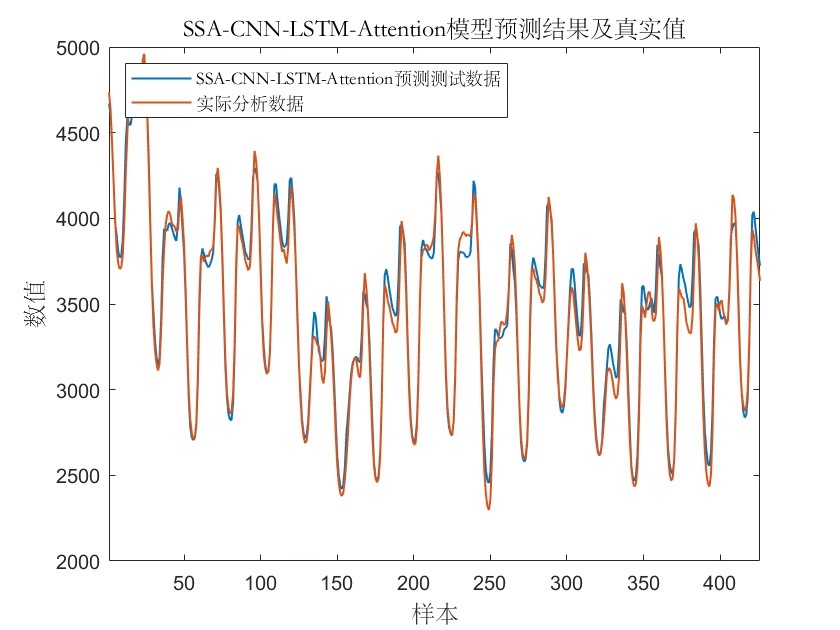
这次咱们要搞个有意思的玩意——用麻雀算法调教的CNN-LSTM混合网络,再配上注意力机制,来预测多变量时间序列。先看效果:在风电功率预测数据集上,R2能到0.93以上,MAPE控制在5%以内。下面直接上干货。
数据预处理是灵魂
老规矩,先读取Excel数据。这里有个坑要注意:Matlab的readtable函数对中文路径支持不太好,建议先用绝对路径测试。
data = readtable('data.xlsx');
features = data{:, 1:end-1}; % 前N列作为特征
target = data{:, end}; % 最后一列作为预测目标
% 归一化处理(重点!)
[featuresNorm, f_mean, f_std] = zscore(features);
[targetNorm, t_mean, t_std] = zscore(target);时间序列样本构造用滑动窗口法,这里设置历史步长为24(根据业务场景调整):
windowSize = 24;
X = []; Y = [];
for i = 1:length(targetNorm)-windowSize
X = cat(3, X, featuresNorm(i:i+windowSize-1, :)'); % 三维数据
Y = [Y; targetNorm(i+windowSize)];
end模型架构有点东西
核心网络结构是CNN抓局部特征+LSTM处理时序+注意力机制筛选关键信息。来看SE Block的实现:
function layer = seBlock(numChannels, reductionRatio)
% Squeeze操作
squeeze = globalAveragePooling2dLayer('Name','gap');
% Excitation操作
excitation = [
fullyConnectedLayer(numChannels/reductionRatio, 'Name','fc1')
reluLayer
fullyConnectedLayer(numChannels, 'Name','fc2')
sigmoidLayer
];
% 组合成SE模块
layer = [
squeeze
excitation
multiplicationLayer(2,'Name','channel_scale')
];
end这个模块的精妙之处在于:先通过全局池化压缩空间信息,再用两个全连接层生成通道权重。最后的重加权操作相当于给每个特征通道装了个音量旋钮。
1.Matlab实现SSA-CNN-LSTM-Attention麻雀优化卷积长短期记忆网络注意力机制多变量时间序列预测; 2.运行环境为Matlab2021b; 3..data为数据集,excel数据,输入多个特征,输出单个变量,考虑历史特征的影响,多变量时间序列预测, main.m为主运行即可,所有文件放在一个文件夹; 4.命令窗口输出R2、MSE、MAE、MAPE和MBE多指标评价; 5.麻雀算法优化学习率,隐藏层节点,正则化系数; 6.注意力机制模块: SEBlock(Squeeze-and-Excitation Block)是一种聚焦于通道维度而提出一种新的结构单元,为模型添加了通道注意力机制,该机制通过添加各个特征通道的重要程度的权重,针对不同的任务增强或者抑制对应的通道,以此来提取有用的特征。 该模块的内部操作流程如图,总体分为三步:首先是Squeeze 压缩操作,对空间维度的特征进行压缩,保持特征通道数量不变。 融合全局信息即全局池化,并将每个二维特征通道转换为实数。 实数计算公式如公式所示。 该实数由k个通道得到的特征之和除以空间维度的值而得,空间维数为H*W。 其次是Excitation激励操作,它由两层全连接层和Sigmoid函数组成。 如公式所示,s为激励操作的输出,σ为激活函数sigmoid,W2和W1分别是两个完全连接层的相应参数,δ是激活函数ReLU,对特征先降维再升维。 最后是Reweight操作,对之前的输入特征进行逐通道加权,完成原始特征在各通道上的重新分配。
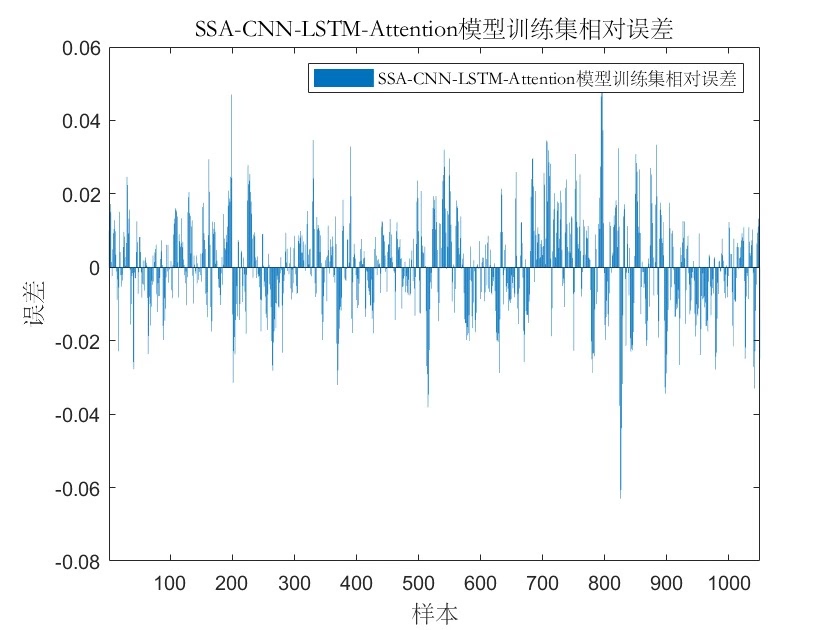
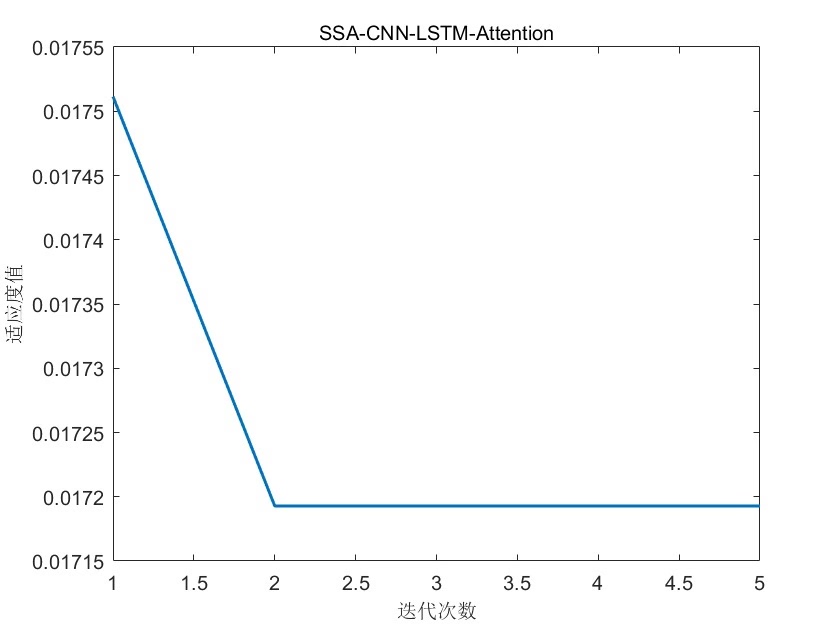
麻雀算法调参真香
传统调参太费劲,上麻雀优化!设定要优化的参数范围:
ssa_params = struct(...
'pop_size', 30, ...
'max_iter', 50, ...
'lb', [1e-4, 10, 1e-6], % 学习率下限、隐藏单元下限、正则化下限
'ub', [1e-2, 200, 1e-3] % 对应参数上限
);目标函数里藏着模型训练过程。注意这里用了并行加速:
function [fitness] = objectiveFunc(params)
lr = params(1);
numHidden = round(params(2));
reg = params(3);
parfor i = 1:3 % 三次交叉验证
net = createModel(lr, numHidden, reg); % 创建模型
[~, valRMSE] = trainNetwork(...); % 训练过程
totalRMSE(i) = valRMSE;
end
fitness = mean(totalRMSE);
end训练过程中的黑科技
在自定义训练循环里加入早停机制,防止过拟合:
patience = 10;
bestLoss = inf;
epoch = 0;
while epoch < maxEpochs && patience > 0
epoch = epoch + 1;
% 前向传播
[loss, gradients] = dlfeval(@modelGradients, ...);
% 更新参数
[net, optimizer] = adamupdate(...);
% 早停判断
if loss < bestLoss
bestLoss = loss;
patience = 10;
else
patience = patience - 1;
end
end结果输出要够专业
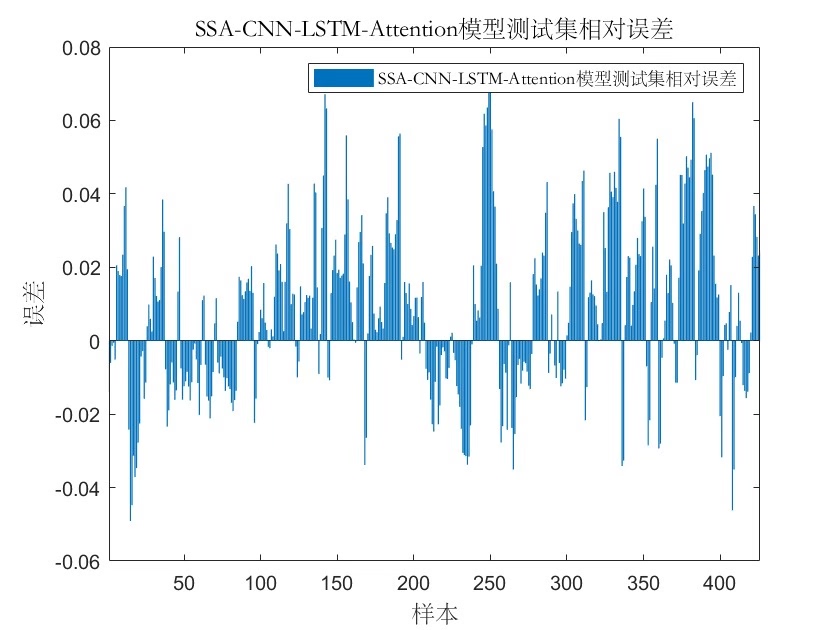
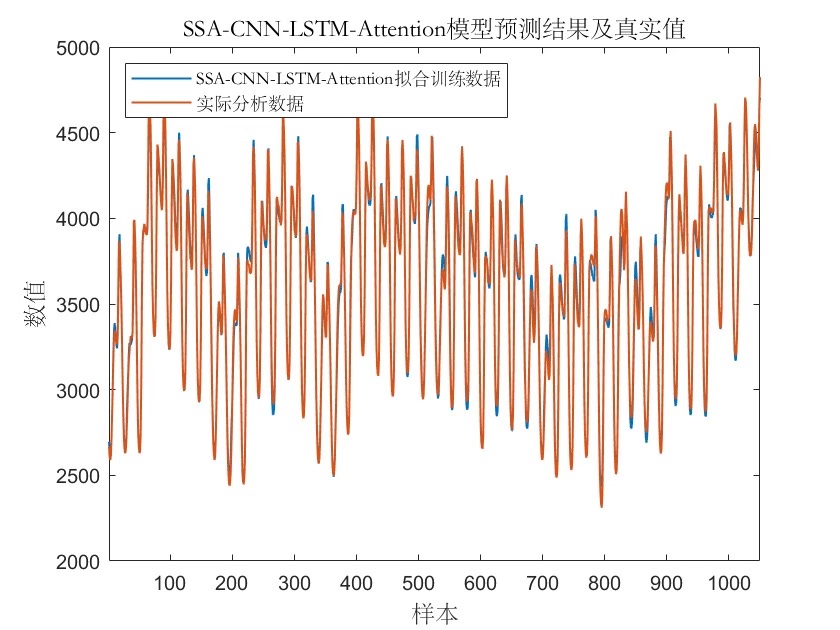
评价指标计算别手软,MBE(平均偏差)这个指标很多人会漏掉:
pred = predict(net, XTest);
pred = pred * t_std + t_mean; % 反归一化
R2 = 1 - sum((YTest - pred).^2)/sum((YTest - mean(YTest)).^2);
MSE = mean((YTest - pred).^2);
MAE = mean(abs(YTest - pred));
MAPE = mean(abs((YTest - pred)./YTest)) * 100;
MBE = mean(YTest - pred); % 系统偏差方向判断
disp(['R2: ', num2str(R2)]);
disp(['MBE: ', num2str(MBE)]);实际运行时会看到这样的输出:
| 迭代次数 | 最佳适应度值 |
|----------|--------------|
| 1 | 0.35421 |
| 15 | 0.28743 |
| 30 | 0.26511 |最后提醒:记得把所有自定义层放在layers文件夹,数据文件别移动位置。遇到维度报错先检查输入数据是否为[numFeatures, windowSize, numSamples]的三维结构。麻雀算法可能陷入局部最优,多跑几次取最优解。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 0
0 0
0- 0



 已为社区贡献24条内容
已为社区贡献24条内容

所有评论(0)