AI 终于有了“记忆操作系统“——MemOS 7100+ Star,让你的 OpenClaw 从此不再失忆
哈喽,大家好,我是最近在焦虑的顾北!
我最近在关注一个项目,叫 MemOS。

起因是我在跑一个长期 Agent 任务的时候,发现一个让人抓狂的问题:每次对话重新开始,AI 完全不记得上次做了什么。哪怕我在 MEMORY.md 里写了一堆上下文,token 消耗还是噌噌往上涨,而且随着会话变长,AI 开始答非所问。
这根本问题是什么?大模型没有真正意义上的记忆管理系统。
MemOS 就是来解决这个问题的。
AI 的"失忆症",比你想象的更严重
现在的 LLM,记忆系统基本上就两种:
-
参数记忆:训练进去的知识,烧死在权重里,改不了,也不会自动更新
-
上下文记忆:当前 session 的对话历史,窗口关了就消失
RAG 算是一个补丁,但它本质上是个无状态系统——只管检索,不管生命周期,不管演化,不管跨平台迁移。
你用一个 Agent 用了三个月,它依然不知道你叫什么名字,不知道你的工作习惯,不知道上次任务是怎么解决的。
每次都在烧你的钱,给你一个失忆的 AI。
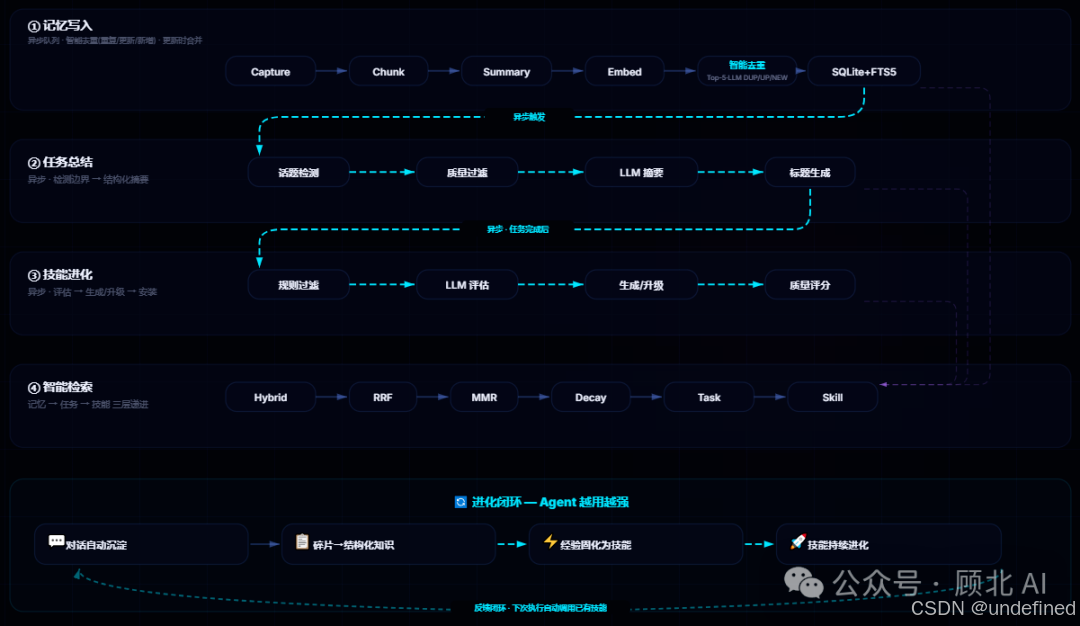
MemOS 的核心思路:把记忆当成操作系统资源来管
MemOS 来自 MemTensor(上海记忆张量科技)和上海交通大学、人民大学、北京大学等多所高校的联合研究,2025 年 7 月在 arXiv 发表论文,随后开源。
它的核心思想其实一句话能说清楚:
像操作系统管理 CPU、内存、存储一样,统一管理 AI 的记忆。
传统 OS 把内存抽象成可调度的系统资源;MemOS 把 AI 的记忆也做成了"一等公民",有生命周期、有优先级、有调度器、有垃圾回收。

三种记忆类型,统一管理
MemOS 定义了三类记忆并统一纳管:
|
记忆类型 |
含义 |
对应传统 OS |
|---|---|---|
| 参数记忆 |
模型权重里的知识 |
ROM/固件 |
| 激活记忆 |
KV Cache,运行时状态 |
RAM |
| 明文记忆 |
可读写的文本记忆 |
磁盘存储 |
以前这三类各自为政,互不沟通。MemOS 用一个叫 MemCube 的标准化容器把它们封装在一起,每个记忆单元都带有元数据:创建时间、来源、相关性评分、生命周期状态。
MemScheduler:记忆调度器
类比 OS 的进程调度器,MemOS 有一个 MemScheduler 来负责:
-
决定哪些记忆应该被召回(检索)
-
哪些记忆已经过时应该被清除(遗忘)
-
哪些记忆应该被合并升级(进化)
这套调度机制让 AI 在回答问题前,会先主动检索相关记忆,而不是傻乎乎地把整段历史对话全塞进 prompt。
MemOS 2.0「星尘 Stardust」:现在的进度
截至今天(2026 年 3 月 16 日),MemOS 已经发布到 v2.0.9,代号「星尘 Stardust」,GitHub Star 数超过 7100,Fork 数 626,40 位贡献者,迭代了 21 个版本。
几个关键数据拎出来:
-
🎯 准确率 vs OpenAI Memory +43.70%(LoCoMo 基准测试 75.80 分)
-
💰 减少 35.24% 记忆 token 消耗
-
📈 LongMemEval +40.43%,PersonaMem +40.75%
-
🤯 PrefEval-10 +2568%(偏好记忆评估)
对 OpenClaw 用户来说,最直观的数字是:
token 消耗从 1560 万降到 440 万,减少 72%。
Skill 记忆:从「记住」到「学会」
最近的版本里,MemOS 推出了一个我觉得很有意思的能力:Skill Memory(技能记忆)。
转化路径大致是:
用户历史对话
→ 任务结构抽取
→ 能力模式归纳
→ Skill 生成
→ Agent 调度执行
说人话就是:AI 从你们之前的对话里,自动归纳出「这个任务怎么做最高效」,把它变成一个可复用的技能模块。
下次遇到同类任务,直接调用这个 Skill,而不是重新推理一遍。
这个能力的价值在于:记忆不只是上下文数据,而是可以指导行为的执行能力。从「记住发生了什么」进化到「学会了怎么做」。
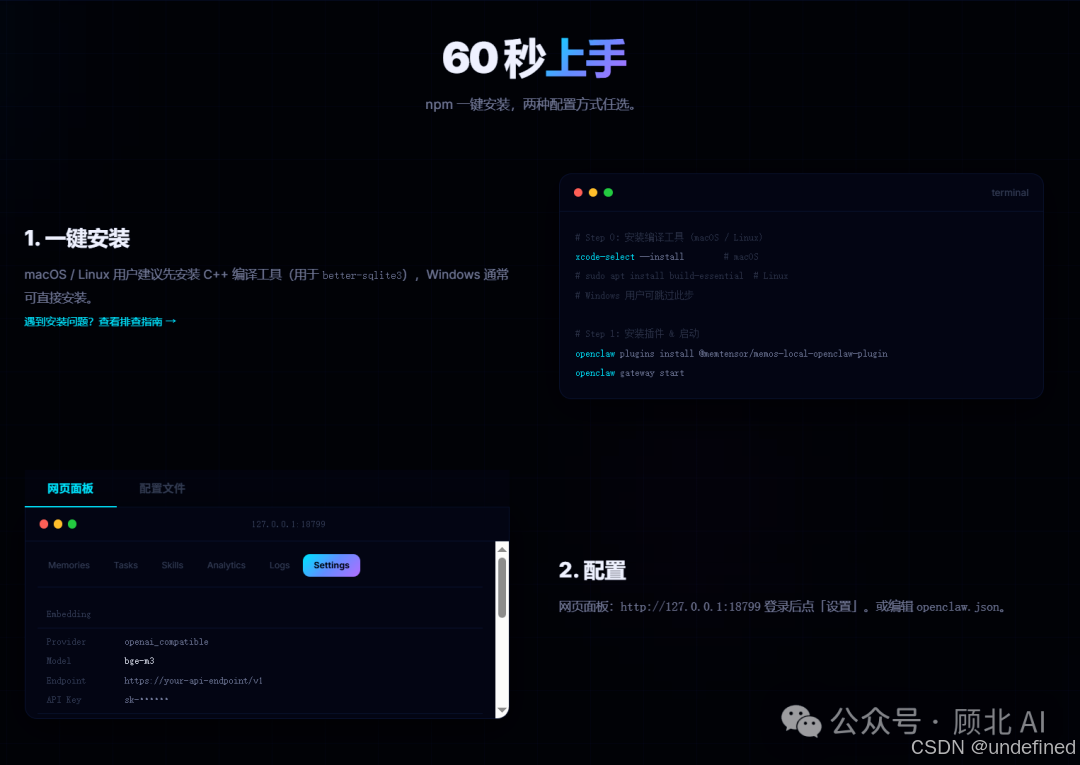
给 OpenClaw 用户:本地插件直接用
MemOS 为 OpenClaw 提供了两个版本的插件:
云端插件(Cloud Plugin):
-
72% 更低的 token 用量
-
多 Agent 共享记忆(同一个 user_id,多个 Agent 实例自动同步上下文)
本地插件(Local Plugin,memos-claw):
-
完全本地化,所有数据存 SQLite,零云依赖
-
内置 Web 管理面板,记忆/任务/技能全可视化
-
分级模型策略:Embedding 用轻量模型,摘要用中等,技能提炼用高质量——按需分配
安装方式:
openclaw plugins install @memtensor/memos-local-openclaw-plugin
openclaw gateway start
# Memory Viewer → http://127.0.0.1:18799
启动后,浏览器打开管理面板,可以直接查看、编辑、删除记忆,不再是黑盒。
多模态记忆:图片也能进记忆库
v2.0.x 版本还加了一个细节:多模态记忆。
之前图片解析是孤立的,没有上下文约束。新版本在 LLM 解析图片时,会结合:
-
历史对话内容
-
用户当前输入的文字
生成的记忆质量明显更高,能捕捉到用户的主观表达和情感线索,而不只是「图片里有一个芒果」这样的硬描述。
# 多模态记忆添加示例
"messages": [
{"role": "user", "content": "我是小王。"},
{"role": "assistant", "content": "小王,你好!"},
{"role": "user", "content": [
{"type": "text", "text": "我正在吃水果,这是我的最爱"},
{"type": "image_url", "image_url": {"url": "..."}} # 芒果图片
]}
]
# 生成记忆:用户可能对芒果有特别的喜好或情感连接
我的判断
MemOS 在做的事情,在我看来是真正必要的基础设施工作,而不是套壳。
把记忆管理抽象成操作系统层面的资源调度,这个思路是对的。现在各家 AI 产品都在自己做一套「记忆」,但大多数停留在「存一个 txt 文件」或「往 prompt 里塞历史」的层面,工程粗糙,没有生命周期管理,也没有演化能力。
当然也有不确定的地方。论文里的 benchmark 数字很好看,但 benchmark 和实际生产环境之间永远有 gap。Skill 自动提炼的质量在复杂任务上能不能扛住?多 Agent 共享记忆的一致性怎么保证?这些我还没有深度测过。
但这个方向是对的,值得持续关注。
项目刚发布 9 个月,已经迭代了 21 个版本,这个节奏说明团队在认真做。

相关链接
-
GitHub:https://github.com/MemTensor/MemOS
-
本地插件官网:https://memos-claw.openmem.net/
-
论文:arXiv 2507.03724
你在用什么方案给 Agent 加记忆?欢迎评论区聊聊。
我是顾北,我们下期再见!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 8
8 0
0- 0



 已为社区贡献54条内容
已为社区贡献54条内容

所有评论(0)