人工智能篇---机器学习常见模型
如果将视野扩展到整个机器学习领域,模型的范畴会更加广阔。它不仅包括我们讨论过的神经网络,还涵盖了从统计学习发展而来的一系列经典算法,它们共同构成了解决不同问题的“武器库”。
下面,我将为你系统性地介绍机器学习中的主要模型结构,并按照它们的学习范式、功能和应用进行分类阐述。
1. 机器学习模型的全景分类
我们可以从两个最重要的维度来理解机器学习模型:学习范式(模型如何学习)和模型结构(模型内部如何组织)。首先,我们来看学习范式:
-
监督学习:模型从有标签的数据中学习,目标是能够对未见过的新数据进行预测。这是最常见的学习方式。
-
无监督学习:模型处理无标签数据,目标是发现数据内在的结构、模式或分布。
-
半监督学习:结合少量有标签数据和大量无标签数据进行训练,在标签获取成本高昂时非常有效。
-
强化学习:模型(智能体)通过与环境的交互,根据获得的奖励或惩罚信号,学习能最大化累积奖励的最优策略。
接下来,我们将深入每一个范式,看看其中具体有哪些重要的模型结构。
2. 监督学习模型:从数据中学习映射
监督学习的核心是学习输入 X 到输出 Y 的映射关系。根据输出 Y 的类型,主要分为回归(预测连续值,如房价)和分类(预测离散类别,如猫或狗)任务。
2.1 经典统计学习模型
这些模型可解释性强,在许多结构化数据任务上依然表现出色。
-
线性回归:用一条直线(或超平面)拟合数据,建立特征与目标值之间的线性关系。是回归任务的基础模型。
-
逻辑回归:名字虽带“回归”,实则是用于二分类任务的线性模型。它通过Sigmoid函数将线性输出映射到0到1之间的概率值。
-
决策树:通过树形结构,对特征进行一系列“是/否”的判断,最终得出结论。模型直观、可解释性强,能处理非线性关系。
-
支持向量机(SVM):核心思想是在高维空间中找到一个能将不同类别数据点“分开”的最优超平面,并最大化两类数据点到该平面的距离(即“间隔”)。对高维数据和小样本学习效果好。
-
K近邻(KNN):一种“惰性学习”模型。对于新数据点,它在特征空间中寻找与其最相似的K个已有数据点,并根据这些“邻居”的标签进行投票(分类)或取平均值(回归)。
2.2 集成学习模型
集成学习通过构建并结合多个“弱学习器”(如决策树),来获得一个更强大、更稳定的“强学习器”。
-
随机森林:属于Bagging(装袋)方法的代表。它训练大量的决策树,每棵树都在用有放回抽样生成的、略有差异的数据子集上训练,并在每个节点分裂时随机选择一部分特征。最终结果由所有树的“投票”或平均值决定,能有效降低过拟合风险。
-
梯度提升树(GBDT):属于Boosting(提升)方法的代表。它不是并行训练树,而是串行地、逐棵树进行训练。每一棵新树都致力于纠正前面所有树组合后产生的残差或梯度,从而一步步逼近真实值。XGBoost、LightGBM和CatBoost是其著名的工程实现,在各类数据科学竞赛和工业界中大放异彩。
2.3 神经网络模型
这部分涵盖了我们上一轮详细讨论的内容,是处理非结构化数据(如图像、文本、音频)的主力。
-
多层感知机(MLP):最基础的前馈神经网络,由输入层、若干全连接的隐藏层和输出层组成。通过隐藏层的非线性激活函数(如ReLU)学习数据的复杂模式,是其他所有复杂神经网络的基础构建块。
-
卷积神经网络(CNN):通过卷积核的局部连接和权值共享,专门用于提取网格状数据(如图像)的局部特征。从经典的LeNet、AlexNet到深度残差网络ResNet,再到轻量级的MobileNet,CNN架构不断演进。
-
循环神经网络(RNN):专为处理序列数据(如文本、时间序列)设计,其内部状态(记忆)可以捕捉序列中的时间动态。其重要变体LSTM通过精巧的门控机制(遗忘门、输入门、输出门)解决了长序列依赖问题,而GRU则是其更高效的简化版本。
-
Transformer:基于自注意力机制的革命性架构,能够并行处理整个序列并捕捉全局依赖关系,成为当今大语言模型(如GPT、BERT、LLaMA系列)和多模态模型的基础。
3. 无监督学习模型:探索数据的内在结构
无监督学习在没有标签指导的情况下,自动发现数据的奥秘。
3.1 聚类模型
将数据点自动分组,使得同一组(簇)内的点相似度高,不同组的点相似度低。
-
K-Means聚类:最经典的划分式聚类算法。它将数据划分为K个簇,通过迭代更新簇中心点来优化簇内数据点到中心点的距离平方和。
-
层次聚类:通过不断合并(自底向上)或分裂(自顶向下)数据点,构建出一个树状的聚类层次结构,无需预先指定簇的数量。
3.2 降维模型
在尽可能保留重要信息的前提下,将高维数据压缩到低维空间,便于可视化和后续处理。
-
主成分分析(PCA):最常用的线性降维方法。它通过正交变换,将原始特征转换为一系列线性不相关的变量,即“主成分”,这些主成分按能解释的数据方差大小排序。
-
t-SNE与UMAP:非线性降维技术,尤其擅长将高维数据映射到2维或3维空间进行可视化,能够很好地保留数据的局部结构,让相似的样本在低维空间中聚拢。
3.3 生成模型与自编码器
-
自编码器(Autoencoder):一种用于学习数据高效表示的神经网络。它由一个编码器(将输入压缩为低维潜在表示)和一个解码器(从潜在表示重构原始输入)组成。
-
变分自编码器(VAE):在自编码器的基础上,引入了概率和变分推断的思想。它学习的是潜在空间的分布(均值和方差),使得潜在空间更加连续和规则,从而能够作为一个生成模型,通过从这个分布中采样来生成全新的、与训练数据相似的样本。
4. 强化学习模型:在与环境互动中学习决策
强化学习的目标是训练一个智能体,使其在特定环境中通过采取行动来最大化累积的奖励。
-
核心要素:智能体(Agent)、环境(Environment)、状态(State)、动作(Action)、奖励(Reward)、策略(Policy)。
-
Q-Learning:一种经典的基于价值(Value-based)的强化学习算法。核心是学习一个函数
Q(s, a),它评估在状态s下采取动作a所能获得的预期累积奖励。智能体通过查询Q值表来选择最优动作。 -
深度Q网络(DQN):将深度学习与Q-Learning结合的革命性工作。它使用深度神经网络来拟合复杂的Q函数
Q(s, a),使得智能体能够直接从高维输入(如游戏画面)中学习玩游戏的策略,实现了从Atari游戏到围棋(AlphaGo)的突破。
5. 前沿与专用模型结构
-
图神经网络(GNN):专门处理图结构数据(如社交网络、分子结构、知识图谱)的模型。其核心思想是邻域聚合,即每个节点通过聚合其邻居节点的信息来更新自己的特征表示。主要的变体包括图卷积网络(GCN)、图注意力网络(GAT)和GraphSAGE等。
-
生成对抗网络(GAN):一种巧妙的生成模型架构,通过生成器(Generator)和判别器(Discriminator)之间的对抗训练来学习数据分布。生成器负责“伪造”逼真样本,判别器负责“鉴别”真假,两者相互博弈、共同进化,最终使生成器能产生以假乱真的数据,如StyleGAN生成的高清人脸。
-
扩散模型(Diffusion Model):当前图像生成领域的主流架构(如Stable Diffusion、DALL-E 2)。其工作原理分为两步:首先,前向过程是不断向数据中添加噪声,直到数据完全变成随机噪声;然后,反向过程是学习一个神经网络,逐步从纯噪声中“去噪”,最终还原出清晰的原始数据分布。
-
状态空间模型(SSM/Mamba):新兴的序列建模架构,旨在解决Transformer在处理超长序列时计算复杂度高的问题。它以Mamba为代表,通过引入选择性机制,在保持线性复杂度的同时,实现了强大的长序列建模能力,是未来值得关注的方向之一。
总结框图:机器学习模型结构全景图
下面这张Mermaid框图总结了上述所有主要模型结构及其分类关系,希望能帮助你建立一个清晰的全局视角。
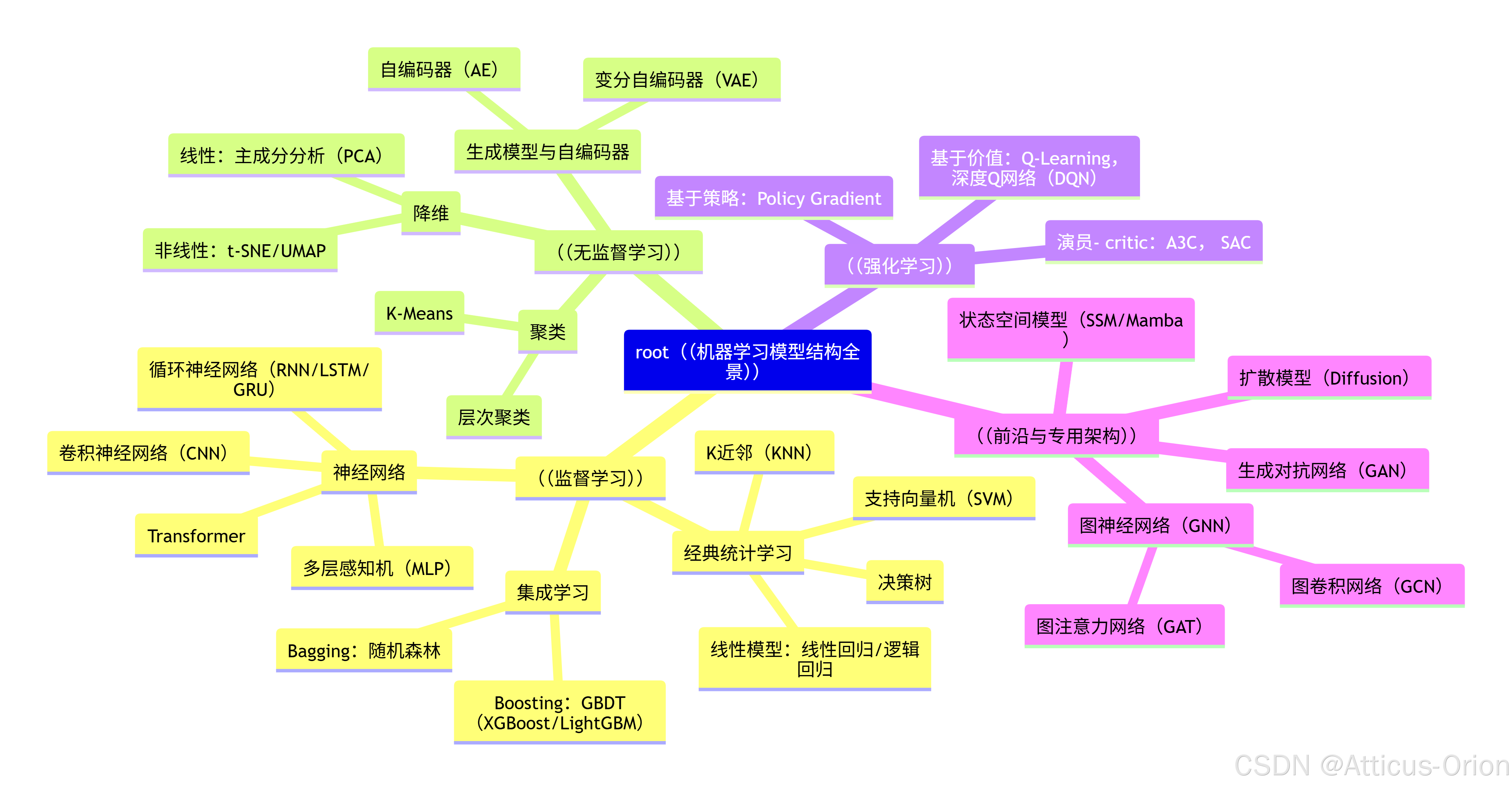
希望这份详尽的介绍能帮助你更好地理解机器学习模型的广阔世界。这些模型构成了现代人工智能的基石,随着技术的不断发展,它们之间的融合与创新也正在不断推进AI能力的边界。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 16
16 0
0- 0



 已为社区贡献40条内容
已为社区贡献40条内容

所有评论(0)