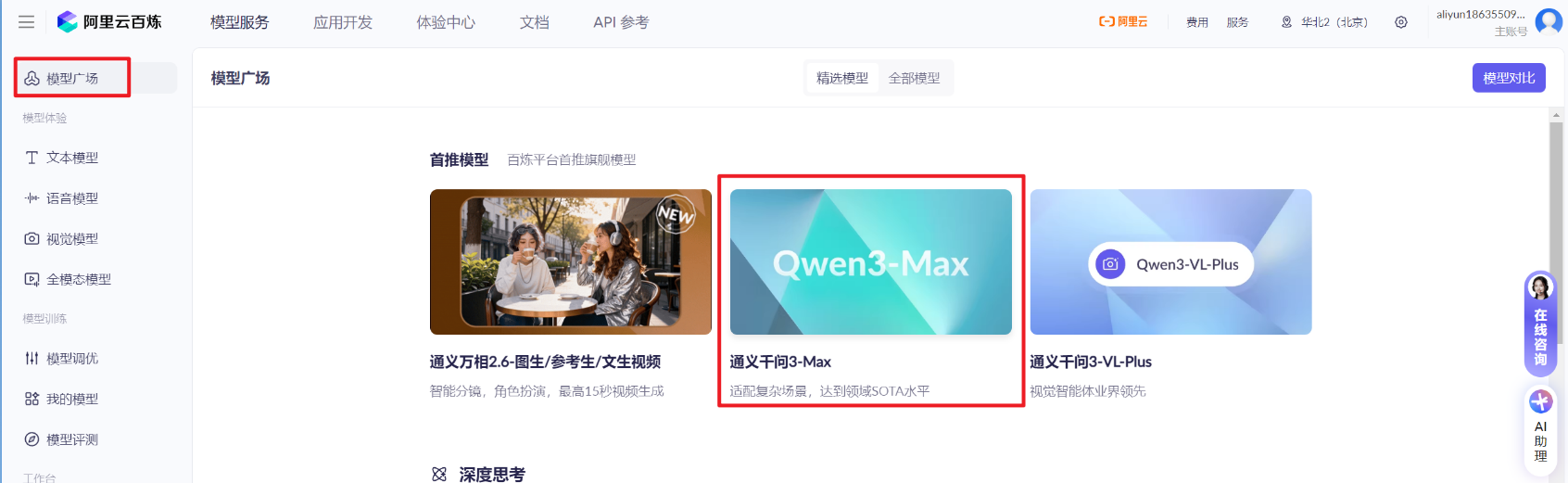
[RAG开发]-大模型接入
百炼平台
大模型接入方式

- 本课程使用阿里云百炼平台接入大模型
注册和使用阿里云百炼平台
- https://bailian.console.aliyun.com/cn-beijing/#/home
- 进入阿里云的百炼大模型平台,完成注册,登录,实名(使用支付宝扫一下)。
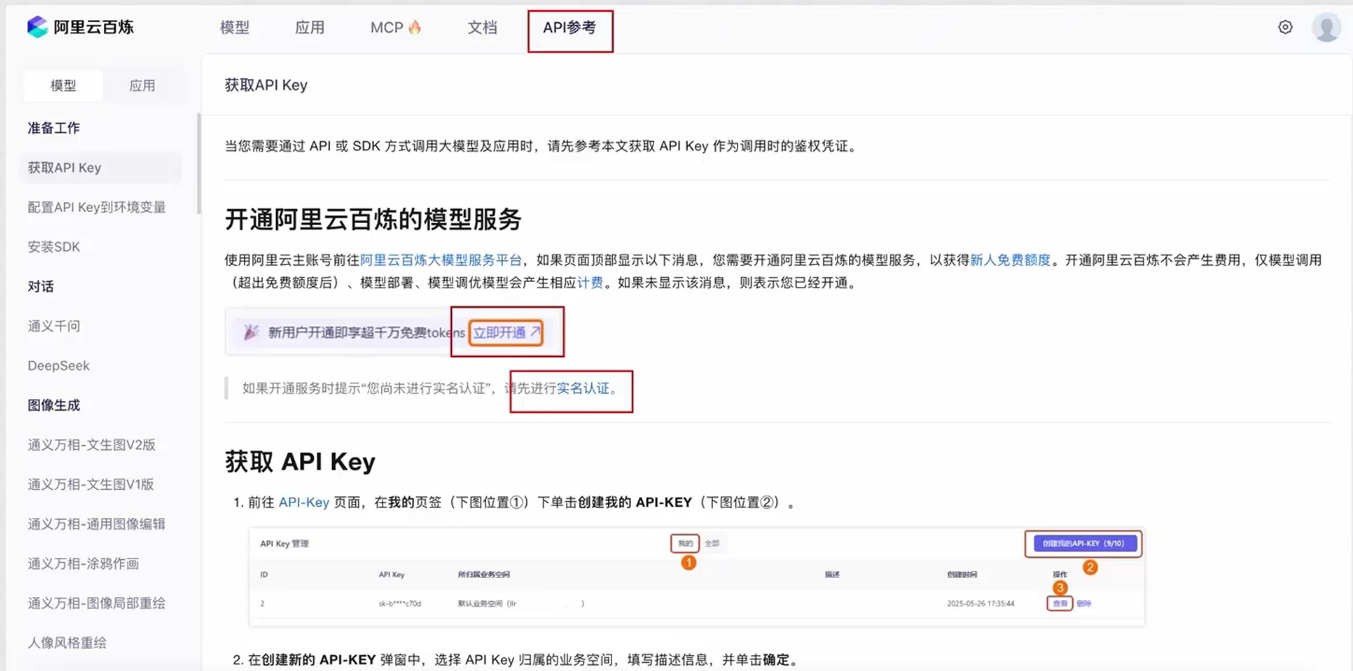
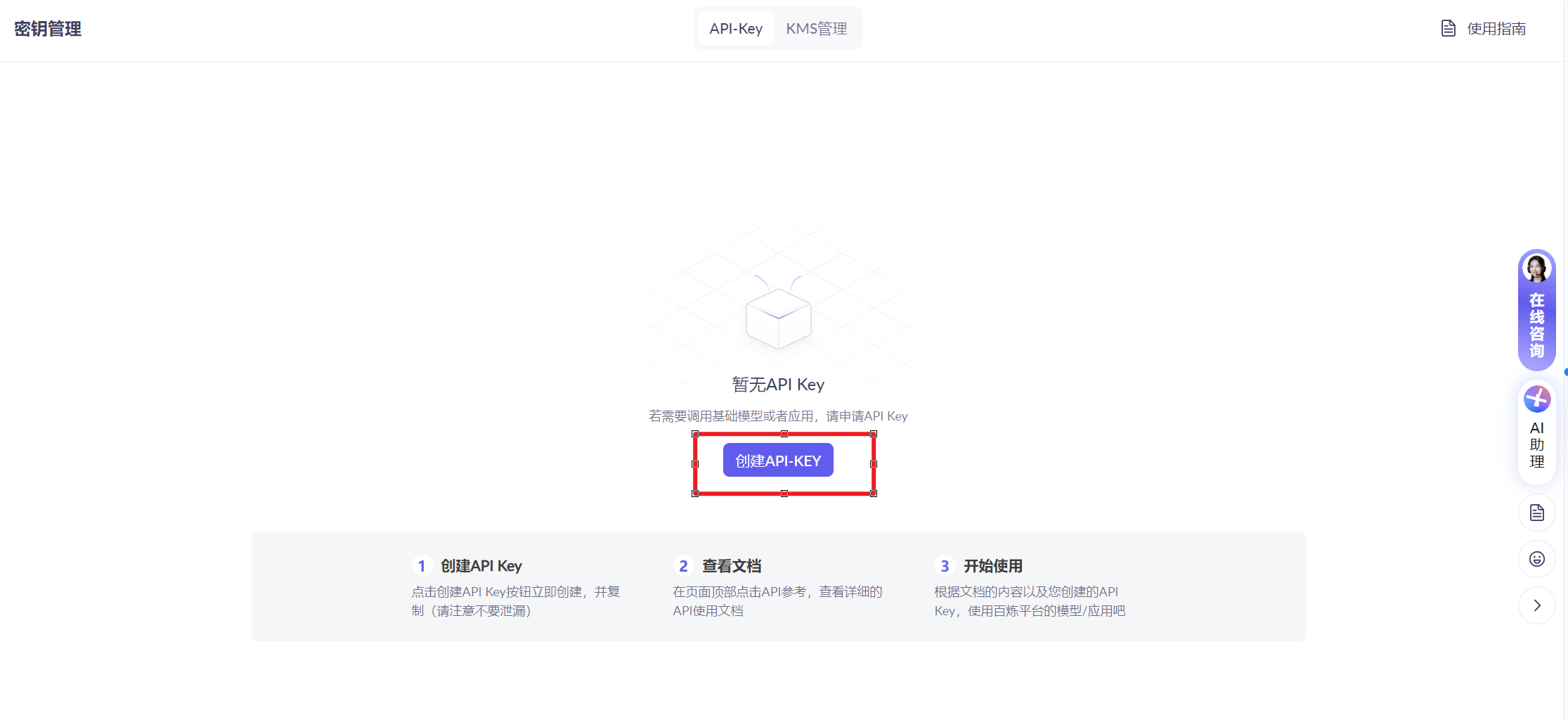
- 创建API-KEY
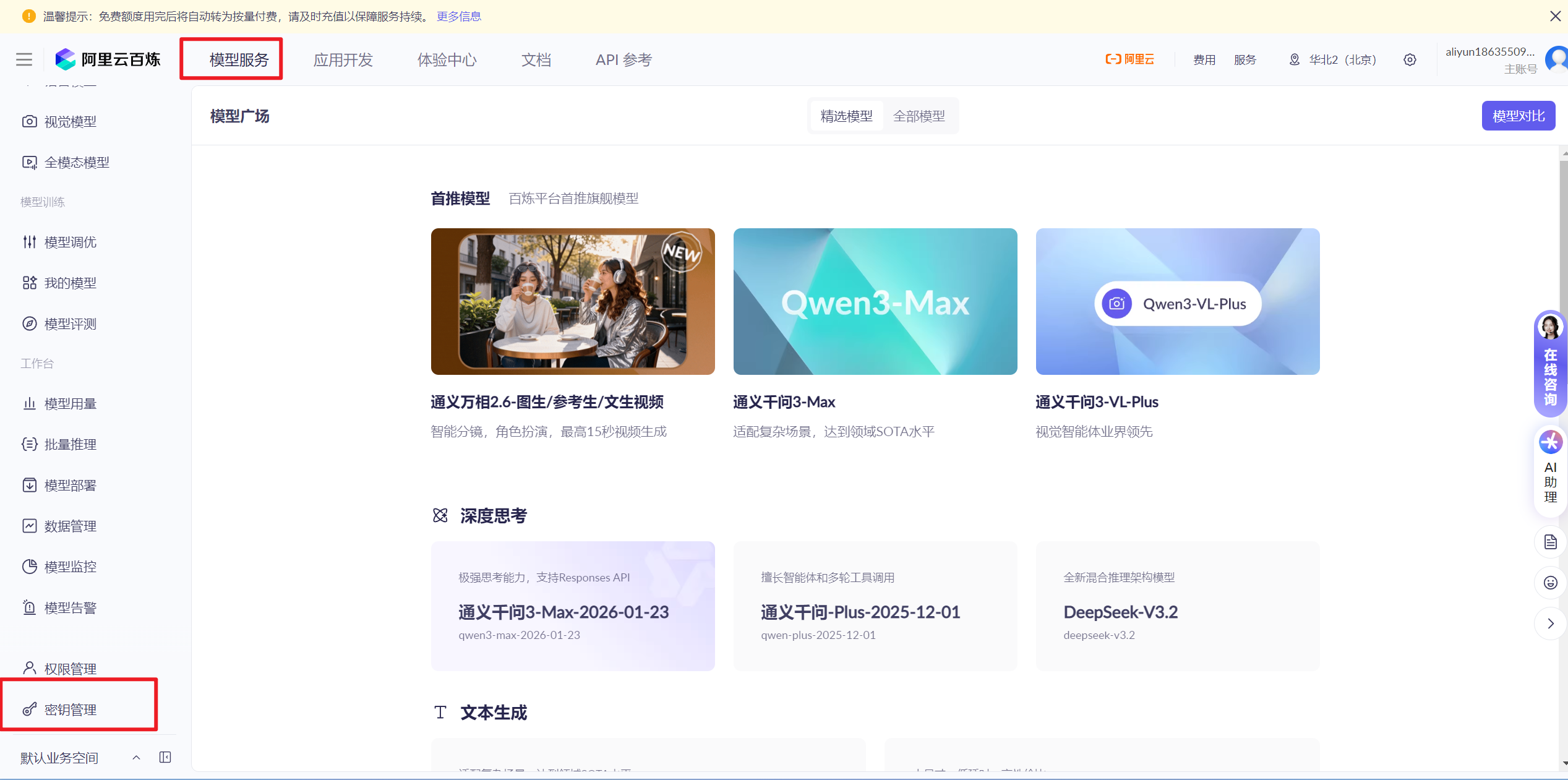

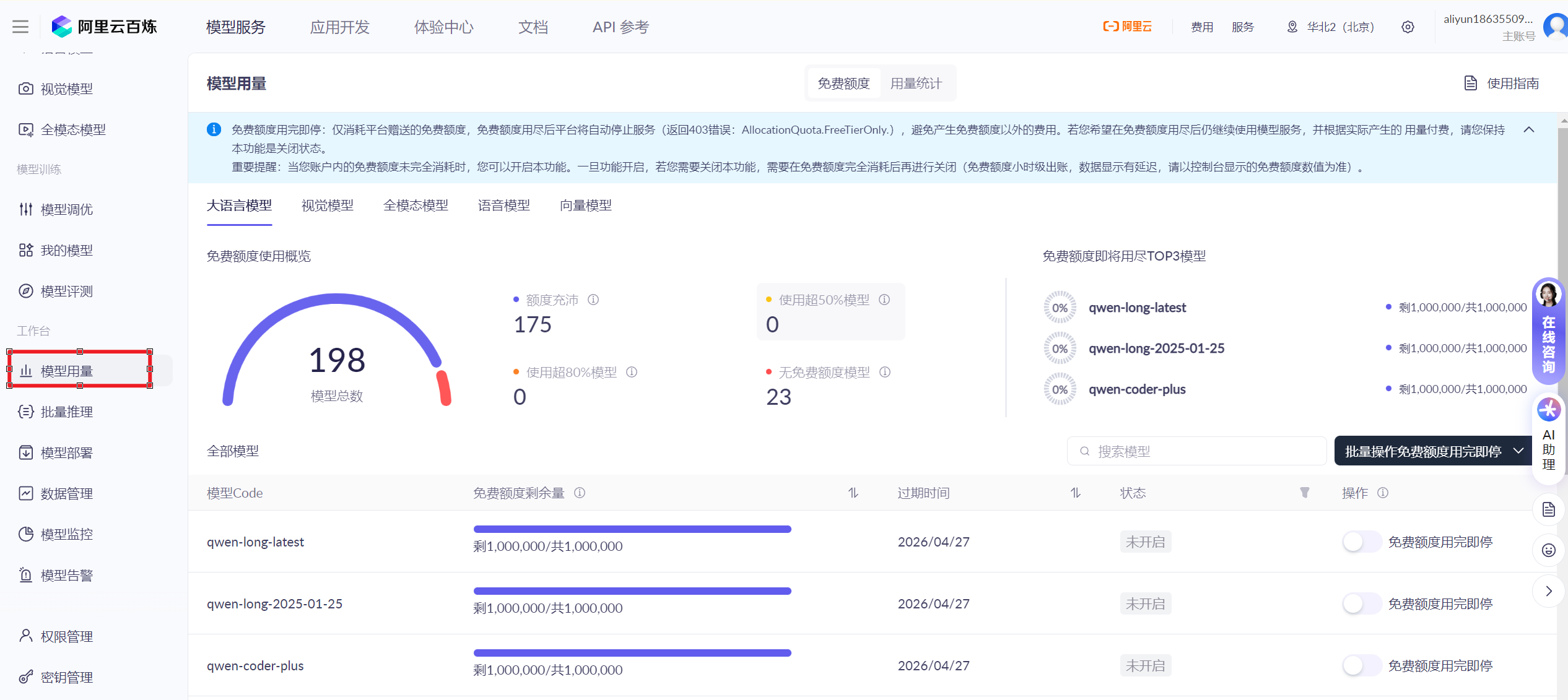
- 查看额度
通过代码调用阿里云百炼平台上的模型很简单,仅需要:
- 阿里云百炼平台上,创建API-KEY
- 通过pip为Python程序提供 OpenAI 库:
-
- pip install openai
- 我这里使用了科学上网, 如果使用国内网络下载工具慢的话, 可以把数据源切换到清华源
- 编写代码测试(可从百炼平台官网复制代码,直接执行)
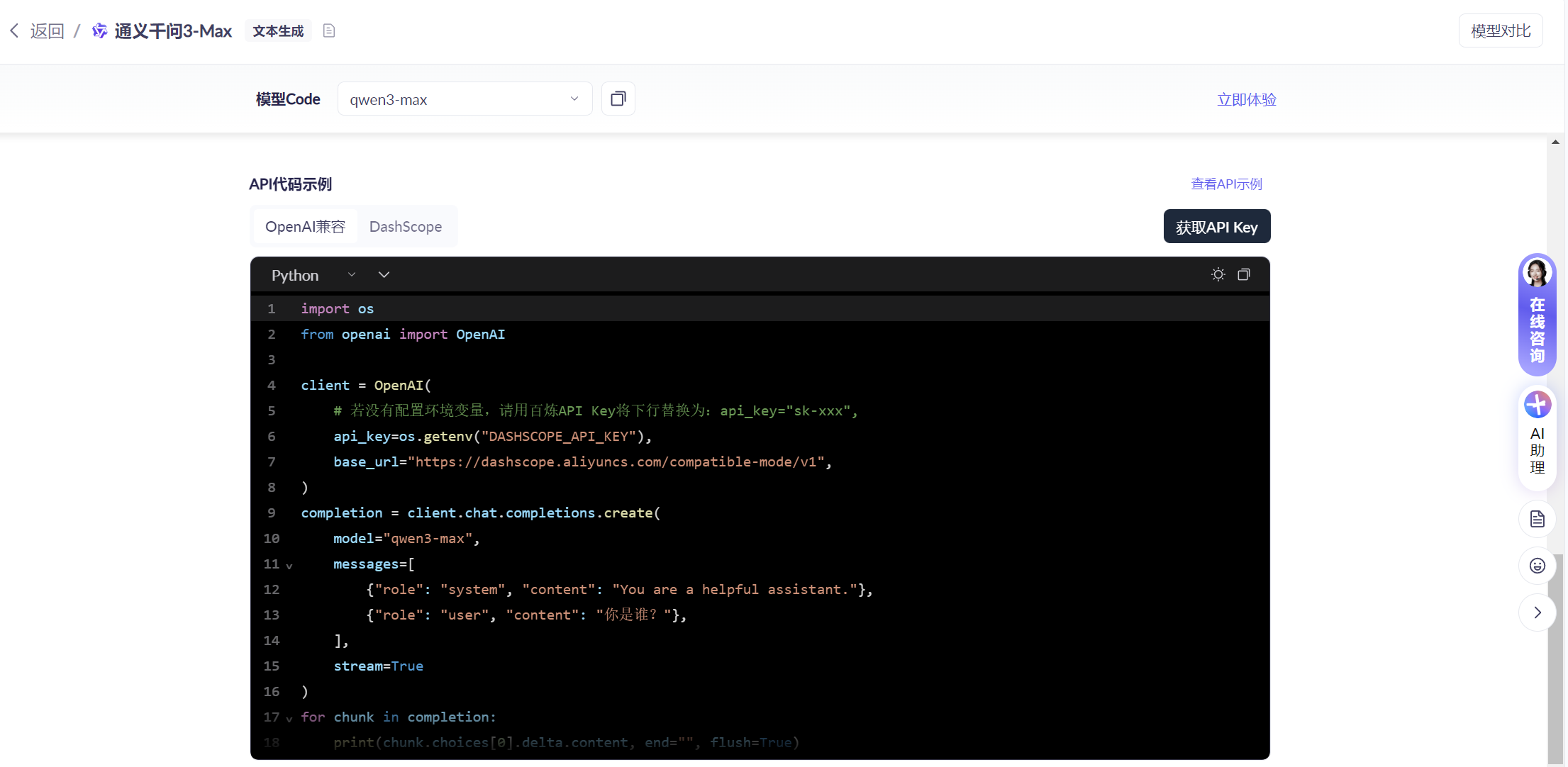
如下代码,将APIKEY明文显示在代码中,是有很大的安全隐患的。
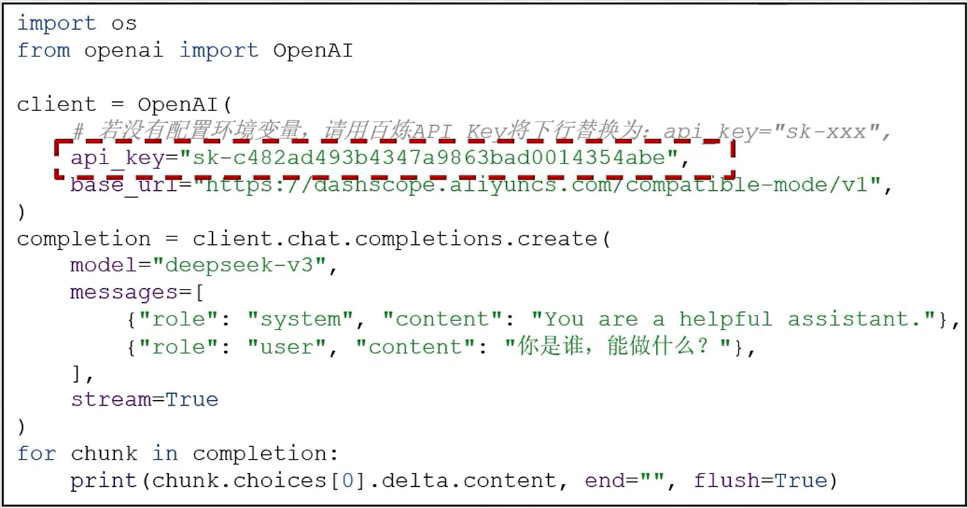
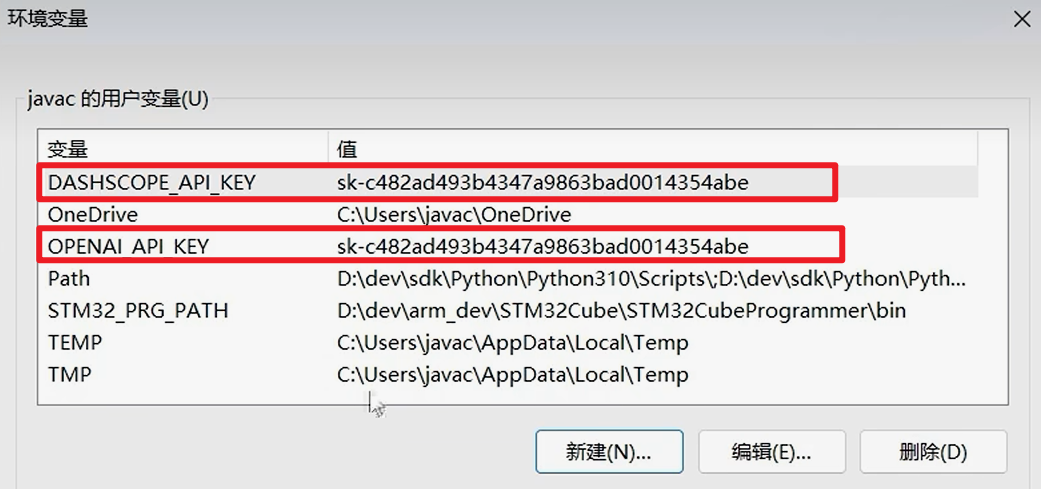
- 我们可以通过环境变量来隐藏明文APIKEY。
- 通过环境变量: OPENAI_API_KEY和DASHSCOPE_API_KEY记录值,
- 代码会自动读取变量从而获取值

- Windows系统通过图形化界面配置环境变量
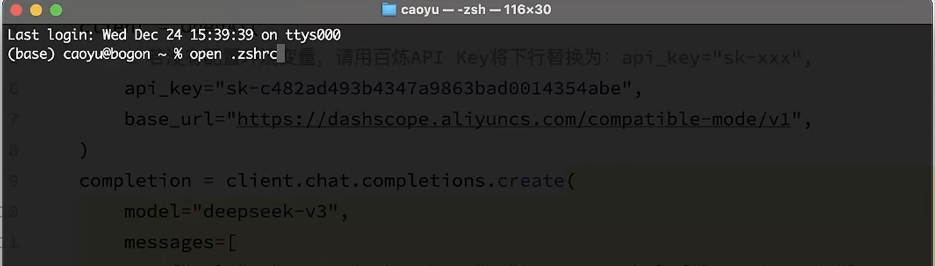
- Mac系统在终端内修改.zshrc文件添加环境变量
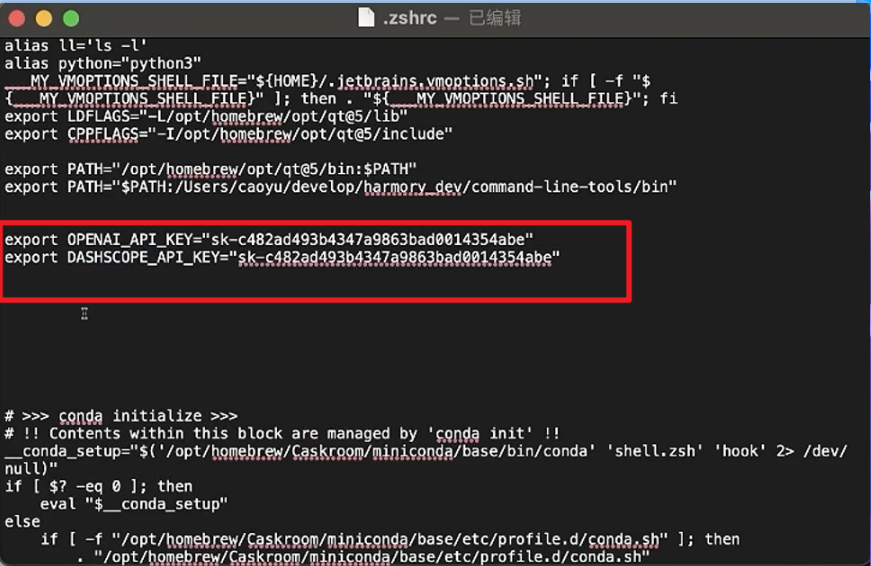
- 配置完成后,重启PyCharm生效(如不生效可以重启电脑)
Ollama
Ollama简介
为了避免未来阿里云免费额度到期或不提供免费活动导致的无法开发,课程额外补充:基于OLlama部署本地模型,供代码调用。
- PS:此为备用方案,课程主体还是基于阿里云百炼平台做开发。
- ollama:是一款旨在简化大型语言模型本地部署和运行过程的开源软件。
- oLlama提供了一个轻量级、易于扩展的框架,让开发者能够在本地机器上轻松构建和管理LLMs(大型语言模型)
- 通过ollama,开发者可以导入和定制自己的模型,无需关注复杂的底层实现细节。
- 网址: https://ollama.com
- 简单来说可以认为是阿里云百炼平台的本地版,在自己电脑上部署和运行大模型,由自己电脑的硬件提供算力支撑模型运行。
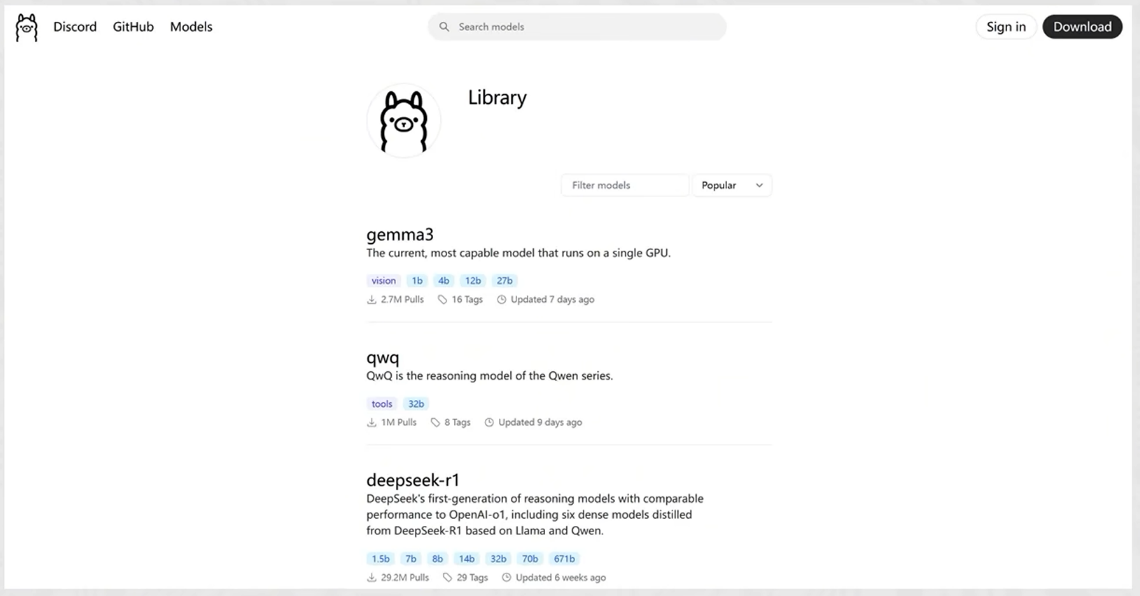
ollama模型库
ollama 支持多种开源模型,涵盖文本生成、代码生成、多模态推理等场景。
- 用户可以根据需求选择合适的模型,并通过简单的命令行操作在本地运行。
- ollama 官方模型库: https://ollama.com/library
Windows/Mac系统部署ollama
Ollama的部署还是很简单的,只需要进入官方网站点击Download按钮下载安装。
- 安装完成后,通过命令:
- ollama run 模型名称
- 即可运行对应的模型,并在命令行内做交互。

- 蒸馏模型就是对标准大模型核心技能的学习,并进行瘦身,从而获得更低的性能要求。 简单来说蒸馏模型就是标准大模型的学生,学到了老师的核心本领,但没有老师强。根据参数量的不同,参数量越大,蒸馏模型学到老师核心本领就越扎实,性能越好。
- 参数量选择:
- 集显: 1.5b左右
- 4G独显: 8b以内
- 8G独显: 14b以内
- ...具体可以自己试一试
- 参数量越大对硬件要求越高,如果硬件能力不足,模型运算和吐字速度会下降。
完成ollama的部署和使用后,后续如果要管理电脑中的模型,可以使用ollama命令。
- 主要介绍如下几个命令:
- ollamalist:列出当前已下载的模型
- ollama pull模型名称:联网下载指定的模型
- ollama run模型名称:运行指定的模型(如不存在会先下载)
- ollama--help:查看其它可用的命令帮助
- PS: 上述命令操作,请先运行ollama
- PS: 上述命令操作,Windows系统和Mac系统通用
代码调用ollama的本地模型
使用代码调用ollama的本地模型还是很简单的,只需要将原有代码进行简单改动即可。
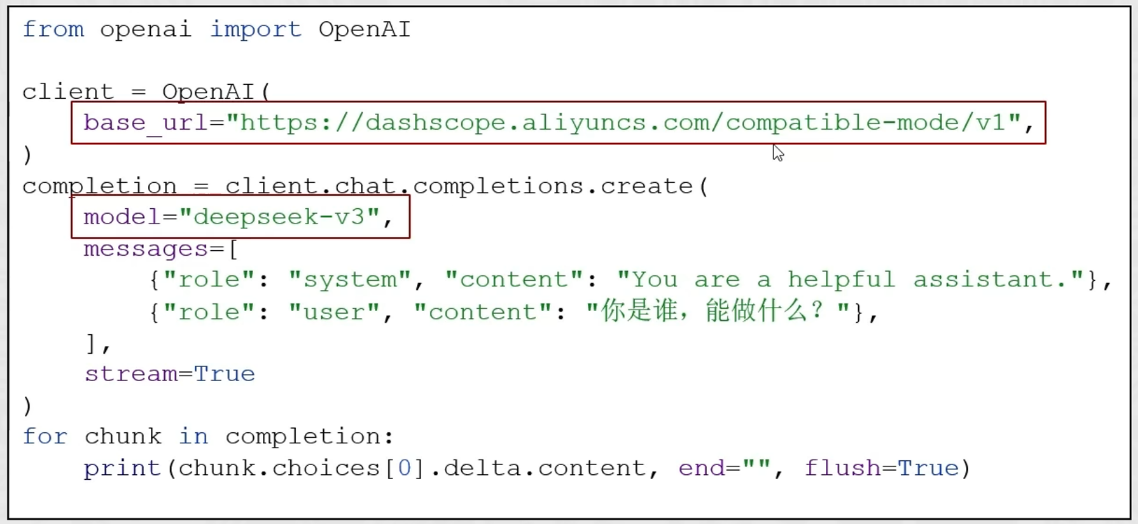
- 将base_url改为: http://localhost:11434/v1
- 将model改为对应本地模型名称,如: qwen3:4b
OpenAi
OpenAI库是OpenAI官方推出的Python SDK,核心作用是让开发者能简单、高效地调用OpenAI 的各类API(如GPT聊天、DALL.E绘图、语音转文字等),无需手动处理HTTP请求、身份验证等底层细节。
- 由于其发布较早且比较易用,现如今许多模型服务商(如阿里云百炼平台)均兼容OpenAI SDK的调用

openAi的基本使用
- 获取客户端对象

- 主要是用如上2个参数:
- api_key: 模型服务商提供的APIKEY密钥
- base_url: 模型服务商的API接入地址
-
- 主要基于此参数来切换不同的模型服务商(如OpenAI、阿里云、腾讯云等)
- 调用模型

- 处理结果
response变量就是ChatCompletion对象,其包含信息如下所示

可以通过 print(response.choices[0].message.content) 输出模型给出的回答信息
- 完整代码
from openai import OpenAI
# 获取client对象
client = OpenAI(
api_key="",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
)
# 调用模型
response = client.chat.completions.create(
model="qwen3-max",
messages=[
{"role": "system", "content": "你是一个Python编程专家,并且不说废话简洁回答"},
{"role": "assistant", "content": "好的, 我是Python编程专家, 你要问什么?"},
{"role": "user", "content": "请写一个python程序, 打印1-10的数字"},
]
)
# 处理结果
print(response.choices[0].message.content)
OpenAI库的流式输出
可以设定结果输出为stream模式(流式输出),获得更好的使用体验。开启流式输出主要就2步:
- 设置模型的输出模式为流式输出
- 在client.chat.completions.create()调用模型的时候设定参数 stream=True
- 循环输出内容
- for循环response对象,并在循环内输出内容
- 完成代码
"""
流式输出
"""
from openai import OpenAI
# 获取client对象
client = OpenAI(
api_key="",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
)
# 调用模型
response = client.chat.completions.create(
model="qwen3-max",
messages=[
{"role": "system", "content": "你是一个Python编程专家,并且不说废话简洁回答"},
{"role": "assistant", "content": "好的, 我是Python编程专家, 你要问什么?"},
{"role": "user", "content": "请写一个python程序, 打印1-10的数字"},
],
stream=True # 开启流式输出
)
# 处理结果
for chunk in response:
print(
chunk.choices[0].delta.content,
end="", # 每一段内容以空格分隔
flush=True # 立刻刷新缓冲区
)OpenAI库附带历史消息调用模型
- 调用模型传入的参数messages,其要求是list对象,即表明其支持非常多的消息在内。
- 我们可以基于此,将历史消息填入,让模型知晓对话的上下文,更好的回答
- 在调用模型时, 通过在messages的list内,组织历史消息提供给模型
- 当前的历史消息是一次性的,如果是生产系统可以将消息保存到文件、数据库等持久化工具内,需要的时候提取使用
- 后续学习LangChain库,会学习短期记忆和长期记忆的使用方法。
"""
携带历史消息
"""
from openai import OpenAI
# 获取client对象
client = OpenAI(
api_key="",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
)
# 调用模型
response = client.chat.completions.create(
model="qwen3-max",
messages=[
{"role": "system", "content": "你AI助理,回答很简洁"},
{"role": "user", "content": "小明有两条狗"},
{"role": "assistant", "content": "好的"},
{"role": "user", "content": "小红有3只猫"},
{"role": "assistant", "content": "好的"},
{"role": "user", "content": "总共有几只宠物"},
],
stream=True
)
# 处理结果
for chunk in response:
print(chunk.choices[0].delta.content, end=" ", flush=True)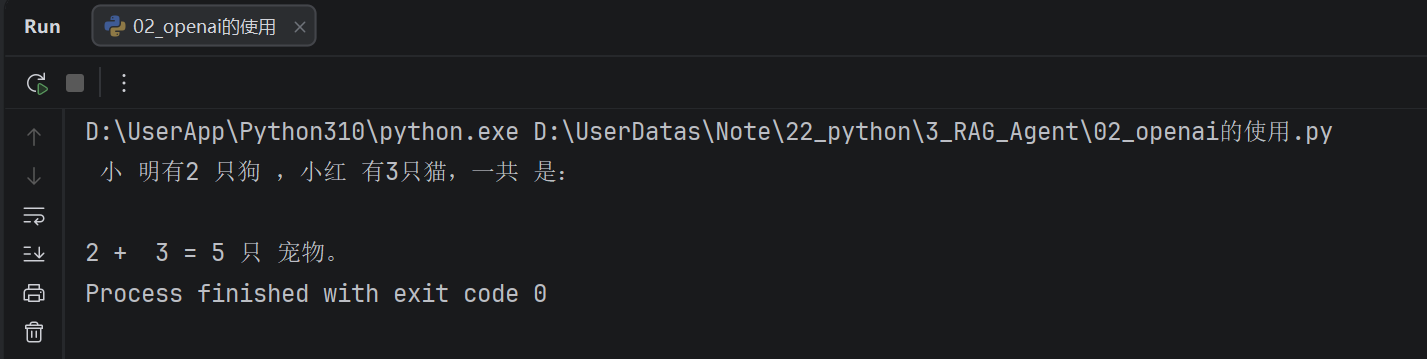
LLM
大语言模型(英文:Large Language Model,缩写LLM)是一种人工智能模型,旨在理解和生成人类语言. 大语言模型可以处理多种自然语言任务,如文本分类、问答、翻译、对话等等.

语言模型(Language Model)旨在建模词汇序列的生成概率,提升机器的语言智能水平,使机器能够模拟人类说话、写作的模式进行自动文本输出。
- 通俗理解: 用来计算一个句子的概率的模型,也就是判断一句话是否是人话的概率
- 标准定义: 对于某个句子序列,如s={W1,W2,W3,...Wn),语言模型就是计算该序列发生的概率,即P(S). 如果给定的词序列符合语用习惯,则给出高概率,否则给出低概率.

- 语言模型技术的发展四阶段

LLM主要类别架构
LLM本身基于transformer架构。自2017年,attention is all you need诞生起,原始的transformer模型为不同领域的模型提供了灵感和启发。
- 基于原始的Transformer框架,衍生出了一系列模型,一些模型仅仅使用encoder或decoder,有些模型同时使用encoder+decoder.
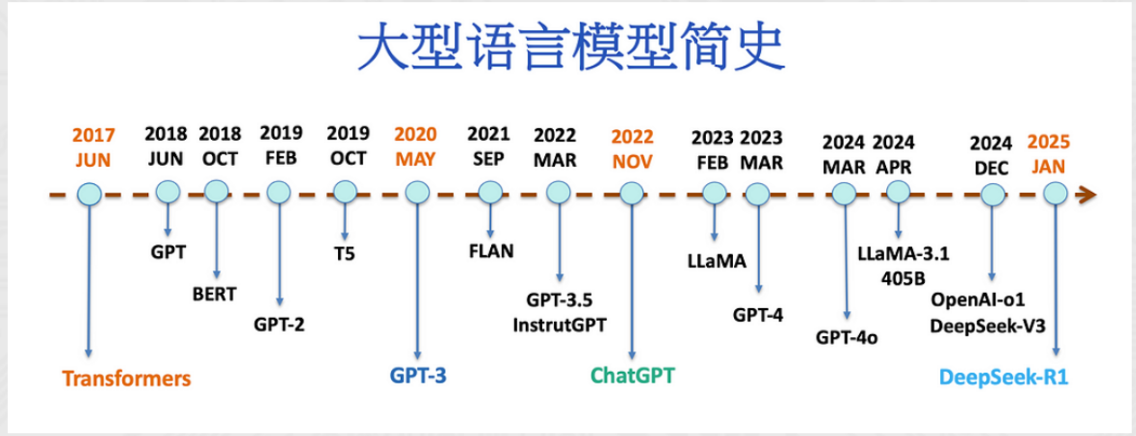
- LLM分类一般分为三种: 自编码模型(encoder)、自回归模型(decoder)和序列到序列模型(encoder-decoder)。
自编码模型(AutoEncoder model,AE)
AE模型,代表作BERT,其特点为: Encoder-Only,基本原理: 是在输入中随机MASK掉一部分单词,根据上下文预测这个词。
- AE模型通常用于内容理解任务,比如自然语言理解(NLU)中的分类任务: 情感分析、提取式问答。
- 代表模型 BERT
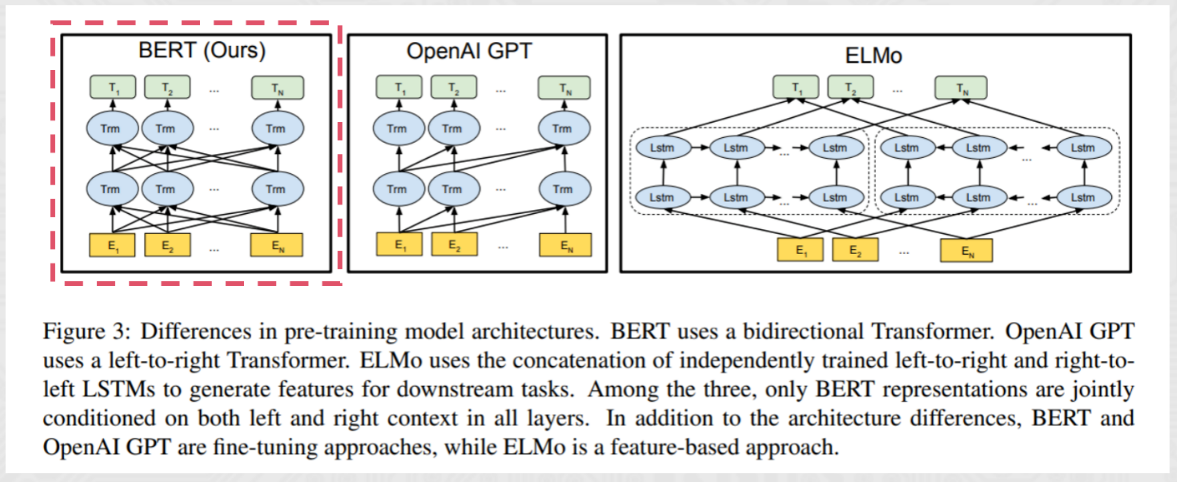
自回归模型(Autoregressive model,AR)
AR模型,代表作GPT,其特点为: Decoder-Only,基本原理: 从左往右学习的模型,只能利用上文或者下文的信息,比如: AR模型从一系列time steps中学习,并将上一步的结果作为回归模型的输入,以预测下一个time step的值。
- AR模型通常用于生成式任务,在长文本的生成能力很强,比如自然语言生成(NLG)领域的任务: 摘要、翻译或抽象问答。
- 代表模型GPT
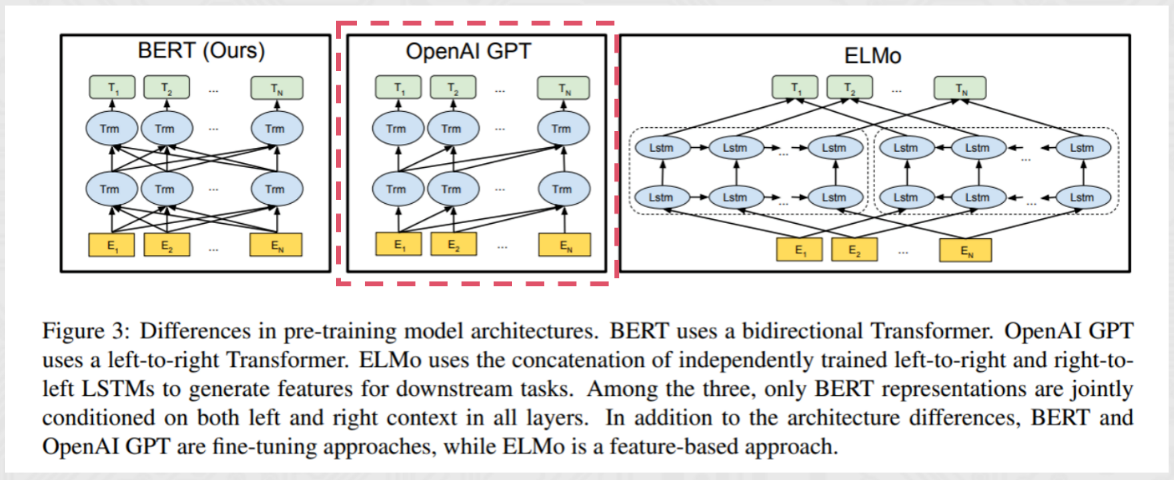
序列到序列 (Sequence to Sequence Model)
encoder-decoder模型同时使用编码器和解码器。它将每个task视作序列到序列的转换/生成 (比如,文本到文本,文本到图像或者图像到文本的多模态任务)。对于文本分类任务来说,编码器将文本作为输入,解码器生成文本标签。
- Encoder-decoder模型通常用于需要内容理解和生成的任务,比如机器翻译。
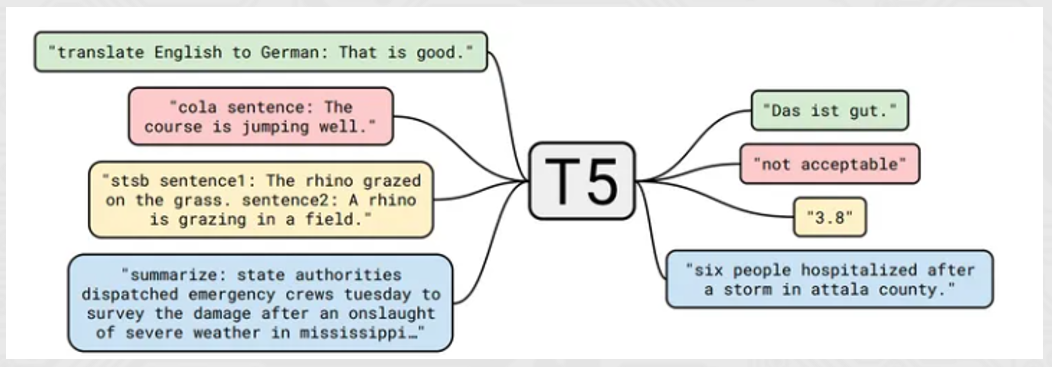
- 代表模型T5
LLM主流大模型类别
随着ChatGPT迅速火爆,引发了大模型的时代变革,国内外各大公司也快速跟进生成式Al市场,近百款大模型发布及应用。目前,比较流行的开源的大语言模型主要以下几种: LLaMA大模型、ChatGLM大模型、Qwen大模型、Deepseek大模型
LLaMA模型
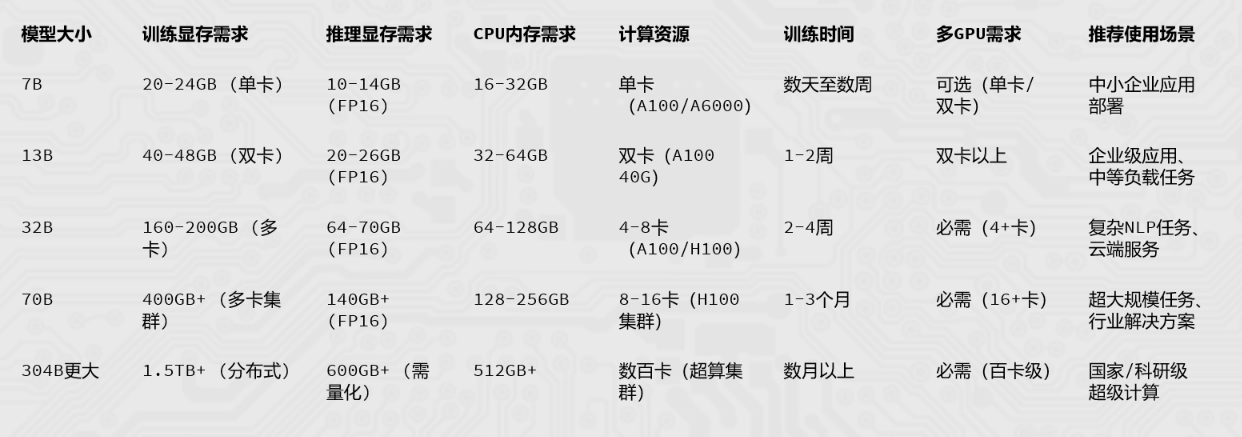
LLaMA (LargeLanguage Model Meta A),由Meta Al于2023年发布的一个开放且高效的大型基础语言模型,共有7B、13B、33B、65B (650亿)四种版本。
- LLaMA训练数据是以英语为主的拉丁语系,另外还包含了来自GitHub的代码数据。
- 训练数据以英文为主,不包含中韩日文,所有训练数据都是开源的。
- 其中LLaMA-65B和LLaMA-33B是在1.4万亿(1.4T)个token上训练的
- 而最小的模型LLaMA-7B和LLaMA-13B是在1万亿(1T)个token 上训练的。

ChatGLM模型
ChatGLM是清华大学提出的一个开源、支持中英双语的对话语言模型。
- 该模型使用了和ChatGPT相似的技术
- 经过约1T标识符的中英双语训练(中英文比例为1:1)
- 辅以监督微调、反馈自助、人类反馈强化学习等技术的加持
- 62亿参数的ChatGLM-6B已经能生成相当符合人类偏好的回答。

Qwen模型
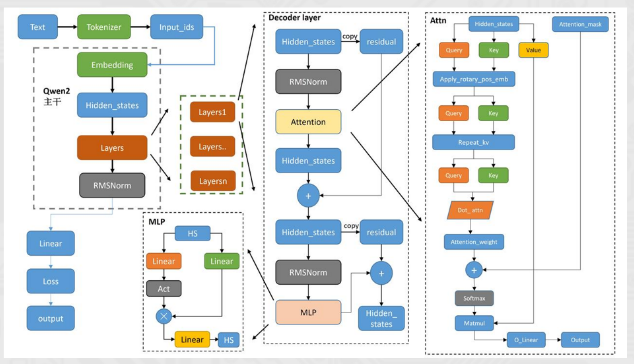
通义干问是由阿里云自主研发的大模型,用于理解和分析用户输入的自然语言,以及图片、音频、视频等多模态数据。
- Qwen模型也是Decoder-only架构,但结合前人的工作做了一些改进,比如:
- 位置编码: 使用RoPE(Rotary PositionalEmbedding),增强长文本建模能力。
- 归一化层: 采用RMSNorm,替代传统LayerNorm,提升训练稳定性。
- 激活函数: 使用SwiGLU,相比GeLU能更好地提取特征。
DeepSeek模型
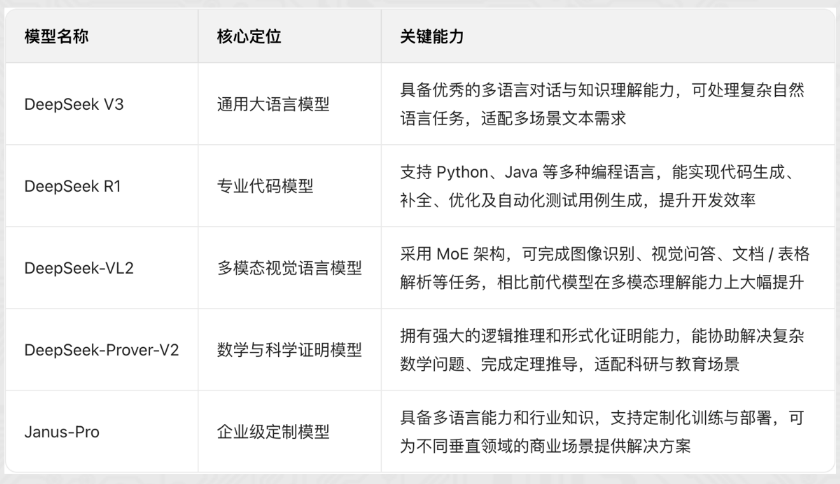
DeepSeek模型是由杭州深度求索人工智能基础技术研究有限公司开发的一系列人工智能模型。该系列模型以Transformer 架构为基础, 核心采用创新的DepselMoE (混合专家)与MLA(多头潜在注意力)技术路线,覆盖通用语言、代码、视觉、数学等多个领域
主流的开源大模型主要有:
- LLaMA,MetaAI2023发布,偏向英语系
- ChatGLM,清华发布,类chatGPT
- Qwen,阿里发布,时下流行
- DeepSeek,深度求索发布

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 18
18 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)