基于MLP-XGBoost的多输入单输出组合回归预测模型 python代码 将两个不同的回归模...
基于MLP-XGBoost的多输入单输出组合回归预测模型 python代码 将两个不同的回归模型(MLP和XGBoost)结合起来,通过加权组合它们的预测结果,以期望获得更好的性能。 这种方法的特点和创新点在于: 模型多样性:组合了两个不同类型的回归模型(神经网络和梯度提升树),这增加了模型多样性。 不同类型的模型可能在不同方面具有优势,因此组合它们可以平衡各自的弱点。 模型融合:通过组合多个模型,可以充分利用它们的优点,减弱它们的缺点。 这种融合可以提高模型的稳定性和鲁棒性。 权重调整:模型的预测结果采用了权重调整,这意味着在组合中,每个模型的贡献可以根据其性能进行调整。 这样,性能较好的模型可以在组合中占据更大的比重,从而提高整体性能。 可解释性:通过特征重要性图表,可以可视化展示每个特征对最终模型的贡献程度,这有助于理解模型的工作原理。 tips:仅包含模型代码 模型只是提供一个衡量数据集精度的方法,因此无法保证替换数据就一定得到您满意的结果
直接上干货,咱们今天玩点不一样的——把MLP和XGBoost这俩不同门派的算法揉在一起搞预测。别看这两个模型八竿子打不着,组合起来还真能擦出火花。(代码环境建议用Python3.8+,记得装好keras和xgboost库)
先搞个多层感知器(MLP)打头阵。这个深度学习的入门款虽然结构简单,但处理非线性关系确实有一手:
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
def create_mlp(input_dim):
model = Sequential()
model.add(Dense(64, input_dim=input_dim, activation='relu')) # 首层64个神经元
model.add(Dense(32, activation='relu')) # 中间层砍半防止过拟合
model.add(Dense(1, activation='linear')) # 回归任务别用激活函数
model.compile(loss='mse', optimizer='adam') # 回归标配损失函数
return model这里有个小细节:中间层神经元数量逐层减半不是必须的,但确实能有效控制参数爆炸。如果数据量特别大,可以考虑增加层数到3-4层。
接着上XGBoost这个传统机器学习界的扛把子:
from xgboost import XGBRegressor
def create_xgboost():
params = {
'n_estimators': 150,
'max_depth': 5,
'learning_rate': 0.1,
'subsample': 0.8,
'objective': 'reg:squarederror'
}
return XGBRegressor(**params)注意subsample参数设了0.8——相当于每棵树只用80%的数据训练,这个防过拟合的trick实测有效。如果发现训练集精度高测试集拉胯,可以继续往下调到0.6。
基于MLP-XGBoost的多输入单输出组合回归预测模型 python代码 将两个不同的回归模型(MLP和XGBoost)结合起来,通过加权组合它们的预测结果,以期望获得更好的性能。 这种方法的特点和创新点在于: 模型多样性:组合了两个不同类型的回归模型(神经网络和梯度提升树),这增加了模型多样性。 不同类型的模型可能在不同方面具有优势,因此组合它们可以平衡各自的弱点。 模型融合:通过组合多个模型,可以充分利用它们的优点,减弱它们的缺点。 这种融合可以提高模型的稳定性和鲁棒性。 权重调整:模型的预测结果采用了权重调整,这意味着在组合中,每个模型的贡献可以根据其性能进行调整。 这样,性能较好的模型可以在组合中占据更大的比重,从而提高整体性能。 可解释性:通过特征重要性图表,可以可视化展示每个特征对最终模型的贡献程度,这有助于理解模型的工作原理。 tips:仅包含模型代码 模型只是提供一个衡量数据集精度的方法,因此无法保证替换数据就一定得到您满意的结果
重头戏来了——给两个模型分配权重的融合策略:
def weighted_ensemble(mlp_pred, xgb_pred, mlp_weight=0.6):
return mlp_weight * mlp_pred + (1 - mlp_weight) * xgb_pred别小看这几行代码,权重的调整直接影响最终效果。建议先在验证集上跑个网格搜索,比如从0.3到0.7每隔0.05试一次,找出最优权重比。不过要注意数据分布变化时,这个比例可能需要动态调整。
训练流程得讲究先后顺序:
def train_models(X_train, y_train):
mlp = create_mlp(X_train.shape[1])
mlp.fit(X_train, y_train, epochs=100, batch_size=32, verbose=0)
# 再训练XGBoost
xgb = create_xgboost()
xgb.fit(X_train, y_train)
return mlp, xgb这里有个经验:先训MLP是因为神经网络对数据尺度更敏感,后训XGBoost可以利用其自动处理特征的优势。如果反过来操作,记得要给MLP做特征标准化。
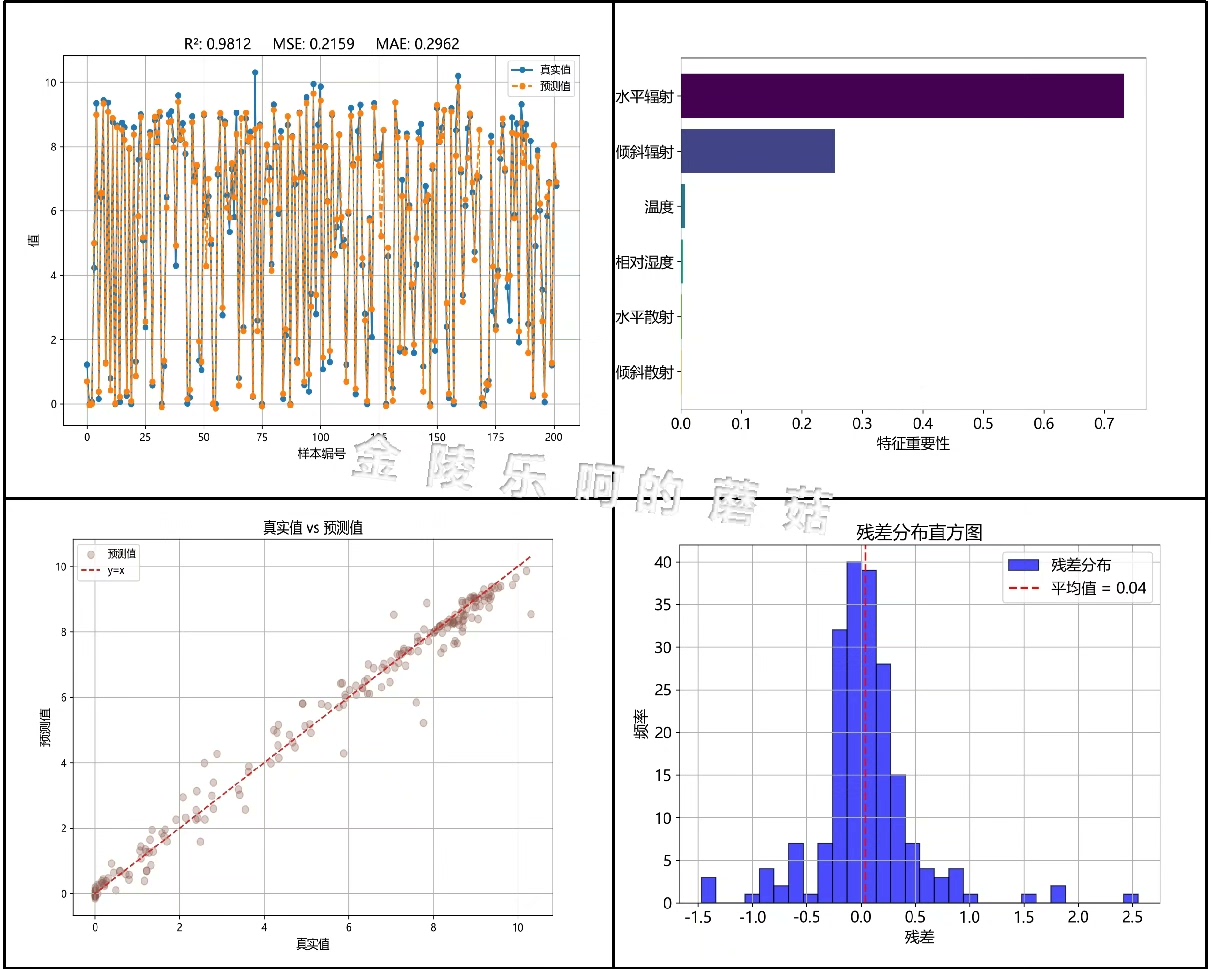
最后来个特征重要性分析(虽然只有XGBoost能直接提供):
def plot_importance(model, feature_names):
importance = model.feature_importances_
sorted_idx = importance.argsort()
plt.barh(range(len(sorted_idx)), importance[sorted_idx])
plt.yticks(range(len(sorted_idx)), [feature_names[i] for i in sorted_idx])
plt.xlabel('XGBoost Feature Importance')这个重要性图建议和permutation importance结合着看,特别是当特征之间存在多重共线性时,单一的重要性指标可能会失真。
几点实战建议:
- 遇到波动大的预测结果时,试试调整MLP的learning rate
- XGBoost的earlystoppingrounds参数能有效防止过拟合
- 融合权重可以改成动态计算——比如根据最近N个样本的预测误差自动调整
- 如果计算资源足够,给MLP加上BatchNormalization层效果更稳
这种混合模型的优势在时序数据预测中尤其明显——XGBoost捕捉规则性趋势,MLP处理突变和噪声,比单模型能多抗住几种异常情况。不过要注意,模型融合不是银弹,遇到特征工程没做好的情况,神仙组合也救不回来。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 0
0 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)