李飞飞团队6篇成果入选ICLR 2026,但我们更该关心那些“还没做到”的部分。。。
“我们尚未找到从“理解”到“行动”的平滑斜坡,每一步突破都踩在自己的假设之上”
——既是进展、也是镜子
目录
THEORY OF SPACE: CAN FOUNDATION MODELS CONSTRUCT SPATIAL BELIEFS THROUGH ACTIVE EXPLORATION?
ENACT: Evaluating Embodied Cognition with World Modeling of Egocentric Interaction
MINDCUBE: Spatial Mental Modeling from Limited Views
ROSETTA: Constructing Code-Based Reward from Unconstrained Language Preference
Cambrian-S: Towards Spatial Supersensing in Video
2026年ICLR会议中,李飞飞团队及其合作者西北大学李曼玲团队等人围绕具身智能的核心痛点——空间认知不足、数据利用低效、人机交互脱节,产出了6项重磅研究。
这些成果从基准构建、数据生成、推理优化三个维度形成闭环,但细看之下,每项突破的背后,都藏着一些尚未回答的追问:
我们构建的“空间信念”,究竟是在模拟人的认知,还是在拟合数据集?所谓“世界模型”,捕捉到的是物理规律,还是统计惯性?当多模态模型开始“理解”空间,它真的看见了世界,还是在用语言反哺视觉?
下文将分方向盘点,不止于成果,也聊聊它们的边界。
01 基准构建与评估
具身智能的发展离不开精准的评估体系,本方向聚焦于设计覆盖空间认知核心能力的基准,暴露现有模型短板,为技术优化提供量化依据。
THEORY OF SPACE: CAN FOUNDATION MODELS CONSTRUCT SPATIAL BELIEFS THROUGH ACTIVE EXPLORATION?
提出空间理论框架,评估具身空间认知能力
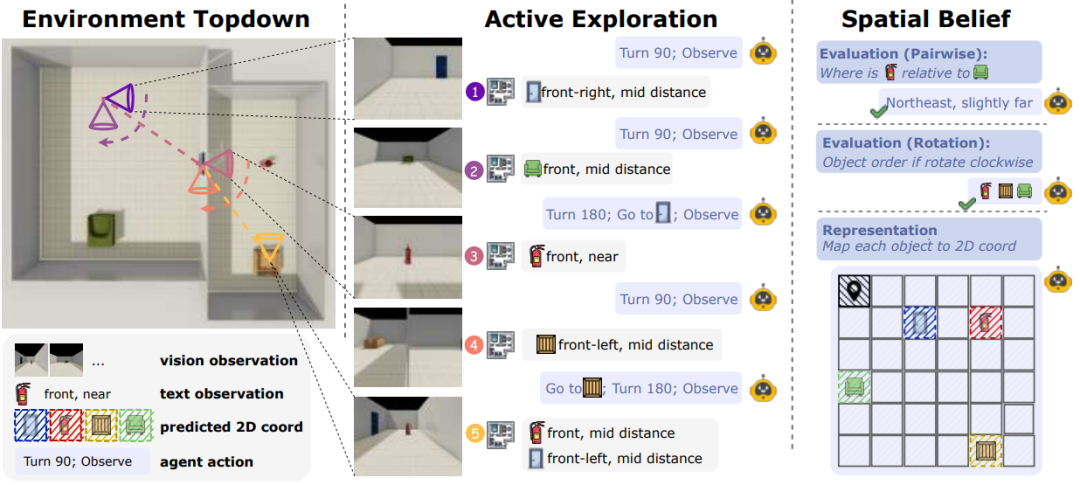
▲空间理论:主动探索、信念探测与评估框架
-
提出“空间理论”概念,定义具身智能体主动构建、修订和利用空间信念的核心能力,填补现有基准对主动空间认知评估的空白。
-
构建文本-视觉平行基准环境,支持探测感知与推理层面的故障分离,覆盖路径级和概览级空间知识评估。
-
创新空间信念探测机制,通过结构化认知地图输出,直接衡量信念准确性、稳定性及不确定性建模能力,突破传统黑箱评估局限。
-
设计虚假信念范式,首次量化“信念惯性”现象,揭示模型在环境动态变化时难以更新过时空间先验的关键缺陷。
-
区分主动探索与被动理解两种评估场景,系统分析环境复杂度对模型空间认知性能的影响规律。

研究局限性:研究仅聚焦单智能体场景,尚未探索多智能体协同探索的相关问题;同时未针对模型视觉感知短板、空间信念易退化及信念惯性等问题,提出有效的优化和改进方案。
论文链接:https://theory-of-space.github.io/paper/Theory_of_Space.pdf
代码链接:https://github.com/mll-lab-nu/Theory-of-Space
ENACT: Evaluating Embodied Cognition with World Modeling of Egocentric Interaction
提出ENACT基准,评估VLM具身认知能力
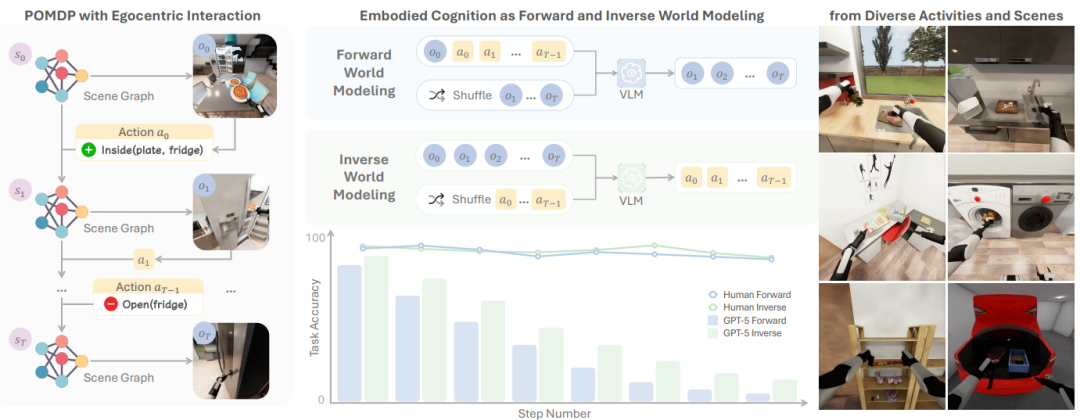
▲ENACT:基于自我中心交互的具身认知世界建模评估框架
该研究提出ENACT基准,以第一人称交互的世界建模为核心,采用视觉问答格式,将具身认知评估转化为前向和逆向世界建模两大序列重排任务。
依托机器人仿真生成8972个QA样本,通过任务准确率和成对准确率两项指标,对多款主流视觉语言模型(VLMs)开展评估,同时探究模型在图像真实性、相机配置等因素影响下的表现及具身偏差。

研究局限性:目前的研究只是初步探索了部分具身相关诊断场景,消融实验的模型和数据范围有限,没尝试通过微调优化模型的具身世界建模能力,也没将视频生成模型纳入评估范畴。
论文链接:https://arxiv.org/abs/2511.20937v1
代码链接:https://enact-embodied-cognition.github.io/
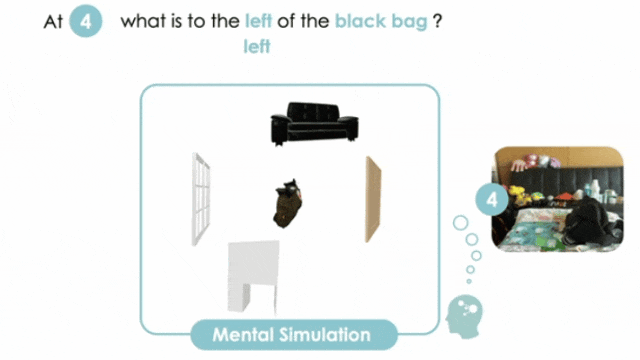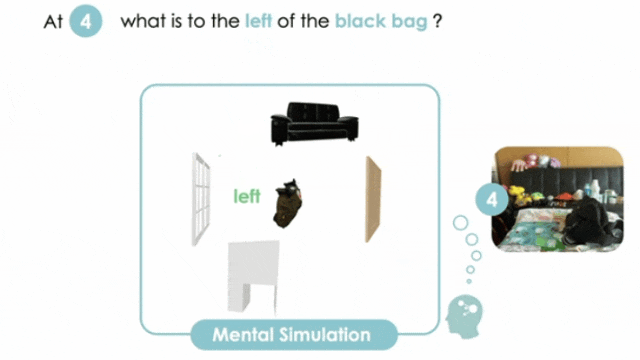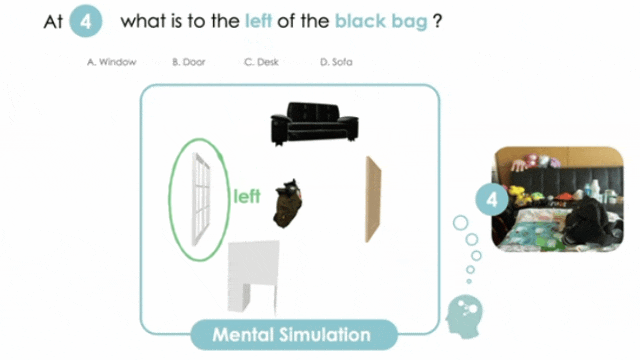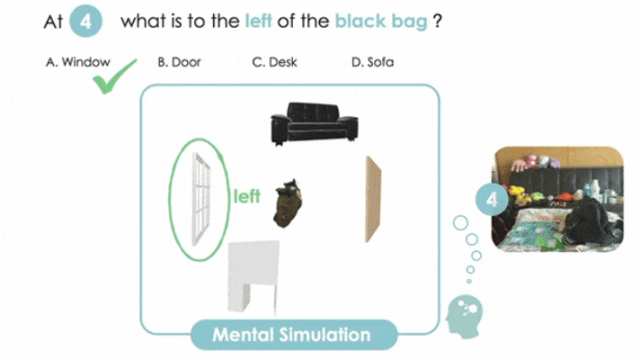
MINDCUBE: Spatial Mental Modeling from Limited Views
构建空间心智建模基准,提升具身空间推理
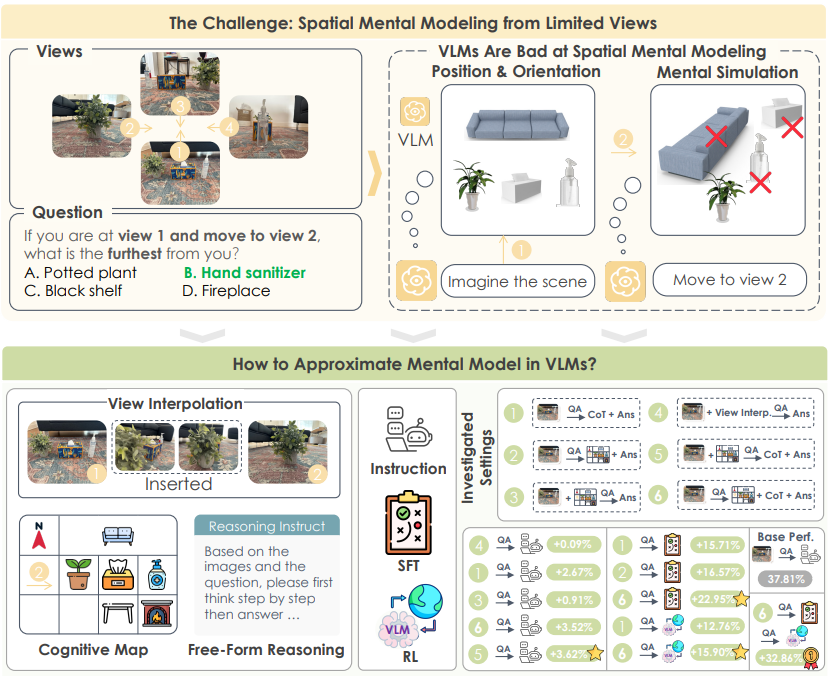
▲上图:在 MINDcube 基准测试中,视觉语言模型(VLM)无法维持一致的心理模型。下图:通过外部方法(视角缩放、认知地图输入)与内部策略(微调、认知地图唤起),帮助模型进行空间想象推理。
-
打造MINDCUBE基准,系统覆盖多视角变换场景,包含21154个问题和3268张图像,聚焦有限视角下的空间心智建模能力评估。
-
通过探索视图插值、自然语言推理链和认知地图,提出三种空间心智建模支架方案,验证认知地图与推理链的协同作用,突破单一支架的性能局限。
-
设计“先地图后推理”训练范式,引导模型主动构建内部空间表征并基于其推理,大幅提升结构一致性。
-
引入强化学习优化微调后模型,将任务准确率从基准37.8%提升至70.7%,实现性能质的飞跃。
局限性:研究仅基于单一基准模型开展实验,未充分探索不同架构 VLMs 的空间推理表现,且未涉及复杂真实场景中动态物体的空间建模,对模型在更长视野下的推理稳定性也未深入验证。
论文链接:https://arxiv.org/pdf/2506.21458
代码链接:https://github.com/mll-lab-nu/MindCube
02 数据生成与偏好适配
本方向聚焦于解决双臂操作、动态偏好适配等场景的数据稀缺问题,通过创新数据生成范式,为模型训练提供高效支撑。
MOMAGEN: GENERATING DEMONSTRATIONS UNDER SOFT AND HARD CONSTRAINTS FOR MULTI-STEP BIMANUAL MOBILE MANIPULATION
单源演示生成多样数据,助力具身智能部署

▲MoMaGen:从单个人类演示生成多样化机器人操作与导航轨迹
-
统一约束优化框架,整合硬约束(可达性、操作时可见性等)与软约束(导航时可见性、收缩动作等),适配双臂移动操作场景。
-
联合优化机器人末端执行器、头部相机和基座姿态,实现全身运动协调,突破传统仅关注末端执行器的局限。
-
通过基座姿态采样与跨场景运动规划,扩展机器人工作空间,支持更激进的场景随机化与障碍物环境。
-
优先进行快速逆运动学检查,分解机器人构型为躯干/手臂子空间采样,提升数据生成效率。
-
支持跨机器人形态的数据生成,通过任务空间轨迹规划复现,降低对特定机器人运动学的依赖。

研究局限性:MOMAGEN 依赖完整的场景知识生成演示,在真实场景中应用受限,且目前仅支持导航与操作交替的任务模式,数据生成过程还需大量 GPU 资源支撑。
论文链接:https://www.arxiv.org/pdf/2510.18316
代码链接:https://momagen.github.io/
ROSETTA: Constructing Code-Based Reward from Unconstrained Language Preference
代码化奖励生成,适配具身智能动态偏好
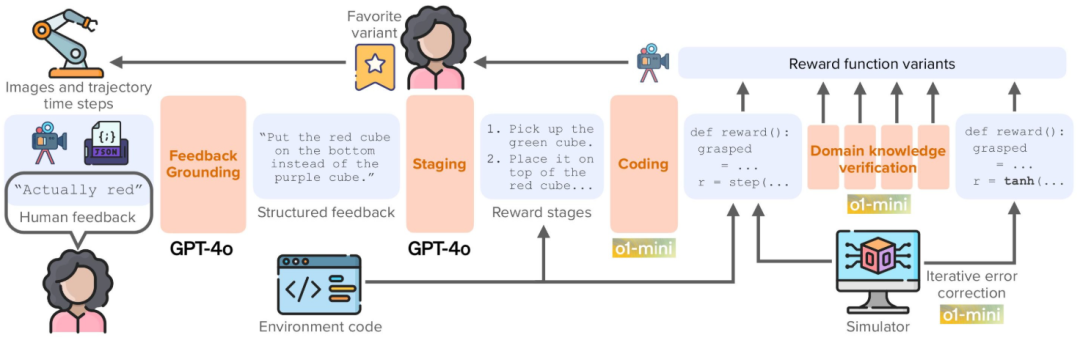
▲ROSETTA:从人类偏好反馈到可执行奖励函数的闭环生成框架
针对具身智能需适配人类非约束语言偏好的需求,该研究提出ROSETTA框架。
-
提出三模块流水线架构(偏好接地、阶段规划、代码生成),实现非约束语言偏好到可执行奖励代码的端到端转换,解决偏好模糊性与动态性难题。
-
创新偏好接地机制,结合轨迹图像、符号状态与任务历史,将口语化、上下文依赖的偏好转化为明确指令,适配复杂场景理解需求。
-
引入阶段化奖励设计,复用大语言模型的规划能力,将单句偏好拆解为原子化任务阶段,保障奖励函数的稠密性与可优化性。
-
构建三位一体评估框架(对齐度、语义匹配度、可优化性),突破传统仅依赖任务成功率的评估局限,全面衡量具身智能偏好适配效果。
-
支持在线单步适配,无需多轮反馈迭代,可处理与历史偏好冲突、新增或变更的任务需求,提升具身智能交互灵活性。

研究局限性:一是语义匹配评估过度依赖专家主观判断,缺乏低成本且客观的自动化衡量指标;二是任务适配中易出现错误累积,对含内容约束的场景适配性不足,整体在评估客观性与复杂场景泛化性上仍有提升空间。
论文链接:https://openreview.net/pdf?id=xuDPUN7Ud4
代码链接:https://sanjanasrivastava.github.io/rosetta-project/
03 空间认知与推理优化
空间认知是具身智能与环境交互的核心能力,本方向聚焦于突破现有模型的空间理解瓶颈,通过创新推理范式与模型架构,提升长时域、复杂场景下的空间推理性能。
Cambrian-S: Towards Spatial Supersensing in Video
提出空间超感知范式,赋能具身视觉推理
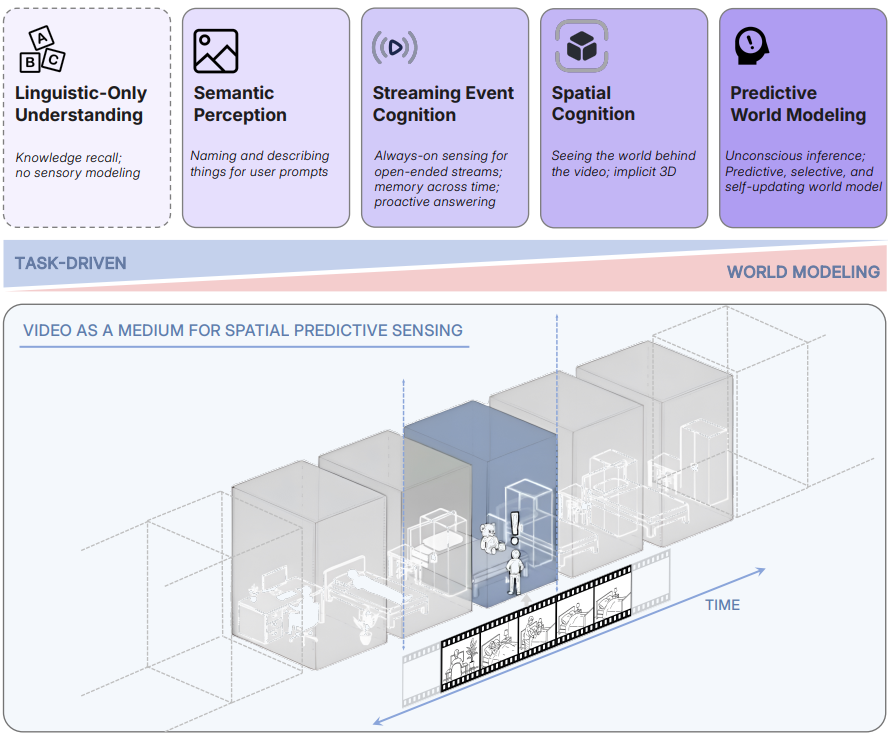
▲从像素到预测思维:超越纯语言理解的多模态智能框架
-
定义空间超感知四阶段层级(语义感知、流式事件认知等),填补现有基准对高阶空间认知与世界建模评估的空白。
-
构建VSI-SUPER基准,设计长时域、抗暴力扩展的空间任务,精准暴露当前模型的持续感知短板。
-
打造VSI-590K大规模空间导向数据集,融合多源3D标注与伪标注数据,为具身空间推理提供优质训练资源。
-
提出预测性感知范式,基于“意外度”信号实现动态记忆管理与事件分割,突破固定上下文窗口限制。
-
训练Cambrian-S模型,在传统空间基准上实现30%+性能提升,同时通过预测性感知范式显著优于主流长上下文基线。
研究局限性:一是当前基准、数据集与模型设计在质量、规模和泛化性上仍有不足,预测性感知仅为概念验证,尚未形成成熟体系;二是场景覆盖偏于室内空间与常规物体交互,缺乏更复杂的具身场景和多样化环境适配;三是未充分联动视觉、语言与世界建模的最新进展,在跨模态深度融合的探索上还有拓展空间。
论文链接:https://arxiv.org/pdf/2511.04670
代码链接:https://github.com/cambrian-mllm/cambrian-s
04 总结
李飞飞&李曼玲团队的6项成果形成了“评估-数据-推理”的完整技术链条:
-
通过多维度、场景化的基准设计,精准定位具身智能在空间认知、交互推理等方面的短板,为技术迭代提供明确方向。
-
创新数据生成与偏好适配范式,解决特殊场景数据稀缺、动态需求难满足等问题,从源头提升模型泛化能力。
-
聚焦有限视角、长时域等复杂场景,通过认知地图、预测性感知等创新,让具身智能具备类人般的空间建模与推理能力。
05 既是进展,也是镜子
综观六项工作,李飞飞团队延续了其在视觉与具身交叉领域的扎实风格:
基准构建明确了能力边界,数据生成降低了落地门槛,认知优化则逼近了人类级空间理解。
好处是,问题意识开始精细化。不再泛泛谈“多模态”,而是拆解成空间建模、主动探索、第一人称交互;不再笼统说“数据不够”,而是试图用约束生成和偏好对齐来补位;不再满足于视频理解,而是开始追问空间超感知的可能性。
但代价同样明显:每一项进展,都建立在更多假设之上。
这并非否定工作的价值。相反,正是因为这些问题足够难,才值得反复叩问。
在这个意义上,这六篇论文既是进展,也是镜子。它们映照出的,是一个正在从狂热中冷静下来的领域,以及那些等待被下一轮思考击穿的常识。
——毕竟,人类学会抓取杯子,不需要一千万次演示。而机器人距离这个“不需要”,还需要多少假设被打破?

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 4
4 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)