self attention多种变体
self attention多种变体
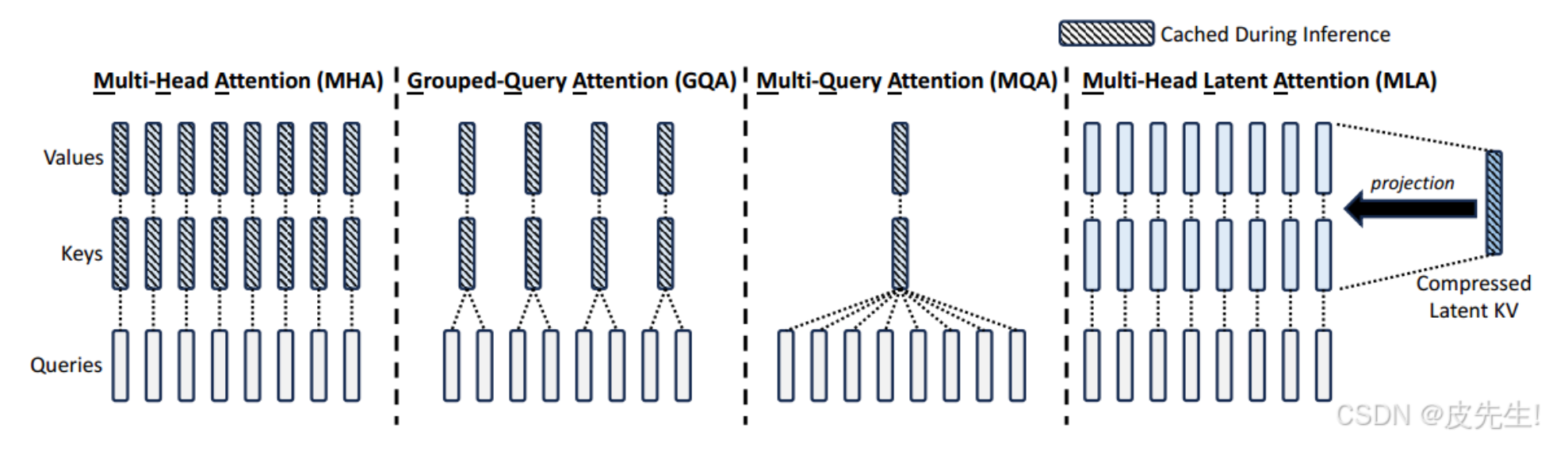
Multi-QueryAttention
每个head的Query 共享K和V矩阵,KV cache的内存占用直接降到了 。
不过这么做的效果还是会有折扣的,即性能上的下降不可避免,也会影响模型的稳定性。
Grouped-QueryAttention
![]()
目前常用的模型:LLAMA2-70B、LLAMA3全系列、TigerBot、DeepSeek-V1、StarCoder2、Yi、ChatGLM2、ChatGLM3用的都是这个方法。
降秩MLA
https://blog.csdn.net/weixin_44994341/article/details/147017174
DeepSeek V2提出了MLA,Multi-headLatentAttention,采用低秩键值联合压缩技术来显著减少KV缓存的内存占用,保持甚至提升性能。MLA 将多头注意力机制与潜在表示学习相结合,解决MHA在高计算成本和KV缓存方面的局限性。它通过将高维输入映射到低维潜在空间,然后在这个低维空间中执行多头注意力计算,从而减少计算量和内存占用。
低秩投影为什么有效?
这里有个假设,即模型在适应新任务的时候,只需要训练很少的参数,其参数变化的有效维度远小于原始维度,低秩矩阵足以捕捉关键信息,而且它在推理的时候没有延迟。
线性注意力机制
线性注意力机制(Linear Attention)是一类通过降低计算复杂度来优化传统注意力机制的方法,尤其适用于长序列任务。其核心思想是将注意力矩阵的计算复杂度从 ![]() ,从而显著减少计算和内存开销
,从而显著减少计算和内存开销
减小KV cache的方法
KV cache示例:
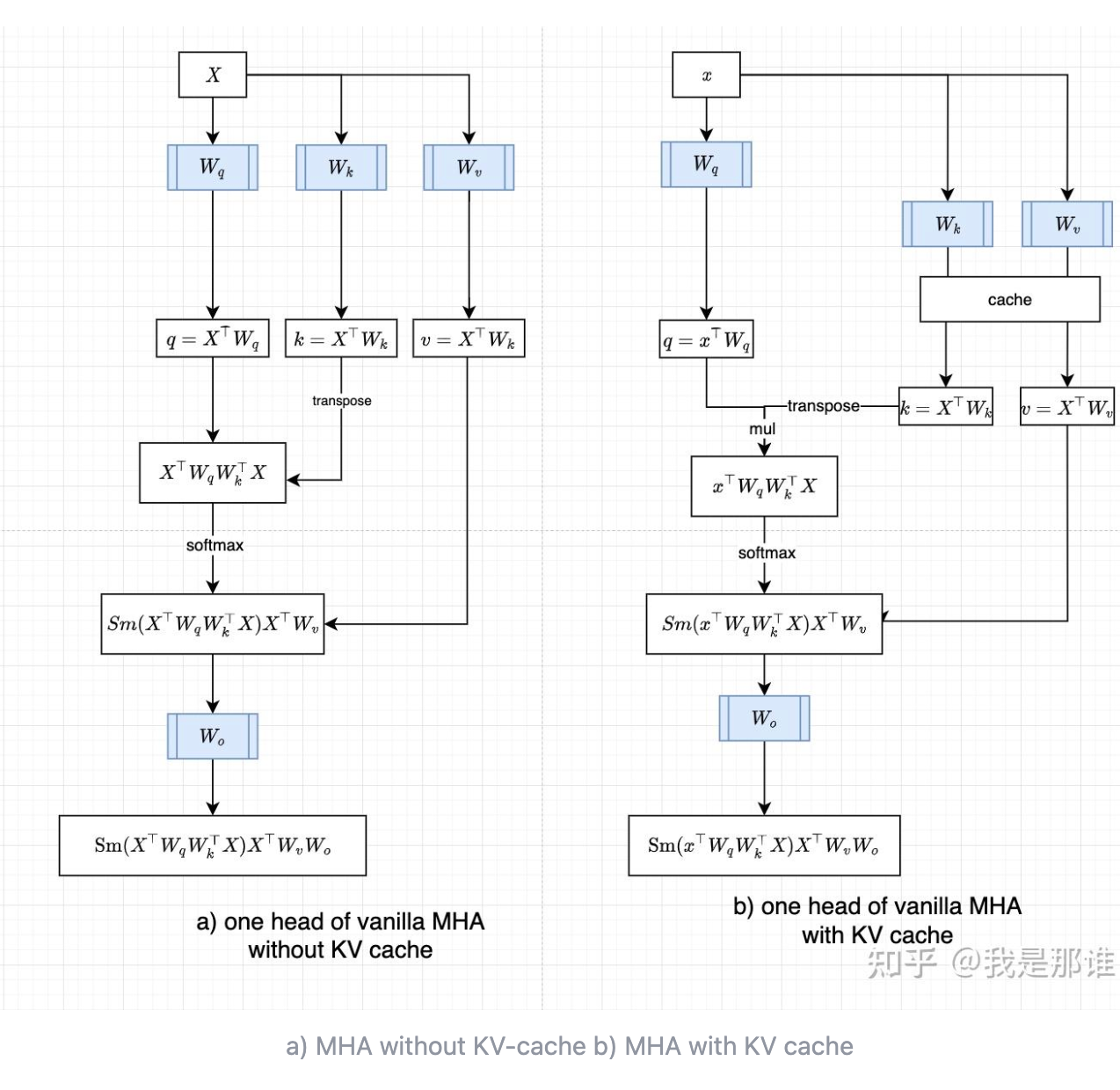
KV Cache 优化方法汇总
业界针对KV Cache的优化,衍生出很多方法,这里我根据自己的积累,稍微总结下,只简单描述优化的思路,不过多展开。
方法主要有四类:
- 共享KV:多个Head共享使用1组KV,将原来每个Head一个KV,变成1组Head一个KV,来压缩KV的存储。代表方法:GQA,MQA等
- 窗口KV:针对长序列控制一个计算KV的窗口,KV cache只保存窗口内的结果(窗口长度远小于序列长度),超出窗口的KV会被丢弃,通过这种方法能减少KV的存储,当然也会损失一定的长文推理效果。代表方法:Longformer等
- 量化压缩:基于量化的方法,通过更低的Bit位来保存KV,将单KV结果进一步压缩,代表方法:INT8等
- 计算优化:通过优化计算过程,减少访存换入换出的次数,让更多计算在片上存储SRAM进行,以提升推理性能,代表方法:flashAttention等

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)