前端转 AI Agent 开发日记 (Day 1):从“调包侠”到手撕“数字大脑”全栈闭环
标签: 前端转行 AI Agent LangGraph FastAPI 大模型全栈
作为一名刚工作几个月、日常切图写小程序、只懂点 Python 皮毛的前端开发,我最近越来越焦虑:大模型满天飞,难道以后前端只能给 AI 写聊天框 UI 吗?
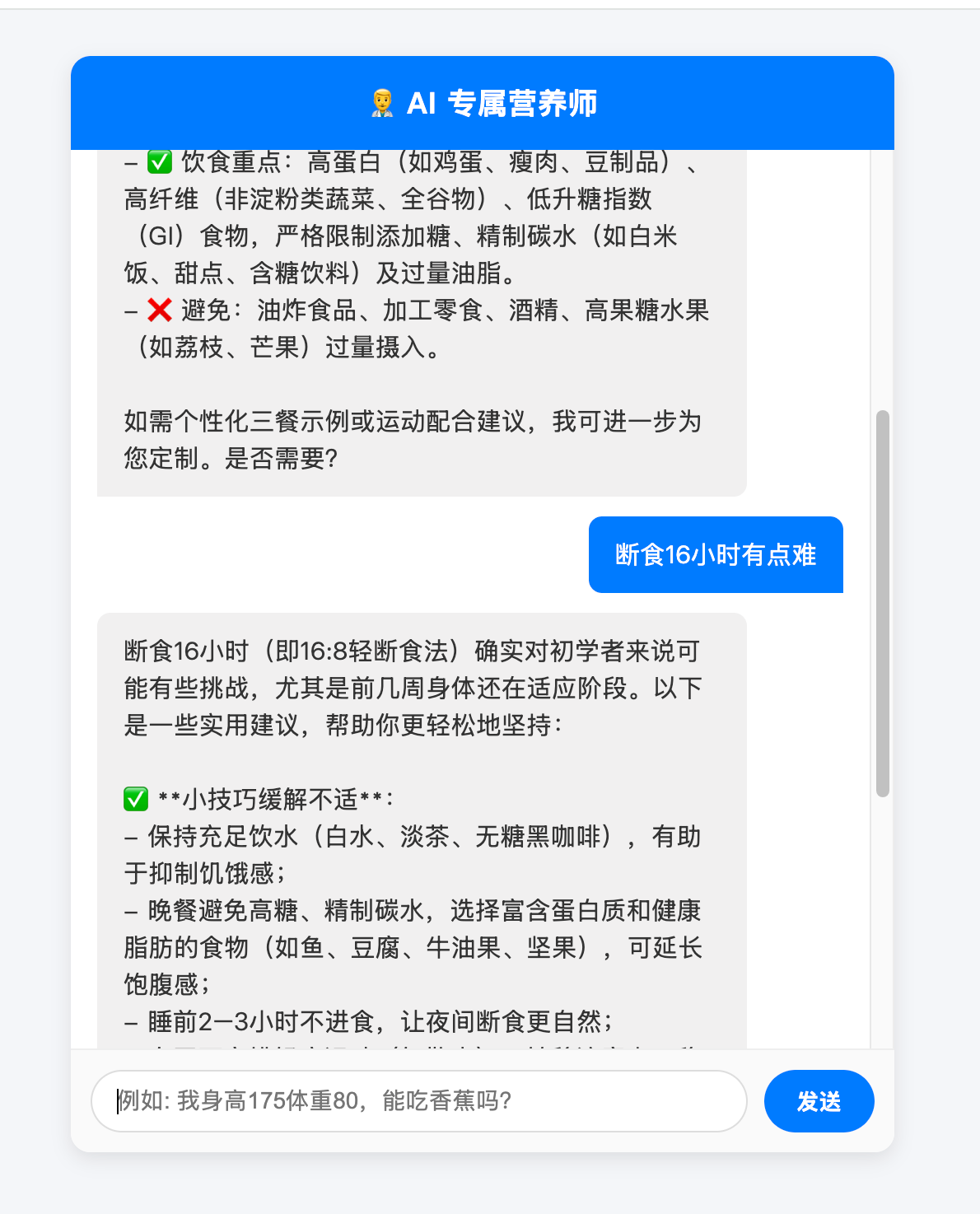
带着这个疑问,我决定正式跨入 AI 赛道,目标是学习 AI Agent(人工智能体)开发。今天是我系统的第一天学习,原本以为会淹没在枯燥的算法推导里,结果却出乎意料的“爽”——我竟然用几个小时,从零手撸了一个带有“独立思考能力”、“能查阅私有资料”并且“会算数”的 AI 专属营养师 API,并用原生的 JS 打通了全栈闭环!
特此记录这高能的一天,给同样想从业务端转行 AI 的小伙伴们避个坑。
💡 认知颠覆:到底什么是真正的 AI Agent?
以前我以为的 AI 应用开发:
前端输入框 -> 发送请求给 ChatGPT API -> 拿到字符串 -> 前端渲染气泡。
(这在行业里叫“套壳”,极易被替代)。
今天学到的真 Agent 核心公式:
Agent = LLM (大模型大脑) + Memory (记忆) + Tools (工具/执行力)
真正的 Agent 不是“你问我答”的字典,而是一个调度中心。当你给它一个复杂任务时,它能自己拆解步骤,决定是去数据库查资料,还是调用本地的 Python 函数跑个计算。
我的实战目标:开发一个健康与饮食管理应用的核心后台。它不能只会胡说八道,它必须严格按照我给的营养学设定回答,并且能帮用户精准计算 BMI。
⚔️ 实战 第一阶段:用 RAG 解决 AI 的“幻觉” (踩坑重灾区)
大模型不懂我的私有业务逻辑怎么办?用 RAG (检索增强生成)。
通俗点说,就是在让 AI 答题前,先扔给它一本“参考书”,让它开卷考试。数学原理是通过向量化(Embedding)计算文本相似度:
。
我兴冲冲地用 LangChain 框架写了第一段代码,结果迎来了疯狂的报错毒打。
坑 1:包名大分裂 ModuleNotFoundError
直接运行报错找不到 langchain_community。
-
复盘: LangChain 更新太快了!官方把第三方生态组件全抽离出去了。
-
解决: 老老实实
pip install langchain-community
坑 2:API 鉴权与向量格式不匹配 (401 & 400 连环杀)
因为我用的是阿里云的通义千问 API,但 LangChain 默认往美国的 OpenAI 服务器发请求,直接报了 401 AuthenticationError。
等我加上了 OPENAI_API_BASE 指向阿里云后,又报了 400 BadRequest。
-
复盘: 核心原因是底层组件自作聪明。LangChain 的
OpenAIEmbeddings会把中文切成数字数组发过去,而阿里云百炼服务器要求接收纯字符串。格式对不上,直接被拒。 -
解决: 抛弃默认组件,安装阿里官方包
pip install dashscope,并把向量工具替换为原生的DashScopeEmbeddings。
跑通的 RAG 核心代码:
Python
# 将私有资料向量化并存入 Chroma 本地数据库
vectorstore = Chroma.from_texts(
texts=["香蕉的GI值为52,属于低中等,可适量食用,但不宜空腹。"],
embedding=DashScopeEmbeddings(model="text-embedding-v2")
)
retriever = vectorstore.as_retriever(search_kwargs={"k": 1})
🛠️ 实战 第二阶段:给大脑装上“手脚” (Tool Use)
大模型算数极差,让他算 BMI 等于买彩票。所以我需要给它写一个本地的 Python 计算器,并告诉它:“遇到算数题,调用这个函数,别自己瞎算”。
这里我引入了当前最火的 LangGraph 框架,用它来构建 ReAct (推理+行动) 智能体。
坑 3:虚拟环境幽灵 (rag_env) (base)
在导包 from langchain.agents import create_react_agent 时死活报错。仔细一看终端前缀,竟然同时叠了两个环境。
-
复盘: 我新开了一个终端窗口,默认进入了系统自带的 conda
base环境,这里面的 langchain 版本太老了! -
解决: 永远记住在跑代码前
source ~/rag_env/bin/activate激活正确的虚拟环境。
极其优雅的 Tool 封装语法:
只要加上 @tool 装饰器,大模型就能自动读取 Python 函数的参数格式和注释说明(Docstring 极其重要,这是给 AI 看的说明书!)。
Python
@tool
def calculate_bmi(weight_kg: float, height_m: float) -> str:
"""根据体重(kg)和身高(m)计算BMI指数,并返回健康状况判定。"""
bmi = weight_kg / (height_m ** 2)
return f"计算结果:BMI值为 {bmi:.1f}"
🚀 实战 第三阶段:终极融合与 FastAPI 后端封装
我把 RAG 检索也包装成了一个 @tool,这样 Agent 手里就有了两把武器:“计算器”和“私有知识库”。
接着,作为半个前端,我轻车熟路地用 FastAPI 把这段 Python 逻辑包成了一个 API 接口 http://127.0.0.1:8000/ask。
坑 4:跨域中间件漏导包 NameError
加了跨域配置后服务直接崩溃。
-
复盘: 复制粘贴太快,忘了写顶部引入。
-
解决: 补上
from fastapi.middleware.cors import CORSMiddleware。
当看到终端打印出 Application startup complete. 的那一刻,我知道,最难的骨头已经啃下来了。
🌟 见证奇迹:原生 JS 打通全栈闭环
回到我的前端主场,我直接手写了一个没有任何脚手架的 index.html。界面包含一个聊天框和一个输入框,核心 JS 就一段 Fetch 请求:
JavaScript
const response = await fetch('http://127.0.0.1:8000/ask', {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({ question: userInput })
});
const result = await response.json();
// 渲染 result.data.ai_answer 到页面上
高能时刻来了!
我在页面的输入框里极其刁钻地问了一句:
“我身高1.75米,体重80公斤,而且我体检有高血糖前期。帮我评估下身体状况,顺便告诉我早上空腹能不能吃根香蕉顶一顶?”
我紧紧盯着后台终端的绿色日志:
-
🔧 [后台执行] 正在运行 BMI 计算器... 体重=80.0, 身高=1.75 -
📚 [后台执行] 正在翻阅私有知识库... 检索关键词: 高血糖 香蕉 -
随后,前端页面优雅地渲染出了一段排版精美、逻辑严密的回答,不仅告诉我 BMI 偏高,还根据私有设定警告我“高血糖不宜空腹吃香蕉”。

那一刻,爽感直冲天灵盖!我不再是一个只会调用接口的前端,我亲手搭建了一个具备思考和多步规划能力的 AI 调度中心。
🎯 Day 1 总结
作为一个前端开发者,我曾觉得转行 AI 门槛太高。但今天实战后我发现:AI 时代的红利,恰恰属于那些懂业务、懂工程、能把 AI 包装成产品的全栈开发者。 算法可以被封装,但如何结合场景(比如健康 App)定义 Tool、如何设计丝滑的前端交互,才是我们的护城河。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 4
4 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)