基于ARIMA时间序列的销量预测:源码与数据集探索
X00307-基于ARIMA时间序列的销量预测模型源码和数据集 ARIMA模型提供了基于时间序列理论,对数据进行平稳化处理(AR和MA过程)、模型定阶(自动差分过程)、参数估计,建立模型,并对模型进行检验。 在Python中statsmodel提供了全套的解决方案,包括窗口选择、自动定阶和平稳性检测等等算法。 每月分上中下旬三个点预测,每月预测三次当月销量。 这么做的好处是,月上旬和中旬的实际销量可以作为先验知识,提高模型预测的准确率。
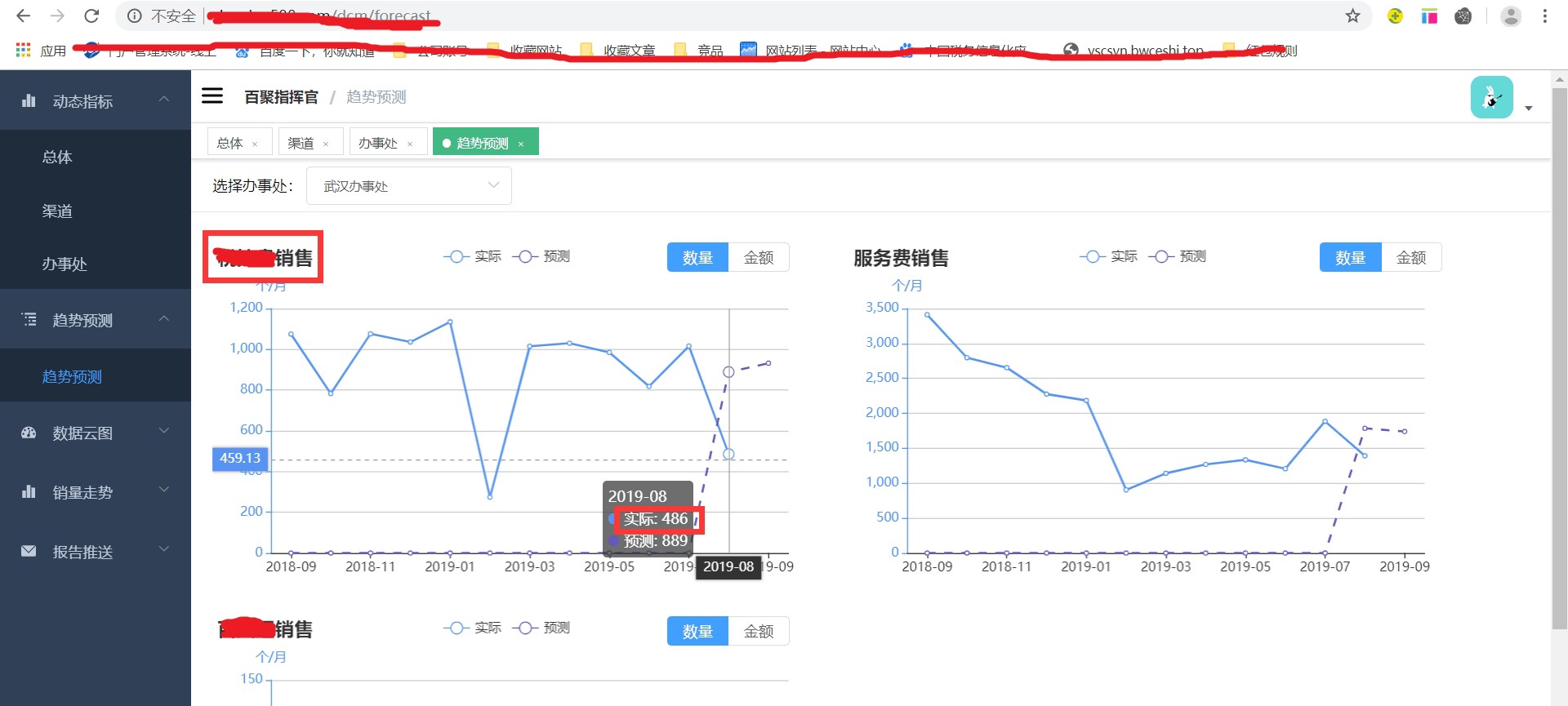
在数据分析与预测领域,时间序列分析一直占据着重要地位。今天咱就来唠唠基于ARIMA时间序列的销量预测模型,还会附上源码和数据集相关的探讨。
ARIMA模型原理浅说
ARIMA模型,全称为自回归积分滑动平均模型(Autoregressive Integrated Moving Average Model),它是基于时间序列理论构建的。整个过程主要分为几个关键步骤:
- 平稳化处理(AR和MA过程):实际中的时间序列数据大多是非平稳的,这就好比股票价格走势,上蹿下跳没个准儿。而ARIMA里的自回归(AR)和移动平均(MA)过程就是用来对数据进行平稳化处理。比如,AR过程通过数据自身的滞后项来构建模型,假设我们有时间序列 $yt$,一阶自回归模型可以写成 $yt = \phi1 y{t - 1} + \epsilont$,这里 $\phi1$ 是自回归系数,$\epsilont$ 是白噪声。这就像是说当前时刻的值 $yt$ 部分依赖于上一时刻的值 $y{t - 1}$,再加上一些随机干扰 $\epsilont$。MA过程则是通过白噪声的滞后项来构建模型,例如一阶移动平均模型 $yt = \mu + \epsilont + \theta1 \epsilon{t - 1}$,其中 $\mu$ 是均值,$\theta_1$ 是移动平均系数。
- 模型定阶(自动差分过程):有时候仅靠AR和MA还搞不定非平稳数据,这时候就要用到差分了。差分就像是给数据做个“按摩”,把数据变得平稳些。自动差分过程会根据数据特点确定合适的差分阶数。比如说一阶差分就是 $yt - y{t - 1}$,通过这种方式去除数据中的趋势。
- 参数估计:确定好模型结构后,就要估计模型中的参数啦,像前面提到的 $\phi1$,$\theta1$ 等,让模型尽可能贴合实际数据。
- 建立模型并检验:一切准备就绪,就可以建立ARIMA模型咯,最后还要对模型进行检验,看看模型预测效果咋样,是不是靠谱。
Python中statsmodel助力预测
在Python的世界里,statsmodel库简直就是ARIMA模型的得力助手,它提供了全套的解决方案。
- 窗口选择:可以根据数据特点和需求选择合适的时间窗口,这就像给数据框定一个观察范围,让分析更聚焦。
- 自动定阶:不用咱手动去试各种差分阶数、AR和MA的阶数啦,statsmodel能自动帮我们找到合适的模型阶数。
- 平稳性检测:能快速判断数据是否平稳,要是不平稳,还能给咱提示该咋处理。
下面咱直接上代码感受感受:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from statsmodels.tsa.arima.model import ARIMA
# 假设从文件中读取销量数据,这里数据格式假设为日期和销量两列
data = pd.read_csv('sales_data.csv', parse_dates=['date'], index_col='date')
# 检查数据是否平稳,这里简单用一阶差分来让数据平稳
data['diff'] = data['sales'].diff(1)
data['diff'].dropna(inplace=True)
# 构建ARIMA模型,这里假设经过检测p=1,d=1,q=1合适
model = ARIMA(data['diff'], order=(1, 0, 1))
model_fit = model.fit()
# 预测未来数据
forecast = model_fit.get_forecast(steps=3)
forecast_mean = forecast.predicted_mean
conf_int = forecast.conf_int()在这段代码里,首先我们从文件读取了销量数据,并将日期设置为索引。为了让数据平稳,对销量数据做了一阶差分(data['diff'] = data['sales'].diff(1))。然后根据检测结果构建了ARIMA(1, 0, 1)模型,这里的 order=(1, 0, 1) 分别对应p(自回归阶数)、d(差分阶数)、q(移动平均阶数)。接着训练模型并进行预测,steps=3 表示预测未来3个时间点的数据,forecastmean 就是预测的均值,confint 是置信区间。
每月分上中下旬预测销量
我们每月分上中下旬三个点预测当月销量,这么做的好处可不少。月上旬和中旬的实际销量可以作为先验知识,大大提高模型预测的准确率。就好比下棋,你知道了前面几步的局势,后面的预测肯定更准些。
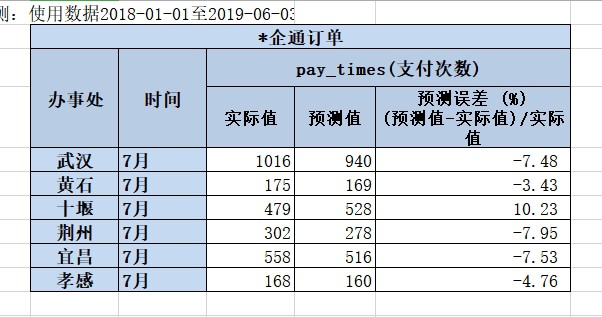
X00307-基于ARIMA时间序列的销量预测模型源码和数据集 ARIMA模型提供了基于时间序列理论,对数据进行平稳化处理(AR和MA过程)、模型定阶(自动差分过程)、参数估计,建立模型,并对模型进行检验。 在Python中statsmodel提供了全套的解决方案,包括窗口选择、自动定阶和平稳性检测等等算法。 每月分上中下旬三个点预测,每月预测三次当月销量。 这么做的好处是,月上旬和中旬的实际销量可以作为先验知识,提高模型预测的准确率。
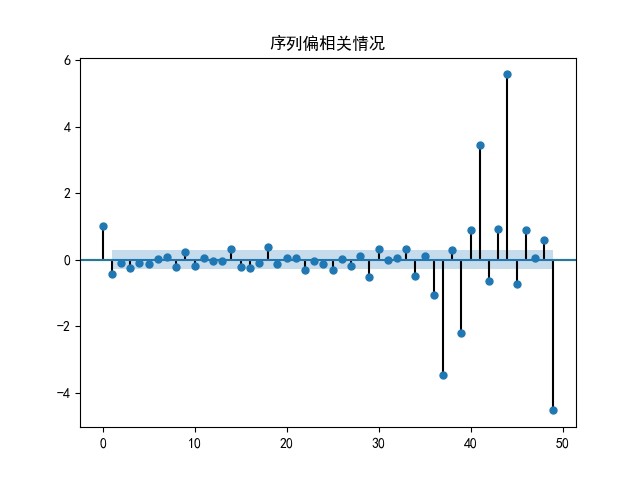
假设我们有每月上中下旬的销量数据,处理数据时可以按这个时间粒度来划分。例如在前面的代码基础上,我们可以按这个粒度重新组织数据:
# 假设数据中有表示上中下旬的列 'period'
data['period'] = pd.cut(pd.to_numeric(data.index.day),
bins=[0, 10, 20, 31],
labels=['上旬', '中旬', '下旬'])
# 分别对上旬、中旬、下旬数据进行处理和预测
for period in ['上旬', '中旬', '下旬']:
sub_data = data[data['period'] == period]
sub_data['diff'] = sub_data['sales'].diff(1)
sub_data['diff'].dropna(inplace=True)
sub_model = ARIMA(sub_data['diff'], order=(1, 0, 1))
sub_model_fit = sub_model.fit()
sub_forecast = sub_model_fit.get_forecast(steps=1)
sub_forecast_mean = sub_forecast.predicted_mean
print(f"{period} 的预测销量均值: {sub_forecast_mean.values[0]}")这段代码里,我们先根据日期把数据划分成上中下旬,然后分别针对每个时间段的数据进行差分、构建ARIMA模型、预测。这样就实现了每月分三次预测当月销量,充分利用了上中旬的实际销量信息来提升预测准确率。
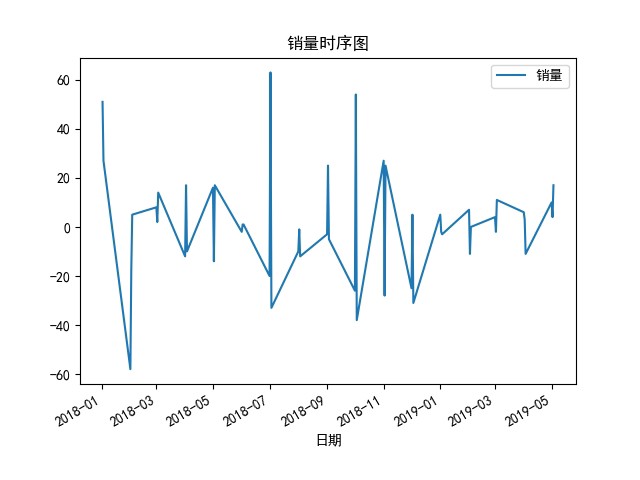
总之,基于ARIMA时间序列的销量预测模型结合Python的statsmodel库,再加上合理的预测策略,能为我们在销量预测这个战场上提供有力的武器。希望大家都能在实际项目中灵活运用起来!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 10
10 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)