关于自然语言处理的理解
一.NLP是什么
NLP 是计算机科学、人工智能与语言学的交叉学科,通过计算语言学、机器学习、深度学习等技术,将人类语言(文本 / 语音)转化为机器可处理的信号,并输出符合人类逻辑的结果。像Bert,transforer和Bart模型都属于NLP的范畴。
怎么表示词?
法一:独热编码
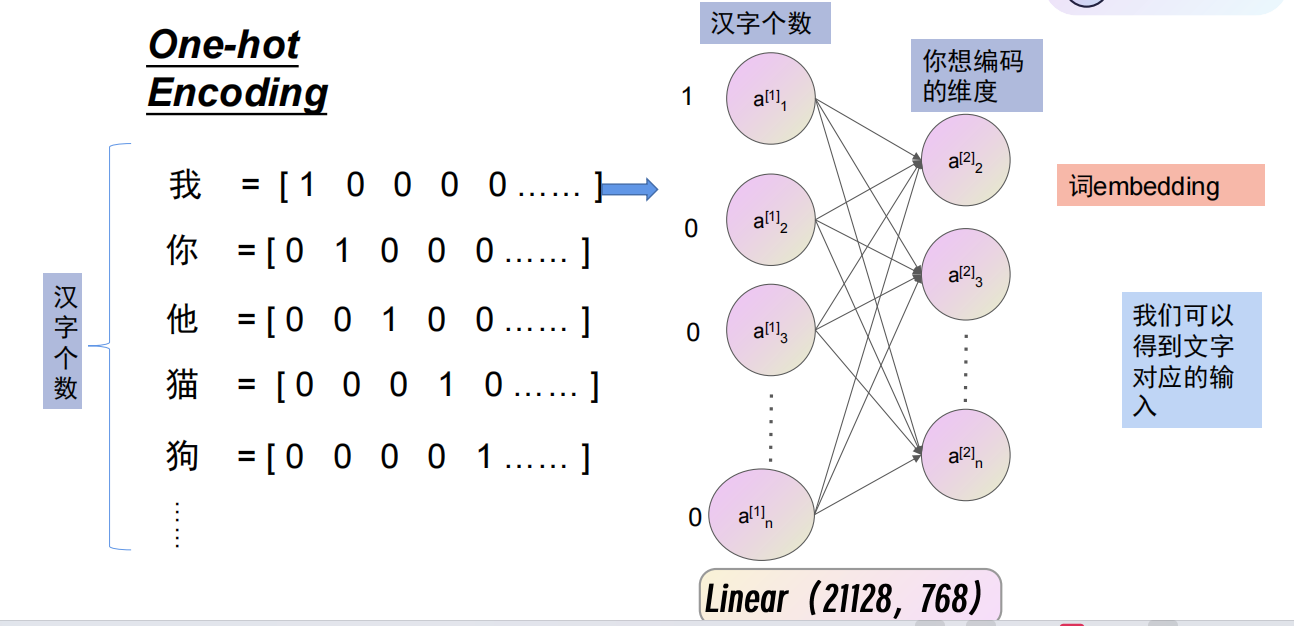
用一个向量来表示一个词。0是无效位,1是有效位。
缺点:1.如果要想表示每一个字,则维度太长了;2.每个字之间体现体现不出关系。
法二:词嵌入(word embedding)
把每个词变成一个短的、有意义的小数数组(向量),让机器能看懂、能计算语言。机器看文字只能看懂 0 和 1,完全不懂文字。所以我们需要把每个词,映射成一个固定长度的数字向量,这就叫 词嵌入。
同时,可以把意思相近的词的id(数组下标)编写得靠近一点,这样就可以让这两个意思相近的词产生一定的关系。

上下文的问题
如何表示词和词之间的关系:
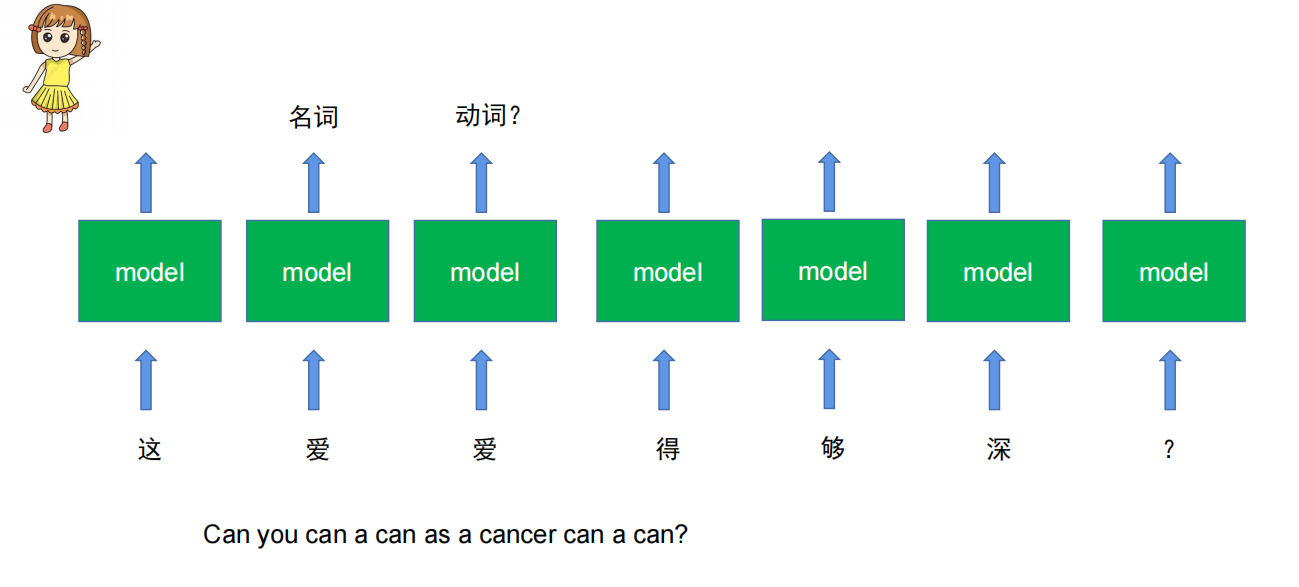
第一个“爱”与第二个“爱”是两个不同的词性,第一个是名词,第二个是动词,而要分清这两个同一个词不同含义的词,就需要用到上下文的机制。
所以引入RNN(循环神经网络)
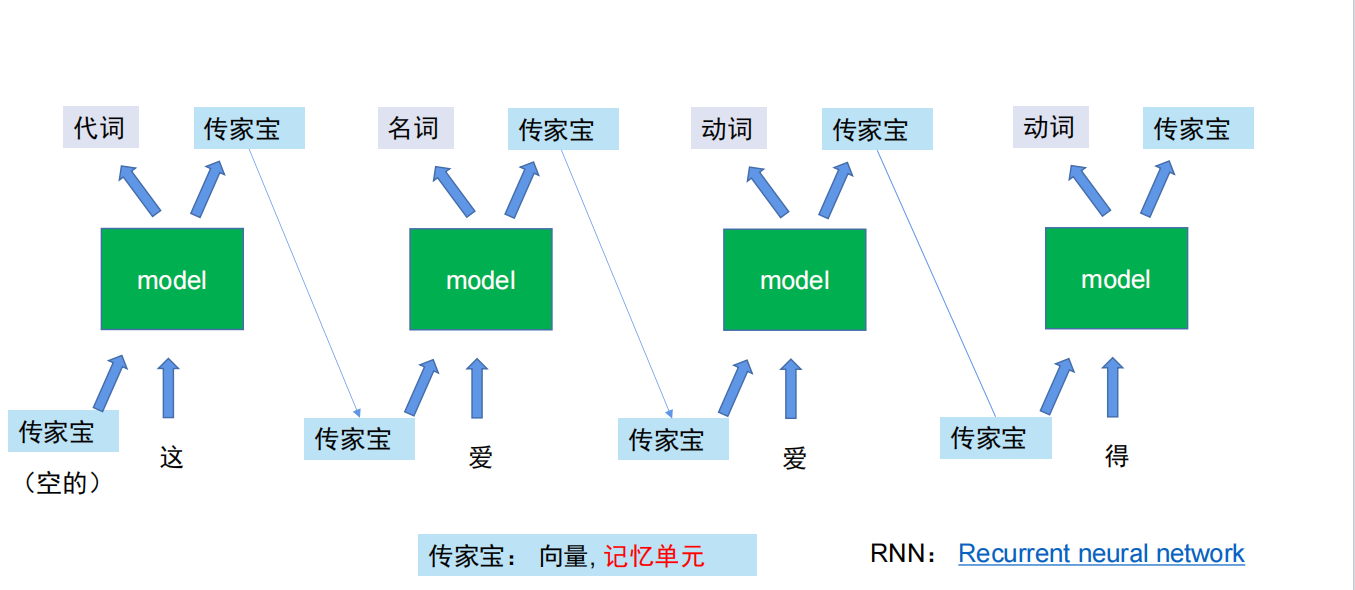
RNN(Recurrent Neural Network)就是一种专门处理序列数据的神经网络,它的核心设计是通过 “记忆” 前一步的信息,来处理当前步的输入,从而自然地捕捉序列的前后关系。RNN 的核心原理:循环 + 状态记忆。
可以理解为有一个记忆单元,将过去所记录的事情都放入这个记忆单元中,这样在本次的输出预测时,就可以考虑到过去以往的信息。(比如上一个词是名词,这次的输出大概率是一个动词)
但RNN本身也存在着问题,就是长序列的数据记不住,比如前面有1000个字,到第1000个字的时候,可能记忆单元里面就只有200个字了,记忆会慢慢消失。

从“我”字到“赛罕塔拉结下”,中间相隔许多字,记忆单元里面的内容也会在一次次记录中把前面的记忆一点点丢失。
为了解决这个问题,对RNN进行一定的改进:LSTM:
LSTM 可以理解为一个「带记忆功能的信息处理单元」,它不像 RNN 那样直接覆盖旧信息,而是通过三个门(输入门、遗忘门、输出门) 来「选择性遗忘旧信息、选择性记忆新信息、选择性输出有用信息」。
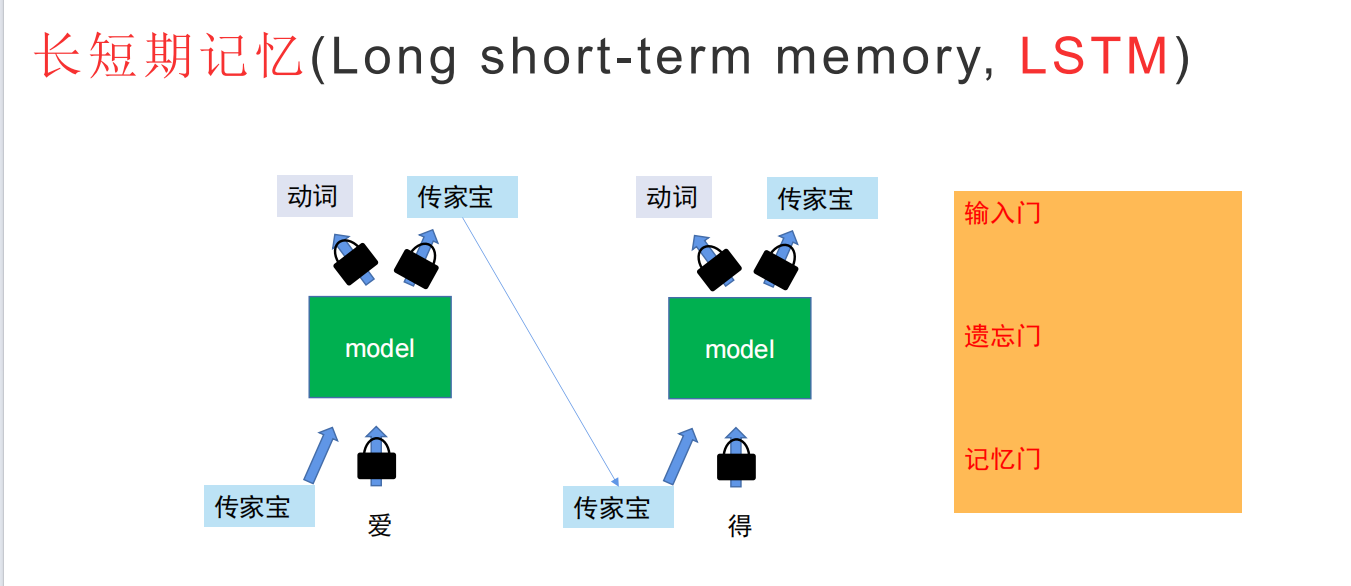
本质是让有效的数据才进入记忆单元中,这样就可以保证有效的数据留在记忆单元里面,为下一次的输出进行更好的预测。
但无论是RNN还是LSTM,都有一个缺点:串行,速度太慢了,必须得一个一个字的预测,因为上一个词的输出对下一个词的预测是有影响的。
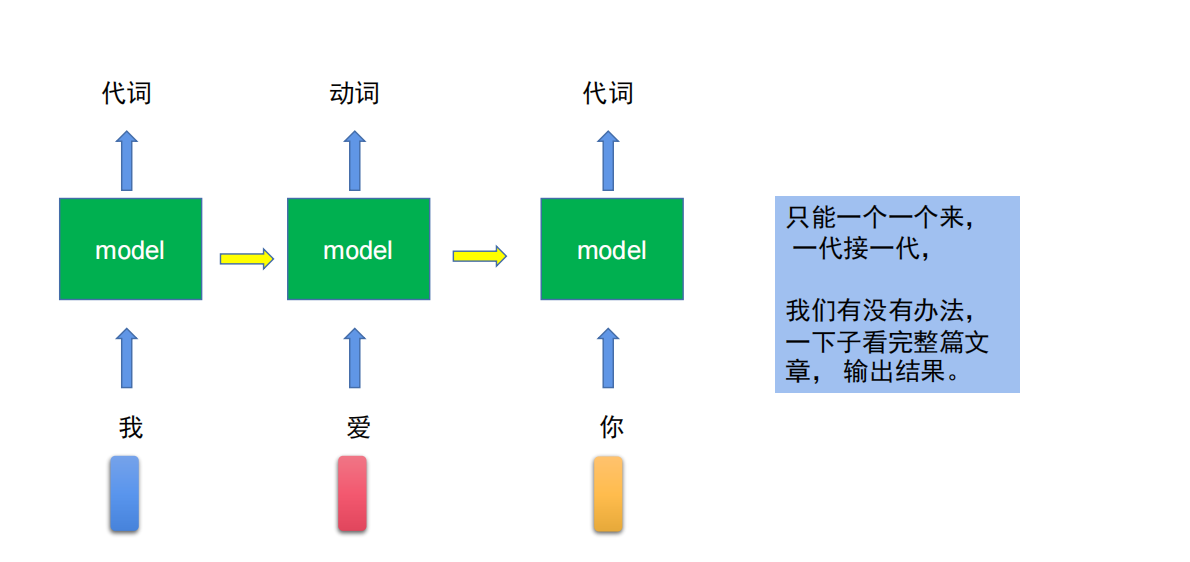
对此,就产生了自注意力机制
二.自注意力机制
注意力
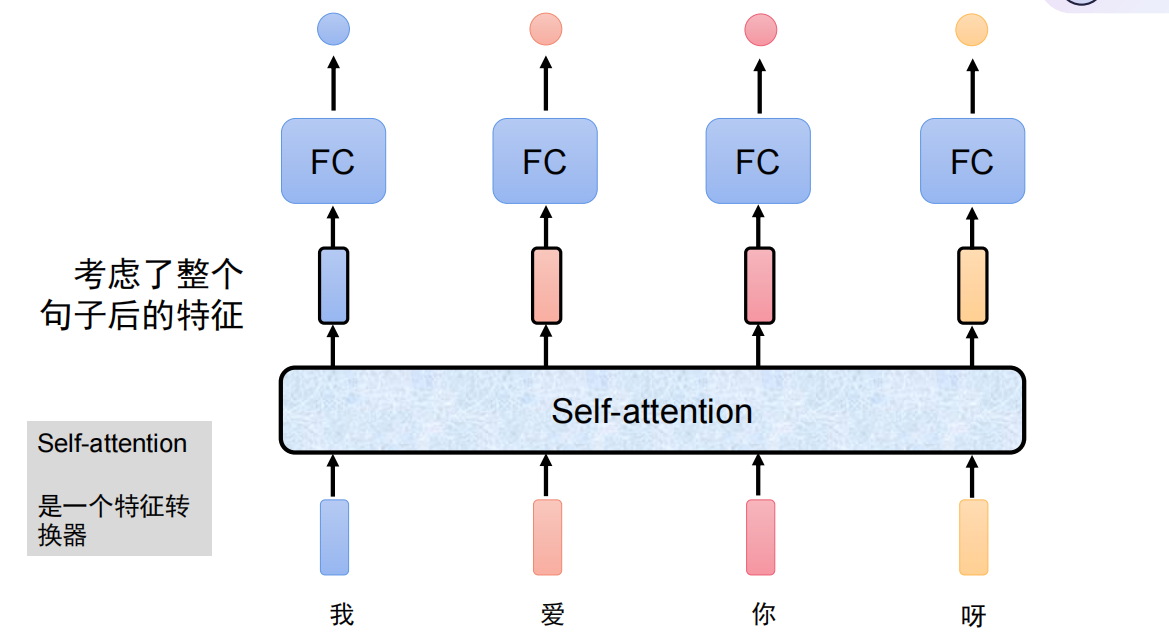
自注意力:一句话所有字同时看,每个字都能直接和任何一个字产生关系。
自注意力 = 一句话里,每个字都看一遍所有字(包括自己),自动决定重点看谁。是 Transformer、BERT、GPT 的灵魂。
即:一句话里,每个字都给其他所有字打个 “相关性分数”,分数高 = 关系近,重点看;分数低 = 关系远,少看。
注意力:就是模型针对问题,应该更加关注哪几个字或者词,并且就把相应词的“注意力”权重提高,这样模型就可以更加有针对性得训练和验证。
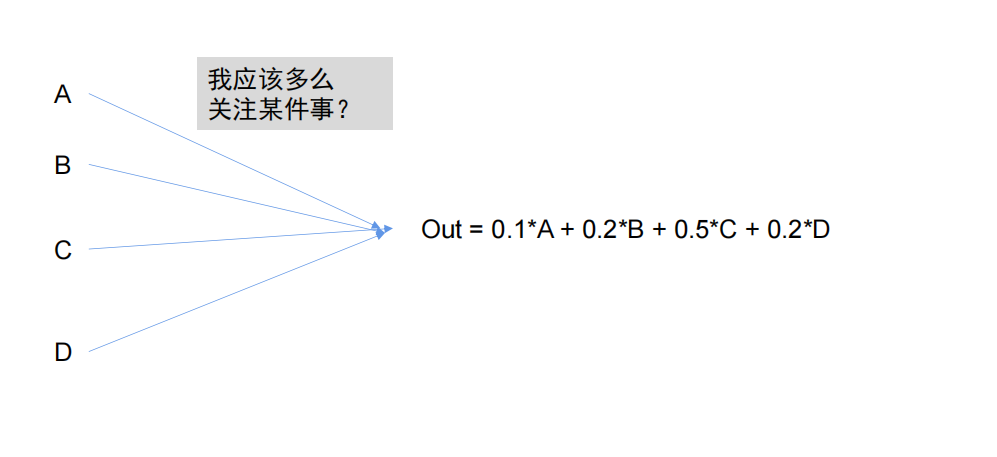
计算注意力的方式
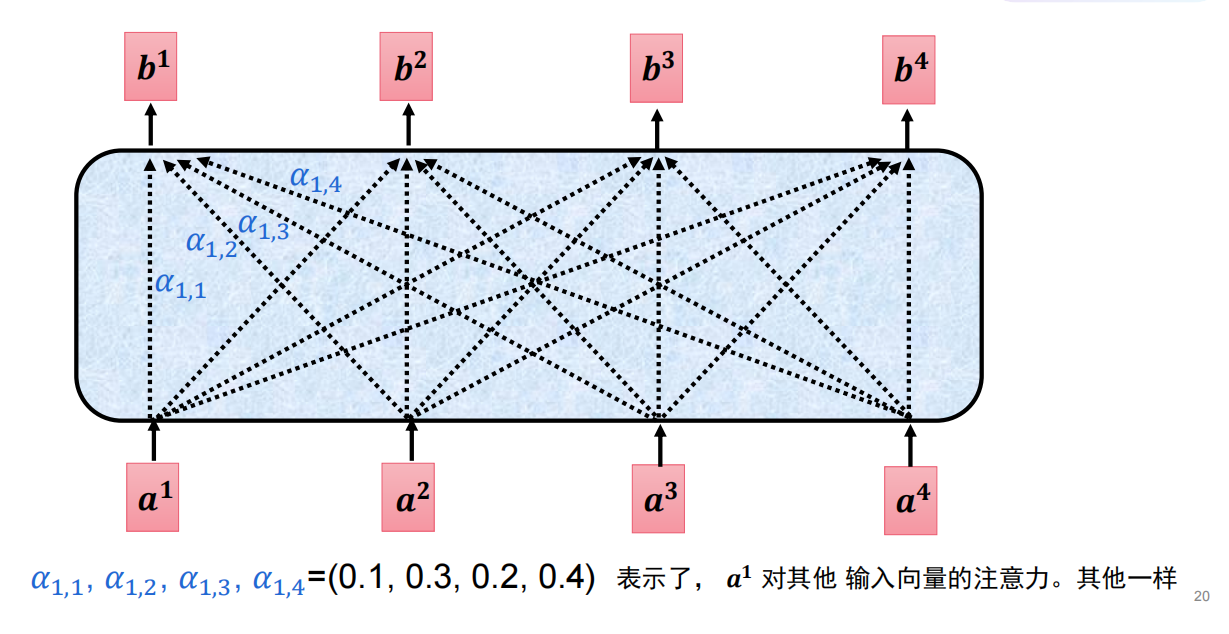
将自己的信息与其他人的信息进行点乘,就可以达到相互影响的效果。
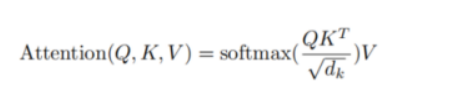
相关步骤:计算每个词的相似度(通过QKV)->通过相似度计算每个词的权重->最后加权平均,便可以知道相互之间的注意力
step1: 为每个词准备QKV

通过点乘的形式完成QKV,内容上QKV的一样的,但用途的不同的。
Q(query):我想到知道被人有什么 (扫码器,去扫别人的K)
K(key):我自己有什么 (二维码,等别人来扫)
V(value):我真正的信息内容 (最后由于Q扫别人的数据会有所变化,所以V是用与最后将Q与自身的V相乘)
step2:计算相似度(QK)


让Q与K点乘,这样就可以知道Q与K的相关程度,点乘值越大,说明相关程度越大,点乘值越小,说明相关程度越小。
同时,用根据自注意力机制的公式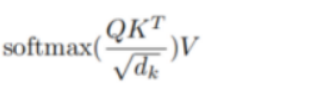 ,要将Q与K相乘后的矩阵除以根号dk,这一步是为了统一量纲。
,要将Q与K相乘后的矩阵除以根号dk,这一步是为了统一量纲。
step3:经过softmax归一化,使之输出的是一个概率的权重

这就是注意力权重。注意力权重 = 每个词该信多少、看多少
step4:最后将算出来的权重与V(自身)相乘
这样就可以知道每次字自身与其他字之间的注意力权重应该是多少,最后做加权平均就可以得到一序列的所有的权重。eg:0.1*我.V +0.7爱.V+0.2你.V,这就是上下文的信息交流。

三.多头自注意力机制
多头自注意力的核心优势
- 多维度捕捉上下文:每个头关注不同类型的关联(指代、属性、动作、逻辑等),比单头更全面;
- 提升模型表达能力:多头拼接相当于 “多角度理解文本”,能捕捉更复杂的语义;
- 并行计算:多头之间可并行,不增加太多计算耗时(相比单头仅增加参数数量)。
本质就是增加自注意力机制的并行性,可以让模型在计算注意力时,不仅仅只是对词进行计算,还可以对语义、语法等属性计算注意力。
四.位序问题
在自注意力机制里面,“我爱你”与“你爱我”这两句话每个字的自注意力都是一样的,因为只是位置不同,而对于字是一样的。但是这不符合常理,原因就在于这个字的位置上,所以就引出了位置编码。
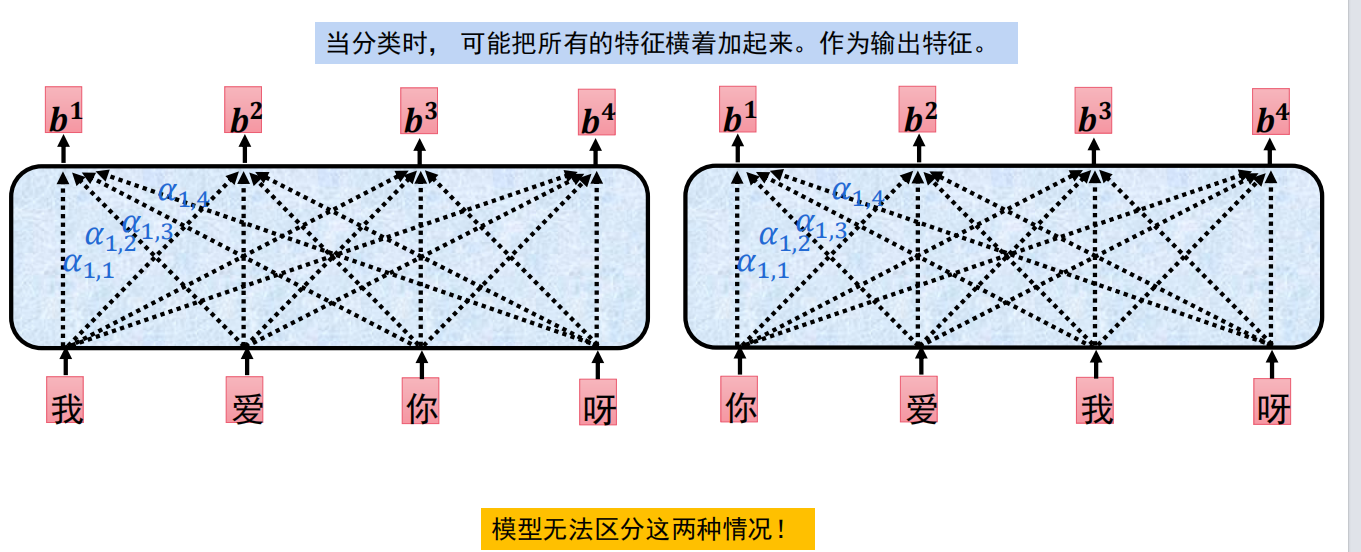
而加上位置编码后,就可以有以下好处:1恢复语序信息 。2帮助理解依赖关系。3让自注意力“有序化”
所以,input=词嵌入+位置编码
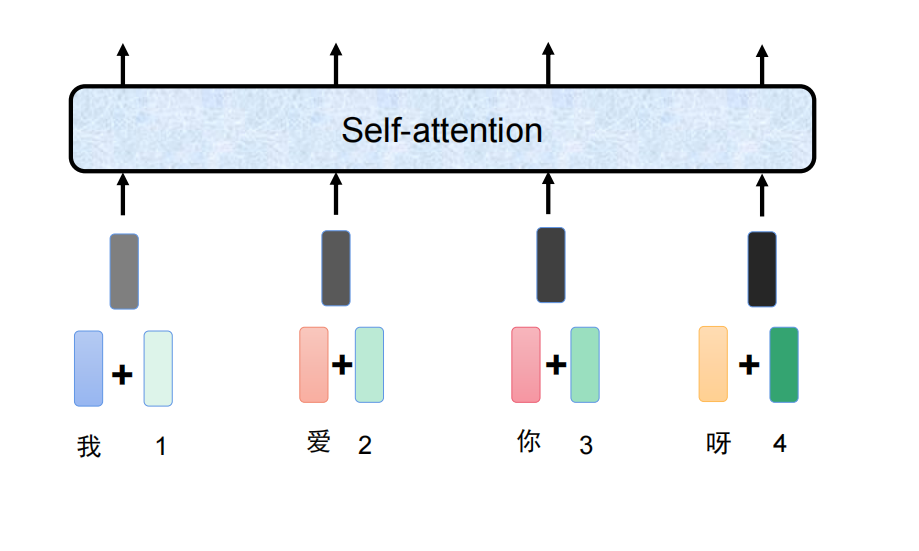
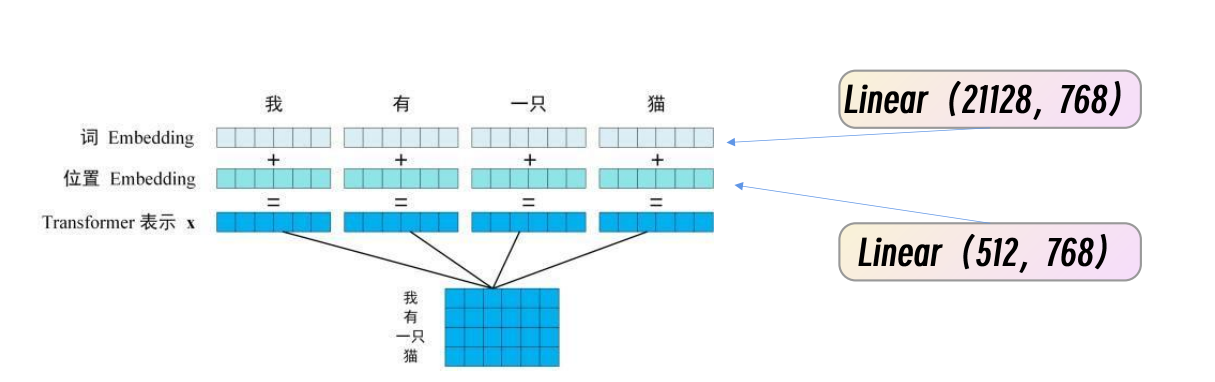
而其实每一个字分出来的词嵌入,位置编码,自注意力都是一个Token
Token(令牌 / 标记) 是文本被模型处理的最小基本单位,也是模型理解语言的 “原子”—— 简单说,模型不会直接认汉字 / 英文单词,只会认拆分后的 Token。
这样模型拿到数据后,就把一个个词切分为多个Token,然后通过这些token去认识和训练这些词。 比如,词嵌入的Token就是一个词典,在词典中通过id找出对应的词的信息。位置编码的Token就哪些是有效字,哪些是无效字,且会为每个字的位置编号。
五.Bert
Bert 就是用 Transformer 的 Encoder 部分做出来的预训练模型,专门做理解类任务:分类、匹配、抽取、问答等。
它是一个 “超级会理解中文 / 英文” 的预训练模型,它的核心:一句话里,每个字都能看懂左右两边的上下文。
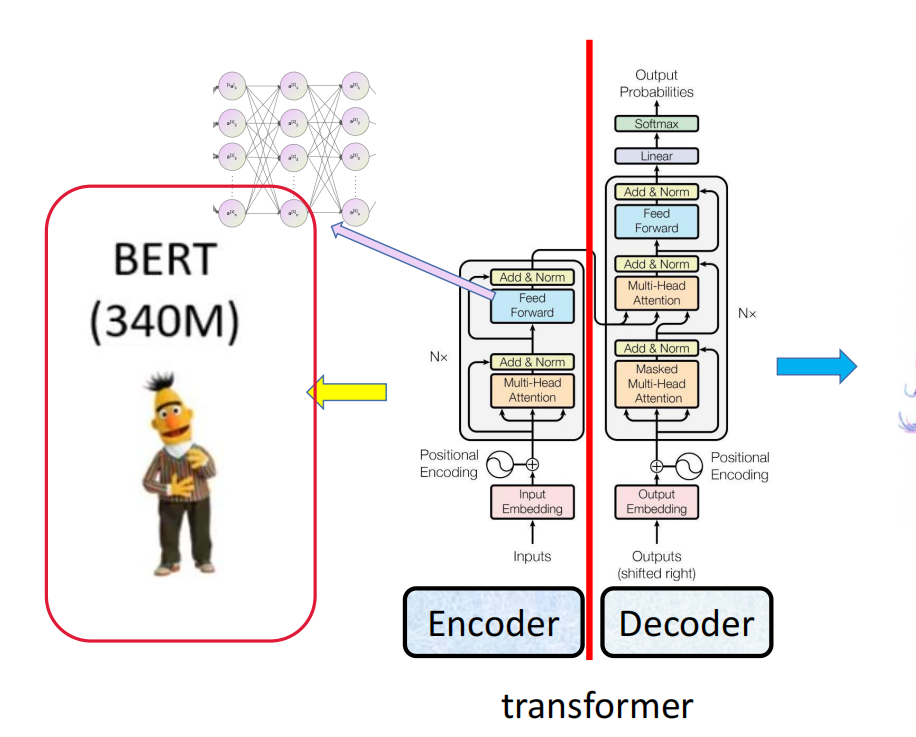
BERT 的核心优势(为什么能胜任这些任务)
- 双向上下文建模:基于 Transformer 的多头自注意力,能捕捉任意位置词的双向关联,远超 LSTM/BiLSTM;
- 预训练 + 微调范式:预训练阶段学习通用语言规律,微调阶段只需少量标注数据就能适配特定任务,降低标注成本;
- 可扩展性强:有丰富的变体(如 RoBERTa、ALBERT、SpanBERT),可针对不同场景优化(比如长文本、小数据、实体识别);
- 开源生态完善:Hugging Face、TensorFlow/PyTorch 都有成熟实现,中文有专门的 bert-base-chinese 版本,开箱即用。
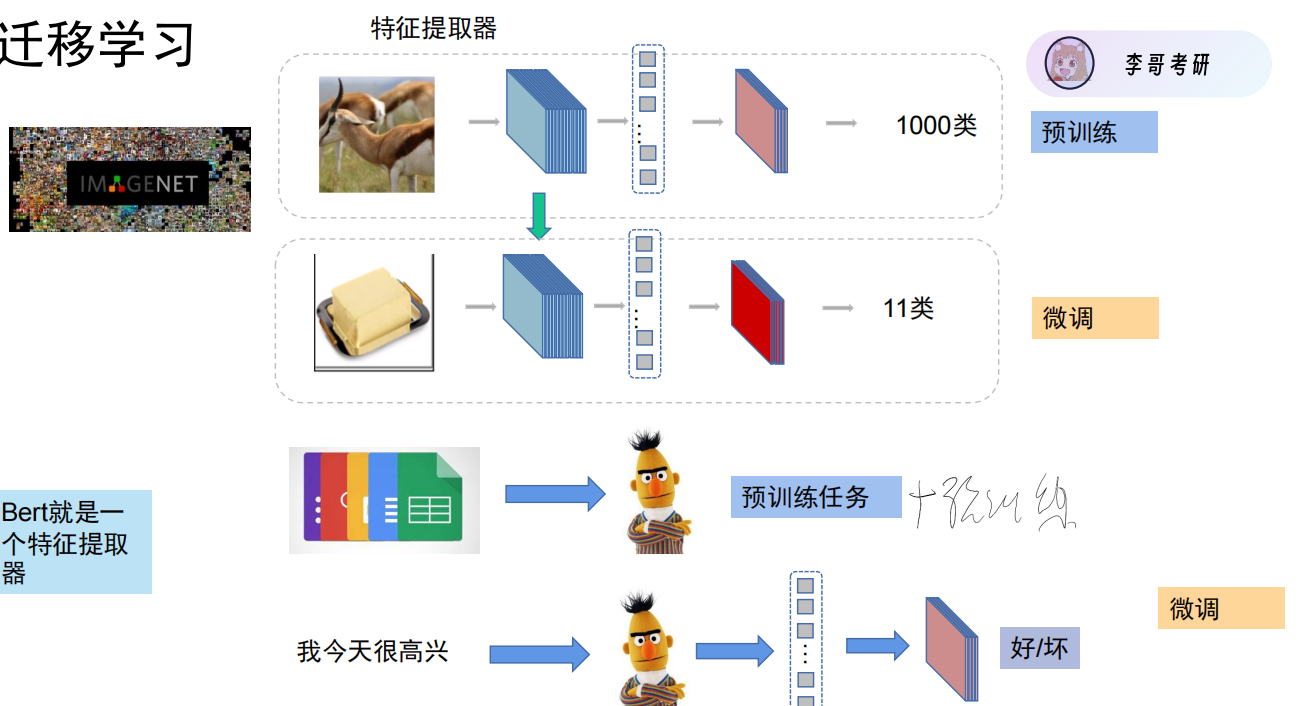
由于上游预训练任务需要大量数据才能训练出性能较好的模型,所以可以借用别人预训练好的模型,自己再做一点下游的微调训练,就可以让该模型适应我们的任务。(这就是迁移学习)
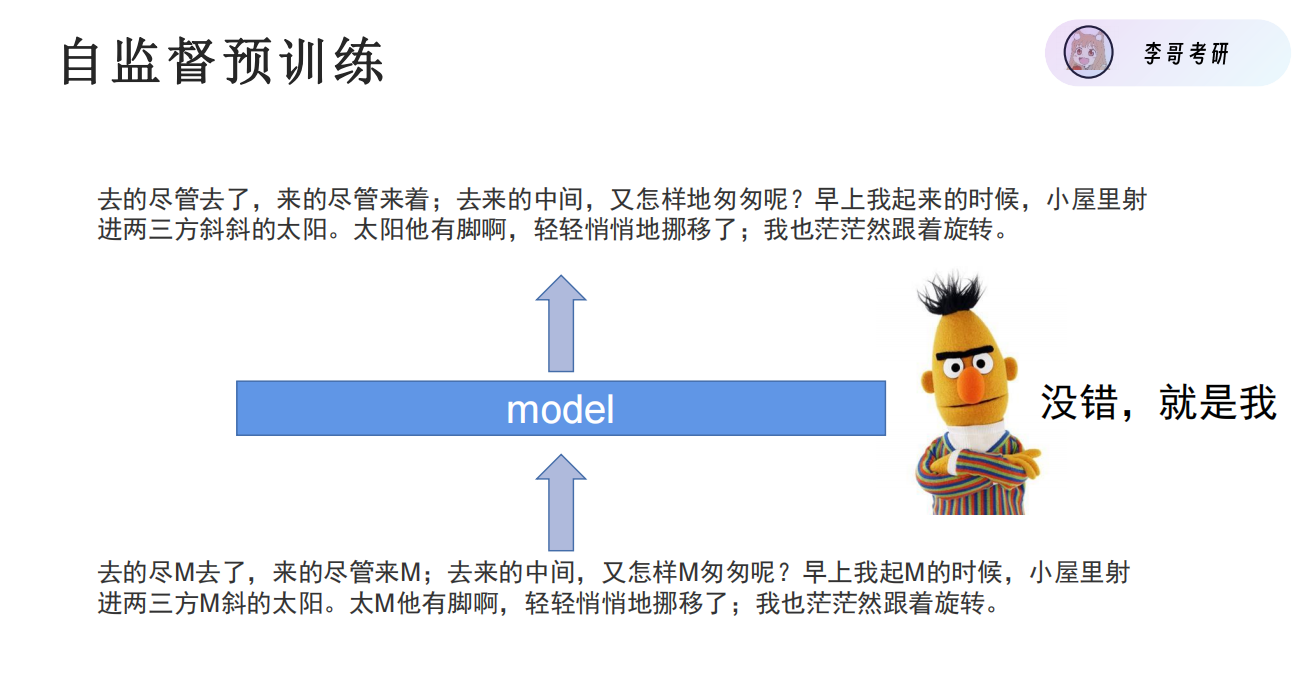
Bert主要用的是自监督预训练,通过MLM与NSP对模型进行预测与loss的回传训练
MLM 的核心思想是:
- 对输入文本随机掩盖(Mask)一部分 Token;
- 让模型基于被掩码 Token 的「前文 + 后文」(双向上下文)预测这个被掩盖的 Token 是什么;
- 通过大量这类 “完形填空” 任务,让模型学习到语言的语义、语法、上下文关联等通用规律。
NSP 任务的本质是:给模型输入两个句子(Sentence A + Sentence B),让模型判断 Sentence B 是否是 Sentence A 在原始文本中的真实下一句(二分类任务:0 = 是真实下一句,1 = 不是)。
六.Bert结构
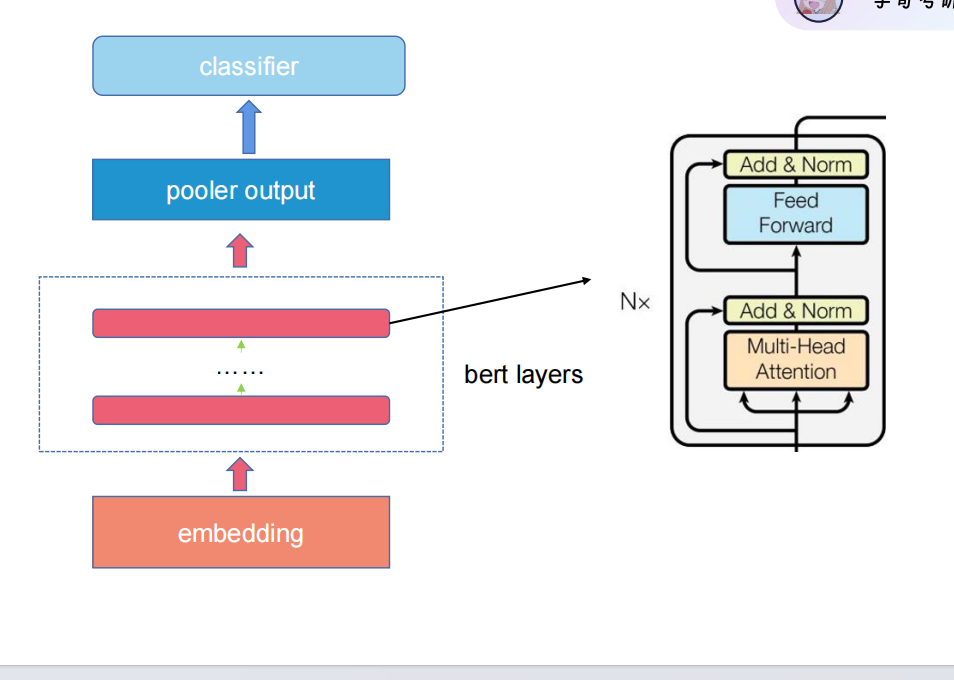
1.输入层(embedding 层)
把每个词切分为token. 让token经过分词器分成
-
- Token Embedding:词的语义信息。
- Segment Embedding:区分两个句子(用于句子对任务)。
- Position Embedding:位置信息,解决 Transformer 无序的问题。
- 三者相加,得到最终输入向量。
2.Transformer Encoder 层
模块 1:多头自注意力层(核心)
这是 Encoder 层的核心,负责捕捉序列中任意两个 Token 之间的双向语义关联(比如 “它” 和 “苹果” 的指代关系)。
- 输入:每个 Token 的向量(维度
d_model,比如 512); - 输出:每个 Token 融合了全序列上下文的向量(维度仍为
d_model); - 关键细节:
- 采用「自注意力」(Q=K=V,自己和自己计算注意力);
- 多头并行计算,捕捉多维度语义关联;
- 加入「注意力掩码(Padding Mask)」,忽略补全的
[PAD]Token,避免无效计算。
模块 2:前馈神经网络(FFN)
对每个 Token 的向量做独立的非线性变换(各 Token 之间无交互),提升模型的语义表达能力。
- 结构:两层全连接 + ReLU 激活(中间维度通常是
4*d_model,比如 2048); - 公式:
FFN(x) = max(0, x·W1 + b1)·W2 + b2; - 作用:对自注意力层输出的上下文向量做 “精细化加工”,捕捉更复杂的语义特征。
残差连接 + 层归一化(稳定训练的关键)
- 残差连接:
x + SubLayer(x),解决深度模型的梯度消失问题(直接把输入加到子层输出上); - 层归一化:
LayerNorm(x + SubLayer(x)),将向量的均值 / 方差归一化,让训练更稳定; - 注意:Transformer 中所有子层的输入 / 输出维度必须一致(均为
d_model),才能做残差连接。
3.输出层
[CLS]位置向量:BERT 等模型在序列开头添加的特殊 Token([CLS]),其输出向量融合了整个序列的全局语义,适合句子级任务(如文本分类、NSP);- Token 级向量:Encoder 层输出的每个普通 Token 的语义向量,适合词 / Token 级任务(如 NER、MLM、词性标注)。
本质是通过池化,让768的维度(词的向量长度)更加规整,输出成一个符合分类任务的向量,就通过一次池化来规整。
七.Bert与GPT的区别
| 对比维度 | BERT(Bidirectional Encoder Representations from Transformers) | GPT(Generative Pre-trained Transformer) |
|---|---|---|
| 核心架构 | Encoder-only(仅 Transformer 编码器) | Decoder-only(仅 Transformer 解码器) |
| 上下文建模方式 | 双向上下文(同时看前文 + 后文) | 单向自回归(仅看前文,从左到右生成) |
| 预训练核心任务 | MLM(掩码语言模型)+ NSP(下一句预测) | CLM(因果语言模型 / 自回归语言模型) |
| 核心能力 | 强于自然语言理解(NLU) | 强于自然语言生成(NLG) |
| 输入输出特点 | 输入完整文本,输出语义向量(无生成能力) | 输入前缀文本,输出续写的文本序列 |
| 注意力机制 | 多头自注意力(无掩码,可看到全序列 Token) | 多头自注意力(带未来 Token 掩码,仅看前文) |
| 典型应用场景 | 文本分类、NER、阅读理解、文本匹配、语义推理 | 文本生成、对话机器人、代码生成、机器翻译 |
| 代表模型版本 | BERT-base/-large、RoBERTa、ALBERT、SpanBERT | GPT-1/2/3/4、LLaMA、ChatGLM、文心一言 |
| 训练目标本质 | 填空式学习(还原掩码 Token) | 续写式学习(预测下一个 Token) |
实战
本次训练主要针对模型的下游训练
导入库函数

数据处理

把数据数据的标签和X分开

1说明是好评,后面的文本数据是X
(细节,由于数据是前4000多条全是好评,而后3000余条是坏评,所有要将这些评论打散后才能喂给模型训练,否则模型会偷懒)【shuffle=True就是要求数据打散的】

要把数据打包成一批数据,用一批数据拿去模型训练。
模型导入和微调
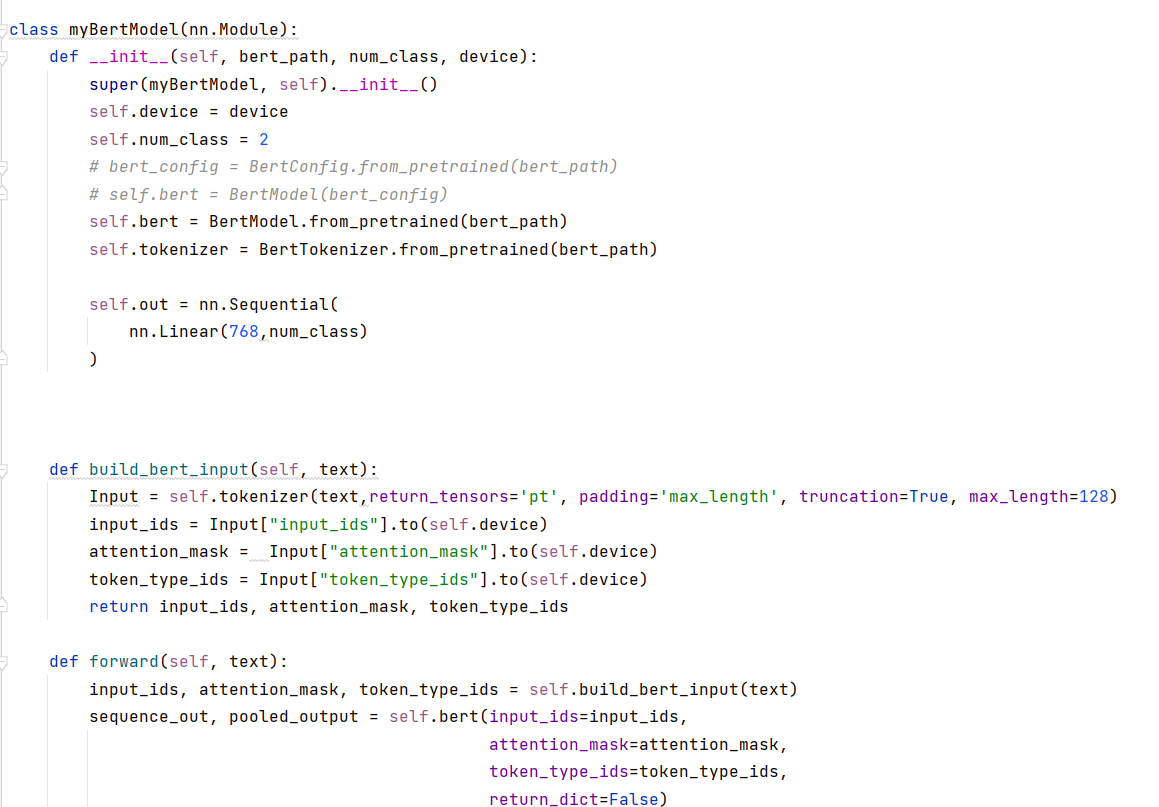
由于模型主要是做下游任务,所以只需要导入Bert模型后,把X数据导入模型中,最后做一个分类头的输出即可。
超参数的设置
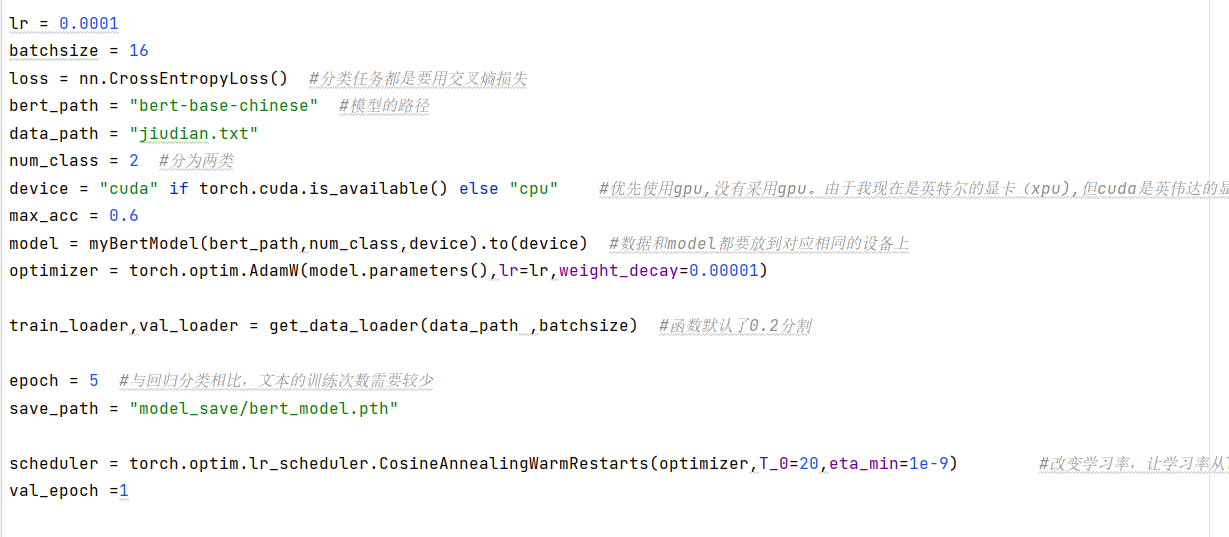
预训练模型(BERT):站在巨人的肩膀上,无需从零训练;
反向传播:loss.backward() + optimizer.step() 是参数更新的核心;
训练 / 验证模式:model.train()/model.eval() 区分训练和验证逻辑;(训练是有lable求loss的,然后要做梯度回传,而验证的就只用model输出预测值即可)

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 10
10 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)