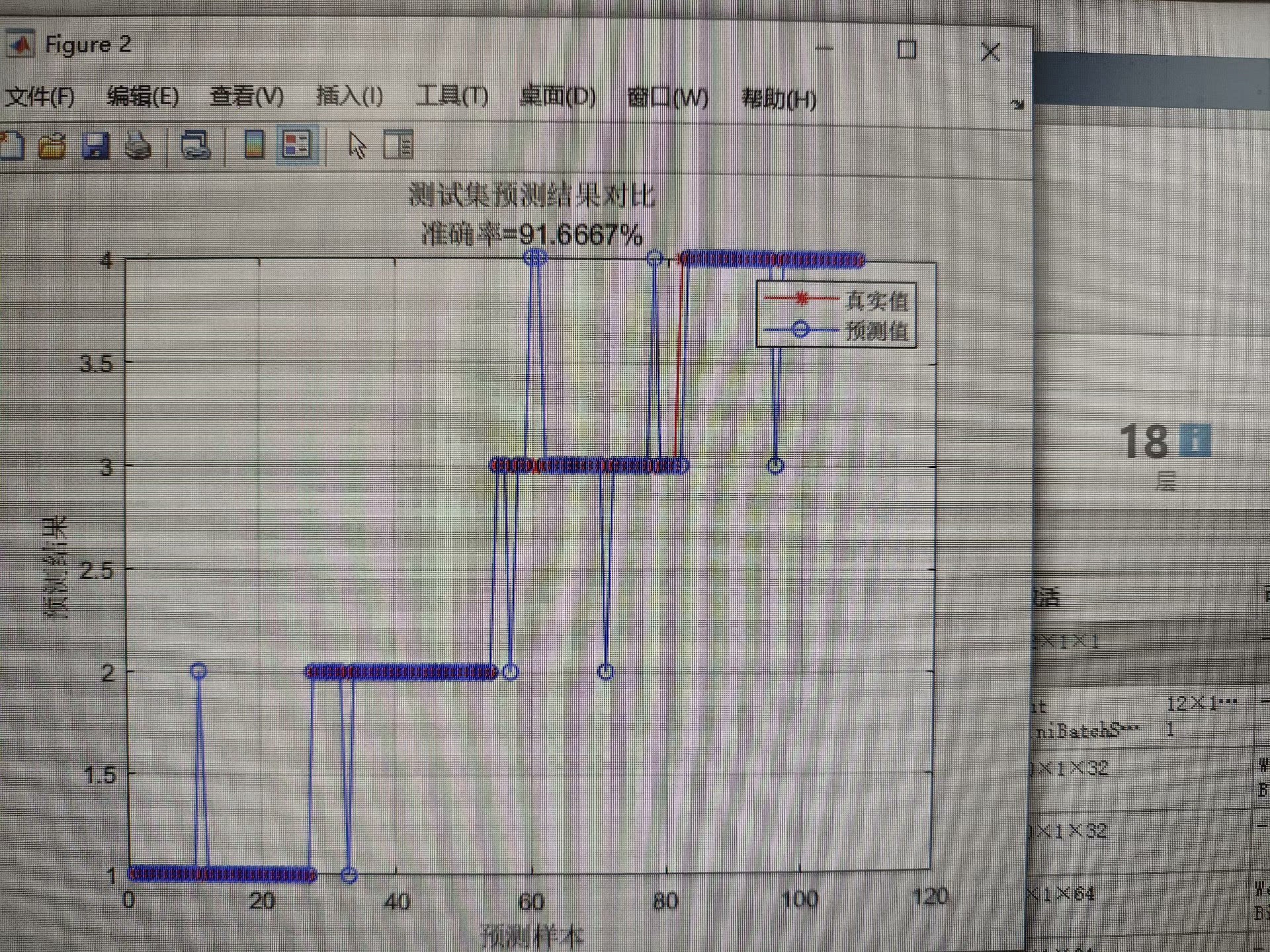
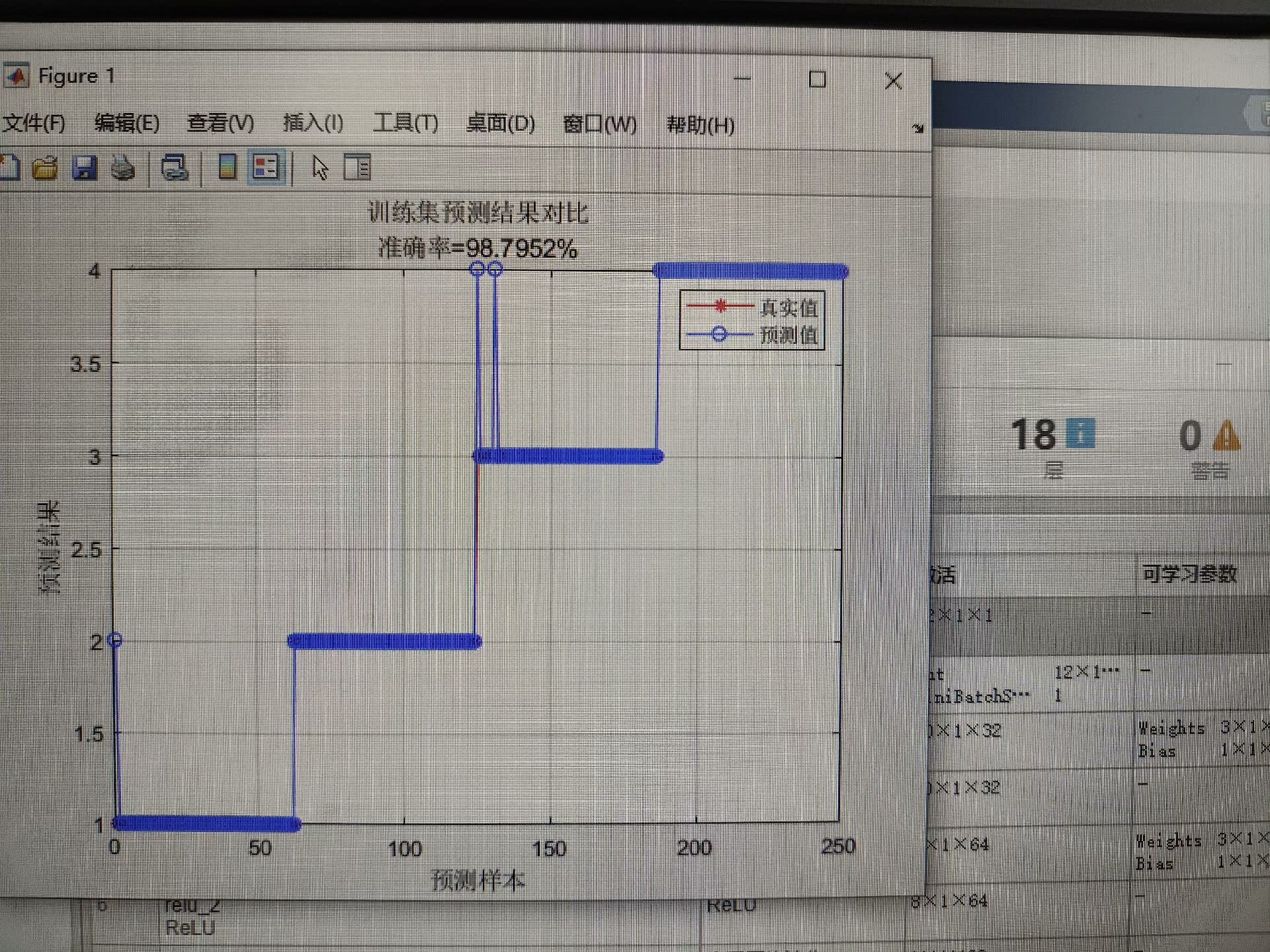
基于CNN-BiLSTM-SE注意力机制的数据分类预测基本流程(MATLAB环境实例)
基于卷积神经网络-双向长短时记忆网络结合SE注意力机制的数据分类预测(CNN-BiLSTM-SE) 基于MATLAB环境 替换自己的数据即可 基本流程:首先通过卷积神经网络CNN进行特征提取,然后通过通道注意力机制SE对不同的特征赋予不同的权重,最后通过双向长短时记忆网络BiLSTM进行分类预测
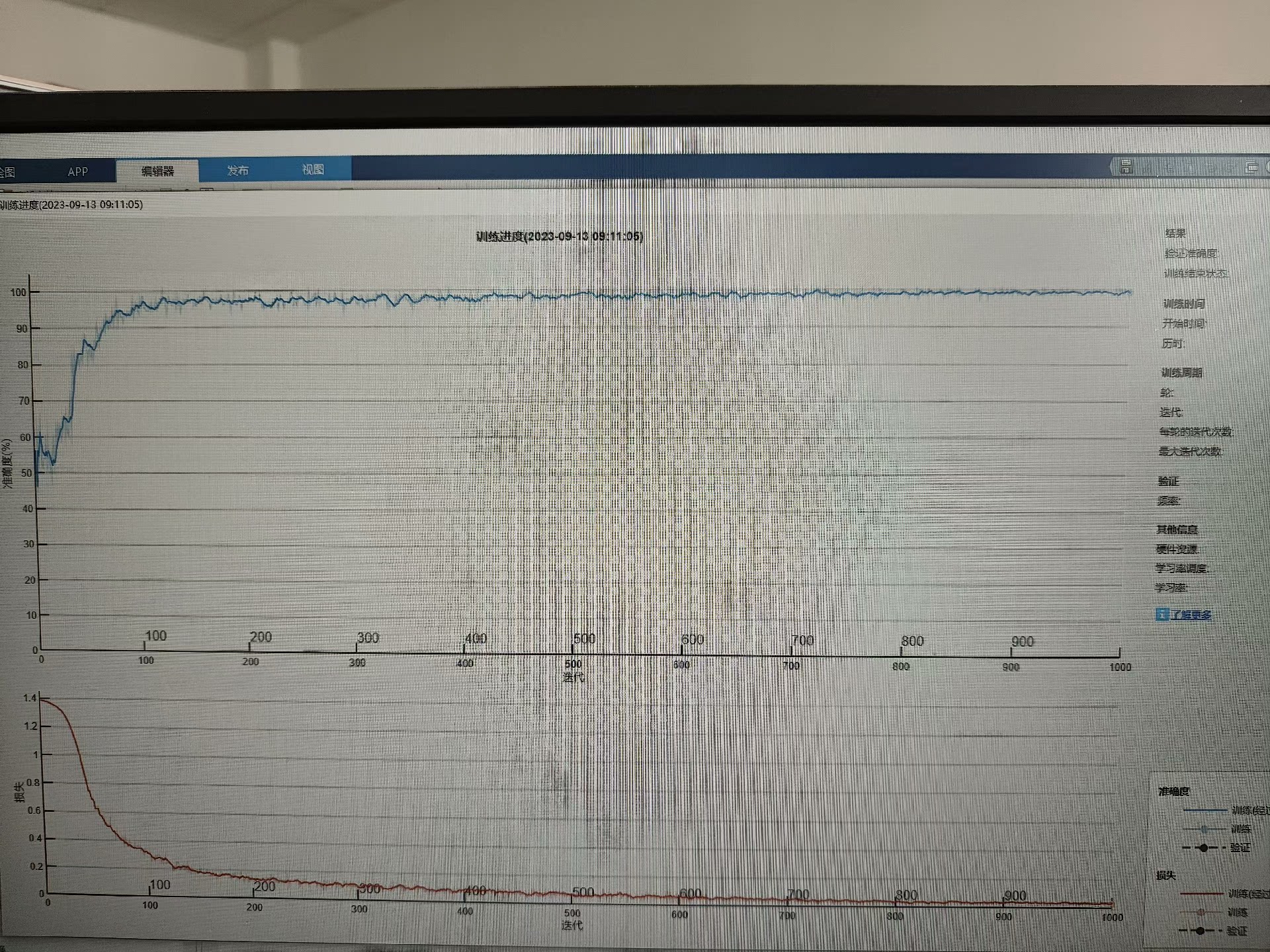
最近在研究数据分类预测的问题,发现卷积神经网络(CNN)结合双向长短时记忆网络(BiLSTM)再加一个通道注意力机制(SE),效果还挺不错的。于是决定把这个思路整理一下,顺便写个简单的流程,方便大家参考。
模型整体思路
这个模型的基本思路是:特征提取 → 注意力权重调整 → 分类预测。具体来说:
- CNN 先对数据做特征提取,特别是对于高维数据(比如图像或时序数据)来说,CNN擅长提取空间或时间上的局部特征。
- SE注意力机制 对提取到的特征进行优化,通过动态调整每个通道的权重,让模型更关注重要的特征。
- BiLSTM 最后负责分类预测,因为它能捕捉到特征的时间依赖性,尤其是在序列数据上表现更好。
第一部分:CNN特征提取
首先,我们用CNN对输入数据进行特征提取。这里的输入可以是任何适合CNN处理的数据,比如图像、时序数据等。举个简单的例子,假设我们有一个序列数据集,可以先把它 reshape 成适合CNN处理的格式。比如,假设输入数据是 batchsize × timestep × feature,那我们可以把它 reshape 成 batchsize × timestep × 1 × feature,然后用二维卷积层提取特征。
% 假设输入数据是 data,维度为 batch_size × time_step × feature
data_reshaped = reshape(data, size(data,1), size(data,2), 1, size(data,3));
% 定义一个简单的CNN层
conv_layer = convolution2dLayer(3, 32, 'Padding', 'same', 'Activation', 'relu');
pool_layer = maxPooling2dLayer([2, 2], 'Stride', [2, 2]);
feature_map = forward(conv_layer, data_reshaped);
feature_map = forward(pool_layer, feature_map);这里用了一个3x3的卷积核,提取32个特征图,然后用最大池化层进一步压缩特征图的维度。这一步的作用是提取数据中的高层次特征。
第二部分:SE注意力机制
接下来,我们需要对提取到的特征进行权重调整。SE注意力机制可以动态地增强重要的通道特征,抑制不太重要的通道特征。
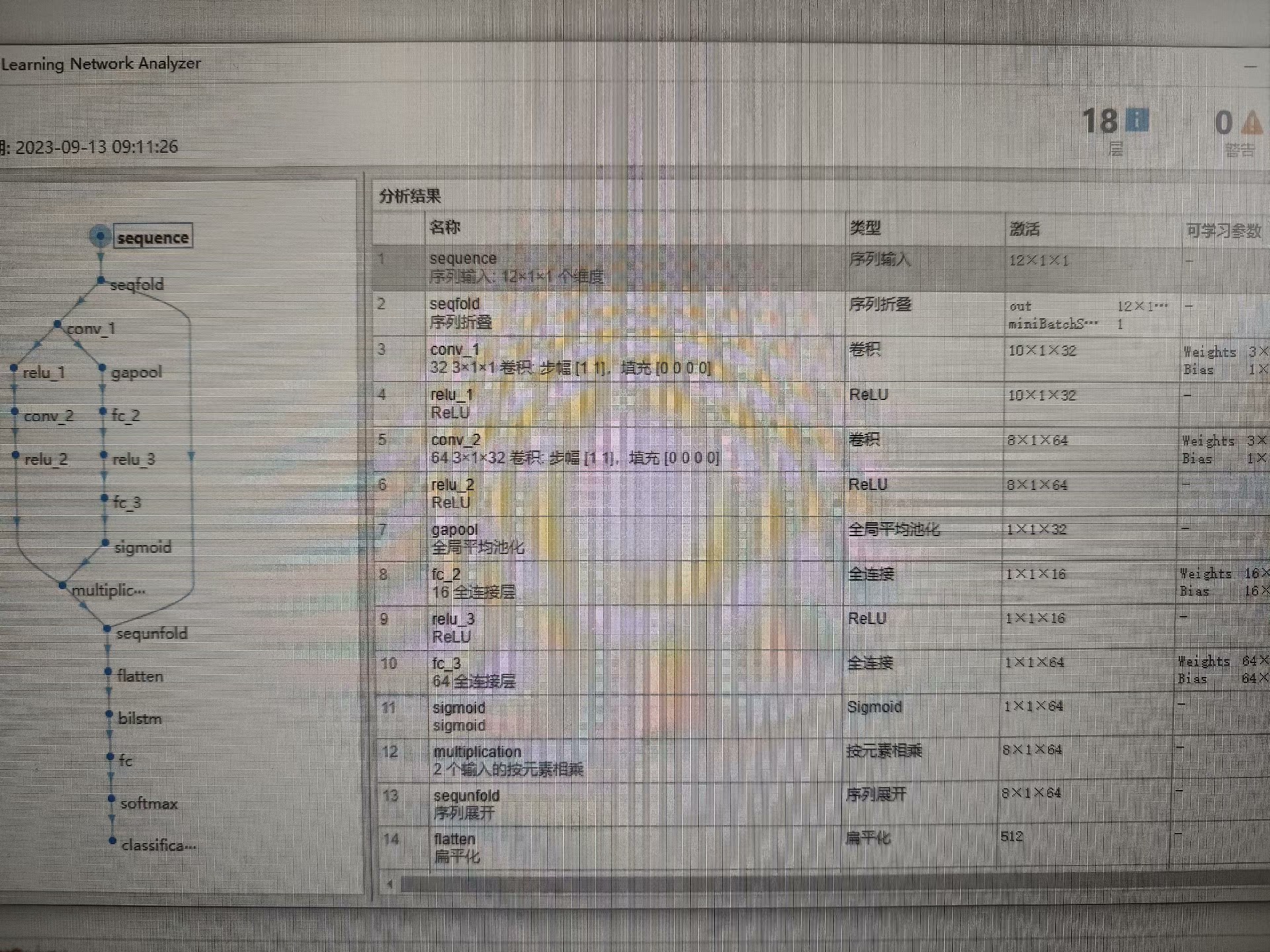
基于卷积神经网络-双向长短时记忆网络结合SE注意力机制的数据分类预测(CNN-BiLSTM-SE) 基于MATLAB环境 替换自己的数据即可 基本流程:首先通过卷积神经网络CNN进行特征提取,然后通过通道注意力机制SE对不同的特征赋予不同的权重,最后通过双向长短时记忆网络BiLSTM进行分类预测
SE机制的流程是:先通过全局平均池化将每个通道的特征压缩成一个标量,然后通过两个全连接层(全连接层的参数通常很少)得到每个通道的权重,最后将这些权重乘以原始特征。
% 假设当前特征是 feature_map,维度为 batch_size × h × w × channels
global_avg = mean(feature_map, [2, 3]); % 全局平均池化
squeezed = reshape(global_avg, size(global_avg,1), size(global_avg,2)); % 维度调整
% 定义两个全连接层
fc1 = fullyConnectedLayer(size(squeezed,2)/2, 'BiasLearnRateFactor', 0);
fc2 = fullyConnectedLayer(size(squeezed,2), 'BiasLearnRateFactor', 0);
attention = forward(fc1, squeezed);
attention = relu(attention); % 添加激活函数
attention = forward(fc2, attention);
attention = sigmoid(attention); % 通过sigmoid归一化权重
% 将注意力权重应用到特征
attention = reshape(attention, size(feature_map,1), 1, 1, size(feature_map,4));
enhanced_feature = feature_map .* attention;这段代码中,squeezed 是全局平均池化后的结果,经过两次全连接层和激活函数,得到每个通道的注意力权重(attention)。最后用这些权重乘以原始特征,得到增强后的特征图 enhanced_feature。
第三部分:BiLSTM分类预测
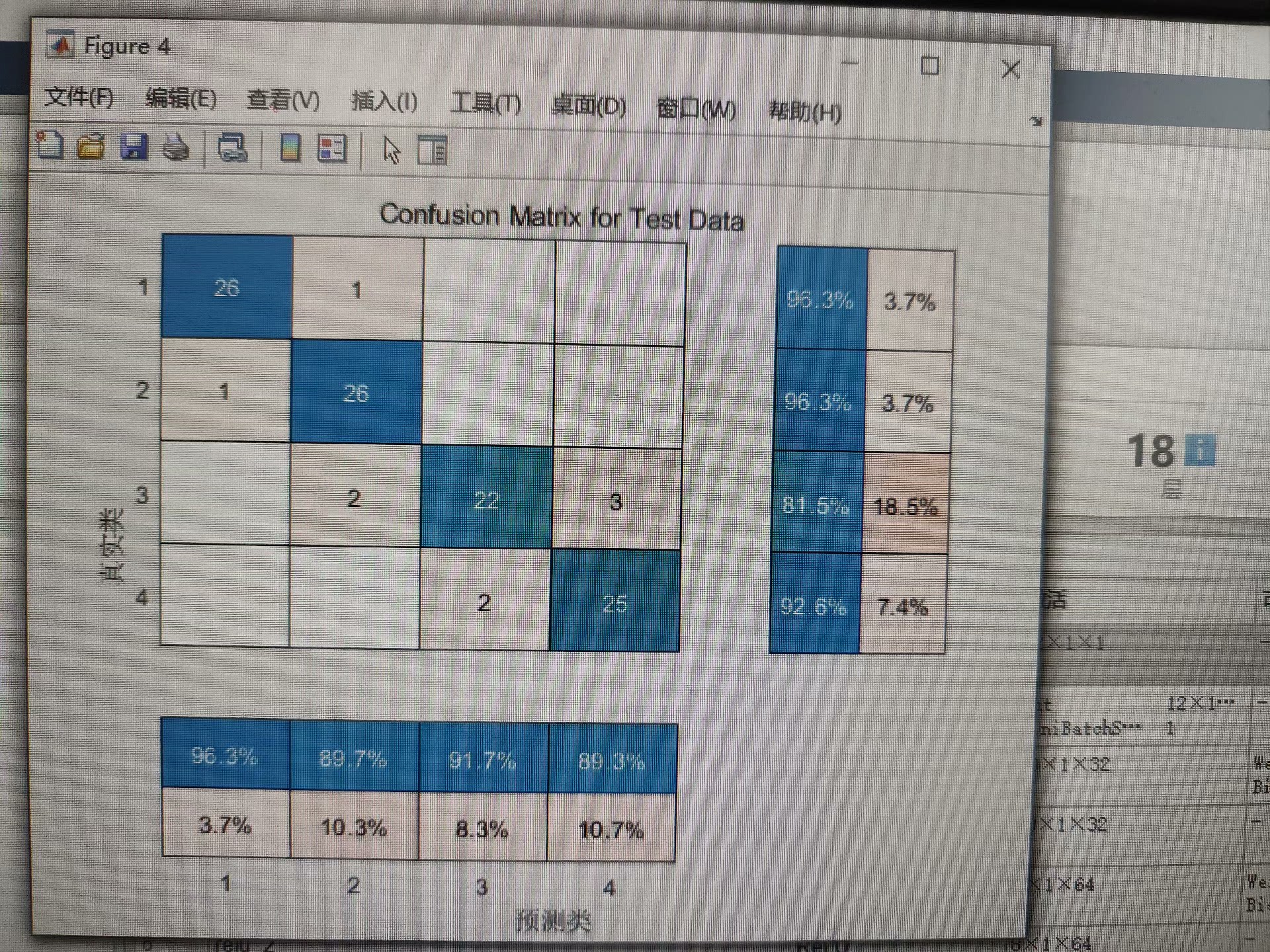
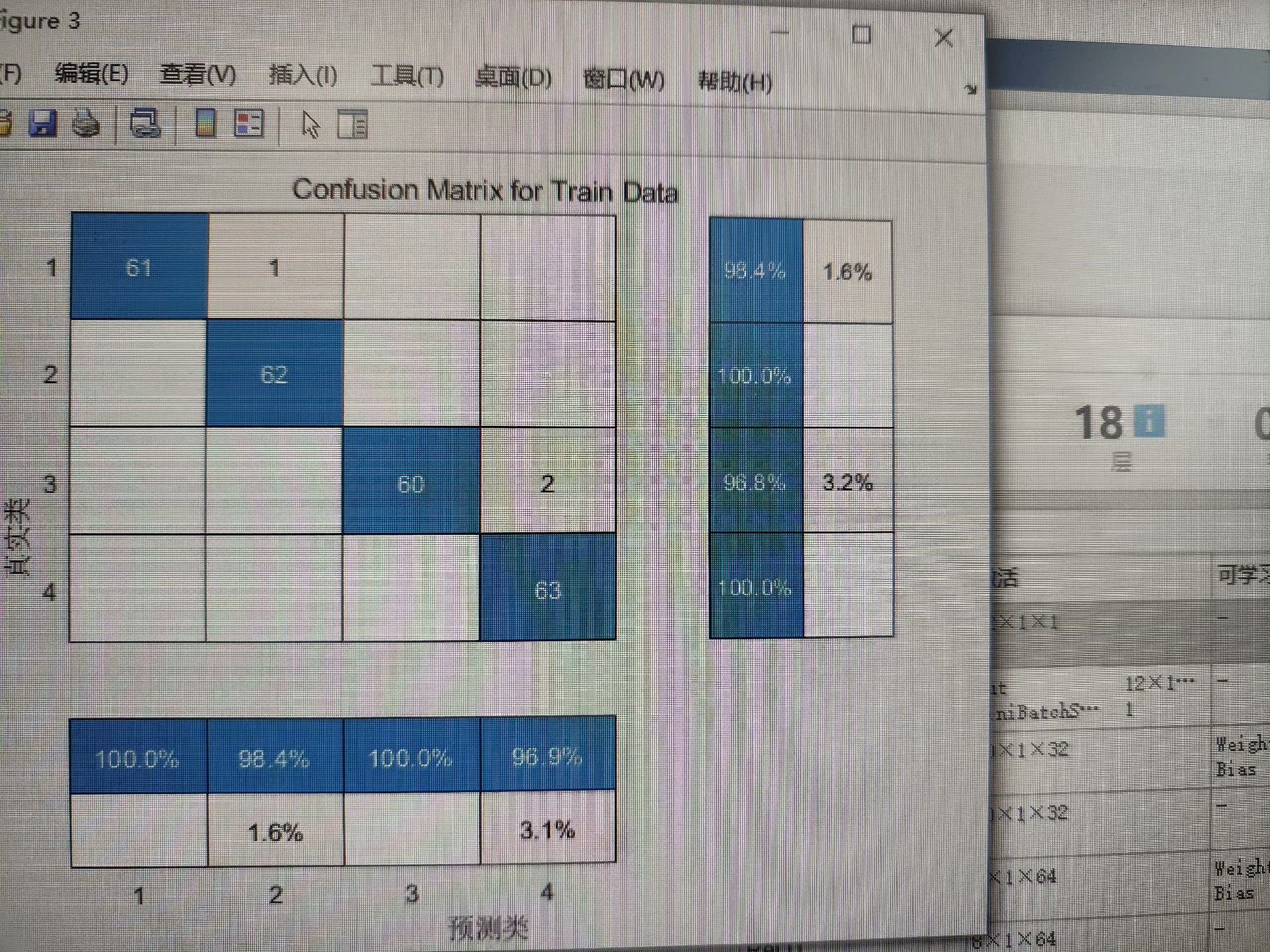
经过SE注意力机制调整后的特征,最后需要输送到分类器里进行预测。这里用了BiLSTM,因为它可以同时捕捉到正向和反向的时间依赖性,非常适合处理序列数据。
% 假设当前特征是 enhanced_feature,先把它 reshape 回适合LSTM的格式
% LSTM的输入格式一般是 batch_size × time_step × feature
% 假设我们有 N 个时间步,M 个特征
feature_sequence = reshape(enhanced_feature, size(enhanced_feature,1), size(enhanced_feature,2), size(enhanced_feature,3)*size(enhanced_feature,4));
% 定义一个双向LSTM层
bilstm = bilstmLayer(numHiddenUnits, 'SequenceOutput', true);
[output, ~] = forward(bilstm, feature_sequence);
% 分类器
fc = fullyConnectedLayer(numClasses);
scores = forward(fc, output);
% 得到预测结果
[_, predicted] = max(scores, 2);这里,numHiddenUnits 是LSTM的隐藏层单元数,numClasses 是类别数。通过双向LSTM处理后,再经过一个全连接层得到最终的分类分数。最后,取每行的最大值对应的索引作为预测结果。
整体流程总结
整个流程可以分为以下几步:
- 数据预处理:加载数据,归一化或标准化。
- 特征提取:用CNN提取高阶特征。
- 注意力机制:用SE机制调整特征权重。
- 序列建模:用BiLSTM捕捉时间依赖关系。
- 分类预测:用全连接层进行最终分类。
结语
这个模型的好处是融合了CNN的特征提取能力、SE机制的注意力优化,以及BiLSTM的时间依赖建模能力。在某些场景下,比如时序数据分类(如ECG分类、股票预测等),效果可能会比单独使用CNN或LSTM更好。当然,具体的超参数和网络结构还需要根据实际数据进行调整。如果你有其他问题,欢迎交流~

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 1
1 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)