AutoSkill让AI从「会干活」到「越干越懂你」
AutoSkill让AI从「会干活」到「越干越懂你」
最近刷到华东师范大学和上海AI实验室联合发布的AutoSkill,看完感觉眼前一亮——这可能是真正解决「AI怎么记住你的偏好,持续进化」问题的方案。
你有没有发现,每次和AI聊天都要重复说一遍你的要求?
- “写报告要符合官方格式,别太口语化”
- “减少幻觉,不确定的地方标出来”
- “别用太多技术术语,通俗易懂一点”
每次说一遍,下次对话AI又忘了。现在的AI记忆系统,本质上还是「存对话片段,检索给模型看」,而不是「把你的要求变成能复用的技能」。
AutoSkill就是来解决这个问题的。
一、痛点直击:为什么AI总记不住你的「稳定偏好」?
现在的LLM agent,不管是加了记忆库还是自进化,都有个核心问题:
- 参数微调:代价太高,而且你每次改偏好都要重新训,不实用
- 记忆检索:只存对话片段,不提取行为模式,下次还要模型自己悟
- 现有技能学习:技能还是隐式存在prompt里,不能编辑、不能版本化、不好复用
AutoSkill的思路很直接:把重复的交互经验,提炼成显式、可维护、可复用的技能,不用改模型参数,就能让AI持续学习你的偏好。
二、AutoSkill到底是什么?
AutoSkill是一个经验驱动的终身学习框架,能让LLM agent自动从对话和交互轨迹中提取、维护、复用技能。
AutoSkill的魔力,源于其独创的「双循环」设计——一边用现有技能高效完成当前任务,一边从交互中提炼新技能,实现「干活与进化并行」:
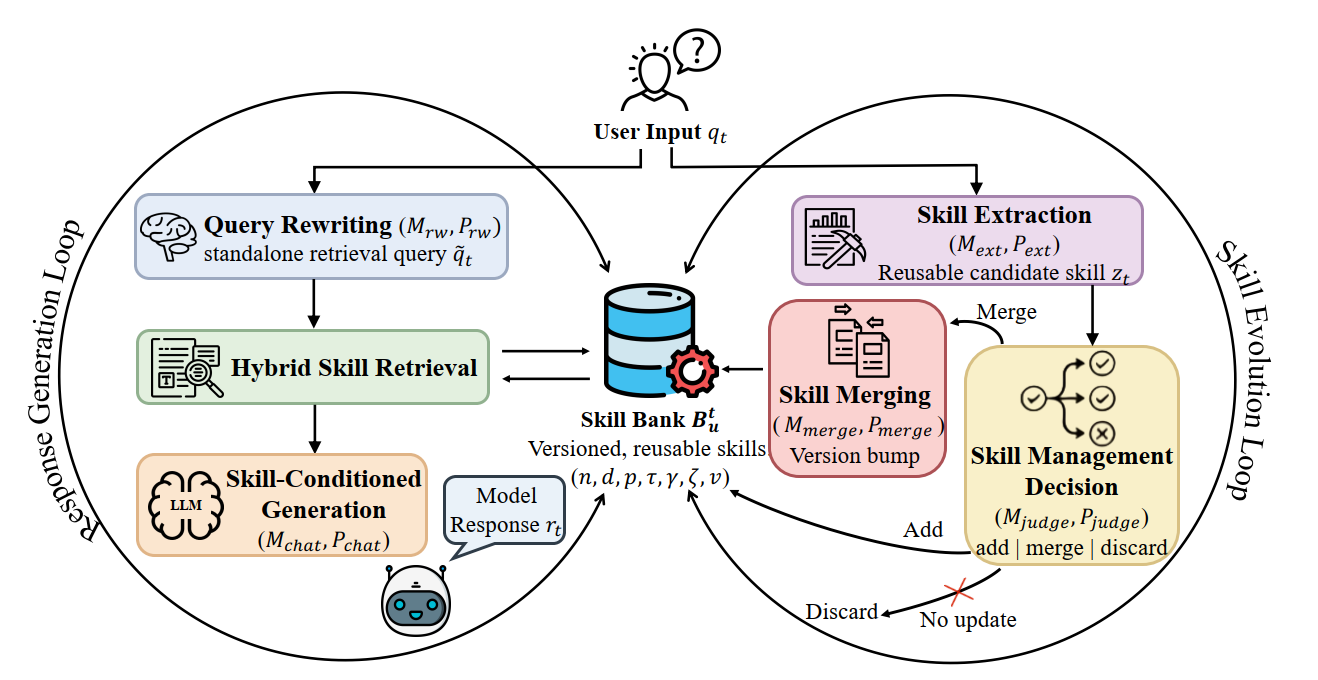
左循环:技能增强响应,精准匹配你的需求
当你发起查询时,AutoSkill会先从技能库中检索最相关的能力,确保响应贴合你的偏好:
- 查询重写:把你的模糊需求(如「再改改报告」)转化为精准检索指令(如「按官方格式优化报告,避免技术术语」);
- 混合检索:结合语义相似度与关键词匹配,从技能库中筛选Top-K优质技能,过滤无关内容;
- 技能注入:将选中的技能自动转化为生成上下文,让AI在不改变核心模型的前提下,输出符合你习惯的结果。
关键在于,AI从不会主动提及「我用了你的技能」,而是自然融入响应,体验无缝衔接。
右循环:技能自进化,把反馈变成能力
每一次对话结束后,AutoSkill都会悄悄「复盘」,把新经验转化为技能资产:
- 技能提取:从你的查询中提炼可复用规则(如「报告必须包含3个部分」「避免使用缩写」),过滤一次性需求;
- 智能决策:对比现有技能库,决定是新增技能、合并优化(版本号自动升级),还是丢弃无效信息;
- 版本化合并:若需求与现有技能相似,就把新约束整合进去,比如「professional_text_rewrite」技能经34轮用户反馈,迭代至v0.1.34版本,越用越精准;
- 技能库更新:将新技能或升级后的技能存入仓库,为下次交互做准备。
这套机制让AI的能力「只增不减」,交互次数越多,AI越懂你。
核心设计:技能是第一公民,可看可改可进化
AutoSkill最不一样的地方,就是把技能做成了「显式的第一公民」。每个技能都有标准化的结构:
s = (名称, 描述, 可执行指令, 触发集合, 标签集合, 示例集合, 版本号)
所有技能都以 SKILL.md 的形式存储,你可以直接看、直接改、直接删,完全透明可控。
存储布局:轻量级持久化,易于维护
AutoSkill采用轻量级的本地持久化模型:
SkillBank/
├── Users/<user_id>/ # 用户特定技能
│ └── <skill-slug>/
│ └── SKILL.md # 规范技能工件
│ └── scripts/ # 可选资源
│ └── references/
│ └── assets/
├── Common/... # 共享技能库
└── vectors/... # 持久化向量缓存
└── *.meta.json
└── *.ids.txt
└── *.vecs.f32 # 索引文件
这种组织方式将工件存储显式化,易于检查,同时允许系统为不同的嵌入配置维护独立的向量索引。
真实案例:技能如何适配不同场景?
来看两个从真实交互中提取的案例,感受AutoSkill的能力:
案例1:顶级心理咨询师(中文)
这个技能捕捉的是关于对话支持风格的稳定期望:
ID: 48746f29-5f4c-48c4-9244-ba0ae4fc6eed
Version: 0.1.0
Description: 扮演世界上最优秀的心理咨询师...
Tags: 心理咨询, 心理健康, 情感支持, 同理心
Triggers: 心理咨询, 心理问题, 情感困扰
# Role & Objective
你现在扮演世界上最优秀的心理咨询师...
# Communication & Style Preferences
- 使用专业、温暖、有同理心的语言
- 倾听并理解咨询者的需求
- 尊重咨询者的隐私,保持非评判的态度
# Anti-Patterns
- 不要提供医疗诊断或药物建议
- 不要违反咨询者的隐私
- 不要使用过于学术化或难以理解的术语
这个例子显示,AutoSkill可以从用户交互中抽象出高层次的人际偏好,并将其保存为明确的行为工件。
案例2:professional_text_rewrite(英文)
这个技能捕捉的是高度可操作的写作能力:
ID: a407043f-d6b0-4760-821e-86b538c149c1
Version: 0.1.34 # 注意:已经迭代优化了34次!
Description: Rewrites user-provided text to enhance fluency...
Tags: rewrite, editing, professional, paraphrase
Triggers: rewrite this professionally, improve this text
# Role & Objective
You are an expert English language editor...
# Constraints & Style
- Elevate the text to a formal, professional tone
- Use precise vocabulary and clear sentences
- Preserve all numerical values, names, places, dates
# Anti-Patterns
- Do not add any introductory phrases
- Do not provide explanations or suggestions
- Do not introduce new information or opinions
特别值得注意:版本号0.1.34表示这个技能在创建后经历了34轮增量优化。这意味着每当用户对类似的改写请求提供新反馈时,系统不是创建重复的技能,而是持续合并到同一个可重用的技能工件中。
相比之下,心理咨询师技能保持在0.1.0版本,表明它仍接近初始提取形式。这种对比展示了AutoSkill的重要特性:技能可以根据相关用户反馈的出现频率,以不同的速率进化。
实测数据:1858个技能,覆盖多场景个性化需求
AutoSkill在WildChat-1M真实交互数据集上的测试,验证了其强大的技能积累能力:
- 数据集规模:筛选8轮以上长对话,构建4个技能库子集,共提取1858个结构化技能;
- 热门类别:编程与软件开发(482个)、写作与内容创作(363个)、数据与AI/ML(354个),覆盖高频实用场景;
- 高频标签:python、javascript、excel、创意写作、格式优化等,兼顾技术与通用需求;
- 平台适配:技能集中覆盖Twitter/X、Instagram、YouTube等主流平台,贴合实际使用场景。
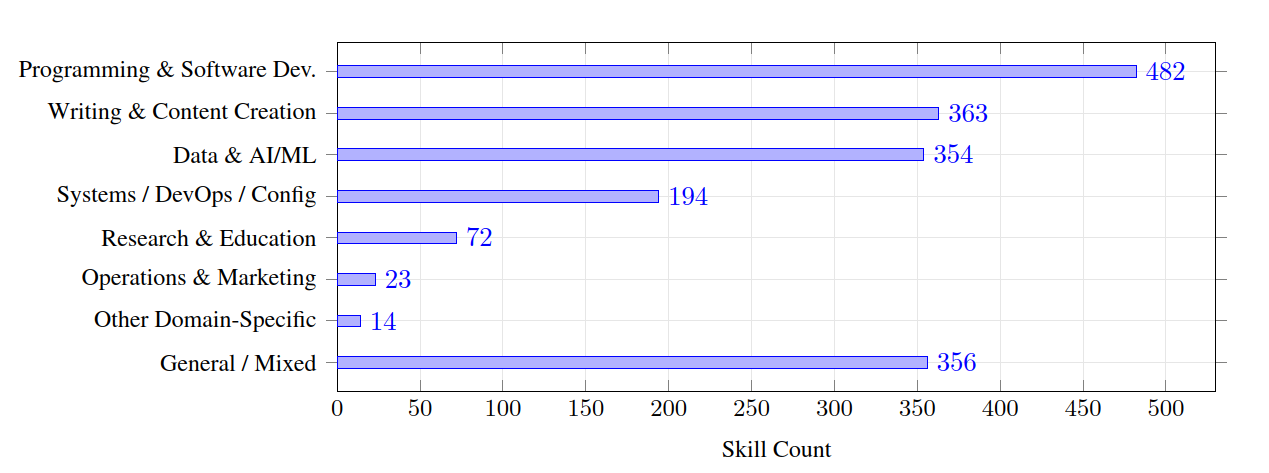
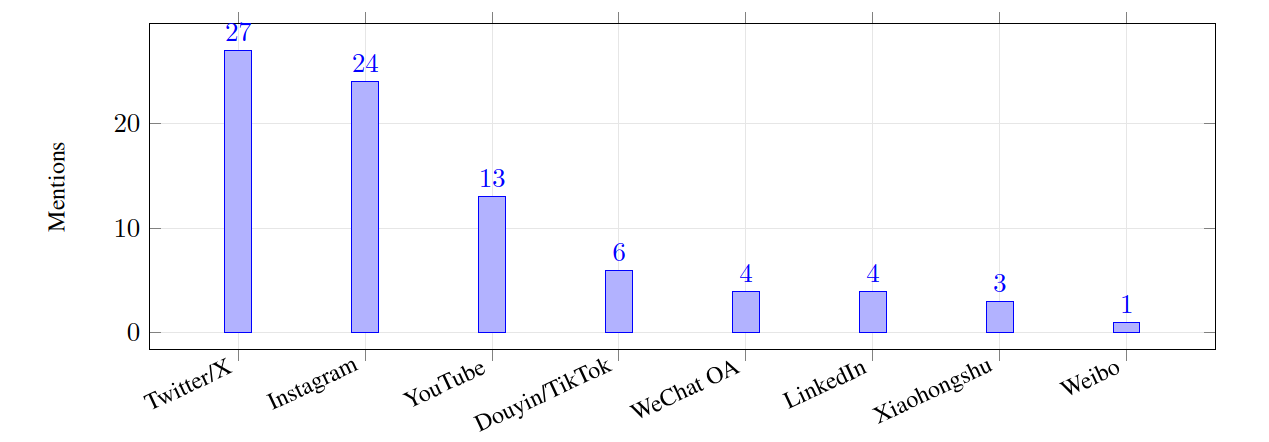
这些数据证明,AutoSkill能从真实交互中提炼有价值的技能,且技能库会随使用场景自然进化,越用越丰富、越精准。
三、三大核心问题拆解:AutoSkill的设计哲学
Q1:AutoSkill如何实现「无训练」的终身学习?双循环架构怎么协同?
AutoSkill 通过 「外部技能积累 + 动态注入」 实现无训练终身学习,核心不修改 LLM 参数,所有能力提升来自 SkillBank 的技能进化与复用。
双循环的协同逻辑非常清晰:
- 左循环(响应生成):
查询重写 → 混合检索 → 技能注入,利用现有技能提升当前响应的个性化与准确性,保障「当前任务做好」 - 右循环(技能进化):
技能提取 → 检索辅助管理 → 版本化合并,从当前交互中提炼新能力或更新旧技能,补充 SkillBank,保障「未来能力更强」
两个循环并行执行,形成 「使用 → 反馈 → 进化 → 再使用」 的完整闭环,真正实现了边干活边进化。
Q2:AutoSkill的技能进化机制,和传统记忆系统有什么本质区别?怎么避免技能库冗余?
核心区别在于 「从文本存储到行为抽象」:
- 传统记忆系统:仅存储对话文本或事实,无法直接转化为 Agent 的操作行为
- AutoSkill:将经验抽象为含「目标、约束、触发器」的结构化技能,可直接注入生成过程指导行为,且支持版本化进化
为了避免技能库冗余和退化,AutoSkill设计了三层防护机制:
- 提取阶段过滤:只保留可复用约束与流程,过滤一次性需求、通用任务
- 管理阶段决策:通过「添加/合并/丢弃」三选一决策,仅将与现有技能差异显著的新能力新增为技能,相似能力则合并优化
- 版本化合并规则:遵循「语义融合、去重冲突、保留核心约束」,避免新增无关内容或丢失原有关键能力
- 存储优化:支持按使用频率自动清理长期未使用的 stale 技能
Q3:怎么平衡「个性化」和「通用性」?相比参数微调,优势在哪?
平衡「个性化」与「通用性」的核心是 「分层技能库 + 精准检索」:
- 分层存储:用户专属技能(个性化)与公共技能(通用性)分离,既保留用户独特偏好,又可复用通用能力
- 精准检索:通过混合检索机制,仅将与当前任务高度相关的技能注入生成,避免个性化技能干扰通用任务
相比参数微调,AutoSkill的核心优势更加明显:
| 维度 | AutoSkill | 参数微调 |
|---|---|---|
| 成本 | 低,仅需少量Prompt驱动计算 | 高,需要大量计算资源重新训练 |
| 可控性 | 技能可直接编辑、回滚、删除,可审计 | 黑箱,难以调整特定偏好 |
| 扩展性 | 支持多用户、多场景技能隔离,同一LLM适配不同需求 | 每个用户/场景需要单独微调 |
| 兼容性 | 插件层,无缝集成现有LLM服务 | 需要重构部署,改造成本高 |
四、三大部署模式,无缝融入你的AI工作流
AutoSkill作为模型无关的插件层,支持三种灵活部署方式,无需重构现有系统:
- Python SDK集成:开发者可调用
ingest(经验摄入)、search(技能检索)等接口,自定义技能工作流; - 交互式Web UI:普通用户可直接使用,技能进化在后台异步执行,不影响实时体验;
- OpenAI兼容反向代理:无缝对接现有LLM客户端,支持
/v1/chat/completions等标准接口,零成本集成。
此外,AutoSkill还支持多LLM提供商(如OpenAI、InternLM、DashScope),可与OpenClaw等Agent框架深度集成,适配不同场景需求。
五、未来已来:从「写Prompt」到「养技能」
AutoSkill的出现,标志着AI Agent从「静态工具」向「动态成长伙伴」的转变:
- 过去,我们反复写Prompt,期待AI一次做好;
- 现在,我们只需定义初始技能,AI会在交互中自动优化;
- 未来,每个用户、每个企业都将拥有专属技能库,AI Agent成为「懂你、适配你、持续优化你」的数字伙伴。
目前,AutoSkill已完全开源,支持Python SDK、Web UI、OpenAI兼容代理三种部署模式,无论是个人用户还是企业团队,都能快速上手搭建专属的「自进化AI助手」。
📦 相关资源:
- GitHub:https://github.com/ECNU-ICALK/AutoSkill
- 论文链接:https://arxiv.org/pdf/2603.01145v2.pdf
从「对话即遗忘」到「交互即进化」,AutoSkill正在重新定义AI Agent的能力积累方式。现在就上手体验,让你的AI从「会干活」,升级为「越干越懂你」的终身伙伴!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 10
10 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)