关于comfyui的mmaudio音频生成插件时时间不一致问题(二)
继续,上一篇看到toml配置文件,接下来是文件夹里面的
configs
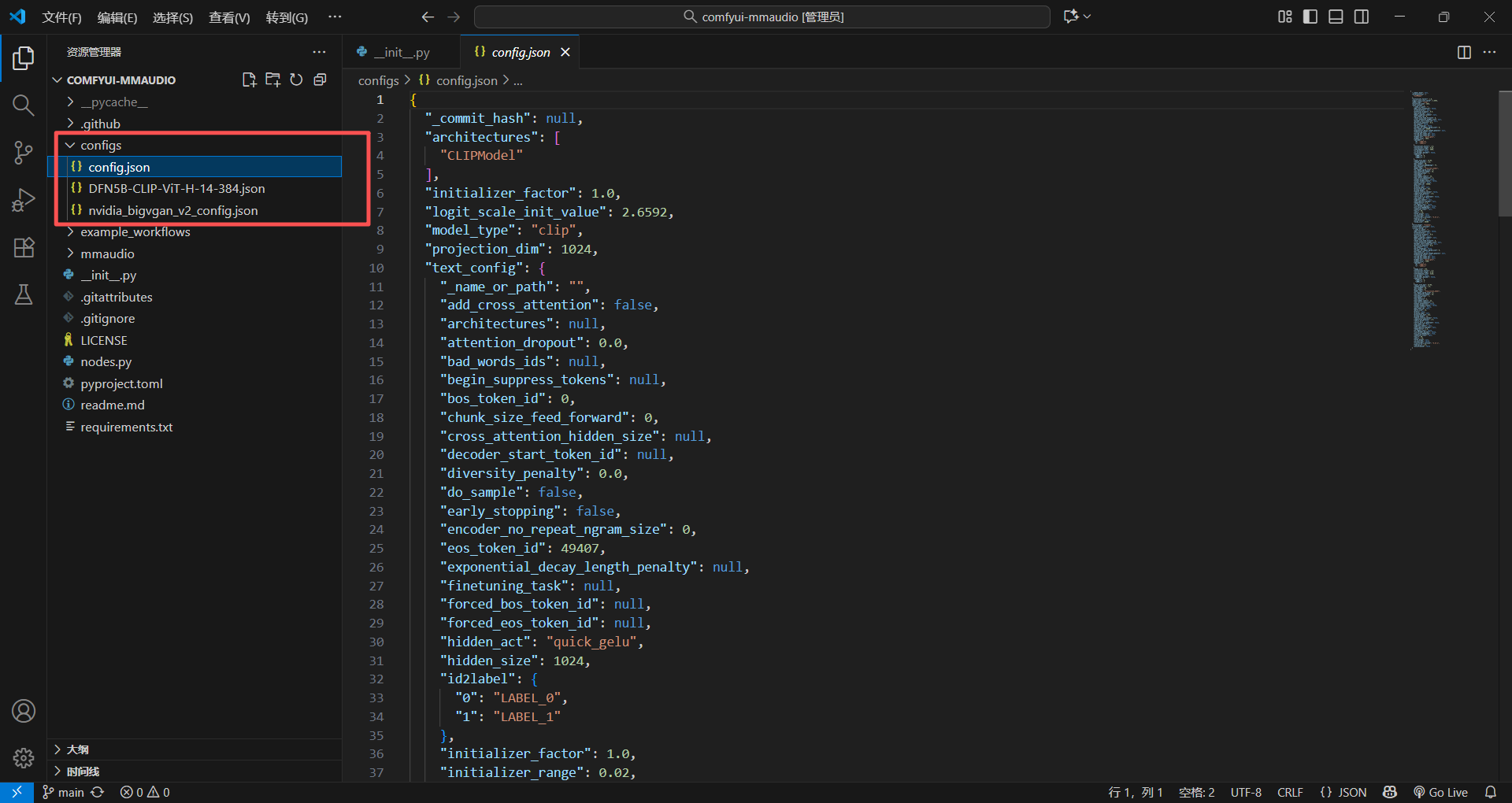
这里面的都是json文件,里面写的都是参数,一般这些都是那些底层包需要用的,例如这里的是clip视觉文件需要的参数,或者nvidia显卡里面某些模型的参数
一般服务于模型,这样的话你需要改参数,直接在这里改就行,不需要去找太深
简单理解成:你在外面写一个文件,里面存着参数,然后某些代码需要用到的时候,直接来这个文件找
我也在想过高为什么不写成.py,其实json会更好,因为还可以给别的代码用,并且给某些不懂代码的人员也可以直接修改
于是我像看看随便找一下某个参数,哪个文件用到了
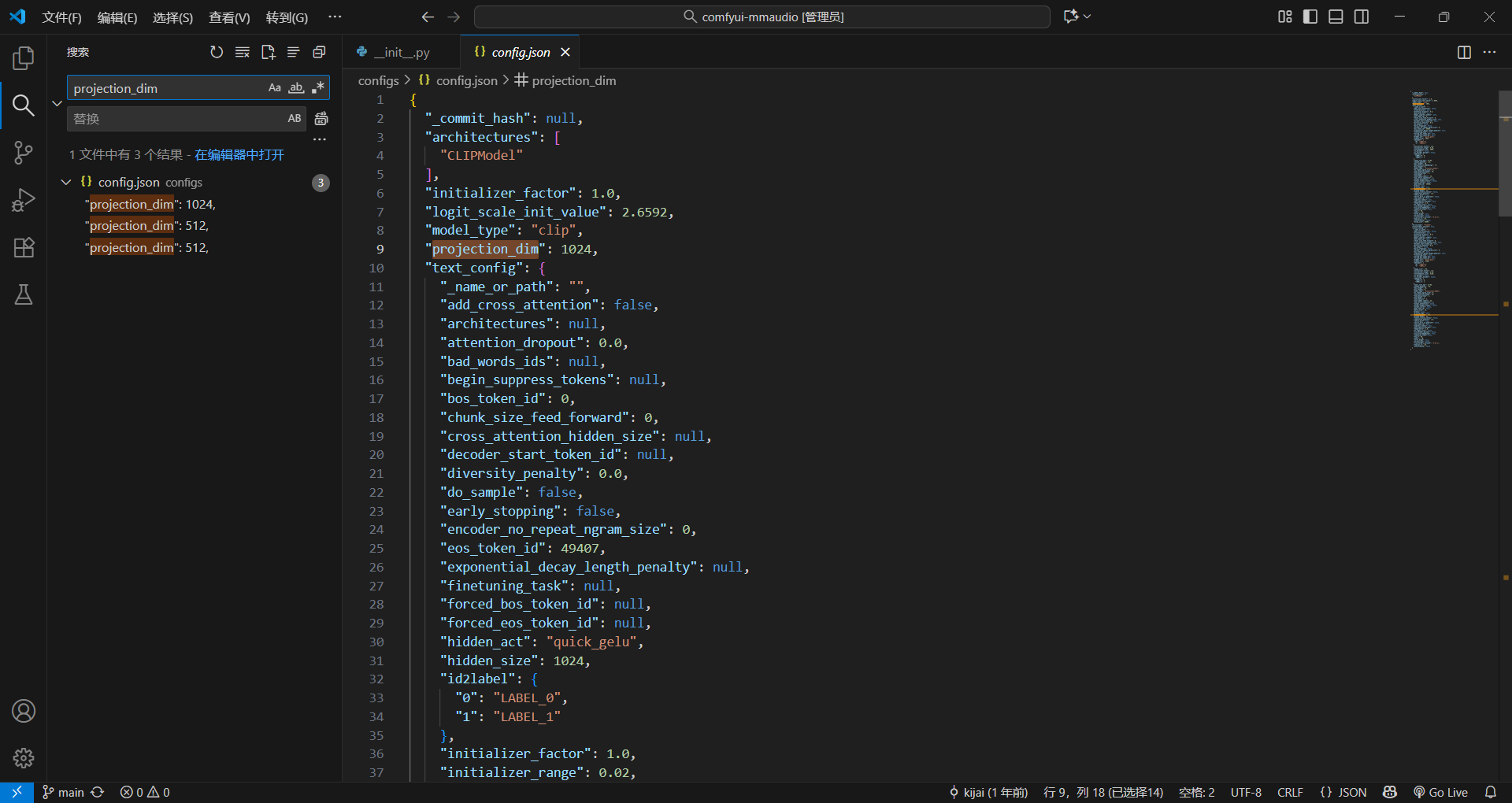
没找到,奇怪,我去查了一下,调用这个一定要用到open文件然后读取内容(除非写在comfyui的代码里,这里只需要传就行了,也就是封装好了)
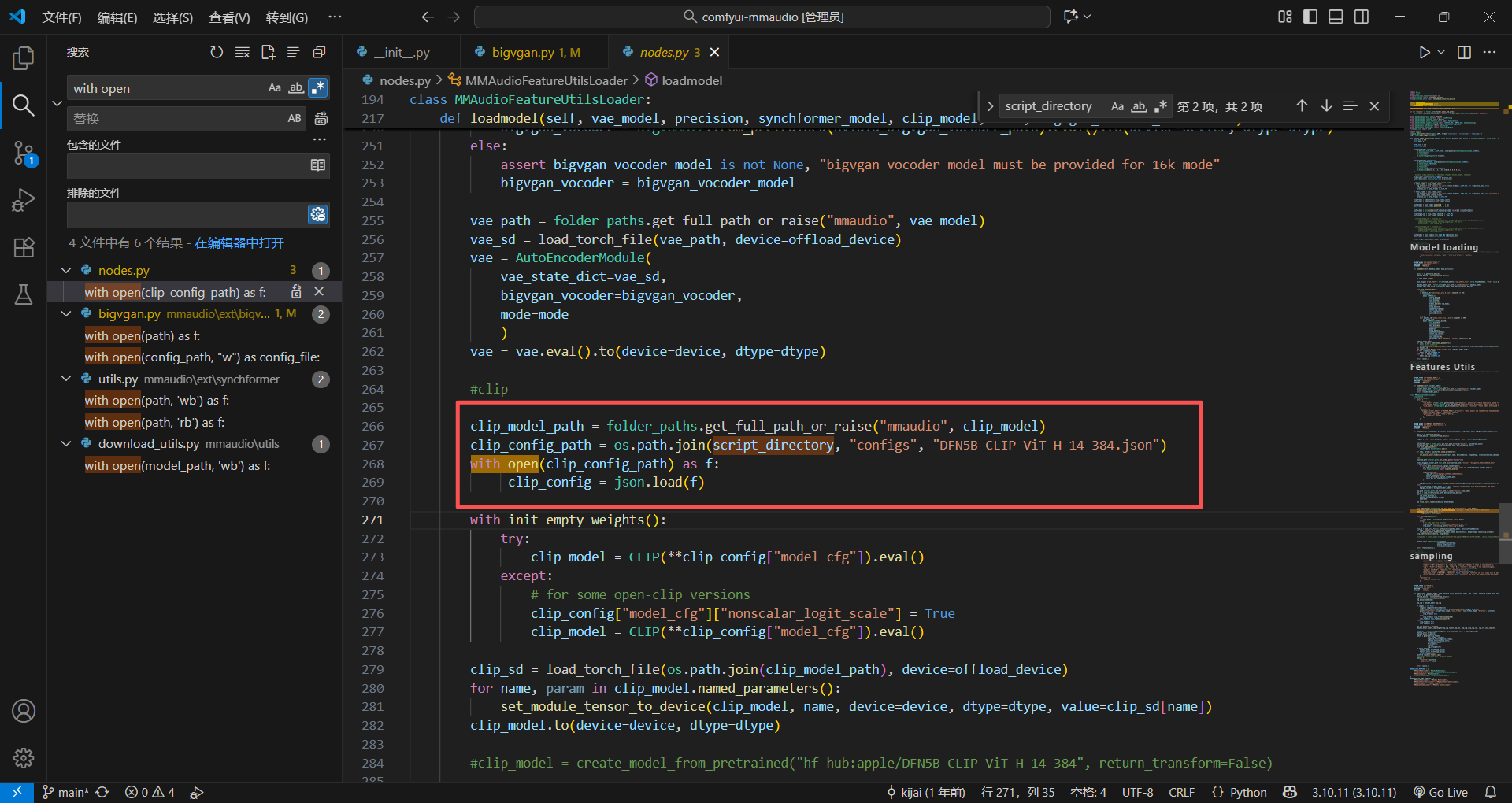
果真找到了,不过好像里面只有DFN5B-CLIP-ViT-H-14-384.json被用到了,不过这个不用去管了,浪费我太多时间了
核心代码mmaudio
接下来就剩下最核心的文件夹mmaudio了,先找阅读顺序
阅读顺序
可以先看看最外层的nodes调用了那些类,这些将是等下最重点关注的
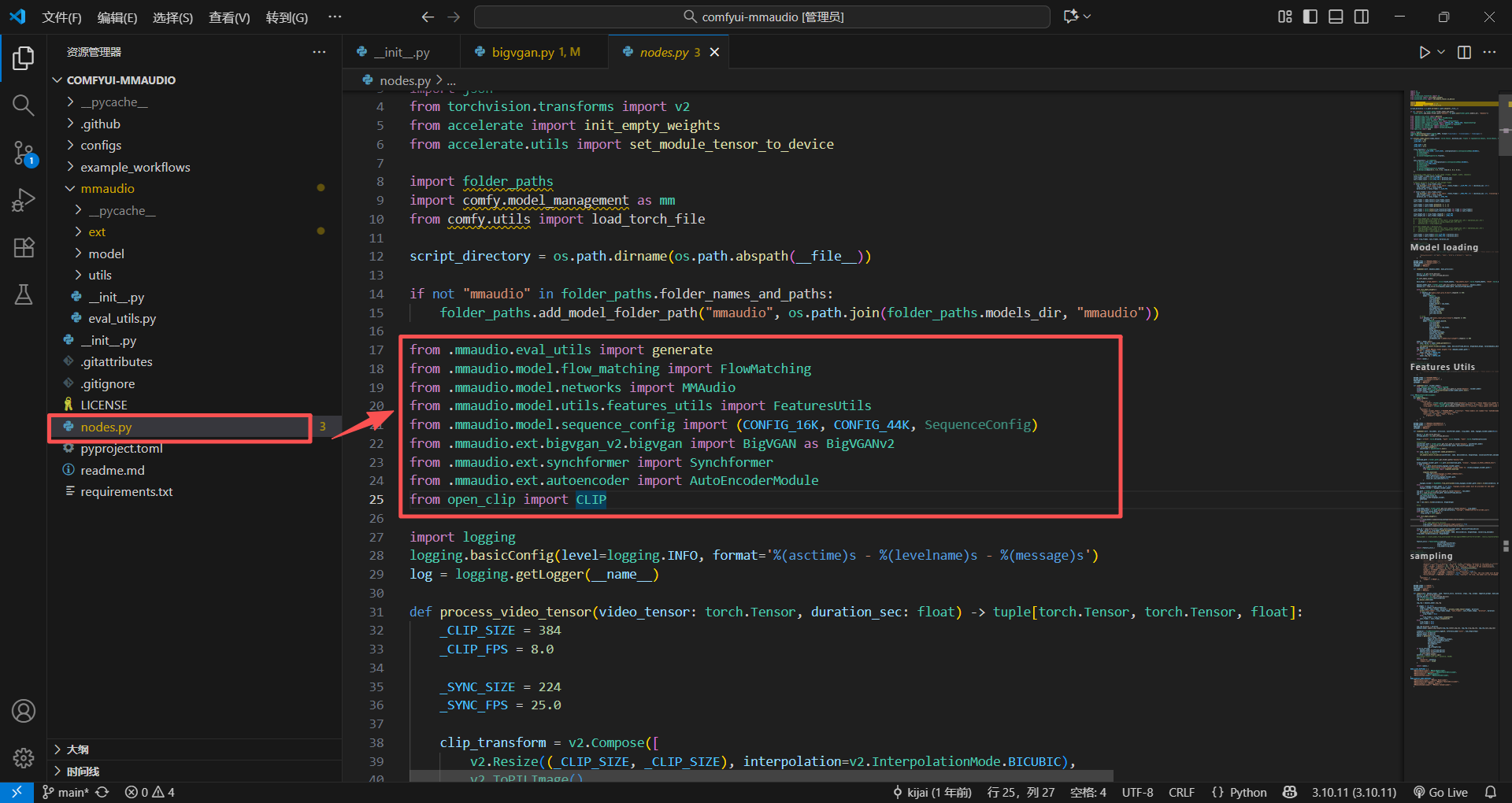
当然我查了一下资料,推荐我这样去剖析,以下是资料
第一步:优先看 mmaudio/__init__.py
这是整个 mmaudio Python 包的入口文件,是你必须第一个看的。
- 核心作用:它定义了整个 mmaudio 包对外暴露的所有类、函数、子模块,你外层的
nodes.py里所有从mmaudio导入的内容,都来自这个文件的导出。 - 看完你能立刻搞懂:整个包的模块架构、哪些是核心对外能力、各个子文件夹(model/utils/ext)的引用关系,避免后面看代码迷路。
第二步:深入核心 mmaudio/model/ 文件夹(重中之重,音频生成的灵魂)
这个文件夹是整个插件的算法内核,所有音频生成的模型结构、核心配置、生成逻辑都在这里,按这个子顺序阅读:
- 先看
model/__init__.py:理清 model 子包的导出关系,你截图里的MMAudio、FlowMatching、CONFIG_16K/CONFIG_44K这些核心对象,都是在这里统一对外导出的。 - 再看
model/sequence_config.py:模型的基础配置底座,定义了 16K/44K 采样率对应的序列参数、音频分块、模型输入输出的维度等核心配置,所有模型和生成逻辑都基于这个文件,先把基础规则搞懂。 - 然后看
model/networks.py:MMAudio 核心网络本体,整个音频生成模型的网络架构、层定义、前向传播逻辑全在这里,是模型的 “硬件本体”。 - 接着看
model/flow_matching.py:音频生成的核心算法,流匹配(FlowMatching)的推理、采样、生成逻辑全在这里,是 “模型怎么生成音频” 的核心实现,决定了生成的完整流程。 - 最后看
model/utils/里的文件(比如你截图里的features_utils.py):音频 / 文本 / 视频特征提取、预处理工具,是把用户输入(文本、视频)转换成模型能接收的特征的桥梁,也是生成流程里的前置关键环节。
第三步:看你当前打开的 mmaudio/eval_utils.py
这个文件是连接外层节点和核心模型的枢纽,是模型能力的封装入口。
- 你截图里的
generate函数,就是整个插件对外提供生成能力的核心函数,外层nodes.py里的所有生成节点,最终都会调用这个函数。 - 看完模型本体再看这个,你就能彻底打通全链路:从 ComfyUI 节点接收用户参数(文本、视频、采样率等),到调用模型完成音频生成的完整流程,每一步是怎么走的。
第四步:看 mmaudio/utils/ 文件夹
这里是整个项目的通用辅助工具集,存放音频读写、格式转换、张量处理、日志管理、路径处理等通用函数,核心逻辑里会频繁调用这些工具。
- 放在主流程之后看,不会影响你对核心生成逻辑的理解,还能补全所有细节实现。
第五步:最后看 mmaudio/ext/ 文件夹
ext是 external 的缩写,也就是外部依赖 / 第三方扩展,存放的是第三方模型(比如你截图里的 synchformer)的适配代码、权重加载逻辑、非核心的外部集成功能。
- 这部分不影响主生成流程的理解,放在最后看即可。
当然如果在哪个文件不太懂的情况下,可以直接从代码慢慢追踪过去,这个又遇到再说,不懂就查资料就行
__init__.py
是空的,说明没有对外暴露,我也不太懂,但是大概能理解啥意思
python里面如果你要外面的文件,调用文件夹里面的文件,那就一定要有__init__.py文件,不然是没办法调用的,至于这个文件写不写都无所谓,写了的话,外面的nodes就不用写完整路径
假设一下,现在是这样(空的)
from .mmaudio.eval_utils import generate
from .mmaudio.model.networks import MMAudio
如果写了对外暴露的接口,就可以直接写简单一些
__init__.py假设暴露接口
from .eval_utils import generate
from .model.networks import MMAudio
nodes就可以不用写完整的路径
from .mmaudio import generate, MMAudio
反正影响不大,如果__init__.py有写东西,我们就得来这里看看,没写就不管,我感觉没写的话还直观一点
不过这个文件是一定要有的,不能删除
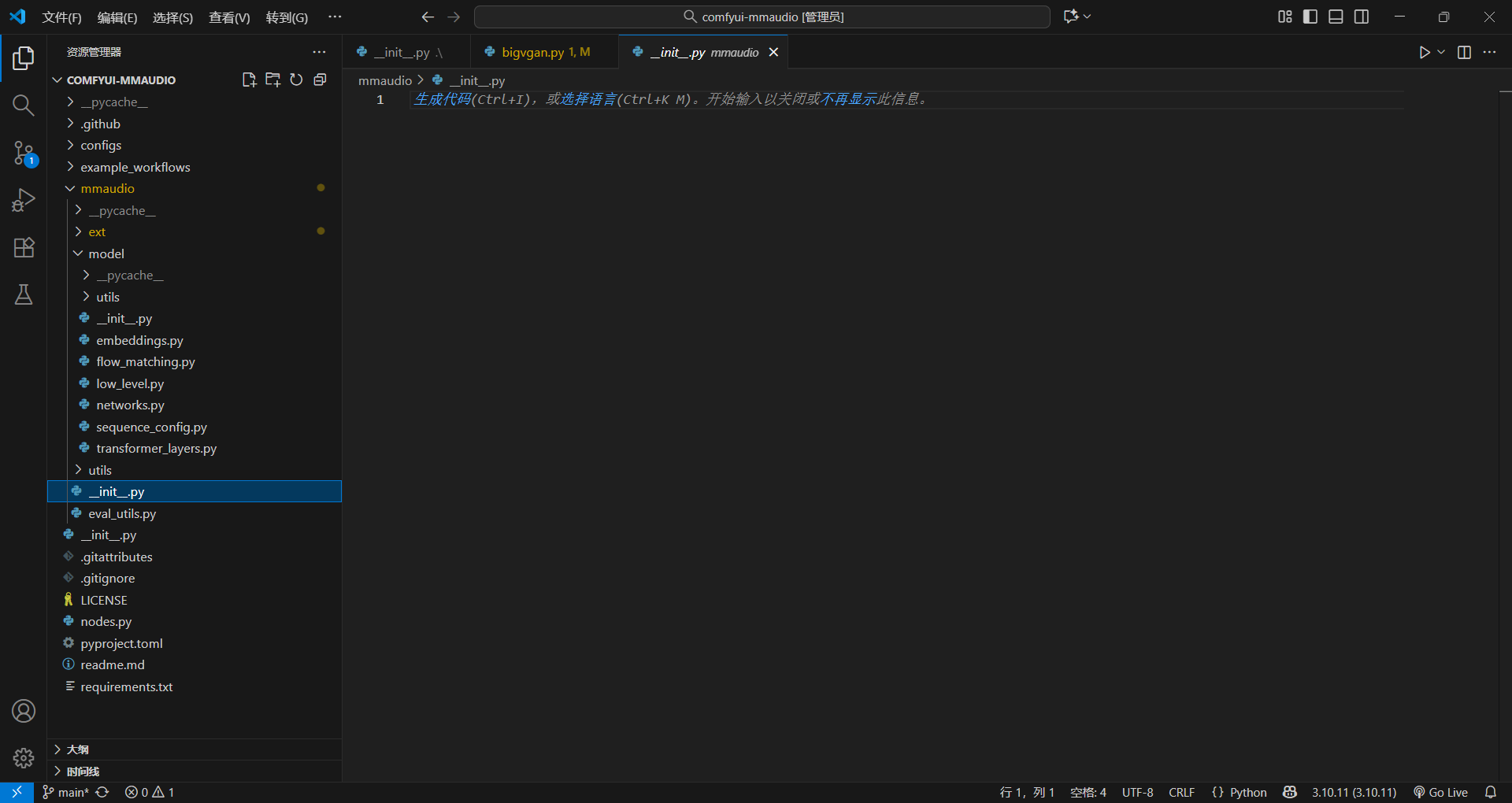
sequence_config.py
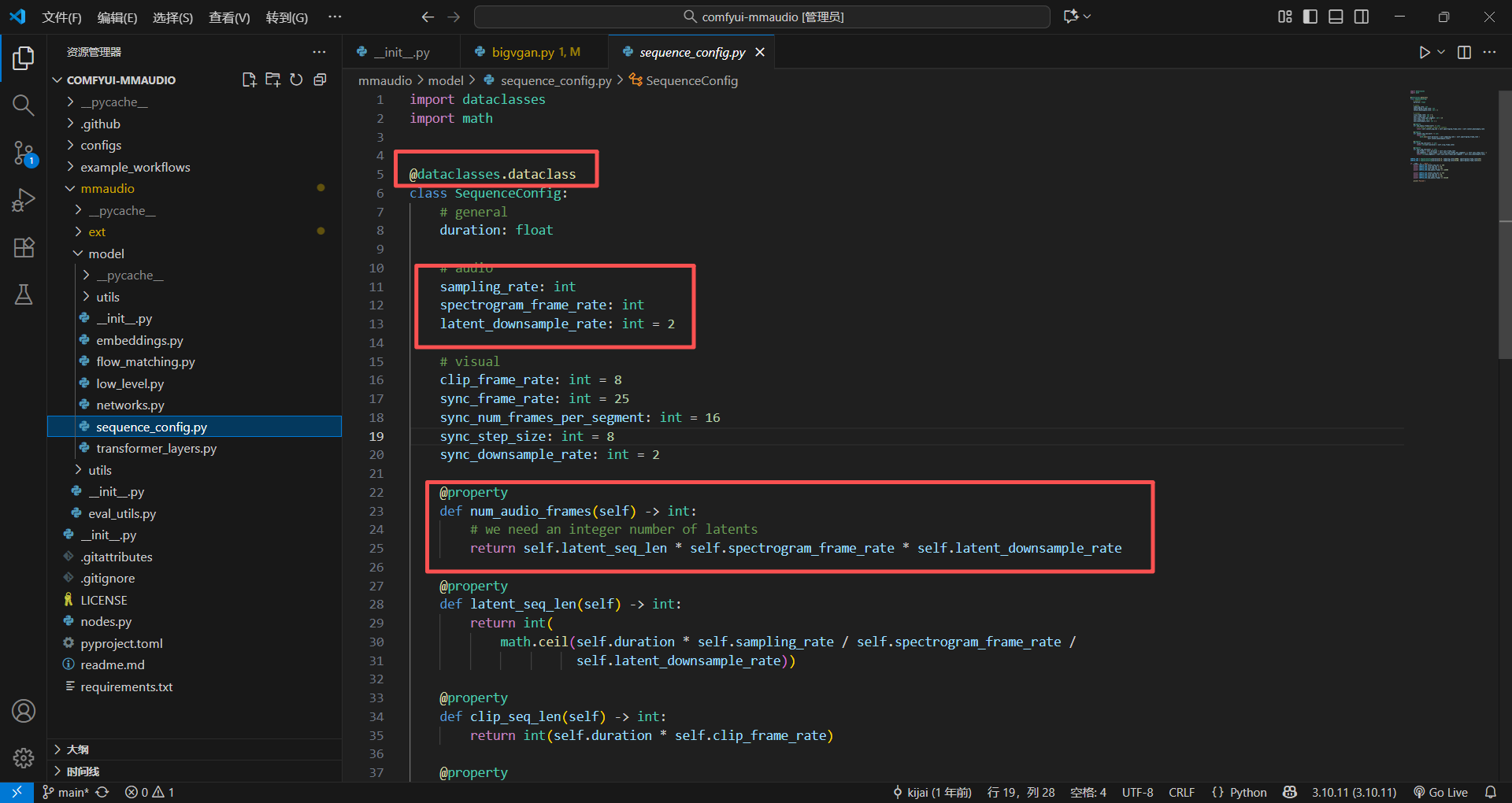
这个里面主要就是定义一些需要使用的参数,主要是给clip(视觉)还有sync(音画同步)模型使用
@dataclasses.dataclass
这个是类装饰器,主要就是把这个类这些参数定义全部给补全,可以理解成简单的一种写法,可以少些很多代码
例如初始化,打印,等于判断等函数,如果不加装饰器得这样写
# 普通类写法(麻烦版)
class SequenceConfig:
def __init__(self, duration: float, sampling_rate: int, spectrogram_frame_rate: int, ...):
self.duration = duration
self.sampling_rate = sampling_rate
self.spectrogram_frame_rate = spectrogram_frame_rate
# ... 还要给所有字段写 self.xxx = xxx
self.latent_downsample_rate = 2 # 还要手动处理默认值
def __repr__(self):
# 手动写打印格式,方便调试
return f"SequenceConfig(duration={self.duration}, sampling_rate={self.sampling_rate}, ...)"
def __eq__(self, other):
# 手动写比较逻辑,判断两个实例是否相等
return (self.duration == other.duration and
self.sampling_rate == other.sampling_rate and
...)加装饰器就简单很多了,少一堆代码
# 数据类写法(简洁版)
import dataclasses
@dataclasses.dataclass
class SequenceConfig:
duration: float
sampling_rate: int
spectrogram_frame_rate: int
latent_downsample_rate: int = 2 # 默认值直接写
# ... 其他字段
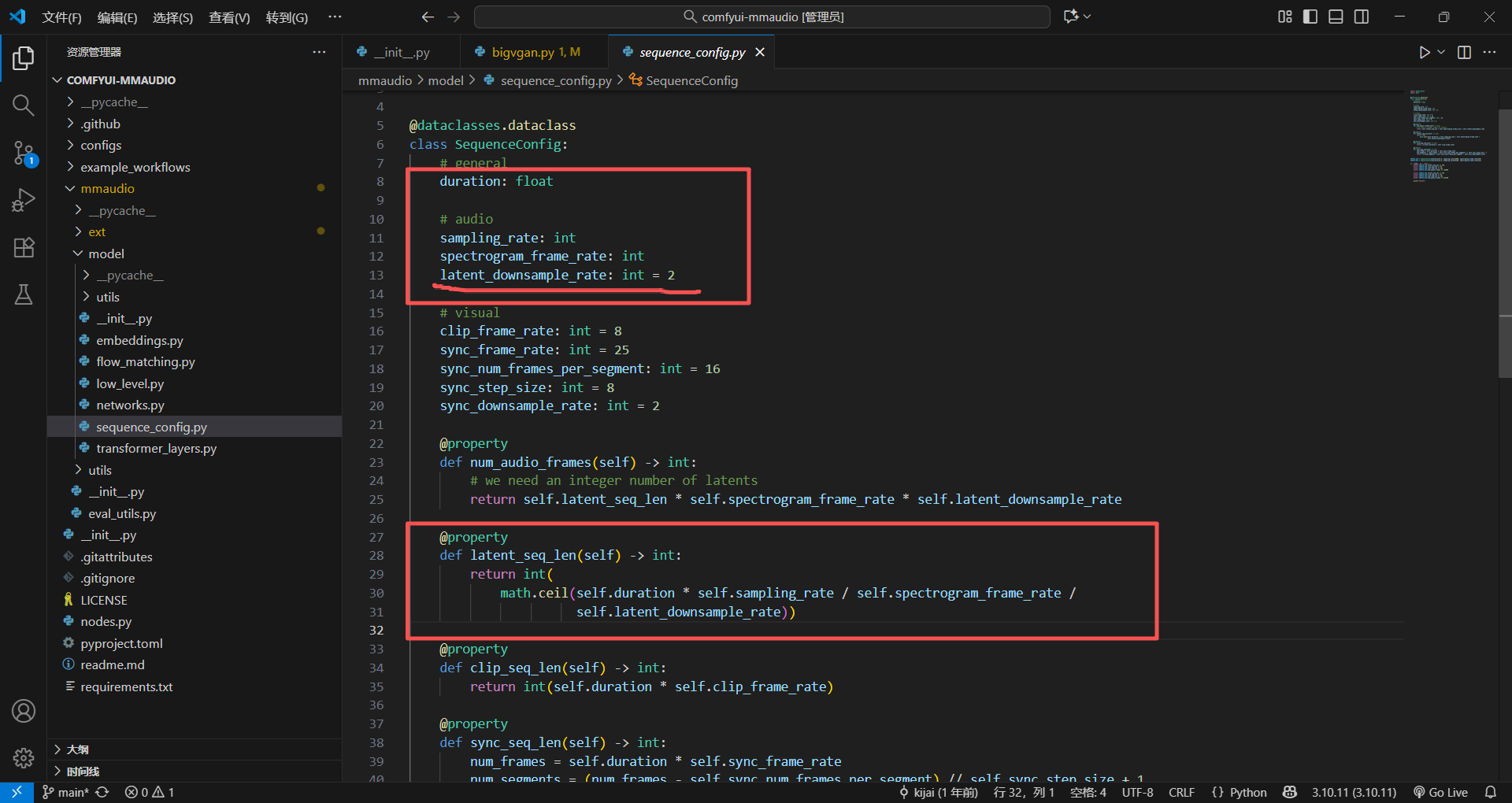
# ✅ 不用写 __init__ / __repr__ / __eq__,装饰器自动生成!@property
这个是属性装饰器,核心作用是:把类里的「方法」伪装成「属性」 —— 调用时不用加括号 (),像访问普通属性(比如 config.duration)一样,但背后能执行复杂的计算逻辑,还能控制读写权限。
直接看一下对比就知道了,不加装饰器
@dataclasses.dataclass
class SequenceConfig:
duration: float
clip_frame_rate: int = 8 # 视频帧率
# 普通方法:计算视频序列长度
def get_clip_seq_len(self):
return self.duration * self.clip_frame_rate
# 调用时必须加括号!
config = SequenceConfig(duration=8.0)
seq_len = config.get_clip_seq_len() # 8.0 * 8 = 64加了装饰器,可以直接调用,不用像方法那样,相当于少了一个括号
@dataclasses.dataclass
class SequenceConfig:
duration: float
clip_frame_rate: int = 8
# @property 装饰:把方法变成属性
@property
def clip_seq_len(self):
return self.duration * self.clip_frame_rate
# 调用时不用加括号!像访问普通属性一样
config = SequenceConfig(duration=8.0)
seq_len = config.clip_seq_len # 直接用,结果也是 64模块自测逻辑
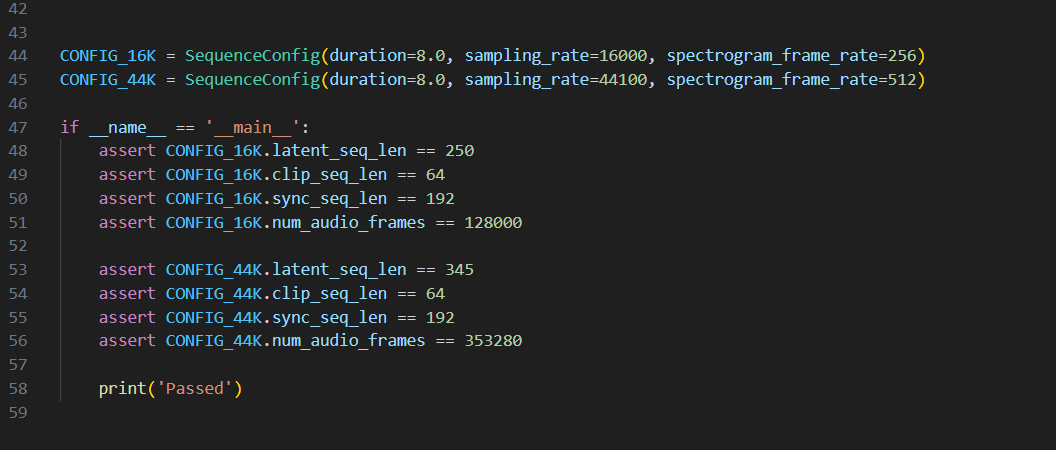
核心入口判断 if __name__ == '__main__':
这是 Python 最基础的「模块入口标识」,规则非常简单:
- 当你直接双击 / 单独运行这个
sequence_config.py文件时,Python 会自动把这个文件的内置变量__name__设为'__main__',这个 if 判断成立,里面的代码会执行; - 当这个文件 ** 被别的文件导入(比如你之前看的
nodes.py、eval_utils.py导入它的 CONFIG_16K)** 时,__name__会变成模块名mmaudio.model.sequence_config,if 判断不成立,里面的代码完全不运行,不会干扰插件的正常加载和使用。
简单来说,就是判断你是不是直接运行这个文件(__main__),是的话就会执行if里面的代码,把一些值给你直接算出来,做一个校验
assert 断言语句:代码正确性校验
直接理解成一种测试,类似try catch,如果这个执行完不成立,那就直接报错,程序崩溃
assert CONFIG_16K.latent_seq_len == 250
用这个为例子,可以看到用了@property装饰器,不用写括号了,如果latent_seq_len算出来的值== 250,那么继续下一行,如果不是,直接报错
直接看一下计算函数,然后看一下赋值语句
CONFIG_16K = SequenceConfig(duration=8.0, sampling_rate=16000, spectrogram_frame_rate=256)
直接算一下 :8 * 16000 / 256 / 2 = 250
没问题,那就继续,不会报错,反正就是一个测试检验
networks.py
整体架构:它是一个「多模态融合的流匹配 Transformer」
这个MMAudio类,本质是基于DiT(Diffusion Transformer) 架构改造的音频生成模型,核心特点是:
- 多模态输入:同时接收「音频潜空间(latent)、CLIP 视觉特征、Synchformer 同步特征、文本特征」;
- 流匹配(Flow Matching):不是传统的扩散模型去噪,而是直接预测「从噪声到真实音频的流(flow)」;
- 分阶段融合:先用
JointBlock分开处理不同模态,再用FusedBlock深度融合,最后输出预测结果。
一大堆解释没怎么看懂,太过于官方了,所以我直接简单理解,大概懂逻辑就行了
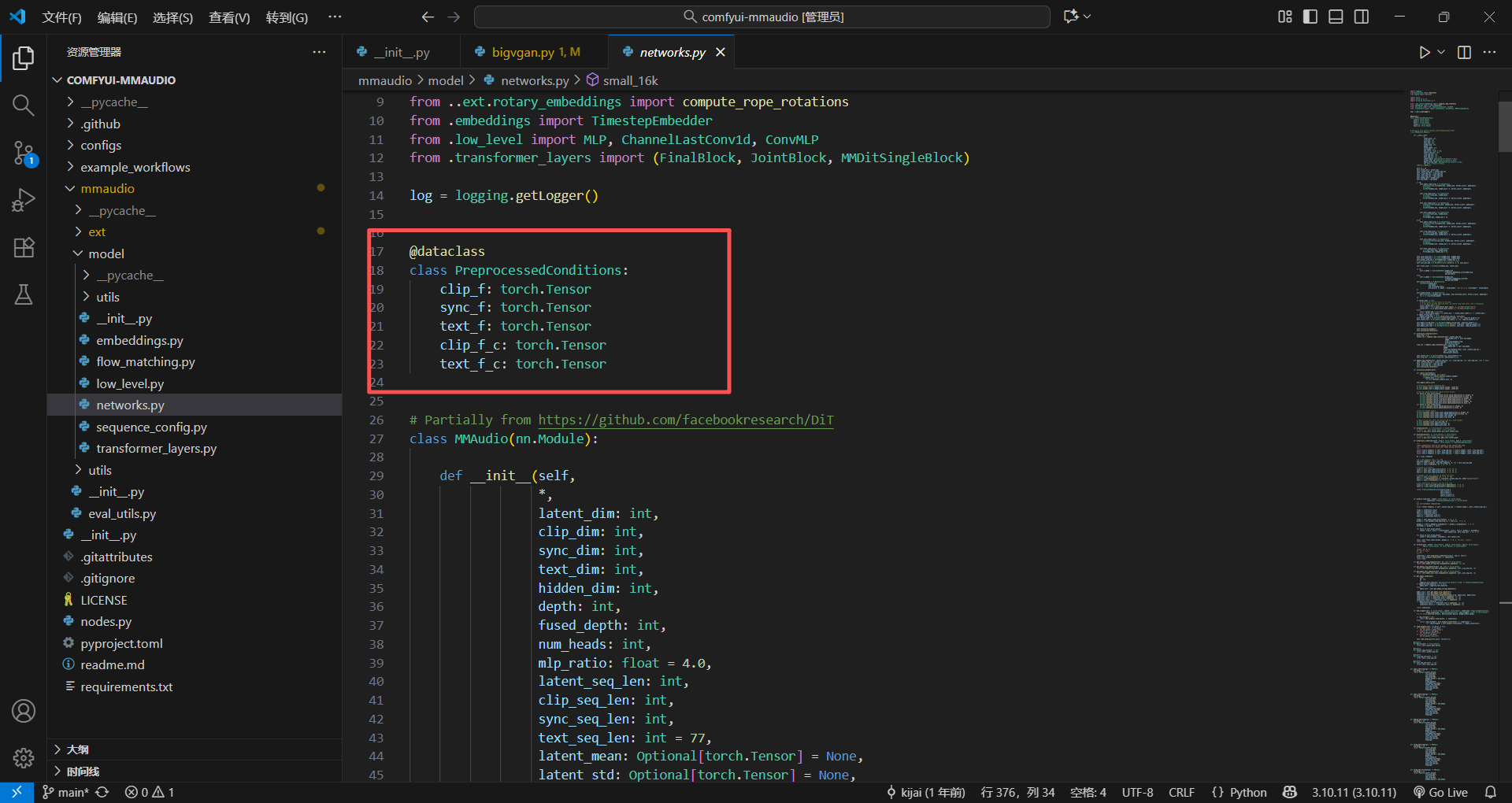
开局熟悉的dataclass装饰器,用来预处理一些参数
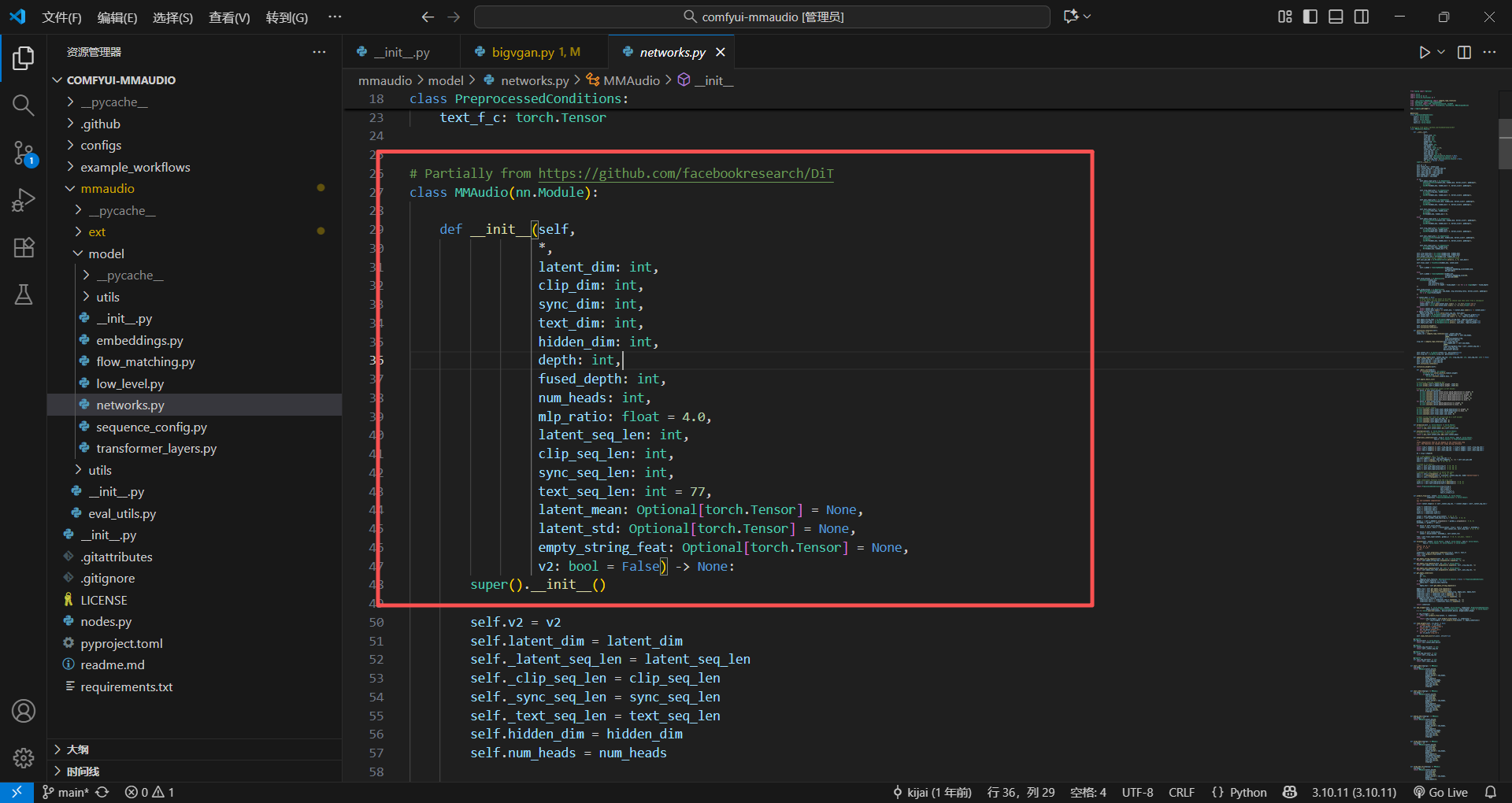
接下来就是初始化函数init,也就是调用这个类的时候,一定得传这些值进来,不然没法初始化
* 代表传进来的值必须写值的名字,例如
MMAudio(latent_dim=20, clip_dim=1024) 这样才是对的
MMAudio(20, 1024) 这样是错的,必须写名字
你会发现这些值,下面有些方法已经定义好了,就是用的哪个版本的包
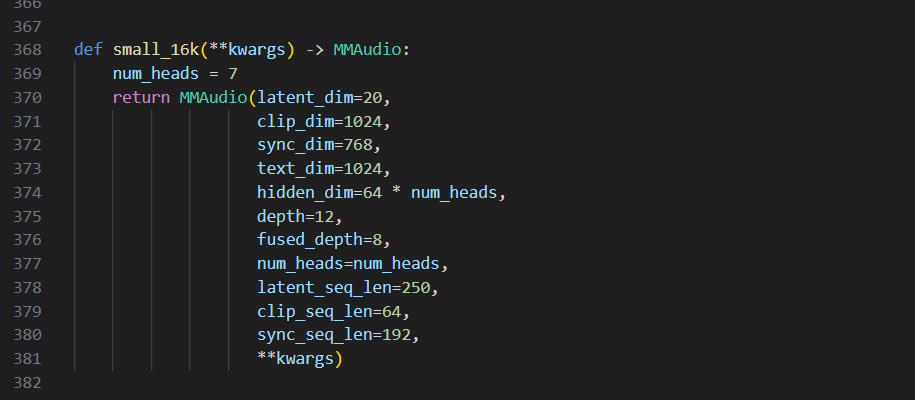
基本上差不多给你赋值好了,各版本的值,最下面那个得注意一下,你会发现跟上面初始化对应,还少了一些可以选择的值
**kwargs这是 Python 的可变关键字参数(Variable Keyword Arguments)
相当于你可以给那些可选择的值传进去,而且你想写几个就几个
假设small_16k(v2=True) ,他除了那些写好的值,还会传一个这个给它
super().__init__()
继承的上一个类的初始化方法,这个是子类,肯定得用torch的方法,看这个类就发现了
接下来的一大堆都是各种clip图片处理啊,进入潜空间啊,反正各种看不懂的操作,整理一下重点函数就行,反正看不懂,直到在干啥就行,真的需要改再去了解就行
1.preprocess_conditions:预处理条件(推理时缓存复用)
这是提升推理速度的关键,因为 CLIP、Sync、Text 特征在每个时间步都是一样的,不用重复计算
2. predict_flow:核心推理逻辑,预测流
这是模型真正干活的函数,对应流匹配(Flow Matching)的核心,看到这个flow matching我就想起那个CFGZeroStar节点
3. ode_wrapper:配合 ODE 求解器,支持 CFG 引导
这是连接模型和eval_utils.py里生成逻辑的桥梁
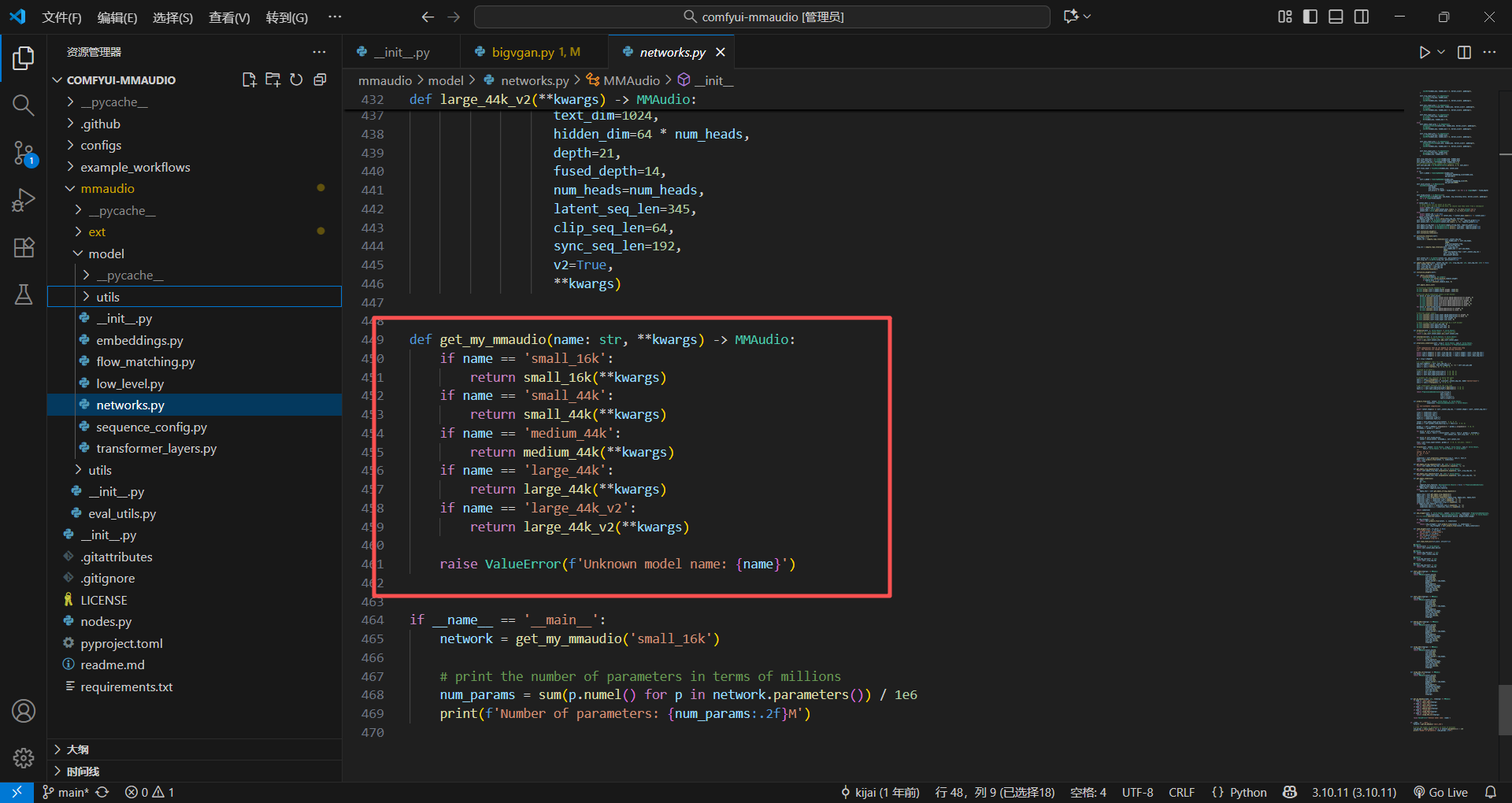
最后还给个函数让别人调用的时候方便实例化,也就传入版本
接下来是
transformer_layers.py:看看JointBlock和FusedBlock内部是怎么工作的,多模态是怎么融合的;flow_matching.py:看看流匹配的训练和推理逻辑,和这个predict_flow是怎么配合的。
太长了,先到这里

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 6
6 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)