图片识别:从 PDF 到图片,大模型结构化提取的「是什么、为什么、怎么办」
本文围绕图片结构化识别,结合通义千问 Qwen3.5-Plus 实战,讲清原理、差异与落地方案,适合 IT 开发阅读。
关键词:通义千问、多模态、OCR、结构化抽取、DashScope
一、是什么:PDF 识别 vs 图片识别,本质是两套链路
在 AI 眼里,PDF 和图片是完全不同的两种输入。
| 输入类型 | 大模型实际「看到」的 | 核心能力 |
|---|---|---|
| PDF(文本型) | 已经解析好的 UTF-8 文本流 + 版面坐标 | 纯 NLP:理解语义、抽取字段 |
| 图片 | 像素矩阵(几百万个 RGB 点) | 先「看图识字」再「理解语义」 |
可以简单理解:
- PDF 识别:像在读一本电子书,字已经在那里,模型只负责「读懂并摘抄」。
- 图片识别:像在看一张照片,模型要先认出「哪里是字、什么字」,再去做摘抄。
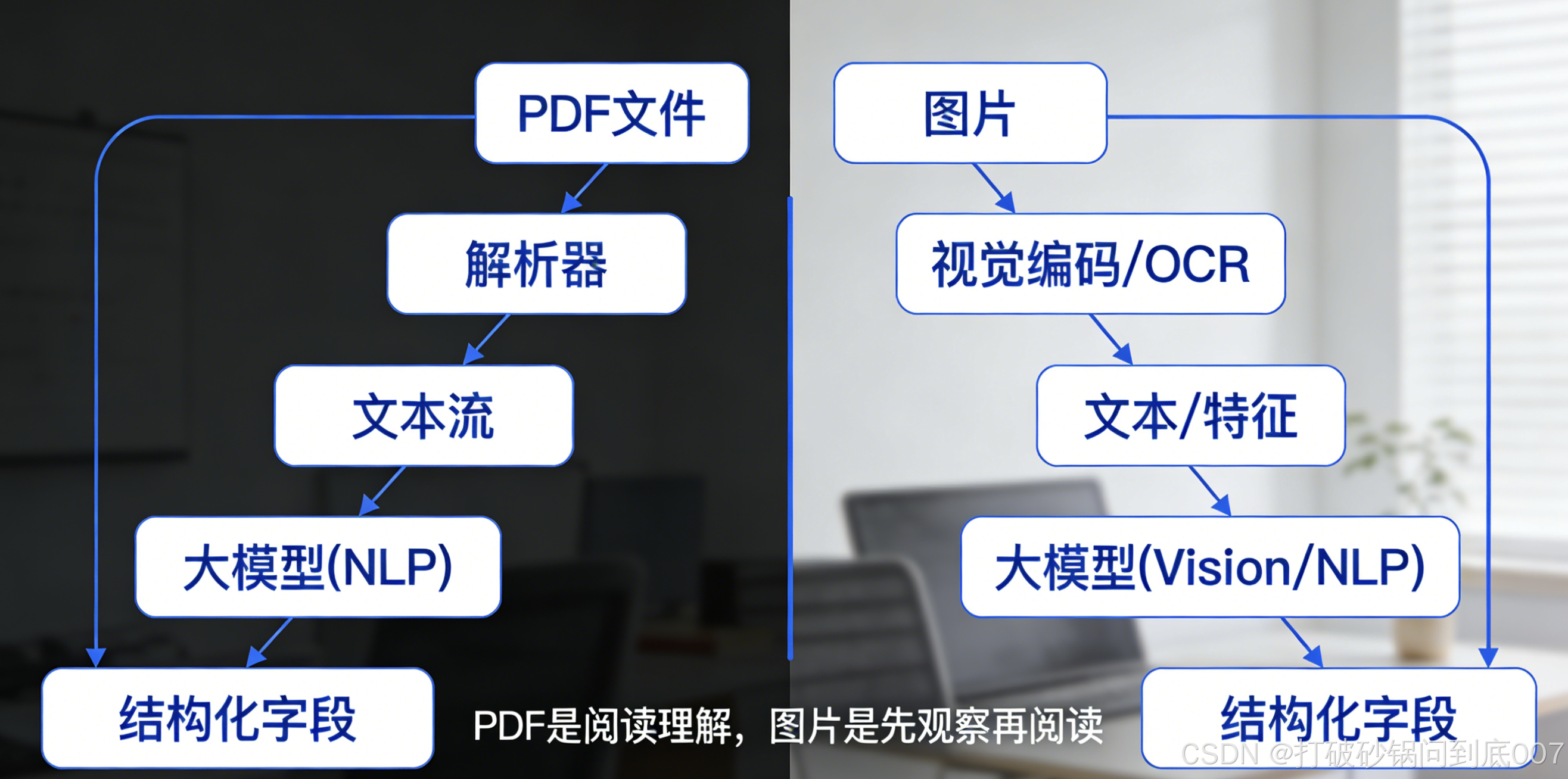
所以:PDF 是「阅读理解」,图片是「先观察再阅读」。两者处理机理不同,不能简单用「PDF 成功率 90%」去推断「图片也能 90%」。
1.1 两条常见技术路线
在实际项目中,针对图片格式的合同文件,通常有两条路线可以对比评估:
路线 A:端到端多模态(Direct)
图片 → 通义多模态大模型(如 qwen3.5-plus)→ 直接输出结构化 JSON
- 一步到位,模型自己完成「看图 + 理解 + 抽取」。
- 适合版面规整、字体清晰的场景;对模糊、印章遮挡、长文档底部小字相对脆弱。
路线 B:OCR 先行,再文本抽取(OCR-First)
图片 → 专用 OCR 模型(如 qwen-vl-ocr)→ 纯文本 → 通义文本大模型 → 结构化 JSON
- 把「识字」和「理解」拆开:OCR 负责把图转成字,大模型只做语义抽取。
- 字符级精度更高,长文档、多页扫描件往往更稳;代价是丢失部分「视觉布局」信息。
后文会给出这两条路线的完整可运行代码,方便你本地对比识别率。
1.2 ①:概念对比图
二、为什么:图片识别成功率往往比 PDF 更「脆弱」
很多同学会直觉认为:既然 PDF 能到 90%+,图片用同一个模型,应该也差不多。实测中,若不专门优化,图片场景的整单成功率常常会掉到 70%~80%,甚至更低。 原因可以归纳为三类。
2.1 输入信号质量:从「确定文本」到「不确定像素」
- PDF 文本:解析出来的是确定的字符序列,没有「看不清」的问题(除非 PDF 本身是扫描图)。
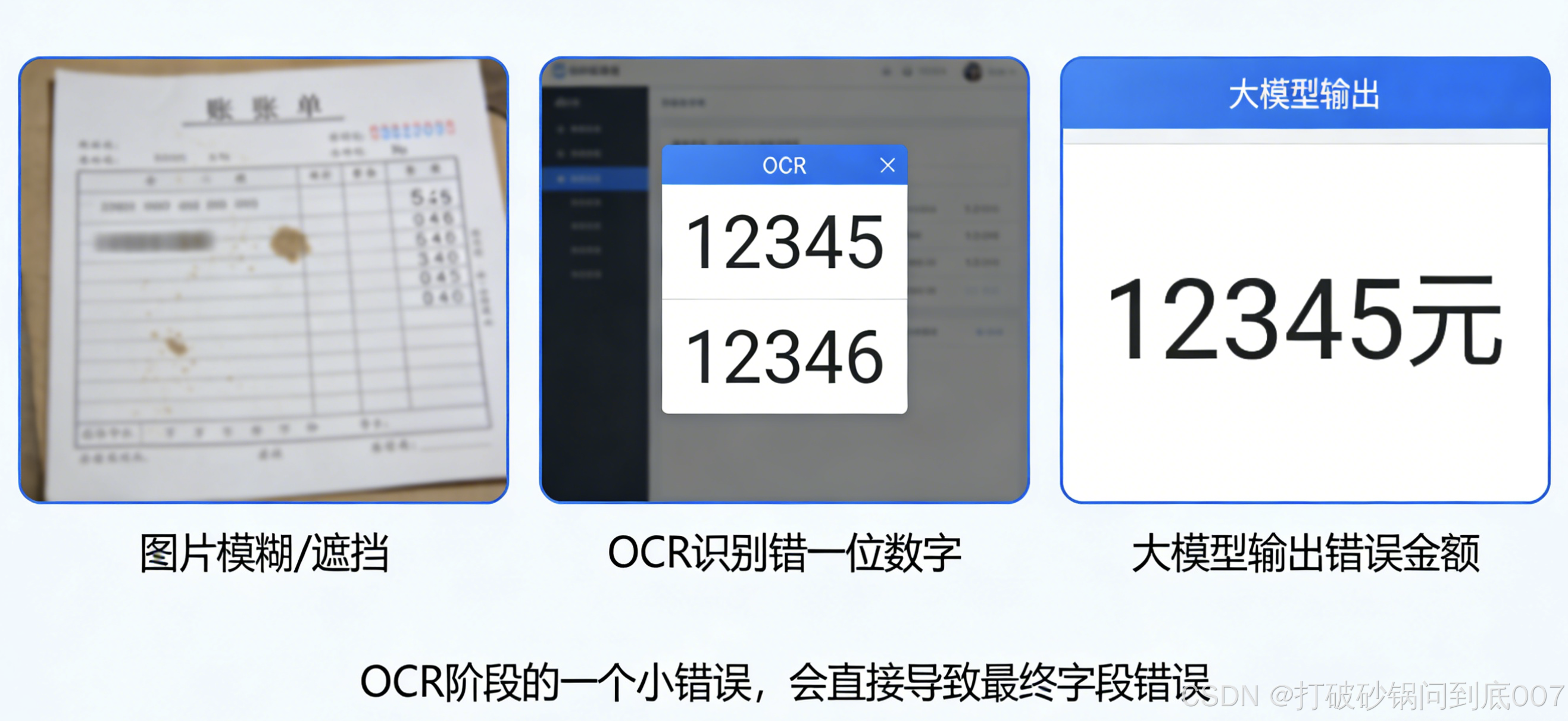
- 图片:受分辨率、光照、折痕、反光、印章遮挡、透视变形、压缩噪点等影响,OCR/视觉模块很容易在关键位置出错,例如:
- 金额
1,000,000被识别成1.000.000或1000000(缺少逗号导致后续解析错误); - 日期
2025-12-31被识别成2025-l2-31(数字与字母混淆)。
- 金额
这类错误一旦发生在 OCR 阶段,后面再强的大模型也无法「无中生有」纠正,属于错误传导。
2.2 版面与结构:坐标信息的丢失
- PDF:通常可以拿到段落、表格、坐标等结构化信息,模型容易知道「左上角是保函编号,中间表格第二行是金额」。
- 图片:需要模型或 OCR 自己从像素中恢复版面(表格线、多列、页眉页脚)。恢复不准时,容易把「申请人」和「受益人」搞混,或把金额填到错误字段。
2.3 模型分工:多模态 ≠ 专精 OCR
- 纯文本大模型:在「长文本理解、字段抽取、格式约束」上非常强,前提是输入已经是高质量文本。
- 多模态大模型:同时做「看图 + 理解」,但在细粒度字符识别上,往往不如专门的工业级 OCR 引擎稳。
所以:「专业 OCR + 强语义 LLM」组合,在金融票据这类对精度要求极高的场景,往往比单一大模型端到端更稳。
2.4 错误传导示意图
三、怎么办:用通义千问做「双链路」评估与落地
思路很直接:在同一批合同图片上,分别跑「端到端多模态」和「OCR + 文本抽取」两条链路,按字段统计准确率,再决定线上用哪条、或如何组合。
下面以阿里云 DashScope(通义千问) 为例,给出可直接运行的代码与使用方式。
通义千问支持 OpenAI 兼容接口,用 openai 官方 Python SDK 即可,对 Java/Go 等开发者也很友好(换对应 SDK 即可)。
3.1 环境准备
# 进入项目目录(示例)
cd Projects/imageRecognition
# 安装依赖
pip install openai pillow
# 配置 API Key(在阿里云 DashScope 控制台获取)
export DASHSCOPE_API_KEY="你的_DashScope_API_Key"
3.2 核心:图片转 Base64,供多模态接口使用
多模态接口需要「图片 URL」或「Base64 Data URL」。本地图片先转成 Data URL 再传给模型即可:
import base64
from PIL import Image
def image_to_data_url(image_path: str) -> str:
"""将本地图片转为 data URL,便于通过 OpenAI 兼容接口传给通义多模态。"""
with open(image_path, "rb") as f:
img_bytes = f.read()
img = Image.open(image_path)
fmt = (img.format or "PNG").lower()
if fmt == "jpeg":
fmt = "jpg"
b64 = base64.b64encode(img_bytes).decode("utf-8")
return f"data:image/{fmt};base64,{b64}"
3.3 统一的「结构化抽取」Prompt
两条链路最终都希望得到同一套 JSON 结构,便于对比。下面是一个精简版 Prompt(实际项目可按业务增减字段):
def build_extraction_prompt() -> str:
return (
"你是一名精通银行业务的智能助手。请从给定内容中精准抽取以下字段,"
"并严格返回 JSON 格式(不要包含多余说明):\n"
"1. guarantee_number 保函编号\n"
"2. applicant 申请人\n"
"3. beneficiary 受益人\n"
"4. issuing_bank 开立行\n"
"5. amount.value 金额(数字)、amount.currency 币种\n"
"6. issue_date 出具日期、expiry_date 截止日期\n"
"缺失字段用 null。只输出 JSON。"
)
3.4 路线 A:端到端多模态(Direct)
from openai import OpenAI
import os, json
client = OpenAI(
api_key=os.getenv("DASHSCOPE_API_KEY"),
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1"
)
def extract_direct_multimodal(image_path: str):
"""图片 → qwen3.5-plus 多模态 → 直接输出结构化字段。"""
data_url = image_to_data_url(image_path)
content = [
{"type": "image_url", "image_url": {"url": data_url}},
{"type": "text", "text": build_extraction_prompt()}
]
resp = client.chat.completions.create(
model="qwen3.5-plus",
messages=[{"role": "user", "content": content}],
temperature=0.1,
)
text = resp.choices[0].message.content
return json.loads(text) if text else {}
3.5 路线 B:OCR 先行,再文本抽取(OCR-First)
def ocr_image(image_path: str) -> str:
"""使用通义 OCR 模型(qwen-vl-ocr)提取图片中的完整文本。"""
data_url = image_to_data_url(image_path)
content = [
{"type": "image_url", "image_url": {"url": data_url}},
{"type": "text", "text": "请将图片中的所有文字按阅读顺序完整输出为纯文本,不要添加解释。"}
]
resp = client.chat.completions.create(
model="qwen-vl-ocr-2025-11-20", # 以 DashScope 文档为准
messages=[{"role": "user", "content": content}],
temperature=0.0,
)
return resp.choices[0].message.content or ""
def extract_from_ocr_text(ocr_text: str):
"""将 OCR 文本交给 qwen3.5-plus 做结构化抽取。"""
prompt = build_extraction_prompt() + "\n\n待处理文本:\n" + ocr_text
resp = client.chat.completions.create(
model="qwen3.5-plus",
messages=[{"role": "user", "content": [{"type": "text", "text": prompt}]}],
temperature=0.1,
)
text = resp.choices[0].message.content
return json.loads(text) if text else {}
3.6 一键对比两种模式(命令行)
项目里提供的 main.py 支持通过参数切换模式,方便批量跑同一批图片:
# 端到端多模态
python main.py --mode direct --image ./samples/baohan-001.png
# OCR 先行 + 文本抽取
python main.py --mode ocr-first --image ./samples/baohan-001.png
两种模式输出同一套 JSON 结构,便于写脚本统计字段级准确率和整单成功率。
3.7 双链路对比 + 结果示例
流程图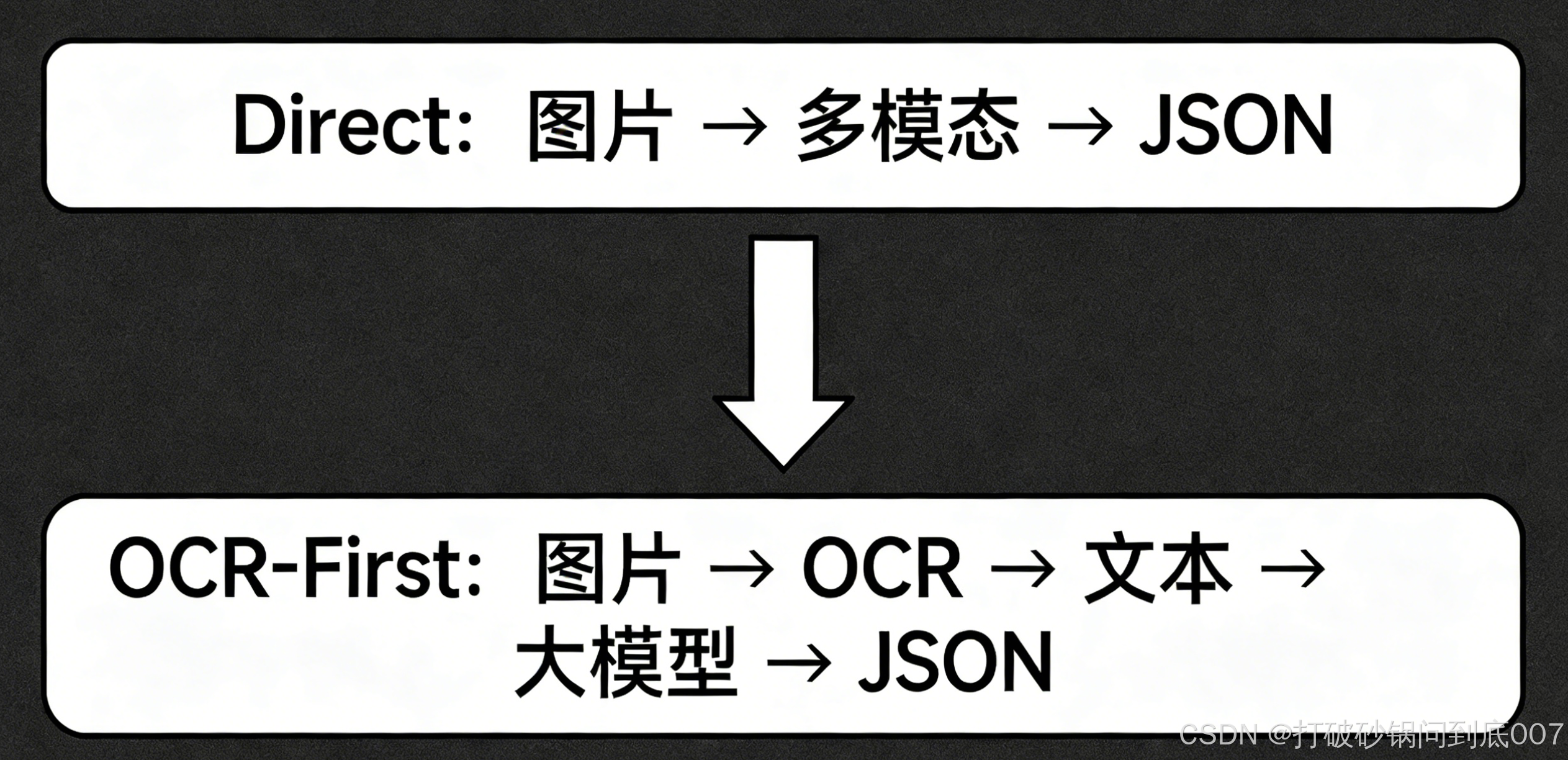
- 运行效果对比
1)python3 main.py --mode direct --image ./DianZiBaoHan.png运行效果
2)python3 main.py --mode ocr-first --image ./DianZiBaoHan.png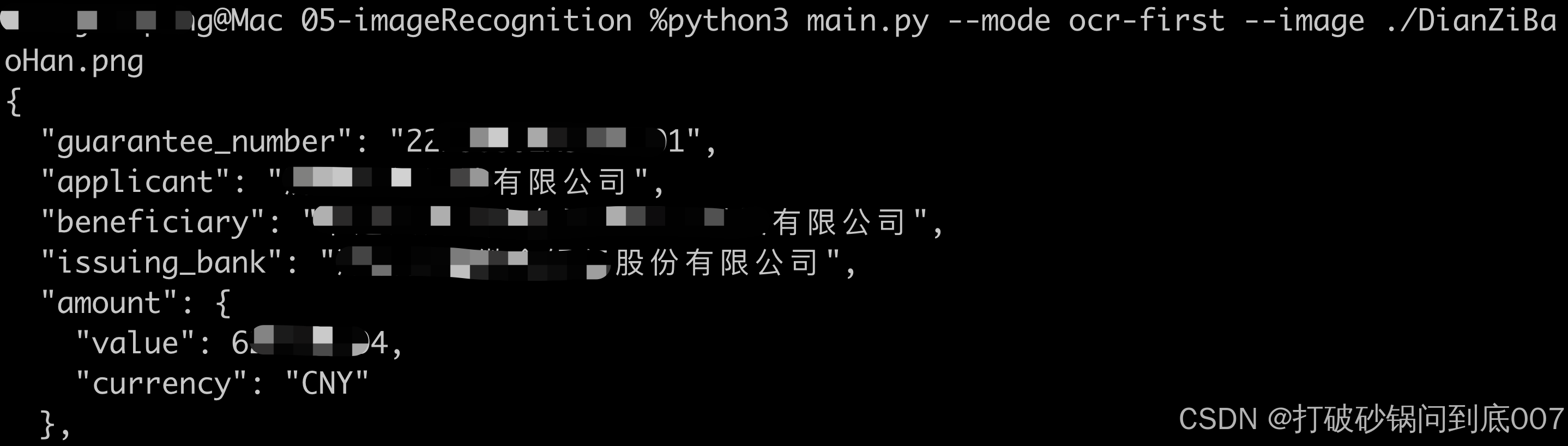
四、如何把识别率「顶」上去:几条实用建议
在「怎么办」的落地层面,除了选对链路,还可以做这几件事:
-
建立错例集
把识别错误的样本按「OCR 错 / 版面理解错 / 字段理解错」分类,针对性地优化:换 OCR、改 Prompt、加后处理规则。 -
关键字段做二次校验
对金额、日期、账号等做正则、格式、校验位等规则校验,对低置信度结果触发人工复核。 -
按银行/模板拆分评估
不同银行的合同版式差异大,建议按模板统计准确率,对低准确率模板单独优化(例如固定锚点文案、区域裁剪再识别)。 -
人机协同
不必追求 100% 全自动。例如:模型先跑一遍,对置信度低或关键金额异常的由人工抽检,整体效率与准确率都能兼顾。
五、小结与 AI 落地的几句心里话
- 是什么:PDF 识别是「阅读理解」,图片识别是「先观察再阅读」;端到端多模态 vs OCR+文本抽取,是两条不同的技术路线。
- 为什么:图片受分辨率、版面、OCR 精度影响大,多模态模型在细粒度文字识别上不一定比「专业 OCR + LLM」更稳,所以图片场景成功率往往比 PDF 更脆弱。
- 怎么办:用同一批图片、同一套 JSON 规范,对比「Direct」和「OCR-First」两条链路,按字段统计准确率;再结合错例集、规则校验和人机协同,把识别率提到可上线水平。
在 2026 年这个 AI 大模型遍地开花的阶段,能选对链路、会评估、会调优,往往比单纯「会用一个大模型」更有价值。技术是手段,业务降本增效才是目的。希望这篇「是什么、为什么、怎么办」能帮你少踩坑、多出活。
关于作者
深耕互联网AI 落地,关注业务架构。欢迎在 CSDN / 公众号交流。
声明
本文涉及的通义千问模型名称与 API 以阿里云 DashScope 当前文档为准,若有变更请以官网为准。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 6
6 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)