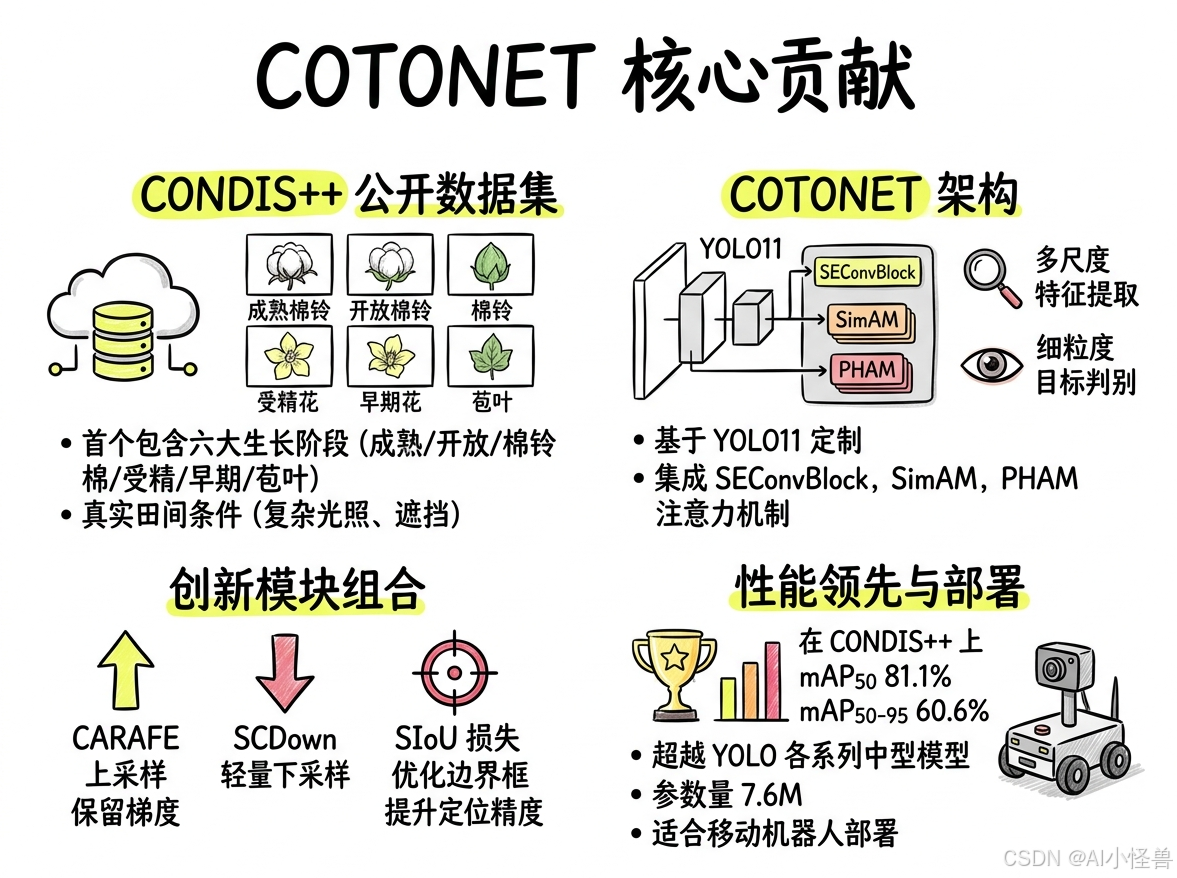
YOLO11+注意力机制=COTONET:棉花生长阶段检测精度突破81%
本文核心贡献如下:
-
构建公开棉花数据集CONDIS++:首个包含棉铃六大生长阶段(成熟/开放棉铃、棉铃、受精/早期花、苞叶)的高质量数据集,涵盖复杂光照、遮挡等真实田间条件。
-
提出COTONET架构:基于YOLO11定制,集成SEConvBlock、SimAM与PHAM注意力机制,增强多尺度特征提取与细粒度目标判别。
-
创新模块组合:采用CARAFE上采样保留梯度信息,SCDown轻量下采样,SIoU损失优化边界框回归,提升定位精度。
-
性能领先:在CONDIS++上mAP50达81.1%,mAP50-95达60.6%,超越YOLO各系列中型模型,参数量仅7.6M,适合移动机器人部署。
博主简介

AI小怪兽 | 计算机视觉布道者 | 视觉检测领域创新者
深耕计算机视觉与深度学习领域,专注于视觉检测前沿技术的探索与突破。长期致力于YOLO系列算法的结构性创新、性能极限优化与工业级落地实践,旨在打通从学术研究到产业应用的最后一公里。
🚀 核心专长与技术创新
-
YOLO算法结构性创新:于CSDN平台原创发布《YOLOv13魔术师》、《YOLOv12魔术师》等全系列深度专栏。系统性提出并开源了多项原创自研模块,在模型轻量化设计、多维度注意力机制融合、特征金字塔重构等关键方向完成了一系列突破性实践,为行业提供了具备高参考价值的技术路径与完整解决方案。
-
技术生态建设与知识传播:独立运营 “计算机视觉大作战” 公众号(粉丝1.6万),成功构建高质量的技术交流社群。致力于将复杂算法转化为通俗易懂的解读与可复现的工程代码,显著降低了计算机视觉的技术入门门槛。
🏆 行业影响力与商业实践
-
荣获腾讯云年度影响力作者与创作之星奖项,内容质量与专业性获行业权威平台认证。
-
全网累计拥有 7万+ 垂直领域技术受众,专栏文章总阅读量突破百万,在目标检测领域形成了广泛的学术与工业影响力。
-
具备丰富的企业级项目交付经验,曾为工业视觉检测、智慧城市安防等多个关键领域提供定制化的算法模型与解决方案,驱动业务智能化升级。
💡 未来方向与使命
秉持 “让每一行代码都有温度” 的技术理念,未来将持续聚焦于实时检测、语义分割及工业缺陷检测的商业化闭环等核心方向。愿与业界同仁协同创新,共同推动技术边界,以坚实的技术能力赋能实体经济与行业变革。
原创自研系列, 26年计算机视觉顶会创新点
原创自研系列, 25年计算机视觉顶会创新点
应用系列篇:
23、24年最火系列,加入24年改进点内涵100+优化改进篇,涨点小能手,助力科研,好评率极高
0.原理介绍

摘要:棉花收获是一个关键阶段,在此过程中棉铃会受到物理操控,可能导致纤维品质下降。为保持最高品质,收获方法必须模仿精细的人工采摘,以保留棉花的固有特性。要实现这一过程的自动化,系统首先必须能够识别处于不同物候阶段的棉铃。为应对这一挑战,我们提出了COTONET,一个增强的定制YOLO11模型,通过引入注意力机制来改进对困难实例的检测。该架构在非可学习操作中引入了梯度,以增强形状和特征提取。关键的架构修改包括:用Squeeze-and-Excitation块替换卷积块,重新设计集成注意力机制的骨干网络,以及用内容感知特征重组替代标准上采样操作。此外,我们还集成了简单注意力模块用于主要特征聚合,以及在下行颈部路径中集成了用于通道、空间和坐标注意力的并行混合注意力机制。这种配置为解读棉花作物生长的复杂性提供了更高的灵活性和鲁棒性。COTONET与中小型YOLO模型相当,拥有760万参数和27.8 GFLOPs的计算量,使其适用于资源受限的边缘计算和移动机器人。COTONET优于标准YOLO基线,实现了81.1% 的mAP50和60.6% 的mAP50-95。
关键词:YOLO,深度学习,计算机视觉,自定义数据集,目标检测,棉花收获。
1. 引言
棉花是一种有弹性、透气、吸水、易于染色且可生物降解的天然纤维。这些特性使棉花成为制造业中使用最广泛的天然纤维。其应用涵盖多个领域,包括时尚、医药、化妆品和食品工业等。传统上,棉花种植涉及大规模收获,当棉铃达到成熟时,工业机械会移除整株植物。然后通过轧花将白色的纤维素纤维分离出来。虽然这种方法节省时间,但需要每年重新种植,增加了运营成本,并且由于轧花过程中的高强度机械应力,可能会降低纤维品质。尽管人工采摘能保持更高的纤维完整性,但高昂的劳动力成本通常使其在经济上不可行。
为了应对这些挑战,研究人员正在开发由计算机视觉引导的移动机器人系统,以高效地检测和采摘棉铃。这些系统旨在通过创新的末端执行器模拟人工采摘,同时不损害纤维质量。近年来的研究表明,多年生棉花种植周期可与一年生作物表现相当甚至更好。在多周期内维持植物生长为传统的一年生再植提供了一种更可持续、更具成本效益的替代方案,显著减少了果园的碳足迹和能源消耗。
精确检测是自动化采摘的关键第一步。从计算机视觉的角度来看,优先任务是识别从未成熟到完全成熟的转变,因为纤维仅在完全成熟时完成发育。一旦成熟,棉铃会在较长时间内保持稳定而不会枯萎。这种稳定性是机器人采摘的一个关键优势:如果不确定成熟度,可以将棉铃安全地留在植株上,等待下一周期,而不会退化。
尽管具有重要性,但针对棉铃检测、分割或定位的研究仍然有限,因为大多数文献集中在病害分类上。此外,公开可用的棉铃检测数据集非常稀缺。这一空白为研究检测特定生长阶段的创新方法提供了机会。
早期的研究,例如 Verma 等人对 YOLOv8 模型进行微调以辨别生长阶段,但仅获得了 0.643 的 mAP50。Li 等人提出了一种结合 SLIC、DBSCAN、Wasserstein 距离和随机森林的区域语义分割方法,在田间棉花图像上实现了比最先进算法更高的平均值和更低的标准差的语义标签预测。随后在 2017 年,Li 等人提出了 DeepCotton,这是一种结合全卷积网络和细化算法来去除干扰的田间棉花分割深度学习解决方案。在普通和多植株场景下,DeepCotton 比最先进方法获得了高达 2.6% 的准确率和 8.1% 的 IoU 增益。
在我们初步工作中,我们分析了所提出的棉花作物数据集的早期版本。尽管我们在简单检测上取得了较好的指标,但一般复杂检测的特征提取仍然较低。该数据集缺乏对关键早期生长阶段的表示,特别是最初的苞叶形成和早期开花阶段,而这些对于全面的生命周期监测至关重要。
除了这项初步工作,其他研究对我们案例也存在局限性。Verma 等人的工作准确率低,且缺少完整生长周期表示的类别。Li 等人实现了实例分割,虽然可以很容易地转换为目标检测,但速度太慢且计算成本高。同样的理由也适用于 Li 等人。最近,Gong 等人提出了一项相关研究,利用 YOLOv10-nano 模型检测四个类别:花、部分开放棉铃、完全开放棉铃和有缺陷的棉铃。他们在 mAP50 上比基线提高了 1.3 个百分点,同时将模型复杂度降低了 5.8% 的参数量和 15.2% 的浮点运算量。他们的数据集收集了 2000 张图像,大约标注了 22350 个标签。鉴于其相关性,Gong 等人的工作是我们提出解决方案的主要基准。
除了针对棉花的研究,许多农学计算机视觉研究也通过整合最先进的模块来改进 YOLO 架构,以增强在专门数据集上的性能。
例如,Li 等人修改了 YOLOv7-tiny 用于露天菠萝检测,引入了卷积块注意力模块以改进特征提取,以及内容感知特征重组模块以扩大上采样期间的感受野。通过使用 Scylla IoU 损失函数重新定义惩罚标准,他们在不显著增加计算开销的情况下,将 mAP50 提高了 5.8%。类似地,在苹果园应用中,Liu 等人通过用部分深度卷积和深度可分离卷积替换标准卷积来优化 YOLOv8 架构。通过利用 Efficient IoU,他们保持了与 YOLOv8n 基线相当的性能,同时将参数从 300 万大幅减少到 66 万。
在葡萄栽培领域也有进展报道;Wang 等人将双通道特征提取注意力和动态蛇形卷积集成到 YOLOv5s 中。这些修改使得 mAP50−95 和 mAP50 分别提高了 2.02% 和 2.5%,为葡萄园的非结构化环境提供了必要的鲁棒性。
在番茄种植方面,Deng 等人从 YOLO11 基线开发了 SE-YOLO,整合了 ADown 进行下采样,以及一个 Sobel 边缘检测与特征融合模块来集成边缘信息。此外,他们的 SPStem 模块促进了对小型或遮挡果实的检测,使 mAP50 整体提高了 3.2%。Zhai 等人也通过 TEAVit 应对了环境复杂性,该模型专为绿色番茄检测定制,利用纹理特征提取、上下文语义,并处理背景复杂性和遮挡问题,在其自定义番茄数据集上的所有主要指标都超过了 90%。
基于这些进展,并识别出当前技术水平的局限性,特别是 Gong 等人的工作,本研究追求以下目标:
-
开发一个公开可用的棉花果实数据集,包含代表不同物候阶段的六个类别,并在不同的视角和光照条件下采集。
-
提出一个自定义的 YOLO 架构 COTONET:一个轻量级、以注意力为中心的模型,它集成了最先进的卷积模块,以在复杂的农业场景中优于标准的 YOLO 变体。
2. 数据集概念化
我们想要解决的任务是在复杂的温室环境中,检测处于不同生长阶段的棉花,并能适应天气条件、光照、视觉噪声和遮挡的变化,以便后续进行作物计数和监测。为实现这一目标,我们需要测试一系列通用的、最先进的目标检测模型,并评估它们以确定哪个表现更好。
然而,关于棉铃检测的研究非常少,因此,处于不同生长阶段的棉铃的公共数据集也很少。大多数关于棉花植株的研究都集中在其可能遭受的病害上,正因为如此,我们决定创建自己的数据集,利用我们之前研究中的图像,添加更多图像,更改类别,调整标签,从而创建更完整的棉铃表示。
在构建研究棉花生长的数据集之前,我们首先需要了解不同的生长阶段及其形态。在我们之前的工作中,我们分析了棉花生长的不同阶段,以二元方式区分成熟和不成熟阶段。此外,我们需要知道一个生长阶段何时转变到下一个阶段的界限,以便进行精确标注。我们将使用相同品种的棉花,称为 Intercott-211。
棉花的形态呈现出非常不同的形状:准备收获的棉铃可能或多或少有纤维散布在其表面,纤维呈拉长或圆形,分成三、四或五个部分,纤维可能因被植物其他部分拉扯而伸展。未成熟的开放棉铃有不同程度的开放度,如果它们刚刚开放,可能会被误认为是封闭棉铃;如果它们的苞叶尚未完全变成棕色,可能会被误认为是成熟棉铃。封闭棉铃可能表现为更发育的蒴果或发育较少的蒴果。此外,当棉蕾开始出现时,也会出现一种类似叶片的器官,称为苞叶,它位于未来棉铃的下方。与负责光合作用的普通叶子不同,苞叶支持花朵发育和随后的棉铃生长。当棉铃开放时,苞叶和含有纤维的蒴果开始干燥,苞叶变得坚硬。
正如我们在现有技术中看到的,Verma 等人识别了棉蕾、花、棉铃、未成熟开放棉铃和成熟棉铃,收集了 Kaggle 数据集和智能手机照片的组合。Gong 等人将花、部分开放棉铃、完全开放棉铃和有缺陷的棉铃作为检测类别。在我们的案例中,我们认为区分未受精花和受精花至关重要,因为它们标志着受精的时刻,颜色从灰白色或浅黄色变为粉紫色。这种区分可以让我们对棉铃及其生长状态进行更详细的分析。因此,我们提出了以下类别的概念:
-
0 - “成熟棉铃”:准备收获、完全发育的棉花。
-
1 - “开放棉铃”:未成熟的开放棉花。
-
2 - “棉铃”:未开放的棉铃,处于花落后到棉铃完全长大的阶段之间。
-
3 - “受精花”:已受精的棉花花朵,颜色为粉红至紫色。
-
4 - “早期花”:未受精的棉花花朵,颜色为灰白色至浅黄色。
-
5 - “苞叶”:花朵开始生长的第一片小叶子。
区分开放棉花和成熟棉花至关重要;然而,了解其他类别何时过渡到下一个状态也同样关键。为此,根据 CEBAS-CSIC 人员提供的棉花物候学专业知识,我们建立了以下标准:
-
“蕾”到“早期花”:花蕾打开,白色至淡黄色的花瓣出现并迅速展开。
-
“早期花”到“受精花”:花朵开始呈现粉紫色调,这意味着花朵已经授粉。
-
“受精花”到“棉铃”:花朵凋落,只剩下叶片包裹正在形成的棉铃。一个微小的绿色蒴果出现。
-
“棉铃”到“开放棉铃”:棉铃达到最大尺寸并开始开放。白色纤维开始从其中露出,变得可见。
-
“开放棉铃”到“成熟棉铃”:包裹棉铃的外壳完全打开,围绕它的苞叶干枯,颜色从深绿色变为棕灰色。
一旦我们构建了可区分的类别,我们就能够收集一组图像,其中展示了棉铃、棉花花朵和棉蕾的不同示例。标注过程使用 LabelImg 软件进行。从现在起,我们将此棉花数据集称为 CONDIS++。
2.1. 数据集属性
图像拍摄条件与之前的研究相同。照片使用 15 MP 智能手机相机拍摄,距离植物 50 厘米到 1 米。数据集包含高清照片,以及展示同一时刻植物生长阶段多样性的全景视图。成像时间为 6 月至 7 月,上午 10 点至中午 12 点之间。棉花植株位于一个 500 平方米的聚碳酸酯温室内。温度范围从夜间 20°C 到白天 32°C,白天相对湿度 50%,夜间 85%。成像时没有遮阳网。

图 2 展示了 CONDIS++ 中不同的光照条件、视角和视觉特征。我们希望创建一个多样化的数据集,包含与田间相同的条件。对于 CONDIS++ 的所有类别,数据集包含清晰的特写镜头、被其他棉铃或叶子遮挡的视图、垂直于植物的视图、不同距离的角度拍摄、具有高细节度的各种距离拍摄,以及差异化的光照条件。CONDIS++ 中包含的自由度使得果园中发现的环境条件具有完全的代表性。

最终,拍摄照片的目的是捕捉不同阶段棉花形状的最大代表性,以及不同的光照和遮挡条件。我们看到,获得每个类别的逼真表示,并有足够的样本来概括棉花形态,是一项复杂的任务。因此,为每个类别获取大量图像至关重要,尤其是那些表现出多样化形态的类别,从而能够开发出一个专业且抽象视角的模型,该模型忽略对表示不重要的细节,并学习棉花生长阶段的关键特征。
2.2. 数据增强
由于训练图像数量较少,并且考虑到我们要检测的类别的复杂性,必须通过人工方法生成新图像。有许多方法可用于处理图像并为模型训练生成新图片,但我们只探索其中一部分。由于温室中存在多种光照和遮挡条件,影响棉铃的外观,主要重点是通过应用图像变换技术来增加数据集规模。
我们将选择不会过度改变图像颜色属性的简单技术,因为任何超出集合分布的变化都会导致检测精度降低。因此,我们将执行简单的几何变换以及颜色属性的轻微变化。为此,提出的技术包括:旋转、翻转、随机裁剪、随机遮挡和颜色增强。这些变换通过提供更多视角来专门研究棉花作物的特性,从而帮助网络。所有增强技术均使用 Albumentations Python 库实现。
3. 目标检测评估概念
为了评估模型在 CONDIS++ 上的性能,将使用召回率和精确率指标:

其中 TP、FP 和 FN 分别指模型检测到的真正例、假正例和假负例的数量。召回率衡量模型在图像中捕获所有相关目标的能力。精确率量化模型做出的正面预测的准确性。
另一个关键概念是交并比,它是预测边界框与真实边界框之间的重叠面积比例: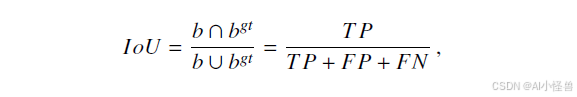
其中 b 和 b_gt 是预测框和真实框。
定义了 IoU 之后,我们可以讨论平均精度和平均精度均值: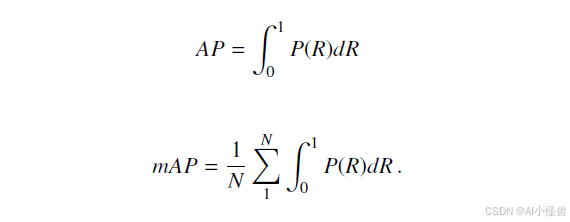
给定类别数 N。每个类别的平均精度是针对给定的交并比阈值,通过精确率-召回率曲线计算得出的。mAP50 是 IoU = 0.5 时的平均精度均值,与“简单检测”相关;mAP50-95 是 IoU ∈ [0.5, 0.95] 范围内,步长为 0.05 时的平均精度均值,与一般检测性能相关,同时考虑了困难检测。
模型的复杂度通过参数量和每秒浮点运算次数来计算,预测的延迟由模型可以计算的每秒帧数给出。对于卷积模型的某一层 L:
其中,C_in 是输入通道数,C_out 是输出通道数,(K_h, K_w) 是卷积核大小,(H_out, W_out) 是输出特征图的高度和宽度。这些公式适用于每个卷积层,因此需要对模型的每一层进行计算。
4. 提出的模块与边界框损失函数
基于当前在 COCO 2017 上的目标检测模型基准测试以及先前综述的文献,YOLO 系列模型在多功能性、易用性、轻量化和 mAP50 精度之间提供了最佳平衡。我们选择 YOLO11 作为起点,因为它架构简单且很少使用注意力机制。选择最适合我们案例研究的架构至关重要,因为这一步能提供最佳精度。我们正在测试最先进的模块和注意力机制,以增强特征提取和细化,从而获得更好的整体指标。本研究的目标是创建一个轻量级但鲁棒的、自定义的类 YOLO 架构,以便部署在移动机器人平台上。
最先进的研究表明,没有一种特定的架构适用于所有问题,但某些卷积块和注意力的组合有助于塑造作物的形状、颜色和其他特性,增强特征提取,实现更好的检测。我们的目标是证明 COTONET 是检测各个生长阶段棉铃的最合适模型。
4.1. 压缩激励与 SEConvBlock
为了改善颈部特征图的细化,我们在每个卷积块后使用压缩激励。SE 模块对通道间的相互依赖关系进行建模,以自适应地重新校准通道级特征图。图 3 展示了 SE 模块的直观表示。
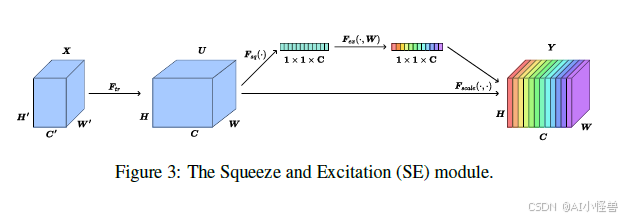
由于 SE 可以放在卷积变换之后,我们假设在该模块之前有一个操作,该操作将给定的特征图 X ∈ R^{H′×W′×C′} 转换为 U = [u₁, u₂, ..., u_C] ∈ R^{H×W×C}。压缩操作通过应用逐通道全局平均池化来利用通道依赖性,获得一个通道描述符。结果是针对 U 中每个通道 C 的一个统计量 z ∈ R^C。
随后,激励操作包括一个自适应重新校准,使网络能够学习通道之间的非线性、非互斥的交互,允许多个通道被强调。这是通过应用门控机制实现的。
最后,使用先前获得的激活 s 对中间特征图 U 进行重新缩放。
SE 应用于骨干网络卷积块的末端,因此它成为一个压缩和激励的卷积块。我们称这种联合为 SEConvBlock。这种组合有助于为卷积块添加最小限度的轻量级注意力,帮助在学习了先前棉花实例的表示后,聚焦于相关区域。
4.2. 注意力机制
由于 CONDIS++ 的类别可能呈现多种形状,难以检测和相互区分,特别是在光线、光学模糊或其他元素改变场景时,注意力是关键。模型必须学习棉花在所有生长阶段中最通用的表示。因此,我们特别重视注意力模块。
YOLO11 在其骨干网络末端利用了 C2PSA 模块,聚焦于相关图像区域,增强对小部分和遮挡实例的注意力,并在输出特征图中强调空间相关性。在我们的案例中,该模块被每个 C3k2 骨干瓶颈后的简单注意力模块所取代。SimAM 提供通道和空间维度的注意力,且不增加梯度,计算量小,计算特征图中每个神经元的重要性。作为一个轻量且快速的模块,它非常适合我们的研究案例。
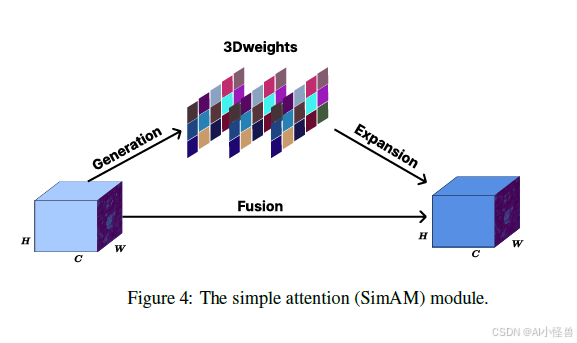
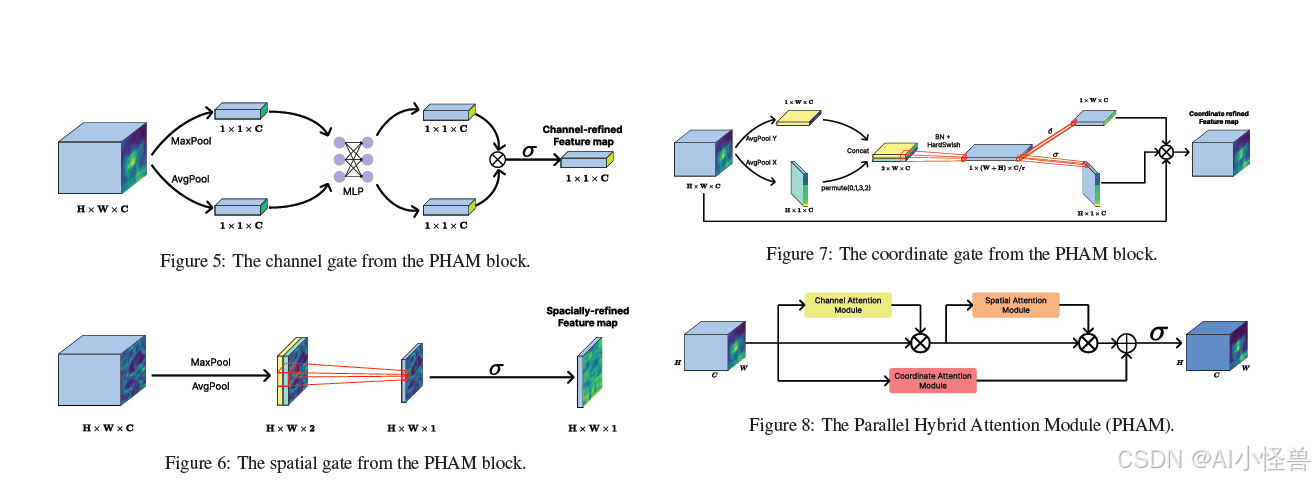
此外,在颈部的 C3k2 瓶颈之前添加了并行混合注意力机制模块,以传递经空间、通道、坐标改进的特征图。通过使用 PHAM 模块进行后处理步骤,我们获得了信息更丰富的特征图,其中图像的相关区域得到了增强。尽管 PHAM 在参数量和计算量上比 SimAM 重,但它为输入特征图提供了局部和非局部的特征计算,并减少了无关背景信息的权重输入。
-
简单注意力模块:SimAM 是一个简单而有效的注意力机制,它专注于 3D 注意力,且不向网络添加参数。这个无参数注意力模块为每个神经元分配 3D 权重,并通过受空间抑制启发的能量函数计算每个神经元的相关性。SimAM 建立了一个能量优化问题,其中目标神经元 t 必须是可区分的,而周围的神经元被抑制,基于以下能量函数测量一个神经元与其他神经元之间的线性可分性,从而获得 w_t、b_t 的快速闭式解。假设单个通道中的所有像素遵循相同的分布,我们得到神经元 t 的较低能量 e^*_t。每个神经元的重要性被计算为 1/e^*_t,因此输出特征图应用为 X * 1/E。
-
并行混合注意力机制:PHAM 允许以最小的计算成本细化中间特征图,适用于大多数前馈视觉模型。在实践中,PHAM 通常被添加到骨干网络中以获得更好的特征提取,但我们想测试不同的位置,看看该模块在何处更有效。
PHAM 由一个连接到坐标门的卷积块注意力模块组成。更具体地说,PHAM 由一个通道门、一个空间门和一个坐标门构成。其目标是细化输入特征图,以从通道、空间和坐标的关系中提取信息。在图像中,该模块增强了什么是重要的,相关性在哪里,以及长程关系。
如图 5 所示,给定输入特征图 X ∈ R^{H×W×C},通道注意力模块首先计算 F 的全局最大池化和全局平均池化通道描述符,并将其馈送到一个由两层组成的多层感知机中,层间有 ReLU 激活。之后,一个张量与另一个逐元素相加,并应用 sigmoid 函数。结果,我们获得了通道注意力 M_c,它与原始特征图逐元素相乘,得到通道细化特征 X_c。
X_c 随后被传递到空间注意力模块,该模块计算空间维度的全局最大和平均池化描述符,并将它们拼接起来,产生一个形状为 H×W×2 的张量。它被馈送到一个卷积块中,最后应用 sigmoid 函数。产生的空间聚焦特征图 M_s(X) 然后与 F_c 逐元素相乘,以计算通道和空间细化的特征图 X_cs。
同时,X 被传递到坐标注意力模块。该模块将通道注意力分解为两个一维特征编码过程,这些过程结合了各个方向的特征。在宽度和高度维度上执行平均池化,获得 X_w 和 X_h,将它们拼接起来,通过一个 2D 卷积、批归一化和 hard swish 激活以获得非线性,从而得到一个维度为 R^{C/r×1×(W+H)} 的特征图。然后应用两个并行的 2D 卷积,加上 sigmoid 激活,以获得两个特征图 X′_w 和 X′_h。因此,X、X′_w 和 X′_h 相乘,得到坐标注意力模块的输出特征图 X_coord。
最后,PHAM 操作被描述为 Y = δ(X_cs ⊕ X_coord)。
4.3. 上采样算子
YOLO11 使用缩放因子为 2 的上采样操作,并采用最近邻作为上采样算法。虽然此操作速度很快,但它不添加可学习参数,可能会丢失来自先前卷积的信息,扰乱特征图之间的梯度关系。为解决此问题,我们使用 CARAFE 替换了上采样操作。CARAFE 扩大了视野,聚合了上下文信息,并增加了实例特定的内容感知处理。该解决方案为整个模型增加了极小的开销,使特征图的高度和宽度加倍而不减少通道数,完美地替代了传统的上采样算子。
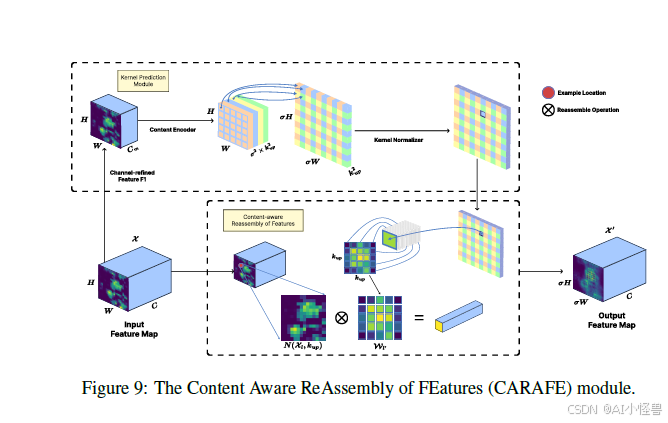
CARAFE 由核预测模块和内容感知重组模块组成。KPM 由一个通道压缩器、一个内容编码器和一个核归一化器构成。
给定一个形状为 H×W×C 的特征图 X 和因子 σ = 2,CARAFE 将产生另一个形状为 σH×σW×C 的特征图 X′。位置相关核 W_l′ 由 KPM 模块计算,输出特征图 X′ 由 CARM 模块计算。首先,通道压缩器接收一个维度为 H×W×C 的特征图并进行卷积,以将通道数从 C 压缩到 C_m,使后续计算成本更低。然后,C_m 被传递到内容编码器,它应用一个卷积层。最后,核归一化器对每个重组核应用空间 softmax 操作。
CARM 模块通过 φ 在一个局部区域内重组特征,φ 使用来自内容编码器的位置相关核 W_l′,取输入特征图 X 中某个像素 l 的关于核 k_up 的邻域。使用 CARAFE 作为我们的上采样算子,我们以增加少量开销为代价,实现了内存和延迟的效率,并赋予上采样操作可学习的能力。
4.4. 下采样算子
尽管 YOLO11 在颈部、检测头之前使用常规卷积块进行下采样,但该块添加的参数数量呈指数增长,并且给定具有大量通道的输入特征图,它可能成为效率和轻量化的巨大瓶颈。为解决此问题,我们提出了 SCDown 模块,此前在 YOLOv10 中使用过。该模块通过先用 1×1 核减少通道数,然后应用可分离的深度 k×k 卷积来减小特征图的高度和宽度,从而解决了与并行卷积核相关的高计算成本。
该模块由两部分组成:一个逐点卷积和一个深度可分离卷积。
4.5. 边界框损失函数的改进
YOLO11 对边界框使用 CIoU 损失,对类别损失使用二元交叉熵,对类别不平衡使用分布焦点损失。
对于新的边界框损失,我们提出用 Scylla IoU 替代默认的 CIoU。SIoU 考虑了成本的四个方面:角度、距离、形状和 IoU 成本,而 CIoU 仅计算距离、形状和 IoU。添加角度成本的核心思想是告知模型真实框指向的方向,所以我们不仅告知距离,还给出了从预测到真实框在 x 和 y 坐标轴上的相对距离。
-
角度成本 Λ 被分解为相关公式。
-
距离成本 Δ 被公式化。
-
形状成本 Ω 被定义,其中 θ 定义了形状成本对整体计算的相关性,实验上 θ 定义在 2 到 6 之间。
最后,SIoU 损失表示为 L_box = 1 - IoU + (Δ + Ω) / 2。
5. 提出的 YOLO11 修改
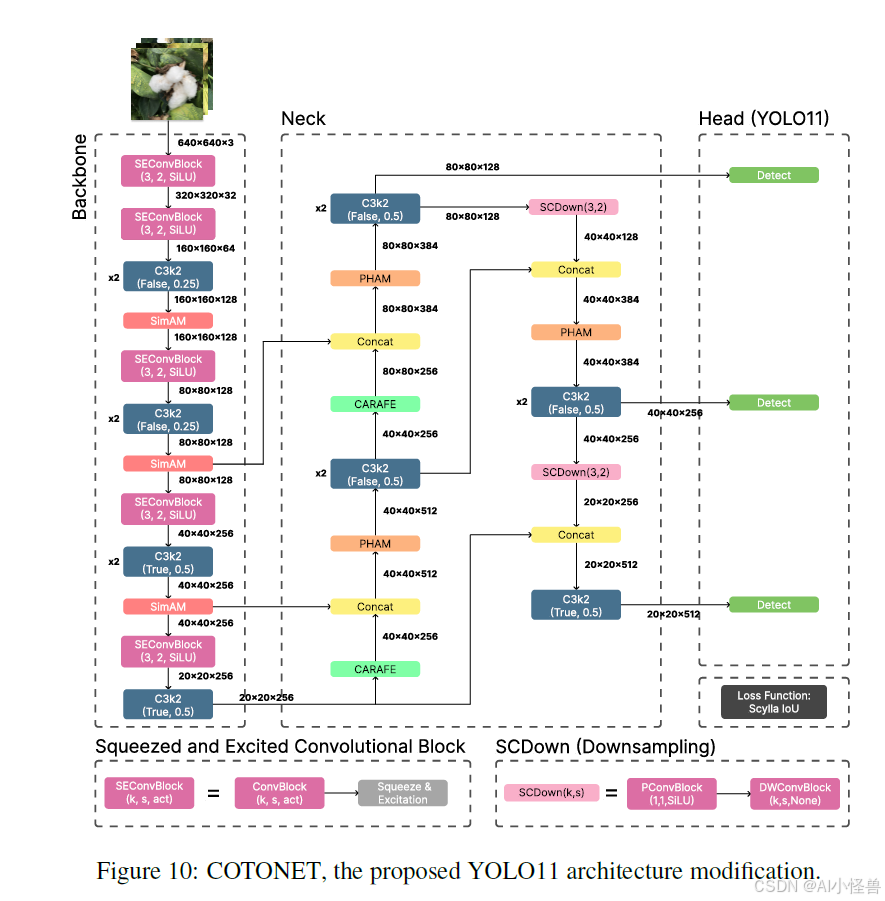
在研究了最先进的技术以及其中主要的卷积块、注意力机制和损失函数之后,我们提出了一个对 YOLO11 的修改,我们称之为 COTONET。网络的主要变化是在骨干网络的卷积块中添加了压缩激励,使用 SimAM 和 PHAM 作为主要的注意力模块,以及使用 SCDown 作为颈部下采样阶段的下采样器。边界框损失也被修改了,用 SIoU 替换了 CIoU。
6. 实验
一旦新模型的结构确定下来,我们就要评估解决方案的鲁棒性和可靠性,确保没有其他组合比为本案例研究所选的组合更合适。因此,我们必须对描述的每个模块和技术进行消融研究,以确保其有效性优于原始解决方案和其他可能的解决方案。
为实现这一点,我们将对 COTONET 进行修改,执行系统训练,并比较在精度和计算成本方面获得的指标。要进行的实验是:
-
对 CONDIS++ 上的人工增强技术进行比较分析。我们从 CONDIS++ 构建了不同的数据集,并对其训练集进行人工增强。我们用每个获得的数据集训练 COTONET,并比较获得的指标。我们选择了那些在数据集上能提供更大模型学习泛化能力的技术。
-
使用增强后的 CONDIS++,对标准 YOLO 模型和 COTONET 的验证指标进行比较分析,范围从 nano 到 medium 大小。
-
对为最终模型选择的关注模块进行消融研究。具体来说,我们对以下方面执行消融测试:
(a) 压缩激励,目的是证明在卷积块后添加它能提供相当程度的特征图细化。将比较无注意力的 ConvBlock、带 SE 的 ConvBlock 和带 ECA 模块的 ConvBlock 的指标。
(b) COTONET 的主要注意力机制,目的是证明它们对特征图中值的相互依赖性进行建模,为后续检测重要的区域提供更好的聚焦。我们将比较无注意力、使用 SimAM、使用 PHAM 以及同时使用两者的情况。 -
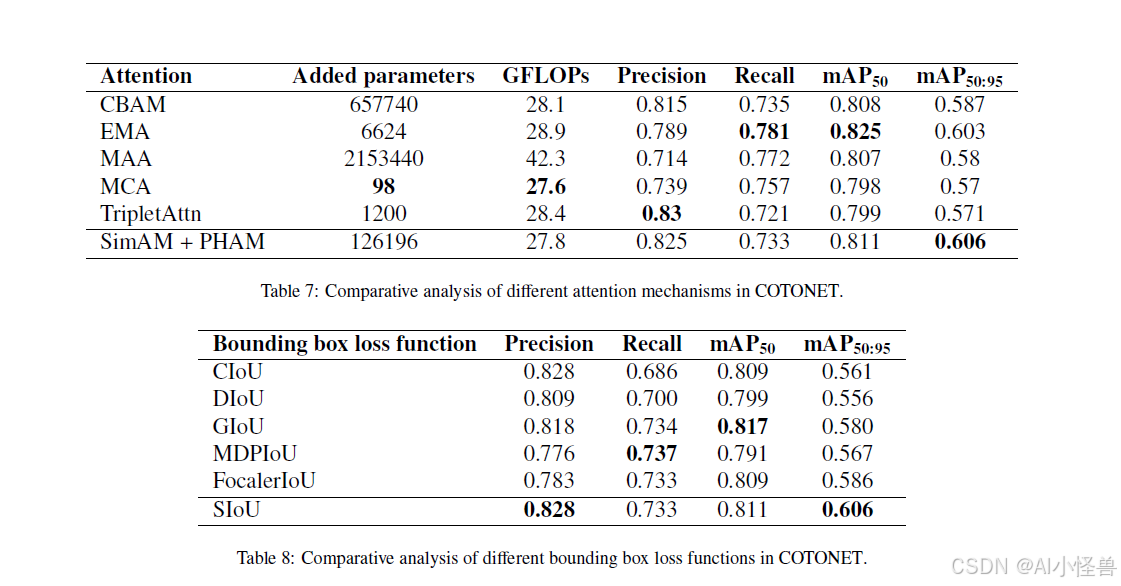
通过将所使用的注意力方法替换为其他最先进的方法进行比较分析,目的是验证所选模块对于我们问题是最合适的。这些方法包括:CBAM、EMA、MAA、MCA 和 Triplet Attention。
-
边界框损失函数研究,比较 YOLO11 中的默认损失函数与文献中的其他损失函数以及所提出的边界框损失函数。
7. 实验结果
表 1 显示了本地服务器的硬件和软件规格,表 2 显示了下面分析的所有模型训练的超参数配置。正如我们在第 3 节中提到的,以下结果的分析主要以 mAP50 作为我们的主要指标,因为它能很好地指示检测效果,特别是对于难以检测的棉铃。mAP50-95 是我们的第二个模型性能指标,提供关于简单检测执行情况的信息。
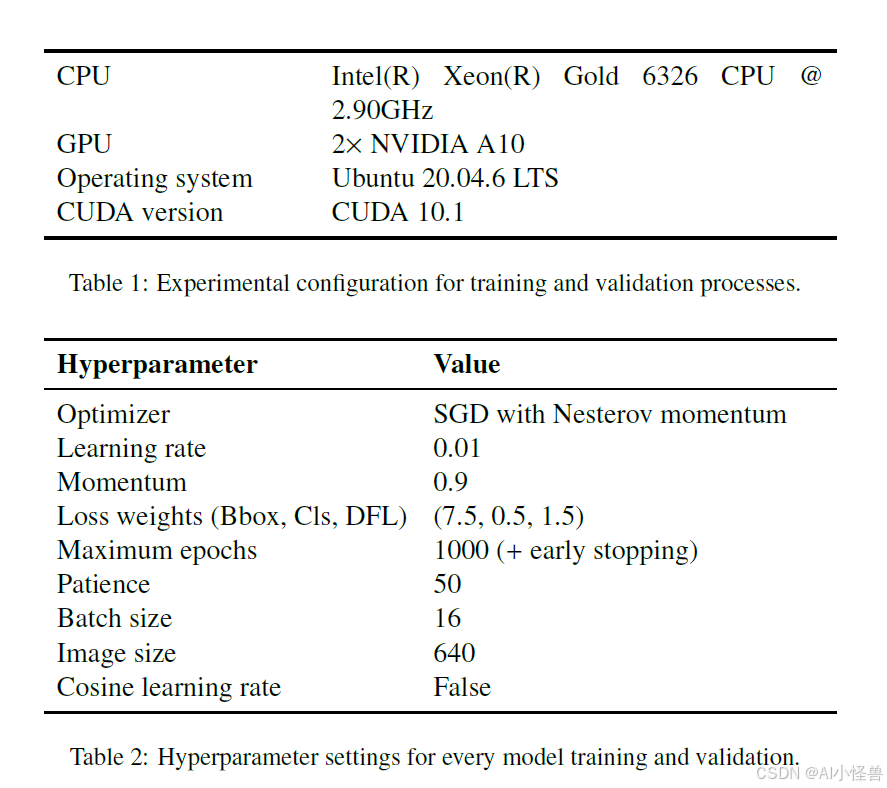
7.1. 数据增强
为了了解不同数据增强技术组合的效果,我们从一系列我们认为适合实现棉花特性及其在温室内表型表达的更大泛化能力的增强开始,考虑到我们所处的环境和光照条件。旋转、翻转以及图像色彩饱和度和色调的变化都是测试的对象。
使用 COTONET,我们将数据增强单独应用于 CONDIS++,并使用我们认为可以很好协同工作的技术子集。表 3 显示了 COTONET 在使用 CONDIS++ 增强变体时的训练结果。指标显示数据增强技术对模型在棉花数据集上的性能有明显影响。简单的几何变换表现出互补的行为:旋转获得了最高的召回率,表明对正实例的检测更好,而翻转有利于精确率,反映了两个指标之间的折衷。
基于内容修改的策略,如随机裁剪和随机遮挡,提高了精度但降低了召回率,可能是由于上下文信息的丢失。相比之下,光度变换,特别是色彩增强,保持了更稳定的平衡,并在单个技术中显示出最一致的平均精度值。
旋转+翻转组合成为最佳配置,达到了 mAP50 和 mAP50-95 的最佳值。这个结果表明,联合空间多样化比单一技术更有效、更鲁棒地提高了模型的泛化能力。
7.2. 提出模型的比较
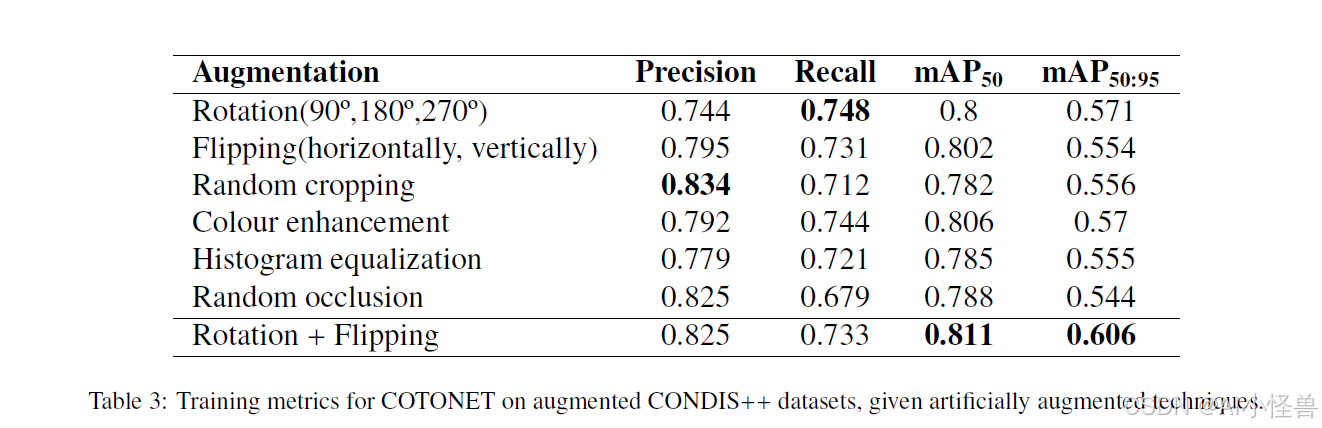
为了证明模型的有效性,我们对所有中小型 YOLO 模型进行了基准测试,并将它们与 COTONET 的指标进行比较。表 4 显示了所有从 nano 到 medium 尺寸的标准 YOLO 模型以及 COTONET 在增强后的 CONDIS++ 上的检测指标。
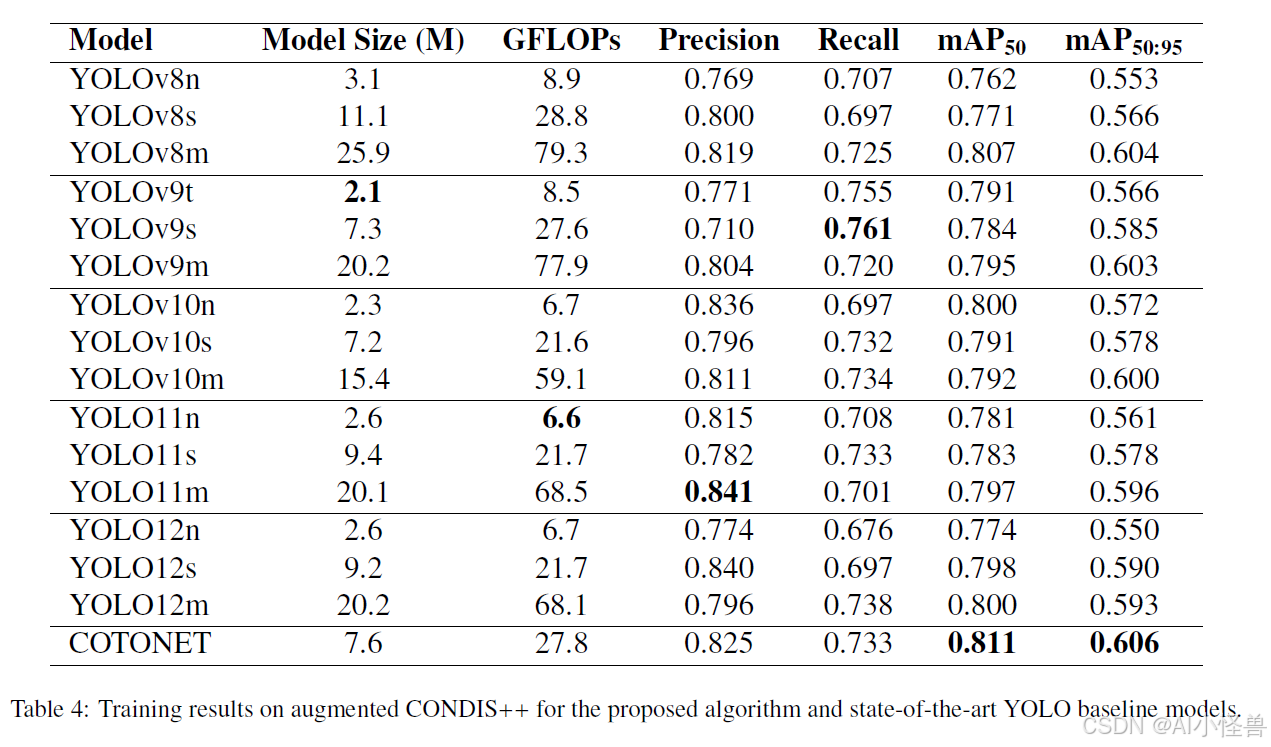
表 4 显示基线 YOLO 模型遵循计算成本和性能之间的相关性。我们可以看到,较大的变体往往能获得更好的预测精度,但同时也显示出训练和执行这些模型的高计算成本,超出了移动机器人平台的部署限制。另一方面,较小的模型在某些特定指标上表现突出。
COTONET 在简单检测和总体检测上达到了最高的精度,分别为 0.811 和 0.606,超过了所有基线模型,减少了参数量,同时计算量略有增加。我们可以得出结论,模型复杂性并不能保证更好的结果,而是资源的明智分配、卷积块以及注意力机制的安排,以最大化视觉信息提取的方式,才是关键。COTONET 在精确率和召回率之间保持了良好的权衡,综合考虑所有指标,我们可以得出结论,与标准的 YOLO 变体相比,所提出的架构提供了最佳的性能-计算成本比。
7.3. 轻量级注意力模块比较分析
本文的贡献之一就是 SEConvBlock。为了证明其有效性,我们将相同的概念与其他类似 SE 的注意力块进行了比较。我们使用无注意力作为对比,并添加 ECA 来构建 ECAConvBlock。
这个比较分析的结果可以在表 5 中找到。我们看到 SE 提供了最高的精确率和 mAP50-95,同时在召回率和 mAP50 上损失了一些点。我们得出的结论是,压缩激励以最小的参数开销提供了最佳的精度。总之,我们发现 SEConvBlock 比基础卷积块有所改进。
7.4. 注意力模块消融研究
我们进行了一项消融研究,以查看所提出的注意力机制是否有效。在这个实验中,我们将注意力模块替换为恒等操作。针对每种可能的组合训练 COTONET 后,表 6 显示,向架构中添加注意力机制会影响模型的性能。尽管注意力机制减少了预测实例的数量,但 SimAM 和 PHAM 的组合在测试配置中提供了最佳的敏感性。对表格的深入分析表明,SimAM 主要负责精确率的提升。SimAM 也略微提高了平均精度指标,提出了更具判别性的特征表示。PHAM 增加了模型复杂性,但提高了 mAP50,表明在较低和限制较少的 IoU 阈值下检测更好。SimAM+PHAM 组合提供了最佳的整体行为,具有更高的精确率和更高的 mAP50-95。我们可以得出结论,PHAM 和 SimAM 是互补的,SimAM 在不增加计算量的情况下提供了预测的一致性,PHAM 则加强了空间相互依赖性的建模。指标的提升证实了集成两种注意力机制允许一个更鲁棒的配置,仅轻微增加了复杂度。
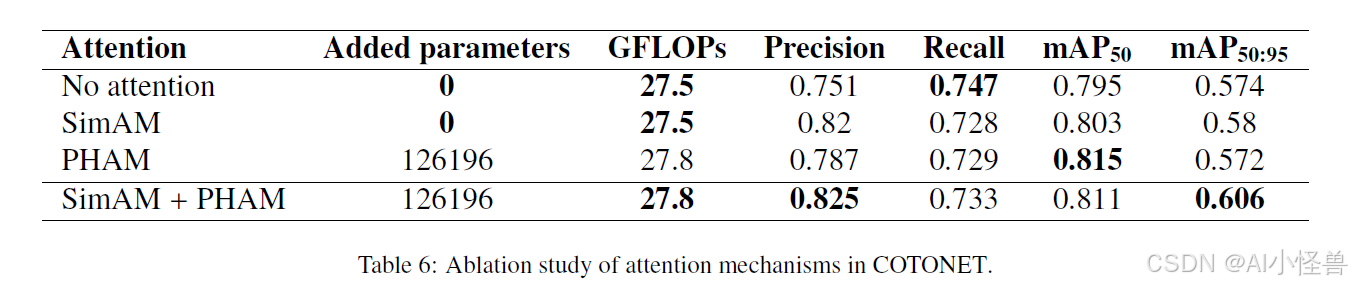
7.5. 边界框损失函数研究
我们想要测试第 6 节中提出的不同损失函数。鉴于默认的边界框损失函数是 CIoU,我们想看看 SIoU 是否能建立一个信息更丰富的模型,以及是否有任何其他损失函数能提供更多信息。
表 8 显示了使用 CONDIS++ 和不同边界框损失函数训练的 COTONET 的指标。经典公式表现出有竞争力的精度值,但在召回率和 mAP50-95 指标上显示出局限性,表明在高 IoU 值下缺乏鲁棒性。GIoU 在精确率和召回率之间提供了更好的平衡,获得了更高的 mAP50 值,但同样,在高 IoU 阈值下缺乏准确性。对于 MDPIoU 和 FocalerIoU,召回率优先,但未能在 mAP 上实现一致的改进。这些结论表明,正面检测的增加并不总能转化为更好的空间精度。
基于 SIoU 的配置被证明是最有效的,精确率和召回率都很高,并且在 mAP50 和 mAP50-95 上取得了最佳结果。这种行为表明在各种 IoU 阈值下定位更一致、更准确,展示了改进的框的几何和空间一致性建模。总的来说,研究结果表明,在所评估的架构中,SIoU 提供了检测性能和定位可靠性之间的最佳平衡。

7.6. 原始检测分析
为了直观地辅助表 4 的结果,我们分析了同一张表中表现最好的 5 个模型之间的比较。图 11 显示了 COTONET 以及 YOLOv8、YOLOv9、YOLOv10、YOLO11 和 YOLO12 的 medium 变体对相同图像的预测。这些检测显示,对于所有类别,COTONET 的准确性都优于对比算法。
在第一张图中,YOLOv10m 对预测框显示出更好的准确性,但漏掉了 COTONET 检测到的成熟棉铃。在第四张图中,YOLOv10m 混淆了右侧棉铃的类别。这些例子表明 YOLOv10 在区分类别上有困难,特别是对于非常相似的类别,有时产生的预测置信度低于 COTONET。
我们可以看到比较的基线 YOLO 模型存在一些类别混淆和幻觉。我们可以得出结论,COTONET 优于基线 YOLO 模型,能正确分类每个预测,并且在 CONDIS++ 上不会对数据产生幻觉。
8. 结论与未来工作
本研究提出了对 YOLO11 框架的若干架构修改,集成了两个纯注意力模块、一个组合卷积和轻量级注意力模块,以及一个用于梯度感知上采样的先进 CARAFE 算子。此外,还实现了 SIoU 损失函数,以创造一个信息更丰富的学习过程。实验结果表明,与基线相比,这个自定义模型在 mAP50 和 mAP50-95 上均实现了卓越的精度。此外,该模型在相关图像区域表现出改进的特征定位,从而显著增强了棉花检测性能。
如果我们将获得的结果与 Gong 等人的研究进行比较,我们看到,基于一种方法,CONDIS++ 是良好规范且从表型角度进行了情境化的,区分了不同的生长阶段,以及蒴果发育中的关键变化状态,如花朵授粉。我们还涵盖了重要的环境变化,这增加了模型的鲁棒性。COTONET 改进了对细微生长阶段的检测能力,结合获得的指标,我们看到它可以在更复杂的任务中更好地泛化。此外,Gong 等人未提供不同 IoU 值下的精度信息,因此我们不知道其在困难检测中的准确性。Gong 等人的研究为其定制模型和数据集取得了更好的指标,但他们在类别概念化方面表现出知识匮乏,建立的类别不能提供有洞察力的信息。我们认为我们对棉花生长阶段类别的分类为后续的田间部署提供了更全面的表示。
最后,获得一个能够适应棉花植株固有复杂性的灵活模型,对于精确监测和最大化收获生产力至关重要。为了实现高细节种植园分析的目标,未来的工作将涉及将所提出的目标检测算法集成到一个移动机器人平台中。该解决方案将配备一个带有专门设计的夹持器的机械臂,旨在在不损害其物理特性的情况下采摘棉纤维。集成系统将负责自主种植园维护、监测棉铃成熟度以及选择性采摘成熟果实。为了进一步完善性能,数据集将扩展以包含更多样化的生长阶段,减少假阴性,并确保机器人能够可靠地区分成熟和未成熟的棉铃。持续跟进目标检测的最新进展将始终是确保自动化收获中最高可能精度的首要任务。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 9
9 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)