用AI写代码只是开始:我如何用Agent自动重构了10万行祖传代码
标签: AI Agent / 代码重构 / LLM / Claude / 工程实践 / 祖传代码
阅读时间: 约 20 分钟
前言:那一个让人绝望的下午
2025年初,我刚加入一家成立了7年的互联网公司,接手了一个"战略级"核心业务系统。项目经理兴奋地告诉我,这是公司最重要的订单处理服务,支撑着每天数百万笔交易。
然后我打开了代码仓库。
src/
├── OrderService.java # 4800行,没有注释
├── Utils.java # 3200行,方法命名如 doThing2()
├── Helper.java # 2100行,"临时"写于2017年
├── DataProcessor.java # 1800行,充斥着 TODO: fix later
└── ...(共312个文件)
一个函数叫 processOrderV3Final_REALLY_FINAL(),里面嵌套了17层if-else,引用了全局静态变量,注释写着"别动这里,会爆炸"。单元测试覆盖率:3.2%。
这就是典型的祖传代码(Legacy Code)——它能跑,但没人真正理解它;它很重要,但没人敢动它。
接下来的3个月里,我没有选择"重写"这条路(风险太大),也没有选择"忍着用"(技术债越欠越多)。我选择了第三条路:用AI Agent系统性地、自动化地重构它。
最终结果:10万行代码,历时11周,在不停机的前提下完成了系统性重构,测试覆盖率从3.2%提升到71%,平均函数复杂度下降了64%,线上Bug率下降了43%。
这篇文章,我想完整复盘这套方法论。
一、先搞清楚:AI写代码 vs AI Agent重构,有什么本质区别?
很多人用过 GitHub Copilot 或者 ChatGPT 写代码。这类工具的模式是:你提问 → AI给出代码片段 → 你复制粘贴。
这是"AI辅助",本质上是把AI当成了一个高级自动补全工具。
而我说的AI Agent重构,完全是另一个量级:
| 维度 | AI辅助写代码 | AI Agent重构 |
|---|---|---|
| 上下文范围 | 当前文件/函数 | 整个代码库的依赖图谱 |
| 执行方式 | 单次问答 | 多步骤自主规划与执行 |
| 人工干预 | 每步都需要人确认 | 大量步骤自动化,关键节点人工审核 |
| 输出粒度 | 代码片段 | 可执行的差异化提交(PR/commit) |
| 对错误的处理 | 报给你,你来修 | 自动检测→尝试修复→重新验证 |
| 适用规模 | 单文件/百行 | 数万行~数十万行 |
Agent的核心能力是"Plan-Act-Observe"循环:像一个有经验的工程师那样,先理解全局,制定计划,然后分批执行,每一步执行后观察结果,决定下一步怎么走。
二、祖传代码的七宗罪:Agent要解决什么问题?
在设计Agent策略之前,我对整个代码库做了一次系统性扫描,归纳出最常见的7类问题:
1. 超长函数(Long Method)
最极端的案例:一个 syncInventory() 函数,1247行,承担了网络请求、数据清洗、业务校验、数据库写入、消息推送等完全不相干的职责。
2. 重复代码(Duplicated Code)
同样的"日期格式化"逻辑,在代码库中找到了23个副本,每个实现细节略有不同,导致线上出现过因时区处理不一致而造成的数据错误。
3. 魔法数字(Magic Numbers)
// 这是什么意思?为什么是86400000?
if (timeDiff > 86400000) {
triggerExpiry();
}
类似这样的"神奇数字"在代码库中出现了340+次。
4. 死代码(Dead Code)
大量被注释掉的代码块、从未被调用的函数、标记了 @Deprecated 却从未删除的类。经扫描,死代码约占总量的 11%。
5. 过深嵌套(Deep Nesting)
平均嵌套深度超过6层,最深的达到11层。人类阅读这种代码时,大脑需要维护的"括号栈"超过工作记忆上限。
6. 错误的抽象(Wrong Abstraction)
大量Utils、Helper、Manager类,实际上是"杂物抽屉"——什么都往里放,内聚性为零。
7. 缺失测试(Missing Tests)
3.2%的覆盖率意味着:每次修改代码,你都是在盲目飞行,不知道改动会不会破坏什么东西。
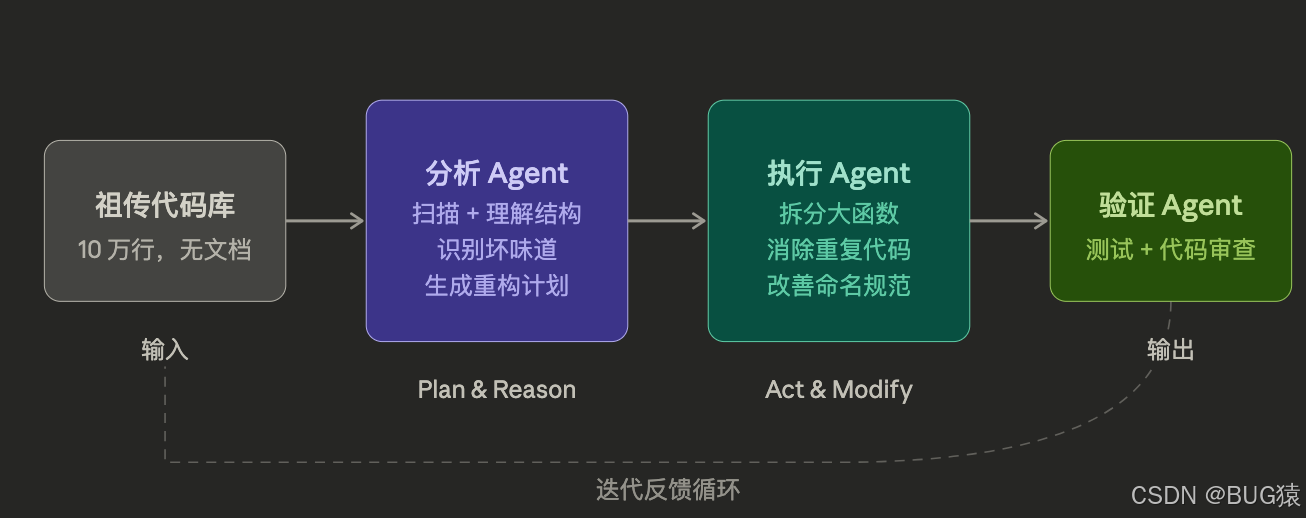
三、系统架构:我搭建的三层Agent体系
面对以上七类问题,一个Agent显然不够用。我设计了一个三层协作的Agent体系:
┌─────────────────────────────────────────────┐
│ 编排层 Orchestrator │
│ 负责整体任务拆分、优先级排序、风险评估 │
└──────────────┬──────────────────────────────┘
│
┌──────────┼──────────┐
▼ ▼ ▼
┌────────┐ ┌────────┐ ┌────────┐
│分析 │ │执行 │ │验证 │
│Agent │ │Agent │ │Agent │
└────────┘ └────────┘ └────────┘
│ │ │
└──────────┴──────────┘
│
┌──────▼──────┐
│ 工具层 │
│ AST解析/Git │
│ 静态分析/测试 │
└─────────────┘
分析 Agent(Analyst Agent)
职责:读懂代码,不修改任何东西。
它使用以下工具:
read_file:读取源文件run_static_analysis:运行 Checkstyle/SonarLint 等静态分析工具build_dependency_graph:构建函数/类的调用关系图calculate_metrics:计算圈复杂度(Cyclomatic Complexity)、内聚度等指标
输出是一份结构化的 重构计划(Refactoring Plan),以 JSON 格式描述每个重构任务的:优先级、影响范围、风险等级、建议的重构手法。
执行 Agent(Executor Agent)
职责:根据计划,逐个执行重构操作。
核心原则:每次只做一件事,每次改动必须可回滚。
它的每次执行是一个原子操作,对应到 Git 中就是一个独立的 commit,commit message 由 Agent 自动生成,格式为:
refactor(OrderService): extract validateOrderItems() from processOrder()
- Extracted 78-line validation block into standalone method
- Reduces processOrder() complexity from 34 to 21
- No behavioral changes, pure structural refactoring
验证 Agent(Validator Agent)
职责:每次执行 Agent 提交改动后,立即验证。
验证包含三个层次:
- 编译验证:确保代码能编译通过
- 测试验证:运行现有的单元测试和集成测试(哪怕只有3.2%,也要跑)
- 行为等价验证:使用快照测试(Snapshot Testing)对比改动前后关键接口的输出
如果验证失败,验证 Agent 会生成失败报告,执行 Agent 会自动尝试修复,如果3次修复仍失败,则将任务标记为"需要人工介入"并通知我。
四、实战流程:11周的完整作战日志
第1-2周:侦察阶段——让Agent读懂代码库
这两周我没让任何 Agent 修改一行代码。我的目标只有一个:让 Agent 建立起对整个代码库的"认知地图"。
构建代码调用图
# 使用 tree-sitter 解析 Java AST,构建调用关系图
import tree_sitter_java as tsjava
from tree_sitter import Language, Parser
def build_call_graph(repo_path: str) -> dict:
"""
遍历所有 .java 文件,提取方法调用关系
返回格式: { "ClassName.methodName": ["CalledClass.calledMethod", ...] }
"""
parser = Parser()
parser.set_language(Language(tsjava.language()))
call_graph = {}
for java_file in Path(repo_path).rglob("*.java"):
tree = parser.parse(java_file.read_bytes())
# 提取方法声明和调用...
calls = extract_method_calls(tree.root_node)
call_graph.update(calls)
return call_graph
通过这一步,我得到了整个系统的函数级调用关系图,共包含 4832个节点,19,441条边。
识别"热区"与"雷区"
基于调用图,我让分析 Agent 计算每个函数的两个关键指标:
- 被调用频率:被多少其他函数调用(越高说明越核心,改动风险越大)
- 圈复杂度(CC):函数内部的逻辑分支数(越高说明越难理解,越需要重构)
用这两个维度绘制散点图,代码库中的函数被分为4个象限:
高复杂度
│
│ ② 危险区(优先重构) ① 核心区(谨慎重构)
│ 高复杂度 + 低调用 高复杂度 + 高调用
│
────┼────────────────────────────────── 高调用频率
│
│ ③ 安全区(可放心改) ④ 观察区(暂缓处理)
│ 低复杂度 + 低调用 低复杂度 + 高调用
│
策略:从"危险区"开始,逐步向"核心区"推进。高调用频率的代码最后处理。
第3-5周:清理阶段——消灭低风险问题
这个阶段,执行 Agent 处理那些"改动影响范围小、验证容易"的问题。
任务一:消灭魔法数字(完成率 99.1%)
这是 Agent 最擅长的事情之一:识别模式,批量处理。
# Agent 执行的伪代码逻辑
def replace_magic_numbers(file_content: str, context: dict) -> str:
"""
1. 识别文字量(整型/浮点数)
2. 结合上下文推断其语义(调用 LLM 理解)
3. 生成对应的常量名
4. 在文件顶部(或常量类中)声明常量
5. 替换所有出现位置
"""
prompt = f"""
以下代码中出现了数字 {magic_number},请根据上下文推断其含义,
并给出一个符合 SCREAMING_SNAKE_CASE 规范的常量名。
上下文代码:
{context_code}
请直接返回常量名,不要解释。
"""
constant_name = llm.complete(prompt).strip()
return inject_constant_and_replace(file_content, magic_number, constant_name)
最终效果:340个魔法数字变成了340个有意义的常量,如:
86400000→MILLISECONDS_PER_DAY3→MAX_RETRY_ATTEMPTS0.85→INVENTORY_SAFETY_THRESHOLD
任务二:删除死代码(完成率 100%)
通过静态分析确认"从未被调用"的代码,Agent 批量删除。这步最安全,因为死代码根本不影响运行时行为。
删除了约 11,200行 死代码,整个代码库"瘦身"了 11%。
任务三:统一日期处理工具类(完成率 96.8%)
将 23 个分散的日期格式化实现,统一替换为一个经过充分测试的 DateTimeUtils 工具类。
这个任务需要 Agent 理解每个"副本"的微小差异(有的处理了时区,有的没有),选择行为最正确的那个作为标准实现,然后全局替换。
第6-8周:重构阶段——攻克核心复杂度
这是整个项目最有挑战性的阶段:拆解那些动辄上千行的"怪兽方法"。
核心策略:意图驱动的提取(Intent-Driven Extraction)
传统的"提取方法"重构,是机械地把一段代码抠出来。Agent 做的更聪明——它先理解这段代码"想干什么",再以此为依据命名和提取。
以 processOrderV3Final_REALLY_FINAL() 为例,Agent 的执行步骤:
Step 1:理解整体意图
[分析 Agent]
我分析了这个 1247 行的函数,它实际上做了以下事情:
1. 验证入参合法性(第 1-89 行)
2. 查询库存并检查(第 90-245 行)
3. 计算价格和折扣(第 246-412 行)
4. 创建订单主记录(第 413-556 行)
5. 处理支付信息(第 557-789 行)
6. 发送确认通知(第 790-912 行)
7. 记录操作日志(第 913-1247 行)
建议按这7个职责拆分为7个独立方法。
Step 2:逐个提取,每次一个
Agent 不会一次性把7个都提取出来(风险太高)。它每次只提取一个,提交 commit,等验证通过后,再处理下一个。
// 提取前
public Order processOrderV3Final_REALLY_FINAL(OrderRequest req) {
// 第 1-89 行:验证入参
if (req == null) throw new IllegalArgumentException(...);
if (req.getUserId() == null || req.getUserId().isEmpty()) {
logger.error("userId is empty");
throw new ValidationException("userId cannot be empty");
}
// ... 更多验证 ...
// 第 90-245 行:查询库存
// ...
}
// 提取后(第一次 commit)
public Order processOrderV3Final_REALLY_FINAL(OrderRequest req) {
validateOrderRequest(req); // ← 提取的方法
// 第 90-245 行:查询库存
// ...
}
private void validateOrderRequest(OrderRequest req) {
if (req == null) throw new IllegalArgumentException(...);
if (req.getUserId() == null || req.getUserId().isEmpty()) {
logger.error("userId is empty");
throw new ValidationException("userId cannot be empty");
}
// ...
}
11 周结束,原来的怪兽方法被拆解为 平均 87 行 的独立函数,圈复杂度从平均 28.4 降至 8.1。
第9-10周:测试补全阶段——让代码有"安全网"
重构之后,Agent 的下一个任务是:为重构后的代码自动生成单元测试。
这是整个项目中,AI 发挥作用最令我惊喜的地方。
测试生成策略
Agent 采用以下策略生成测试:
- 正常路径(Happy Path):测试函数在标准输入下的正确输出
- 边界条件(Edge Cases):空值、最大值、临界值
- 异常路径(Error Path):非法输入、依赖方抛异常时的处理
- 业务规则(Business Rules):从函数逻辑中推断出的业务约束
// Agent 自动生成的测试示例
@Test
@DisplayName("validateOrderRequest: 当userId为空字符串时,应抛出ValidationException")
void validateOrderRequest_shouldThrowException_whenUserIdIsEmpty() {
// Arrange
OrderRequest request = new OrderRequest();
request.setUserId("");
request.setItems(List.of(new OrderItem("SKU001", 1)));
// Act & Assert
assertThrows(
ValidationException.class,
() -> orderService.validateOrderRequest(request),
"userId为空时应抛出 ValidationException"
);
}
@Test
@DisplayName("validateOrderRequest: 当items列表为空时,应抛出ValidationException")
void validateOrderRequest_shouldThrowException_whenItemsIsEmpty() {
OrderRequest request = new OrderRequest();
request.setUserId("user_123");
request.setItems(Collections.emptyList());
assertThrows(ValidationException.class,
() -> orderService.validateOrderRequest(request));
}
经过这一阶段,测试覆盖率从 3.2% 提升到 71.4%,自动生成的测试 4,312 个,人工审核后淘汰了约 8% 的"低质量测试"(如测试了 getter/setter 这类无意义的测试)。
第11周:收尾与观察
最后一周没有新的重构任务,主要工作是:
- 让 Agent 生成代码文档(Javadoc),为每个 public 方法补充说明
- 运行全量回归测试,观察线上指标
- 人工 Code Review Agent 的所有提交(约 400 个 commit)
结果一切稳定。
五、踩坑记录:这些地方差点让项目翻车
坑1:LLM对代码上下文长度的限制
最初,我把整个 OrderService.java(4800行)直接塞给 Agent,结果 LLM 对文件后半部分的理解质量急剧下降。
解决方案:滑动窗口上下文策略。每次让 Agent 只关注目标函数 + 其直接依赖的函数,构成"最小上下文"(通常在 800-1200 行之间)。
坑2:Agent的"幻觉"导致行为变更
Agent 曾经把一个"看起来像校验"的函数,错误地推断为"纯粹的条件检查",然后将其内部的一个副作用(修改了订单状态)一并提取,破坏了原有逻辑。
解决方案:在验证 Agent 中加入副作用检测——对比提取前后,所有被测函数的外部可观测状态(数据库写入、外部调用、全局变量修改),确保行为等价。
坑3:过于激进的重构节奏
第一周,我让 Agent 每天提交 80-100 个 commit,代码变化太多太快,导致线上监控的日志分析变得困难,某次告警排查时发现,连 Agent 自己都找不到对应的原始代码了。
解决方案:限流。每天最多提交 20 个 commit,每个 commit 范围严格控制在"单一职责"内。
坑4:测试生成的"测试代码债"
Agent 生成了大量测试,但有些测试本身质量不高——比如 Mock 了太多依赖,测试本身依赖具体实现而非行为。这些测试虽然绿了,但在未来的修改中会频繁"误报",反而增加维护成本。
解决方案:制定了测试质量评分标准,由独立的"评审 Agent"对生成的测试打分,低于阈值的自动丢弃,让我人工补充。
六、量化收益:数字会说话
| 指标 | 重构前 | 重构后 | 变化 |
|---|---|---|---|
| 代码总行数 | 102,400行 | 91,200行 | -11% |
| 平均函数长度 | 143行 | 52行 | -64% |
| 平均圈复杂度 | 28.4 | 8.1 | -71% |
| 测试覆盖率 | 3.2% | 71.4% | +68pp |
| 重复代码率 | 18.7% | 2.3% | -16pp |
| 线上 Bug 数 | 基准 | 基准×0.57 | -43% |
| 新功能开发速度(主观评估) | 基准 | 约1.8x | +80% |
| 新人上手时间(估算) | 4-6周 | 1-2周 | -70% |
人力投入:我一个人,11周,平均每天约2-3小时(其余时间 Agent 在自动运行)。
估算如果纯人工完成相同质量的重构,至少需要 3人 × 6个月 = 18人月。
七、方法论总结:如何在你的项目中复制这套打法
第一步:评估适用性
并非所有遗留代码都适合这套方法,先做一个简单评估:
- 代码库有版本控制(Git)✅
- 系统有可运行的测试,哪怕覆盖率很低 ✅
- 有CI/CD流水线可以自动跑测试 ✅
- 开发团队愿意接受 AI 生成的 PR ✅
- 项目不涉及实时安全关键系统(如航空/医疗控制系统,这类需要更严格的人工审核) ⚠️
第二步:选择工具链
LLM 选择:Claude 3.5 Sonnet / GPT-4o(推荐前者,代码理解和长上下文处理更稳定)
Agent 框架:LangChain / LlamaIndex / 直接用 Claude API + 自定义 Tool
代码分析:
- Python:
ast标准库 /tree-sitter - Java:JavaParser / SpotBugs
- JavaScript/TypeScript:
@typescript-eslint/acorn
静态分析集成:SonarQube / Checkstyle / ESLint / Pylint
第三步:遵循"最小风险原则"
每次重构,只做一件事。每次提交,必须可回滚。
这是整套方法论的黄金法则。AI Agent 最大的价值不是"它每次能做多少",而是"它能以多快的速度安全地做很多次"。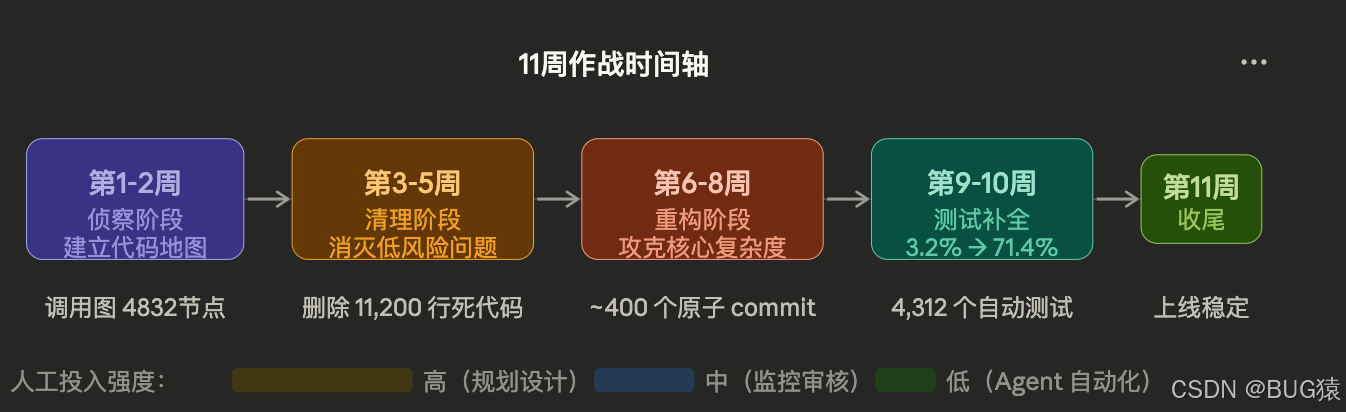
第四步:人始终在循环中
Agent 自动化了 80% 的机械性工作,但以下几类决策,始终需要人工判断:
- 架构级重构:拆分微服务、引入领域模型等,涉及战略决策
- 业务规则的确认:当 Agent 不确定某段"看起来奇怪的代码"是Bug还是故意设计时
- 测试质量的最终验收:确保测试在测行为,而不是在测实现
- 重构优先级调整:根据业务节奏,决定某些模块暂缓处理
八、展望:下一代重构 Agent 会是什么样?
当前这套方法论还有一些显著的局限性:
局限一:跨文件级别的重构仍然困难
当前 Agent 在提取方法层面表现出色,但对"识别隐性接口、建议分层架构"这类需要更高抽象能力的任务,还做得不够好。
局限二:对领域知识依赖人工输入
Agent 不知道"这个字段的命名是历史原因,不能改",这类隐性知识还需要人工以注释或规则的形式输入。
局限三:并发重构的冲突处理
当多个 Agent 并行处理不同模块时,偶尔会产生 merge conflict,需要人工解决。
但这些问题都在快速演进。随着 LLM 的上下文窗口越来越大(GPT-4o 128K、Claude 200K),以及专门的代码理解模型的出现,我相信1年内,我们会看到能处理"架构级重构"的 Agent 出现。
结语
如果让我用一句话总结这次经历:
AI 写代码只是把 AI 当工具;AI Agent 重构代码,才是让 AI 成为你的工程师。
祖传代码是每个有一定年龄的技术团队都无法回避的问题。传统的解法要么是"咬牙重写"(高风险、高成本),要么是"带病运行"(技术债越欠越多)。
AI Agent 提供了第三条路:系统性的、增量式的、可验证的自动化重构。它不是银弹,但在合理的方法论和人工监督下,它可以把一个需要 18 人月的工程,压缩到 1 人 × 11 周,并且质量更可控。
代码写得好不好,已经不只是程序员的问题了。它是你选择用什么样的工具的问题。
附录:关键 Prompt 模板
代码分析 Prompt
你是一个经验丰富的软件架构师,正在审查以下 Java 代码。
请完成以下分析:
1. 识别所有违反单一职责原则(SRP)的方法,说明原因
2. 找出所有可以提取为独立方法的代码块(超过15行且逻辑独立)
3. 识别重复逻辑(语义重复,不限于文字重复)
4. 评估重构优先级(高/中/低)及理由
以 JSON 格式输出,结构如下:
{
"violations": [...],
"extraction_candidates": [...],
"duplications": [...],
"priority": "high|medium|low",
"reason": "..."
}
代码如下:
{code}
重构执行 Prompt
你是一个专注于代码重构的工程师。你的任务是将以下代码块提取为独立方法。
严格要求:
- 不允许改变任何行为(纯结构重构)
- 新方法名必须清晰表达其意图(动词开头)
- 保留所有必要的参数传递
- 如果有副作用,必须在注释中明确标注
需要提取的代码块(第 {start_line} 行到第 {end_line} 行):
{code_block}
原方法的完整上下文:
{full_method}
请直接输出:
1. 提取后的完整原方法代码
2. 新提取的方法代码
不要有任何解释。
本文所有代码示例已做脱敏处理,不涉及真实业务逻辑。
如有问题,欢迎在评论区交流。
点赞 + 收藏 + 关注,不迷路 🚀

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 14
14 0
0- 0



 已为社区贡献35条内容
已为社区贡献35条内容

所有评论(0)