Obsidian MCP + Skills 实现本地知识库检索,提高测试用例覆盖率
大家在使用AI辅助开展测试工作时,比如生成测试点、测试用例等,经常会遇到一个共性问题:由于需求文档不规范、不完善,甚至存在描述模糊、信息缺失的情况,导致AI生成的结果不符合实际业务预期,需要反复修改核对,反而增加了额外工作量。那要如何改善这个问题呢?可以搭建一个专属的知识库——把所有相关资料集中管理,让AI生成用例时,能获取更全面、更精准的上下文信息。
一、什么是知识库?
对测试工程师来说,知识库不是复杂的系统,而是一个集中管理测试相关资料、可快速检索、可复用的知识集合,适配测试全流程工作需求,而非单一环节。
它的核心作用,是把开展测试工作所需的所有信息,整合到一起,包括但不限于:需求文档(核心要点)、接口文档、数据库表结构、测试规范、历史测试用例、产品沟通纪要、异常问题记录等,覆盖用例生成、接口测试、问题排查、复盘总结等全场景。
针对这个需求,我去调研了几种方法,今天分享其中一种实测可行的方案:用 Obsidian 搭建本地测试知识库,在AI工具里面接入Obsidian MCP,并封装成检索Skill,就可以让大模型在生成用例时,快速检索知识库中所有相关资料,提高用例覆盖率和准确性。
二、什么是Obsidian?能解决测试的哪些问题?
Obsidian 是一款轻量、免费的本地知识库工具,核心功能是“笔记管理+知识关联”,不需要复杂的部署,安装后就能直接使用,非常适合测试工程师搭建个人或项目专属知识库。
1. 解决资料零散问题:可以将需求、接口、表结构等所有测试相关资料,整理成独立笔记,集中存放在本地仓库,统一管理,不管是生成用例、排查问题,查找时只需检索关键词,无需翻找多个文件夹。

2. 解决知识关联问题:可以给不同笔记添加标签、建立关联(比如“入住记录”笔记,关联需求要点、接口说明、表结构、历史异常问题),不管是AI检索,还是手动查找,都能快速关联所有相关内容,让工作更全面。
3. 解决复用问题:不同项目的知识库可以独立创建,同类项目的笔记可以复制、修改,复用之前的整理成果,不管是开展同类项目测试,还是复盘总结,都能减少重复劳动。
三、什么是Obsidian MCP?核心作用是什么?
很多小伙伴会疑惑,Obsidian 只是一个本地知识库,怎么和AI工具联动,辅助我们开展全流程测试工作?答案就是 Obsidian MCP。
首先明确:Obsidian 本身不具备联动AI的功能,而 Obsidian MCP,是实现“Obsidian 知识库”与“AI工具”联动的关键桥梁。
简单来说,Obsidian MCP 是一套适配 Obsidian 的协议工具,通过它,我们可以让 Cursor、Trae 等常用AI工具,直接检索 Obsidian 知识库中的所有笔记内容——不用手动复制粘贴资料,AI就能主动获取所需的上下文信息,辅助我们开展用例生成、接口测试、问题排查等各类工作。
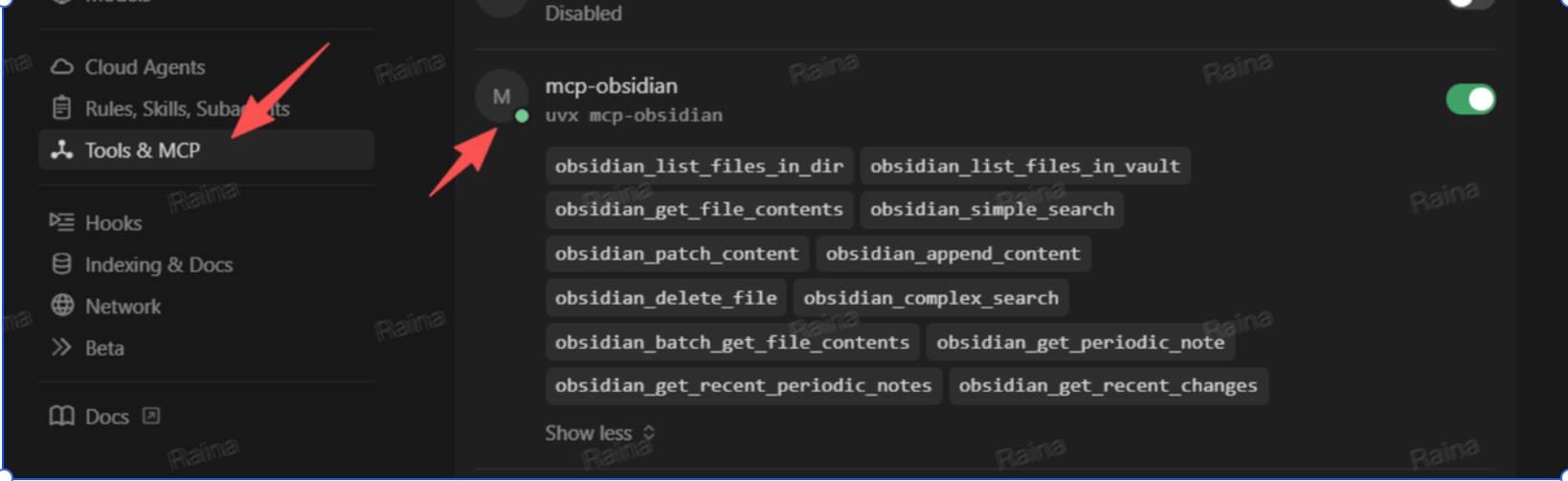
五、案例实战(封装一个检索Skills)
案例:基于 Obsidian 知识库检索「入住记录」
场景:在 Obsidian 仓库中存放了「公寓管理系统」相关的三份文档:接口文档、需求文档、MySQL 表结构。希望在 Cursor 里提问时,AI 能自动从这三份文档中检索与某主题(如「入住记录」)相关的内容并汇总输出。
知识库中的文件(示例):
1、接口文档
2、需求文档
3、MySQL 表结构

做法:封装一个 Obsidian Skill,在 Skill 中约定「优先调用 Obsidian MCP 在指定文件或仓库中检索相关内容」。这样在 Cursor 中执行该 Skill 并输入查询主题(如「入住记录」)时,AI 会按 Skill 的指引去调用 Obsidian MCP,而不是仅依赖当前对话里的粘贴内容。
执行:在对话中触发该 Skill,并输入要检索的主题(例如「入住记录」)。

过程:AI 会调用 Obsidian MCP,在以上三个文件中查找与「入住记录」相关的内容(接口定义、需求描述、表结构等),并将检索到的片段汇总后返回。
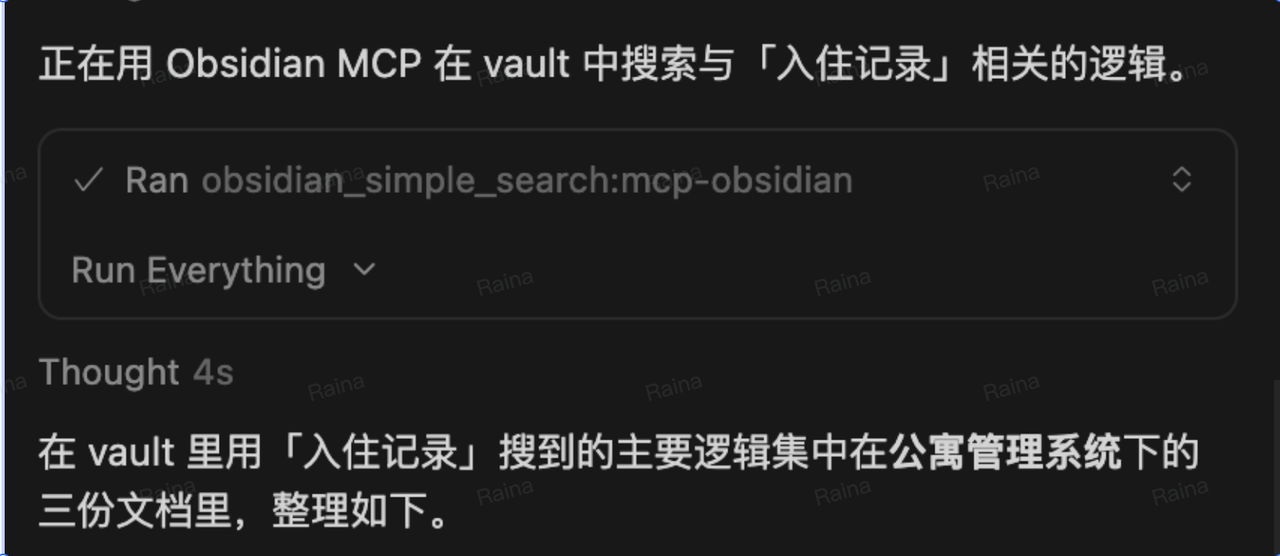
结果:AI 输出与「入住记录」相关的接口、需求与表结构等内容,便于后续写用例、写接口调用或做需求对照。

关于Obsidian 安装、MCP 具体配置步骤,以及封装检索 Skill 的详细操作,都更新到Raina的AI&测试学习圈里了,感兴趣的小伙伴可以前往公众号【Raina测试】了解哦~

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 9
9 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)