RLHF->DPO->GRPO
RLHF->DPO->GRPO
- RLHF的标准四步流程
- DPO的数学消元技巧
- GRPO的组内对比设计
- 一条做减法的演进主线
在大模型(LLM)的演进过程中,**对齐(Alignment)**是让模型从“乱说话的概率预测器”变成“听话的智能助手”的关键。对齐的核心目标是使模型的输出符合人类的价值观、意图和偏好(即 Helpful, Honest, Harmless)。
从早期的 RLHF 到如今大火的 GRPO,技术路线经历从“复杂昂贵”到“极简高效”的剧烈变革。
RLHF的标准四步流程
RLHF(Reinforcement Learning from Human Feedback) 标准流程:四步,如下图所示: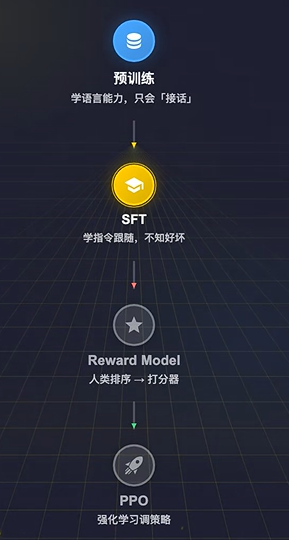
- 预训练。拿大规模语料,让模型学到语言能力,但此时它只会[接话],不会[听话]
- SFT。拿人工写的高质量prompt-reponse对,教模型学会按指令回答问题。到这一步模型能干活了,但它不知道真么叫做[好]什么叫[不好]
- 训练Reward Model。
-
同一个prompt,让SFT模型生成多个回答,
-
然后让人类标注员来排序,哪个好那个差,
-
用这些偏好数据,基于Bradley-Terry模型训练一个打分器出来。
-
训练Reward Model过程如下图所示: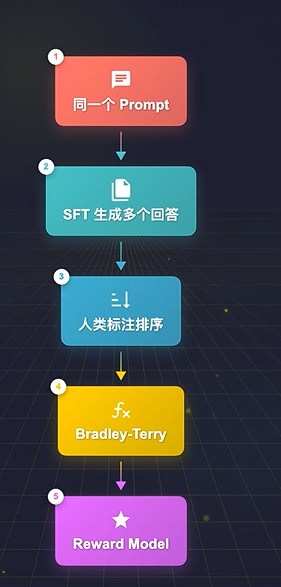
Bradley-Terry模型的意思就是假设人类选A不选B的概率正比于A和B奖励分数之差的sigmod。
Bradley-Terry 模型:经典的人类偏好建模方法及其在 DPO 方法中的应用
这样就可以用标注的数据做极大似然,把Reward Model 学出来
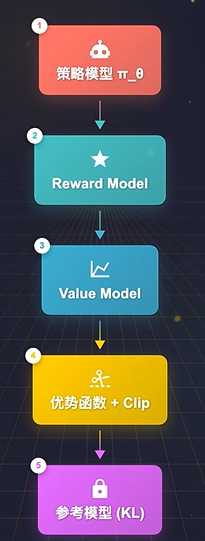
- PPO优化(近端策略优化):通过强化学习算法,在奖励模型的指导下调整模型参数。通过PPO算法去调整策略模型的输出分布,让他尽量往高分方向靠,同时加一个KL散度约束,不让他偏离参考模型太远。
- 用Reward Model的打分作为奖励信号
- 具体来说,PPO会维护一个Value Model,也叫Critic ,来估计当前状态的价值
- 然后通过实际奖励和价值估计的差值来计算优势函数
- 再用clip机制限制每一步的策略更新幅度,防止训崩。
GPT3.5就是这样训练出来的,但是问题就很明显
- 同时需要维护四个模型:策略模型、参考模型、奖励模型、价值模型。
- 显存压力巨大,PPO本身的超参数也非常难调。
- Reward Hacking问题也很常见。模型学会了骗Reward Model拿高分,而不是真的在变好。
- 核心矛盾是:RLHF的训练范式太重了,工程复杂度和训练稳定性都是瓶颈
DPO的数学消元技巧
Q:DPO是怎么解决这个问题的?
Ans:能不能不训Reward Model,直接用偏好数据优化策略
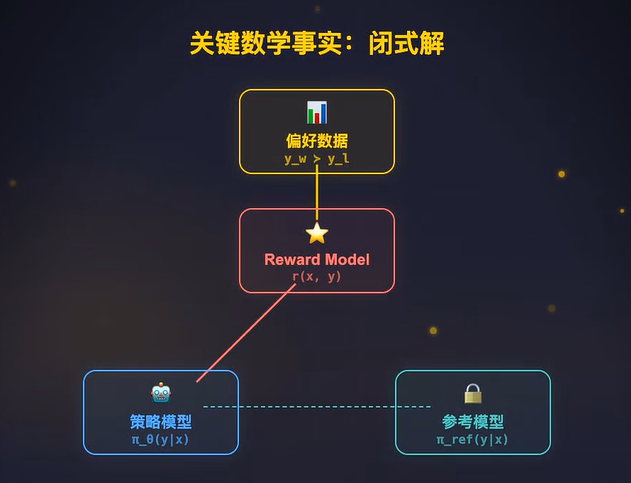
要理解它为什么能做到,首先理解一个关键数学事实:在RLHF的目标函数里,我们要最大化期望奖励同时最小化跟参考策略的KL散度,这个带KL约束的优化问题其实是有闭式解的。
最优策略=参考策略×exp(奖励函数)/配分函数
公式化表达为:
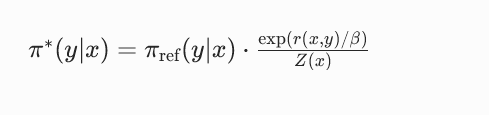
其中π_ref为固定的参考模型,r(x,y)为奖励函数,β为 KL 约束的温度系数,Z(x)是仅和输入 prompt x 相关的配分函数(归一化常数)。
对这个闭式解做公式变形,就能实现一个核心的逻辑反转:奖励函数可以完全用最优策略和参考模型的对数概率差来表示,公式为:
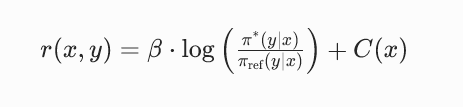
其中C(x)是仅和输入 prompt x 相关、与生成内容 y 无关的常数项。
接下来是 DPO 最关键的消元步骤:
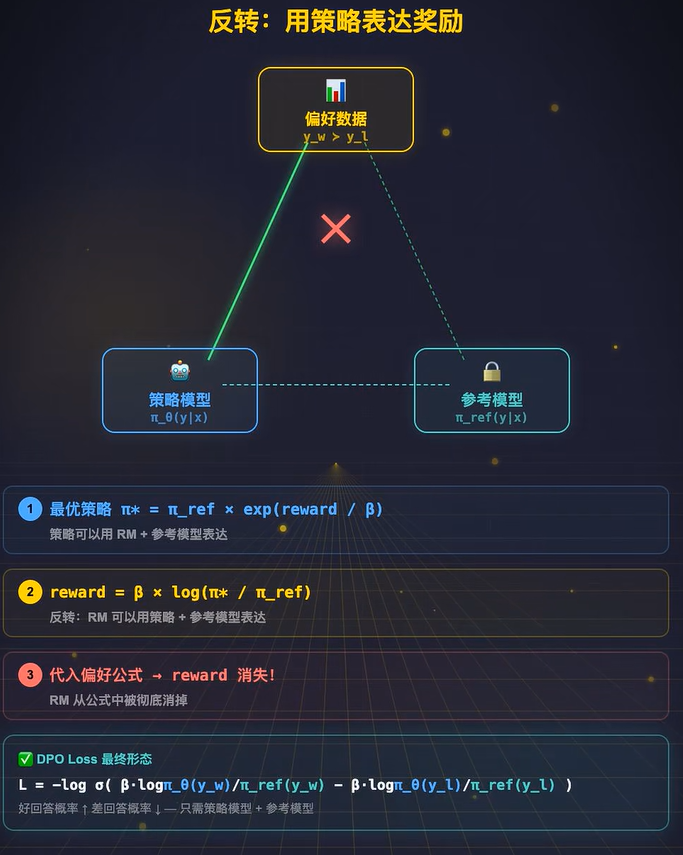
人类偏好建模的核心是 Bradley-Terry(BT)模型,其核心逻辑是:人类更偏好优胜回答y_w、而非劣败回答y_l的概率,由两个回答的奖励分差值的 sigmoid 函数决定。
当我们把上面反转后的奖励函数表达式代入 BT 偏好模型时,会发现:仅和输入 x 相关的常数项C(x),在y_w和y_l的奖励差值计算中会被完全抵消。
最终得到的人类偏好概率表达式里,奖励模型的所有相关项被彻底消除,整个式子仅由策略模型、参考模型分别在优胜回答和劣败回答上的对数概率比之差,再经过 sigmoid 函数映射得到,完全不再依赖任何独立训练的奖励模型。
基于这个数学等价性,DPO 直接对这个偏好概率表达式做极大似然估计,构建出最终的 DPO 损失函数,实现了完全绕开奖励模型、价值模型和 PPO 复杂的强化学习采样迭代循环,仅用成对的人类偏好数据,直接优化策略模型。
剩下的就是:
人类选好回答的概率=策略模型和参考模型在好回答与坏回答上的对数概率比之差,再套一个sigmod。
这个表达式里面**已经没有Reward Model 的任何参数了,全部都是策略模型和参考模型**的概率。
所以可以直接对这个式子**做极大似然,Reward Model 就被数学上等价地消掉了**。这一核心创新,带来了 RLHF 范式的革命性简化,核心收益包括:
- 彻底砍掉了独立的奖励模型、价值模型训练环节,训练所需的模型从 4 个缩减为 2 个(仅需待优化的策略模型 + 全程冻结的参考模型);
- 完全消除了 PPO 算法复杂的在线采样迭代循环,把高难度的强化学习问题,转化为了简单的有监督式损失优化问题,工程实现难度和算力成本大幅下降;
- 彻底规避了 PPO 训练中常见的训练不稳定、奖励黑客、超参数高度敏感等痛点,训练过程更稳定,对齐效果更可控。
Q:DPO就没有问题吗?
Ans: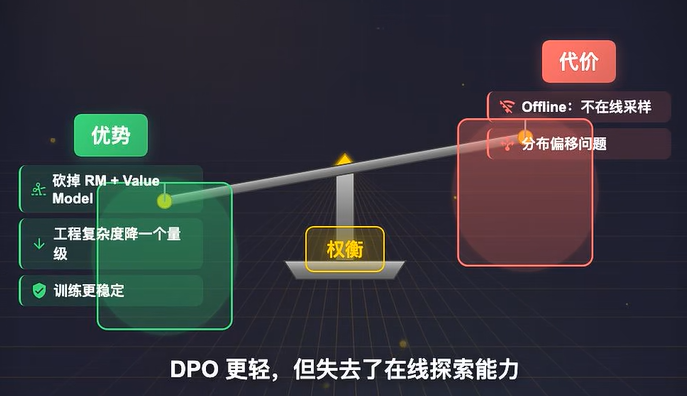
DPO是offline的,他/她只学习训练数据中已有的偏好对,不会像PPO那样在线探索采样–DPO的分布偏移问题
偏好数据的分布和当前策略的输出分布之间会出现偏移,偏移越大,DPO的优化方向就不准,正因为这个问题,后来出现了一系列DPO的变体。
- Iterative DPO和Online DPO的核心思路就是在训练过程中不断用当前模型重新采样,重新标注偏好对,来缓解分布偏移。
- KTO更激进,连成对的偏好数据都不要了,只需要回答【这个回答好】或者【这个回答不好】的单条标签就能训练
整个社区都在做减法,不断追问到底哪些组件是可以省略掉的。
GRPO的组内对比设计
GRPO(Group Relative Policy Optimization)是 DeepSeek 团队提出的轻量化强化学习对齐算法,最早落地于 DeepSeek Math 数学推理模型,后在 DeepSeek R1 等爆款模型中大规模应用。它走出了与 PPO、DPO 不同的优化路径,核心解决了数学推理、代码生成等可验证任务,无需人工标注偏好数据、无需复杂模型组件,就能实现高效的策略对齐的核心痛点。
一、GRPO 的核心定位:解决了什么问题
在 GRPO 之前,大模型对齐的两大主流范式各有明显短板:
- RLHF+PPO:对齐能力完整、支持在线训练,但架构极重,需要训练奖励模型、价值模型、策略模型、参考模型共 4 个模型,工程复杂度高、算力成本大,且高度依赖人工标注的偏好数据;
- DPO:通过数学等价性砍掉了奖励模型和价值模型,仅需 2 个模型,大幅简化了流程,但它是离线(offline)训练范式,必须依赖提前准备好的成对偏好数据,无法实现模型的在线自优化,也无法适配可自动化验证的任务场景。
而 GRPO 的核心突破,是针对数学推理、代码生成这类答案可直接自动化验证、有明确对错标准的任务,提出了一个极简的解决方案:既然能直接验证答案对错,就完全不需要人工标注偏好,也不需要额外训练奖励模型、价值模型,就能实现轻量化的在线强化学习对齐。
二、GRPO 的核心机制:从强化学习谱系看设计巧思
要理解 GRPO 的核心设计,必须先看强化学习中 Baseline(基线)的演进脉络,这也是 GRPO 最核心的创新点所在。
1. Baseline 的演进:GRPO 的设计源头
强化学习策略梯度训练的核心痛点,是梯度估计的方差过大,导致训练极不稳定,而 Baseline 的核心作用就是降低方差,整个演进路径如下:
- REINFORCE:纯策略梯度算法,无 Baseline,仅用单个样本估计梯度,方差极大,训练完全不可控;
- REINFORCE + Baseline:引入基线项抵消梯度噪声,大幅降低方差,但「Baseline 该怎么估计」成了新的核心难题;
- PPO:专门训练一个独立的Value Model(价值模型) 来预估 Baseline,完美解决了方差问题,但引入了额外的模型组件,工程复杂度和训练成本大幅上升;
- GRPO:用「同批次组内奖励均值」作为免费的 Baseline,无需训练任何额外模型,样本量足够时估计精度完全达标,彻底砍掉了价值模型,同时保留了 PPO 的训练稳定性。

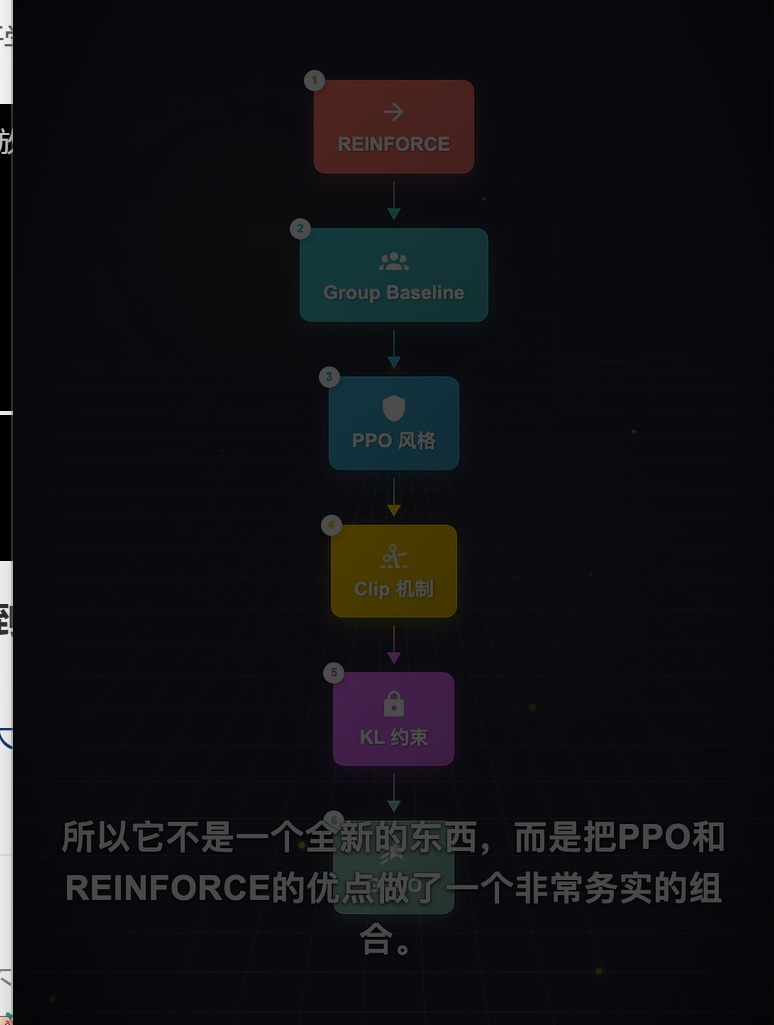
GRPO本质是REINFORCE算法的一个变体
- 经典的REINFORCE用单个样本估计梯度,方差很大,训练不稳。
- 后来人们加了baseline来降方差,但是baseline怎么估又是个问题
- PPO专门训了一个Value Model来干这个事情
- GRPO的聪明之处在于,它说我不需要学一个baseline,我直接采一组样本,用这一组的平均奖励当baseline就行了,样本量足够大的时候,这个估计已经足够准了,而你省掉了整个Value Model,同事GRPO的梯度还是PPO风格的
2. GRPO 完整工作流程
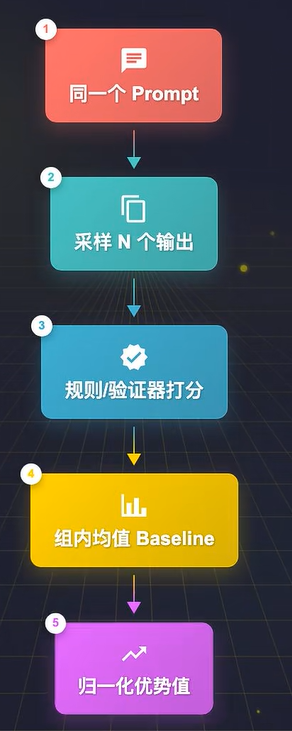
GRPO 本质是 REINFORCE 与 PPO 优点的务实结合,它沿用了 REINFORCE 的极简策略梯度框架,同时吸收了 PPO 保障训练稳定的核心设计,完整流程分为 6 步:
- 分组批量采样:对同一个 Prompt,一次性采样生成一组输出(通常为 16 个、64 个),这是「分组」的核心基础;
- 自动化奖励打分:无需人工标注、无需奖励模型,直接用规则 / 验证器给每个输出自动打分 —— 数学题校验最终答案是否正确,代码跑测试用例验证是否通过,完全实现自监督;
- 组内 Baseline 与优势计算:用该组所有输出的奖励均值作为 Baseline,结合组内标准差做归一化,计算每个输出的相对优势值(优势 = 当前样本奖励 - 组内均值),无需任何额外模型学习;
- PPO 风格梯度更新:沿用 PPO 的核心 Clip 裁剪机制,严格限制策略模型的参数更新幅度,避免单次更新过猛导致模型崩塌、能力退化;
- KL 约束兜底:加入与固定参考模型的 KL 散度约束,惩罚策略模型与初始模型的输出分布偏差,防止模型为了刷分出现「奖励黑客」行为,保留基础语言与推理能力;
- 循环迭代:重复采样 - 打分 - 更新的流程,完成策略模型的在线对齐优化。
三、GRPO vs PPO vs DPO:三大对齐范式核心对比
GRPO 完美补齐了 PPO 和 DPO 的短板,形成了「重而全、轻而离线、轻而在线」的清晰演进线,核心差异如下表:
| 对齐范式 | 核心依赖组件 | 训练模式 | 所需模型数量 | 核心特点 |
|---|---|---|---|---|
| RLHF+PPO | 奖励模型 RM、价值模型 VM、策略模型、参考模型 | 在线训练 | 4 个 | 重但完整,适配全场景,高度依赖人工偏好数据 |
| DPO | 策略模型、参考模型 | 离线训练(offline) | 2 个 | 轻但 offline,依赖离线成对偏好数据,无法在线自优化 |
| GRPO | 策略模型、参考模型 | 在线训练(online) | 2 个 | 轻且 online,无需 RM/VM,无需人工偏好标注,可通过验证器自动在线优化 |
GRPO 的核心优势非常明确:它既像 DPO 一样,把训练所需的模型从 4 个精简到 2 个,彻底砍掉了奖励模型和价值模型,工程复杂度、算力成本大幅下降;又保留了 PPO 的在线训练能力,无需提前准备离线偏好数据,能通过自动化验证器实现模型的自监督在线迭代,完美适配可验证类任务。
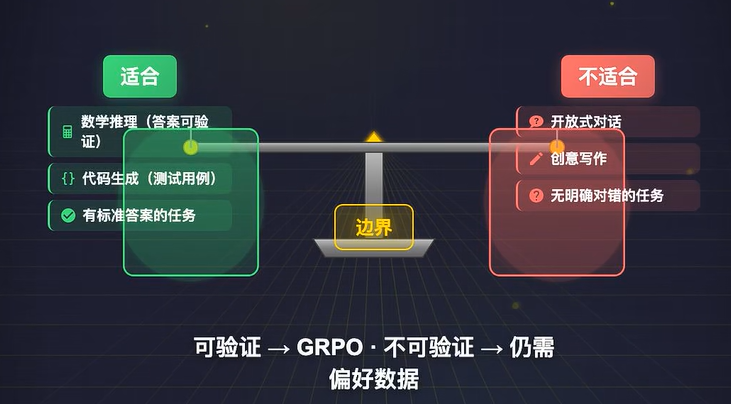
四、GRPO 的适用边界
GRPO 的能力边界非常清晰,核心取决于任务结果是否可自动化、标准化验证,和 DPO 形成了明确的场景互补。
适合:核心是有明确标准答案、结果可直接自动化验证的任务:
- 数学推理、逻辑计算:答案可直接校验对错,是 GRPO 的原生落地场景;
- 代码生成、工具调用:可通过测试用例、执行结果自动验证是否符合预期;
- 其他有明确对错标准、可自动化校验的结构化任务。
不适合:无明确对错标准、高度依赖人类主观偏好的任务:
- 开放式对话、闲聊:没有唯一标准答案,好坏完全取决于人类的主观偏好与对话适配度;
- 创意写作、文案创作:风格、文采、创意没有统一的可量化、可自动化验证标准;
- 其他无法自动化校验、必须依赖人类主观判断的非结构化任务。
GRPO的适用边界

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)