基于LangChain的RAG与Agent智能体开发 - Ollama简介以及安装和使用
大家好,我是小锋老师,最近更新《2027版 基于LangChain的RAG与Agent智能体 开发视频教程》专辑,感谢大家支持。
本课程主要介绍和讲解RAG,LangChain简介,接入通义千万大模型,Ollama简介以及安装和使用,OpenAI库介绍和使用,以及最重要的基于LangChain实现RAG与Agent智能体开发技术。
视频教程+课件+源码打包下载:
链接:https://pan.baidu.com/s/1_NzaNr0Wln6kv1rdiQnUTg
提取码:0000
基于LangChain的RAG与Agent智能体开发 - Ollama简介以及安装和使用
前面我们用阿里云百炼平台,是很方便,快捷,有免费额度,但是仅仅是部分模型有免费额度,而且额度也是有限制的。所以我们还有一种本地方案 - 使用Ollama部署蒸馏模型。
Ollama简介
Ollama官网:
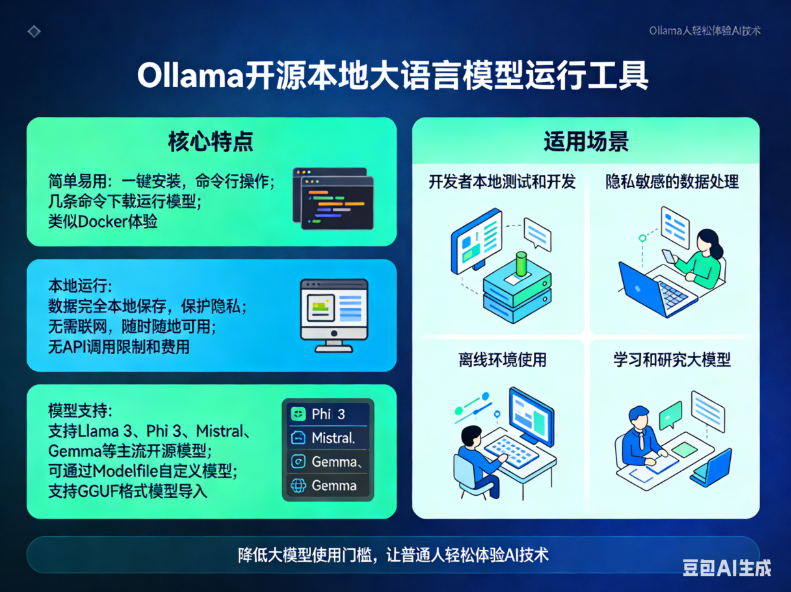
https://ollama.com/Ollama 是一个开源的本地大语言模型运行工具,它让用户能够轻松地在自己的电脑上部署和使用各种大型语言模型,无需联网也不需要昂贵的云服务。
核心特点
1. 简单易用
-
一键安装,命令行操作
-
几条命令就能下载和运行模型
-
类似 Docker 的使用体验
2. 本地运行
-
数据完全本地保存,保护隐私
-
无需联网,随时随地可用
-
没有 API 调用限制和费用
3. 模型支持
-
支持 Llama 3、Phi 3、Mistral、Gemma 等主流开源模型
-
可通过 Modelfile 自定义模型
-
支持 GGUF 格式的模型导入
适用场景
-
开发者本地测试和开发
-
隐私敏感的数据处理
-
离线环境使用
-
学习和研究大模型
Ollama 极大地降低了普通人使用大语言模型的门槛,让任何人都能方便地在自己的电脑上体验先进的 AI 技术。
Ollama蒸馏模型介绍
蒸馏模型(Distilled Model)是通过知识蒸馏技术压缩后的小型模型,Ollama 支持运行这类轻量化模型,让普通电脑也能流畅运行 AI。
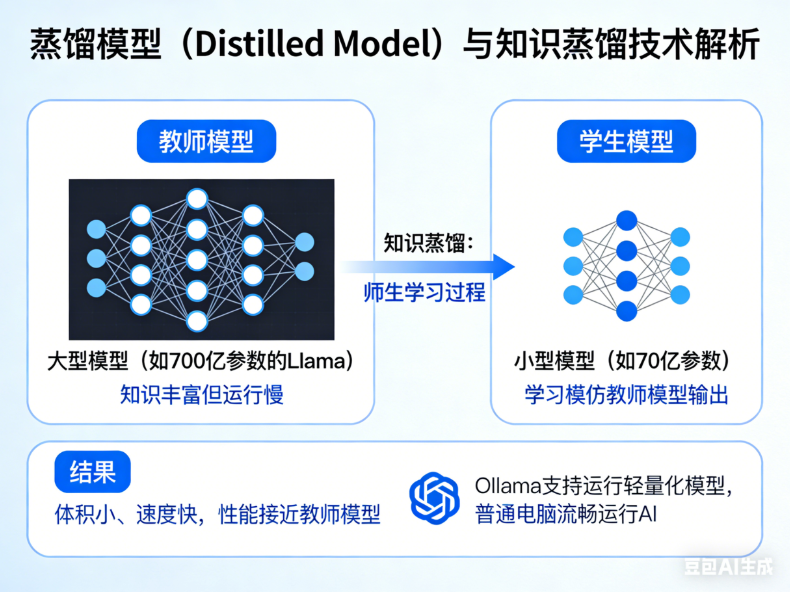
什么是知识蒸馏?
知识蒸馏就像一个师生学习过程:
-
教师模型:大型模型(如 700 亿参数的 Llama),知识丰富但运行慢
-
学生模型:小型模型(如 70 亿参数),学习模仿教师模型的输出
-
结果:学生模型体积小、速度快,同时保持接近教师模型的性能
Ollama 支持的蒸馏模型
1. Llama 3.2 系列(Meta)
-
1B 和 3B 参数版本
-
适合移动设备和低配置电脑
-
保持较好的对话能力
2. Phi-3 系列(微软)
-
Mini(3.8B)、Small(7B)版本
-
微软精心挑选训练数据
-
小尺寸但推理能力强
3. Gemma 系列(Google)
-
2B 和 7B 参数
-
基于 Gemini 技术蒸馏而来
-
开源免费商用
4. Qwen 系列(阿里)
-
0.5B、1.8B、4B、7B 版本
-
中英文能力均衡
-
适合中文场景
蒸馏模型在 Ollama 中的优势
性能对比(以 Llama 3 为例):
| 模型 | 参数 | 内存需求 | 速度 | 适用设备 |
|---|---|---|---|---|
| 原版 | 70B | >140GB | 慢 | 服务器 |
| 蒸馏版 | 8B | ~16GB | 快 | 个人电脑 |
| 蒸馏版 | 3B | ~6GB | 极快 | 笔记本/RPi |
实际好处:
-
普通电脑(8-16GB 内存)也能运行
-
生成速度快 3-10 倍
-
功耗低,适合长时间运行
-
硬盘空间占用小
Ollama下载安装
ollama下载地址:
https://ollama.com/download点击 下载即可。
下载到本地后,我们双击安装:

出现下面这个界面,就说明安装好了
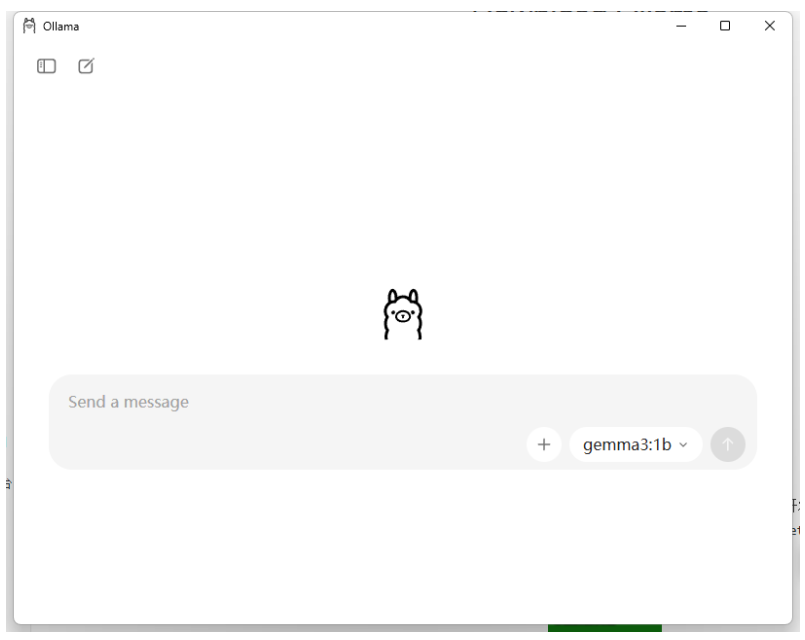
默认界面还是很简约的,提供了聊天对话框,以及右侧可以选择模型,我们可以搜索然后下载需要的模型
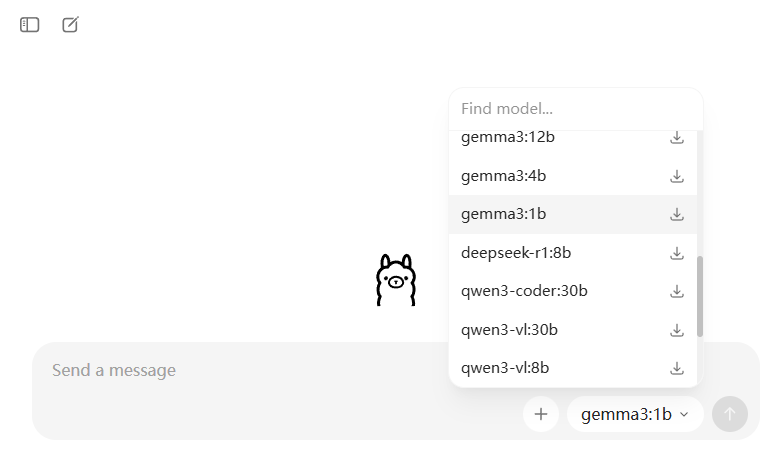
这里面每个模型后面都有多少b,比如4b,这个b就是10亿参数,4b就是40亿参数,我们根据当前机器的显卡显存大小来选择具体的参数模型,比如你电脑就4个G的显存,那就选个4b,如果是高配32G显存,那基本都能跑。
比如我们选择一个4b(40亿参数)的qwen模型,去提问“你是谁?”,那么Ollama先会自动下载模型,然后回答问题。
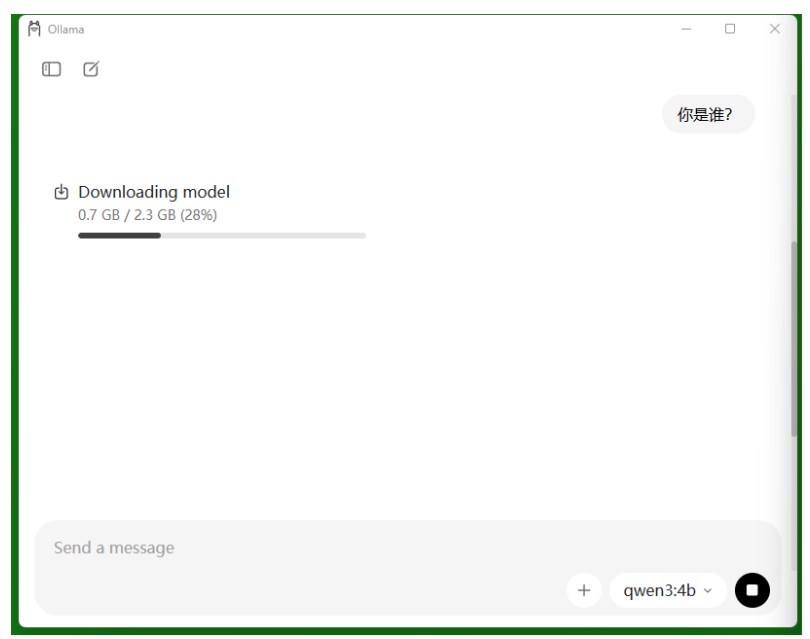
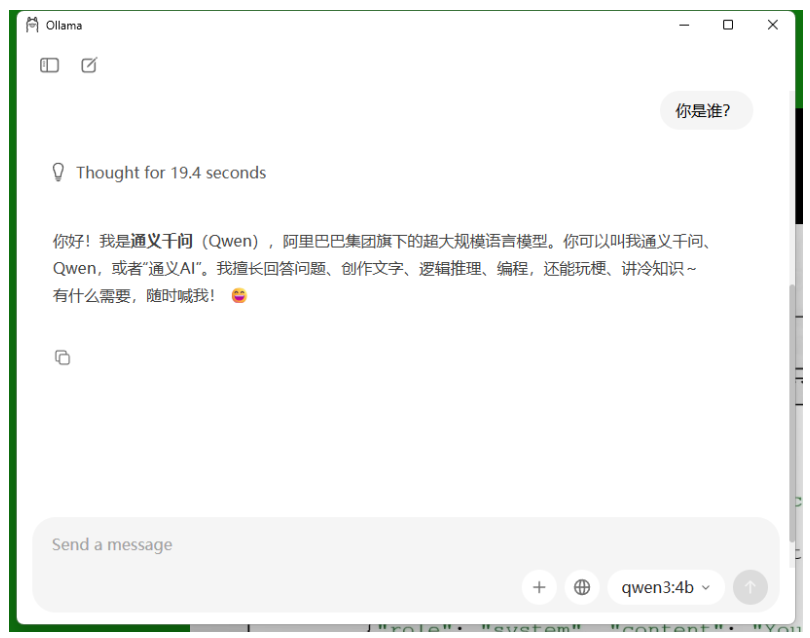
下载完后,就自动回答你的问题。
使用OpenAI库调用Ollama本地大模型
我们参考ollama对openai兼容支持的文档:
https://docs.ollama.com/api/openai-compatibility#openai-compatibility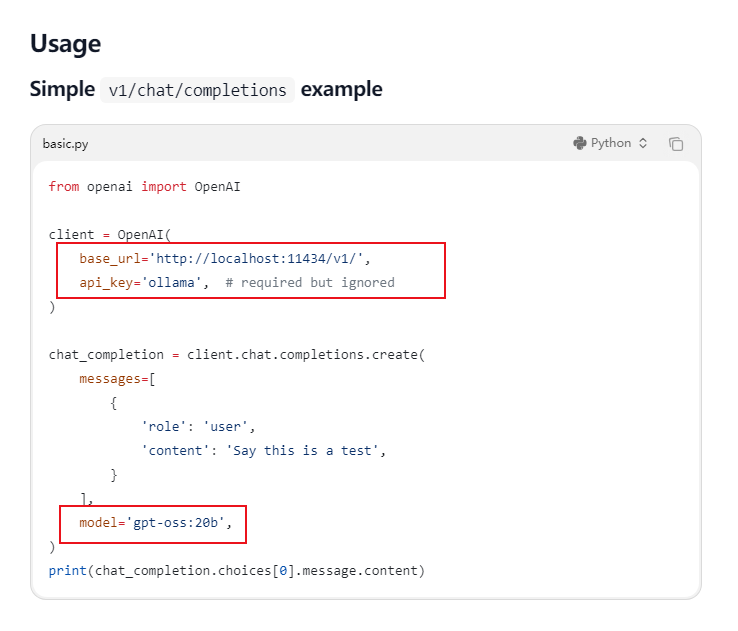
主要是三个地方的
1,base_url改成
http://localhost:11434/v1/ 2,api_key改成ollama
3,model换成你的ollama里你要用的模型
我们把前面1讲的helloWorld.py复制一份,改成ollama.py,然后修改三个参数:
from openai import OpenAI
import os
client = OpenAI(
api_key='ollama',
base_url="http://localhost:11434/v1/"
)
messages = [{"role": "user", "content": "你是谁"}]
completion = client.chat.completions.create(
model="qwen3:4b", # 您可以按需更换为其它深度思考模型
messages=messages,
extra_body={"enable_thinking": True},
stream=True
)
is_answering = False # 是否进入回复阶段
print("\n" + "=" * 20 + "思考过程" + "=" * 20)
for chunk in completion:
delta = chunk.choices[0].delta
if hasattr(delta, "reasoning_content") and delta.reasoning_content is not None:
if not is_answering:
print(delta.reasoning_content, end="", flush=True)
if hasattr(delta, "content") and delta.content:
if not is_answering:
print("\n" + "=" * 20 + "完整回复" + "=" * 20)
is_answering = True
print(delta.content, end="", flush=True)我们在运行下,输出:

我们发现,本地的ollama里的大模型运行速度明显比调用阿里云百炼平台接口慢多了,但是本地跑不用花钱,而且模型选择也多,所以还是一个不错的选择。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 12
12 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)