大模型:使用langchain库调用大模型(1)
API调用模型:
在本地和网页使用ai的区别就在于服务器不同,一个是厂家服务器一个是自己电脑上,一个联网一个不联网,Token数不一样,用人家服务器可能要计费,部署在自己电脑上就不需要计费
一、前置准备
阿里云网页:AI 焕新季, 马上用千问(这个一般是要收钱的,我们需要花钱买tokens,但是一般情况下,新用户注册都会有免费的tokens能用)
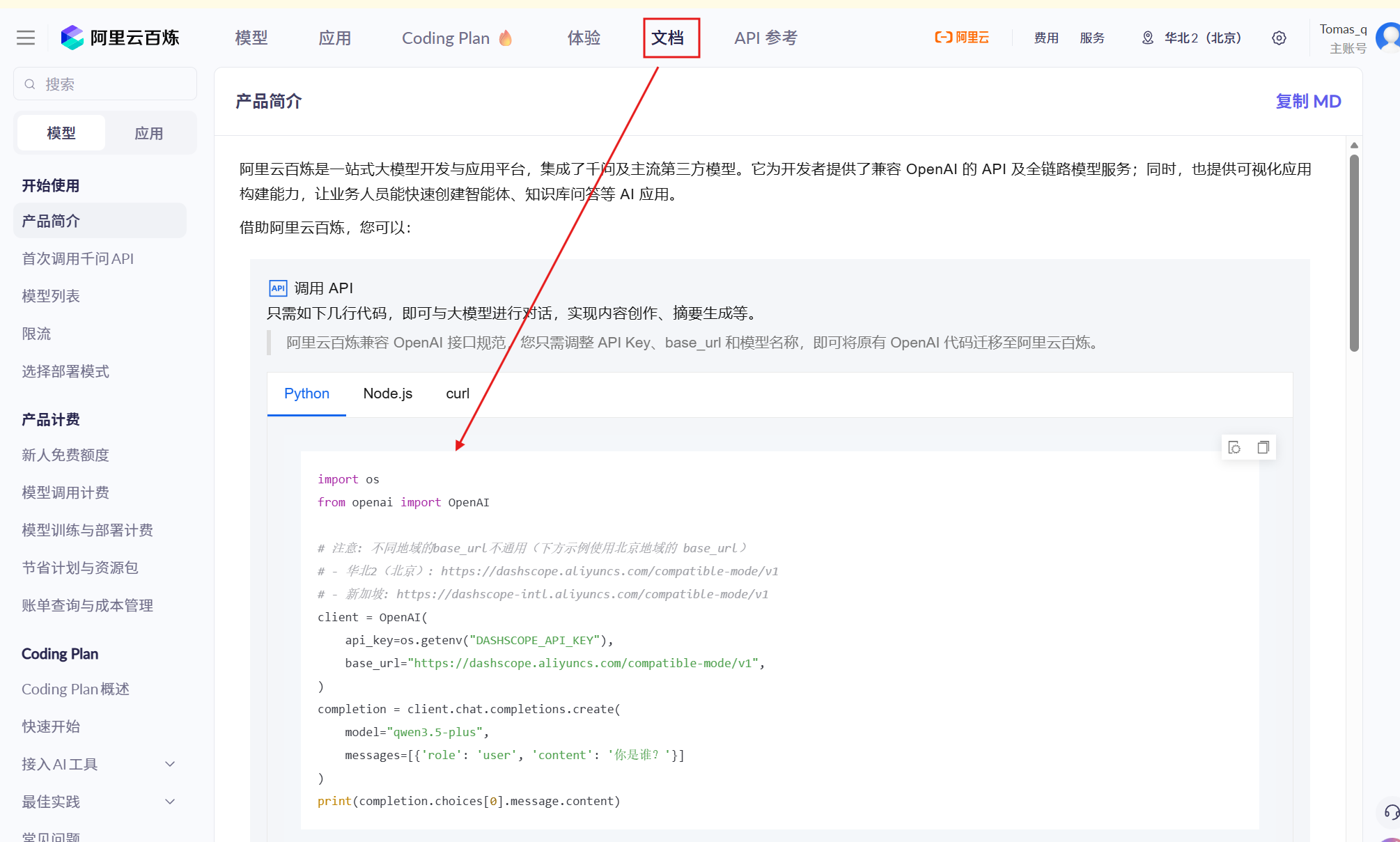
1.先注册并实名
2.左上角点击大模型,选择我们想要调用的模型,这里选择千问3.5,也可以选择别的。
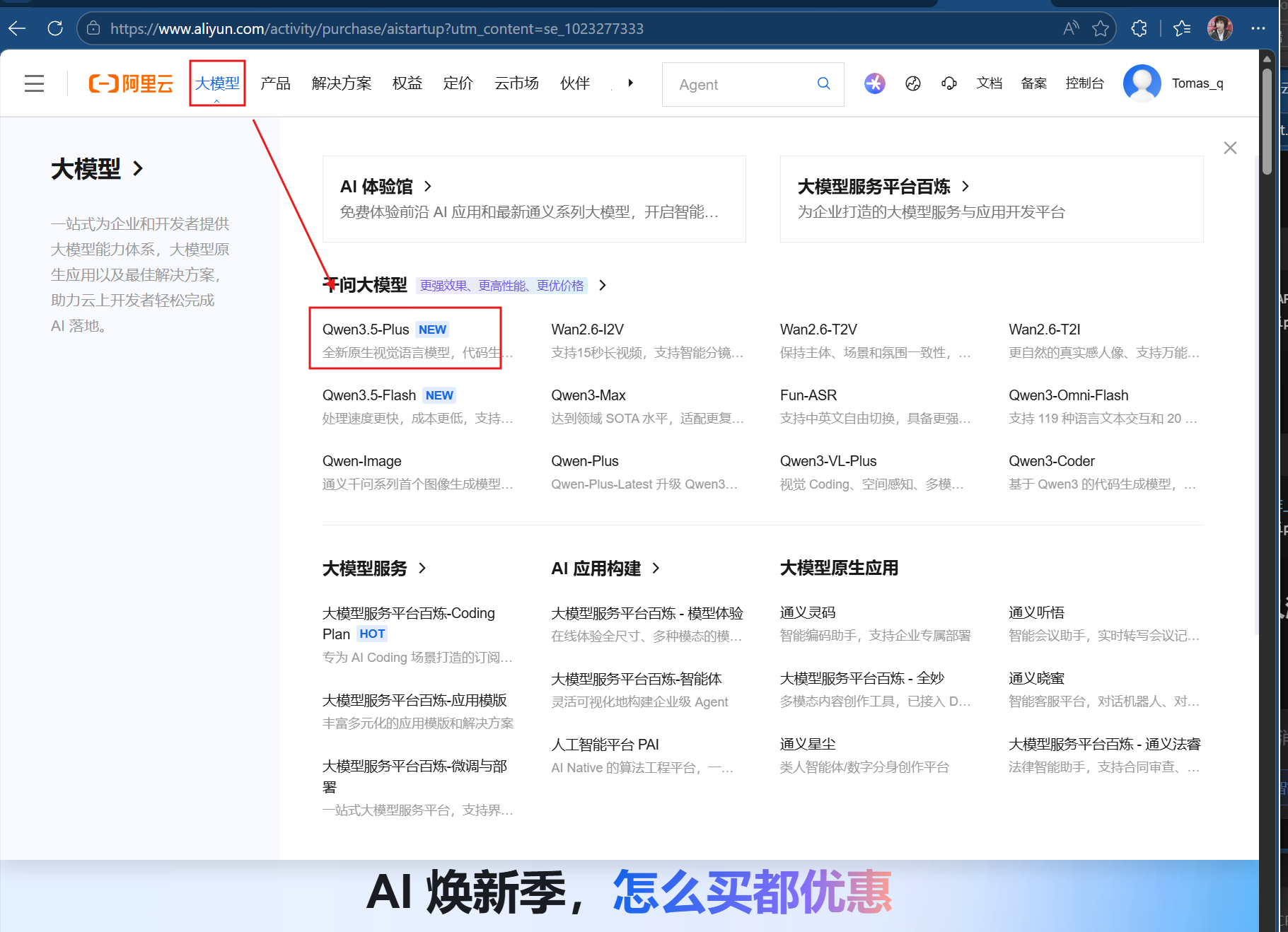
3.点击右上角设置,然后左栏apl_key,创建apl_key
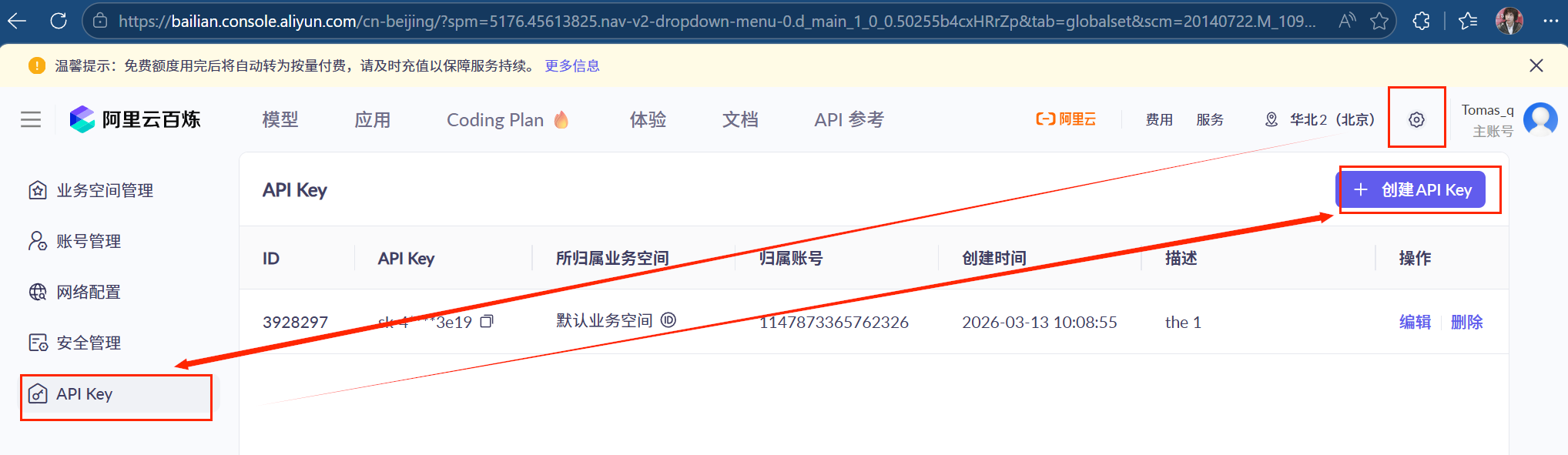
4.这样我们就建好一个apl_key
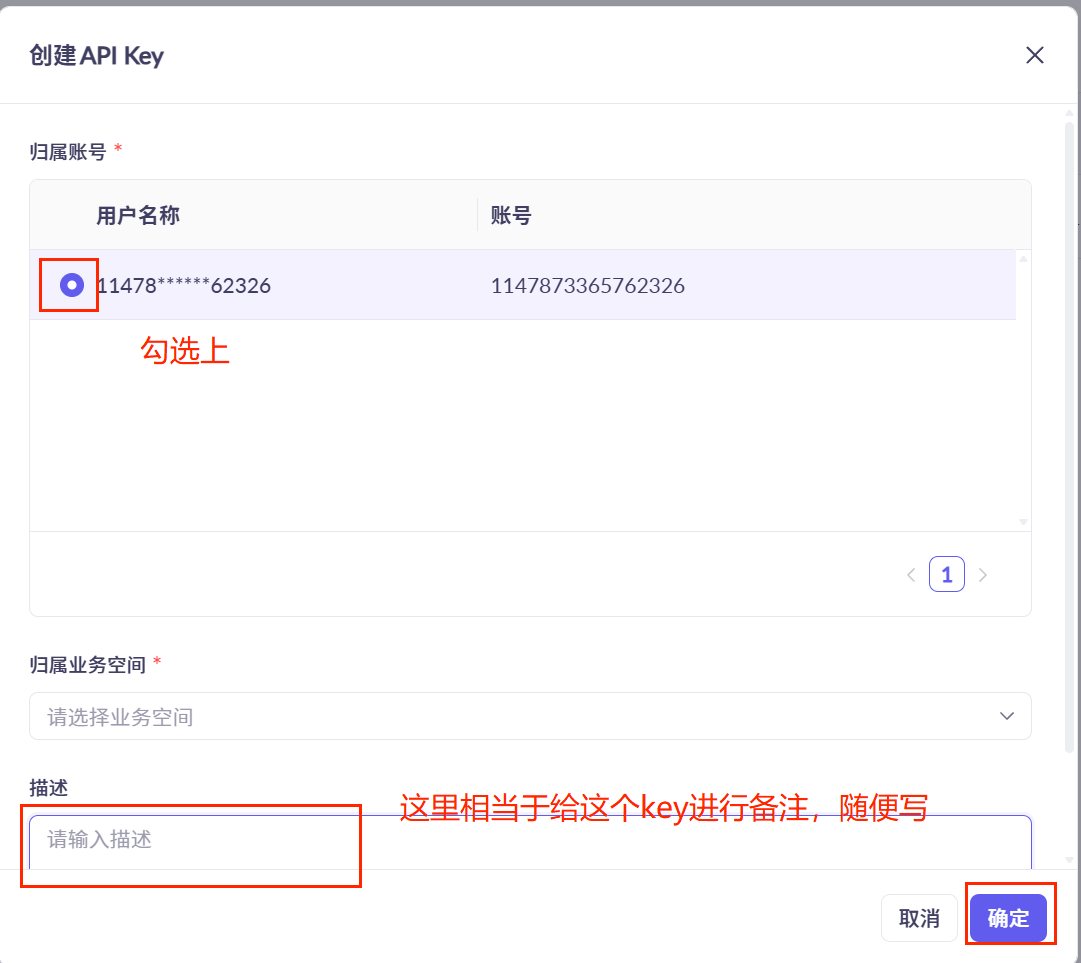
API Key相当于密码,不能随便分享,建议使用环境变量。
二、环境配置
1.下载第三方库
这里我们设置一个虚拟环境,因为对库的版本要求不同,防止冲突
pip install langchain_openai可以把以下写入一个txt文件,在python编写工具里,这里我使用的 是pycharm,就在pycharm终端里面执行pip install -r 文件地址,就可以全部直接下载了。
aiofiles==23.2.1
aiohttp==3.9.1
aiosignal==1.3.1
altair==5.2.0
annotated-types==0.6.0
anyio==3.7.1
async-timeout==4.0.3
attrs==23.1.0
beautifulsoup4==4.12.2
blinker==1.7.0
Brotli==1.1.0
cachetools==5.3.2
certifi==2023.11.17
charset-normalizer==3.3.2
click==8.1.7
dataclasses-json==0.6.3
distro==1.8.0
duckduckgo-search==3.9.9
exceptiongroup==1.2.0
frozenlist==1.4.0
gitdb==4.0.11
GitPython==3.1.40
greenlet==3.0.1
h11==0.14.0
h2==4.1.0
hpack==4.0.0
httpcore==1.0.2
httpx==0.25.2
hyperframe==6.0.1
idna==3.6
importlib-metadata==6.8.0
Jinja2==3.1.2
jsonpatch==1.33
jsonpointer==2.4
jsonschema==4.20.0
jsonschema-specifications==2023.11.2
langchain==0.1.9
langchain-community==0.0.24
langchain-core==0.1.26
langchain-openai==0.0.7
langsmith==0.1.6
lxml==4.9.3
markdown-it-py==3.0.0
MarkupSafe==2.1.3
marshmallow==3.20.1
mdurl==0.1.2
multidict==6.0.4
mypy-extensions==1.0.0
numpy==1.26.2
openai==1.12.0
orjson==3.9.15
packaging==23.2
pandas==2.1.3
Pillow==10.1.0
protobuf==4.25.1
pyarrow==14.0.1
pydantic==2.5.2
pydantic_core==2.14.5
pydeck==0.8.1b0
Pygments==2.17.2
python-dateutil==2.8.2
pytz==2023.3.post1
PyYAML==6.0.1
referencing==0.31.1
regex==2023.12.25
requests==2.31.0
rich==13.7.0
rpds-py==0.13.2
six==1.16.0
smmap==5.0.1
sniffio==1.3.0
socksio==1.0.0
soupsieve==2.5
SQLAlchemy==2.0.23
streamlit==1.31.1
tenacity==8.2.3
tiktoken==0.6.0
toml==0.10.2
toolz==0.12.0
tornado==6.4
tqdm==4.66.1
typing-inspect==0.9.0
typing_extensions==4.8.0
tzdata==2023.3
tzlocal==5.2
urllib3==2.1.0
validators==0.22.0
wikipedia==1.4.0
yarl==1.9.3
zipp==3.17.02.使用key的两种方式
1)在环境变量中添加
这种方式一般比较保密,以防我们的aplkey暴露
首先打开环境变量
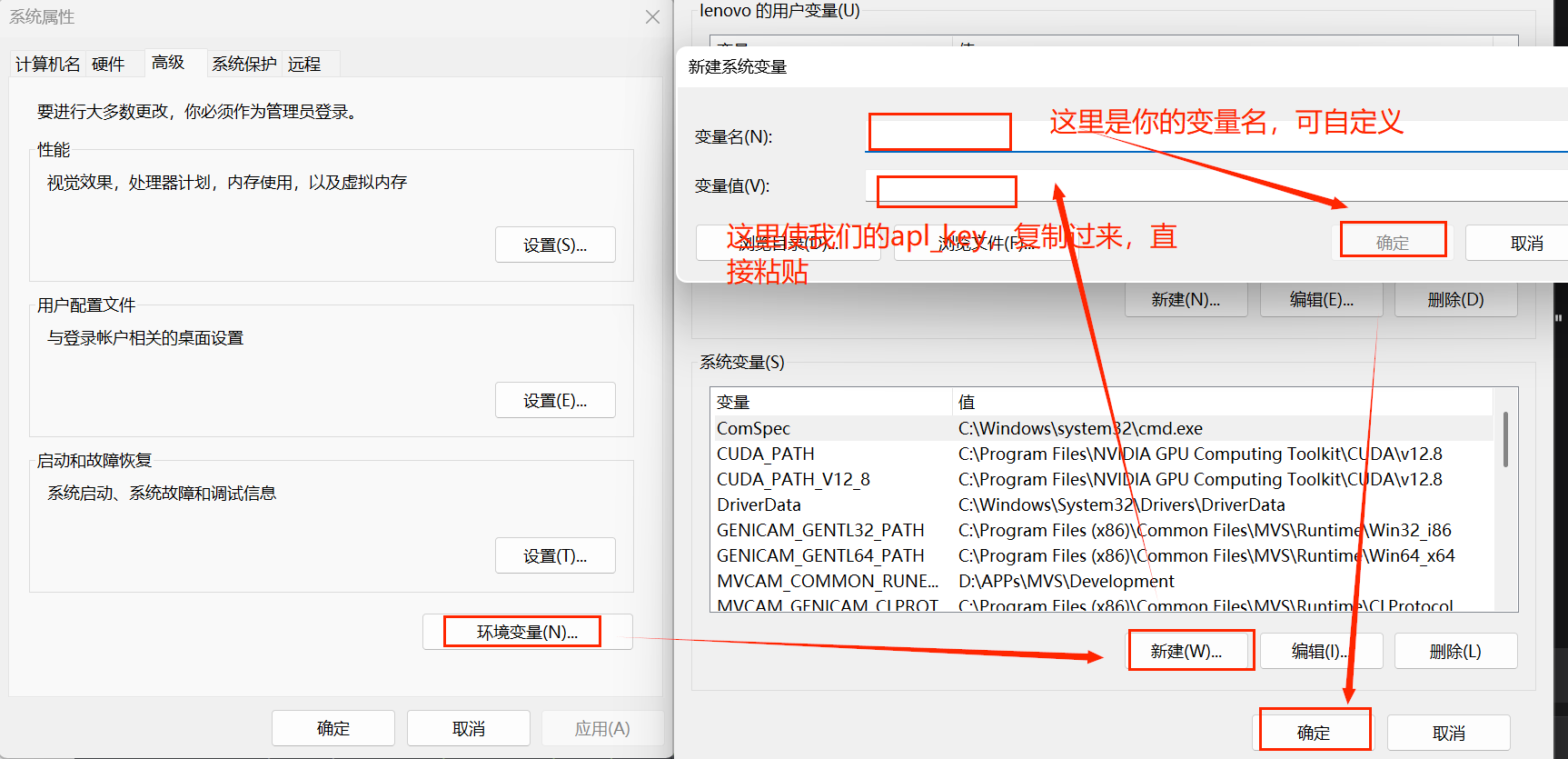
具体使用方法可以询问大模型
2)直接在代码中使用
在下面代码中所用方法都是这种
当然官方使用方法也是这种
三、代码实现
from langchain_openai import ChatOpenAI
model = ChatOpenAI(model="qwen3.5-plus",
openai_api_key="sk-45*******************3e19",
openai_api_base="https://dashscope.aliyuncs.com/compatible-mode/v1",
temperature=1.2,#越高越随机
max_tokens=300)
# model = ChatOpenAI(model="gpt-3.5-turbo", temperature=1.2, max_tokens=500, model_kwargs={"frequency_penalty":1.1})
from langchain.schema.messages import HumanMessage, SystemMessage
messages = [
SystemMessage(content="请你作为我的数学课助教,用通俗易懂且直接的语言帮我解释数学原理。"),
HumanMessage(content="什么是勾股定理?"),
]
response = model.invoke(messages)
print(response.content)这里使用的是langchain的chatOpenAI类,兼容OpenAI,调用了阿里云的千问模型。temperature值越高,输出月随机,值越低输出越保守。
消息结构,这里设置的是humanmessage(用户的具体提问)和systemmessage(设定ai角色和行为准则)
最后response和print进行调用和输出,invoke()发送消息并获取响应,reponse.content提取ai返回的文本内容
四、提示词
from langchain_openai import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
prompt_template = ChatPromptTemplate.from_messages(
[
("system", "你是一位专业的翻译,能够将{input_language}翻译成{output_language},并且输出文本会根据用户要求的任何语言风格进行调整。请只输出翻译后的文本,不要有任何其它内容。"),
("human", "文本:{text}\n语言风格:{style}"),
]
)
ChatPromptTemplate 动态模板
{input_language},{output_language}占位符,是模版变量。可以实现动态填充。
prompt_value = prompt_template.invoke({"input_language": "汉语", "output_language": "汉语",
"text":"勿以善小而不为,勿以恶小而为之。", "style": "白话文"})
model = ChatOpenAI(model="qwen-plus",
openai_api_key="sk-450********************9",
openai_api_base="https://dashscope.aliyuncs.com/compatible-mode/v1")
response = model.invoke(prompt_value)
模版嵌套调用,两个invoke,第一个是进行填充模板变量,生成完整的prompt;第二个是调用模型,生成回复。
input_variables = [
{
"input_language": "汉语",
"output_language": "汉语",
"text": "勿以善小而不为,勿以恶小而为之。",
"style": "白话文"
},
{
"input_language": "法语",
"output_language": "英语",
"text": "Je suis désolé pour ce que tu as fait",
"style": "古英语"
},
{
"input_language": "俄语",
"output_language": "意大利语",
"text": "Сегодня отличная погода",
"style": "网络用语"
},
{
"input_language": "韩语",
"output_language": "日语",
"text": "너 정말 짜증나",
"style": "口语"
}
]
for input in input_variables:
response = model.invoke(prompt_template.invoke({"input_language": input["input_language"], "output_language": input["output_language"],
"text":input["text"], "style": input["style"]}))
print(response.content)多轮批量调用,循环调用同一个模版处理多组数据,进行批量处理。对同一个模版处理成不同的语言组合
输入数据结构化,input_variables是一个字典列表,结构化存储多组参数,每组可设置不同语言风格,实现灵活配置。
模版中定义了四个变量,input_language&out_language&text&style,分别是原语言,目标语言,等待翻译的文本,输出风格。
五、少样本学习
from langchain_openai import ChatOpenAI
from langchain.prompts import FewShotChatMessagePromptTemplate, ChatPromptTemplate
example_prompt = ChatPromptTemplate.from_messages(
[
("human", "格式化以下客户信息:\n姓名 -> {customer_name}\n年龄 -> {customer_age}\n 城市 -> {customer_city}"),
("ai", "##客户信息\n- 客户姓名:{formatted_name}\n- 客户年龄:{formatted_age}\n- 客户所在地:{formatted_city}")
]
)
examples = [
{
"customer_name": "张三",
"customer_age": "27",
"customer_city": "长沙",
"formatted_name": "张三",
"formatted_age": "27岁",
"formatted_city": "湖南省长沙市"
},
{
"customer_name": "李四",
"customer_age": "42",
"customer_city": "广州",
"formatted_name": "李四",
"formatted_age": "42岁",
"formatted_city": "广东省广州市"
},
]
human,展示输入格式,也就是用户说了什么
ai:ai回答的输出格式,和human是一一对应的
我们还给出了两个example
example_prompt,用来定义示例的格式
few_shot_template = FewShotChatMessagePromptTemplate(
example_prompt=example_prompt,
examples=examples,
)这里给先给模型例子,展示了两个格式化示例,在要求他去处理新数据,上面的例子都是直接给指令,是零样本学习
将多个示例组合成一个few-shot模版
final_prompt = final_prompt_template.invoke({"input": "格式化以下客户信息:\n姓名 -> 王五\n年龄 -> 31\n 城市 -> 郑州'"})
model = ChatOpenAI(model="qwen3.5-plus",
openai_api_key="sk-**********************",
openai_api_base="https://dashscope.aliyuncs.com/compatible-mode/v1")
response = model.invoke(final_prompt)
print(response.content)
final_prompt_template是将few-shot模版+新用户输入组合成最终prompt

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 13
13 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)